数据挖掘的承诺是,算法会处理数据并找出可以利用在您的业务中的有趣模式。
这一承诺的典范是市场篮子分析(维基百科称之为亲和力分析)。给定大量的交易记录,发现有趣的购买模式,可以用来在商店中利用,例如促销和产品布局。
在这篇文章中,您将通过关联规则学习在Weka 中完成一个市场篮子分析教程。如果您遵循分步说明,您将在 5 分钟内对销售点数据运行市场篮子分析。
通过我的新书《Weka 机器学习精通》启动您的项目,书中包含分步教程和所有示例的清晰屏幕截图。
让我们开始吧。

市场篮子分析
图片由 HealthGauge 提供,保留部分权利。
关联规则学习
我曾为一家初创公司做过咨询工作,该公司正在研究 SaaS 应用中的客户行为。我们对表明客户流失或从免费账户转换为付费账户的行为模式感兴趣。
我花了数周时间仔细研究数据,查看相关性和图表。我得出了一系列表明结果的规则,并提出了可能干预以影响这些结果的设想。
我得出了类似这样的规则:“*用户在 y 天内创建了 x 个小部件,并登录了 n 次,那么他们将转化*”。我给这些规则赋予了数字,例如支持度(与规则匹配的记录占所有记录的比例)和提升度(使用该规则预测转化时的预测准确性提升百分比)。
直到我交付并提交报告后,我才意识到我犯了一个多么严重的错误。我竟然是手工完成了关联规则学习,而实际上有现成的算法可以替我完成这项工作。
我分享这个故事是为了让它留在您的脑海中。如果您正在筛选大型数据集以寻找有趣的模式,关联规则学习是一套您应该使用的方法。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
1. 启动 Weka Explorer
在之前的教程中,我们已经学习了运行分类器、设计和运行实验、算法调优和集成方法。如果您需要有关下载和安装 Weka 的帮助,请参阅这些之前的帖子。
Weka GUI 选择器
启动 Weka Explorer。
2. 加载超市数据集
Weka 附带了 Weka 安装“data”目录中的许多真实数据集。这非常方便,因为您可以探索和实验这些著名的项目,并了解 Weka 中可用的各种方法。
加载超市数据集(data/supermarket.arff)。这是一个销售点信息的 数据集。数据是标称型的,每个实例代表一次超市客户交易,购买的产品以及涉及的部门。关于这个数据集的在线信息不多,尽管您可以 看到这个评论(“使用 supermarket.arff 进行学术研究的问题”),这是收集数据的个人提供的。
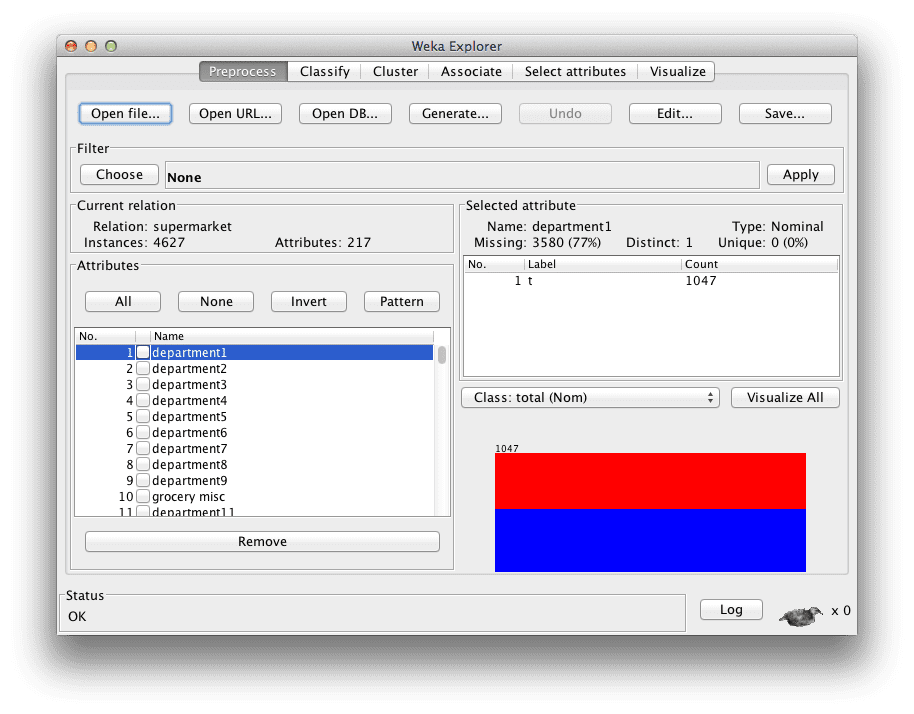
超市数据集已加载到 Weka Explorer 中
该数据包含 4,627 个实例和 217 个属性。数据是反规范化的。每个属性都是二元的,要么有一个值(“*t*”表示真),要么没有值(“*?*”表示缺失)。有一个名为“total”的标称类属性,表示交易金额是低于 100 美元(low)还是高于 100 美元(high)。
我们不关心创建“total”的预测模型。相反,我们关心的是哪些商品被一起购买。我们感兴趣的是在该数据中找到可能与预测属性相关或不相关的有用模式。
3. 发现关联规则
在 Weka Explorer 中点击“Associate”选项卡。“Apriori”算法将已自动选中。这是最著名的关联规则学习方法,因为它可能是最早的(1994 年由Agrawal 和 Srikant提出),并且效率非常高。
原则上,该算法非常简单。它构建属性-值(项)集,以最大化可以解释的实例数量(数据集的覆盖范围)。项空间的搜索在很大程度上类似于属性选择和子集搜索所面临的问题。
点击“Start”按钮在数据集上运行 Apriori。
4. 分析结果
关联规则学习的真正工作在于对结果的解释。
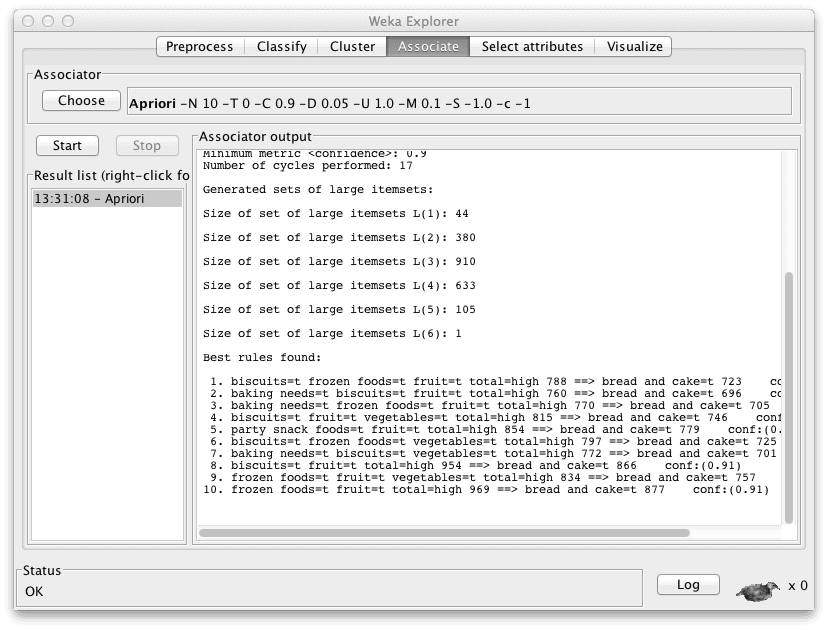
Weka 中 Apriori 关联规则学习的结果
从“Associator output”窗口中可以看出,该算法从超市数据集中提取了 10 条规则。该算法默认配置为停止在 10 条规则,如果您愿意,可以通过更改“numRules”值来点击算法名称进行配置,以查找和报告更多规则。
发现的规则是
- biscuits=t frozen foods=t fruit=t total=high 788 ==> bread and cake=t 723 conf:(0.92)
- baking needs=t biscuits=t fruit=t total=high 760 ==> bread and cake=t 696 conf:(0.92)
- baking needs=t frozen foods=t fruit=t total=high 770 ==> bread and cake=t 705 conf:(0.92)
- biscuits=t fruit=t vegetables=t total=high 815 ==> bread and cake=t 746 conf:(0.92)
- party snack foods=t fruit=t total=high 854 ==> bread and cake=t 779 conf:(0.91)
- biscuits=t frozen foods=t vegetables=t total=high 797 ==> bread and cake=t 725 conf:(0.91)
- baking needs=t biscuits=t vegetables=t total=high 772 ==> bread and cake=t 701 conf:(0.91)
- biscuits=t fruit=t total=high 954 ==> bread and cake=t 866 conf:(0.91)
- frozen foods=t fruit=t vegetables=t total=high 834 ==> bread and cake=t 757 conf:(0.91)
- frozen foods=t fruit=t total=high 969 ==> bread and cake=t 877 conf:(0.91)
很酷,对吧!
您可以看到规则是以“前项 => 后项”的格式呈现的。与前项关联的数字是数据集中绝对覆盖数(在本例中为总共 4,627 个中的一个数字)。与后项关联的数字是匹配前项和后项的实例的绝对数量。括号中的数字是规则的支持度(前项数量除以匹配后项的数量)。您可以看到选择规则时使用了 91% 的阈值,这在“Associator output”窗口中提到过,并且在此处显示为没有规则的覆盖率低于 0.91。
我不想一一介绍这 10 条规则,那样太繁琐了。以下是一些观察结果:
- 我们可以看到所有呈现的规则的后项都是“bread and cake”。
- 所有呈现的规则都表明总交易金额较高。
- “biscuits”和“frozen foods”出现在许多呈现的规则中。
您必须非常小心地解释关联规则。它们是关联(考虑相关性),不一定是因果关系。此外,较短的前项可能比更长的前项更稳健,后者更可能脆弱。

增加篮子尺寸
图片由 goosmurf 提供,保留部分权利。
例如,如果我们对总金额感兴趣,我们可能会想说服购买饼干、冷冻食品和水果的顾客购买面包和蛋糕,以便他们获得高总交易金额(规则 #1)。这听起来似乎有道理,但推理是错误的。产品组合并不会导致高总金额,它仅仅与高总金额相关。那 723 笔交易可能除了规则中的商品外,还有大量随机的其他商品。
可能有趣的是测试模型通过商店的路径来收集相关商品,并观察路径的变化(更短、更长、展示的促销等)是否会影响交易金额或篮子尺寸。
总结
在这篇文章中,您发现了从大型数据集中自动学习关联规则的强大功能。您了解到,与手工推导规则相比,使用 Apriori 等算法是一种更有效的方法。
您在 Weka 中进行了第一次市场篮子分析,并了解到真正的工作在于对结果的分析。您发现了在解释规则时所需的细致关注,并且关联(相关性)不等于因果关系。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






好文章。我写过关于使用 R 进行关联规则挖掘的两部分文章,第一部分解释概念,第二部分解释使用 R 进行可视化实现。
请在这里查看 http://prdeepakbabu.wordpress.com/2010/11/13/market-basket-analysisassociation-rule-mining-using-r-package-arules/
Deepak,好文章,谢谢分享。
谢谢,我对这个例子理解了很多概念。但我使用的是 weka 3.7.1,您能给我提供一个 weka 中使用小型数据集的例子吗,比如 weather.arff,.cpu.arff 等等。
我很感激。
非常感谢您的合作。
但是有一个问题,超市数据集太大。
我尝试进行示例,但超市数据集不可用。
先生,如果您能提供像 weather.arrf 这样的其他数据集的示例,我将不胜感激。
期待您的关照。
我正在处理阿拉伯语文本,您能为我提供阿拉伯语数据集的示例,然后将其转换为 CSV 和 ARFF 格式吗?
我很感激。
哥们,你真让我开心了一天。非常感谢。
我还有另一个问题,如何增加堆内存大小?我尝试编辑 runWeka.bat 文件和 runWeka.ini。我尝试了 xmx 和 maxheap=2014mb 以及其他所有内容。但问题是,我无法保存编辑后的文件。
你可以,但最好还是处理你的源数据的代表性样本。
这个 weka 工具是否有助于找到频繁和不频繁项集,然后找到关联规则?
你好,Jason。
您的文章非常适合用 Weka 的超市示例介绍关联规则。
我想指出,在解释规则含义的这一点上存在错误
“括号中的数字是规则的支持度(前项数量除以匹配后项的数量)。”
该数字是置信度指标的值,这也暗示了规则在输出中的排序方式。
此致,
Álvaro
我想使用关联规则挖掘来计算每个用户的购买次数。例如,用户 A 听了项目 a 3 次。谢谢
请帮助我,如何在 weka 中创建这个规则?
“点击 (CDi) 和阅读时长 (High))___点击 (CDj)”
“购物篮摆放 (CDi) 和播放次数 (3)____购物篮
摆放 (CDj)”
您好。
您的文章非常适合用 Weka 的超市示例介绍关联规则。
最佳规则发现
1. biscuits=t frozen foods=t fruit=t total=high 788 ==> bread and cake=t 723 lift:(1.27) lev:(0.03) [155] conv:(3.35)
2. baking needs=t biscuits=t fruit=t total=high 760 ==> bread and cake=t 696 lift:(1.27) lev:(0.03) [149] conv:(3.28)
3. baking needs=t frozen foods=t fruit=t total=high 770 ==> bread and cake=t 705 lift:(1.27) lev:(0.03) [150] conv:(3.27)
4. biscuits=t fruit=t vegetables=t total=high 815 ==> bread and cake=t 746 lift:(1.27) lev:(0.03) [159] conv:(3.26)
5. party snack foods=t fruit=t total=high 854 ==> bread and cake=t 779 lift:(1.27) lev:(0.04) [164] conv:(3.15)
6. biscuits=t frozen foods=t vegetables=t total=high 797 ==> bread and cake=t 725 lift:(1.26) lev:(0.03) [151] conv:(3.06)
7. baking needs=t biscuits=t vegetables=t total=high 772 ==> bread and cake=t 701 lift:(1.26) lev:(0.03) [145] conv:(3.01)
8. biscuits=t fruit=t total=high 954 ==> bread and cake=t 866 lift:(1.26) lev:(0.04) [179] conv:(3)
9. frozen foods=t fruit=t vegetables=t total=high 834 ==> bread and cake=t 757 lift:(1.26) lev:(0.03) [156] conv:(3)
10. frozen foods=t fruit=t total=high 969 ==> bread and cake=t 877 lift:(1.26) lev:(0.04) [179] conv:(2.92)
干得好!
我想使用关联规则挖掘来计算每个用户的购买次数。例如,用户 A 听了项目 a 3 次。谢谢
请帮助我,如何在 weka 中创建这个规则?
而且我想分析结果中的 True,而不是 False,对于项目,谢谢。
如果有日期怎么办?如果我们想找出何时购买的模式以及它们之间的关联
是的,日期通常可以提供很多有用的信息。
Jason 你好!感谢你提供这么棒的网站!我有一个问题。如果我的数据集是二元的(0,1)怎么办?我有一个杂货店数据集,其中每一列是一个商品,0 或 1 表示是否购买。行是收据,或个人购买的商品列表。我想通过使用 weka 关联来找出哪些商品一起购买,但生成的排名前十的规则总是 0(否)。我想找出只有 1 的规则,因为它们告诉我人们买了什么。目前生成的否规则在结果中告诉我人们没有买什么。我该如何解决这个问题?我希望我解释得很清楚。
例子
1. Vanilla Eclair=No Vanilla Meringue=No Chocolate Croissant=No Almond Bear Claw=No 63188 ==> Almond Tart=No 60738 lift:(1) lev:(0) [206] conv:(1.08)
2. Vanilla Eclair=No Vanilla Meringue=No Chocolate Croissant=No Blueberry Danish=No 63064 ==> Almond Tart=No 60618 lift:(1) lev:(0) [205] conv:(1.08)
3. Chocolate Eclair=No Vanilla Eclair=No Vanilla Meringue=No Chocolate Croissant=No 63181 ==> Almond Tart=No 60730 lift:(1) lev:(0) [205] conv:(1.08)
4. Vanilla Eclair=No Apricot Tart=No Vanilla Meringue=No Almond Bear Claw=No 63254 ==> Almond Tart=No 60797 lift:(1) lev:(0) [202] conv:(1.08)
5. Vanilla Eclair=No Apricot Tart=No Vanilla Meringue=No Blueberry Danish=No 63118 ==> Almond Tart=No 60666 lift:(1) lev:(0) [201] conv:(1.08)
6. Chocolate Eclair=No Vanilla Eclair=No Apricot Tart=No Vanilla Meringue=No 63234 ==> Almond Tart=No 60777 lift:(1) lev:(0) [201] conv:(1.08)
7. Vanilla Eclair=No Apricot Tart=No Vanilla Meringue=No Chocolate Croissant=No 63180 ==> Almond Tart=No 60725 lift:(1) lev:(0) [201] conv:(1.08)
也有可能根本找不到有趣的模式,请记住这一点。
这是个好问题。也许数据不够丰富?也许你可以收集更多特征来描述每个结果?
嗨 Jason.. 如果我想创建个性化的推送通知给我的客户,我该如何使用这些规则?
我已经有一个包含客户过去购买记录的数据集。我发现困难的是如何一键将个性化广告发送给他们。
这真的取决于您的应用程序和数据。
非常好。感谢分享这个分析。
不客气。
您好,篮子大小是否必须大于 1?也就是说,我们需要只考虑那些购买了超过 1 种产品的发票才能获得产品关联吗?
是的,除非您是在客户的购买记录中进行查找。
谢谢 Jason,是的,跨客户的购买记录也能带来一些不错的见解,我会看看的。
您好,我已经完成了市场篮子报告的处理,现在是时候从中提取一些见解并进行推荐了。
我的问题是,看过置信度和提升度参数后,哪个是更好的指标?其次,我看到一些前项具有不错的支持度和提升度 > 1,但置信度矩阵较低,约为 15%。
我知道推荐是非常主观的,主要取决于业务如何看待每个参数。
但需要一些指导性的观点,说明我们如何向客户推荐产品。
也许找出利益相关者的目标,并以此来推动解释。
或者在报告中采取不同的立场,然后解释结果。例如,如果 x 很重要,那么该方法发现...,否则,如果 y 很重要,该方法发现...
希望这能有所帮助。
好博客!感谢分享这篇有用的文章。
谢谢。
嗨 Jason
对于相同的示例且不更改任何参数,第二条规则的支持度是多少?以及如何获得它?
嗨 Jason,我该如何使用关联规则中的属性来作为 MLP 等分类器的输入?
我不确定这是否是合适的方法。
谢谢 Jason,是否可以从生成的规则中选择最佳属性?
不行。
Jason,您好,我使用了具有9个属性和一个类别属性的wbc数据集来创建关联规则模型,生成的规则只有6个属性和一个类别属性。这3个属性是否不相关?
我不知道,抱歉。
Jason,非常感谢您提供的所有精彩教程!
我的问题是,是否可以在Python中实现Apriori算法来预测房价(例如,针对普通的波士顿房价数据集)?
Apriori 查找模式,但不进行预测。
我认为您想使用回归算法。也许这会有所帮助
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
Jason,这篇文章非常有趣!
我认为有一点可以补充的是,存在许多算法,它们在给定一组参数的情况下基本上可以得到相同的规则,并且它们在计算速度上有所不同。因此,根据您的数据集有多宽,您可能需要考虑使用 ECLAT 或 F-P Growth。
我最近在我的博客上发表了一篇关于一些理论和Python实现的文章,您可以随意看看,并告诉我您的想法: https://pyshark.com/market-basket-analysis-using-association-rule-mining-in-python/
感谢分享。
嗨 Jason
感谢您这篇精彩的文章。我正在为一个学校作业使用weka和超市数据集。我有一个问题感到困惑,希望您能尽快提供帮助。
问题:假设此数据集中80%的值是缺失的。那么,平均客户购物篮中包含多少商品(提示:这意味着平均而言,20%的属性在实例中值为“t”)?
谢谢
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-help-me-with-my-homework-or-assignment
你好!
这太棒了。谢谢您。您能告诉我如何在此找到排名最高的关联规则吗?
抱歉,我没有更多关于关联规则的教程。也许将来会有。
“括号里的数字是规则的支持度”
那么“非”呢?
“支持度”是靠近规则的“承诺”部分和“结果”部分的数字。
下一篇关于Apriori的文章,作者不知道如何解释结果。
谢谢。
Jason,您好,我喜欢您的文章。我只是想指出一些错别字。希望这有帮助。
“我分享这个故事是为了让它留在您的脑海里。如果您正在从大型数据集中筛选有趣的模式,那么关联规则学习是一套您应该使用的方法。”
抓得好!谢谢。
嗨,Jason,
感谢您的帖子,一如既往的优秀。我们热爱您的作品!只是提醒一下,我发现您提供的有关数据的信息链接已失效,但我查找了一下,在另一篇讨论中发现了一些关于数据集的细节,就在这里
https://list.waikato.ac.nz/hyperkitty/list/wekalist@list.waikato.ac.nz/thread/M5Y6F2ZMYQFBWJTUHJNRHHRS27RWSNQL/
我希望它有所帮助。
谢谢
谢谢。链接已相应更新。