时间序列预测的残差误差为我们提供了可以建模的另一个信息来源。
残差误差本身构成了一个可能具有时间结构的时间序列。对此结构进行简单的自回归建模可以用来预测预测误差,进而可以用来纠正预测。这类模型称为移动平均模型,其名称与移动平均平滑法相同,但含义却大不相同。
在本教程中,您将了解如何对残差误差时间序列进行建模,并使用Python对其进行纠正以改进预测。
完成本教程后,您将了解:
- 关于如何使用自回归模型对残差误差时间序列进行建模。
- 如何开发和评估残差误差时间序列模型。
- 如何使用残差误差模型来纠正预测并提高预测技能。
开启您的项目,阅读我的新书《Python时间序列预测入门》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 更新于2017年1月:改进了部分代码示例,使其更完整。
- 2019 年 4 月更新:更新了数据集链接。
- 2019年8月更新:更新了数据加载以使用新的API。
- 2020 年 4 月更新:由于 API 更改,将 AR 更改为 AutoReg。
残差误差模型
预期值与预测值之间的差值称为残差误差。
其计算公式为:
|
1 |
残差误差 = 预期值 - 预测值 |
与输入观测值本身一样,时间序列的残差误差可能具有趋势、偏差和季节性等时间结构。
残差时间序列中的任何时间结构都可以作为诊断,因为它表明了可以纳入预测模型的信息。理想的模型应在残差误差中不留下任何结构,只留下无法建模的随机波动。
残差中的结构也可以直接建模。残差误差中可能存在难以直接纳入模型的复杂信号。取而代之的是,您可以创建一个残差误差时间序列模型,并预测模型的预期误差。
然后,可以将预测误差从模型预测中减去,从而提供额外的性能提升。
残差误差的一个简单而有效的模型是自回归。这是指使用一定数量的滞后误差值来预测下一个时间步的误差。这些滞后误差以线性回归模型结合,非常类似于直接时间序列观测值的自回归模型。
残差误差时间序列的自回归称为移动平均(MA)模型。这令人困惑,因为它与移动平均平滑过程无关。将其视为自回归(AR)过程的同胞,但作用于滞后残差误差而不是滞后原始观测值。
在本教程中,我们将开发一个残差误差时间序列的自回归模型。
在我们深入之前,让我们先看一下我们将要构建模型的单变量数据集。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
每日女性出生数据集
此数据集描述了 1959 年加利福尼亚州每日女性出生人数。
单位是计数,共有 365 个观测值。数据集的来源归功于 Newton (1988)。
下载数据集并将其放在您当前的工作目录中,文件名为“_daily-total-female-births.csv_”。
下面是如何从CSV加载每日女性出生数据集的示例。
|
1 2 3 4 5 6 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-total-female-births.csv', header=0, index_col=0) print(series.head()) series.plot() pyplot.show() |
运行该示例将打印加载文件的前5行。
|
1 2 3 4 5 6 7 |
日期 1959-01-01 35 1959-01-02 32 1959-01-03 30 1959-01-04 31 1959-01-05 44 Name: Births, dtype: int64 |
该数据集也显示在时间序列观测值的折线图中。
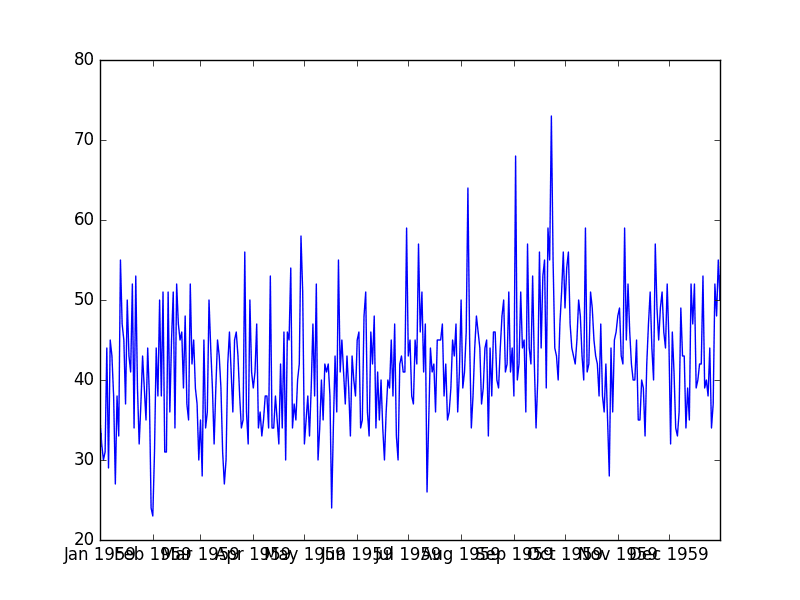
每日女性出生总数图
我们可以看到没有明显的趋势或季节性。该数据集看起来是平稳的,这是使用自回归模型的预期。
持久性预测模型
我们可以做的最简单的预测是预测上一个时间步发生的情况与下一个时间步发生的情况相同。
这被称为“朴素预测”或持久性预测模型。该模型将提供用于计算残差误差时间序列的预测。或者,我们可以开发一个时间序列的自回归模型并将其作为我们的模型。为了简洁起见,并且为了专注于残差误差模型,我们在此不开发自回归模型。
我们可以在Python中实现持久性模型。
数据集加载后,将其解析为监督学习问题。创建数据集的滞后版本,其中将上一个时间步(t-1)用作输入变量,将下一个时间步(t+1)用作输出变量。
|
1 2 3 4 |
# 创建滞后数据集 values = DataFrame(series.values) dataframe = concat([values.shift(1), values], axis=1) dataframe.columns = ['t-1', 't+1'] |
接下来,数据集被分为训练集和测试集。总共66%的数据用于训练,其余34%用于测试集。持久性模型不需要训练;这只是一个标准的测试框架方法。
分割后,训练集和测试集被分离成输入和输出部分。
|
1 2 3 4 5 6 |
# 拆分为训练集和测试集 X = dataframe.values train_size = int(len(X) * 0.66) train, test = X[1:train_size], X[train_size:] train_X, train_y = train[:,0], train[:,1] test_X, test_y = test[:,0], test[:,1] |
持久性模型通过将输出值(y)预测为输入值(x)的副本来实现。
|
1 2 |
# 持久性模型 predictions = [x for x in test_X] |
然后,残差误差计算为预期结果(test_y)与预测(predictions)之间的差值。
|
1 2 |
# 计算残差 residuals = [test_y[i]-predictions[i] for i in range(len(predictions))] |
该示例将所有内容组合在一起,为我们提供了一组残差预测误差,我们可以在本教程中进行探索。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 为持久性预测模型计算残差误差 from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat from sklearn.metrics import mean_squared_error from math import sqrt # 加载数据 series = read_csv('daily-total-female-births.csv', header=0, index_col=0, parse_dates=True, squeeze=True) # 创建滞后数据集 values = DataFrame(series.values) dataframe = concat([values.shift(1), values], axis=1) dataframe.columns = ['t', 't+1'] # 拆分为训练集和测试集 X = dataframe.values train_size = int(len(X) * 0.66) train, test = X[1:train_size], X[train_size:] train_X, train_y = train[:,0], train[:,1] test_X, test_y = test[:,0], test[:,1] # 持久性模型 predictions = [x for x in test_X] # 持久性模型的技能 rmse = sqrt(mean_squared_error(test_y, predictions)) print('Test RMSE: %.3f' % rmse) # 计算残差 residuals = [test_y[i]-predictions[i] for i in range(len(predictions))] residuals = DataFrame(residuals) print(residuals.head()) |
然后,该示例将打印RMSE以及预测残差误差的前5行。
|
1 2 3 4 5 6 7 |
Test RMSE: 9.151 0 0 9.0 1 -10.0 2 3.0 3 -6.0 4 30.0 |
现在我们有了一个残差误差时间序列,可以对其进行建模。
残差误差的自回归
我们可以使用自回归模型对残差误差时间序列进行建模。
这是一个线性回归模型,它将滞后残差误差项进行加权线性求和。例如:
|
1 |
error(t+1) = b0 + b1*error(t-1) + b2*error(t-2) ...+ bn*error(t-n) |
我们可以使用statsmodels库提供的自回归模型(AR)。
在上一节的持久性模型基础上,我们可以首先在训练数据集上计算出的残差误差上训练模型。这需要我们为训练数据集中的每个观测值进行持久性预测,然后创建AR模型,如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 残差误差的自回归模型 from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat from statsmodels.tsa.ar_model import AutoReg series = read_csv('daily-total-female-births.csv', header=0, index_col=0, parse_dates=True, squeeze=True) # 创建滞后数据集 values = DataFrame(series.values) dataframe = concat([values.shift(1), values], axis=1) dataframe.columns = ['t', 't+1'] # 拆分为训练集和测试集 X = dataframe.values train_size = int(len(X) * 0.66) train, test = X[1:train_size], X[train_size:] train_X, train_y = train[:,0], train[:,1] test_X, test_y = test[:,0], test[:,1] # 训练集上的持久性模型 train_pred = [x for x in train_X] # 计算残差 train_resid = [train_y[i]-train_pred[i] for i in range(len(train_pred))] # 对训练集残差进行建模 model = AutoReg(train_resid, lags=15) model_fit = model.fit() print('Coef=%s' % (model_fit.params)) |
运行这段代码将打印所选滞后的16个系数(截距以及每个滞后一个系数),这些系数来自训练好的线性回归模型。
|
1 2 3 |
Coef=[ 0.10120699 -0.84940615 -0.77783609 -0.73345006 -0.68902061 -0.59270551 -0.5376728 -0.42553356 -0.24861246 -0.19972102 -0.15954013 -0.11045476 -0.14045572 -0.13299964 -0.12515801 -0.03615774] |
接下来,我们可以逐步遍历测试数据集,对于每个时间步,我们必须:
- 计算持久性预测(t+1 = t-1)。
- 使用自回归模型预测残差误差。
自回归模型需要前15个时间步的残差误差。因此,我们必须将这些值妥善保存。
当我们逐步遍历测试数据集,进行预测和误差估计时,我们可以计算实际的残差误差,并更新残差误差时间序列的滞后值(历史),以便我们能够计算下一个时间步的误差。
这是一种前向预测或滚动预测模型。
我们最终得到一个来自训练数据集的残差预测误差时间序列,以及在测试数据集上的预测残差误差。
我们可以绘制这些图表,并快速了解模型在预测残差误差方面的能力。完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
# 预测残差预测误差 from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat from statsmodels.tsa.ar_model import AutoReg from matplotlib import pyplot series = read_csv('daily-total-female-births.csv', header=0, index_col=0, parse_dates=True, squeeze=True) # 创建滞后数据集 values = DataFrame(series.values) dataframe = concat([values.shift(1), values], axis=1) dataframe.columns = ['t', 't+1'] # 拆分为训练集和测试集 X = dataframe.values train_size = int(len(X) * 0.66) train, test = X[1:train_size], X[train_size:] train_X, train_y = train[:,0], train[:,1] test_X, test_y = test[:,0], test[:,1] # 训练集上的持久性模型 train_pred = [x for x in train_X] # 计算残差 train_resid = [train_y[i]-train_pred[i] for i in range(len(train_pred))] # 对训练集残差进行建模 window = 15 model = AutoReg(train_resid, lags=window) model_fit = model.fit() coef = model_fit.params # 遍历测试集中的时间步 history = train_resid[len(train_resid)-window:] history = [history[i] for i in range(len(history))] predictions = list() expected_error = list() for t in range(len(test_y)): # 持久性 yhat = test_X[t] error = test_y[t] - yhat expected_error.append(error) # 预测误差 length = len(history) lag = [history[i] for i in range(length-window,length)] pred_error = coef[0] for d in range(window): pred_error += coef[d+1] * lag[window-d-1] predictions.append(pred_error) history.append(error) print('predicted error=%f, expected error=%f' % (pred_error, error)) # 绘制预测误差 pyplot.plot(expected_error) pyplot.plot(predictions, color='red') pyplot.show() |
运行该示例首先打印测试数据集中每个时间步的预测和预期残差误差。
|
1 2 3 4 5 6 7 |
... predicted error=-1.951332, expected error=-10.000000 predicted error=6.675538, expected error=3.000000 predicted error=3.419129, expected error=15.000000 predicted error=-7.160046, expected error=-4.000000 predicted error=-4.179003, expected error=7.000000 predicted error=-10.425124, expected error=-5.000000 |
接下来,将时间序列的实际残差误差(蓝色)与预测的残差误差(红色)进行比较绘制。
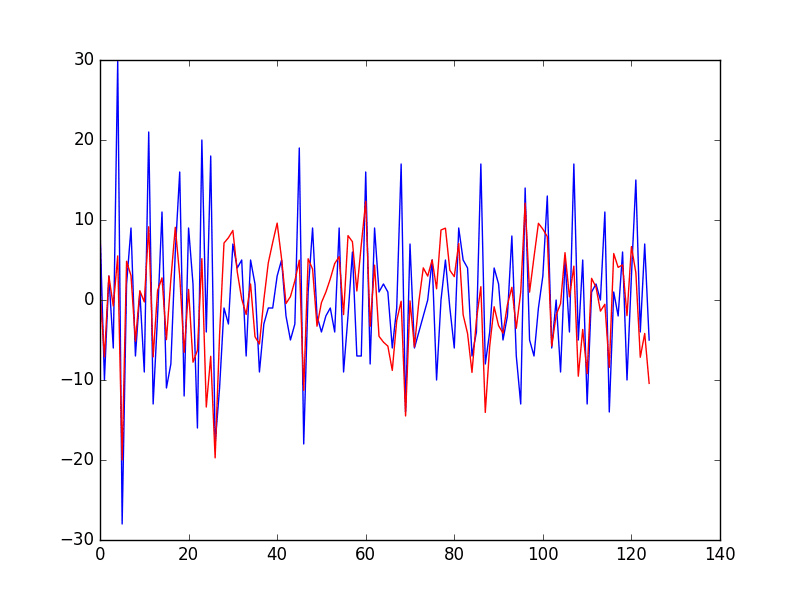
残差误差时间序列的预测
现在我们知道了如何对残差误差进行建模,接下来我们将研究如何纠正预测并提高模型技能。
使用残差误差模型纠正预测
预测残差误差模型很有趣,但它也可以用于进行更好的预测。
通过对某个时间步的预测误差进行良好估计,我们可以进行更好的预测。
例如,我们可以将预期的预测误差添加到预测中来纠正它,从而提高模型的技能。
|
1 |
改进后的预测 = 预测 + 估计误差 |
让我们用一个例子来具体说明。
假设某个时间步的预期值为10。模型预测为8,估计误差为3。改进后的预测将是:
|
1 2 3 |
改进后的预测 = 预测 + 估计误差 改进后的预测 = 8 + 3 改进后的预测 = 11 |
这使得实际的预测误差从2个单位减少到1个单位。
我们可以更新上一节的示例,将估计的预测误差添加到持久性预测中,如下所示:
|
1 2 |
# 纠正预测 yhat = yhat + pred_error |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
# 使用预测残差误差模型纠正预测 from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat from statsmodels.tsa.ar_model import AutoReg from matplotlib import pyplot from sklearn.metrics import mean_squared_error from math import sqrt # 加载数据 series = read_csv('daily-total-female-births.csv', header=0, index_col=0, parse_dates=True, squeeze=True) # 创建滞后数据集 values = DataFrame(series.values) dataframe = concat([values.shift(1), values], axis=1) dataframe.columns = ['t', 't+1'] # 拆分为训练集和测试集 X = dataframe.values train_size = int(len(X) * 0.66) train, test = X[1:train_size], X[train_size:] train_X, train_y = train[:,0], train[:,1] test_X, test_y = test[:,0], test[:,1] # 训练集上的持久性模型 train_pred = [x for x in train_X] # 计算残差 train_resid = [train_y[i]-train_pred[i] for i in range(len(train_pred))] # 对训练集残差进行建模 window = 15 model = AutoReg(train_resid, lags=15) model_fit = model.fit() coef = model_fit.params # 遍历测试集中的时间步 history = train_resid[len(train_resid)-window:] history = [history[i] for i in range(len(history))] predictions = list() for t in range(len(test_y)): # 持久性 yhat = test_X[t] error = test_y[t] - yhat # 预测误差 length = len(history) lag = [history[i] for i in range(length-window,length)] pred_error = coef[0] for d in range(window): pred_error += coef[d+1] * lag[window-d-1] # 纠正预测 yhat = yhat + pred_error predictions.append(yhat) history.append(error) print('predicted=%f, expected=%f' % (yhat, test_y[t])) # 误差 rmse = sqrt(mean_squared_error(test_y, predictions)) print('Test RMSE: %.3f' % rmse) # 绘制预测误差 pyplot.plot(test_y) pyplot.plot(predictions, color='red') pyplot.show() |
运行该示例将打印测试数据集中每个时间步的预测和预期结果。
纠正后的预测的RMSE计算为7.499,这比仅使用持久性模型的得分9.151要好得多。
|
1 2 3 4 5 6 7 |
... predicted=40.675538, expected=37.000000 predicted=40.419129, expected=52.000000 predicted=44.839954, expected=48.000000 predicted=43.820997, expected=55.000000 predicted=44.574876, expected=50.000000 Test RMSE: 7.499 |
最后,将测试数据集的预期值(蓝色)与纠正后的预测(红色)进行比较绘制。
我们可以看到,持久性模型已被大幅度纠正,使其看起来像一个移动平均。
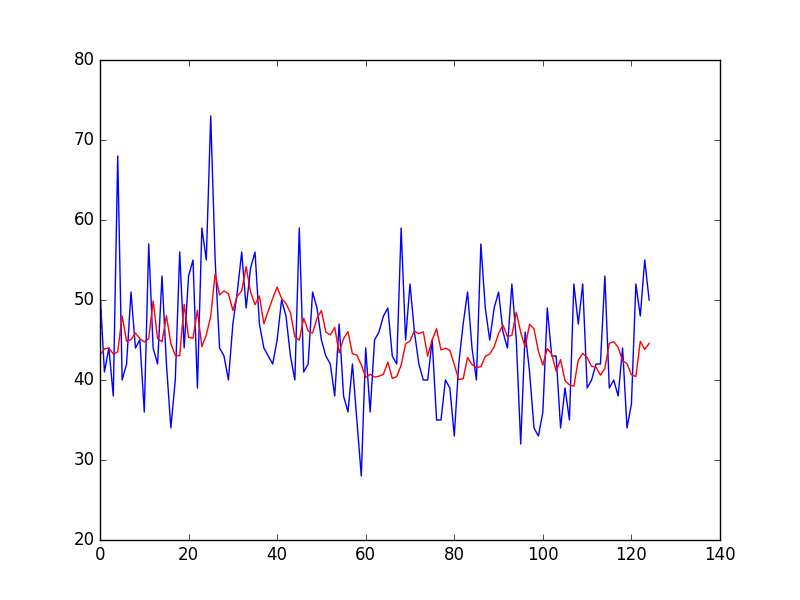
每日女性出生人口的纠正持久性预测
总结
在本教程中,您了解了如何对残差误差时间序列进行建模,并使用Python对其进行纠正以改进预测。
具体来说,你学到了:
- 关于使用自回归模型来处理残差误差的移动平均(MA)方法。
- 如何开发和评估残差误差模型以预测预测误差。
- 如何使用预测误差的预测来纠正预测并提高模型技能。
您对移动平均模型或本教程有任何疑问吗?
在下面的评论中提出你的问题,我会尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






有人发现这些教程根本行不通吗?
听到这个消息我很难过,你具体遇到了什么问题?
更新:我更新了前两个代码示例,使其更完整/易于直接运行。
您好 Jason,有没有办法在没有测试数据残差的情况下预测自相关残差?
也许可以。您对如何构建问题(例如输入和输出)拥有完全的自由。
请务必选择在预测时可用的输入。
嗨,如何知道滞后数?
我能否将上述过程总结为ARIMA(p,d,q)模型在后台的工作原理?
抱歉,我不明白。也许您可以提供更多上下文来重述您的问题?
我正在尝试使用ANN对ARIMA的残差进行建模,这称为混合ARIMA。你有什么线索吗?
你具体遇到什么问题了?
先生,实际上他指的是混合ARIMA-ANN模型 G. Peter Zhang模型,其中残差由ANN建模。
问题在于如何用ANN对如此小的数据集残差进行建模…
提前感谢
感谢您的教程。您能否用MATLAB解释一下这个教程?
抱歉,我没有MATLAB教程,这是一个只在学校使用的平台——不用于项目。
你好 Jason,
我对我的时间序列数据使用了一个SARIMAX模型,在计算训练集和测试集的残差误差时,我观察到了残差误差中的季节性。您认为我应该以某种方式重新纠正SARIMAX模型,还是可以按照您解释的方法将此应用于残差误差?
谢谢你,Jason!
祝您有美好的一天。
附注:当您回复我们的消息时,如果能收到您的电子邮件将很有帮助。
是的,如果残差误差中有信号,那么模型应该被更新以尽可能涵盖该信号。
你好 Jason,
“我们可以使用自回归模型对残差误差时间序列进行建模”
是否有可能(并且更准确)使用机器学习模型来对残差误差进行建模?
为什么?
Jason您好,我想问和Fatima一样的问题。
在我的案例中,数据集实际上是多元的,我想对这个多元数据集上的残差进行建模,并且我假设 AR 模型在这种情况下不适用。我可以使用经典的机器学习模型来实现相同的目的吗?
请知悉,我的数据集中确实包含了滞后项。
或许可以尝试一系列模型,包括线性模型和机器学习模型,然后找出最适合您特定数据集的模型。
嗨,Jason,
我不太明白您是如何得到
“下一个时间步(t+1)被作为输出变量”
看起来您将时间 t 的值用作时间 t+1 的值。
是不是应该是“values.shift(-1)”?
非常感谢!
是的,我用 t+1 代替了 t。那不是一个好的术语选择。
你好 Jason,
再次感谢您所有有用的教程!
我正在 Rob Hyndman 的博客上阅读关于带有 ARMA 误差的回归(https://robjhyndman.com/hyndsight/arimax/)。这是否与您这里的内容相似,只是您使用的是持续模型而不是 ARMA / ARIMA?
Row
是的,ARIMA 是 ARMA,只是增加了差分步骤。
谢谢你,Jason。
不客气。
嗨,Jason,
感谢您发布这个示例。
在您的示例中,您只预测未来 1 步,但如果使用这种持续模型结合此误差校正模型来预测 10 步,会怎么样?
您是否只需通过修改代码来预测误差
model_fit.forecast()[10] ?
总的来说,我认为如果您能展示一个提前多步样本外预测的示例,那将非常有帮助。
祝好!
调用 model.forecast(10)
history = train_resid[len(train_resid)-window:]
history = [history[i] for i in range(len(history))]
第一行与第二行输出的结果相同。您能解释一下为什么两者都包含在内吗?谢谢。
我猜是笔误。
感谢您的回复。我为我的数据集做了 ARIMA 预测,我也想预测它的误差。我应该创建一个训练集,拟合 ARIMA 模型,对测试集的长度进行预测,然后从测试集中获取误差吗?还是在使用 ARIMA 方法时会有所不同?
是的,这听起来是合理的。确保以与观测值相同的方式收集误差,例如,逐步或逐序列。
因此,我逐步收集了误差,然后使用 ADF 和 KPSS 检验检查了平稳性,这些检验告诉我误差是平稳的。然后,在查看了自相关和偏自相关图之后,我在误差上拟合了一个 ARIMA(0, 0, 0) 模型。这个模型在某种程度上是平均的,不是很灵活,因为它的意思是它不能捕捉数据中的峰值,也就是说,误差偏离均值很大的地方。是否有办法拟合一个更灵活的模型或使用不同的模型?请告诉我。谢谢!
干得好!
或许可以尝试一系列模型和模型配置,然后找出最适合您数据集的模型。
嗨,Jason,
能否将 LSTM 与残差架构混合使用?
提前感谢。
是的,残差可以作为输入提供给模型。
嗨,Jason,
非常感谢您的工作!是否可以安全地假设,您在此博客中概述的流程是我在 ARIMA 模型中包含 MA 项时后台所发生的情况?
非常接近。
嗨,Jason,
将文章中描述的分步估计模型(首先是响应模型,然后是残差模型)并随后在预测步骤中结合的方法,与 GLMM 或传递函数模型等方法进行对比,在这些方法中,我们可以直接对误差施加某种相关结构:如果实际目标仅仅是一个“良好”的预测(如本文所测量的 RMSE),是否存在任何陷阱(而不是例如对参数进行假设检验)?
感谢您的出色工作,我非常欣赏。
抱歉,我不确定我是否理解您的问题。也许您可以重新表述一下?
在文章中您说
“残差中的结构也可以直接建模。残差中可能存在难以直接纳入模型的复杂信号。取而代之的是,您可以对残差时间序列进行建模,并预测模型的预期误差。”
现在的问题是:在哪些情况下,直接建模误差结构比提出的两步法更受青睐?
我猜参数的标准误差会受到影响,但就预测性能本身而言,是否存在实际差异?
谢谢
不,请使用结果/数据来指导模型选择。
或许可以尝试这两种方法,并使用技能更好/误差更小的模型。
我想知道 ARMARESULT.resid 是否给出实际的残差。我想在另一个模型中使用这些残差。但它返回的数组大小是 55,而我拟合的数据集是 57。
也许模型有一个相差 2 的差分来解释残差的数量?
您是说 q 值是 2?
如果 q 是导致我得到这些结果的原因,我该如何将残差与时间序列数据对齐,以便将它们输入到 LSTM 等其他模型中?
如果您能回答我并给我一个示例或任何参考,我将不胜感激。
我没有示例,您需要自己尝试。
是的。
好帖子。关于一个点有个问题。
最初博客提到这一点
“残差中可能存在难以直接纳入模型的复杂信号。”
关于这一点,问题是,您能否分享一些技术或方法来检测残差序列中的这种结构。这将有助于确定我们是否需要进行残差建模,或者根本不需要。
有时,仅在残差上拟合模型就可以提高性能。
嗨 Jason..关于白噪声的解释… 您提到从任何时间序列中提取信号后的唯一误差应该是白噪声。但那是我们试图达到的理想模型…但总会有一些残差,我们通过 RMSE 等误差度量来计算这些残差。所以基本上任何模型都会有可减少的残差误差和不可减少的白噪声?
正如 George Box 所说:“所有模型都是错误的,但有些是有用的。”
理想情况下,我们会达到残差仅由白噪声组成的点。
这是一个理想情况,在实践中不可能或很难实现。
嗨 Jason,感谢您精彩的解释!我有一些问题
– 这些方法是否对“动态环境”(即当观察到的时间序列的可能原因发生变化时(新原因,…))效果更好?我的意思是,如果环境是“稳定的”,模型中不应该出现白噪声吗?
– 多次应用此方法是否有意义?我的意思是检查“二阶”预测:即添加误差预测后的误差,依此类推……我猜理论上是的,如果第二个误差仍然不是白噪声,但它在实践中真的会发生吗?
这真的取决于数据集的具体情况。
也许吧。可能需要一些实验。
嗨,Jason,
我的销售预测出现了负值,您能提供一些修复方法吗,特别是关于调整超参数。仅供参考,我正在使用 azure automl 来生成模型。
也许尝试替代模型?
或许可以尝试替代的模型配置?
或许可以尝试建模前的数据预处理?
或许可以尝试对预测结果进行后处理?
您能否添加一个按日期排序评论的选项?这真的可以节省时间。
评论线程按升序(从最早到最新)的日期时间顺序排列。
我认为这种方法不起作用。主要原因是使用预期误差(真实值)在“历史”列表中来预测相同的东西。将自回归系数与预测误差相乘,这在第一个循环中仅是预测误差。从下一个循环开始,您就在作弊。
是的,这是真的。在阅读了评论之后,我了解到我们可以通过实际使用在残差误差上训练的 AR 模型进行预测,将预测误差添加到历史中。
这就是我们在 ARIMA 方程中得到残差项的方式吗?假设 ARIMA(2,0,4) 模型,我们可以得到系数,但 model_fit.summary() 中有 4 个 q 项的系数,但 e(t-1)、e(t-2)、e(t-3) 和 e(t-4) 是如何计算的?如果您能提供相关链接,我将非常感激。
误差/残差项被假定为随机的,但遵循正态分布。如果您知道 x(t-1)、x(t-2) 等的真实值,并与预测进行比较,那么差值就是误差项。否则,误差项是未知的。