不平衡分类是指示例在类别标签上的分布不均等的预测任务。
大多数不平衡分类示例都集中在二元分类任务上,但许多用于不平衡分类的工具和技术也直接支持多类别分类问题。
在本教程中,您将学习如何将不平衡分类工具应用于多类别数据集。
完成本教程后,您将了解:
- 关于玻璃识别标准不平衡多类别预测问题。
- 如何使用SMOTE过采样进行不平衡多类别分类。
- 如何使用成本敏感学习进行不平衡多类别分类。
通过我的新书《使用Python进行不平衡分类》**启动您的项目**,其中包括**分步教程**和所有示例的**Python源代码**文件。
让我们开始吧。
- 2021 年 1 月更新:更新了 API 文档链接。

多类别不平衡分类
图片由istolethetv提供,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 玻璃多类别分类数据集
- SMOTE多类别分类过采样
- 多类别分类的成本敏感学习
玻璃多类别分类数据集
在本教程中,我们将重点关注一个标准的不平衡多类别分类问题,称为“**玻璃识别**”或简称“*玻璃*”。
该数据集描述了玻璃的化学性质,涉及使用其化学性质将玻璃样本分类为六个类别之一。该数据集于1987年由Vina Spiehler提供。
忽略样本识别号,有九个输入变量总结了玻璃数据集的属性;它们是
- RI:折射率
- Na:钠
- Mg:镁
- Al:铝
- Si:硅
- K:钾
- Ca:钙
- Ba:钡
- Fe:铁
化学成分以相应氧化物的重量百分比测量。
列出了七种类型的玻璃;它们是
- 类别1:建筑窗户(浮法工艺)
- 类别2:建筑窗户(非浮法工艺)
- 类别3:车辆窗户(浮法工艺)
- 类别4:车辆窗户(非浮法工艺)
- 类别5:容器
- 类别6:餐具
- 类别7:车头灯
浮法玻璃指用于制造玻璃的工艺。
数据集中有214个观测值,每个类别中的观测值数量不平衡。请注意,数据集中没有类别4(非浮法工艺车辆窗户)的示例。
- 类别1:70个示例
- 类别2:76个示例
- 类别3:17个示例
- 类别4:0个示例
- 类别5:13个示例
- 类别6:9个示例
- 类别7:29个示例
尽管存在少数类别,但在此预测问题中所有类别都同样重要。
该数据集可分为窗玻璃(类别1-4)和非窗玻璃(类别5-7)。窗玻璃有163个示例,非窗玻璃有51个示例。
- 窗玻璃:163个示例
- 非窗玻璃:51个示例
另一种观测值划分是在窗玻璃中,浮法玻璃和非浮法玻璃之间。这种划分更为平衡。
- 浮法玻璃:87个示例
- 非浮法玻璃:76个示例
你可以在此处了解更多关于此数据集的信息:
无需下载数据集;我们将在工作示例中自动下载它。
以下是数据前几行的示例。
|
1 2 3 4 5 6 |
1.52101,13.64,4.49,1.10,71.78,0.06,8.75,0.00,0.00,1 1.51761,13.89,3.60,1.36,72.73,0.48,7.83,0.00,0.00,1 1.51618,13.53,3.55,1.54,72.99,0.39,7.78,0.00,0.00,1 1.51766,13.21,3.69,1.29,72.61,0.57,8.22,0.00,0.00,1 1.51742,13.27,3.62,1.24,73.08,0.55,8.07,0.00,0.00,1 ... |
我们可以看到所有输入都是数值,最后一列中的目标变量是整数编码的类别标签。
您可以在本教程中了解如何将此数据集作为项目的一部分进行处理。
现在我们熟悉了玻璃多类别分类数据集,接下来让我们探讨如何使用标准不平衡分类工具。
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
SMOTE多类别分类过采样
过采样是指复制或合成少数类别的新示例,使得少数类别中的示例数量更好地类似于或匹配多数类别中的示例数量。
也许最广泛使用的合成新示例的方法称为合成少数类别过采样技术(Synthetic Minority Oversampling TEchnique),简称SMOTE。该技术由Nitesh Chawla等人于2002年在他们题为“SMOTE: Synthetic Minority Over-sampling Technique”的论文中描述。
您可以在本教程中了解更多关于SMOTE的信息。
imbalanced-learn库提供了SMOTE的实现,我们可以使用它,并且它与流行的scikit-learn库兼容。
首先,必须安装该库。我们可以使用pip进行安装,如下所示
sudo pip install imbalanced-learn
我们可以通过打印已安装库的版本来确认安装成功
|
1 2 3 |
# 检查版本号 import imblearn print(imblearn.__version__) |
运行示例将打印已安装库的版本号;例如
|
1 |
0.6.2 |
在应用SMOTE之前,让我们首先加载数据集并确认每个类别中的示例数量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 加载并汇总数据集 from pandas import read_csv from collections import Counter from matplotlib import pyplot 从 sklearn.preprocessing 导入 LabelEncoder # 定义数据集位置 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/glass.csv' # 将csv文件加载为数据框 df = read_csv(url, header=None) data = df.values # 分割输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码 y = LabelEncoder().fit_transform(y) # 汇总分布 counter = Counter(y) for k,v in counter.items(): per = v / len(y) * 100 print('Class=%d, n=%d (%.3f%%)' % (k, v, per)) # 绘制分布图 pyplot.bar(counter.keys(), counter.values()) pyplot.show() |
运行示例首先下载数据集并将其拆分为训练集和测试集。
然后报告每个类别中的行数,确认某些类别(如0和1)比其他类别(如3和4)有更多的示例(超过70个),而后者少于15个。
|
1 2 3 4 5 6 |
类别=0,n=70 (32.710%) 类别=1,n=76 (35.514%) 类别=2,n=17 (7.944%) 类别=3,n=13 (6.075%) 类别=4,n=9 (4.206%) 类别=5,n=29 (13.551%) |
创建了一个条形图,可视化了数据集的类别细分。
这更清楚地表明,类别0和1比类别2、3、4和5有更多的示例。
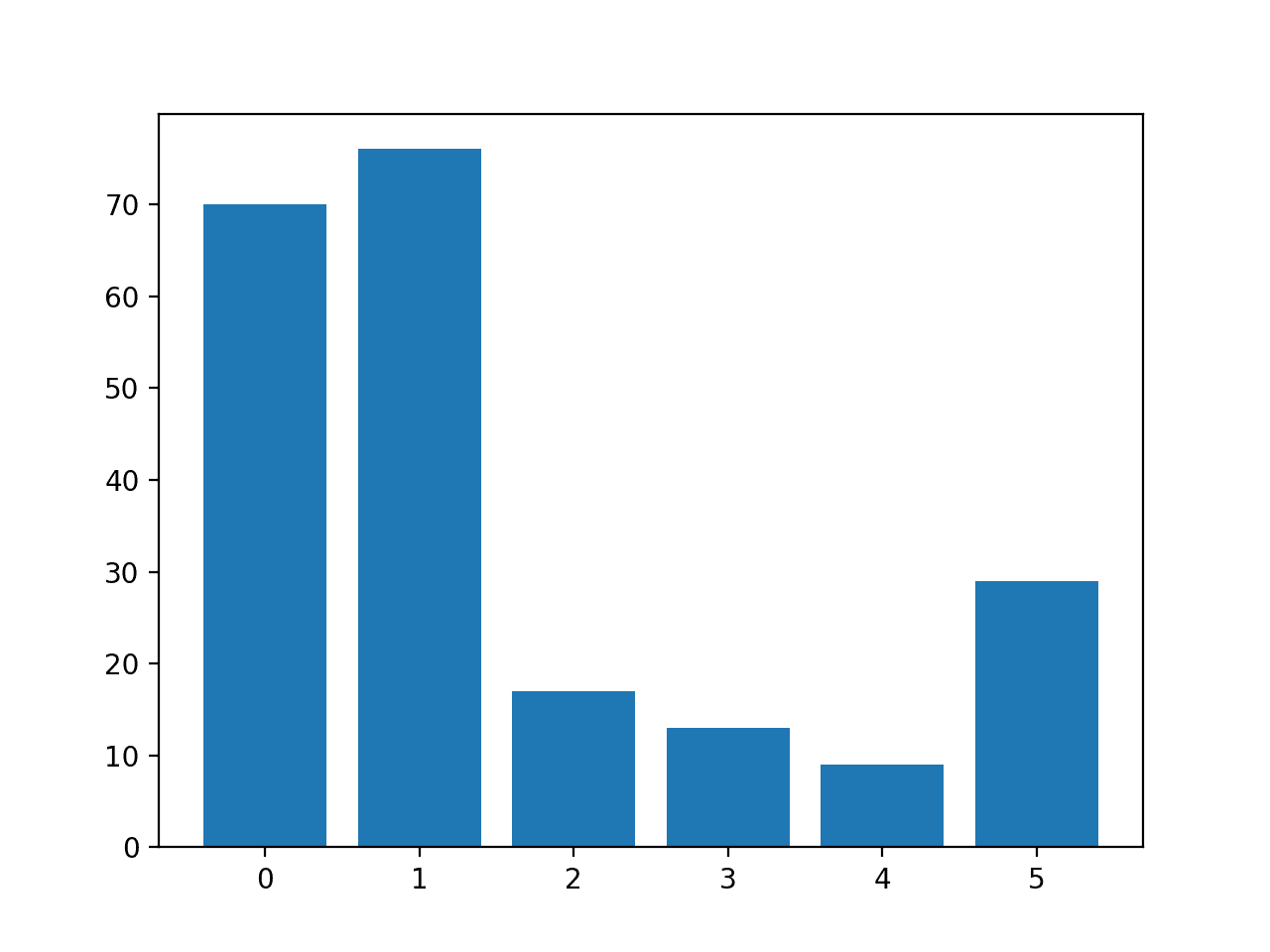
玻璃多类别分类数据集中每个类别的示例直方图
接下来,我们可以应用SMOTE对数据集进行过采样。
默认情况下,SMOTE会将所有类别过采样到与包含最多示例的类别相同的示例数量。
在这种情况下,类别1拥有最多的示例,为76个,因此SMOTE会将所有类别过采样到拥有76个示例。
下面列出了使用SMOTE对玻璃数据集进行过采样的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 对多类别分类数据集进行过采样的示例 from pandas import read_csv from imblearn.over_sampling import SMOTE from collections import Counter from matplotlib import pyplot 从 sklearn.preprocessing 导入 LabelEncoder # 定义数据集位置 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/glass.csv' # 将csv文件加载为数据框 df = read_csv(url, header=None) data = df.values # 分割输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码 y = LabelEncoder().fit_transform(y) # 转换数据集 oversample = SMOTE() X, y = oversample.fit_resample(X, y) # 汇总分布 counter = Counter(y) for k,v in counter.items(): per = v / len(y) * 100 print('Class=%d, n=%d (%.3f%%)' % (k, v, per)) # 绘制分布图 pyplot.bar(counter.keys(), counter.values()) pyplot.show() |
运行示例首先加载数据集并对其应用SMOTE。
然后报告每个类别中示例的分布,确认每个类别现在都有76个示例,正如我们所预期的。
|
1 2 3 4 5 6 |
类别=0,n=76 (16.667%) 类别=1,n=76 (16.667%) 类别=2,n=76 (16.667%) 类别=3,n=76 (16.667%) 类别=4,n=76 (16.667%) 类别=5,n=76 (16.667%) |
还创建了一个类别分布的条形图,提供了所有类别现在具有相同示例数量的强烈视觉指示。
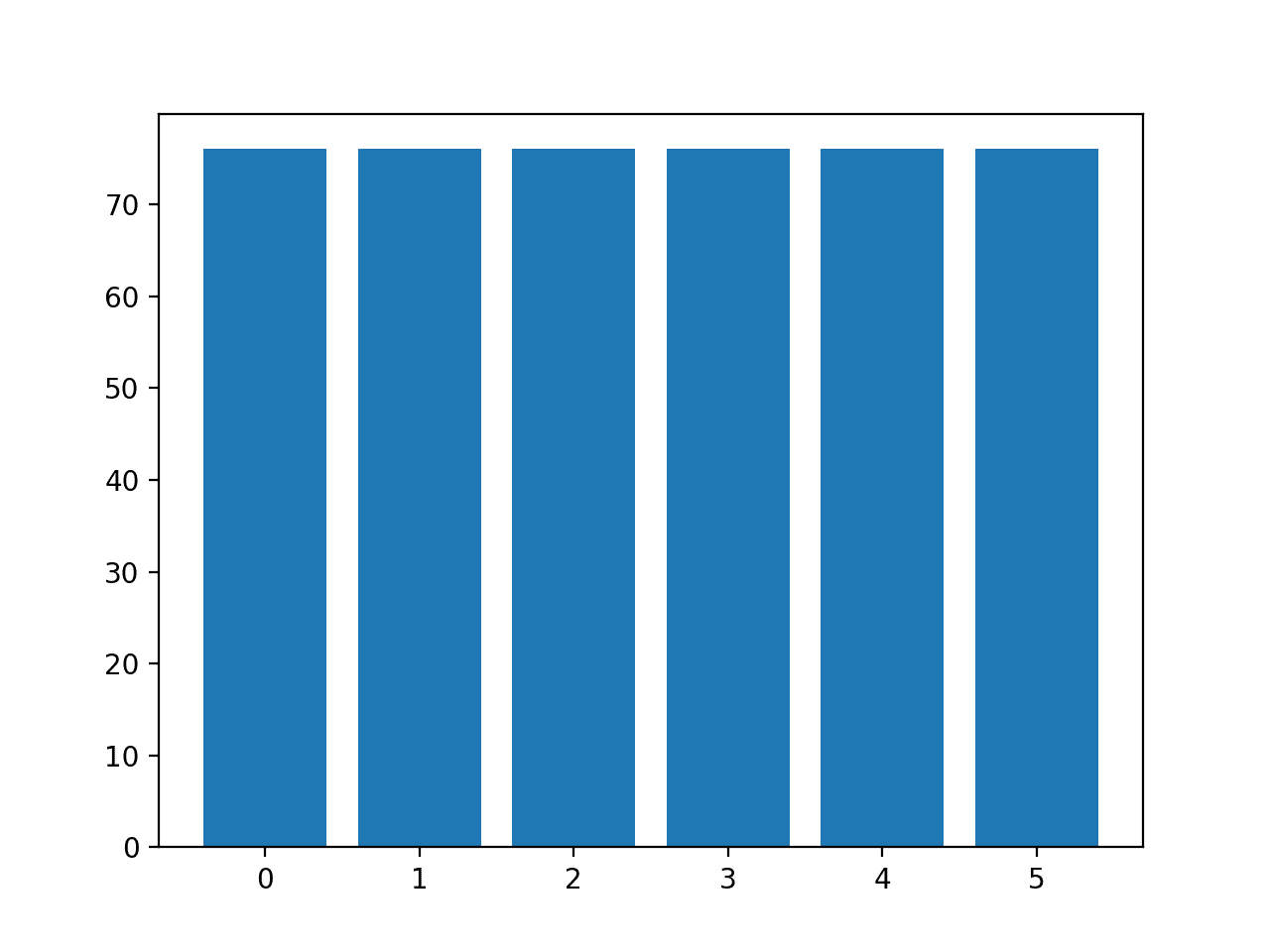
默认SMOTE过采样后玻璃多类别分类数据集中每个类别的示例直方图
我们可以不使用SMOTE的默认策略将所有类别过采样到多数类别中的示例数量,而是指定每个类别中要过采样的示例数量。
例如,我们可以在类别0和1中过采样到100个示例,在其余类别中过采样到200个示例。这可以通过创建一个将类别标签映射到每个类别中所需示例数量的字典来实现,然后通过SMOTE类的“*sampling_strategy*”参数指定此字典。
|
1 2 3 4 5 |
... # 转换数据集 strategy = {0:100, 1:100, 2:200, 3:200, 4:200, 5:200} oversample = SMOTE(sampling_strategy=strategy) X, y = oversample.fit_resample(X, y) |
综合起来,下面列出了使用自定义过采样策略进行SMOTE的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 使用自定义策略对多类别分类数据集进行过采样的示例 from pandas import read_csv from imblearn.over_sampling import SMOTE from collections import Counter from matplotlib import pyplot 从 sklearn.preprocessing 导入 LabelEncoder # 定义数据集位置 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/glass.csv' # 将csv文件加载为数据框 df = read_csv(url, header=None) data = df.values # 分割输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码 y = LabelEncoder().fit_transform(y) # 转换数据集 strategy = {0:100, 1:100, 2:200, 3:200, 4:200, 5:200} oversample = SMOTE(sampling_strategy=strategy) X, y = oversample.fit_resample(X, y) # 汇总分布 counter = Counter(y) for k,v in counter.items(): per = v / len(y) * 100 print('Class=%d, n=%d (%.3f%%)' % (k, v, per)) # 绘制分布图 pyplot.bar(counter.keys(), counter.values()) pyplot.show() |
运行示例会创建所需的采样并总结其对数据集的影响,从而确认预期的结果。
|
1 2 3 4 5 6 |
类别=0,n=100 (10.000%) 类别=1,n=100 (10.000%) 类别=2,n=200 (20.000%) 类别=3,n=200 (20.000%) 类别=4,n=200 (20.000%) 类别=5,n=200 (20.000%) |
注意:您可能会看到一些警告,为了本例的目的可以安全地忽略它们,例如
|
1 |
UserWarning: 过采样后,类别5中的样本数量(200)将大于多数类别(类别#1 -> 76)中的样本数量 |
还创建了一个类别分布的条形图,确认了数据采样后指定的类别分布。
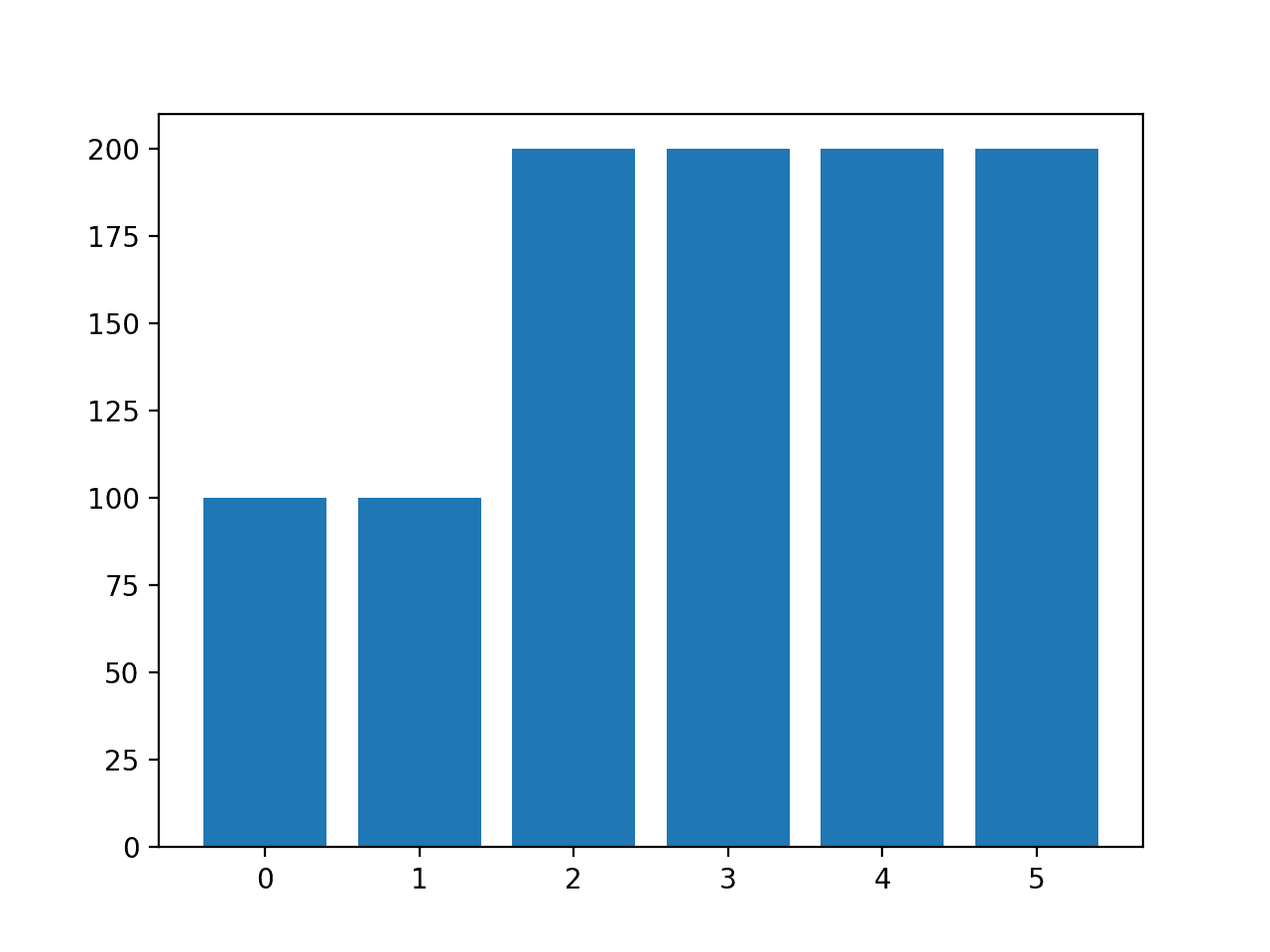
自定义SMOTE过采样后玻璃多类别分类数据集中每个类别的示例直方图
**注意**:当使用SMOTE等数据采样时,它必须只应用于训练数据集,而不是整个数据集。我建议使用管道(Pipeline)来确保在评估模型和使用模型进行预测时正确使用SMOTE方法。
您可以在本教程中看到在管道中正确使用SMOTE的示例
多类别分类的成本敏感学习
大多数机器学习算法假设所有类别都具有相同数量的示例。
在多类别不平衡分类中并非如此。算法可以进行修改,以改变学习的执行方式,从而偏向于训练数据集中示例较少的类别。这通常被称为成本敏感学习。
有关成本敏感学习的更多信息,请参阅本教程
scikit-learn中的RandomForestClassifier类通过“class_weight”参数支持成本敏感学习。
默认情况下,随机森林类为每个类别分配相等的权重。
我们可以评估默认随机森林类别权重在玻璃不平衡多类别分类数据集上的分类精度。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# 玻璃识别数据集的基线模型和测试工具 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 data = read_csv(full_path, header=None) # 检索numpy数组 data = data.values # 分割为输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码,使其具有类别0和1 y = LabelEncoder().fit_transform(y) 返回 X, y # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集位置 full_path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/glass.csv' # 加载数据集 X, y = load_dataset(full_path) # 定义参考模型 model = RandomForestClassifier(n_estimators=1000) # 评估模型 scores = evaluate_model(X, y, model) # 总结性能 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行示例评估了默认随机森林算法(包含1,000棵树)在玻璃数据集上的性能,使用了重复分层k折交叉验证。
运行结束时报告了平均和标准差分类精度。
**注意**:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到默认模型实现了大约79.6%的分类精度。
|
1 |
平均精度:0.796 (0.047) |
我们可以将“*class_weight*”参数指定为“*balanced*”值,这将自动计算一个类别权重,确保在模型训练期间每个类别获得相等的权重。
|
1 2 3 |
... # 定义模型 model = RandomForestClassifier(n_estimators=1000, class_weight='balanced') |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# 具有默认类别权重的成本敏感随机森林 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 data = read_csv(full_path, header=None) # 检索numpy数组 data = data.values # 分割为输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码 y = LabelEncoder().fit_transform(y) 返回 X, y # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集位置 full_path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/glass.csv' # 加载数据集 X, y = load_dataset(full_path) # 定义模型 model = RandomForestClassifier(n_estimators=1000, class_weight='balanced') # 评估模型 scores = evaluate_model(X, y, model) # 总结性能 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行示例报告了成本敏感版随机森林在玻璃数据集上的平均和标准差分类精度。
**注意**:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到默认模型在分类精度上比非成本敏感版算法有所提升,从79.6%提高到80.2%。
|
1 |
平均精度:0.802 (0.044) |
“*class_weight*”参数接受一个字典,该字典将类别标签映射到类别权重值。
我们可以使用它来指定自定义权重,例如,对于具有许多示例的类别0和1.0使用默认权重,而对于其他类别使用双倍类别权重2.0。
|
1 2 3 4 |
... # 定义模型 weights = {0:1.0, 1:1.0, 2:2.0, 3:2.0, 4:2.0, 5:2.0} model = RandomForestClassifier(n_estimators=1000, class_weight=weights) |
综合起来,下面列出了在玻璃多类别不平衡分类问题上使用自定义类别权重进行成本敏感学习的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 具有自定义类别权重的成本敏感随机森林 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier # 加载数据集 def load_dataset(full_path): # 将数据集加载为numpy数组 data = read_csv(full_path, header=None) # 检索numpy数组 data = data.values # 分割为输入和输出元素 X, y = data[:, :-1], data[:, -1] # 对目标变量进行标签编码 y = LabelEncoder().fit_transform(y) 返回 X, y # 评估模型 def evaluate_model(X, y, model): # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集位置 full_path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/glass.csv' # 加载数据集 X, y = load_dataset(full_path) # 定义模型 weights = {0:1.0, 1:1.0, 2:2.0, 3:2.0, 4:2.0, 5:2.0} model = RandomForestClassifier(n_estimators=1000, class_weight=weights) # 评估模型 scores = evaluate_model(X, y, model) # 总结性能 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行示例报告了成本敏感版随机森林在玻璃数据集上使用自定义权重的平均和标准差分类精度。
**注意**:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到,通过更偏向的类别权重,精度从平衡类别权重的约80.2%进一步提升到80.8%。
|
1 |
平均精度:0.808 (0.059) |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
相关教程
API
总结
在本教程中,您学习了如何将不平衡分类工具应用于多类别数据集。
具体来说,你学到了:
- 关于玻璃识别标准不平衡多类别预测问题。
- 如何使用SMOTE过采样进行不平衡多类别分类。
- 如何使用成本敏感学习进行不平衡多类别分类。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...






您好Jason,感谢这篇精彩的文章。我的问题是,作为经验法则,过采样应该做到什么程度?我有一个包含6个类别的数据集,示例数量如下(大约):[10000, 1000, 12000, 8000, 400, 6000]。那么,将包含400和1000个示例的类别过采样到12000的水平是否可以?
我建议您尝试一下——就像任何方法一样,然后使用最适合您特定数据集的方法。
你好 Jason,
我在https://scikit-learn.cn/stable/tutorial/machine_learning_map/index.html(但仅适用于scikit learn)上找到了一张有用的地图。
您是否制作了一张有助于选择正确分类器/回归器的地图(或思维导图)?(或者您建议我在哪里可以找到它?)
谢谢,
Marco
这个可能会有帮助
https://machinelearning.org.cn/a-tour-of-machine-learning-algorithms/
您好 Jasonn,
我看到可以使用XGBoost进行时间序列分析。
XGBoost还可以应用于哪些领域(即XGBoost的典型应用是什么)?
时间序列是一种回归吗?
谢谢,
Marco
是的,时间序列可以被视为回归监督学习问题。
XGBoost可用于回归和分类,许多预测任务都可以简化为这些问题。
您好,非常感谢您精彩的教程。祝您一切顺利
谢谢!
早上好,先生!
希望您身体健康。先生,我在机器学习分类器训练和测试中遇到了一个问题,这个问题是由于数据集造成的。我使用UNSW-NB15数据集,这是一个攻击数据集。它有两个特征,一个是攻击类别,另一个是标签特征。现在我困惑的是如何将这两个特征作为标签类用于机器学习分类器。请您指导我,提前感谢。
也许可以从本教程开始,熟悉API和数据准备。
https://machinelearning.org.cn/machine-learning-in-python-step-by-step/
嗨,Jason,
是否可以将SMOTE应用于多目标问题?
也许吧。我不能马上确定。试试看吧。
您好 Jason,文章很有趣。我没有找到任何关于文本数据的提及。我假设这与任何形式的向量化数据一样有效,对吗?
您对此有任何经验吗?或者您会建议其他库或方法来处理不平衡的文本数据?
谢谢。
您可以从这里开始处理文本数据
https://machinelearning.org.cn/start-here/#nlp
嗨,Jason,
非常棒的文章!
根据您的经验,过采样和成本敏感学习哪个更好?
当然,过采样让您可以控制采样方法。但除此之外呢?
此外,
这取决于数据集,您必须通过受控实验发现哪种方法对您的数据集效果最好。
一如既往的精彩文章!
如果我正在建模文本意图(例如从16000个文本中提取50个意图标签),并且意图的频率不平衡,您能否建议是否有必要处理不平衡问题?如果我不处理不平衡问题会发生什么?
这确实取决于您项目的具体情况和项目目标。
也许可以尝试一些技术,看看它是否会对您所选指标的模型性能产生影响。
一如既往的精彩文章!
我们可以将其应用于ADAYSN吗?
<>
或许可以试试看?
这真的很有帮助!
谢谢!
你好 Jason,
希望你一切都好?
感谢您的这篇文章,它非常有帮助,而且简单明了。
实际上,我正在从事一个机器学习项目,特别是NLP项目,它涉及多类别不平衡数据,而且数据集很小。我有465个类别,但只有1050个示例,以及3列,这些列是几个单词的列表(不是结构化的句子或段落)。正如我所说,这非常小。您知道我如何解决这个问题吗?我如何将SMOTE方法应用于文本数据?您知道是否有API或库可以将外部语料库添加到我的语料库中?
请您给我一些文章或建议。
提前非常感谢
不,SMOTE不适合文本。
也许你可以探索使用生成模型来创建更多的文本数据,例如语言模型。
非常感谢 Jason。我尝试将所有小类别重新分组,并采用高频类别,这暂时给我带来了不错的准确性。
太棒了!
smote只应用于训练集,但本文中应用于x和y,这是否正确?
这只是一个演示,说明如何使用该类及其影响。
在评估模型时,请使用管道,请参见此示例。
https://machinelearning.org.cn/smote-oversampling-for-imbalanced-classification/
您好,Jason,我想知道在我的项目中如何计算成本矩阵或class_weight?
您认为我是否需要在XGBoost之前使用成本敏感学习和特征选择?我打算在XGBoost之前使用数据集平衡和特征选择。
期待您的回答。非常感谢
XGBoost在成本敏感学习中只支持两个类别,请参阅本教程中的示例。
https://machinelearning.org.cn/xgboost-for-imbalanced-classification/
是否有可能使用任何单一选项(如SMOTE)在单个代码库中同时处理二元和多类别问题?
例如,我们将提供数据集,算法将识别它是二元问题还是多类别问题,然后根据它们进行预测。
抱歉,我不太明白。每个数据集都是一个不同的“项目”。
您好,Jason,混淆矩阵有助于查看使用SMOTE平衡的数据与不平衡数据的比较吗?如果可以,我应该如何在SMOTE过采样之前应用混淆矩阵?
请注意,混淆矩阵显示您的模型输出与训练数据中真实情况的关系。因此,您不能这样做。您需要将数据应用于一个使用SMOTE训练的模型和一个不使用SMOTE训练的模型,然后您将得到两个混淆矩阵进行比较。
感谢您的回复!我如何获取两个混淆矩阵进行比较?您的帖子中有没有使用混淆矩阵的教程呢?:“您需要将数据应用于一个使用SMOTE训练的模型和一个不使用SMOTE训练的模型” 我很乐意自己尝试一下并比较两个混淆矩阵。
我认为这篇帖子包含您想要的示例代码:https://machinelearning.org.cn/confusion-matrix-machine-learning/
您好 Adrian,抱歉一直提问。我是否需要先拆分数据才能使用此数据集的混淆矩阵?
由于我是编码新手,我不确定如何将
“# 拆分为输入和输出元素
X, y = data[:, :-1], data[:, -1]”
这部分拆分为“confusion_matrix(y_true=y_test, y_pred=y_pred_single)”
如果你的“y”是整个数据,你需要把它分成训练集和测试集,例如在scikit-learn中寻找“train_test_split”函数。
您好 Adrian!再次感谢您的回复!Jason用于这篇文章的数据集(玻璃数据集)也能进行train_test_split拆分吗?
此致
是的,那个 train_test_split 函数非常灵活和强大。
您好@Jason Brownlee – 我有一个如下所示的数据集。
FeatureA Target
a,b,c,d xyz
FeatureA中包含多个以逗号分隔的分类值,我需要预测目标分类值。
我有几个问题
1. 如何绘制此数据的图表?
2. 解决不平衡问题的最佳方法是什么?
3. 如何绘制精度图,例如混淆矩阵(CM)、F1分数、精确率(Precision)和召回率(Recall)。
提前感谢。
(1)如果您使用分类值绘制分类值,我认为您只需计算a=value1到xyz=value1的计数,然后您将得到一个计数矩阵。
(2)您尝试过SMOTE吗?
(3)如果目标是二元的,我相信最常见的图是ROC。
非常感谢Adrian的快速回复。
1. a,b,c,d在单个特征中,而不是在不同的特征中。在这种情况下,我需要将它们分离为不同的特征吗?
2. 是的,我尝试了SMOTENC,它适用于分类和数值数据,但我的数据集中没有数值特征。对于过采样数据还有其他建议吗?
3. 我的目标仍然是分类,而不是二元的。
感谢您的建议。
(1)同样。您的特征中有4个不同的可能值,目标中有N个不同的类别,那么您将得到一个4xN的表格。
(2)如果您的输入中没有数值,SMOTE不适用。也许您可以只进行引导重采样:https://machinelearning.org.cn/a-gentle-introduction-to-the-bootstrap-method/
(3)您可以考虑使用平均F1分数作为评分函数。
@Adrian,
感谢您的建议。
我使用了SMOTEN并对不平衡类别进行了重采样,现在训练、测试和交叉验证的准确率很高(约99%),但是当我用未见过的数据进行测试时,模型大多数情况下无法预测。您能帮我找出我的模型训练有什么问题吗?
此致,
Ashok。
无法预测是指预测了相反的类别吗?我建议您重新检查您的模型以及您在训练中处理数据的方式。在大多数情况下,总是高达99%的准确率可能不是一个现实的结果。
在用SMOTE过采样平衡数据之前,不使用任何分类器有什么原因吗?
您能详细说明一下您认为分类器如何使用吗?
嗨,Jason,
这是一篇很棒的文章。
是否可以将SMOTE应用于计算机视觉系统?
因为当我尝试将SMOTE与图像一起使用并将我的图像数据集传递给fit_resample(X, y)函数时,它不起作用,出现一个错误,即“fit_resample函数发现数组维度为3。估计器期望<=2)”
如果fit_resample(X, y)接受3维数组,请告诉我如何操作?
SMOTE是关于一个向量空间模型的,其中一个数据点由一个坐标(x1,x2,…,xn)表示。如果您的计算机视觉系统能够识别这种格式的输入,我相信SMOTE也可以工作。但通常将2D像素(即图像)转换为1D向量效果不佳。
好的,现在清楚了。
非常感谢,先生。
您好,先生!我如何将SMOTE应用于我的数据集,其中包含4个类别(无(2552),缺血(227),两者都有(621),感染(2555))?
您好 Goe...请您具体说明您尝试完成什么任务,因为它与所提供的代码示例相关,以便我更好地帮助您。
实际上,我想将SMOTE应用于我的图像数据集,该数据集包含5955张图像,分为4个类别(2552、227、621、2555)。请问有人能帮我吗?我将不胜感激!
提前感谢您的帮助
您好 Goe...您尝试过模型实现吗?如果是,请提供任何错误消息或未预期的结果,以便我们更好地协助您。
为什么不使用随机分层抽样呢?
您好 Sruthi...这当然是一种选择。请随意实施并告知我们您的发现。
你好,
工作非常出色。一如既往,感谢您在文章中涵盖了如此多有用的主题。
我想问您以下问题:在我的数据集中,3类别多类别目标的类别比例为[1, 16, 83]。如果我尝试使用类别权重的成本敏感学习策略,并且指标良好,我是否仍应尝试SMOTE,因为少数类别(1%)的比例非常低?
谢谢你
您好 Michele...感谢您的宝贵反馈和支持!我建议尝试SMOTE。
https://machinelearning.org.cn/smote-oversampling-for-imbalanced-classification/
您好!非常感谢您的解释,这帮助很大。
我将提出以下一些问题
我正在尝试将成本敏感学习应用于我的多类别不平衡数据集的随机森林分类器。代码中的权重与成本矩阵相同吗?我看到您给多数类别1.0,给其他类别2.0。有没有什么依据或参考来决定我应该为每个类别分配什么权重值?
希望这个问题能得到您的关注。非常感谢。
您好 Jess...以下资源可能对您有用
https://www.analyticsvidhya.com/blog/2020/10/improve-class-imbalance-class-weights/
您好 Jason,您的训练和测试数据是相同的,所以准确率可能很高。您能否将数据拆分为训练集和测试集,并在预测后显示一些分类报告,以便我们了解模型如何预测其他类别。
您好 Sagar N.R...感谢您的推荐!
我正在尝试将成本敏感学习应用于我的多类别分类问题,该问题涉及竞争风险生存预测。主要事件和竞争事件都不平衡,因此我需要分配基于实例的权重。我还在思考基于实例的权重和基于类别的权重以及成本矩阵之间的区别。您能否为这项任务提供一些R代码?
你好 James
如何构建SMOTE+LSTM技术来缓解数据不平衡和时间特征选择,并用它来评估其他分类器的性能
您好 Johnbosco...要构建SMOTE(合成少数类过采样技术)+LSTM(长短期记忆)方法来缓解数据不平衡和时间特征选择,并用它来评估其他分类器的性能,请遵循以下步骤
### 步骤1:数据预处理
1. **加载和清洗数据:**
– 加载您的时间序列数据集。
– 处理缺失值(如果有)。
– 对数据进行归一化或标准化。
2. **为LSTM创建序列:**
– 将您的时间序列数据转换为适合LSTM输入的序列。
### 步骤2:应用SMOTE处理数据不平衡
1. **提取特征和标签:**
– 将数据分为特征(X)和标签(y)。
2. **为SMOTE展平序列:**
– SMOTE需要2D数据。将3D序列展平为2D。
3. **应用SMOTE:**
– 使用SMOTE平衡数据中的类别。
– 应用SMOTE后,将数据重新塑形回3D序列。
### 步骤3:构建和训练LSTM模型
1. **设计LSTM网络:**
– 使用TensorFlow/Keras等框架定义LSTM模型。
2. **训练LSTM模型:**
– 在平衡的数据上训练LSTM模型。
### 步骤4:提取时间特征
1. **从LSTM提取特征:**
– 使用训练好的LSTM从序列中提取时间特征。
### 步骤5:评估其他分类器
1. **准备特征集:**
– 使用LSTM模型从原始序列中提取特征。
– 这些特征将用作其他分类器的输入。
2. **训练和评估分类器:**
– 使用提取的特征训练不同的分类器(例如,随机森林,SVM)。
– 使用适当的指标(例如,准确率、精确率、召回率)评估其性能。
### 实施
这是一个使用TensorFlow/Keras和`imblearn`库(用于SMOTE)的Python示例实现。
#### 步骤1:数据预处理
pythonimport numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 加载数据
data = pd.read_csv('your_time_series_data.csv')
# 归一化数据
缩放器 = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
# 创建序列
def create_sequences(data, time_steps)
X, y = [], []
for i in range(len(data) - time_steps)
X.append(data[i:i + time_steps])
y.append(data[i + time_steps])
return np.array(X), np.array(y)
time_steps = 10 # 示例时间步长
X, y = create_sequences(data_scaled, time_steps)
#### 步骤2:应用SMOTE处理数据不平衡
pythonfrom imblearn.over_sampling import SMOTE
# 为SMOTE展平序列
n_samples, time_steps, n_features = X.shape
X_2d = X.reshape(n_samples * time_steps, n_features)
# 应用 SMOTE
smote = SMOTE()
X_resampled, y_resampled = smote.fit_resample(X_2d, y)
# 重新塑形回3D
n_resampled_samples = len(y_resampled)
X_resampled_3d = X_resampled.reshape(n_resampled_samples // time_steps, time_steps, n_features)
#### 步骤3:构建和训练LSTM模型
pythonfrom keras.models import Sequential
from keras.layers import LSTM, Dense
# 设计LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(time_steps, n_features)))
model.add(LSTM(50))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_resampled_3d, y_resampled, epochs=10, batch_size=32, validation_split=0.2)
#### 步骤4:提取时间特征
python
# 使用训练好的LSTM模型提取特征
feature_extractor = Sequential(model.layers[:-1]) # 移除最后一层
X_features = feature_extractor.predict(X)
#### 步骤5:评估其他分类器
pythonfrom sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, precision_score, recall_score
# 训练和评估随机森林
rf = RandomForestClassifier()
rf.fit(X_features, y)
rf_predictions = rf.predict(X_features)
print('随机森林准确率:', accuracy_score(y, rf_predictions))
print('随机森林精确率:', precision_score(y, rf_predictions))
print('随机森林召回率:', recall_score(y, rf_predictions))
# 训练和评估SVM
svm = SVC()
svm.fit(X_features, y)
svm_predictions = svm.predict(X_features)
print('SVM准确率:', accuracy_score(y, svm_predictions))
print('SVM精确率:', precision_score(y, svm_predictions))
print('SVM召回率:', recall_score(y, svm_predictions))
### 结论
通过遵循这些步骤,您可以构建一个用于时间序列预测的LSTM模型,应用SMOTE来解决数据不平衡问题,并使用提取的特征来评估其他分类器的性能。根据您的特定数据集和要求,调整参数并微调模型。