机器学习中许多计算密集型任务可以通过将工作分配给多个 CPU 核心(称为多核处理)来实现并行化。
可以并行化的常见机器学习任务包括训练模型(如决策树集成)、使用重采样程序(如 k 折交叉验证)评估模型,以及调整模型超参数(如网格搜索和随机搜索)。
在常见机器学习任务中使用多个核心可以显著缩短执行时间,缩短的程度与您系统上可用核心的数量成正比。常见的笔记本电脑和台式电脑可能有 2、4 或 8 个核心。大型服务器系统可能有 32、64 个或更多核心,从而可以将花费数小时的机器学习任务缩短到几分钟内完成。
在本教程中,您将了解如何为多核机器学习配置 scikit-learn。
完成本教程后,您将了解:
- 如何使用多个核心训练机器学习模型。
- 如何并行评估机器学习模型。
- 如何使用多个核心调整机器学习模型超参数。
让我们开始吧。

使用 Scikit-Learn 在 Python 中进行多核机器学习
照片由 ER Bauer 拍摄,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 多核 Scikit-Learn
- 多核模型训练
- 多核模型评估
- 多核超参数调优
- 建议
多核 Scikit-Learn
机器学习可能计算成本很高。
这种计算成本主要有三个方面;它们是
- 训练机器学习模型。
- 评估机器学习模型。
- 调整机器学习模型超参数。
更糟糕的是,这些问题会累加。
例如,使用像 k 折交叉验证 这样的重采样技术来评估机器学习模型,需要重复训练过程多次。
- 评估需要重复训练
调整模型超参数会进一步加剧这种情况,因为它要求对测试的每个超参数组合重复评估过程。
- 调优需要重复评估
大多数现代计算机(如果不是全部的话)都拥有多核 CPU。这包括您的工作站、笔记本电脑以及大型服务器。
您可以配置您的机器学习模型来利用计算机的多个核心,从而大大加快计算密集型操作的速度。
scikit-learn Python 机器学习库通过 n_jobs 参数在关键机器学习任务(如模型训练、模型评估和超参数调整)中提供了此功能。
此配置参数允许您指定用于任务的核心数。默认值为 None,表示使用单个核心。您也可以指定一个整数核心数,例如 1 或 2。最后,您可以指定 -1,在这种情况下,任务将使用您系统上的所有可用核心。
- n_jobs:指定用于关键机器学习任务的核心数。
常见值为
- n_jobs=None:使用单个核心或您的后端库配置的默认核心。
- n_jobs=4:使用指定数量的核心,此例为 4。
- n_jobs=-1:使用所有可用核心。
什么是核心?
CPU 可能有多个物理 CPU 核心,这基本上就像拥有多个 CPU。每个核心也可能有超线程,这项技术在许多情况下允许您将核心数量加倍。
例如,我的工作站有四个物理核心,由于超线程技术,它们翻倍为八个核心。因此,我可以尝试使用 1-8 个核心,或者指定 -1 来使用我工作站上的所有核心。
现在我们熟悉了 scikit-learn 库支持多核并行处理机器学习的功能,让我们通过一些示例来学习。
您将获得所有示例的不同计时;请在评论中分享您的结果。您可能还需要更改核心数以匹配您系统上的核心数。
注意:是的,我知道 timeit API,但在此教程中选择不使用它。我们不是在剖析代码示例本身;相反,我希望您专注于如何以及何时使用 scikit-learn 的多核功能,以及它们提供了哪些实际的好处。我希望代码示例清晰简洁,即使对于初学者也能轻松阅读。我将其设置为一个扩展,用于更新所有示例以使用 timeit API 并获得更准确的计时。请在评论中分享您的结果。
多核模型训练
许多机器学习算法通过在定义模型时使用 n_jobs 参数来支持多核训练。
这不仅会影响模型的训练,还会影响模型在进行预测时的使用。
一个流行的例子是决策树集成,例如装袋决策树、随机森林和梯度提升。
在本节中,我们将使用多个核心来加速 RandomForestClassifier 模型的训练。我们将使用合成分类任务进行实验。
在这种情况下,我们将定义一个具有 500 棵树的随机森林模型,并使用一个核心来训练模型。
|
1 2 3 |
... # 定义模型 model = RandomForestClassifier(n_estimators=500, n_jobs=1) |
我们可以使用 time() 函数记录对 train() 函数调用之前和之后的时间。然后,我们可以从结束时间中减去开始时间,并以秒为单位报告执行时间。
使用单个核心训练随机森林模型执行时间评估的完整示例列于下文。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 使用单个核心计时训练随机森林模型的示例 from time import time from sklearn.datasets import make_classification from sklearn.ensemble import RandomForestClassifier # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=3) # 定义模型 model = RandomForestClassifier(n_estimators=500, n_jobs=1) # 记录当前时间 start = time() # 拟合模型 model.fit(X, y) # 记录当前时间 end = time() # 报告执行时间 result = end - start print('%.3f seconds' % result) |
运行示例会报告使用单个核心训练模型所需的时间。
在这种情况下,我们可以看到它大约需要 10 秒。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 |
10.702 秒 |
现在我们可以修改示例以使用系统上的所有物理核心,在本例中为四个。
|
1 2 3 |
... # 定义模型 model = RandomForestClassifier(n_estimators=500, n_jobs=4) |
使用四个核心进行多核模型训练的完整示例列于下文。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 使用 4 个核心计时训练随机森林模型的示例 from time import time from sklearn.datasets import make_classification from sklearn.ensemble import RandomForestClassifier # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=3) # 定义模型 model = RandomForestClassifier(n_estimators=500, n_jobs=4) # 记录当前时间 start = time() # 拟合模型 model.fit(X, y) # 记录当前时间 end = time() # 报告执行时间 result = end - start print('%.3f seconds' % result) |
运行示例会报告使用单个核心训练模型所需的时间。
在这种情况下,我们可以看到执行速度减半多,降至约 3.151 秒。
在您的系统上需要多长时间?请在下面的评论中分享您的结果。
|
1 |
3.151 秒 |
我们现在可以将核心数更改为八个,以考虑由四个物理核心支持的超线程。
|
1 2 3 |
... # 定义模型 model = RandomForestClassifier(n_estimators=500, n_jobs=8) |
通过将 n_jobs 设置为 -1 以自动使用所有核心,我们可以达到相同的效果;例如
|
1 2 3 |
... # 定义模型 model = RandomForestClassifier(n_estimators=500, n_jobs=-1) |
我们暂时坚持手动指定核心数。
使用八个核心进行多核模型训练的完整示例列于下文。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 使用 8 个核心计时训练随机森林模型的示例 from time import time from sklearn.datasets import make_classification from sklearn.ensemble import RandomForestClassifier # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=3) # 定义模型 model = RandomForestClassifier(n_estimators=500, n_jobs=8) # 记录当前时间 start = time() # 拟合模型 model.fit(X, y) # 记录当前时间 end = time() # 报告执行时间 result = end - start print('%.3f seconds' % result) |
运行示例会报告使用单个核心训练模型所需的时间。
在这种情况下,我们可以看到通过使用所有核心,执行速度从约 3.151 秒又下降到约 2.521 秒。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 |
2.521 秒 |
我们可以通过比较从一到八的所有值并绘制结果,使训练期间使用的核心数与执行速度之间的关系更加具体。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 比较训练期间使用的核心数与执行速度的示例 from time import time from sklearn.datasets import make_classification from sklearn.ensemble import RandomForestClassifier from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=3) results = list() # 比较核心数的计时 n_cores = [1, 2, 3, 4, 5, 6, 7, 8] for n in n_cores: # 捕获当前时间 start = time() # 定义模型 model = RandomForestClassifier(n_estimators=500, n_jobs=n) # 拟合模型 model.fit(X, y) # 捕获当前时间 end = time() # 存储执行时间 result = end - start print('>cores=%d: %.3f seconds' % (n, result)) results.append(result) pyplot.plot(n_cores, results) pyplot.show() |
运行示例首先报告了训练期间使用的每个核心数的执行速度。
我们可以看到从一个核心到八个核心的执行速度稳步下降,尽管在四个物理核心之后,显著的好处就停止了。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 2 3 4 5 6 7 8 |
>cores=1: 10.798 秒 >cores=2: 5.743 秒 >cores=3: 3.964 秒 >cores=4: 3.158 秒 >cores=5: 2.868 秒 >cores=6: 2.631 秒 >cores=7: 2.528 秒 >cores=8: 2.440 秒 |
还会创建一个图来显示训练期间使用的核心数与执行速度之间的关系,表明我们一直受益于八个核心。
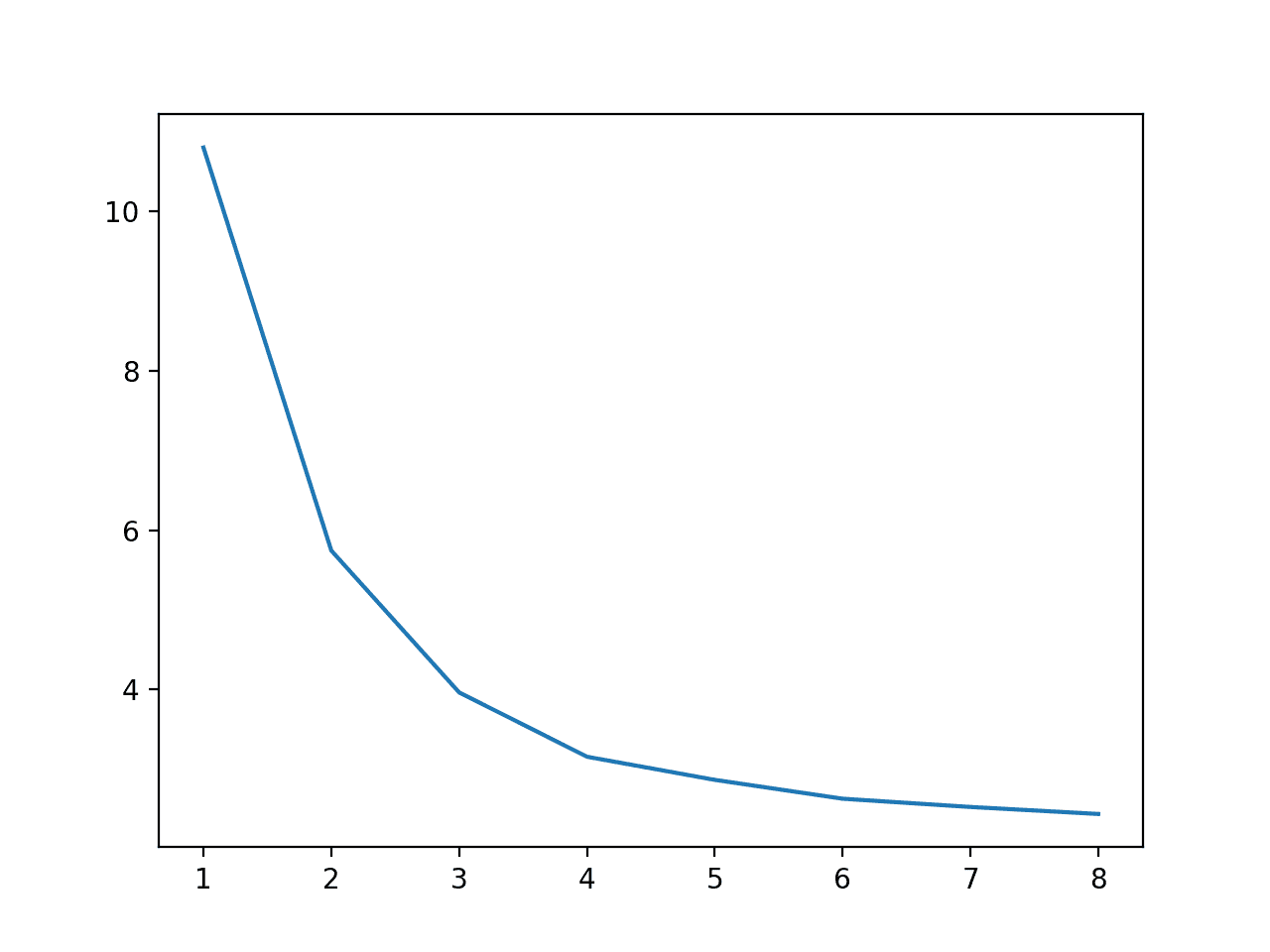
训练期间使用的核心数与执行速度的关系折线图
现在我们熟悉了多核机器学习模型训练的好处,让我们来看看多核模型评估。
多核模型评估
模型评估的金标准是 k 折交叉验证。
这是一种重采样程序,需要对数据集的不同分区子集进行模型训练和评估 *k* 次。结果是模型在对训练期间未使用的进行预测时性能的估计,可用于比较和选择适合数据集的良好或最佳模型。
此外,重复进行此评估过程(称为重复 k 折交叉验证)也是一项好习惯。
评估过程可以配置为使用多个核心,其中每个模型训练和评估发生在不同的核心上。这可以通过在调用 cross_val_score() 函数时设置 n_jobs 参数来实现;例如
我们可以探讨多核对模型评估的影响。
首先,让我们使用单个核心评估模型。
|
1 2 3 |
... # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=1) |
我们将评估随机森林模型,并在模型训练中使用单个核心(目前)。
|
1 2 3 |
... # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=1) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 使用单个核心评估模型的示例 from time import time from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3) # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=1) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 记录当前时间 start = time() # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=1) # 记录当前时间 end = time() # 报告执行时间 result = end - start print('%.3f seconds' % result) |
运行示例使用 10 折交叉验证和三次重复来评估模型。
在这种情况下,我们看到模型评估大约需要 6.412 秒。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 |
6.412 秒 |
我们可以更新示例以使用系统上的所有八个核心,并期望获得很大的加速。
|
1 2 3 |
... # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=8) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 使用 8 个核心评估模型的示例 from time import time from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3) # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=1) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 记录当前时间 start = time() # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=8) # 记录当前时间 end = time() # 报告执行时间 result = end - start print('%.3f seconds' % result) |
运行示例使用多个核心评估模型。
在这种情况下,我们可以看到执行时间从 6.412 秒下降到约 2.371 秒,实现了可喜的加速。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 |
2.371 秒 |
与上一节一样,我们可以为从一个到八个核心的每个核心计时执行速度,以了解它们之间的关系。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 比较模型评估的执行速度与 CPU 核心数的关系 from time import time from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier from matplotlib import pyplot # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3) results = list() # 比较核心数的计时 n_cores = [1, 2, 3, 4, 5, 6, 7, 8] for n in n_cores: # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=1) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 记录当前时间 start = time() # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=n) # 记录当前时间 end = time() # 存储执行时间 result = end - start print('>cores=%d: %.3f seconds' % (n, result)) results.append(result) pyplot.plot(n_cores, results) pyplot.show() |
运行示例首先报告了为评估模型而使用的每个核心数的执行时间(以秒为单位)。
我们可以看到,在四个物理核心以上没有显著的改进。
我们还可以看到与之前实验使用八个核心进行训练的差异。在这种情况下,评估性能需要 1.492 秒,而单独的案例大约需要 2.371 秒。
这凸显了我们正在使用的评估方法论的局限性,即我们报告的是单次运行的性能,而不是重复运行的性能。需要一些启动时间来将类加载到内存中并执行任何 JIT 优化。
无论我们的粗略剖析的准确性如何,我们确实看到了随着过程中使用的核心数量的增加,模型评估的熟悉的速度提升。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 2 3 4 5 6 7 8 |
>cores=1: 6.339 秒 >cores=2: 3.765 秒 >cores=3: 2.404 秒 >cores=4: 1.826 秒 >cores=5: 1.806 秒 >cores=6: 1.686 秒 >cores=7: 1.587 秒 >cores=8: 1.492 秒 |
还会创建一个图来显示核心数与执行速度之间的关系。
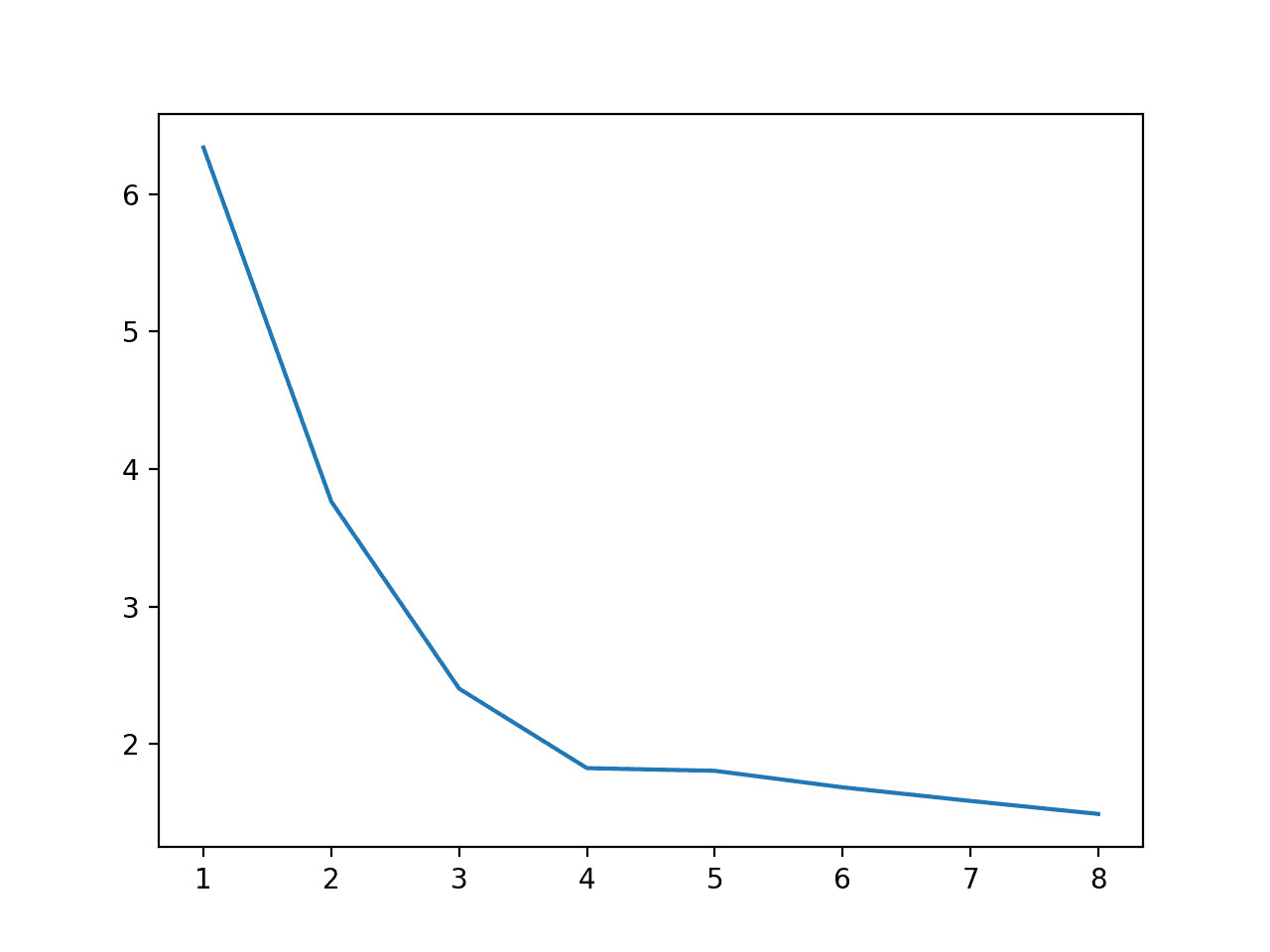
模型评估期间使用的核心数与执行速度的关系折线图
我们还可以使模型训练过程在模型评估过程中并行化。
虽然这是可能的,但我们应该这样做吗?
为了探讨这个问题,让我们首先考虑模型训练使用所有核心而模型评估使用单个核心的情况。
|
1 2 3 4 5 6 |
... # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=8) ... # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=1) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 使用多个核心进行模型训练而非模型评估的示例 from time import time from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3) # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=8) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 记录当前时间 start = time() # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=1) # 记录当前时间 end = time() # 报告执行时间 result = end - start print('%.3f seconds' % result) |
运行示例使用单个核心评估模型,但每个训练模型使用单个核心。
在这种情况下,我们可以看到模型评估需要超过 10 秒,远长于使用单个核心进行训练和所有核心进行并行模型评估的 1 或 2 秒。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 |
10.461 秒 |
如果我们将在训练和评估过程之间分配核心数呢?
|
1 2 3 4 5 6 |
... # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=4) ... # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=4) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 使用多个核心进行模型训练和评估的示例 from time import time from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3) # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=8) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=4) # 记录当前时间 start = time() # 评估模型 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=4) # 记录当前时间 end = time() # 报告执行时间 result = end - start print('%.3f seconds' % result) |
运行示例使用四个核心评估模型,并且每个模型使用四个不同的核心进行训练。
我们看到与使用所有核心训练和使用一个核心评估相比有所改进,但至少对于此模型在此数据集上,将所有核心用于模型评估和单个核心用于模型训练更为高效。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 |
3.434 秒 |
多核超参数调优
使用网格搜索或随机搜索来调整机器学习模型的超参数是很常见的。
scikit-learn 库分别通过 GridSearchCV 和 RandomizedSearchCV 类提供了这些功能。
通过设置 n_jobs 参数,可以将这两种搜索过程并行化,为每个超参数配置分配一个核心进行评估。
模型评估本身也可以是多核的,正如我们在上一节中所见,并且给定评估中的模型训练也可以是多核的,正如我们在前两节中所见。因此,潜在多核进程的堆栈开始变得难以配置。
在此特定实现中,我们可以使模型训练并行化,但我们无法控制每个模型超参数以及如何使每个模型评估多核化。截至撰写本文时,文档并不清楚,但我猜测每个模型评估使用单个核心超参数配置会分解为作业。
让我们探讨使用多个核心进行模型超参数调整的优势。
首先,让我们使用单个核心评估随机森林算法的各种配置网格。
|
1 2 3 |
... # 定义网格搜索 search = GridSearchCV(model, grid, n_jobs=1, cv=cv) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 使用单个核心调整模型超参数的示例 from time import time from sklearn.datasets import make_classification from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3) # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=1) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义网格 grid = dict() grid['max_features'] = [1, 2, 3, 4, 5] # 定义网格搜索 search = GridSearchCV(model, grid, n_jobs=1, cv=cv) # 记录当前时间 start = time() # 执行搜索 search.fit(X, y) # 记录当前时间 end = time() # 报告执行时间 result = end - start print('%.3f seconds' % result) |
运行此示例会测试随机森林的max_features配置的不同值,其中每个配置都使用重复的k折交叉验证进行评估。
在这种情况下,单核网格搜索大约需要 28.838 秒。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 |
28.838 秒 |
我们现在可以配置网格搜索以使用系统上所有可用的核心,在本例中为八个核心。
|
1 2 3 |
... # 定义网格搜索 search = GridSearchCV(model, grid, n_jobs=8, cv=cv) |
然后,我们可以评估此多核网格搜索需要多长时间才能执行。完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 使用 8 个核心调整模型超参数的示例 from time import time from sklearn.datasets import make_classification from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3) # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=1) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义网格 grid = dict() grid['max_features'] = [1, 2, 3, 4, 5] # 定义网格搜索 search = GridSearchCV(model, grid, n_jobs=8, cv=cv) # 记录当前时间 start = time() # 执行搜索 search.fit(X, y) # 记录当前时间 end = time() # 报告执行时间 result = end - start print('%.3f seconds' % result) |
运行示例会报告网格搜索的执行时间。
在这种情况下,我们看到速度加快了大约四倍,从大约 28.838 秒缩短到约 7.418 秒。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 |
7.418 秒 |
直观地说,我们期望将网格搜索设为多核是重点,而不是模型训练。
尽管如此,我们可以将核心分配给模型训练和网格搜索之间,看看这是否能为此数据集上的此模型带来好处。
|
1 2 3 4 5 6 |
... # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=4) ... # 定义网格搜索 search = GridSearchCV(model, grid, n_jobs=4, cv=cv) |
多核模型训练和多核超参数调优的完整示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# 多核模型训练和超参数调优的示例 from time import time from sklearn.datasets import make_classification from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=3) # 定义模型 model = RandomForestClassifier(n_estimators=100, n_jobs=4) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 定义网格 grid = dict() grid['max_features'] = [1, 2, 3, 4, 5] # 定义网格搜索 search = GridSearchCV(model, grid, n_jobs=4, cv=cv) # 记录当前时间 start = time() # 执行搜索 search.fit(X, y) # 记录当前时间 end = time() # 报告执行时间 result = end - start print('%.3f seconds' % result) |
在这种情况下,我们确实看到了执行速度的下降,与单核情况相比,但收益不如将所有核心分配给网格搜索过程。
在您的系统上需要多长时间?请在下方的评论中分享您的结果。
|
1 |
14.148 秒 |
建议
本节列出了一些在使用多核进行机器学习时的一般性建议。
- 确认系统上的可用核心数。
- 考虑使用具有多个核心的 AWS EC2 实例以立即获得速度提升。
- 查看 API 文档,了解您使用的模型是否支持多核训练。
- 确认多核训练在您的系统上是否提供可衡量的优势。
- 在使用 k 折交叉验证时,最好将核心分配给重采样过程,而让模型训练保持单核。
- 在使用超参数调优时,最好将搜索过程设为多核,而让模型训练和评估保持单核。
您是否有自己的建议?
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
相关教程
API
- 如何优化速度,scikit-learn 文档.
- Joblib:将 Python 函数作为管道作业运行
- timeit API.
- sklearn.ensemble.RandomForestClassifier API.
- sklearn.model_selection.cross_val_score API.
- sklearn.model_selection.GridSearchCV API.
- sklearn.model_selection.RandomizedSearchCV API.
- n_jobs scikit-learn 参数.
文章
总结
在本教程中,您学习了如何将 scikit-learn 配置为多核机器学习。
具体来说,你学到了:
- 如何使用多个核心训练机器学习模型。
- 如何并行评估机器学习模型。
- 如何使用多个核心调整机器学习模型超参数。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。






Jason,感谢您的教程。我在我的新笔记本电脑 Lenovo Yoga Slim 7 (https://www.tomshardware.com/news/lenovo-yoga-slim-7-review-tested) 上运行了这些示例
以下是用于比较的结果
Jason 的工作站 vs. Oliver 的笔记本电脑
---------------------------------
测试 1:10.702 秒 vs. 11.967 秒
测试 2:3.151 秒 vs. 3.287 秒
测试 3:2.521 秒 vs. 1.965 秒
测试 4
>核心=1:10.798 秒 vs. 11.933 秒
>核心=2:5.743 秒 vs. 6.292 秒
>核心=3:3.964 秒 vs. 4.290 秒
>核心=4:3.158 秒 vs. 3.467 秒
>核心=5:2.868 秒 vs. 3.014 秒
>核心=6:2.631 秒 vs. 2.669 秒
>核心=7:2.528 秒 vs. 2.448 秒
>核心=8:2.440 秒 vs. 2.189 秒
测试 5:6.412 秒 vs. 6.451 秒
测试 6:2.371 秒 vs. 1.179 秒
测试 7
>核心=1:6.339 秒 vs. 6.443 秒
>核心=2:3.765 秒 vs. 4.238 秒
>核心=3:2.404 秒 vs. 3.061 秒
>核心=4:1.826 秒 vs. 2.128 秒
>核心=5:1.806 秒 vs. 2.526 秒
>核心=6:1.686 秒 vs. 1.663 秒
>核心=7:1.587 秒 vs. 1.487 秒
>核心=8:1.492 秒 vs. 1.482 秒
测试 8:10.461 秒 vs. 3.263 秒(这可能吗?)
测试 9:3.434 秒 vs. 1.395 秒
测试 10:28.838 秒 vs. 28.937 秒
测试 11:7.418 秒 vs. 5.033 秒
测试 12:14.148 秒 vs. 8.051 秒
谢谢
奥利弗
干得好,感谢分享!
有人将 Python ML 程序编译成 .exe,该程序使用多个核心进行超参数调优,并解决了 .exe 崩溃的问题吗?
也许这会有帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-deploy-my-python-file-as-an-application
谢谢 Jason,我正在使用 Pyinstaller,但它默认模式不处理多核处理,我还没有发现任何技巧或开关来启用它。
抱歉,我不知道。也许直接联系项目作者。
这可能是一个多窗口问题,我正在使用 Tkinter。
“这可能对我和其他人有帮助
在创建窗口之前,将行 multiprocessing.freeze_support() 添加到您的代码中。此处有文档记录”
来自 stackoverflow
谢谢分享。Tkinter 是什么?
Tkinter 是 Python 的 GUI 界面库,允许开发 GUI 应用程序。
谢谢。
Jason,我在尝试在我的电脑上运行这些测试——您提供的多核模型训练和评估示例中
# 定义模型
model = RandomForestClassifier(n_estimators=100, n_jobs=4)
# 评估模型
n_scores = cross_val_score(model, X, y, scoring=’accuracy’, cv=cv, n_jobs=4)
在它下面的主代码块中,看起来您对 n_scores 使用了 n_jobs=8?
谢谢,
Dana
是的,代码上方的文字说明我们使用了 8。
您可以根据需要更改它。
哇,不错的博客,我喜欢它,但我想知道 n_jobs 是一个基类属性,还是仅限于随机森林分类器?
谢谢。
n_jobs 仅适用于支持并行训练的算法,例如集成算法。如果您不确定,请查阅您选择的算法的 API。
很棒的博客!
学到了很多新东西
谢谢!
Jason,感谢您的教程。我在我的戴尔酷睿 i7 U5500 笔记本电脑(2 核 4 线程)上运行了这些示例。
测试 1:16.842 秒
干得好!
嗨,Jason,
我刚进行了随机测试以供测试
>核心=1:34.046 秒
>核心=2:20.409 秒
>核心=3:14.541 秒
>核心=4:11.483 秒
>核心=5:9.330 秒
>核心=6:8.326 秒
>核心=7:7.281 秒
>核心=8:6.996 秒
>核心=10:6.626 秒
>核心=19:6.336 秒
>核心=100:6.565 秒
import multiprocessing as mp
print(“笔记本逻辑处理器数量:”, mp.cpu_count())
笔记本逻辑处理器数量:8
为什么给超过 8 个处理器会减少时间
6.996 – 6.626,
0.3700000000000001 秒
列表中的其他数字 19、100 只是随机数……用于查看效果。
第 2 点:我们还可以使用 multiprocessing pool 和 multiprocessing 中提供的其他函数来并行执行。
太酷了!
我们可以与 TPOT 一起使用多核吗?
我认为 TPOT 已经使用了多核。
多核是否仅适用于少数 Scikit-Learn 算法,如随机森林,还是适用于所有算法?
仅适用于支持并行训练的算法。并非所有算法都支持。
非常感谢 Jason 提供如此有用的教程。
添加这个简单的参数 njobs=-1 将我的 RandomForestClassifier() 的耗时从 24.67 秒减少到了 4.76 秒。
这将对我的集成模型的整体执行时间产生巨大影响。
干得好!
尊敬的Jason博士,
我将报告我关于 n_jobs 的实验。在 (1) 中,我指的是简单的 n_jobs = 1 和 n_jobs = 8,分别用于模型和评估,然后在 (2) 中,n_jobs = 1 用于模型,并改变核心数量;n_jobs = 8 用于模型,并改变核心数量。
对于 (2),行为不符合我的预期。
现在
(1) 在本教程的前半部分,我将 n_jobs = 1 和 n_jobs = 8 的所有排列组合分别用于模型和 cv。
从上面可以看出,当 cross_val_score 的 n_jobs=8 时,时间会减少。增加模型的 n_jobs 会略微降低性能。
(2) 当模型的 n_jobs = 1 和 8 时,改变 cv 的核心数量。
当 n_jobs = 1 或 8 时,模型的 n_jobs 会出现“不规律”的下降趋势。这种“不规律”变化无法解释。不过,当模型的 n_jobs=8 时,时间会增加。
总的来说,如果模型的 n_jobs 增加,不一定能提高执行速度。它只会略微提高执行速度。但对于 (2),无法解释执行速度没有恒定下降的原因。
谢谢你,
悉尼的Anthony
干得不错。
我们可以预料到一些随机变异。请比较平均值和标准差,而不是单次运行——这是大多数计算机操作的格言。
尊敬的Jason博士,
在最后一个使用网格搜索的示例中,我创建了一个“全能”脚本,并注释掉了适当的部分。
表格中的结果
与作者(Jason 博士)的结果类似,增加模型 n_jobs 并不能提高性能。还可以看到,增加模型 n_jobs 的数量会增加执行时间。
总而言之,对于本教程的所有示例,增加 cvs(repeatedstratifiedkfold)或网格搜索的 n_jobs 可以提高性能,但增加模型的 n_jobs 会增加执行时间 = 略微降低性能。
谢谢你,
悉尼的Anthony
但是,当
结果如下
尊敬的Jason博士,
抱歉。我分别对模型和网格搜索进行了以下 n_jobs 设置:(1,1), (4,4),(1,8) 和 (8,8)。结论相同。
结论相同。增加网格搜索的 n_jobs 会减少执行时间。增加模型的 n_jobs 会增加执行时间。平均分配 n_jobs 的数量并不能提高执行时间。
谢谢你,
悉尼的Anthony
太棒了!
我的电脑
AMD Ryzen 7 3700x (16 线程) – 32GB。RAM @ 3600Mhz。
Windows 10 和 Linux(测试是在 Windows 环境下运行的)。
由于我的 CPU 有 16 个核心,我把您的脚本推到了…… 16 个核心 :) 玩玩。
测试 1 多核:多核模型训练
#>核心=1:11.458 秒
#>核心=2:5.885 秒
#>核心=3:4.104 秒
#>核心=4:3.203 秒
#>核心=5:2.676 秒
#>核心=6:2.260 秒
#>核心=7:1.978 秒
#>核心=8:1.805 秒
#>核心=9:1.709 秒
#>核心=10:1.585 秒
#>核心=11:1.531 秒
#>核心=12:1.457 秒
#>核心=13:1.419 秒
#>核心=14:1.359 秒
#>核心=15:1.317 秒
#>核心=16:1.302 秒
测试 2:多核模型评估
#>核心=1:6.084 秒
#>核心=2:3.786 秒
#>核心=3:2.717 秒
#>核心=4:2.301 秒
#>核心=5:1.907 秒
#>核心=6:1.723 秒
#>核心=7:1.091 秒
#>核心=8:0.973 秒
#>核心=9:1.678 秒!!!!非常奇怪……我测试了很多次,结果都已确认。
#>核心=10:0.969 秒
#>核心=11:0.848 秒
#>核心=12:0.843 秒
#>核心=13:0.838 秒
#>核心=14:0.824 秒
#>核心=15:0.870 秒
#>核心=16:0.893 秒
# 使用单个核心调整模型超参数的示例
# 27.340 秒
# 使用 8 个核心调整模型超参数的示例
# 5.090 秒
# 多核模型训练和超参数调优的示例
# 6.295 秒
如果我设置为 8 个任务,执行时间低至 4.5 秒。
# 多核模型训练和超参数调优的示例
# 6.491 秒……比你的电脑快得多……这很奇怪
最后,在一核上,你的电脑在训练方面比我的快,但在评估方面却慢 🙂
运行 9 个核心时,我的电脑也出现了一种奇怪的现象——性能比 8 个核心差。
“多核模型训练和超参数调优”的最终测试在我这边显示出比您的结果更好的性能。我无法用相同的代码和之前的那些结果来解释这种差异。
顺祝商祺 Gilles
干得好!
我们可能会看到随机效应。
我们也可能开始看到与 Python JIT/内存管理等相关的开销和其他效应。
重复实验并取平均值可能会有所帮助。
我完全同意 :)
我正在考虑多次运行相同的代码以获得更好的视图(使用平均值和/或图形图)。
事实上我做到了,但没有汇总结果。
我还在考虑以加速度与单核的比例来绘制结果。
例如
我不知道如何在此处插入图形... 但在我的电脑上,很明显,我们设想获得的增益与实际观察到的相比要小得多。
Gilles
太棒了!
嗨,Jason,
我今天下午花了一些时间,修改了您的代码以多次运行测试,并最终绘制了箱线图。
我选择了 10 次运行,但这在代码中很容易参数化。
这真的很有趣,因为第一次运行总是比其他人慢。
在我的箱线图中,异常值总是第一次运行。我怀疑 Python 会在内存中保留一些东西。
另一件有趣的事情是,10 到 14 个线程之间的性能几乎没有提升,但 15 和 16 个线程的性能显着提高。从 0.8 秒下降到 0.6 秒。
请享用 :)
对于那些想深入研究并克服随机方差的人来说,可以使用相同的方法来处理您所有的代码。
这是代码
干得好。
是的,第一次运行必须启动Python运行时。通常在进行基准测试时,我们需要进行预热启动并丢弃前几次运行。
抱歉,复制代码时缩进不正确
没关系,我添加了pre标签。
你好Jason,这是一篇很棒的文章。感谢你如此明确地讨论多核处理。我大部分时间都在进行深度机器学习工作的并行计算。只是想补充两点建议,这是我在给学生教授并行计算时发现的
1.除了‘njobs’之外,再添加一个参数‘verbose’,它允许我们在使用多个核心时打印一些关于进程当前位置的注释。这有助于理解后台进程。
2.在Windows中,要使用多个核心,我们需要一些额外的设置,即
if __name__ == ‘__main__’
带njobs=...的代码
如果我们不提供此设置,那么即使我们提供多个核心,作业也只在单个核心上处理。
感谢分享!
嗨,Jason。
关于当前主题“python中的多核机器学习”,你能否建议一些方法来提高SVM(sklearn.svm.SVC)二元分类模型在45K记录上的执行速度,它已经运行了几天?我尝试了以下用于Spark分布式计算的代码,但没有效果。
from sklearn.utils import parallel_backend
from joblibspark import register_spark
register_spark()
from sklearn.svm import SVC
svm = SVC(kernel = ‘linear’, probability = True , class_weight = ‘balanced’, random_state = 12 )
with parallel_backend(‘spark’, n_jobs = 4)
%time feature_selection(model = svm, data = train_data_3, cont_features = cont_features)
谢谢!
也许这些想法会有帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-speed-up-the-training-of-my-model
谢谢 Jason。
不客气。
你好,杰森,
我有一个2.2 GHz四核Intel Core i7 Macbook 2015型号
对于比较核心数量的代码,我得到了以下输出。它看起来相当快。
>核心数=1: 15.357 秒
>核心数=2: 8.948 秒
>核心数=3: 6.525 秒
>核心数=4: 4.728 秒
>核心数=5: 4.615 秒
>核心数=6: 5.048 秒
>核心数=7: 3.799 秒
>核心数=8: 3.987 秒
使用单个核心调整模型超参数所需时间如下
39.653 秒
我对GridSearchCV有一个问题。我正在训练一个模型来拟合MNIST数据集,其维度为7000×784。每次拟合大约需要30分钟。如何加快这个速度?
from sklearn.model_selection import GridSearchCV
param_grid = [{‘weights’: [“uniform”, “distance”], ‘n_neighbors’: [3, 4, 5]}]
knn_clf = KNeighborsClassifier()
grid_search = GridSearchCV(knn_clf, param_grid, cv=5, verbose=3)
grid_search.fit(X_train, y_train)
干得不错。
一些建议
也许使用GPU?
也许使用更多CPU?
也许使用更快的GPU/CPU?
也许可以使用更小的模型?
也许使用较少的数据?
也许在搜索中使用更少的超参数?
你好Jason,感谢您更新这个多核进程。我有一个问题。我可以在RNN中启用多核计算吗?我使用的是顺序模型,它似乎没有n_jobs参数。
感谢您的回复。
是的,Keras会自动使用多个CPU核心。
嗨,Jason,
我一直在思考…尽管存在固有的随机波动,但我们的一些朋友上面看到的性能不增加(甚至下降)可能是由多线程行为解释的。当计算机开始使用超线程而不是物理核心时,某些操作的并行效率会下降。当您选择n_jobs=8核在一个4核CPU上运行时,可能会发生这种情况。
这有意义吗?
感谢您提供有用的文章。
是的,可能就是这种情况。
这突显了进行测试的重要性,而不是假设线性或超线性加速。
嗨,精彩的文章。我有一个问题。我可以在模型训练、评估和超参数调优时设置n_jobs = -1吗?
当然可以。
“…我猜想,每个使用单个核心超参数配置的模型评估都会被拆分成多个任务。”
通过查看处理此问题的GridSearchCV代码[1],它看起来每个超参数集+训练分割的组合都会得到一个自己的任务(例如,5个分割*2个超参数集=10个任务)。
…这让我想知道缓存转换器[2]在网格搜索中是如何工作的。如果joblib同时为“Fold 1, hyperparam set A”和“Fold 1, hyperparam set B”启动任务,那么在其中一个完成之前,就没有缓存结果可供使用。看起来您可能无法从中获得缓存的好处,具体取决于任务的运行顺序。
[1] https://github.com/scikit-learn/scikit-learn/blob/2beed5584/sklearn/model_selection/_search.py#L795
[2] https://scikit-learn.cn/stable/modules/compose.html#caching-transformers-avoid-repeated-computation
你说得对。毕竟,缓存并不保证更快。缓存失效也应该被考虑在内!
你好,杰森
我叫Danial。
我的论文有很多问题。
请请请帮助我。
你好Danial…我们很乐意帮助回答您关于我们内容的问题。
您可以在这里找到一个很好的起点
https://machinelearning.org.cn/start-here/
嗨,Jason,
我有一个疑问,当我们使用多核处理训练ML/DL模型时,权重是如何在核心之间共享的,模型是如何在训练结束时保存的?
你好Yogeeshwari…以下内容可能对您感兴趣。
https://www.analyticsvidhya.com/blog/2021/04/train-machine-learning-models-using-cpu-multi-cores/
建议的链接并未回答所提出的问题!
谢谢链接!
你好Jason,如何在PyTorch中微调/训练Hugging Face Transformer模型?我正在我的个人笔记本电脑上训练。所以请帮助我。
我们都有一些强大的家用PC。还有一些昂贵但强大的Nvidia GPU,至少在理论上是这样。现在我对Nvidia如何利用CUDA进行深度学习以及系统中所有其他并行处理感到非常失望,而不是在SLI中使用CUDA,这对于并行处理来说更有意义(SLI用于其他任务效果不佳)。基本上您只能限制在一块显卡上!?那么专家是如何使用多GPU并行处理的呢?我已经安装了Nvidia Tool和驱动程序,以便能够利用CUDA广泛的系统支持,却发现Python和其他数据挖掘软件根本不使用CUDA。我曾尝试手动添加支持并安装所需的库,但都没有成功。我们的“赛车”停在“车库”里,什么也没做。
为什么要购买昂贵的硬件而不从中受益?而您的神经网络和数据挖掘软件的运行速度仅限于您的CPU?最后,人们会说使用云服务而不是(只需要终端,不需要电脑)。
你好Steve…你提出了一些有趣的观点!如果您有关于我们内容的问题,请告诉我们。
看看这个
https://towardsdatascience.com/10x-faster-parallel-python-without-python-multiprocessing-e5017c93cce1
即使在多核24核Xeon CPU工作站上,Python的运行速度也与桌面CPU i7-7700K一样慢。我正在切换到MatLab,因为我只需要编写一次代码,就可以用于我测试的所有版本,这是其一,并且不像Python那样每次都需要重写。另一个是我需要相对快速地获得结果,而不是缓慢。我确信你们IT部门的一些博士比我对这个问题的看法和主题不同,但我只是一个最终用户(不是开发者),作为一个工程师,我更关心最终解决方案和结果,而不是如何以及如何做的。我的观点是,在高性能硬件上开发的软件应该“即插即用”般地开箱即用,并且最终用户不应该为了获得性能而与之搏斗。Python是一个很好的简单快速解决方案的编程语言,但一旦你需要性能……事情和问题就会出现,像我这样的人很难解决,即使有时也不能。
谢谢。