移动平均平滑是一种简单而有效的时间序列预测技术。
它可用于数据准备、特征工程,甚至可直接用于进行预测。
在本教程中,您将了解如何使用移动平均平滑进行时间序列预测,并使用 Python。
完成本教程后,您将了解:
- 移动平均平滑的工作原理以及在使用它之前,您对数据的期望。
- 如何使用移动平均平滑进行数据准备和特征工程。
- 如何使用移动平均平滑进行预测。
启动您的项目,阅读我的新书《Python 时间序列预测》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。
- 2019年8月更新:更新了数据加载以使用新的API。

使用 Python 进行数据准备、特征工程和时间序列预测的移动平均平滑
照片由 Bureau of Land Management 拍摄,保留部分权利。
移动平均平滑
平滑是一种应用于时间序列的技术,用于去除时间步之间的细微变化。
平滑的目的是去除噪声,更好地暴露潜在因果过程的信号。移动平均是时间序列分析和时间序列预测中使用的一种简单且常见的平滑方法。
计算移动平均需要创建一个新序列,其中值由原始时间序列中的原始观测值的平均值组成。
移动平均要求您指定一个称为窗口宽度的窗口大小。这定义了用于计算移动平均值的原始观测值的数量。
移动平均中的“移动”一词指的是由窗口宽度定义的窗口沿着时间序列滑动以计算新序列中的平均值这一事实。
有两种主要的移动平均类型:中心移动平均和拖尾移动平均。
中心移动平均
时间 (t) 的值计算为时间 (t) 前、后和此时的原始观测值的平均值。
例如,窗口为 3 的中心移动平均计算方法如下:
|
1 |
center_ma(t) = mean(obs(t-1), obs(t), obs(t+1)) |
此方法需要了解未来值,因此用于时间序列分析以更好地理解数据集。
中心移动平均可以用作从时间序列中去除趋势和季节性成分的通用方法,而当我们预测时,这种方法通常无法使用。
拖尾移动平均
时间 (t) 的值计算为时间 (t) 及之前时间点的原始观测值的平均值。
例如,窗口为 3 的拖尾移动平均计算方法如下:
|
1 |
trail_ma(t) = mean(obs(t-2), obs(t-1), obs(t)) |
拖尾移动平均仅使用历史观测值,并用于时间序列预测。
这是我们将在本教程中重点关注的移动平均类型。
数据预期
计算时间序列的移动平均值会使您的数据产生一些假设。
假设趋势和季节性成分已从您的时间序列中移除。
这意味着您的时间序列是平稳的,即不显示明显的趋势(长期增加或减少的运动)或季节性(一致的周期性结构)。
在进行时间序列数据集预测时,有许多方法可以去除趋势和季节性。每种方法都有两种好方法:使用差分法和对行为进行建模并将其显式地从序列中减去。
在时间序列问题中使用机器学习算法时,移动平均值可以以多种方式使用。
在本教程中,我们将介绍如何计算拖尾移动平均值,用于数据准备、特征工程以及直接进行预测。
在深入研究这些示例之前,让我们看一下将在每个示例中使用的每日女性出生数据集。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
每日女性出生数据集
此数据集描述了 1959 年加利福尼亚州每日女性出生人数。
单位是计数,共有 365 个观测值。数据集的来源归功于 Newton (1988)。
以下是数据的前 5 行样本,包括标题行。
|
1 2 3 4 5 6 |
"日期","出生人数" "1959-01-01",35 "1959-01-02",32 "1959-01-03",30 "1959-01-04",31 "1959-01-05",44 |
以下是整个数据集的图。
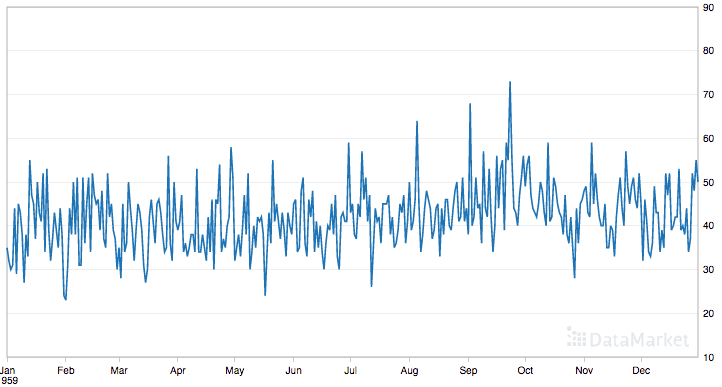
每日女性出生数据集
该数据集是探索移动平均方法的良好示例,因为它不显示任何明显的趋势或季节性。
加载每日女性出生数据集
下载数据集,并将其以文件名“daily-total-female-births.csv”放在当前工作目录中。
下面的代码片段加载数据集作为 Series,显示数据集的前 5 行,并将整个序列绘制为折线图。
|
1 2 3 4 5 6 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-total-female-births.csv', header=0, index_col=0) print(series.head()) series.plot() pyplot.show() |
运行示例将按如下方式打印前 5 行
|
1 2 3 4 5 6 |
日期 1959-01-01 35 1959-01-02 32 1959-01-03 30 1959-01-04 31 1959-01-05 44 |
下面是加载数据的折线图。
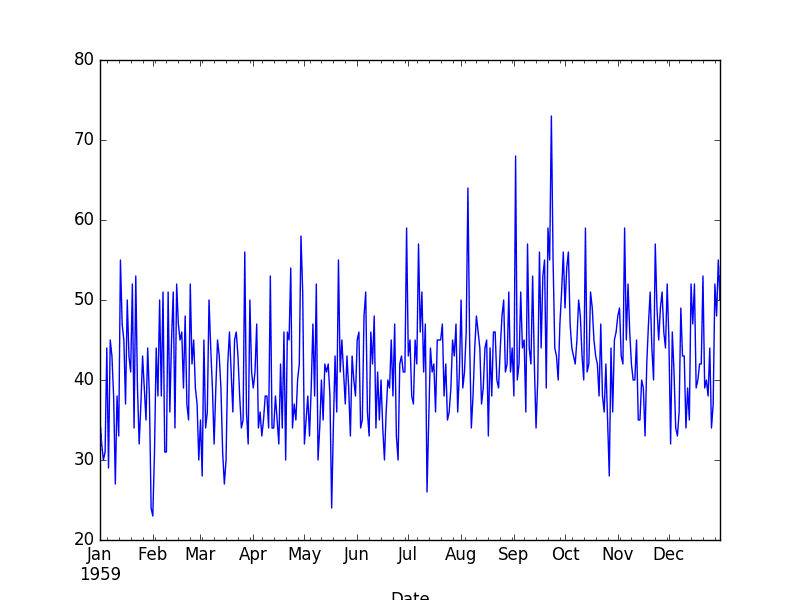
每日女性出生数据集图
移动平均作为数据准备
移动平均可用作数据准备技术,以创建原始数据集的平滑版本。
平滑作为数据准备技术很有用,因为它可以减少观测值中的随机变化,并更好地揭示潜在因果过程的结构。
Series Pandas 对象上的 rolling() 函数将自动将观测值分组到窗口中。您可以指定窗口大小,并且默认创建一个拖尾窗口。创建窗口后,我们可以取平均值,这就是我们的转换后的数据集。
未来新观测值的转换同样容易,方法是保留最后几个观测值的原始值并更新新的平均值。
为了具体说明,当窗口大小为 3 时,时间 (t) 的转换值计算为前 3 个观测值 (t-2, t-1, t) 的平均值,如下所示:
|
1 |
obs(t) = 1/3 * (t-2 + t-1 + t) |
对于每日女性出生数据集,第一个移动平均将在 1 月 3 日进行,如下所示:
|
1 2 3 |
obs(t) = 1/3 * (t-2 + t-1 + t) obs(t) = 1/3 * (35 + 32 + 30) obs(t) = 32.333 |
下面是一个将每日女性出生数据集转换为移动平均的示例,窗口大小为 3 天,该大小是任意选择的。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-total-female-births.csv', header=0, index_col=0) # 拖尾滚动平均转换 rolling = series.rolling(window=3) rolling_mean = rolling.mean() print(rolling_mean.head(10)) # 绘制原始数据集和转换后的数据集 series.plot() rolling_mean.plot(color='red') pyplot.show() |
运行示例将打印转换后的数据集的前 10 个观测值。
我们可以看到前 2 个观测值需要被丢弃。
|
1 2 3 4 5 6 7 8 9 10 11 |
日期 1959-01-01 NaN 1959-01-02 NaN 1959-01-03 32.333333 1959-01-04 31.000000 1959-01-05 35.000000 1959-01-06 34.666667 1959-01-07 39.333333 1959-01-08 39.000000 1959-01-09 42.000000 1959-01-10 36.000000 |
原始观测值(蓝色)与移动平均转换(红色)叠加绘制。
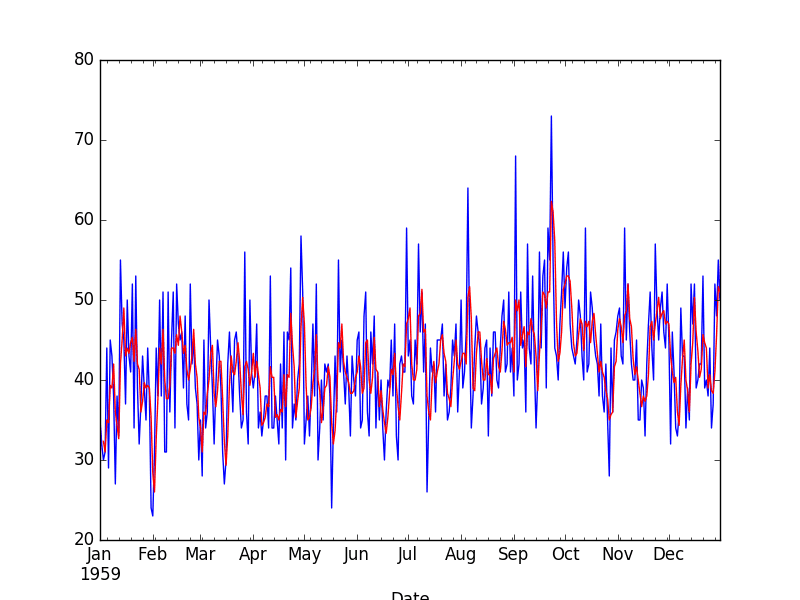
移动平均转换
为了更好地了解转换的效果,我们可以放大并绘制前 100 个观测值。
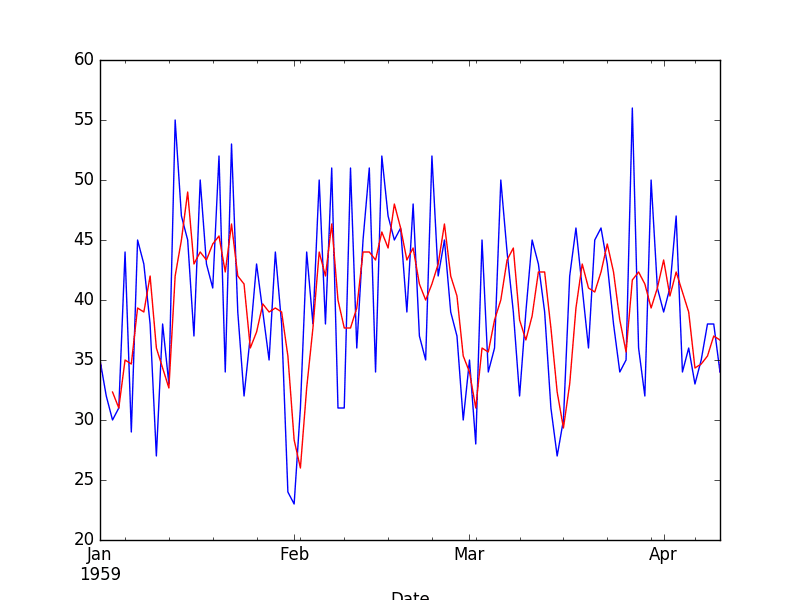
缩放的移动平均转换
在这里,您可以清楚地看到转换后的数据集中的延迟。
接下来,让我们看看如何使用移动平均作为特征工程方法。
移动平均作为特征工程
当将时间序列预测建模为监督学习问题时,移动平均可用作新信息的来源。
在这种情况下,计算移动平均并将其添加为用于预测下一个时间步的新输入特征。
首先,必须将 Series 的副本向前移动一个时间步。这将代表我们预测问题的输入,或者 Series 的滞后 1 版本。这是时间序列问题的标准监督学习视图。例如:
|
1 2 3 4 |
X, y NaN, obs1 obs1, obs2 obs2, obs3 |
接下来,需要将 Series 的第二个副本向前移动一个时间步,减去窗口大小。这是为了确保移动平均总结了最后几个值,并且不包括要预测的值在平均值中,这将是一个无效的问题框架,因为输入将包含被预测的未来信息。
例如,当窗口大小为 3 时,我们必须将序列向前移动 2 个时间步。这是因为我们希望将前两个观测值以及当前观测值包含在移动平均中,以便预测下一个值。然后,我们可以从这个移位序列中计算移动平均。
下面是前 5 个移动平均值计算示例。请记住,数据集向前移位了 2 个时间步,并且随着我们沿着时间序列移动,至少需要 3 个时间步才能有足够的数据来计算窗口为 3 的移动平均值。
|
1 2 3 4 5 6 |
观测值,平均值 NaN NaN NaN, NaN NaN NaN, NaN, 35 NaN NaN, 35, 32 NaN 30, 32, 35 32 |
下面是将前 3 个值的移动平均作为新特征的示例,以及作为每日女性出生数据集的滞后 1 输入特征。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat series = read_csv('daily-total-female-births.csv', header=0, index_col=0) df = DataFrame(series.values) width = 3 lag1 = df.shift(1) lag3 = df.shift(width - 1) window = lag3.rolling(window=width) means = window.mean() dataframe = concat([means, lag1, df], axis=1) dataframe.columns = ['mean', 't-1', 't+1'] print(dataframe.head(10)) |
运行示例会创建新数据集并打印前 10 行。
我们可以看到前 3 行不能使用,必须丢弃。lag1 数据集的第一行不能使用,因为没有先前的观测值来预测第一行,因此使用了 NaN 值。
|
1 2 3 4 5 6 7 8 9 10 11 |
mean t-1 t+1 0 NaN NaN 35 1 NaN 35.0 32 2 NaN 32.0 30 3 NaN 30.0 31 4 32.333333 31.0 44 5 31.000000 44.0 29 6 35.000000 29.0 45 7 34.666667 45.0 43 8 39.333333 43.0 38 9 39.000000 38.0 27 |
下一部分将介绍如何使用移动平均作为朴素模型进行预测。
移动平均作为预测
移动平均值也可以直接用于进行预测。
它是一种朴素模型,假设时间序列的趋势和季节性成分已被移除或调整。
用于预测的移动平均模型可以很容易地以向前行走的方式使用。随着新观测值的可用(例如,每天),模型可以更新并为第二天做出预测。
我们可以在 Python 中手动实现它。下面是移动平均模型以向前行走方式使用的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from pandas import read_csv from numpy import mean from sklearn.metrics import mean_squared_error from matplotlib import pyplot series = read_csv('daily-total-female-births.csv', header=0, index_col=0) # 准备情况 X = series.values window = 3 history = [X[i] for i in range(window)] test = [X[i] for i in range(window, len(X))] predictions = list() # 遍历测试集中的时间步 for t in range(len(test)): length = len(history) yhat = mean([history[i] for i in range(length-window,length)]) obs = test[t] predictions.append(yhat) history.append(obs) print('predicted=%f, expected=%f' % (yhat, obs)) error = mean_squared_error(test, predictions) print('Test MSE: %.3f' % error) # 绘图 pyplot.plot(test) pyplot.plot(predictions, color='red') pyplot.show() # 缩放图 pyplot.plot(test[0:100]) pyplot.plot(predictions[0:100], color='red') pyplot.show() |
运行示例将打印预测值和实际值,每次向前移动一个时间步,从时间步 4 (1959-01-04) 开始。
最后,报告了所有预测的均方误差 (MSE)。
|
1 2 3 4 5 6 7 8 9 10 11 |
predicted=32.333333, expected=31.000000 predicted=31.000000, expected=44.000000 predicted=35.000000, expected=29.000000 predicted=34.666667, expected=45.000000 predicted=39.333333, expected=43.000000 ... predicted=38.333333, expected=52.000000 predicted=41.000000, expected=48.000000 predicted=45.666667, expected=55.000000 predicted=51.666667, expected=50.000000 Test MSE: 61.379 |
示例最后绘制了实际测试值(蓝色)与预测值(红色)。
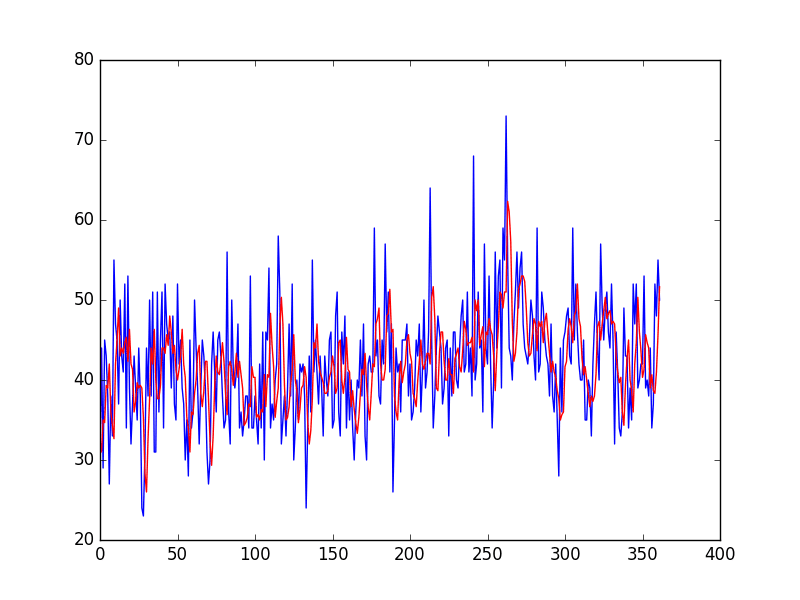
移动平均预测
同样,放大前 100 个预测值可以了解 3 天移动平均预测的准确性。
请注意,窗口宽度 3 是任意选择的,并未优化。
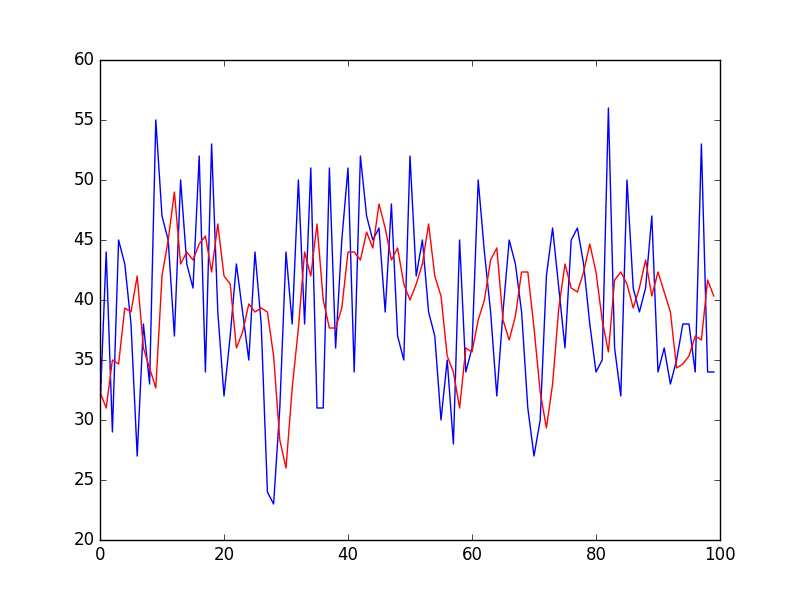
缩放移动平均预测
进一步阅读
本节列出了一些关于时间序列分析和时间序列预测的平滑移动平均的资源,您可能会发现它们很有用。
- 第 4 章,平滑方法,R 时间序列预测实用指南。
- 第 1.5.4 节平滑,R 入门时间序列。
- 时间序列上下文中的第 2.4 节平滑,时间序列分析及其应用:R 示例。
总结
在本教程中,您了解了如何使用移动平均平滑进行时间序列预测,并使用 Python。
具体来说,你学到了:
- 移动平均平滑的工作原理以及在使用它之前对时间序列数据的期望。
- 如何在 Python 中使用移动平均平滑进行数据准备。
- 如何在 Python 中使用移动平均平滑进行特征工程。
- 如何在 Python 中使用移动平均平滑进行预测。
您对移动平均平滑或本教程有任何疑问吗?
在下面的评论中提出你的问题,我会尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






你好,
感谢您的所有文章和书籍,它们非常棒。
在这里,我有一件事不确定。
shift(width - 1)是正确的吗?在这段代码中width = 3
lag1 = df.shift(1)
lag3 = df.shift(width – 1)
我认为它应该总是
shift(2),无论宽度是多少,因为我们进行移位是为了跳过一个当前值(因此它不包含在窗口中)。例如,对于输入序列 df=[1,2,3,4,5,6,7] 和 width=4,会有
shift(3),结果是t t+1 shift(3) mean
– 1 – –
1 2 – –
2 3 – –
3 4 1 –
4 5 2 –
5 6 3 –
6 7 4 2,5
但平均值 2.5 应该属于 t=5,而不是 t=6,对吗?
当然,也许我只是没有正确理解。
Petr,听起来有道理。
如果数据集不是连续序列,这意味着某些日期的观测值丢失了,该怎么办?在这种情况下,rolling 函数能否识别不连续的序列并相应地创建平均值?
这篇帖子提供了一些想法。
https://machinelearning.org.cn/handle-missing-timesteps-sequence-prediction-problems-python/
令我惊讶的是,您没有 pd.rolling_apply,因为有些人可能想要滚动标准差或时间域统计。“用于多功能肌电控制的稳健、实时控制方案”
好建议,谢谢!
我想接续 Petr 的评论,并说我认为我们想要的是从这个
lag1 = df.shift(1)
至此
lag1 = df.shift(window – 2)
我也同意他的观点,您的教程很棒。
谢谢 Matt。
很棒的文章。我正在尝试将其用于节点的 CPU 利用率。我想找出使用率何时保持在 90% 或更高。我该如何实现?您能提供一些提示吗?
不知道,抱歉。
很棒的文章……
if ynew == 2
print (“识别出移动”)
else
print (“稳定状态”)
time.sleep(0.5)
在这种情况下,我如何对 (ynew== 2) 进行移动平均?
抱歉,我没明白,您到底是什么意思?
在计算移动平均时,为什么我们需要移动数据?我的意思是,滚动窗口将始终基于当前和过去的值,而不是未来的值。所以,即使不移动数据,我们也能得到有效的结果吗?在上面的例子中,我们可以在特征工程部分从索引2开始得到有效的均值。
我是否错过了什么?
移动数据是为了将序列转化为监督学习问题
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
说到时间移动,我认为你可以帮助我当前关于使用广义线性模型进行时间序列预测的工作。我使用GLM方法的原因是我考虑了温度(T(t)、T(t-1)、…)、降雨(R(t)、R(t-1)、…)、湿度(H(t)、H(t-1)、…)和过去的事件(Y(t-1)、…)作为当前事件(Y(t))的解释变量。假设对于滞后1,Y(t)~T(t)+R(t)+H(t)+Y(t-1)+T(t-1)+R(t-1)+H(t-1)。通过比较图表,我可以看到我在时间t的预测与时间t-1的实际观测值越来越相似。我说这就像移动(延迟)了一个时间步长。我不知道为什么会发生这种情况。我认为这与“时间序列”作为随机游走过程有关。你能解释一下为什么吗?提前谢谢您,Jason。我是学生,所以我真的很感谢您的帮助。
这可能表明您的模型已经学会了持续性预测
https://machinelearning.org.cn/faq/single-faq/why-is-my-forecasted-time-series-right-behind-the-actual-time-series
嘿,您如何确定时间序列数据中的窗口大小?在这方面是否有我可以参考的出版物?
经验评估。
测试一系列窗口大小,看看哪种最适合您特定的数据集。
教授您好,感谢您在这里分享的宝贵知识。对于将移动平均作为LSTM模型的特征之一,我是否还需要去除趋势或季节性?
这是否有效?
MA30 = data[‘close’].rolling(30).mean().
我认为这应该适用于移动平均,也适用于方差。
假设已经有一个包含收盘价作为列的数据集。
谢谢你
是的,最好先使序列平稳。
以上文章有1个疑问。请回复。
> 中心移动平均可以作为一种通用方法来去除时间序列的趋势和季节性成分,而这在我们进行预测时通常无法使用。
> 这是一个朴素模型(用于预测),并假设时间序列的趋势和季节性成分已被去除或调整。
1) 为什么要在预测之前去除趋势和季节性成分?
2) 如果在预测之前必须去除季节性,那么为什么不能使用中心移动平均?根据上述文章,中心移动平均会去除季节性!
去除趋势和季节性可以使序列平稳,更容易建模
https://machinelearning.org.cn/time-series-data-stationary-python/
移动平均可能无法去除季节性。
感谢您的文章,它非常启发人
数据准备中的移动平均平滑很有趣。
假设之后,将使用某种算法进行预测。
平滑是应用于整个原始数据还是仅应用于训练数据集?
所有输入到模型的数据,包括训练数据以及任何新输入的数据。
当我每60秒平均一次数据集时,它就变成了每分钟一个数据集。当一些重要信息隐藏在秒级别,但在每分钟平均后消失了,我如何利用秒级别的信息来改进每分钟的预测?谢谢
它可以平滑掉“秒”级别的方差。这可能有效,也可能无效——这取决于您的数据和模型选择。
Jason您好,非常棒的时间序列入门教程。不过这次我不太理解时间序列移动进行特征工程的逻辑。如果想在时间t利用所有数据来预测并与时间t+1的实际值进行比较,那么我应该期望,如果我们将窗口大小固定为n,每当时间t有相同数量的可用行时,我们就可以创建一个平均值并用它来预测。这意味着我只需要将lag_mean移动1位,而.rolling函数会自行处理,直到有n个测量值在时间t时填充NaN,然后我们就可以计算它们的平均值。
我是否遗漏了什么显而易见的?
为了构建摘要输入特征,我们可能需要删除一些观测值。
不确定我是否理解您遇到的问题,抱歉。
我想要R语言的代码
抱歉,我没有此教程的R语言示例。
亲爱的 Jason,
感谢您的出色帖子。
如果我在使用MLP模型进行滞后预测之前使用MA进行平滑,我是否需要在计算MSE并将其预测值与平滑前的原始值进行比较之前,先反转我的平滑?
例如,就像我们在转换数据然后计算MSE之前反转转换一样?
如果是这样,如何反转平滑MA?
我非常感谢您的回复和意见
是的,应用于目标变量的任何转换都必须在评估或使用模型的预测之前进行反转。
移动平均是不可逆的。如果您希望仅作为输入操作移动平均,作为补充输入,或者您希望使用数据的平滑版本进行操作,那么可以使用它。
谢谢你,Jason。
我一直在为间歇性需求数据集(许多时期需求为0,然后突然出现需求高峰)处理时间序列场景。使用LSTM模型对移动平均转换的平滑数据进行处理很有帮助。
我可以使用以下方法在预测后反转拖尾移动平均转换,使用原始数据集:
原始未转换值 = (窗口大小 * 预测的拖尾移动平均值) – (窗口中所有其他未转换值之和)
我使用了平均公式:average = sum(values)/n,其中value(s) = average * n;
来自先前时间步长的所有其他值之和将不包括正在进行未转换计算的原始值。我通过使用数据集中的原始移动平均值(而不是预测值)进行了测试,以查看该方法是否真正返回了原始值。
使用拖尾移动平均转换作为特征工程步骤,确实显著改善了我对稀疏/间歇性需求数据集的预测。
您好 Ola…感谢您的反馈!如果您有任何需要我们解答的问题,请告知。
嗨,Jason博士,
我猜您所说的“仅作为输入”是指当您希望在训练集上使用目标变量的平滑版本,然后对实际测试目标变量进行预测,对吗?当然,您选择的方法将取决于您的应用和问题框架。在某些应用中,我们称之为“噪声”的东西是至关重要的。其他您可以应用MA或滚动平均的实例是当您希望在平滑版本上估计您的响应变量,或者将它们作为补充或新的预测变量使用,就像您刚才提到的那样,对吗?
谢谢你的回复。
Jason,只有当我在数据准备中包含MA数据平滑时,我的MLP模型才能给出较低(足够好)的MSE。
但是,我担心这不再代表我的实际数据。
这是正确的,您将选择对问题的一个不同版本或框架进行建模。
从一个对您的项目/问题的明确定义开始,然后考虑问题的新框架是否能够解决它。
MAPE怎么样?
MAPE怎么样?
你好Jason。谢谢你的好帖子。
我正在使用您的代码计算滑动窗口的平均值作为特征工程。现在我也想用滑动窗口计算方差和标准差。你能指导我如何做吗?谢谢
df = DataFrame(series.values)
width = 3
lag1 = df.shift(1)
lag3 = df.shift(width – 1)
window = lag3.rolling(window=width)
means = window.mean()
dataframe = concat([means, lag1, df], axis=1)
dataframe.columns = [‘mean’, ‘t-1’, ‘t+1’]
print(dataframe.head(10))
不客气。
也许您可以直接参考上面教程中的示例?
亲爱的 Jason,
感谢您的出色帖子。
我可以在使数据平稳之前使用移动平均作为数据准备吗?
谢谢你。
当然可以。
您好,我尝试使用15天的移动平均,包括前15天的数据,并预测第二天的值。
听起来不错!
关于使用MA进行预测,我有一个问题。
如何对测试(样本外数据)进行预测,比如12个月的样本外数据,使用训练数据(比如测试数据之前的24个月)?
我不能使用测试数据来创建MA并预测测试数据。我只能使用训练数据。那么我该如何使用MA进行预测呢?
请告诉我。
这听起来您没有足够的数据。
也许可以在前12个观测值上拟合模型,然后预测接下来的12个观测值。
嗨,Jason,
我已阅读您的示例,以及其他示例。如何才能实际获得带有实际输入的预测值?例如,我想从最后当前数据预测未来30天。
首先,在所有可用数据上拟合模型,然后调用model.predict或model.forest,并指定要预测的时间步长或日期/索引范围,请参见此
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
你好 Jason,
很棒的文章。我定期阅读您的电子邮件。看起来R语言有一种非常简洁的方法来计算移动平均的滚动移动平均。Python中是否有这样的方法,以及如何实现它?感谢您的评论
上面教程中描述的方法是有的,可能还有其他方法。我不确定是否有与您在R中所描述的方法相等的Python方法。
Jason您好,感谢您这篇精彩的文章。我有一个问题:您是否有关于如何使用移动平均滤波器估计季节性的帖子?我正在阅读《时间序列与预测导论》这本书,作者在书中用数学方法解释了如何使用移动平均滤波器来处理季节性。然而,理解正在发生的事情有点复杂。
不客气。
也许SARIMA会有帮助
https://machinelearning.org.cn/sarima-for-time-series-forecasting-in-python/
以及
https://machinelearning.org.cn/how-to-grid-search-sarima-model-hyperparameters-for-time-series-forecasting-in-python/
嗨,Jason,
感谢信息丰富的帖子!!!我有一个关于不同数据集的问题。这是具有年度季节性模式的商店销售数据。在去季节化后,如果使用滚动窗口平均值进行预测,如何决定窗口大小?
谢谢
也许可以评估不同的窗口大小,然后使用最适合您的数据和模型的。
感谢您信息丰富的帖子。
我有两个问题。
1. 我如何将此方法用于多步预测?我应该基于我的预测继续预测下一个时间步长,而我的预测显然包含一些错误吗?
2. 使用SMA进行预处理(去除趋势和/或季节性)以及用于预测是否合乎逻辑?
提前感谢您的回复
您可以将该方法外推到数据集之外作为一种预测,也许您可以为此目的改编上述代码。
也许可以尝试一下,然后与使用原始数据集进行比较。
‘中心移动平均可以作为一种通用方法来去除时间序列的趋势和季节性成分,而这在我们进行预测时通常无法使用。’
我不明白它如何有助于去除趋势和季节性成分。平均值不是也会受到趋势和季节性的影响吗?
提前感谢,
您好 Mourad…您可能会发现以下内容很有趣。
https://machinelearning.org.cn/remove-trends-seasonality-difference-transform-python/
Jason您好,一如既往的精彩文章。
我想知道当每个时间点有多个测量值时,如何进行时间序列平滑。例如,假设您每天测量女性出生人数,但在4个不同的城市。如何聚合数据进行平滑?也许分别对每个城市进行平滑,然后取城市间的平均信号?似乎对城市进行每时间点平均然后进行平滑是不恰当的,并且可能会“过度平滑”数据,如果这是可能的话。
嗨,Jason,
感谢您在平台上提供的技术知识。
我使用滚动窗口作为数据准备过程,将训练数据和测试数据的噪声分开去除。预测结果看起来很好,但我注意到测试预测值与实际值存在偏移。您认为这可以接受吗?我希望我能在此处粘贴图表。
您好 Jamiu…以下讨论可能会有所帮助
https://stats.stackexchange.com/questions/330928/time-series-prediction-shifted
感谢您信息丰富的帖子。
为什么将移动平均平滑称为“朴素”?
您好 Achraf…不客气!朴素意味着假设一个类别中所有输入特征之间的关系都是独立的。