本教程介绍了数据科学和自动化学习中的两个基本概念。一个是机器学习管道,第二个是其优化。这两个原则是实现任何基于机器学习的成功智能系统的关键。
机器学习管道可以通过将训练机器学习模型所涉及的一系列步骤组合在一起而创建。它可以用于自动化机器学习工作流程。管道可以包括预处理、特征选择、分类/回归和后处理。更复杂的应用程序可能需要在该管道中适应其他必要的步骤。
通过优化,我们指的是调整模型以获得最佳性能。任何学习模型的成功都取决于选择能带来最佳结果的最佳参数。优化可以被看作是一种搜索算法,它遍历参数空间并从中找出最佳参数。
完成本教程后,您应该
- 理解管道及其优化的重要性。
- 能够设置机器学习管道。
- 能够优化管道。
- 了解分析优化结果的技术。
启动您的项目,阅读我的新书《机器学习优化》,其中包括分步教程和所有示例的Python源代码文件。
本教程简单易懂。您不需要花费太长时间就能完成。所以,请享受吧!教程概述
本教程将向您展示如何
- 使用 sklearn.pipeline 中的 Pipeline 对象设置管道。
- 使用 sklearn.model_selection 中的 GridSearchCV() 执行网格搜索以查找最佳参数。
- 分析 GridSearchCV() 的结果并可视化它们。
在演示上述所有内容之前,让我们先编写导入部分。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from pandas import read_csv # 用于数据帧 from pandas import DataFrame # 用于数据帧 from numpy import ravel # 用于矩阵 import matplotlib.pyplot as plt # 用于绘制数据 import seaborn as sns # 用于绘制数据 from sklearn.model_selection import train_test_split # 用于训练/测试分割 from sklearn.neighbors import KNeighborsClassifier # k近邻分类器 from sklearn.feature_selection import VarianceThreshold # 特征选择器 from sklearn.pipeline import Pipeline # 用于设置管道 # 各种预处理步骤 from sklearn.preprocessing import Normalizer, StandardScaler, MinMaxScaler, PowerTransformer, MaxAbsScaler, LabelEncoder from sklearn.model_selection import GridSearchCV # 用于优化 |
数据集
我们将使用来自UCI机器学习存储库的Ecoli数据集来演示本教程的所有概念。该数据集由Kenta Nakai维护。让我们首先将Ecoli数据集加载到Pandas DataFrame中,并查看前几行。
|
1 2 3 4 5 6 7 |
# 从UCI ML Repository读取ecoli数据集并存储在 # DataFrame df中 df = read_csv( 'https://archive.ics.uci.edu/ml/machine-learning-databases/ecoli/ecoli.data', sep = '\s+', header=None) print(df.head()) |
运行示例,您应该会看到以下内容
|
1 2 3 4 5 6 |
0 1 2 3 4 5 6 7 8 0 AAT_ECOLI 0.49 0.29 0.48 0.5 0.56 0.24 0.35 cp 1 ACEA_ECOLI 0.07 0.40 0.48 0.5 0.54 0.35 0.44 cp 2 ACEK_ECOLI 0.56 0.40 0.48 0.5 0.49 0.37 0.46 cp 3 ACKA_ECOLI 0.59 0.49 0.48 0.5 0.52 0.45 0.36 cp 4 ADI_ECOLI 0.23 0.32 0.48 0.5 0.55 0.25 0.35 cp |
我们将忽略第一列,它指定了序列名称。最后一列是类标签。让我们将特征与类标签分开,并将数据集分为2/3的训练实例和1/3的测试示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
... # 数据矩阵 X X = df.iloc[:,1:-1] # 标签 y = (df.iloc[:,-1:]) # 将标签编码为唯一的整数 编码器 = LabelEncoder() y = encoder.fit_transform(ravel(y)) # 将数据分割为测试集和训练集 X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=1/3, random_state=0) print(X_train.shape) print(X_test.shape) |
运行示例,您应该会看到以下内容
|
1 2 |
(224, 7) (112, 7) |
太好了!现在我们有224个训练样本和112个测试样本。我们选择了一个小数据集,以便我们可以专注于概念,而不是数据本身。
在本教程中,我们选择 k-nearest neighbor 分类器来对该数据集进行分类。
想要开始学习优化算法吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
没有管道和优化的分类器
首先,让我们检查一下 k-nearest neighbor 在训练集和测试集上的表现。这将为我们提供性能基线。
|
1 2 3 4 |
... knn = KNeighborsClassifier().fit(X_train, y_train) print('训练集得分: ' + str(knn.score(X_train,y_train))) print('测试集得分: ' + str(knn.score(X_test,y_test))) |
运行示例,您应该会看到以下内容
|
1 2 |
训练集得分: 0.9017857142857143 测试集得分: 0.8482142857142857 |
我们应该记住,分类器性能的真正衡量标准是测试集得分,而不是训练集得分。测试集得分反映了分类器的泛化能力。
设置机器学习管道
在本教程中,我们将设置一个非常基础的管道,它包括以下序列:
- 缩放器:用于预处理数据,即使用 StandardScaler() 将数据转换为零均值和单位方差。
- 特征选择器:使用 VarianceThreshold() 来丢弃方差小于某个预定阈值的特征。
- 分类器:KNeighborsClassifier(),它实现了k近邻分类器,并为最接近测试样本的k个点的多数选择类别。
|
1 2 3 4 5 6 |
... pipe = Pipeline([ ('scaler', StandardScaler()), ('selector', VarianceThreshold()), ('classifier', KNeighborsClassifier()) ]) |
pipe对象很简单易懂。它表示先缩放,再选择特征,最后分类。让我们在我们的训练数据上调用pipe对象的fit()方法,并获得训练和测试得分。
|
1 2 3 4 5 |
... pipe.fit(X_train, y_train) print('训练集得分: ' + str(pipe.score(X_train,y_train))) print('测试集得分: ' + str(pipe.score(X_test,y_test))) |
运行示例,您应该会看到以下内容
|
1 2 |
训练集得分: 0.8794642857142857 测试集得分: 0.8392857142857143 |
所以看起来这个管道的表现不如原始数据上的单个分类器。我们不仅增加了额外的处理,而且所有这些都是徒劳的。不要气馁,管道的真正好处来自于它的调优。下一节将解释如何做到这一点。
优化和调优管道
在下面的代码中,我们将展示以下内容:
- 我们可以搜索最佳缩放器。除了 StandardScaler(),我们还可以尝试 MinMaxScaler()、Normalizer() 和 MaxAbsScaler()。
- 我们可以为选择器中使用的方差阈值搜索最佳值,即 VarianceThreshold()。
- 我们可以为 KNeighborsClassifier() 搜索最佳的 k 值。
下面的 parameters 变量是一个字典,指定了键值对。注意,键必须是这样写的,用双下划线__分隔我们在Pipeline()中选择的模块名称及其参数。请注意以下几点:
- 由于我们在那里指定了一个对象列表,所以缩放器没有双下划线。
- 我们将搜索选择器的最佳阈值,即 VarianceThreshold()。因此,我们指定了一个值列表 [0, 0.0001, 0.001, 0.5] 供选择。
- 为 KNeighborsClassifier() 的 n_neighbors、p 和 leaf_size 参数指定了不同的值。
|
1 2 3 4 5 6 7 8 |
... parameters = {'scaler': [StandardScaler(), MinMaxScaler(), Normalizer(), MaxAbsScaler()], 'selector__threshold': [0, 0.001, 0.01], 'classifier__n_neighbors': [1, 3, 5, 7, 10], 'classifier__p': [1, 2], 'classifier__leaf_size': [1, 5, 10, 15] } |
然后将 pipe 以及上述参数列表传递给 GridSearchCV() 对象,该对象在参数空间中搜索最佳参数集,如下所示。
|
1 2 3 4 5 |
... grid = GridSearchCV(pipe, parameters, cv=2).fit(X_train, y_train) print('训练集得分: ' + str(grid.score(X_train, y_train))) print('测试集得分: ' + str(grid.score(X_test, y_test))) |
运行示例,您应该会看到以下内容
|
1 2 |
训练集得分: 0.8928571428571429 测试集得分: 0.8571428571428571 |
通过对管道进行调优,我们取得了比简单分类器和未优化管道更好的性能。分析优化过程的结果很重要。
不要太担心运行上述代码时出现的警告。这是因为我们的训练样本非常少,并且交叉验证对象在其中一个折叠中没有足够的样本来进行某个类别。所以会产生这个警告。
分析结果
让我们看一下调优后的 grid 对象,以便了解 GridSearchCV() 对象。
该对象之所以如此命名,是因为它设置了一个多维网格,每个角代表一个要尝试的参数组合。这定义了一个参数空间。例如,如果我们有三个 n_neighbors 值,即 {1,3,5},两个 leaf_size 值,即 {1,5},以及两个 threshold 值,即 {0,0.0001},那么我们就有一个 3D 网格,有 3x2x2=12 个角。每个角代表一个不同的组合。
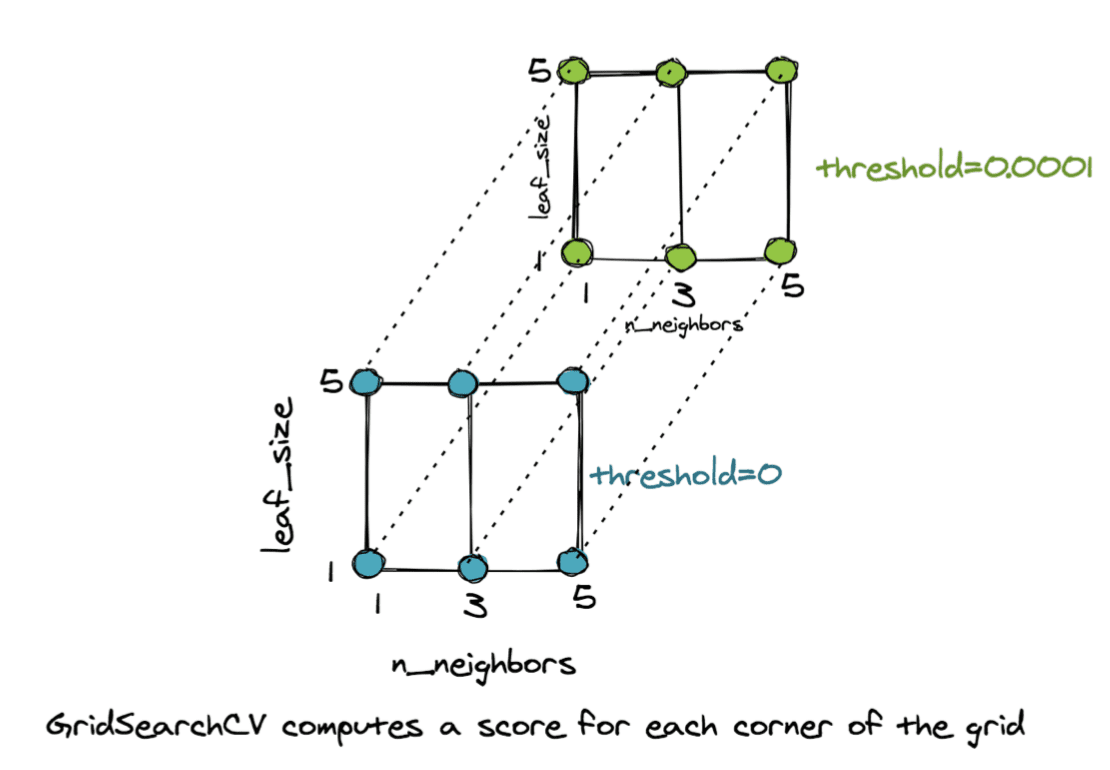
GridSearchCV 为网格的每个角计算得分
对于上述网格的每个角,GridSearchCV() 对象都会计算看不见样本的平均交叉验证得分,并选择产生最佳结果的角/参数组合。下面的代码展示了如何访问我们任务的最佳参数和最佳管道。
|
1 2 3 4 5 6 7 |
... # 访问最佳参数集 best_params = grid.best_params_ print(best_params) # 将最佳模型存储在best_pipe中 best_pipe = grid.best_estimator_ print(best_pipe) |
运行示例,您应该会看到以下内容
|
1 2 3 4 5 |
{'classifier__leaf_size': 1, 'classifier__n_neighbors': 7, 'classifier__p': 2, 'scaler': StandardScaler(), 'selector__threshold': 0} Pipeline(steps=[('scaler', StandardScaler()), ('selector', VarianceThreshold(threshold=0)), ('classifier', KNeighborsClassifier(leaf_size=1, n_neighbors=7))]) |
分析结果的另一种有用技术是从grid.cv_results_构建一个DataFrame。让我们查看这个DataFrame的列。
|
1 2 3 |
... result_df = DataFrame.from_dict(grid.cv_results_, orient='columns') print(result_df.columns) |
运行示例,您应该会看到以下内容
|
1 2 3 4 5 6 |
Index(['mean_fit_time', 'std_fit_time', 'mean_score_time', 'std_score_time', 'param_classifier__leaf_size', 'param_classifier__n_neighbors', 'param_classifier__p', 'param_scaler', 'param_selector__threshold', 'params', 'split0_test_score', 'split1_test_score', 'mean_test_score', 'std_test_score', 'rank_test_score'], dtype='object') |
这个DataFrame非常有价值,因为它显示了不同参数下的得分。mean_test_score列是在交叉验证期间对所有折叠的测试集得分的平均值。DataFrame可能太大了,无法手动可视化,因此,最好绘制结果。让我们看看n_neighbors如何影响不同缩放器和不同p值的性能。
|
1 2 3 4 5 6 7 8 |
... sns.relplot(data=result_df, kind='line', x='param_classifier__n_neighbors', y='mean_test_score', hue='param_scaler', col='param_classifier__p') plt.show() |
运行示例,您应该会看到以下内容
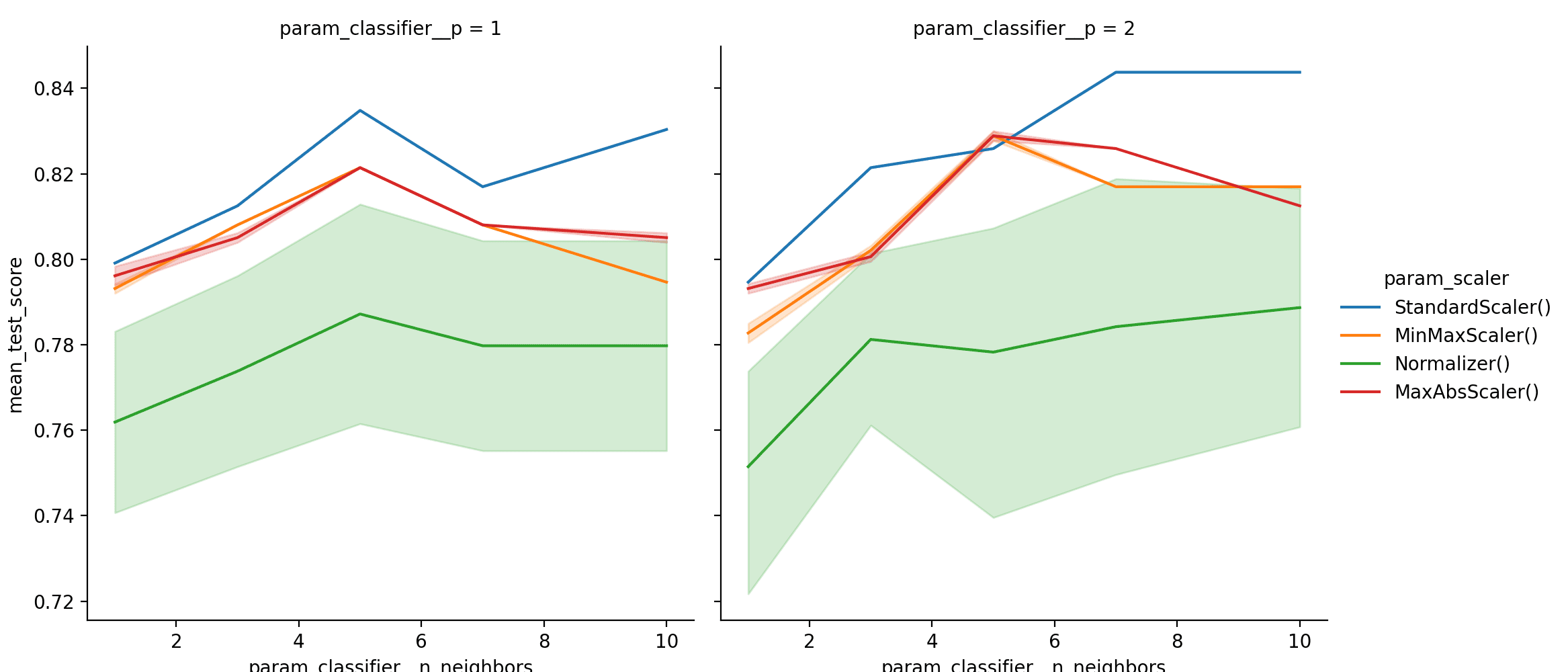
管道GridSearchCV结果的折线图
图表清楚地表明,使用 StandardScaler(),n_neighbors=7 和 p=2 可获得最佳结果。让我们再制作一组带有 leaf_size 的图。
|
1 2 3 4 5 6 7 8 |
... sns.relplot(data=result_df, kind='line', x='param_classifier__n_neighbors', y='mean_test_score', hue='param_scaler', col='param_classifier__leaf_size') plt.show() |
运行示例,您应该会看到以下内容
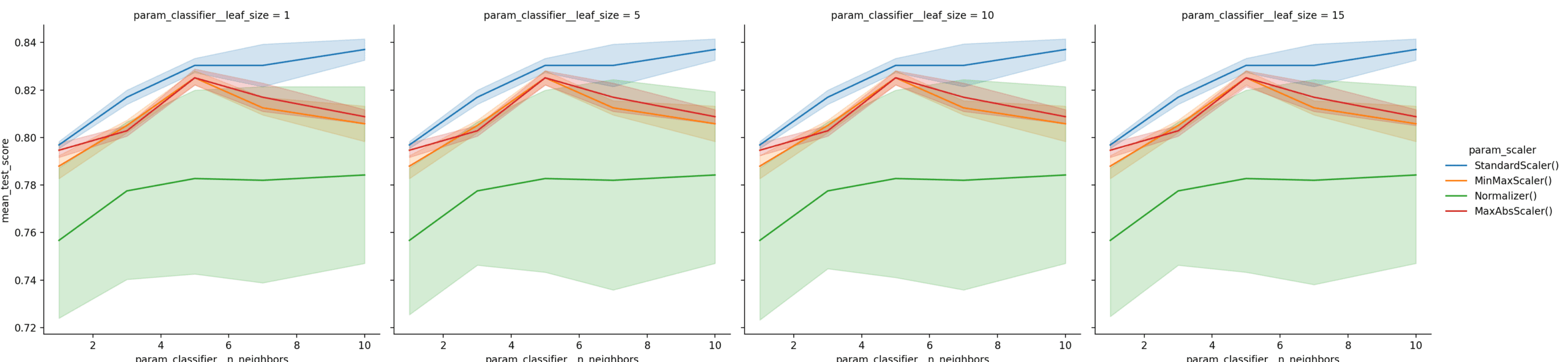
完整示例
总而言之,完整的代码示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
from pandas import read_csv # 用于数据帧 from pandas import DataFrame # 用于数据帧 from numpy import ravel # 用于矩阵 import matplotlib.pyplot as plt # 用于绘制数据 import seaborn as sns # 用于绘制数据 from sklearn.model_selection import train_test_split # 用于训练/测试分割 from sklearn.neighbors import KNeighborsClassifier # k近邻分类器 from sklearn.feature_selection import VarianceThreshold # 特征选择器 from sklearn.pipeline import Pipeline # 用于设置管道 # 各种预处理步骤 from sklearn.preprocessing import Normalizer, StandardScaler, MinMaxScaler, PowerTransformer, MaxAbsScaler, LabelEncoder from sklearn.model_selection import GridSearchCV # 用于优化 # 从UCI ML Repository读取ecoli数据集并存储在 # DataFrame df中 df = read_csv( 'https://archive.ics.uci.edu/ml/machine-learning-databases/ecoli/ecoli.data', sep = '\s+', header=None) print(df.head()) # 数据矩阵 X X = df.iloc[:,1:-1] # 标签 y = (df.iloc[:,-1:]) # 将标签编码为唯一的整数 编码器 = LabelEncoder() y = encoder.fit_transform(ravel(y)) # 将数据分割为测试集和训练集 X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=1/3, random_state=0) print(X_train.shape) print(X_test.shape) knn = KNeighborsClassifier().fit(X_train, y_train) print('训练集得分: ' + str(knn.score(X_train,y_train))) print('测试集得分: ' + str(knn.score(X_test,y_test))) pipe = Pipeline([ ('scaler', StandardScaler()), ('selector', VarianceThreshold()), ('classifier', KNeighborsClassifier()) ]) pipe.fit(X_train, y_train) print('训练集得分: ' + str(pipe.score(X_train,y_train))) print('测试集得分: ' + str(pipe.score(X_test,y_test))) parameters = {'scaler': [StandardScaler(), MinMaxScaler(), Normalizer(), MaxAbsScaler()], 'selector__threshold': [0, 0.001, 0.01], 'classifier__n_neighbors': [1, 3, 5, 7, 10], 'classifier__p': [1, 2], 'classifier__leaf_size': [1, 5, 10, 15] } grid = GridSearchCV(pipe, parameters, cv=2).fit(X_train, y_train) print('训练集得分: ' + str(grid.score(X_train, y_train))) print('测试集得分: ' + str(grid.score(X_test, y_test))) # 访问最佳参数集 best_params = grid.best_params_ print(best_params) # 将最佳模型存储在best_pipe中 best_pipe = grid.best_estimator_ print(best_pipe) result_df = DataFrame.from_dict(grid.cv_results_, orient='columns') print(result_df.columns) sns.relplot(data=result_df, kind='line', x='param_classifier__n_neighbors', y='mean_test_score', hue='param_scaler', col='param_classifier__p') plt.show() sns.relplot(data=result_df, kind='line', x='param_classifier__n_neighbors', y='mean_test_score', hue='param_scaler', col='param_classifier__leaf_size') plt.show() |
总结
在本教程中,我们学习了以下内容:
- 如何构建机器学习管道。
- 如何使用 GridSearchCV 优化管道。
- 如何分析和比较使用不同参数集获得的结果。
本教程使用的数据集样本点很少,但结果仍然比简单的分类器要好。
进一步阅读
对于有兴趣的读者,这里有一些资源:
教程
- Gavin Cawley 和 Nicola Talbot 的《模型选择中的过拟合和随后的性能评估选择偏差》
- k折交叉验证入门详解
- 模型选择
- k-nearest Neighbors Algorithm (k近邻算法)
- 机器学习建模流程简明介绍
API
- sklearn.model_selection.ParameterSampler API
- sklearn.model_selection.RandomizedSearchCV API
- sklearn.model_selection.KFold API
- sklearn.model_selection.ParameterGrid API
数据集
- Dua 和 Graff 维护的 UCI Machine Learning Repository (UCI机器学习存储库).
- Ecoli Dataset (Ecoli数据集),由 Kenta Nakai 维护。请参阅这篇论文了解更多信息。

")





感谢这篇帖子。几乎和JBL的帖子一样清晰。
如果我们想测试多个带有多个超参数的选择器怎么办?使用 sklearn 是否可行?如果可行,语法是怎样的?
您可以将模型替换为 gridsearch 对象,它将找到最佳参数集。
女士,
很棒。
非常感谢。
拉维
不客气!
非常有用的帖子!
只是有一个疑问,在标题为“设置机器学习管道”的内容中,它定义为“特征选择器:使用 VarianceThreshold() 来选择方差小于某个预定阈值的特征。”
但实际上 VarianceThreshold() 是一个特征选择器,它会移除所有低方差的特征。也就是说,方差低于该阈值的特征将被移除。
您能检查并确认一下吗?
您说得完全正确。非常感谢您指出这一点。所有低方差的特征都应该被丢弃。我已经进行了更正。
很棒的文章,感谢分享,Mehreen Saeed!
代码是否在git repo或Colab notebook中可用?
这将帮助您从教程中复制代码
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
做得很好。
谢谢 Mehreen
感谢您的精彩文章。我有一个问题。
如果数据集非常大(例如,1000000 行,100 列),GridSearchCV 将花费太长时间,尤其是在需要遍历许多参数的情况下。
在这种情况下,对数据进行采样(比如 10k 行)并将其输入 GridSearchCV 是否有意义?
我们可以假设采样数据的结果对整个数据也有效吗?
您有几种选择,例如使用更快的机器、使用更小的数据样本、使用替代的搜索方法、使用更简单的模型等。
非常感谢您提供的详细有用的帖子。
不客气,TrongDV!
我总觉得将数据预处理(缩放器)放入网格搜索中存在数据泄露问题。基于管道,训练数据将首先被预处理,然后其输出被分割成(新的)训练集和 CV 估算器中的交叉验证数据集。因此,您将看到交叉验证集实际上与(新的)训练集在同一阶段被预处理。这存在数据泄露问题。大多数时候,我们期望这种影响最小,但如果模型对缩放器非常敏感,那么它就很重要。
Gru Lee,非常好的反馈!
这个网站上又一篇精彩的文章!快速提问:在重新训练 sklearn 管道时,您是建议直接重新训练:加载旧管道并调用它的 `.fit()`,还是加载旧管道,调用 sklearn 的 clone(),然后用这个新的未拟合管道和相同的参数运行 `.fit()`?谢谢。