当我们谈论管理数据时,看到表格形式呈现的数据是不可避免的。带有列标题,有时还有行名,这使得理解数据更容易。事实上,我们经常会看到不同类型的数据共存于一个表格中。例如,在食谱原料的表格中,我们有作为数字的数量和作为字符串的名称。在 Python 中,我们有 pandas 库来帮助我们处理表格数据。
完成本教程后,你将学到:
- Pandas 库提供了什么
- Pandas 中的 DataFrame 和 Series 是什么
- 如何对 DataFrame 和 Series 进行超越琐碎数组运算的操作
开启您的项目,阅读我的新书《Python for Machine Learning》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧!
使用 Pandas 处理数据
照片由 Mark de Jong 拍摄。部分权利保留。
概述
本教程分为五个部分
- DataFrame 和 Series
- DataFrame 中的基本函数
- 操作 DataFrame 和 Series
- DataFrame 中的聚合
- 在 Pandas 中处理时间序列数据
DataFrame 和 Series
首先,让我们从一个示例数据集开始。我们将导入 pandas 并读取 美国空气污染物排放数据 到 DataFrame 中。
|
1 2 3 4 5 6 |
import pandas as pd URL = "https://www.epa.gov/sites/default/files/2021-03/state_tier1_caps.xlsx" df = pd.read_excel(URL, sheet_name="State_Trends", header=1) print(df) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
州 FIPS 州 一级代码 一级描述 ... emissions18 emissions19 emissions20 emissions21 0 1 AL 1 FUEL COMB. ELEC. UTIL. ... 10.050146 8.243679 8.243679 8.243679 1 1 AL 1 FUEL COMB. ELEC. UTIL. ... 0.455760 0.417551 0.417551 0.417551 2 1 AL 1 FUEL COMB. ELEC. UTIL. ... 26.233104 19.592480 13.752790 11.162100 3 1 AL 1 FUEL COMB. ELEC. UTIL. ... 2.601011 2.868642 2.868642 2.868642 4 1 AL 1 FUEL COMB. ELEC. UTIL. ... 1.941267 2.659792 2.659792 2.659792 ... ... ... ... ... ... ... ... ... ... 5314 56 WY 16 PRESCRIBED FIRES ... 0.893848 0.374873 0.374873 0.374873 5315 56 WY 16 PRESCRIBED FIRES ... 7.118097 2.857886 2.857886 2.857886 5316 56 WY 16 PRESCRIBED FIRES ... 6.032286 2.421937 2.421937 2.421937 5317 56 WY 16 PRESCRIBED FIRES ... 0.509242 0.208817 0.208817 0.208817 5318 56 WY 16 PRESCRIBED FIRES ... 16.632343 6.645249 6.645249 6.645249 [5319 行 x 32 列] |
这是每年的污染物排放量表格,其中包含污染物的种类和每年的排放量信息。
这里我们演示了 pandas 的一个有用特性:你可以使用 `read_csv()` 读取 CSV 文件,或者像上面一样使用 `read_excel()` 读取 Excel 文件。文件名可以是本地文件,也可以是可供下载文件的 URL。我们从美国环境保护署的网站上了解到这个 URL。我们知道哪个工作表包含数据以及数据从哪一行开始,因此在 `read_excel()` 函数中使用了额外的参数。
上面创建的 pandas 对象是一个 DataFrame,以表格形式呈现。与 NumPy 类似,Pandas 中的数据组织在数组中。但是 Pandas 为列分配数据类型,而不是整个数组。这允许在同一数据结构中包含不同类型的数据。我们可以通过调用 DataFrame 的 `info()` 函数来检查数据类型
|
1 2 |
... df.info() # 打印信息到屏幕 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<class 'pandas.core.frame.DataFrame'> RangeIndex: 5319 entries, 0 to 5318 Data columns (total 32 columns) # Column Non-Null Count Dtype --- ------ -------------- ----- 0 State FIPS 5319 non-null int64 1 State 5319 non-null object 2 Tier 1 Code 5319 non-null int64 3 Tier 1 Description 5319 non-null object 4 Pollutant 5319 non-null object 5 emissions90 3926 non-null float64 6 emissions96 4163 non-null float64 7 emissions97 4163 non-null float64 ... 29 emissions19 5052 non-null float64 30 emissions20 5052 non-null float64 31 emissions21 5052 non-null float64 dtypes: float64(27), int64(2), object(3) memory usage: 1.3+ MB |
或者我们也可以获取一个 pandas Series 类型的类型
|
1 2 3 |
... coltypes = df.dtypes print(coltypes) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
State FIPS int64 State object Tier 1 Code int64 Tier 1 Description object Pollutant object emissions90 float64 emissions96 float64 emissions97 float64 ... emissions19 float64 emissions20 float64 emissions21 float64 dtype: object |
在 pandas 中,DataFrame 是一张表,而 Series 是表中的一列。这个区别很重要,因为 DataFrame 后面的数据是二维数组,而 Series 是一维数组。
类似于 NumPy 中的花式索引,我们可以从一个 DataFrame 中提取列来创建另一个 DataFrame。
|
1 2 3 4 |
... cols = ["State", "Pollutant", "emissions19", "emissions20", "emissions21"] last3years = df[cols] print(last3years) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
State Pollutant emissions19 emissions20 emissions21 0 AL CO 8.243679 8.243679 8.243679 1 AL NH3 0.417551 0.417551 0.417551 2 AL NOX 19.592480 13.752790 11.162100 3 AL PM10-PRI 2.868642 2.868642 2.868642 4 AL PM25-PRI 2.659792 2.659792 2.659792 ... ... ... ... ... ... 5314 WY NOX 0.374873 0.374873 0.374873 5315 WY PM10-PRI 2.857886 2.857886 2.857886 5316 WY PM25-PRI 2.421937 2.421937 2.421937 5317 WY SO2 0.208817 0.208817 0.208817 5318 WY VOC 6.645249 6.645249 6.645249 [5319 行 x 5 列] |
或者,如果传递给字符串而不是列名列表,则我们提取 DataFrame 中的一列作为 Series。
|
1 2 3 |
... data2021 = df["emissions21"] print(data2021) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
0 8.243679 1 0.417551 2 11.162100 3 2.868642 4 2.659792 ... 5314 0.374873 5315 2.857886 5316 2.421937 5317 0.208817 5318 6.645249 Name: emissions21, Length: 5319, dtype: float64 |
DataFrame 中的基本函数
Pandas 功能丰富。对表或列的许多基本操作都作为 DataFrame 或 Series 上定义的函数提供。例如,我们可以使用以下方法查看表中包含的污染物列表:
|
1 2 |
... print(df["Pollutant"].unique()) |
|
1 |
['CO' 'NH3' 'NOX' 'PM10-PRI' 'PM25-PRI' 'SO2' 'VOC'] |
同样,我们可以找到 Series 的平均值(`mean()`)、标准差(`std()`)、最小值(`min()`)和最大值(`max()`)。
|
1 2 |
... print(df["emissions21"].mean()) |
但实际上,我们更可能使用 `describe()` 函数来探索新的 DataFrame。由于本例中的 DataFrame 列数过多,因此最好对 `describe()` 的结果 DataFrame 进行转置。
|
1 2 |
... print(df.describe().T) |
|
1 2 3 4 5 6 7 8 9 10 |
count mean std min 25% 50% 75% max State FIPS 5319.0 29.039481 15.667352 1.00000 16.000000 29.000000 42.000000 56.000000 Tier 1 Code 5319.0 8.213198 4.610970 1.00000 4.000000 8.000000 12.000000 16.000000 emissions90 3926.0 67.885173 373.308888 0.00000 0.474330 4.042665 20.610050 11893.764890 emissions96 4163.0 54.576353 264.951584 0.00001 0.338420 3.351860 16.804540 6890.969060 emissions97 4163.0 51.635867 249.057529 0.00001 0.335830 3.339820 16.679675 6547.791030 ... emissions19 5052.0 19.846244 98.392126 0.00000 0.125881 1.180123 7.906181 4562.151689 emissions20 5052.0 19.507828 97.515187 0.00000 0.125066 1.165284 7.737705 4562.151689 emissions21 5052.0 19.264532 96.702411 0.00000 0.125066 1.151917 7.754584 4562.151689 |
确实,`describe()` 生成的 DataFrame 可以帮助我们了解数据。从中,我们可以看出有多少缺失数据(通过查看计数),数据是如何分布的,是否存在异常值等等。
想开始学习机器学习 Python 吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
操作 DataFrame 和 Series
类似于 NumPy 中的布尔索引,我们可以从 DataFrame 中提取一个行的子集。例如,这是选择一氧化碳排放数据的方法:
|
1 2 3 |
... df_CO = df[df["Pollutant"] == "CO"] print(df_CO) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
州 FIPS 州 一级代码 一级描述 ... emissions18 emissions19 emissions20 emissions21 0 1 AL 1 FUEL COMB. ELEC. UTIL. ... 10.050146 8.243679 8.243679 8.243679 7 1 AL 2 FUEL COMB. INDUSTRIAL ... 19.148024 17.291741 17.291741 17.291741 14 1 AL 3 FUEL COMB. OTHER ... 29.207209 29.201838 29.201838 29.201838 21 1 AL 4 CHEMICAL & ALLIED PRODUCT MFG ... 2.774257 2.626484 2.626484 2.626484 28 1 AL 5 METALS PROCESSING ... 12.534726 12.167189 12.167189 12.167189 ... ... ... ... ... ... ... ... ... ... 5284 56 WY 11 HIGHWAY VEHICLES ... 70.776546 69.268149 64.493724 59.719298 5291 56 WY 12 OFF-HIGHWAY ... 31.092228 30.594383 30.603392 30.612400 5298 56 WY 14 MISCELLANEOUS ... 3.269705 3.828401 3.828401 3.828401 5305 56 WY 15 WILDFIRES ... 302.235376 89.399972 89.399972 89.399972 5312 56 WY 16 PRESCRIBED FIRES ... 70.578540 28.177445 28.177445 28.177445 [760 行 x 32 列] |
正如您可能预期的那样,`==` 运算符将 Series `df["Pollutant"]` 的每个元素进行比较,结果是一个布尔 Series。如果长度匹配,DataFrame 将根据布尔值选择行。事实上,我们可以使用按位运算符组合布尔值。例如,这是选择公路车辆产生的一氧化碳排放行的代码:
|
1 2 3 |
... df_CO_HW = df[(df["Pollutant"] == "CO") & (df["Tier 1 Description"] == "HIGHWAY VEHICLES")] print(df_CO_HW) |
|
1 2 3 4 5 6 7 8 9 10 11 |
State FIPS State Tier 1 Code Tier 1 Description ... emissions18 emissions19 emissions20 emissions21 70 1 AL 11 HIGHWAY VEHICLES ... 532.140445 518.259811 492.182583 466.105354 171 2 AK 11 HIGHWAY VEHICLES ... 70.674008 70.674008 63.883471 57.092934 276 4 AZ 11 HIGHWAY VEHICLES ... 433.685363 413.347655 398.958109 384.568563 381 5 AR 11 HIGHWAY VEHICLES ... 228.213685 227.902883 215.937225 203.971567 ... 5074 54 WV 11 HIGHWAY VEHICLES ... 133.628312 126.836047 118.621857 110.407667 5179 55 WI 11 HIGHWAY VEHICLES ... 344.340392 374.804865 342.392977 309.981089 5284 56 WY 11 HIGHWAY VEHICLES ... 70.776546 69.268149 64.493724 59.719298 [51 rows x 32 columns] |
如果您更喜欢像 Python 列表一样选择行,您可以通过 `iloc` 接口来实现。这是选择第 5 行到第 10 行(从零开始索引)或第 1 列到第 6 列和第 5 行到第 10 行的方法。
|
1 2 3 |
... df_r5 = df.iloc[5:11] df_c1_r5 = df.iloc[5:11, 1:7] |
如果你熟悉 Excel,你可能知道它一个很棒的功能,叫做“数据透视表”。Pandas 也可以实现同样的功能。我们来考虑一下这个数据集中所有州在 2021 年的的一氧化碳污染情况。
|
1 2 3 |
... df_all_co = df[df["Pollutant"]=="CO"][["State", "Tier 1 Description", "emissions21"]] print(df_all_co) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
州 FIPS 州 一级代码 一级描述 ... emissions18 emissions19 emissions20 emissions21 0 1 AL 1 FUEL COMB. ELEC. UTIL. ... 10.050146 8.243679 8.243679 8.243679 7 1 AL 2 FUEL COMB. INDUSTRIAL ... 19.148024 17.291741 17.291741 17.291741 14 1 AL 3 FUEL COMB. OTHER ... 29.207209 29.201838 29.201838 29.201838 21 1 AL 4 CHEMICAL & ALLIED PRODUCT MFG ... 2.774257 2.626484 2.626484 2.626484 28 1 AL 5 METALS PROCESSING ... 12.534726 12.167189 12.167189 12.167189 ... ... ... ... ... ... ... ... ... ... 5284 56 WY 11 HIGHWAY VEHICLES ... 70.776546 69.268149 64.493724 59.719298 5291 56 WY 12 OFF-HIGHWAY ... 31.092228 30.594383 30.603392 30.612400 5298 56 WY 14 MISCELLANEOUS ... 3.269705 3.828401 3.828401 3.828401 5305 56 WY 15 WILDFIRES ... 302.235376 89.399972 89.399972 89.399972 5312 56 WY 16 PRESCRIBED FIRES ... 70.578540 28.177445 28.177445 28.177445 [760 行 x 32 列] |
通过数据透视表,我们可以将不同的产生一氧化碳的方式作为列,将不同的州作为行。
|
1 2 3 |
... df_pivot = df_all_co.pivot_table(index="State", columns="Tier 1 Description", values="emissions21") print(df_pivot) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Tier 1 Description CHEMICAL & ALLIED PRODUCT MFG FUEL COMB. ELEC. UTIL. ... WASTE DISPOSAL & RECYCLING WILDFIRES State ... AK NaN 4.679098 ... 0.146018 4562.151689 AL 2.626484 8.243679 ... 47.241253 38.780562 AR 0.307811 5.027354 ... 26.234267 3.125529 AZ 0.000000 4.483514 ... 6.438484 248.713896 ... WA 0.116416 4.831139 ... 2.334996 160.284327 WI 0.023691 7.422521 ... 35.670128 0.911783 WV 0.206324 7.836174 ... 16.012414 5.086241 WY 14.296860 14.617882 ... 1.952702 89.399972 [51 rows x 15 columns] |
上面的 `pivot_table()` 函数不需要将值与索引和列唯一对应。换句话说,如果原始 DataFrame 中一个州有两个“野火”行,这个函数会将这两个聚合(默认取平均值)。要撤销数据透视操作,我们可以使用 `melt()` 函数。
|
1 2 3 |
... df_melt = df_pivot.melt(value_name="emissions 2021", var_name="Tier 1 Description", ignore_index=False) print(df_melt) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Tier 1 Description emissions 2021 State AK CHEMICAL & ALLIED PRODUCT MFG NaN AL CHEMICAL & ALLIED PRODUCT MFG 2.626484 AR CHEMICAL & ALLIED PRODUCT MFG 0.307811 AZ CHEMICAL & ALLIED PRODUCT MFG 0.000000 CA CHEMICAL & ALLIED PRODUCT MFG 0.876666 ... ... ... VT WILDFIRES 0.000000 WA WILDFIRES 160.284327 WI WILDFIRES 0.911783 WV WILDFIRES 5.086241 WY WILDFIRES 89.399972 [765 rows x 2 columns] |
DataFrame 还有更多可以做的事情。例如,我们可以对行进行排序(使用 `sort_values()` 函数),重命名列(使用 `rename()` 函数),删除重复行(`drop_duplicates()` 函数)等等。
在机器学习项目中,我们经常需要在开始使用数据之前进行一些清理工作。Pandas 在这方面非常有用。我们刚刚创建的 `df_pivot` DataFrame 中有一些值为 `NaN`,表示没有可用数据。我们可以用以下任何一种方法将所有这些值替换为零:
|
1 2 3 |
df_pivot.fillna(0) df_pivot.where(df_pivot.notna(), 0) df_pivot.mask(df_pivot.isna(), 0) |
DataFrame 中的聚合
事实上,Pandas 提供的表操作功能,否则只能轻松地使用数据库 SQL 语句来完成。重用上面的示例数据集,表中的每种污染物都被分解为不同的来源。如果我们想知道汇总的污染物排放量,我们可以将所有来源加起来。这与 SQL 类似,这是一个“分组”操作。我们可以通过以下方式实现:
|
1 2 3 |
... df_sum = df[df["Pollutant"]=="CO"].groupby("State").sum() print(df_sum) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
State FIPS Tier 1 Code emissions90 emissions96 ... emissions18 emissions19 emissions20 emissions21 State ... AK 28 115 4502.12238 883.50805 ... 5216.369575 5218.919502 5211.711803 5204.504105 AL 15 123 3404.01163 2440.95216 ... 1574.068371 1350.711872 1324.945132 1299.178392 AR 75 123 1706.69006 1356.08524 ... 1168.110471 1055.635824 1043.724418 1031.813011 AZ 60 123 2563.04249 1876.55422 ... 1000.976184 977.916197 964.504353 951.092509 ... WA 795 123 3604.39515 2852.52146 ... 1703.948955 1286.715920 1266.983767 1247.251614 WI 825 123 2849.49820 2679.75457 ... 922.375165 872.231181 838.232783 804.234385 WV 810 123 1270.81719 941.39753 ... 424.120829 395.720171 387.565561 379.410950 WY 840 123 467.80484 1598.56712 ... 549.270377 306.461296 301.695879 296.930461 [51 rows x 29 columns] |
`groupby()` 函数的结果将使用分组列作为行索引。它通过将具有相同分组列值的行放入一个组中来工作。然后,作为一个组,将应用一些**聚合**函数,将许多行减少为一行。在上面的例子中,我们是对每一列进行求和。Pandas 提供了许多其他聚合函数,例如计算平均值或仅仅计算行数。由于我们执行的是 `sum()` 操作,非数字列将被从输出中删除,因为它们不适用于该操作。
这使我们能够完成一些有趣的任务。假设,使用上面 DataFrame 中的数据,我们创建一个表格,显示每个州在一氧化碳(CO)和二氧化硫(SO2)的总排放量。其推理过程如下:
- 按“State”和“Pollutant”分组,然后对每个组进行求和。这样我们就可以得到每个州每种污染物的总排放量。
- 仅选择 2021 年的列。
- 运行数据透视表,将州作为行,污染物作为列,总排放量作为值。
- 仅选择 CO 和 SO2 的列。
用代码表示就是:
|
1 2 3 4 5 6 7 8 9 |
... df_2021 = ( df.groupby(["State", "Pollutant"]) .sum() # 获取每年的总排放量 [["emissions21"]] # 只选择 2021 年 .reset_index() .pivot(index="State", columns="Pollutant", values="emissions21") .filter(["CO","SO2"]) ) print(df_2021) |
|
1 2 3 4 5 6 7 8 9 10 11 |
Pollutant CO SO2 State AK 5204.504105 32.748621 AL 1299.178392 52.698696 AR 1031.813011 55.288823 AZ 951.092509 15.281760 ... WA 1247.251614 13.178053 WI 804.234385 21.141688 WV 379.410950 49.159621 WY 296.930461 37.056612 |
在上面的代码中,`groupby()` 函数之后的每个步骤都是创建一个新的 DataFrame。由于我们使用的是 DataFrame 下定义的函数,因此我们使用了上面的函数式**链式调用语法**。
`sum()` 函数将从 `GroupBy` 对象创建一个 DataFrame,该对象将分组列“State”和“Pollutant”作为索引。因此,在我们将 DataFrame 截断为只有一列后,我们使用 `reset_index()` 将索引转换为列(即会有三列:`State`、`Pollutant` 和 `emissions21`)。由于会有比我们需要的更多的污染物,因此我们使用 `filter()` 从结果 DataFrame 中仅选择 CO 和 SO2 的列。这类似于使用复杂的索引来选择列。
实际上,我们可以用不同的方式做到这一点:
- 仅选择 CO 的行并计算总排放量;仅选择 2021 年的数据。
- 对 SO2 做同样的事情。
- 合并前两步产生的 DataFrame。
在 Pandas 中,DataFrame 有一个 `join()` 函数,可以帮助我们通过匹配索引来合并列与另一个 DataFrame。在代码中,上述步骤如下:
|
1 2 3 4 |
... df_co = df[df["Pollutant"]=="CO"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"CO"}) df_so2 = df[df["Pollutant"]=="SO2"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"SO2"}) df_joined = df_co.join(df_so2) |
`join()` 函数仅限于索引匹配。如果你熟悉 SQL,Pandas 中 `JOIN` 子句的等价物是 `merge()` 函数。如果为 CO 和 SO2 创建的两个 DataFrame 中,州的列是单独的列,我们可以这样做:
|
1 2 3 |
df_co = df[df["Pollutant"]=="CO"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"CO"}).reset_index() df_so2 = df[df["Pollutant"]=="SO2"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"SO2"}).reset_index() df_merged = df_co.merge(df_so2, on="State", how="outer") |
Pandas 中的 `merge()` 函数可以执行所有类型的 SQL 连接。我们可以匹配来自不同 DataFrame 的不同列,并且可以执行左连接、右连接、内连接和外连接。这在整理项目数据时将非常有用。
DataFrame 中的 `groupby()` 函数非常强大,因为它允许我们灵活地操作 DataFrame,并为许多复杂的转换打开了大门。有时在 `groupby()` 之后可能没有内置函数可以提供帮助,但我们总是可以提供自己的函数。例如,这里是创建一个函数来操作子 DataFrame(除了分组列之外的所有列),并应用它来查找最小和最大排放量的年份:
|
1 2 3 4 5 6 7 8 9 |
... def minmaxyear(subdf): sum_series = subdf.sum() year_indices = [x for x in sum_series if x.startswith("emissions")] minyear = sum_series[year_indices].astype(float).idxmin() maxyear = sum_series[year_indices].astype(float).idxmax() return pd.Series({"min year": minyear[-2:], "max year": maxyear[-2:]}) df_years = df[df["Pollutant"]=="CO"].groupby("State").apply(minmaxyear) |
`apply()` 函数是提供最大灵活性的最后手段。除了 GroupBy 对象之外,DataFrame 和 Series 也有 `apply()` 接口。
以下是演示我们上面介绍的所有操作的完整代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
import pandas as pd # 来自美国环境保护署的污染物数据 URL = "https://www.epa.gov/sites/default/files/2021-03/state_tier1_caps.xlsx" # 读取 Excel 文件并打印 df = pd.read_excel(URL, sheet_name="State_Trends", header=1) print("US air pollutant emission data:") print(df) # 显示信息 print("\nInformation about the DataFrame:") df.info() # 打印数据类型 coltypes = df.dtypes print("\nColumn data types of the DataFrame:") print(coltypes) # 获取最后 3 列 cols = ["State", "Pollutant", "emissions19", "emissions20", "emissions21"] last3years = df[cols] print("\nDataFrame of last 3 years data:") print(last3years) # 获取一个 Series data2021 = df["emissions21"] print("\nSeries of 2021 data:") print(data2021) # 打印唯一污染物 print("\nUnique pollutants:") print(df["Pollutant"].unique()) # 打印平均排放量 print("\nMean on the 2021 series:") print(df["emissions21"].mean()) # 描述 print("\nBasic statistics about each column in the DataFrame:") print(df.describe().T) # 获取仅 CO 的数据 df_CO = df[df["Pollutant"] == "CO"] print("\nDataFrame of only CO pollutant:") print(df_CO) # 获取 CO 和 Highway 的数据 df_CO_HW = df[(df["Pollutant"] == "CO") & (df["Tier 1 Description"] == "HIGHWAY VEHICLES")] print("\nDataFrame of only CO pollutant from Highway vehicles:") print(df_CO_HW) # 获取所有 CO 的 DataFrame df_all_co = df[df["Pollutant"]=="CO"][["State", "Tier 1 Description", "emissions21"]] print("\nDataFrame of only CO pollutant, keep only essential columns:") print(df_all_co) # 数据透视 df_pivot = df_all_co.pivot_table(index="State", columns="Tier 1 Description", values="emissions21") print("\nPivot table of state vs CO emission source:") print(df_pivot) # 融化 df_melt = df_pivot.melt(value_name="emissions 2021", var_name="Tier 1 Description", ignore_index=False) print("\nMelting the pivot table:") print(df_melt) # 三者都是相同的 df_filled = df_pivot.fillna(0) df_filled = df_pivot.where(df_pivot.notna(), 0) df_filled = df_pivot.mask(df_pivot.isna(), 0) print("\nFilled missing value as zero:") print(df_filled) # 聚合 df_sum = df[df["Pollutant"]=="CO"].groupby("State").sum() print("\nTotal CO emission by state:") print(df_sum) # 分组 df_2021 = ( df.groupby(["State", "Pollutant"]) .sum() # 获取每年的总排放量 [["emissions21"]] # 只选择 2021 年 .reset_index() .pivot(index="State", columns="Pollutant", values="emissions21") .filter(["CO","SO2"]) ) print("\nComparing CO and SO2 emission:") print(df_2021) # 连接 df_co = df[df["Pollutant"]=="CO"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"CO"}) df_so2 = df[df["Pollutant"]=="SO2"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"SO2"}) df_joined = df_co.join(df_so2) print("\nComparing CO and SO2 emission:") print(df_joined) # 合并 df_co = df[df["Pollutant"]=="CO"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"CO"}).reset_index() df_so2 = df[df["Pollutant"]=="SO2"].groupby("State").sum()[["emissions21"]].rename(columns={"emissions21":"SO2"}).reset_index() df_merged = df_co.merge(df_so2, on="State", how="outer") print("\nComparing CO and SO2 emission:") print(df_merged) def minmaxyear(subdf): sum_series = subdf.sum() year_indices = [x for x in sum_series if x.startswith("emissions")] minyear = sum_series[year_indices].astype(float).idxmin() maxyear = sum_series[year_indices].astype(float).idxmax() return pd.Series({"min year": minyear[-2:], "max year": maxyear[-2:]}) df_years = df[df["Pollutant"]=="CO"].groupby("State").apply(minmaxyear) print("\nYears of minimum and maximum emissions:") print(df_years) |
在 Pandas 中处理时间序列数据
如果你处理时间序列数据,你会发现 Pandas 的另一个强大功能。首先,让我们考虑一些每日污染数据。我们可以从 EPA 的网站选择并下载一些数据。
为说明起见,我们下载了德克萨斯州 2021 年的 PM2.5 数据。我们可以像下面这样导入下载的 CSV 文件,即 ad_viz_plotval_data.csv。
|
1 2 |
df = pd.read_csv("ad_viz_plotval_data.csv", parse_dates=[0]) print(df) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
数据源 站点 ID POC ... 县代码 县 站点纬度 站点经度 0 2021-01-01 AQS 480131090 1 ... 13 阿塔索萨 29.162997 -98.589158 1 2021-01-02 AQS 480131090 1 ... 13 阿塔索萨 29.162997 -98.589158 2 2021-01-03 AQS 480131090 1 ... 13 阿塔索萨 29.162997 -98.589158 3 2021-01-04 AQS 480131090 1 ... 13 阿塔索萨 29.162997 -98.589158 4 2021-01-05 AQS 480131090 1 ... 13 阿塔索萨 29.162997 -98.589158 ... ... ... ... ... ... ... ... ... ... 19695 2021-12-27 AQS 484790313 1 ... 479 韦伯 27.599444 -99.533333 19696 2021-12-28 AQS 484790313 1 ... 479 韦伯 27.599444 -99.533333 19697 2021-12-29 AQS 484790313 1 ... 479 韦伯 27.599444 -99.533333 19698 2021-12-30 AQS 484790313 1 ... 479 韦伯 27.599444 -99.533333 19699 2021-12-31 AQS 484790313 1 ... 479 韦伯 27.599444 -99.533333 [19700 行 x 20 列] |
pandas 中的 read_csv() 函数允许我们指定某些列为日期,并将它们解析为 datetime 对象而不是字符串。这对于进一步处理时间序列数据至关重要。如我们所知,第一列(零索引)是日期列;我们在上面提供了参数 parse_dates=[0]。
为了处理时间序列数据,重要的是在 DataFrame 中使用时间作为索引。我们可以通过 set_index() 函数将其中一列设为索引。
|
1 2 3 |
... df_pm25 = df.set_index("Date") print(df_pm25) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
数据源 站点ID POC 日均值PM2.5 浓度 ... 县代码 县站点纬度 站点经度 日期 ... 2021-01-01 AQS 480131090 1 4.6 ... 13 阿塔索萨 29.162997 -98.589158 2021-01-02 AQS 480131090 1 3.7 ... 13 阿塔索萨 29.162997 -98.589158 2021-01-03 AQS 480131090 1 6.3 ... 13 阿塔索萨 29.162997 -98.589158 2021-01-04 AQS 480131090 1 6.4 ... 13 阿塔索萨 29.162997 -98.589158 2021-01-05 AQS 480131090 1 7.7 ... 13 阿塔索萨 29.162997 -98.589158 ... ... ... ... ... ... ... ... ... ... 2021-12-27 AQS 484790313 1 15.7 ... 479 韦伯 27.599444 -99.533333 2021-12-28 AQS 484790313 1 17.6 ... 479 韦伯 27.599444 -99.533333 2021-12-29 AQS 484790313 1 14.1 ... 479 韦伯 27.599444 -99.533333 2021-12-30 AQS 484790313 1 18.5 ... 479 韦伯 27.599444 -99.533333 2021-12-31 AQS 484790313 1 21.5 ... 479 韦伯 27.599444 -99.533333 [19700 行 x 19 列] |
如果我们检查此 DataFrame 的索引,我们会看到以下内容:
|
1 2 |
... print(df_pm25.index) |
|
1 2 3 4 5 6 7 8 |
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04', '2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08', '2021-01-09', '2021-01-10', ... '2021-12-22', '2021-12-23', '2021-12-24', '2021-12-25', '2021-12-26', '2021-12-27', '2021-12-28', '2021-12-29', '2021-12-30', '2021-12-31'], dtype='datetime64[ns]', name='Date', length=19700, freq=None) |
我们知道它的类型是 datetime64,这是 pandas 中的一个时间戳对象。
从上面的索引可以看出,每个日期不是唯一的。这是因为 PM2.5 浓度是在不同站点观测的,每个站点都会为 DataFrame 贡献一行。我们可以将 DataFrame 过滤到一个站点,以使索引唯一。或者,我们可以使用 pivot_table() 来转换 DataFrame,其中透视操作保证了生成的 DataFrame 将具有唯一的索引。
|
1 2 3 4 5 6 |
df_2021 = ( df[["Date", "Daily Mean PM2.5 Concentration", "Site Name"]] .pivot_table(index="Date", columns="Site Name", values="Daily Mean PM2.5 Concentration") ) print(df_2021) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
站点名称 阿马里洛 A&M 阿斯卡拉特公园 SE 奥斯汀北山大道 ... 冯奥米公路 16 号 韦科马扎内克 世界贸易桥 日期 ... 2021-01-01 1.7 11.9 3.0 ... 4.6 2.7 4.4 2021-01-02 2.2 7.8 6.1 ... 3.7 2.2 6.1 2021-01-03 2.5 4.2 4.3 ... 6.3 4.2 8.5 2021-01-04 3.7 8.1 3.7 ... 6.4 4.2 5.7 2021-01-05 4.5 10.0 5.2 ... 7.7 6.1 7.1 ... ... ... ... ... ... ... ... 2021-12-27 1.9 5.8 11.0 ... 13.8 10.5 15.7 2021-12-28 1.8 6.6 14.1 ... 17.7 9.7 17.6 2021-12-29 NaN 8.1 21.8 ... 28.6 12.5 14.1 2021-12-30 4.0 9.5 13.1 ... 20.4 13.4 18.5 2021-12-31 3.6 3.7 16.3 ... 18.3 11.8 21.5 [365 行 x 53 列] |
我们可以用以下方式检查唯一性:
|
1 |
df_2021.index.is_unique |
现在,此 DataFrame 中的每一列都是一个**时间序列**。虽然 pandas 不提供时间序列的任何预测功能,但它提供了可以帮助您清理和转换数据的工具。将 DataFrame 设置为 DateTimeIndex 对于时间序列分析项目非常有用,因为我们可以轻松地提取某个时间间隔的数据,例如时间序列的训练-测试拆分。下面是如何从上面的 DataFrame 中提取三个月的数据子集。
|
1 |
df_3month = df_2021["2021-04-01":"2021-07-01"] |
时间序列中一个常用的函数是**重采样**数据。考虑到此 DataFrame 中的每日数据,我们可以将其转换为每周观测值。我们可以指定结果数据按每周日索引。但我们仍然需要告诉重采样数据应该是什么样的。如果是销售数据,我们可能想在整个星期内求和以获得每周收入。在这种情况下,我们可以对一周的数据求平均值以平滑波动。另一种方法是取每个期间的第一次观测值,如下所示:
|
1 2 3 |
... df_resample = df_2021.resample("W-SUN").first() print(df_resample) |
|
1 2 3 4 5 6 7 8 9 10 11 |
站点名称 阿马里洛 A&M 阿斯卡拉特公园SE 奥斯汀北山大道驱动 ... 冯奥米公路 16 韦科马扎内克 世界贸易桥 日期 ... 2021-01-03 1.7 11.9 3.0 ... 4.6 2.7 4.4 2021-01-10 3.7 8.1 3.7 ... 6.4 4.2 5.7 2021-01-17 5.8 5.3 7.0 ... 5.4 6.9 4.8 ... 2021-12-19 3.6 13.0 6.3 ... 6.9 5.9 5.5 2021-12-26 5.3 10.4 5.7 ... 5.5 5.4 3.9 2022-01-02 1.9 5.8 11.0 ... 13.8 10.5 15.7 [53 行 x 53 列] |
字符串“W-SUN”用于确定每周日的平均值。这被称为“偏移别名”。您可以在下方找到所有偏移别名的列表:
重采样在金融市场数据中特别有用。设想我们有市场价格数据,但原始数据不是以固定间隔生成的。我们仍然可以使用重采样将数据转换为固定间隔。由于它非常常用,pandas 甚至提供了开-高-低-收(即 OHLC,即一个期间内的第一次、最大值、最小值和最后一次观测值)。下面我们演示如何在一个观测站点上获得每周的 OHLC。
|
1 2 |
df_ohlc = df_2021["San Antonio Interstate 35"].resample("W-SUN").ohlc() print(df_ohlc) |
|
1 2 3 4 5 6 7 8 9 10 11 |
open high low close 日期 2021-01-03 4.2 12.6 4.2 12.6 2021-01-10 9.7 9.7 3.0 5.7 2021-01-17 5.4 13.8 3.0 13.8 2021-01-24 9.5 11.5 5.7 9.0 ... 2021-12-12 5.7 20.0 5.7 20.0 2021-12-19 9.7 9.7 3.9 3.9 2021-12-26 6.1 14.7 6.0 14.7 2022-01-02 10.9 23.7 10.9 16.3 |
特别地,如果我们从较粗的频率重采样到较细的频率,这被称为**升采样**。Pandas 在升采样期间通常会插入 NaN 值,因为原始时间序列在中间时间实例期间没有数据。一种避免在升采样期间出现这些 NaN 值的方法是要求 pandas 进行前向填充(将值从较早的时间传递)或后向填充(使用较晚时间的值)数据。例如,以下是将一个站点每日 PM2.5 观测值前向填充到每小时。
|
1 2 3 |
... series_ffill = df_2021["San Antonio Interstate 35"].resample("H").ffill() print(series_ffill) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
日期 2021-01-01 00:00:00 4.2 2021-01-01 01:00:00 4.2 2021-01-01 02:00:00 4.2 2021-01-01 03:00:00 4.2 2021-01-01 04:00:00 4.2 ... 2021-12-30 20:00:00 18.2 2021-12-30 21:00:00 18.2 2021-12-30 22:00:00 18.2 2021-12-30 23:00:00 18.2 2021-12-31 00:00:00 16.3 Freq: H, Name: San Antonio Interstate 35, Length: 8737, dtype: float64 |
除了重采样,我们还可以使用滑动窗口来转换数据。例如,下面是如何从时间序列中计算 10 天的移动平均值。这不是重采样,因为生成的数据仍然是每日的。但对于每个数据点,它是过去 10 天的平均值。同样,我们可以通过将不同的函数应用于 rolling 对象来找到 10 天的标准差或 10 天的最大值。
|
1 2 3 |
... df_mean = df_2021["San Antonio Interstate 35"].rolling(10).mean() print(df_mean) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
日期 2021-01-01 NaN 2021-01-02 NaN 2021-01-03 NaN 2021-01-04 NaN 2021-01-05 NaN ... 2021-12-27 8.30 2021-12-28 9.59 2021-12-29 11.57 2021-12-30 12.78 2021-12-31 13.24 Name: San Antonio Interstate 35, Length: 365, dtype: float64 |
为了展示原始时间序列和滚动平均时间序列的差异,下面是图示。我们在 rolling() 函数中添加了 min_periods=5 参数,因为原始数据在某些天存在缺失数据。这会在每日数据中产生间隙,但我们要求在过去 10 天的窗口中有 5 个数据点时仍然计算平均值。
|
1 2 3 4 5 6 7 8 9 |
... import matplotlib.pyplot as plt fig = plt.figure(figsize=(12,6)) plt.plot(df_2021["San Antonio Interstate 35"], label="daily") plt.plot(df_2021["San Antonio Interstate 35"].rolling(10, min_periods=5).mean(), label="10-day MA") plt.legend() plt.ylabel("PM 2.5") plt.show() |
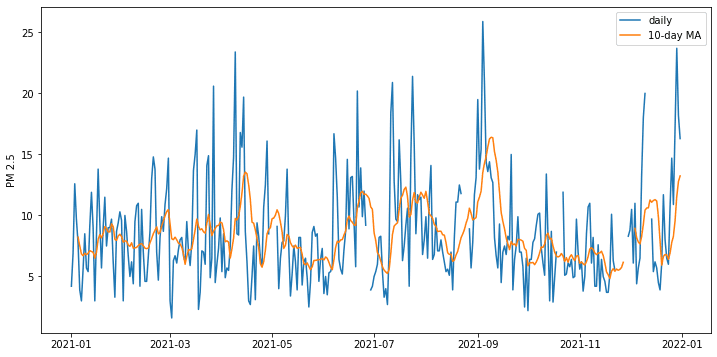
以下是展示我们上面介绍的时间序列操作的完整代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import pandas as pd import matplotlib.pyplot as plt # 加载时间序列 df = pd.read_csv("ad_viz_plotval_data.csv", parse_dates=[0]) print("Input data:") print(df) # 设置日期索引 df_pm25 = df.set_index("Date") print("\nUsing date index:") print(df_pm25) print(df_pm25.index) # 2021 日数据 df_2021 = ( df[["Date", "Daily Mean PM2.5 Concentration", "Site Name"]] .pivot_table(index="Date", columns="Site Name", values="Daily Mean PM2.5 Concentration") ) print("\nUsing date index:") print(df_2021) print(df_2021.index.is_unique) # 时间间隔 df_3mon = df_2021["2021-04-01":"2021-07-01"] print("\nInterval selection:") print(df_3mon) # 重采样 print("\nResampling dataframe:") df_resample = df_2021.resample("W-SUN").first() print(df_resample) print("\nResampling series for OHLC:") df_ohlc = df_2021["San Antonio Interstate 35"].resample("W-SUN").ohlc() print(df_ohlc) print("\nResampling series with forward fill:") series_ffill = df_2021["San Antonio Interstate 35"].resample("H").ffill() print(series_ffill) # rolling print("\nRolling mean:") df_mean = df_2021["San Antonio Interstate 35"].rolling(10).mean() print(df_mean) # 绘制移动平均线 fig = plt.figure(figsize=(12,6)) plt.plot(df_2021["San Antonio Interstate 35"], label="daily") plt.plot(df_2021["San Antonio Interstate 35"].rolling(10, min_periods=5).mean(), label="10-day MA") plt.legend() plt.ylabel("PM 2.5") plt.show() |
进一步阅读
Pandas 是一个功能丰富的库,其细节远超我们在此介绍的范畴。以下是一些供您深入学习的资源:
API 文档
书籍
- Python for Data Analysis,第二版,作者 Wes McKinney
总结
在本教程中,您简要了解了 pandas 提供的功能。
具体来说,你学到了:
- 如何使用 pandas DataFrame 和 Series
- 如何以类似于关系数据库中的表操作的方式来操作 DataFrame
- 如何利用 pandas 来帮助操作时间序列数据
掌握机器学习 Python!

更自信地用 Python 编写代码
...从学习实用的 Python 技巧开始
在我的新电子书中探索如何实现
用于机器学习的 Python
它提供自学教程和数百个可运行的代码,为您提供包括以下技能:
调试、性能分析、鸭子类型、装饰器、部署等等...






暂无评论。