图像扩散模型,最简单的形式是根据提示生成图像。提示可以是文本提示,也可以是图像,只要有合适的编码器将其转换为模型可以使用的张量,作为指导生成过程的条件。文本提示可能是提供条件的最简单方法。它很容易提供,但您可能发现很难生成符合您期望的图片。在这篇文章中,您将学习:
- 如何构建您的提示
- 有效提示的要素
使用我的书《Mastering Digital Art with Stable Diffusion》启动您的项目。它提供了自学教程和可运行的代码。
让我们开始吧。

稳定扩散的更多提示技术
照片由 Simon English 拍摄。保留部分权利。
概述
这篇文章分为三个部分;它们是
- 使用审问器
- 创建有效的提示
- 试验提示
使用审问器
如果您从头开始,可能很难描述您脑海中的图片。这并不容易,因为并非每个人都能有效地用语言传达自己的想法。此外,Stable Diffusion 模型也可能无法如您预期地理解您的提示。
不可否认,从某些东西开始并对其进行修改会更容易。您可以从网上别人的成功案例中复制提示。您也可以提供一个样本图片,让 Stable Diffusion Web UI 构建一个提示。此功能称为“审问器”。
让我们将一张图片下载到硬盘。在 Web UI 的“img2img”选项卡上,上传该图片,然后点击带有回形针图标的“Interrogate CLIP”按钮。
Web UI 中 img2img 选项卡的审问按钮
您应该会看到生成的提示如下:
一个男人站在山顶,望着他下方的群山,背上有一个背包,肩上也有一个背包,康斯坦特·佩尔梅克,一张库存照片,敬畏感,后极简主义
这对于开始提示工程非常有帮助。您可以看到,提示的第一部分描述了图片。然后“康斯坦特·佩尔梅克”是一位画家。“后极简主义”是一种艺术运动。与“一张库存照片”一起,它们的作用是控制风格。“敬畏感”这个词控制了感觉,暗示男人背对着相机,面对着大自然的奇观。
确实,在 Web UI 中,“Interrogate CLIP”旁边还有一个审问按钮。带有纸板箱图标的那个是“Interrogate Deepbooru”,它基于一个不同的图像字幕模型。对于同一张图片,您会看到生成的提示如下:
1个男孩,背包,袋子,蓝天,靴子,建筑,城市,城市景观,悬崖,云,多云天空,白天,背对,田野,从背后,草,山丘,地平线,房子,岛屿,湖泊,风景,男性焦点,山,多山地平线,海洋,户外,河流,岩石,风景,天空,雪,独自,站立,树,水,瀑布,波浪
您得到的是一系列关键词而不是一个句子。您可以根据需要编辑提示,或者将生成的提示作为您的灵感。
审问模型有多好?您不应该期望提示能生成原始图片,但应该接近。在 txt2img 选项卡中重复该提示会得到这个:
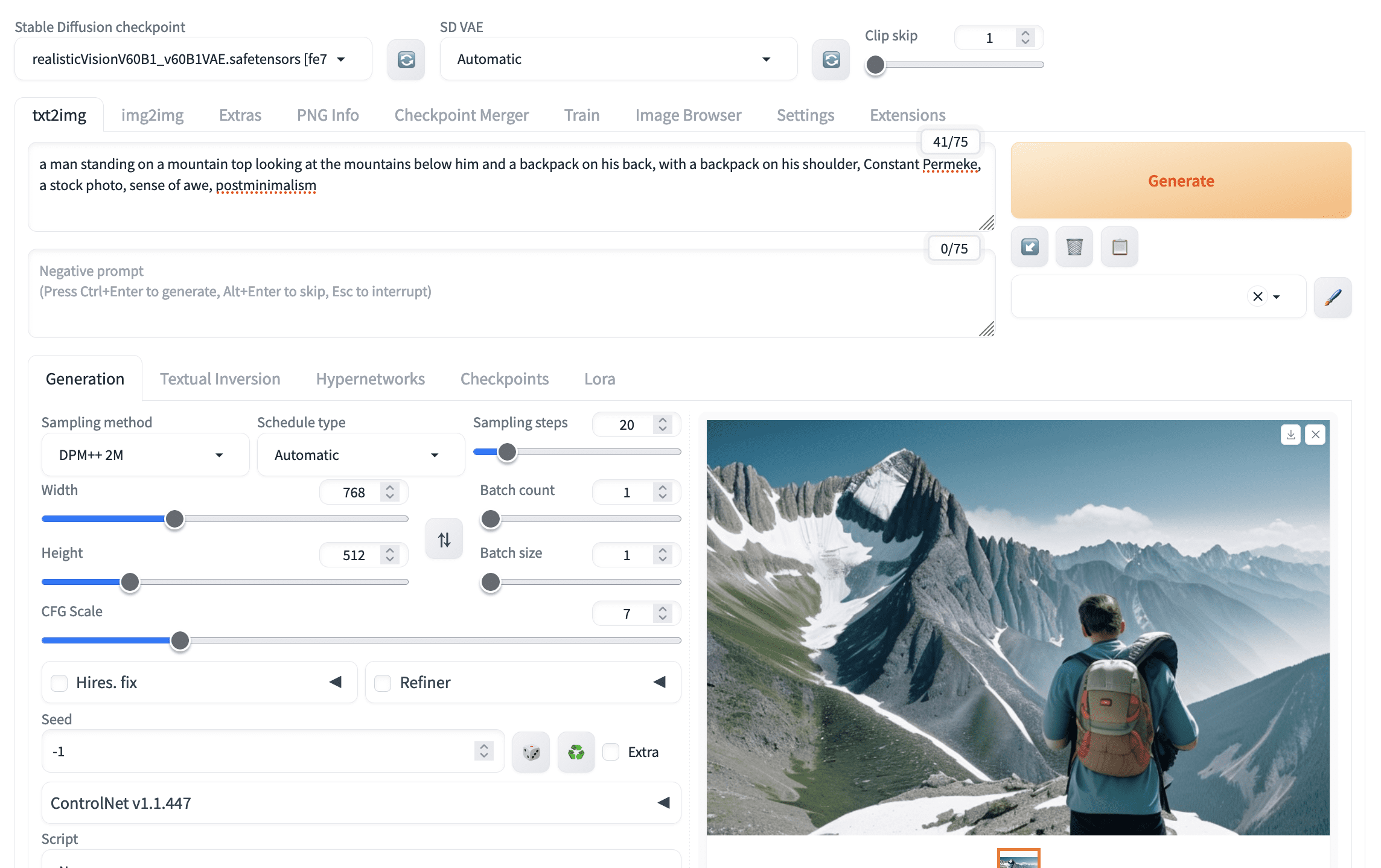
使用 CLIP 审问器建议的提示生成的图片
不算太糟。但如果您使用 Deepbooru 创建的提示,您可能会发现它不太准确。
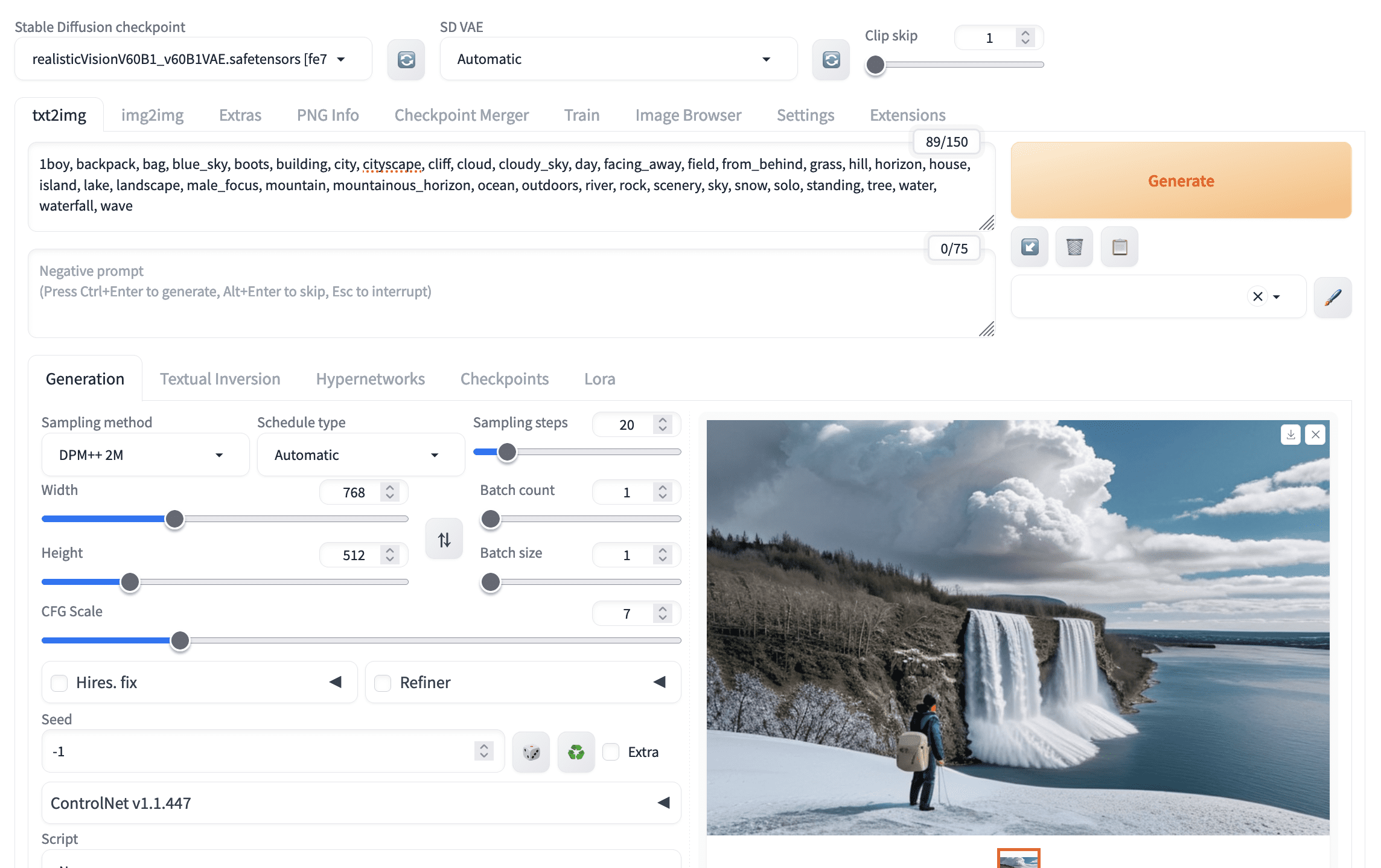
使用 Deepbooru 审问器建议的提示生成的图片
创建有效的提示
CLIP 模型适用于照片,而 Deepbooru 模型适用于插图、动漫和漫画。但是,使用适当的模型来使用提示很重要。例如,如果您打算生成动漫风格的图片,使用动漫检查点(例如 Counterfeit)会很有帮助。
让我们回顾一下 CLIP 模型生成的提示。为什么没有生成原始图片?
一个好的提示应该包含三个 S
- 主体 (Subject):前景中有什么,以及它的背景。
- 场景 (Scene):背景中有什么,包括构图和色彩运用。
- 风格 (Style):图片的抽象描述,包括媒介。
事实上,还有第四个 S:具体 (specific)。您应该详细描述您看到的东西,而不是您知道的东西。您不应该说图片中没有显示的东西。例如,不要描述背包里的东西,因为您从照片中看不到。您应该提到不仅仅是一个男人,还有他的着装。描述看不见和无形的东西(如男人的情绪)通常无济于事。如果您需要一本同义词词典来帮助您,可以尝试在线提示生成器,甚至 ChatGPT。

使用 ChatGPT 帮助构思图像生成文本提示
让我们尝试丰富一下提示。
- 主体:一个男人站在山顶,望着他下方的群山,背着一个背包,穿着红色夹克,短裤,背对观看者。
- 场景:明亮的蓝天,白云,岩石堆旁边,敬畏感。
- 风格:写实,细节丰富,广角,后极简主义,康斯坦特·佩尔梅克。
将所有这些结合起来,您可能会发现输出结果如下:
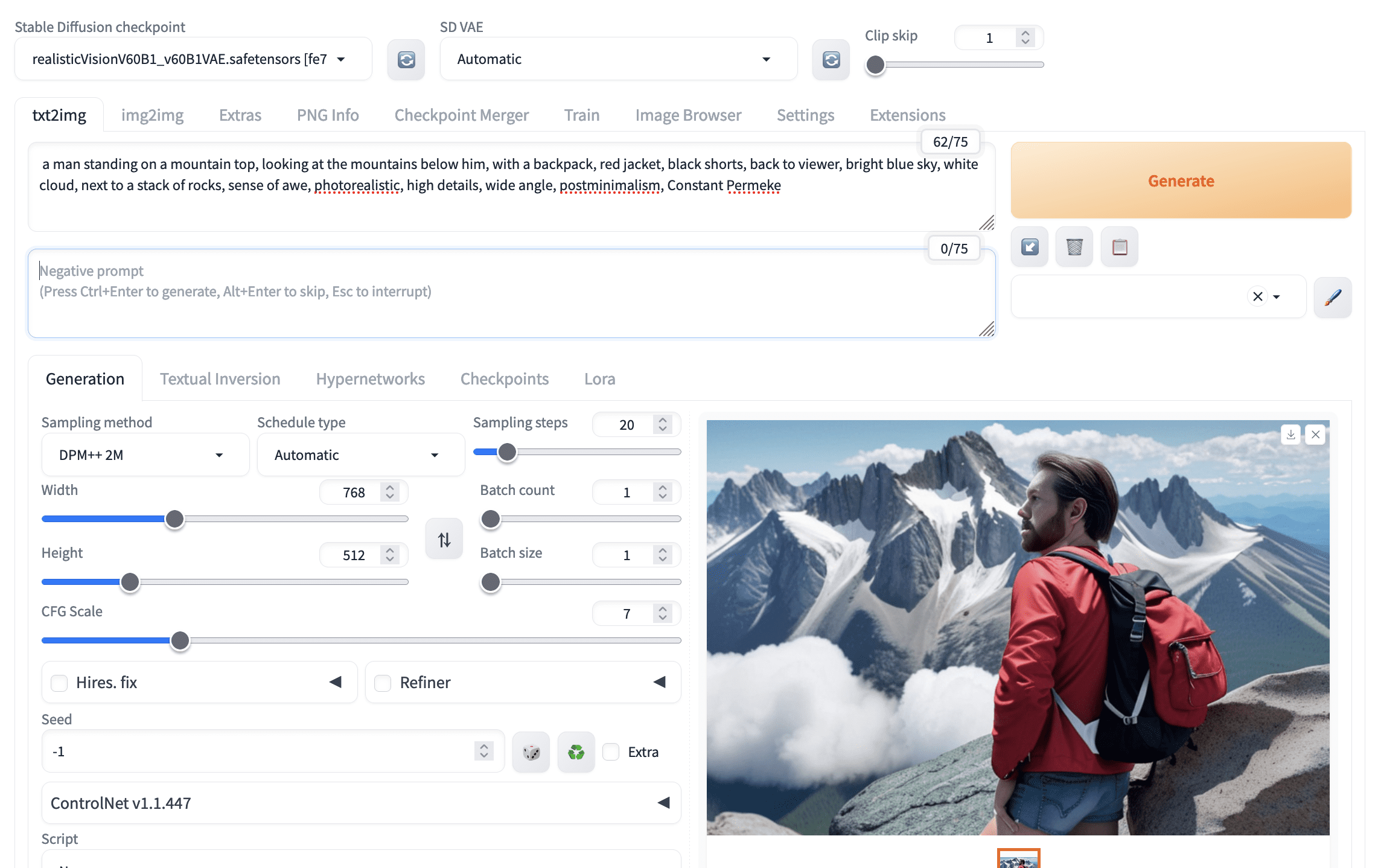
Stable Diffusion 生成的图片,但未准确遵循提示。
不完美。提示提供了许多细节,但模型没有匹配所有内容。当然,增加“CFG Scale”参数会有帮助,因为它要求模型更严格地遵循您的提示。另一种改进方法是查看模型生成的内容,并强调模型遗漏的关键词。您可以使用语法 (keyword:weight) 来调整权重;默认权重为 1.0。
上面的图片缺少几个问题。图片是男人的特写,所以不是广角镜头。男人没有穿黑色短裤。让我们都强调一下。通常,将权重从 1.0 增加到 1.1 会有帮助。只有当您确认需要时,才会尝试使用更高的权重。
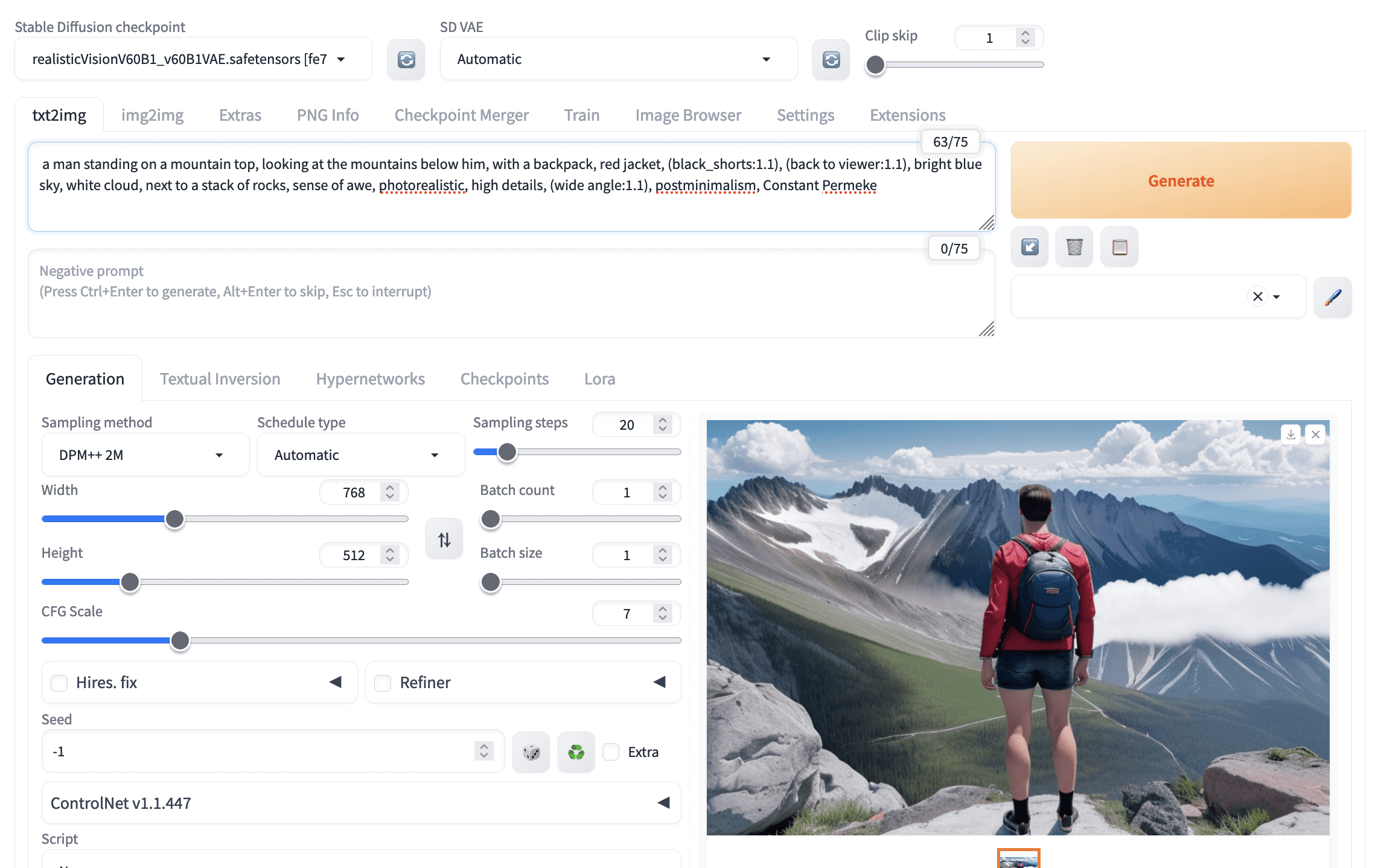
调整提示中的关键词权重后,图片效果更好。
上面的图片显示使用了提示 (black_shorts:1.1)。下划线是故意的,因为它将被解释为空格,但为了确保这两个词被一起解释。因此,“black”很可能被解释为名词“shorts”的形容词。
有时,您非常努力,但模型并不准确地遵循您的提示。您可以使用负面提示来强制执行您不想要的内容。例如,您看到男人没有完全背对着您。您可以将“face”作为负面提示,意思是您不想看到他的脸。
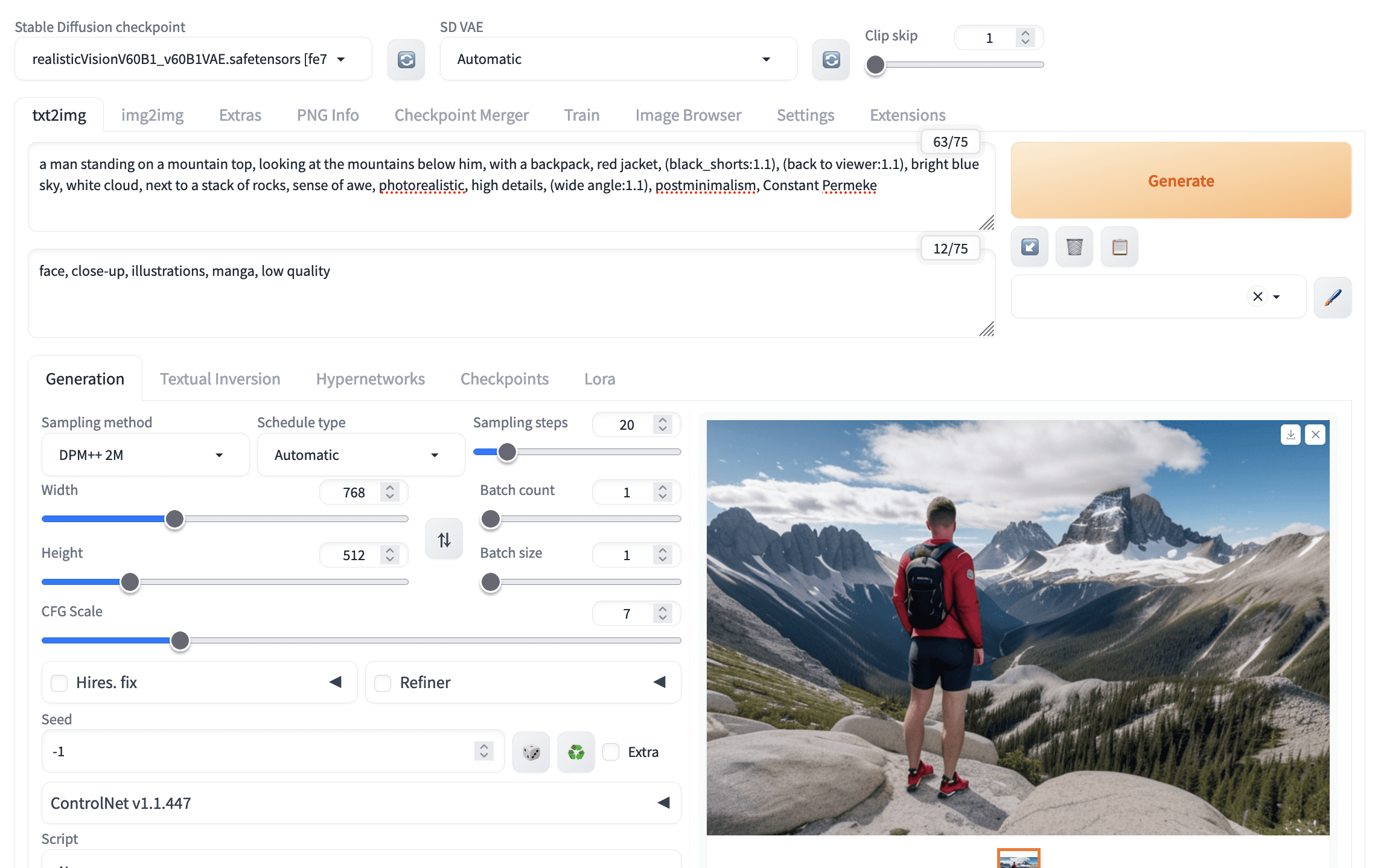
使用负面提示有助于生成更好的图片。
试验提示
使用 Stable Diffusion 创建图片可能需要耐心和大量的实验。这是因为不同的模型对相同的提示可能工作方式不同,并且图像扩散过程存在随机性。您可能想尝试不同的模型,尝试不同的提示,甚至多次重复生成。
一些工具可以为您节省此实验过程中的时间。最简单的方法是一次生成多张图片,每张图片都有不同的随机种子。如果将批量大小设置为大于 1,并将种子保留为 -1(表示每次都生成新种子),您就可以单击一次创建多张图片。请注意,这会消耗更多的 GPU 内存。如果内存不足,您可以增加批次数,即运行多次图像生成迭代。速度较慢,但内存占用较少。
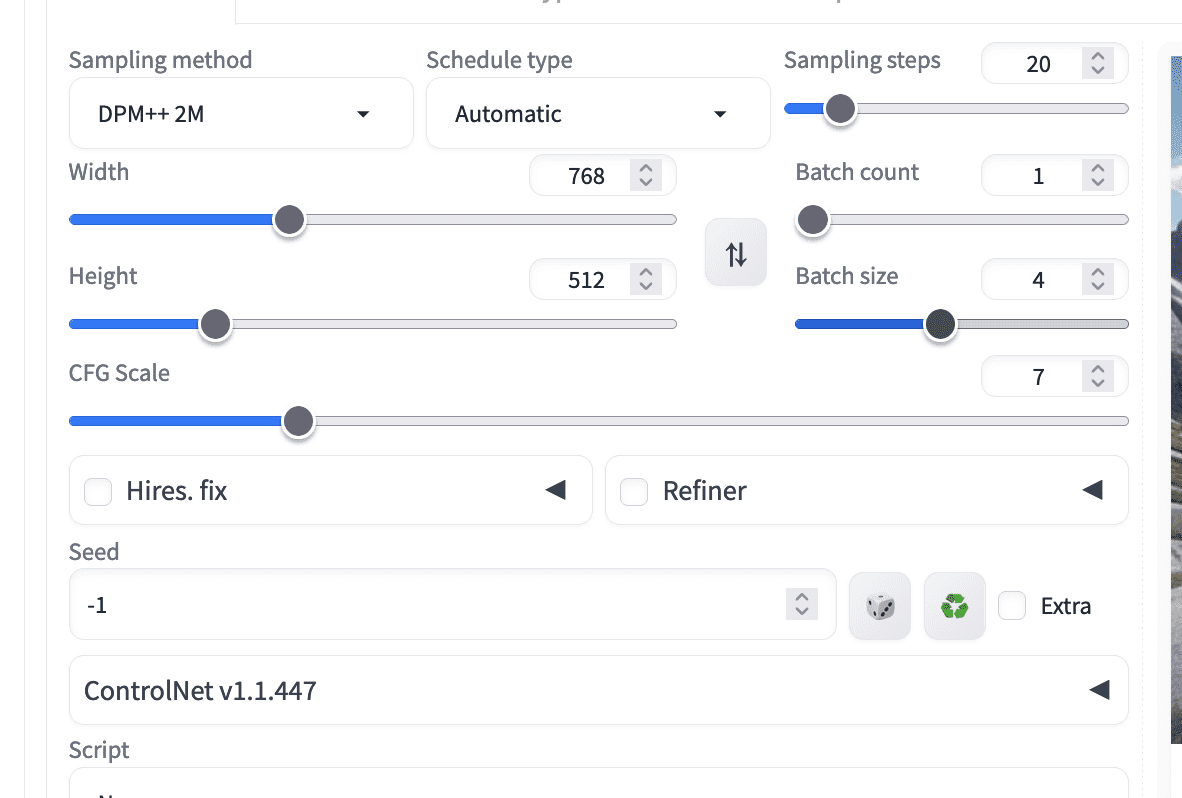
将批量大小和批次数设置为 -1 种子,一次生成多张图像。
一旦从许多生成的图片中找到一个好的候选图片,您就可以单击该图片找到使用的种子。然后,为了进一步完善图片,您应该固定种子,同时修改提示。每次稍微修改提示,以便您可以缓慢地引导生成过程,从而创建您想要的图像。
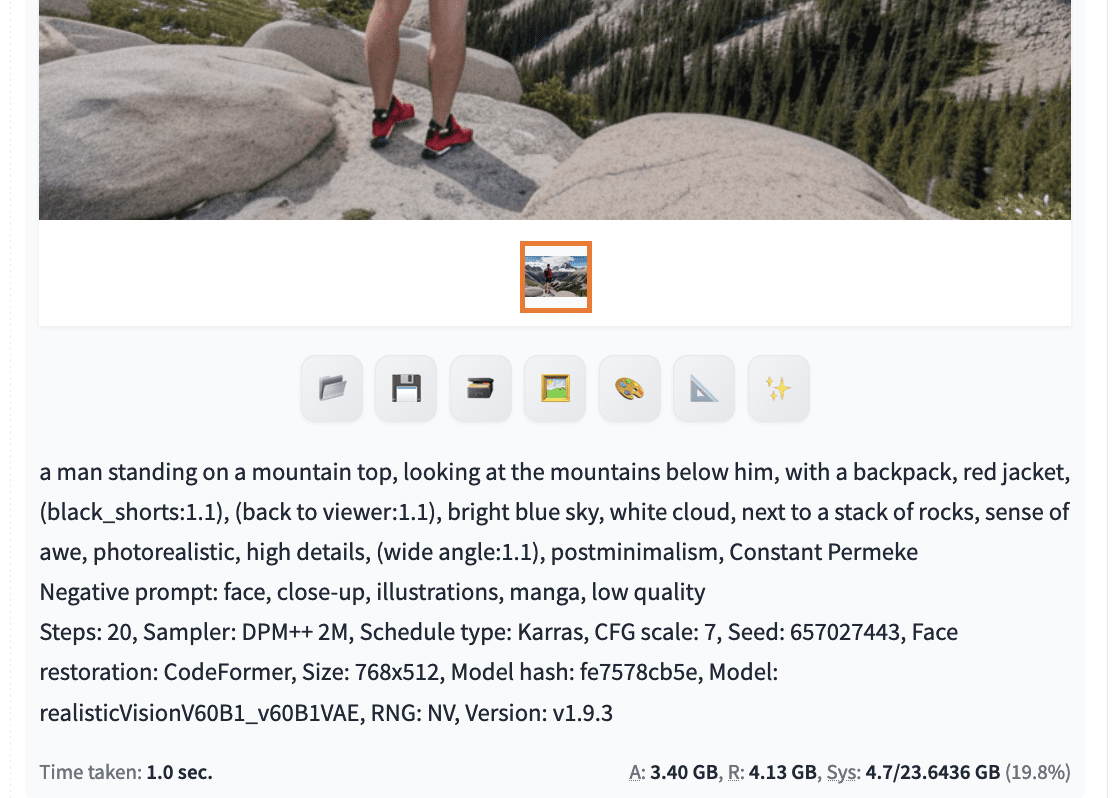
Web UI 将报告用于生成图片的参数,您可以在其中找到种子。
但是应该如何修改提示?一种方法是尝试关键词的不同组合。在 Web UI 中,您可以使用“prompt matrix”脚本来帮助加快此实验。您将提示分成不同的部分,用竖线字符( | )分隔,例如:
一个男人站在山顶,望着他下方的群山,背着一个背包,穿着红色夹克,(黑色短裤:1.1),(背对观看者:1.1),明亮的蓝天,白云,岩石堆旁边,敬畏感,(广角:1.1) | 写实,细节丰富 | 后极简主义,康斯坦特·佩尔梅克
然后,在 txt2img 选项卡的底部,在 Script 部分选择“Prompt matrix”。因为上面的提示被设置为正面提示,所以在“Select prompt”部分选择“positive”。单击“Generate”,您将看到多张生成的图片。
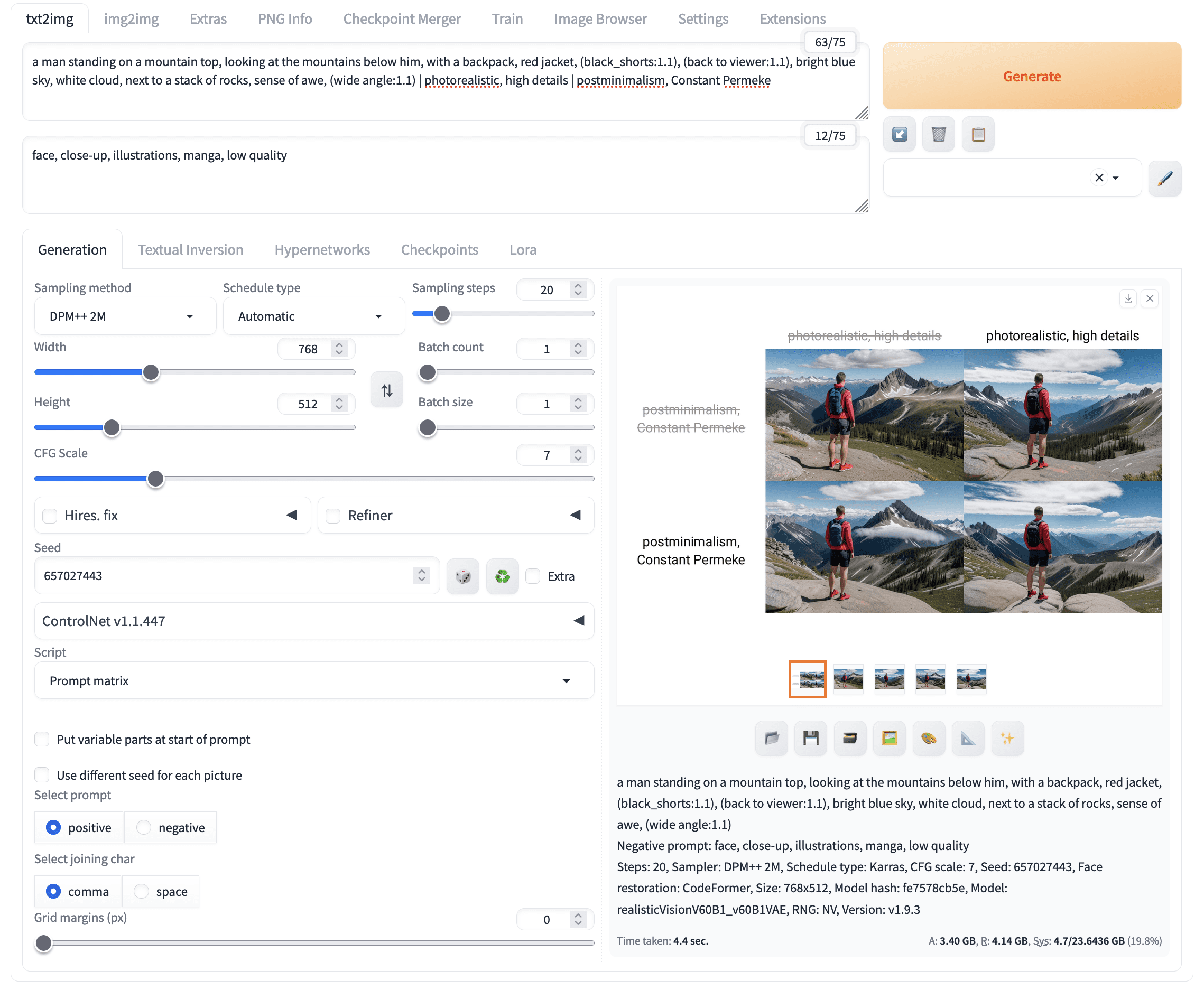
使用 prompt matrix 脚本进行不同提示的实验。
“prompt matrix”会列出您提示的所有组合,每个部分作为一个单元。请注意,种子和所有其他参数都已固定;只有提示在变化。这对于公平地比较提示的效果至关重要。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
- 动漫风格图片的 Counterfeit 模型: https://civitai.com/models/4468/counterfeit-v30
- 写实图片的 Realistic Vision 模型: https://civitai.com/models/4201/realistic-vision-v60-b1
- Promptomania 的提示生成器,您可以从中了解提示的不同关键词。
- Stable Diffusion Web UI wiki 功能页面上的“Attention and Emphasis”部分。
总结
在这篇文章中,您了解了一些有助于您在 Stable Diffusion 中创建更好图片的技巧。具体来说,您学习了:
- 如何使用审问器从现有图像生成提示。
- 有效提示的三个 S:主体、场景和风格。
- 如何有效地试验提示。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
本书提供自学教程,包含所有 Python可运行代码,引导您从新手成为图像生成专家。它教您如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等……所有这些都将帮助您创作出令人惊叹的数字艺术。






暂无评论。