长短期记忆网络(LSTM)是一种循环神经网络,可以学习和预测长序列。
LSTM 的一个优点是除了学习长序列外,它们还可以学习进行一次性的多步预测,这对于时间序列预测可能很有用。
LSTM 的一个难点在于配置它们可能很棘手,并且需要大量准备才能使数据以正确的格式进行学习。
在本教程中,您将了解如何在 Python 中使用 Keras 为多步时间序列预测开发 LSTM。
完成本教程后,您将了解:
- 如何为多步时间序列预测准备数据。
- 如何为多步时间序列预测开发 LSTM 模型。
- 如何评估多步时间序列预测。
开始您的项目,阅读我的新书《深度学习时间序列预测》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。

Python 中使用长短期记忆网络进行多步时间序列预测
照片作者:Tom Babich,保留部分权利。
教程概述
本教程分为 4 个部分;它们是
- 洗发水销售数据集
- 数据准备和模型评估
- 持续模型
- 多步 LSTM
环境
本教程假定您已安装 Python SciPy 环境。您可以使用 Python 2 或 3。
本教程假定您已安装 Keras v2.0 或更高版本,并使用 TensorFlow 或 Theano 后端。
本教程还假定您已安装 scikit-learn、Pandas、NumPy 和 Matplotlib。
如果您需要帮助设置 Python 环境,请参阅此帖子
接下来,让我们看看一个标准的时间序列预测问题,我们可以将其作为本次实验的背景。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
洗发水销售数据集
此数据集描述了 3 年期间洗发水月销量。
单位是销售计数,共有 36 个观测值。原始数据集归功于 Makridakis、Wheelwright 和 Hyndman (1998)。
以下示例加载并创建加载数据集的图表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 加载并绘制数据集 from pandas import read_csv from pandas import datetime from matplotlib import pyplot # 加载数据集 def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 总结前几行 print(series.head()) # 线图 series.plot() pyplot.show() |
运行该示例将数据集作为 Pandas Series 加载并打印前 5 行。
|
1 2 3 4 5 6 7 |
月份 1901-01-01 266.0 1901-02-01 145.9 1901-03-01 183.1 1901-04-01 119.3 1901-05-01 180.3 名称:销售额,数据类型:float64 |
然后创建该系列的线图,显示出明显的上升趋势。
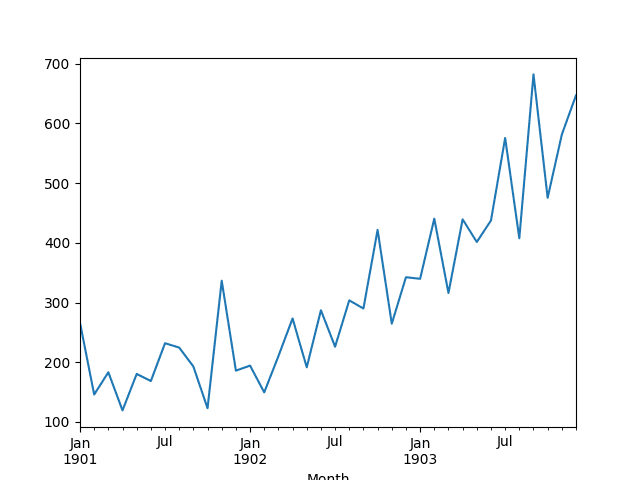
洗发水销售数据集的折线图
接下来,我们将看一下实验中使用的模型配置和测试工具。
数据准备和模型评估
本节介绍本教程中使用的和数据准备和模型评估
数据分割
我们将把洗发水销售数据集分为两部分:训练集和测试集。
前两年的数据将用于训练数据集,剩下的一年数据将用于测试集。
模型将使用训练数据集进行开发,并对测试数据集进行预测。
供参考,最近 12 个月的观测值如下
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"3-01",339.7 "3-02",440.4 "3-03",315.9 "3-04",439.3 "3-05",401.3 "3-06",437.4 "3-07",575.5 "3-08",407.6 "3-09",682.0 "3-10",475.3 "3-11",581.3 "3-12",646.9 |
多步预测
我们将构造一个多步预测。
对于数据集中最后 12 个月的某个月,我们将需要进行 3 个月的预测。
即给定历史观测值(t-1,t-2,… t-n),预测 t、t+1 和 t+2。
具体来说,从第二年的 12 月开始,我们必须预测 1 月、2 月和 3 月。从 1 月开始,我们必须预测 2 月、3 月和 4 月。一直到第三年的 9 月进行 10 月、11 月和 12 月的预测。
总共需要 10 次 3 个月的预测,如下所示
|
1 2 3 4 5 6 7 8 9 10 |
12 月、1 月、2 月、3 月 1 月、2 月、3 月、4 月 2 月、3 月、4 月、5 月 3 月、4 月、5 月、6 月 4 月、5 月、6 月、7 月 5 月、6 月、7 月、8 月 6 月、7 月、8 月、9 月 7 月、8 月、9 月、10 月 8 月、9 月、10 月、11 月 9 月、10 月、11 月、12 月 |
模型评估
将使用滚动预测方案,也称为向前验证模型。
测试数据集的每个时间步都将逐一进行。模型将用于预测时间步,然后将从测试集中获取下一个月的实际预期值,并使其可用于模型进行下一个时间步的预测。
这模拟了现实世界场景,其中每个月都会有新的洗发水销售观察值,并用于预测下个月。
这将通过训练和测试数据集的结构进行模拟。
将收集测试数据集上的所有预测,并计算误差分数以总结模型在每个预测时间步的技能。将使用均方根误差 (RMSE),因为它会惩罚较大的误差,并且得出的分数与预测数据的单位相同,即月度洗发水销量。
持续模型
时间序列预测的一个良好基准是持续模型。
这是一个将最后一个观测值向前持续的预测模型。由于其简单性,它通常被称为朴素预测。
您可以在以下帖子中了解更多关于时间序列预测的持续模型的信息
2. 准备数据
第一步是将数据从序列转换为监督学习问题。
即从数字列表到输入和输出模式列表。我们可以使用一个预先准备好的名为 series_to_supervised() 的函数来实现这一点。
有关此函数的更多信息,请参阅帖子
该函数列示如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 将时间序列转换为监督学习问题 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols, names = list(), list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)] # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [('var%d(t)' % (j+1)) for j in range(n_vars)] else: names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)] # 将它们组合在一起 agg = concat(cols, axis=1) agg.columns = names # 删除包含 NaN 值的行 if dropnan: agg.dropna(inplace=True) return agg |
通过传入加载的序列值,并将 n_in 值设置为 1,n_out 值设置为 3,可以调用该函数;例如
|
1 |
supervised = series_to_supervised(raw_values, 1, 3) |
接下来,我们可以将监督学习数据集分割为训练集和测试集。
我们知道,在这种形式下,最后 10 行包含第二年的数据。这些行构成测试集,其余数据构成训练数据集。
我们可以将所有这些内容放入一个新函数中,该函数接收加载的序列和一些参数,并返回一个已准备好进行建模的训练集和测试集。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 将序列转换为监督学习的训练集和测试集 def prepare_data(series, n_test, n_lag, n_seq): # 提取原始值 raw_values = series.values raw_values = raw_values.reshape(len(raw_values), 1) # 转换为监督学习问题 X, y supervised = series_to_supervised(raw_values, n_lag, n_seq) supervised_values = supervised.values # 分割为训练集和测试集 train, test = supervised_values[0:-n_test], supervised_values[-n_test:] return train, test |
我们可以用洗发水数据集来测试这个。完整的示例将在下面列出。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
from pandas import DataFrame 从 pandas 导入 concat from pandas import read_csv from pandas import datetime # 用于加载数据集的日期时间解析函数 def parser(x): return datetime.strptime('190'+x, '%Y-%m') # 将时间序列转换为监督学习问题 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols, names = list(), list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)] # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [('var%d(t)' % (j+1)) for j in range(n_vars)] else: names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)] # 将它们组合在一起 agg = concat(cols, axis=1) agg.columns = names # 删除包含 NaN 值的行 if dropnan: agg.dropna(inplace=True) return agg # 将序列转换为监督学习的训练集和测试集 def prepare_data(series, n_test, n_lag, n_seq): # 提取原始值 raw_values = series.values raw_values = raw_values.reshape(len(raw_values), 1) # 转换为监督学习问题 X, y supervised = series_to_supervised(raw_values, n_lag, n_seq) supervised_values = supervised.values # 分割为训练集和测试集 train, test = supervised_values[0:-n_test], supervised_values[-n_test:] return train, test # 加载数据集 series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 配置 n_lag = 1 n_seq = 3 n_test = 10 # 准备数据 train, test = prepare_data(series, n_test, n_lag, n_seq) print(test) print('Train: %s, Test: %s' % (train.shape, test.shape)) |
运行示例首先打印整个测试数据集,即最后 10 行。还会打印训练和测试数据集的形状和大小。
|
1 2 3 4 5 6 7 8 9 10 11 |
[[ 342.3 339.7 440.4 315.9] [ 339.7 440.4 315.9 439.3] [ 440.4 315.9 439.3 401.3] [ 315.9 439.3 401.3 437.4] [ 439.3 401.3 437.4 575.5] [ 401.3 437.4 575.5 407.6] [ 437.4 575.5 407.6 682. ] [ 575.5 407.6 682. 475.3] [ 407.6 682. 475.3 581.3] [ 682. 475.3 581.3 646.9]] Train: (23, 4), Test: (10, 4) |
我们可以看到测试数据集第一行的单个输入值(第一列)与第二年 12 月洗发水销量中的观测值相匹配。
|
1 |
"2-12",342.3 |
我们还可以看到,每行包含 4 列,用于每个观测值中的 1 个输入值和 3 个输出值。
进行预测
下一步是进行持续预测。
我们可以轻松地将持续预测实现到一个名为 persistence() 的函数中,该函数接收最后一个观测值和要持续的预测步数。此函数返回一个包含预测的数组。
|
1 2 3 |
# 进行持续预测 def persistence(last_ob, n_seq): return [last_ob for i in range(n_seq)] |
然后,我们可以从第二年的 12 月到第三年的 9 月,为测试数据集中的每个时间步调用此函数。
下面是一个执行此操作的函数 make_forecasts(),它将训练集、测试集和数据集配置作为参数,并返回一个预测列表。
|
1 2 3 4 5 6 7 8 9 10 |
# 评估持续模型 def make_forecasts(train, test, n_lag, n_seq): forecasts = list() for i in range(len(test)): X, y = test[i, 0:n_lag], test[i, n_lag:] # 进行预测 forecast = persistence(X[-1], n_seq) # 存储预测 forecasts.append(forecast) return forecasts |
我们可以这样调用该函数
|
1 |
forecasts = make_forecasts(train, test, 1, 3) |
评估预测
最后一步是评估预测。
我们可以通过计算多步预测的每个时间步的 RMSE 来做到这一点,在这种情况下,我们将得到 3 个 RMSE 分数。下面的 evaluate_forecasts() 函数计算并打印每个预测时间步的 RMSE。
|
1 2 3 4 5 6 7 |
# 评估每个预测时间步的 RMSE def evaluate_forecasts(test, forecasts, n_lag, n_seq): for i in range(n_seq): actual = test[:,(n_lag+i)] predicted = [forecast[i] for forecast in forecasts] rmse = sqrt(mean_squared_error(actual, predicted)) print('t+%d RMSE: %f' % ((i+1), rmse)) |
我们可以像这样调用它
|
1 |
evaluate_forecasts(test, forecasts, 1, 3) |
将预测与原始数据集中的上下文进行绘制也有助于了解 RMSE 分数与问题的关系。
我们可以首先绘制整个洗发水数据集,然后将每个预测绘制为红线。下面的 plot_forecasts() 函数将创建并显示此图。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 在原始数据集的上下文中绘制预测 def plot_forecasts(series, forecasts, n_test): # 以蓝色绘制整个数据集 pyplot.plot(series.values) # 以红色绘制预测 for i in range(len(forecasts)): off_s = len(series) - n_test + i off_e = off_s + len(forecasts[i]) xaxis = [x for x in range(off_s, off_e)] pyplot.plot(xaxis, forecasts[i], color='red') # 显示图表 pyplot.show() |
我们可以像这样调用该函数。请注意,测试集中的观测值数量为 12 个月(12 个),而不是像上面使用的 10 个监督学习输入/输出模式。
|
1 2 |
# 绘制预测 plot_forecasts(series, forecasts, 12) |
通过将持续预测与原始数据集中的实际持续值连接起来,我们可以使图表更好。
这将需要将最后一个观测值添加到预测的前面。下面是 plot_forecasts() 函数的更新版本,包含了这项改进。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 在原始数据集的上下文中绘制预测 def plot_forecasts(series, forecasts, n_test): # 以蓝色绘制整个数据集 pyplot.plot(series.values) # 以红色绘制预测 for i in range(len(forecasts)): off_s = len(series) - 12 + i - 1 off_e = off_s + len(forecasts[i]) + 1 xaxis = [x for x in range(off_s, off_e)] yaxis = [series.values[off_s]] + forecasts[i] pyplot.plot(xaxis, yaxis, color='red') # 显示图表 pyplot.show() |
完整示例
我们可以将所有这些部分组合在一起。
多步持续预测的完整代码示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
from pandas import DataFrame 从 pandas 导入 concat from pandas import read_csv from pandas import datetime from sklearn.metrics import mean_squared_error from math import sqrt from matplotlib import pyplot # 用于加载数据集的日期时间解析函数 def parser(x): return datetime.strptime('190'+x, '%Y-%m') # 将时间序列转换为监督学习问题 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols, names = list(), list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)] # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [('var%d(t)' % (j+1)) for j in range(n_vars)] else: names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)] # 将它们组合在一起 agg = concat(cols, axis=1) agg.columns = names # 删除包含 NaN 值的行 if dropnan: agg.dropna(inplace=True) return agg # 将序列转换为监督学习的训练集和测试集 def prepare_data(series, n_test, n_lag, n_seq): # 提取原始值 raw_values = series.values raw_values = raw_values.reshape(len(raw_values), 1) # 转换为监督学习问题 X, y supervised = series_to_supervised(raw_values, n_lag, n_seq) supervised_values = supervised.values # 分割为训练集和测试集 train, test = supervised_values[0:-n_test], supervised_values[-n_test:] return train, test # 进行持续预测 def persistence(last_ob, n_seq): return [last_ob for i in range(n_seq)] # 评估持续模型 def make_forecasts(train, test, n_lag, n_seq): forecasts = list() for i in range(len(test)): X, y = test[i, 0:n_lag], test[i, n_lag:] # 进行预测 forecast = persistence(X[-1], n_seq) # 存储预测 forecasts.append(forecast) return forecasts # 评估每个预测时间步的 RMSE def evaluate_forecasts(test, forecasts, n_lag, n_seq): for i in range(n_seq): actual = test[:,(n_lag+i)] predicted = [forecast[i] for forecast in forecasts] rmse = sqrt(mean_squared_error(actual, predicted)) print('t+%d RMSE: %f' % ((i+1), rmse)) # 在原始数据集的上下文中绘制预测 def plot_forecasts(series, forecasts, n_test): # 以蓝色绘制整个数据集 pyplot.plot(series.values) # 以红色绘制预测 for i in range(len(forecasts)): off_s = len(series) - n_test + i - 1 off_e = off_s + len(forecasts[i]) + 1 xaxis = [x for x in range(off_s, off_e)] yaxis = [series.values[off_s]] + forecasts[i] pyplot.plot(xaxis, yaxis, color='red') # 显示图表 pyplot.show() # 加载数据集 series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 配置 n_lag = 1 n_seq = 3 n_test = 10 # 准备数据 train, test = prepare_data(series, n_test, n_lag, n_seq) # 进行预测 forecasts = make_forecasts(train, test, n_lag, n_seq) # 评估预测 evaluate_forecasts(test, forecasts, n_lag, n_seq) # 绘制预测 plot_forecasts(series, forecasts, n_test+2) |
运行该示例首先会为每个预测的时间步长打印 RMSE。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
这为我们提供了每个时间步长的性能基准,这是我们期望 LSTM 能够超越的。
|
1 2 3 |
t+1 RMSE: 144.535304 t+2 RMSE: 86.479905 t+3 RMSE: 121.149168 |
还创建了原始时间序列与多步持续预测的图。线条连接到每个预测的适当输入值。
这种背景显示了持续预测的朴素程度。
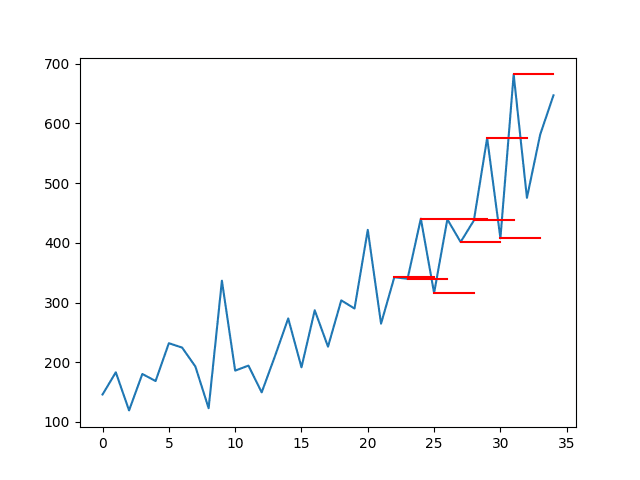
带有步骤持续预测的洗发水销售数据集的折线图
多步 LSTM 网络
在本节中,我们将以持续性示例为起点,并查看将 LSTM 拟合到训练数据并为测试数据集进行多步预测所需的更改。
2. 准备数据
在我们可以使用数据训练 LSTM 之前,必须先进行准备。
具体来说,需要进行另外两个更改:
- 平稳性。数据显示出增加的趋势,必须通过差分去除。
- 缩放。数据的大小必须减小到 -1 和 1 之间的值,这是 LSTM 单元的激活函数。
我们可以引入一个名为 difference() 的函数来使数据平稳。这将把值序列转换为差值序列,后者是更容易处理的表示。
|
1 2 3 4 5 6 7 |
# 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return Series(diff) |
我们可以使用 sklearn 库中的 MinMaxScaler 来缩放数据。
将这些放在一起,我们可以更新 prepare_data() 函数,使其首先对数据进行差分和重新缩放,然后像之前对持续性示例一样,执行转换为监督学习问题和训练测试集。
该函数现在除了训练集和测试集之外,还返回一个 scaler。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 将序列转换为监督学习的训练集和测试集 def prepare_data(series, n_test, n_lag, n_seq): # 提取原始值 raw_values = series.values # 将数据转换为平稳 diff_series = difference(raw_values, 1) diff_values = diff_series.values diff_values = diff_values.reshape(len(diff_values), 1) # 缩放值到 -1, 1 scaler = MinMaxScaler(feature_range=(-1, 1)) scaled_values = scaler.fit_transform(diff_values) scaled_values = scaled_values.reshape(len(scaled_values), 1) # 转换为监督学习问题 X, y supervised = series_to_supervised(scaled_values, n_lag, n_seq) supervised_values = supervised.values # 分割为训练集和测试集 train, test = supervised_values[0:-n_test], supervised_values[-n_test:] return scaler, train, test |
我们可以这样调用该函数
|
1 2 |
# 准备数据 scaler, train, test = prepare_data(series, n_test, n_lag, n_seq) |
拟合 LSTM 网络
接下来,我们需要将 LSTM 网络模型拟合到训练数据。
这首先要求将训练数据集从 2D 数组 [样本, 特征] 转换为 3D 数组 [样本, 时间步, 特征]。我们将时间步固定为 1,因此此更改很简单。
接下来,我们需要设计一个 LSTM 网络。我们将使用一个简单的结构,其中包含 1 个具有 1 个 LSTM 单元的隐藏层,然后是一个具有线性激活和 3 个输出值的输出层。该网络将使用均方误差损失函数和高效的 ADAM 优化算法。
LSTM 是有状态的;这意味着我们必须在每个训练周期结束时手动重置网络的状。网络将训练 1500 个周期。
训练和预测必须使用相同的批量大小,并且我们需要在测试数据集的每个时间步长进行预测。这意味着必须使用批量大小为 1。批量大小为 1 也称为在线学习,因为网络权重将在每次训练模式后(而不是 mini batch 或 batch 更新)更新。
我们可以将所有这些组合到一个名为 fit_lstm() 的函数中。该函数接受一些关键参数,这些参数可用于以后调整网络,并且该函数返回一个已拟合的 LSTM 模型,可用于预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 训练一个 LSTM 网络 def fit_lstm(train, n_lag, n_seq, n_batch, nb_epoch, n_neurons): # 将训练重塑为 [样本, 时间步, 特征] X, y = train[:, 0:n_lag], train[:, n_lag:] X = X.reshape(X.shape[0], 1, X.shape[1]) # 设计网络 model = Sequential() model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True)) model.add(Dense(y.shape[1])) model.compile(loss='mean_squared_error', optimizer='adam') # 拟合网络 for i in range(nb_epoch): model.fit(X, y, epochs=1, batch_size=n_batch, verbose=0, shuffle=False) model.reset_states() return model |
可以如下调用该函数:
|
1 2 |
# 拟合模型 model = fit_lstm(train, 1, 3, 1, 1500, 1) |
网络的配置尚未调整;您可以尝试不同的参数。
请在下面的评论中报告您的发现。我很想看看您能得到什么。
进行 LSTM 预测
下一步是使用已拟合的 LSTM 网络进行预测。
可以通过调用 model.predict() 来使用已拟合的 LSTM 网络进行单个预测。同样,数据必须格式化为 3D 数组,格式为 [样本, 时间步, 特征]。
我们可以将此包装到一个名为 forecast_lstm() 的函数中。
|
1 2 3 4 5 6 7 8 |
# 使用 LSTM 进行一次预测, def forecast_lstm(model, X, n_batch): # 将输入模式重塑为 [样本, 时间步, 特征] X = X.reshape(1, 1, len(X)) # 进行预测 forecast = model.predict(X, batch_size=n_batch) # 转换为数组 return [x for x in forecast[0, :]] |
我们可以从 make_forecasts() 函数调用此函数,并更新它以接受模型作为参数。更新版本如下所示。
|
1 2 3 4 5 6 7 8 9 10 |
# 评估持续模型 def make_forecasts(model, n_batch, train, test, n_lag, n_seq): forecasts = list() for i in range(len(test)): X, y = test[i, 0:n_lag], test[i, n_lag:] # 进行预测 forecast = forecast_lstm(model, X, n_batch) # 存储预测 forecasts.append(forecast) return forecasts |
更新后的 make_forecasts() 版本可以如下调用:
|
1 2 |
# 进行预测 forecasts = make_forecasts(model, 1, train, test, 1, 3) |
反转换
在进行预测后,我们需要反转换,将值恢复到原始尺度。
这是必需的,以便我们可以计算误差分数和与其他模型(如上面的持续预测)可比较的图。
我们可以直接使用提供 inverse_transform() 函数的 MinMaxScaler 对象来反转换预测的尺度。
通过将最后一个观测值(前几个月的洗发水销量)添加到第一个预测值,然后将该值向下传播到预测中,我们可以通过添加最后一个观测值来反转换差分。
这有点棘手;我们可以将此行为包装到一个名为 inverse_difference() 的函数中,该函数将最后一个观测值(在预测之前)和预测作为参数,并返回反转换后的预测。
|
1 2 3 4 5 6 7 8 9 |
# 反转换差分预测 def inverse_difference(last_ob, forecast): # 反转换第一个预测 inverted = list() inverted.append(forecast[0] + last_ob) # 使用反转换的第一个值传播差分预测 for i in range(1, len(forecast)): inverted.append(forecast[i] + inverted[i-1]) return inverted |
将这些放在一起,我们可以创建一个 inverse_transform() 函数,该函数遍历每个预测,首先反转换尺度,然后反转换差分,将预测恢复到其原始尺度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 对预测进行反数据转换 def inverse_transform(series, forecasts, scaler, n_test): inverted = list() for i in range(len(forecasts)): # 从预测创建数组 forecast = array(forecasts[i]) forecast = forecast.reshape(1, len(forecast)) # 反转缩放 inv_scale = scaler.inverse_transform(forecast) inv_scale = inv_scale[0, :] # 反转差分 index = len(series) - n_test + i - 1 last_ob = series.values[index] inv_diff = inverse_difference(last_ob, inv_scale) # 存储 inverted.append(inv_diff) return inverted |
我们可以使用预测来调用此函数:
|
1 2 |
# 对预测和测试进行反转换 forecasts = inverse_transform(series, forecasts, scaler, n_test+2) |
我们还可以反转换输出部分的测试数据集,以便我们可以正确计算 RMSE 分数,如下所示:
|
1 2 |
actual = [row[n_lag:] for row in test] actual = inverse_transform(series, actual, scaler, n_test+2) |
我们还可以简化 RMSE 分数的计算,使测试数据只包含输出值,如下所示:
|
1 2 3 4 5 6 |
def evaluate_forecasts(test, forecasts, n_lag, n_seq): for i in range(n_seq): actual = [row[i] for row in test] predicted = [forecast[i] for forecast in forecasts] rmse = sqrt(mean_squared_error(actual, predicted)) print('t+%d RMSE: %f' % ((i+1), rmse)) |
完整示例
我们可以将所有这些部分结合起来,将 LSTM 网络拟合到多步时间序列预测问题。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 |
from pandas import DataFrame from pandas import Series 从 pandas 导入 concat from pandas import read_csv from pandas import datetime from sklearn.metrics import mean_squared_error 从 sklearn.预处理 导入 MinMaxScaler from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 LSTM from math import sqrt from matplotlib import pyplot from numpy import array # 用于加载数据集的日期时间解析函数 def parser(x): return datetime.strptime('190'+x, '%Y-%m') # 将时间序列转换为监督学习问题 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols, names = list(), list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)] # 预测序列 (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [('var%d(t)' % (j+1)) for j in range(n_vars)] else: names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)] # 将它们组合在一起 agg = concat(cols, axis=1) agg.columns = names # 删除包含 NaN 值的行 if dropnan: agg.dropna(inplace=True) return agg # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i - interval] diff.append(value) return Series(diff) # 将序列转换为监督学习的训练集和测试集 def prepare_data(series, n_test, n_lag, n_seq): # 提取原始值 raw_values = series.values # 将数据转换为平稳 diff_series = difference(raw_values, 1) diff_values = diff_series.values diff_values = diff_values.reshape(len(diff_values), 1) # 缩放值到 -1, 1 scaler = MinMaxScaler(feature_range=(-1, 1)) scaled_values = scaler.fit_transform(diff_values) scaled_values = scaled_values.reshape(len(scaled_values), 1) # 转换为监督学习问题 X, y supervised = series_to_supervised(scaled_values, n_lag, n_seq) supervised_values = supervised.values # 分割为训练集和测试集 train, test = supervised_values[0:-n_test], supervised_values[-n_test:] return scaler, train, test # 训练一个 LSTM 网络 def fit_lstm(train, n_lag, n_seq, n_batch, nb_epoch, n_neurons): # 将训练重塑为 [样本, 时间步, 特征] X, y = train[:, 0:n_lag], train[:, n_lag:] X = X.reshape(X.shape[0], 1, X.shape[1]) # 设计网络 model = Sequential() model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True)) model.add(Dense(y.shape[1])) model.compile(loss='mean_squared_error', optimizer='adam') # 拟合网络 for i in range(nb_epoch): model.fit(X, y, epochs=1, batch_size=n_batch, verbose=0, shuffle=False) model.reset_states() return model # 使用 LSTM 进行一次预测, def forecast_lstm(model, X, n_batch): # 将输入模式重塑为 [样本, 时间步, 特征] X = X.reshape(1, 1, len(X)) # 进行预测 forecast = model.predict(X, batch_size=n_batch) # 转换为数组 return [x for x in forecast[0, :]] # 评估持续模型 def make_forecasts(model, n_batch, train, test, n_lag, n_seq): forecasts = list() for i in range(len(test)): X, y = test[i, 0:n_lag], test[i, n_lag:] # 进行预测 forecast = forecast_lstm(model, X, n_batch) # 存储预测 forecasts.append(forecast) return forecasts # 反转换差分预测 def inverse_difference(last_ob, forecast): # 反转换第一个预测 inverted = list() inverted.append(forecast[0] + last_ob) # 使用反转换的第一个值传播差分预测 for i in range(1, len(forecast)): inverted.append(forecast[i] + inverted[i-1]) return inverted # 对预测进行反数据转换 def inverse_transform(series, forecasts, scaler, n_test): inverted = list() for i in range(len(forecasts)): # 从预测创建数组 forecast = array(forecasts[i]) forecast = forecast.reshape(1, len(forecast)) # 反转缩放 inv_scale = scaler.inverse_transform(forecast) inv_scale = inv_scale[0, :] # 反转差分 index = len(series) - n_test + i - 1 last_ob = series.values[index] inv_diff = inverse_difference(last_ob, inv_scale) # 存储 inverted.append(inv_diff) return inverted # 评估每个预测时间步的 RMSE def evaluate_forecasts(test, forecasts, n_lag, n_seq): for i in range(n_seq): actual = [row[i] for row in test] predicted = [forecast[i] for forecast in forecasts] rmse = sqrt(mean_squared_error(actual, predicted)) print('t+%d RMSE: %f' % ((i+1), rmse)) # 在原始数据集的上下文中绘制预测 def plot_forecasts(series, forecasts, n_test): # 以蓝色绘制整个数据集 pyplot.plot(series.values) # 以红色绘制预测 for i in range(len(forecasts)): off_s = len(series) - n_test + i - 1 off_e = off_s + len(forecasts[i]) + 1 xaxis = [x for x in range(off_s, off_e)] yaxis = [series.values[off_s]] + forecasts[i] pyplot.plot(xaxis, yaxis, color='red') # 显示图表 pyplot.show() # 加载数据集 series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 配置 n_lag = 1 n_seq = 3 n_test = 10 n_epochs = 1500 n_batch = 1 n_neurons = 1 # 准备数据 scaler, train, test = prepare_data(series, n_test, n_lag, n_seq) # 拟合模型 model = fit_lstm(train, n_lag, n_seq, n_batch, n_epochs, n_neurons) # 进行预测 forecasts = make_forecasts(model, n_batch, train, test, n_lag, n_seq) # 对预测和测试进行反转换 forecasts = inverse_transform(series, forecasts, scaler, n_test+2) actual = [row[n_lag:] for row in test] actual = inverse_transform(series, actual, scaler, n_test+2) # 评估预测 evaluate_forecasts(actual, forecasts, n_lag, n_seq) # 绘制预测 plot_forecasts(series, forecasts, n_test+2) |
运行该示例首先会为每个预测的时间步长打印 RMSE。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
我们可以看到,在每个预测的时间步长上,分数都比持续性预测要好,在某些情况下甚至好得多。
这表明配置好的 LSTM 在此问题上确实具有预测能力。
有趣的是,正如预期的那样,均方根误差(RMSE)并没有随着预测范围的长度而逐渐变差。这一点在 t+2 比 t+1 更容易预测的事实中得到了体现。这可能是因为与系列中观察到的向上波动相比,向下波动更容易预测(这一点可以通过对结果进行更深入的分析来证实)。
|
1 2 3 |
t+1 RMSE: 95.973221 t+2 RMSE: 78.872348 t+3 RMSE: 105.613951 |
还创建了包含系列(蓝色)和预测(红色)的折线图。
该图显示,尽管模型的预测能力有所提高,但一些预测效果并不好,仍有很大的改进空间。
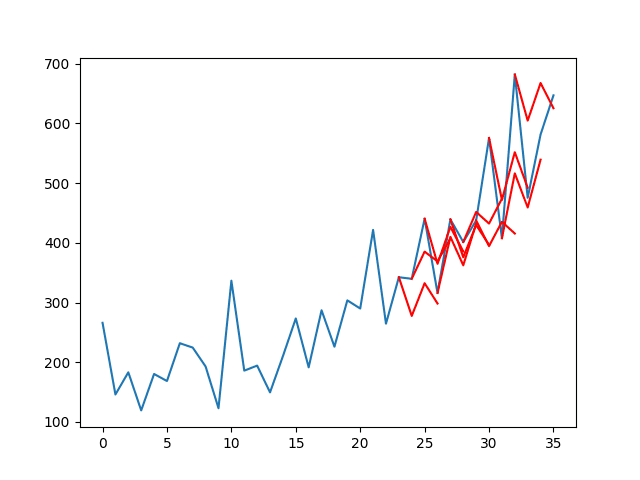
洗发水销售数据集的折线图与多步 LSTM 预测
扩展
如果您想深入研究本教程,可以考虑以下一些扩展。
- 更新 LSTM。将示例修改为在获得新数据后重新拟合或更新 LSTM。训练 10 个 epoch 应该足以用新的观测值重新训练。
- 调整 LSTM。对教程中使用的一些 LSTM 参数进行网格搜索,例如 epoch 数、神经元数和层数,看看是否能进一步提升性能。
- Seq2Seq。使用 LSTM 的编码器-解码器范例来预测每个序列,看看这是否能带来任何好处。
- 预测范围。尝试预测不同的时间范围,并观察网络在不同超前时间下的行为变化。
你尝试过这些扩展吗?
请在评论区分享您的结果;我很乐意倾听。
总结
在本教程中,您了解了如何为多步时间序列预测开发 LSTM 网络。
具体来说,你学到了:
- 如何为多步时间序列预测开发持久性模型。
- 如何为多步时间序列预测开发 LSTM 网络。
- 如何评估和绘制多步时间序列预测的结果。
关于使用 LSTM 进行多步时间序列预测,您有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






谢谢
你最棒了
没等多久。几天前在不同的博客上就有要求了
希望您觉得这篇文章有帮助!
我相信是的。这里的东西越来越深入了。
我们很快就会有用于多步预测的递归 LSTM 模型了吗?
会热切期待那篇博客。
谢谢
也许可以。
先生,
希望很快就能看到。
你好 Masum,
我正在网站(https://machinelearning.org.cn/multi-step-time-series-forecasting-long-short-term-memory-networks-python/)上学习 LSTM,并在留言板上找到了你。你对多步预测有什么想法吗?我运行了教程中的代码,但使用历史数据总是得到过度拟合的结果。
谢谢,期待您的回复。
当您使用递归 LSTM 模型进行预测时,能否获得相对精确的结果?
我发现很难获得令人满意的结果,也许我不太擅长这样训练模型。
您好,我完全是 RNN 和神经网络的新手。我有一个项目,需要用到 9 年的月度销售数据。我想应用 LSTM 来预测未来 6-7 个月。
我使用了 ARIMA 并获得了不错的准确度。但我想尝试 LSTM,因为我读了很多支持它的文章。
这是一个单一变量(包含 9 年月度销售历史数据)的稳定时间序列数据。
您能建议我从哪里开始学习吗?或者我应该直接将此博客用于我的数据吗?
您最早的回复将不胜感激。
感谢您所有的博客。它们真的很有帮助。
我建议从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
我不确定为什么您会用相同的参数多次调用以下内容?
model.fit(X, y, epochs=1, batch_size=n_batch, verbose=0, shuffle=False)
model.reset_states()
X 和 y 是否真的需要按 i 索引到不同的 epoch?
这是训练神经网络的标准过程,例如,多次 epoch 显示相同的数据集,在本例中我们是手动执行而不是由框架自动执行。
非常感谢这篇帖子。我从九月开始就一直在尝试这个,但没有取得好的结果。但我遇到了麻烦:我无法编译。也许您或有人能告诉我为什么会这样:运行代码时出现以下错误
TensorFlow 库没有针对 SSE 指令进行编译,但这些指令在您的机器上可用,并且可以加快 CPU 计算。
TensorFlow 库没有针对 SSE2 指令进行编译,但这些指令在您的机器上可用,并且可以加快 CPU 计算。
TensorFlow 库没有针对 SSE3 指令进行编译,但这些指令在您的机器上可用,并且可以加快 CPU 计算。
.
TensorFlow 库没有针对 SSE4.1 指令进行编译,但这些指令在您的机器上可用,并且可以加快 CPU 计算。
TensorFlow 库没有针对 SSE4.2 指令进行编译,但这些指令在您的机器上可用,并且可以加快 CPU 计算。
TensorFlow 库没有针对 AVX 指令进行编译,但这些指令在您的机器上可用,并且可以加快 CPU 计算。
显然这与 Tensorflow 有关(我阅读过有关此问题的信息,我认为是因为它不是从源代码安装的,但我不知道如何解决)。
先谢谢您了。
这些是警告,您可以忽略它们。
先生,
我们可以说这里使用了多种输出策略(避免了 1. 直接、2. 递归、3. 直接递归混合策略)吗?
我说的对吗?
我认为 LSTM 实现的是直接策略。
先生,
有什么办法可以使其成为迭代策略?任何代码示例都会很好。
这不就是一种多种输出策略吗?
据我理解,输出数量内置于模型中。您输入一个样本,它就会根据该样本返回整个输出。
该模型将生成一个向量输出。
编码器-解码器将逐个时间步输出。
您有 seq2seq 的代码吗?
是的,我的博客上有一些通用示例,您可以从这里开始
https://machinelearning.org.cn/start-here/#lstm
我在这本书中有用于时间序列预测的 seq2seq 示例
https://machinelearning.org.cn/deep-learning-for-time-series-forecasting/
您好,Jason,
您的文章非常有帮助!我有一个问题,如果数据序列是三维数据,第二行是输入数据,第三行是预测数据(都包含训练和测试数据),它们可以运行“差分”和“转换”吗?
非常感谢!
很好的问题。
您可能只想让预测变量保持平稳。考虑进行三项测试
– 按原样建模
– 输出变量平稳的建模
– 所有变量平稳的建模(如果其他变量不平稳)
我通过询问一些人发现了如何做到这一点。序列对象实际上是一个 Pandas Series。它是一个信息向量,带有一个命名的索引。然而,您的数据集除了时间序列索引之外,还包含两个信息字段,这使得它成为一个 DataFrame。这就是为什么教程代码在您的数据上会出错。
要将您的整个数据集传递给 MinMaxScaler,只需对两个列运行 difference(),然后将转换后的向量传递给缩放器。MinMaxScaler 接受一个 n 维 DataFrame 对象。
ncol = 2
diff_df = pd.concat([difference(df[i], 1) for i in range(1, ncol+1)], axis=1)
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_values = scaler.fit_transform(diff_df)
所以,通过这个,我们可以使用任意数量的变量。但现在我有一个大疑问。
当将数据集转换为监督学习问题时,我们在列中有一个分布,如https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/ 所示
我的意思是,对于您这样的 2 变量数据集,我们可以设置,例如,这些值
n_lags=1
n_seq=2
因此,我们将拥有一个如下的监督数据集
var1(t-1) var2(t-1) var1(t) var2 (t) var1(t+1) var2 (t+1)
所以,如果我们想训练 ANN 来预测 var2(这是我们想要预测的目标),并以 var1 作为输入,并且以前的 var2 值也作为输入,我们必须将它们分开,这就是我的疑问开始的地方。
在代码部分
def fit_lstm(train, n_lag, n_seq, n_batch, nb_epoch, n_neurons)
# reshape training into [samples, timesteps, features]
X, y = train[:, 0:n_lag], train[:, n_lag:]
X = X.reshape(X.shape[0], 1, X.shape[1])
我认为如果我们想定义 X,我们应该使用
X=train[:,0:n_lag*n_vars]
这意味着我们从上一个示例中选择 X
var1(t-1) var2(t-1)
(滞后数*变量数),所以:X=train[:,0:1*2]=train[:,0:2]
但是……
Y=train[:,n_lag*n_vars:] 是 ¿目标的向量?
问题是,通过这种方式,我们将以下内容选为目标
var1(t) var2(t) var1(t+1) var2(t+1)
所以我们包含了 var1(我们不打算预测它,只是用它作为输入)。
我想知道是否有解决方案可以解决这个问题,以便使用变量 1,2…n-1 作为输入,但不对其进行预测。
希望这很清楚 :/
感谢之前的澄清。我有一个关于“拟合网络”部分的疑问。我在尝试绘制训练图(验证 vs 训练)以查看网络是否过拟合时遇到了一些麻烦,但由于“model.reset_states()”语句,我只能从 history 语句中保存最后一个 loss 和 val_loss。有什么方法可以解决这个问题吗?
提前感谢 🙂
我回复我自己,如果有人也感兴趣的话。
只需创建 2 个列表(或 1 个,但我这样看更清楚),并在函数中返回它们。然后,在外部,只需绘制它们。抱歉提问,也许答案很明显,但我刚开始接触 Python,不是程序员。
# 拟合网络
loss=list()
val_loss=list()
for i in range(nb_epoch)
history=model.fit(X, y, epochs=1, batch_size=n_batch,shuffle=True, validation_split=val_split)
eqm=history.history[‘loss’]
eqm_val=history.history[‘val_loss’]
loss.append(eqm)
val_loss.append(eqm_val)
model.reset_states()
return model,loss,val_loss
# 拟合模型
model,loss,val_loss=fit_lstm(train, n_lag, n_seq, n_batch, n_epochs, n_neurons)
pyplot.figure()
pyplot.plot(loss)
pyplot.plot(val_loss)
pyplot.title(‘cross validation’)
pyplot.ylabel(‘MSE’)
pyplot.xlabel(‘epoch’)
pyplot.legend([‘training’, ‘test’], loc=’upper left’)
pyplot.show()
很高兴看到您取得了进展 jvr,做得好。
你好 jrv,
我知道现在很晚了,但我想知道您是否还有实现多变量解决方案的完整代码?
如果其他人有解决方案,可以将多变量和多滞后输入预测为单个列,我将非常乐意交流!
提前感谢
我在该主题上有很多新教程,您可以从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
调用 model.fit() 时会返回历史记录。
我们一次只拟合一个 epoch,因此您可以在 epoch 循环中检索并累积每个 epoch 的性能,然后在循环结束时处理数据(保存/绘图/返回)。
这有帮助吗?
这有帮助,谢谢。
现在我正在尝试寻找一种方法来加快训练过程并降低 RMSE,但这非常困难(目的是使结果优于 Matlab 神经网络工具箱中实现的 NARx 模型,但结果和计算时间很难克服)。
LSTM 通常需要比您想象的更长的训练时间,并且可以大大受益于正则化。
你好,
感谢精彩的教程,我想知道您能否帮助我澄清您为什么
model.reset_states()
(第 83 行)
在拟合模型时,我发现在没有这一行的情况下也能获得类似的结果。
谢谢!
它会清除 LSTM 的内部状态。
我尝试过使用和不使用 model.reset_states(),使用了一些其他的数据集。
我正在进行 6-10 步的多步预测,在不使用 model.reset_states() 的情况下我能获得更好的结果。
是我做错了什么,还是这完全取决于数据集?
提前感谢。
这完全取决于数据集和模型。
非常感谢。:)
感谢您快速回复 Jason :-)。我看到其他地方通过使用 model.fit 中的 callbacks 参数来重置状态。
class ResetStatesCallback(Callback):
def __init__(self):
self.counter = 0
def on_batch_begin(self, batch, logs={}):
if self.counter % max_len == 0:
self.model.reset_states()
self.counter += 1
然后回调的使用方法如下
model.fit(X, y, epochs=1, batch_size=1, verbose=2,
shuffle=False, callbacks=[ResetStatesCallback()])
ResetStatesCallback 代码片段来自
http://philipperemy.github.io/keras-stateful-lstm/
请告诉我您的想法。
谢谢!
是的,有很多方法可以实现重置。使用最适合您应用程序的方法。
你好 Jason,很棒的文章,我有一些问题
1. 在您的 fit_lstm 函数中,您重置了每个 epoch 的状态,为什么?
2. 为什么您自己迭代每个 epoch,而不是使用 model.fit(X, y, epochs)?
谢谢 Jason
# 训练一个 LSTM 网络
def fit_lstm(train, n_lag, n_seq, n_batch, nb_epoch, n_neurons)
# reshape training into [samples, timesteps, features]
X, y = train[:, 0:n_lag], train[:, n_lag:]
X = X.reshape(X.shape[0], 1, X.shape[1])
# 设计网络
model = Sequential()
model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(y.shape[1]))
model.compile(loss='mean_squared_error', optimizer='adam')
# 拟合网络
for i in range(nb_epoch)
model.fit(X, y, epochs=1, batch_size=n_batch, verbose=0, shuffle=False)
model.reset_states()
return model
epoch 结束是序列的结束,内部状态不应在下一个 epoch 的序列开始时延续。
我手动运行 epoch 以实现对重置发生时间的精细控制(默认情况下,它们在每个 batch 结束时发生)。
我想澄清 LSTM 示例中的第 99 行
—– plot_forecasts(series, forecasts, n_test+2)
Is the n_test + 2 == n_test + n_lag – n_seq?
谢谢,
J
我也想知道为什么使用 n_test + 2
我认为应该是 n_test + 2 == n_test+n_seq-1(与 n_seq 无关)。如果有人能澄清这一点,那就太好了。
M,你说得对。否则 RMS 会被错误计算,并且绘图会不对齐。
我也非常想知道为什么使用 n_test + 2
你好 jason,
当我将您的代码应用于 22 年的每日时间序列时,我发现 LSTM 预测结果与持久性预测结果相似,即红线只是一个水平线。我确定我没有搞砸这两种方法,我想知道是什么原因?
我的关键配置如下
n_lag = 1
n_seq = 3
n_test = 365*3
我的序列长度是 8035。
您需要调整模型以适应您的问题。
感谢您的教程,我这些天一直在调整 epoch 数和神经元数等参数。然而,我注意到您提到了网格搜索方法来获取合适的参数,您能否解释一下如何将其应用于 LSTM?我对我从其他教程中看到的模型类感到困惑,这似乎不熟悉。
请看这个关于如何手动进行 LSTM 网格搜索的示例
https://machinelearning.org.cn/tune-lstm-hyperparameters-keras-time-series-forecasting/
谢谢,我刚完成了一个测试。如果误差随着 epoch 的增加而剧烈震荡,而不是稳定下降,这说明了什么?我能更好地调整模型,还是 LSTM 不适用于这个时间序列?
您可能需要一个更大的模型(更多的层和/或更多的神经元)。
Jason,
感谢您的这些教程。这是网络上最好的教程。一个问题:预测最后两个值的最佳方法是什么?
谢谢你
谢谢 MM。
没有人能告诉你应用机器学习中做任何事情的“最佳”方法,你必须通过在你特定的问题上进行反复试验来发现它。
Jason,
明白了。请允许我重新表述一下这个问题。在实际应用中,人们会关注预测最后一个数据点,即在洗发水数据集,“3-12”。您会建议如何做到这一点?
将您的模型拟合到所有数据,然后调用 predict(),传入您的模型所需的任何滞后输入。
Jason,
plot_forecasts() 中启动偏移点的行应该是
off_s = len(series) – n_test + i + 1
而不是
off_s = len(series) – n_test + i – 1
嗨,Jason,
感谢您出色的教程!
我看了您的几篇关于 LSTM 的文章,学到了很多,但脑海中有一个问题:我能否在模型中引入一些干扰因素?例如,对于洗发水销售问题,可能有一些假日销售数据,或者事件发生后的销售数据。如果我想对这些事件之后的销售进行预测,我该怎么做?
更重要的是,我注意到您会使用解析器来解析日期/时间,但您并没有真正将时间特征引入模型。例如,我想预测下周一或明年一月的销售情况,我该如何输入时间特征?
谢谢!
是的,请参阅这篇关于添加附加功能的帖子。
https://machinelearning.org.cn/basic-feature-engineering-time-series-data-python/
感谢您的澄清。
我还有两个更具体的问题
1) 在 inverse_transform 中,为什么索引是 len(series) – n_test + i – 1?
2) 在 fit_lstm 中,您说“将训练重塑为 [samples, timesteps, features]”,但我认为第 74 行的代码与您的格式略有不同
73 X, y = train[:, 0:n_lag], train[:, n_lag:]
74 X = X.reshape(X.shape[0], 1, X.shape[1])
在第 74 行,我认为它应该是 X = X.reshape(X.shape[0], X.shape[1], 1)
您好 Michael,
是的,偏移量在原始时间序列中找到预测之前的一个步长。我在整个教程中都使用了这个模式。
在下一行我说:“我们将时间步长固定为 1,所以这个改变很简单。”
嗨,Jason,
首先,感谢您提供的所有精彩教程。
我正在详细地逐步分析这个例子,并且遇到了和 Michael 在 (2) 中提出的相同问题。恐怕我还不完全理解“我们将时间步长固定为 1”的说法。
我们需要 X 的维度为 [samples, timesteps, features]
因此,第 74 行不应该写成
X = X.reshape(X.shape[0], X.shape[1], 1) (如 Michael 所建议的)
我期望 X.shape[1] 与 n_lag 相同(即 timesteps),在这个例子中只有 1 个特征。
如果像您的例子中那样,timesteps = n_lag = n_features = 1,这不会有区别,但是,我尝试了 n_lag = 2。
对于 1 个特征和 n_lag = 2,我期望 X.shape 是 [n_samples, 2, 1],而代码给我的却是 [n_samples, 1, 2]。
提前感谢,Mark。
据我回忆,特征数量和时间步长都是 1。它们是等效的。
另外,这或许会有帮助
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
嗨,Jason,
我想知道如何用最少数量的模型来做短期和长期预测?
例如,我有一个 12 步输入和 12 步输出的模型 A,以及一个 12 步输入和 1 步输出的模型 B,模型 A 对第一个时间步的预测会比模型 B 好吗?
更重要的是,如果我们有一个 1 步输入和 1 步输出的模型,它对长期预测更容易出错。
如果我们有一个多步输入和 1 步输出的模型,它仍然更容易出错于长期预测。那么如何看待长期和短期预测?
我建议针对不同的用例开发和评估每个模型。我发现 LSTM 在实践中相当不受假设和经验法则的影响。
您好,感谢您的教程
如果我的预测模型是三个时间序列 a、b、c,我想用 a、b、c 来预测未来的 a,我该如何构建我的 LSTM 模型?
非常感谢!
a、b 和 c 中的每一个都将是输入特征。请记住,输入数据的形状或维度是 [samples, timesteps, features]。
数据平稳化对 LSTM 真的有帮助吗?如果有,其直觉是什么?我的意思是,我能理解为什么这对 ARIMA 类方法来说是这样,但为什么对 LSTM 呢?
是的,根据我的经验,主要是因为它是一个更简单的预测问题。
我建议尝试几种不同的序列“视图”,看看哪种最容易建模/能获得最佳的模型技能。
嗨,Jason,
我想用以下输入大小的模型进行训练:[6000, 4, 2]([samples, timestamps, features])
例如,我想预测未来两年的洗发水销量。如果我有经济指数等其他特征,我能否将销售数据和指数数据以上述格式连接起来?那么我的输入将是一个 3D 向量。我应该如何修改模型来训练?
我总是遇到这样的错误:ValueError: Error when checking target: expected dense_1 to have 2 dimensions, but got array with shape (6000, 2, 2)。
错误来自这一行:model.fit(X, y, epochs=1, batch_size=n_batch, verbose=0, shuffle=False)。您能提供一些建议吗?谢谢!
重新调整数据以使其成为 [6000, 4, 2]。
将网络的输入形状更新为 (4,2)。
调整您想要预测的输出序列的长度。
先生,
要用 LSTM 进行一次预测,如果我们这样写
oneforecast = forecast_lstm(model, X, n_batch)
它显示:未定义的 X
X 的值应该是什么?我们知道模型和 n_batch 的值?
你能帮忙吗?
X 将是进行预测所需的输入序列,例如滞后观测值。
先生,
如果我想让模型从训练数据(这里是 23 个样本)学习,并且只想预测 3 个时间步(1 月、2 月、3 月),该怎么办?我想在这种情况下避免使用持久化模型,并且只要求 3 步直接策略。希望您理解了。
任何帮助都将不胜感激。
训练(过去数据)= 预测(1月、2月、3月)
也许我误解了,但这正是教程中提出的模型。它预测 3 个时间步。
# 评估持续模型
def make_forecasts(model, n_batch, train, test, n_lag, n_seq)
forecasts = list()
for i in range(len(test))
X, y = test[i, 0:n_lag], test[i, n_lag:]
# 进行预测
forecast = forecast_lstm(model, X, n_batch)
# 存储预测结果
forecasts.append(forecast)
return forecasts
在这里,如果我想对 3 个步骤(1 月、2 月、3 月)进行一次预测,我需要更改什么。我不需要这个月的其余部分(4 月、5 月、6 月、7 月、8 月……12 月)。一次预测或 3 步预测。
希望您明白了。
传入进行这 3 个月预测所需的输入即可。
先生,
能否请您再简化一点?
我没明白。
在加载 CSV 文件数据时,我遇到了日期解析错误。
错误是
ValueError: time data '1901-Jan' does not match format '%Y-%m'
有人能帮我解决这个问题吗?
很抱歉听到这个消息。请确认您已精确复制代码,并且数据文件中没有额外的页脚信息。
你好
我遇到了这个问题
我已从文本中的链接下载了数据集
我认为这个错误发生是因为我们 CSV 文件中的数据格式不正确!
谁能给我数据集,拜托??
这是准备好的原始数据。
先生,
我遇到了同样的问题。如何修复解析器以解决此错误?
您选择的数据 csv 是用“,”分隔的,如果是“;”则无法工作。
我遇到了同样的问题。对我来说,问题在于 CSV 文件中的第一列(“m-y”)默认设置为“1-Jan, 1-Feb, …. , 3-Dec”,并且无法与“‘%Y-%m’”匹配。
但是,通过在 Excel 中手工制作日期列,在日期前加上一个“‘”,解决了这个问题。例如:‘1-01, ‘2-01 .. 等。
希望这能帮助到未来的人。🙂
也许您下载的数据集格式不正确?
这是我自己的 GitHub 帐户中的原始数据。
https://raw.githubusercontent.com/jbrownlee/Datasets/master/shampoo.csv
@Jason,
数据文件没有页脚,我只是复制粘贴了代码,但 dateparser 抛出了错误。我不知道为什么它表现得如此奇怪。
抱歉,我没有什么好主意。可能是 Python 环境问题?
嗨,Jason,
再次精彩的解释。我有一个关于这段代码的疑问
# 评估持续模型
def make_forecasts(model, n_batch, train, test, n_lag, n_seq)
forecasts = list()
for i in range(len(test))
X, y = test[i, 0:n_lag], test[i, n_lag:]
# 进行预测
forecast = forecast_lstm(model, X, n_batch)
# 存储预测结果
forecasts.append(forecast)
return forecasts
为什么您将“n_seq”参数传递给函数,而它在函数内部没有使用?
说得对,谢谢。
你好,
我该如何预测一整月?(假设我有每日数据)。
假设我有大约 5 年的数据,1.8k 个数据点用于训练。
我想使用一年前的数据来预测下个月的全部情况?
为了做到这一点,我应该改变这个模型的训练方式吗?
我的理解是否正确,即这个模型试图仅通过当前值来预测下一个值?
是的,将数据框定为预测一个月,然后训练模型。
模型可以输入您想要的任何内容,例如,过去一个月或一年的序列。
嘿,感谢您的回复。
这篇帖子真的帮到我了。
现在下一个问题是如何增强它以在预测中考虑外部变量?
如果我只是在这个步骤中添加外部变量值
train, test = supervised_values[0:-n_test], supervised_values[-n_test:], (显然在 model fit 中进行适当的 batch_input_shape 更改)。
这有助于提高预测吗?
添加自变量的正确方法是什么?
我已阅读了您关于此主题的帖子。
https://machinelearning.org.cn/basic-feature-engineering-time-series-data-python/
这很有帮助,但如何使用具有 LSTM 的神经网络来做到这一点?
您能给我指明正确的方向吗?
可以向模型直接提供附加功能作为新功能。
请参阅此关于构建问题的帖子,然后重塑结果。
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
您好 Jason,感谢您写下如此详细的解释。
我正在为一个时间序列预测问题使用 LSTM 层。
一切都很好,除了当我尝试使用 inverse_transform 来撤销数据的缩放时。我收到了以下错误。
ValueError: Input contains NaN, infinity or a value too large for dtype(‘float64’).
不确定如何解决这个问题。您能帮我一下吗?
看起来您正在尝试对 NaN 值执行逆变换。
也许尝试使用 print 语句来帮助追踪 NaN 值来自哪里。
感谢您的回复。是的,我的预测中确实有一些 NaN 值。这是否表明模型训练不当?
您的模型可能正在接收 NaN 作为输入,请检查一下。
如果输入正常,模型也可能产生 NaN 预测,在这种情况下,它可能在训练过程中遇到了困难。有一些方法,如梯度裁剪,可以解决这个问题。
https://keras.org.cn/optimizers/
但首先要弄清楚是哪种情况。
谢谢!我的输入没有 NaN。我会看看梯度裁剪。
Kiran,让我知道进展。
嗨 Jason
我遇到了数据文件格式问题和 Kiran 遇到的类似 NaN 问题。
我下载的文件格式没有 19 的格式。
例如:
Month,Sales of shampoo over a three year period
01-Jan,266
所以我修改了 parser(),使其只返回 x 本身。
然后在 Multi-Step LSTM Network 上,我得到了以下 NaN。
ipdb> series
月份
01-Jan 266.0
…
03-Nov 581.3
03-Dec 646.9
NaN NaN
Sales of shampoo over a three year period NaN
Name: Sales of shampoo over a three year period, dtype: float64
我更改了调用以使用 skipfooter,例如:
series = read_csv(‘shampoo-sales.csv’, header=0,skipfooter=2, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
网络运行了,但实现了略有不同的训练 RMSE。
t+1 RMSE: 97.719515
t+2 RMSE: 80.742075
t+3 RMSE: 110.313295
干得好!
考虑到该方法的随机性,这些差异是相当小的。
https://machinelearning.org.cn/randomness-in-machine-learning/
嗨,Jason,
我遇到了类似的问题。我的 train_x 中的所有输入都不是 nan,但一旦我进行训练,并且打印 train_predict,它会给我一整串 nan 值。我也收到了这个错误。
ValueError: 输入包含 NaN、无穷大或对于 dtype('float32') 来说太大的值。
请帮忙……
注意:我正在使用日期和值的数据集,格式如下(每日而不是每月),因为我想预测每日值:不确定这是否会影响代码中的任何内容。
2013-12-02,3840457
2013-12-03,3340470
2013-12-04,3356629
2013-12-05,3324450
2013-12-06,3275983
2013-12-07,2968327
我有大约 1500 条记录。
您必须在建模之前对数据进行缩放。
我在建模前已经规范化了数据。我做了和您在这段代码中为 LSTM 预测所做的一模一样。唯一的区别是我的数据是每日的,而不是每月的。
这是我的 train_x 在构建模型之前的样子。
train_x
[[[0.939626 ]
[0.9441713 ]
[0.93511975]
…
[0.5557002 ]
[0.5948241 ]
[0.5920827 ]]
[[0.9441713 ]
[0.93511975]
[0.9214866 ]
…
[0.5948241 ]
[0.5920827 ]
[0.5772988 ]]
有趣的是您会遇到 NaN。也许模型需要进一步的调整,进行实验看看能否更多地了解它为什么会发生。
嗯,或者,
我只是使用了另一个示例中的相同模型和数据框准备(关于航空公司乘客),然后我调用了这里的 make_forecast 函数,并将 testX 集作为输入(所以我想它正在使用 testX 的最后一个值来预测未来……?),并且我还调用了我们在此示例中构建的模型。
它进行了预测……但出于某种原因,预测值持续增加,即使这些数据非常有周期性,它会上下波动。——这很奇怪,因为当我们验证模型时,准确性非常令人印象深刻。但现在当我尝试预测未来几个时间步时,它的准确性差了很多,而且它只是在向上走……。
我该如何解决这个问题?我的方法是错误的吗?
非常感谢您的回复——这对您真的很有帮助。
我建议针对问题调整模型。
另外,我的预测在大约 25-30 个时间步后会变得几乎恒定。
嗨,Jason,
当我尝试分步预测时。也就是说,预测 1 个点,然后将其作为数据使用并预测下一个点,我的预测在仅 2 个时间步后就变得恒定,有时从一开始就是如此。
https://datascience.stackexchange.com/questions/22047/time-series-forecasting-with-rnnstateful-lstm-produces-constant-values
详细介绍了其中的内容。您能解释一下为什么会发生这种情况吗?哪种预测方法通常更好?逐步预测还是窗口式预测?
另外,何时 ARIMA/线性模型可能比网络/RNN 表现更好?
使用预测作为输入是不好的,因为错误会累积。只有在无法获取真实观测值时才这样做。
如果您的模型具有线性关系,那么使用线性模型(如 ARIMA)进行建模会更好,模型将训练得更快且更简单。
但是 ARIMA 模型不就是这样预测的吗?
它们是逐点预测。根据我的结果,ARIMA(或 STL ARIMA 甚至 XGBOOST)在与 RNN 相比时表现相当不错。🙁
但我没有考虑平稳性和异常值处理,我发现 RNN 在数据非平稳/有异常值时表现很差。
这是预期的吗?我读过 RNN 应该能自动处理平稳性?
另外,如果我们对数据进行一阶差分,即使数据不存在平稳性,结果也会很糟糕吗?
在规范化方面,是否有可能在某些情况下 RNN 在没有规范化的情况下也能表现良好?
何时通常推荐规范化?当标准差很大时?
我发现 RNN 在自回归问题上表现不佳,它们在更多的数据预处理(例如,去除任何系统性东西)方面表现更好。请参阅此帖子。
https://machinelearning.org.cn/suitability-long-short-term-memory-networks-time-series-forecasting/
通常,如果您不需要,则不要进行差分,但请测试所有内容以确保。
如果分布是高斯的,则进行标准化,否则进行归一化。RNN(如 LSTM)需要良好的数据缩放,MLP 则不太需要,尤其是在 ReLU 时代。
哦,那么使用 ARIMA 残差的混合模型进行 RNN 应该效果很好吧?🙂
残差将没有任何季节性成分。(即使缩放也应该得到很好的处理)。
或者在这里您也期望 MLP 表现更好吗?
很难确定,我建议使用实验来收集数据以确切了解,而不是猜测。
我认为在进行多步预测的逆差分时存在问题(以处理非平稳数据)。
此示例将先前预测的(并已进行逆差分)值添加到当前预测值。如果我们有30个点需要预测,这种方法是否是错误的,因为它会不断累加结果,从而导致输出持续增加?
下面是我得到的结果。
https://ibb.co/d1oyNF
我是否应该只将最后一个已知的真实观测值添加到所有预测值中?我猜这可能也不奏效。
对于长超前时间,这可能是一个问题,因为误差会累积。
如果真实观测值可用于逆差分,您将不需要进行如此长的超前时间预测,该问题也就无关紧要了。
考虑对比有差分和无差分的模型技能,至少作为起点。
你好,感谢你精彩的教程。
关于序列到序列的时间序列预测问题,我有一个关于多步 LSTM 的问题。
我创建了一个监督数据集,包含 (t-1), (t-2), (t-3)…, (t-look_back) 和 (t+1), (t+2), (t+3)…, (t+look_ahead),我们的目标是预测 look_ahead 个时间步。
我们尝试了你完整的示例代码,将最后一个层设置为 Dense(look_ahead),但结果并不理想。这是使用有状态和无状态网络都进行的。
然后我们尝试使用 Dense(1) 再 repeatvector(look_ahead),我们得到所有 look_ahead 时间步的(平均)相同值。这是使用无状态网络进行的。
然后我创建了一个逐步预测,其中 look_ahead 始终为 1。那么 t+2 的预测是基于 (t+1)(t)(t-1)… 的历史。这给了我更好的结果,但只尝试了无状态网络。
我的问题是
– 使用非状态网络是否可以与 repeatvector 一起使用?或者网络必须是有状态的?您是否知道我的预测值为何都相同?
– 您推荐哪种网络来处理这类问题?有状态还是无状态,序列到序列还是逐步预测?
提前感谢!
Sandra
Sandra,你的工作很棒,谢谢分享。
RepeatVector 仅用于编码器-解码器架构,以确保输出序列中的每个时间步都能访问编码器中的整个固定宽度编码向量。它与有状态或无状态模型无关。
我会开发一个简单的 MLP 基线,并带有向量输出,并挑战所有 LSTM 架构来超越它。我会查看简单 LSTM 和序列到序列模型的向量输出。我也会尝试递归模型(将输出作为输入重复一步预测)。
听起来你正在尝试所有正确的事情。
现在,说了这么多,LSTM 可能不擅长简单的自回归问题。我经常发现 MLP 在自回归方面的表现优于 LSTM。请参阅这篇帖子
https://machinelearning.org.cn/suitability-long-short-term-memory-networks-time-series-forecasting/
希望这有帮助,请告诉我进展如何。
嗨,Jason,
感谢您的教程。我正在学习机器学习,您的网站非常有帮助!
我对 inverse_difference 函数有点困惑。特别是需要传递的 last_ob。
假设我有以下数据
原始数据 差分 缩放后的预测值
raw_val1=.4
raw_val2=.35 -.05 -.045 [0.80048585, 0.59788215, -0.13518856]
raw_val3=.29 -.06 -.054 [0.65341175, 0.37566081, -0.14706305]
raw_val4=.28 -.01 -.009 [[0.563694, -0.09381149, 0.03976132]
当将 last_ob 传递给 inverse_difference 函数时,我需要将哪个观测值传递给函数,raw_val2 还是 raw_val1?
我的猜测是我需要传递 raw_val2。这正确吗?
另外,在您的示例中,在这一行
forecasts = inverse_transform(series, forecasts, scaler, n_test+2)
为什么是 n_test+2 呢?
提前感谢!
Oscar
嗨,Jason,
做得很好。
我有一个问题。在为 lstm 重塑 X 时(样本数,时间步长,特征数),为什么您将问题建模为时间步长=1 和特征数=X.shape[1]?难道不应该是时间步长 = 滞后窗口大小
并且输出的密集层应该具有视野窗口的大小。我认为这样会得到更好的结果。
这是一个链接,可以更清楚地说明我的问题
https://stackoverflow.com/questions/42585356/how-to-construct-input-data-to-lstm-for-time-series-multi-step-horizon-with-exte
我以没有时间步长和大量特征(同一时间点的多个观测值)的方式对问题进行建模。
我发现,如果以多个时间步长和多个特征来构建问题,性能会更差。基本上,我们在这里将 LSTM 用作 MLP 型网络。
LSTM 在自回归方面并不擅长,但这篇帖子是我有过最多人询问的。
更多关于 LSTM 适用性的信息在这里
https://machinelearning.org.cn/suitability-long-short-term-memory-networks-time-series-forecasting/
所以 Jason,
如果我没理解错的话,RNN+LSTM 学习随时间(隐藏状态取决于过去的值)的全部意义在这里就消失了。
本质上,这只是一个自回归神经网络。没有随时间的存储状态。
是的,没有 BPTT,因为我们只输入一个时间步。
您可以添加更多历史数据,但结果会更差。事实证明,LSTM 在自回归方面很差
https://machinelearning.org.cn/suitability-long-short-term-memory-networks-time-series-forecasting/
尽管如此,我还是收到很多人询问如何做到这一点,所以在这里分享。
嗨,我尝试使用这个例子来识别形状变化的角度,这个教程有用吗?我应该如何测试我训练的模型?
此致,
Hanen
嗨——我喜欢你的博客和这些教程!它们非常有帮助。
我一直在学习这个教程和这个教程:https://machinelearning.org.cn/time-series-prediction-lstm-recurrent-neural-networks-python-keras/。
我已经将两个代码应用到我正在处理的一个简单数据集中(日期、ROI%)。两个代码都能很好地处理我的数据,但我遇到了一个让我完全困惑的问题
使用此代码,我能够实际预测未来的 ROI%。而使用另一个代码,它在建模历史数据方面做得更好,但我无法弄清楚如何让它预测未来。两个代码都有我需要的元素,但我似乎无法弄清楚如何将它们结合起来。
任何见解都将是极好的!谢谢!
问题究竟是什么?
Jason,首先,我想感谢您所做的工作。它非常有帮助。
我有一个问题,正在寻求您的专家意见。
如何处理一个具有多个且可变粒度输入的单时间步长的时间序列数据集。例如,考虑下面的数据集
日期 | 区域 | 产品类别 | 订单 | 收入 | 成本
因此,在这种情况下,一天会有多个记录,按日期汇总,这也是我想要的粒度。
应该如何处理这类数据,因为这些特征将贡献于收入和订单?
您可以标准化数据并将其输入一个模型,或者构建单独的模型并组合它们的预测。
尝试几种方法,看看哪种最适合您的问题。
我正在使用这个框架进行第一次 LSTM 网络尝试,用于监控网络响应时间。我目前正在处理的数据是通过模拟 API 调用随机生成的。我看到 LSTM 似乎总是预测会回到看起来像数据均值的地方。这是随机数据的一个特性吗?
另外一个问题:由于 LSTM 的神经元内置了记忆组件,使用较大的 n_in/n_lag(大于 1)有什么优点/缺点?
问题可能对您的模型来说太难了,也许可以调整 LSTM 或尝试其他算法?
LSTM 的一个关键优势是它们的滞后可以比其他方法长得多,例如数百个时间步。这意味着您正在模拟这样的东西
yhat = f(t-1, …, t-500)
并且模型可以根据需要重现它在 500 个时间步之前看到的东西。
谢谢。我现在正在使用一些玩具数据,只是为了确保我理解它是如何工作的。
我能够很好地用 5 个神经元、100 个 epoch 的训练运行来模拟余弦波,处理 np.cos(range(100)) 并将其分成 80/20 的训练集。这是在进行缩放但没有进行差分的情况下。我输入 10 个输入,得到 30 个输出。
调用 model.predict 会改变模型吗?我用相同的 10 个输入反复调用,每次都得到不同的结果。看起来预测的波形在不同的幅度之间循环。
啊,明白了。由于 stateful 为 True,我需要在预测之间显式调用 reset_states()。有道理,我想!Stateful 对于训练很有用,但由于我不会进行“在线学习”,并且我会在特征中馈送滞后,因此在预测时不应该依赖状态。
干得好!
是的,通常缩放很重要,但如果您的余弦波值在 [0,1] 范围内,那么您就没问题了。
我有一个简单的问题。我试图设置一个不同的玩具问题,数据生成方式为 y=x,共 800 个点(保留接下来的 200 个作为验证集)。无论我训练多少层、多少神经元、多少个 epoch,结果似乎都是预测值在较低值时接近直线,但在较高值时迅速发散并接近某个固定值 y=400。
您对此有何看法?
可能是误差累积。您给 LSTM 带来了麻烦。
您能否就我遇到的这个问题提供一些意见?我真的很想确保我没有错误地实现。如果我需要调整网络参数,我可以进行练习。但是,我对我在这条正确的道路上的情况没有信心。 https://stackoverflow.com/questions/45982445/keras-lstm-time-series-multi-step-predictions-has-same-output-for-any-input
你好,代码有问题。在进行数据处理时,即计算差分和最小-最大缩放。您不应该使用所有数据。在更真实的情况下,您只能对训练数据进行此操作。因为您不了解测试数据。
所以我修改了代码,将最后 12 个月作为测试集。然后只使用 24 个月的数据进行差分、最小-最大缩放、拟合模型并预测第 25、26、27 个月。
然后我继续使用 25 个月的数据进行差分、最小-最大缩放、拟合模型并预测第 26、27、28 个月。
…
最终结果比基线差!
没错,这是我为保持教程简短易懂而进行的简化。
Jason,您好,我使用自定义损失函数(加权 MSE)取得了一些更好的结果
def weighted_mse(yTrue,yPred)
ones = K.ones_like(yTrue[0,:])
idx = K.cumsum(ones)
return K.mean((1/idx)*K.square(yTrue-yPred))
功劳归于 Stack Overflow 上的 Daniel Möller,因为我无法自己弄清楚张量修改步骤,他在那里回答了我的问题
干得漂亮!感谢分享。
def make_forecasts(model, n_batch, train, test, n_lag, n_seq)
forecasts = list()
for i in range(len(test))
X, y = test[i, 0:n_lag], test[i, n_lag:]
# 进行预测
forecast = forecast_lstm(model, X, n_batch)
# 存储预测结果
forecasts.append(forecast)
return forecasts
如果“train”数据集作为参数传递给这个函数,但它没有被使用,那么它的作用是什么?
谢谢
是的,看起来它没有被使用。你可能可以删除它。
您好,这是一个非常有用的教程。我是 Python 和编程的初学者。我能否将模型的输入转换为 4 个或更多变量?并且将 n_batch 更改为非 1 的其他数字?
当然可以。
但是,当我更改 n_batch 大小时,模型就不工作了。另外,您手动指定了模型的 epoch,您能否告诉我如何做?
嗨,Jason,
非常感谢您关于 LSTM 的教程。
您对如何为多元多步预测建模网络有什么建议吗?我读了您关于多元预测和多步预测的文章,但将两者结合起来似乎更棘手,因为密集层的输出维度会更高。
用您这里的例子来说:如果我想在 T 时间步后预测洗发水和牙膏的销售量,我该如何实现预测维度为 2xT?密集层有替代方案吗?
我明白了。您可以在网络的输出层中有两个神经元,就这样。
感谢这个精彩的教程。您认为这项技术适用于多对多预测吗?
一个玩具场景:想象一台机器有 5 个调谐旋钮 [x1, x2, x3, x4, x5],作为结果,我们可以读出 2 个值 [y, z],作为对任何旋钮变化的响应。
我想知道我是否可以使用 LSTM 来预测 y 和 z,用一个模型而不是为 y 构建一个模型,为 z 构建另一个模型?我计划遵循这个教程,但我很想听听您对此的看法。
是的,LSTM 可以轻松配置为支持多个输入序列并输出一个向量或并行序列。
例如,要将多个序列作为输入,请参阅这篇帖子
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
嗨 Jason,非常感谢您的教程。我刚开始学习 LSTM,您关于 LSTM 的系列非常有价值。
关于多输出预测的一个问题:如何处理多输出时绘制真实数据与预测数据的对比。
假设我有一个模型来预测接下来的 10 个时间步(t, t+1…,t+9)。
使用时间 t 的观测值
–> t=0,模型将给出 t=1,2,3,4,5,6,7,8,9,10 的预测
同样,在
–> t=1,将输出 t=2,3,4,5,6,7,8,9,10,11 的预测
等等…
从 t=0 和 t=1 的预测在时间步上有重叠。例如,如果我想知道 t=2 的值,我应该使用 t=1 的预测还是 t=0 的预测,或者预测的加权平均值?
也许只使用 t=1 的预测就足够了,因为它已经包含了时间序列的历史(即它已经包含了 t=0 的观测值)。
我不确定我是否理解。也许您最好先从线性模型开始,然后迁移到 LSTM 以提高在已经奏效的框架/问题上的技能。
https://machinelearning.org.cn/start-here/#timeseries
你好 Jean-Marc
“例如,如果我想知道 t=2 的值,我应该使用 t=1 的预测还是 t=0 的预测,或者预测的加权平均值?”
我也有同样的问题,您知道如何解决这个“重叠”问题吗?
我不确定我是否理解,您能详细说明您想通过一个例子来实现什么吗?例如,输入和输出?
The
return datetime.strptime('190'+x, '%Y-%m')
它给我
ValueError: time data ‘1901/1’ does not match format ‘%Y-%m’
提前感谢
请确认您下载了 CSV 格式的数据集。
所以您实际上不需要将数据分割成测试集和训练集,因为您在这段代码中不使用训练集。那么这就变成了一个无监督问题吗?
不,这是一个有监督学习模型。
我们使用前向验证。在此处了解更多信息
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
这是我的错,我当时只看了多步持久性模型。谢谢!
不客气。
抱歉,我对 inverse_transform 函数感到困惑,为什么您在函数中使用 n_test+2 而不是 n_test?
嗨,Jason,
非常感谢您发表如此精彩的博文!
您解释说将使用“滚动预测场景”,也称为前向模型验证。您说“测试数据集的每个时间步将逐一进行。将使用一个模型来预测该时间步,然后将从测试集中获取下一个月的实际预期值,并将其提供给模型以进行下一个时间步的预测”。
在这种没有此类测试/验证数据的情况下,您会建议使用哪种方法/算法?换句话说,我有一系列时间序列数据,在某个点停止了,我需要预测接下来的点。
提前感谢您的建议!
上面,我正在描述如何在训练期间评估模型。您正在描述如何在模型经过评估和选择后,使用最终模型对新数据进行预测。
这是不同的活动。
请参阅此帖以弄清情况
https://machinelearning.org.cn/train-final-machine-learning-model/
嗨,Jason,
感谢这个精彩的教程。我正在尝试解决一个问题,并希望得到您的意见,该问题大致如下。我拥有两年的每日销售数据,以及一些其他预测变量,如节假日、促销等。假设从2015年1月到2017年1月。我想预测2月份。我正在考虑数据准备,将过去60天的数据作为输入序列,并预测接下来的30个时间步。由于数据集非常小,您认为这会奏效吗?您有什么建议?
试试看。
通常,除非您有大量数据或问题相对简单,否则提前预测30天是非常困难的。
是的,这也是我的担忧。因为数据集非常小。
Bryant 2017年10月24日晚上8:12 #
我有两个问题:
1.在此示例中,导出了三个RMSE。如果我想输出每个时间步的三个预测并将所有输出整合到一个数据框(易于观察)中,我该怎么办?
2.如果我需要进行6个月、12个月的预测,该如何更改?
抱歉,我的Python不是很好。
非常感谢!
这篇帖子将帮助您更好地理解如何使用LSTM进行预测
https://machinelearning.org.cn/make-predictions-long-short-term-memory-models-keras/
嗨,Jason,
我正在学习您的教程,但在“prepare_data”函数中的重塑时遇到了问题。
我目前使用的数据形状如下
(156960, 3)
但是prepare_data函数中的重塑告诉我这个
ValueError 回溯 (最近一次调用)
in ()
—-> 1 train, test = prepare_data(X, 15696, 2, 4)
在prepare_data(series, n_test, n_lag, n_seq)
3 # 提取原始值
4 raw_values = series.values
—-> 5 raw_values = raw_values.reshape(len(raw_values), 1)
6 # 转换为监督学习问题 X, y
7 supervised = series_to_supervised(raw_values, n_lag, n_seq)
ValueError: cannot reshape array of size 470880 into shape (156960,1)
这个数组大小470880是156960(我的数据长度)的三倍。
您能给我一些建议如何解决这个问题吗?
这篇帖子将帮助您理解如何为LSTM重塑数据
https://machinelearning.org.cn/reshape-input-data-long-short-term-memory-networks-keras/
嗨,Jason,
我是机器学习的初学者。这些教程对我学习和提高帮助很大。非常感谢您发布您所有的探索。
现在我有一个问题想问您,
本例中有36个月的数据。现在我需要知道第37个月的预测。我该如何在模型中进行预测?
在预测之前,我是否应该重塑新值,还是直接将新数据注入预测模型?
例如。
new_data = 145
predicted_output = model.predict(new_data, verbose = 0)
(或者)
new_data = 145
x = x.reshape(1,1,1)
predicted_output = model.predict(x, verbose = 0)
(或者)
我们是否需要任何其他方法来做到这一点?
注意:根据您的回答,我想预测4个月。
提前感谢您的时间和帮助
这篇帖子提供了更多关于如何重塑输入数据的建议
https://machinelearning.org.cn/reshape-input-data-long-short-term-memory-networks-keras/
这篇帖子展示了如何为最终的LSTM模型进行预测
https://machinelearning.org.cn/make-predictions-long-short-term-memory-models-keras/
谢谢你的回复。
当我保存模型并尝试预测已加载的模型时,我看到两个不同的预测结果。
但是,在保存模型之前无限次运行模型时,预测结果是相同的。
使用已保存和加载的模型,每次运行已加载的模型时,结果都是相同的预测输出。
问题是,在保存模型之前提供的结果与已加载的模型不匹配/不相同。
看起来在保存模型时,训练模型内部发生了某些变化。
在保存模型之前,它提供98%的准确率。而在保存模型后,当尝试预测时,它给出90%的准确率。
您能否帮助我弄清这个疑问。我已在此处提供代码片段及输出。此保存和加载模型的代码片段来自同一个Python程序,而不是多个Python脚本。
注意:我正在尝试使用不同的数据集,该数据集包含小数价格,与本教程数据集类似。
程序代码
#########################################
value = [ 0.0568]
value = array(value)
value = value.reshape(1, 1, len(value))
predicted_example = model.predict(value, batch_size=1, verbose = 0)
print (“predicted example %s” % predicted_example)
model.save(‘saved_keras_model_1.h5’)
model_storage_1 = load_model(‘saved_keras_model_1.h5’)
predicted_example_1 = model_storage_1.predict(value, batch_size=1, verbose = 0)
print (“predicted example_1 %s” % predicted_example_1)
#######################################################
收到的输出
predicted example [[-0.0193442 0.01113211 -0.00196517 0.00191608 -0.00315076 0.0080449]]
predicted example_1 [[-0.02511037 0.01445036 -0.00255096 0.00248715 -0.00408998 0.0104428]]
这很有趣。
我没有什么好主意。如果这是任务关键的,我建议设计实验来进一步探究该效果的原因和限制。
没关系。为什么这些预测值有正有负?它意味着什么?我们需要进一步将其转换为其他函数或进行任何操作吗?
model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True))
当 X.shape[1] =1 时,step=1。LSTM 可能失去意义,因为它将变成一个回归模型。
是的。
嗨,Jason,
您的博客非常好。我从中学到了很多,并且仍在学习。
我正尝试将推文情感与一些数值特征(例如价格、成交量)一起应用于LSTM,但尚未成功。我阅读了一些博客和论文,但到处都是推文和数值特征分开输入,而我想将它们都作为特征向量输入。
有什么好的建议吗?
此致,
我推荐使用嵌入层(Embedding layer),然后是LSTM,请参阅此帖
https://machinelearning.org.cn/use-word-embedding-layers-deep-learning-keras/
谢谢你,Jason。
我一直在学习您的教程,这些教程非常有用和
清晰——即使对于非Python程序员来说,在这篇教程中,我有点迷失在
“拟合LSTM网络。我担心“固定时间步为1”。
当时间步长大小不恒定时该怎么办?一个具体的例子:我正在
驾驶,每五分钟记录我的位置、加速度、方向和时间。
由于各种原因,五分钟只是近似值。另外,有时我会丢失GPS,
因此会错过一个或几个记录。
显然,位置取决于时间。我应该重新采样所有记录,使时间段均匀吗?我应该插值来提供缺失的值吗?如果我晚上停止怎么办?我能否以某种方式将两天的数��拼接在一起?
第二个问题:在这篇教程中,您在哪里为模型提供了惩罚反馈?我想使用一个不对称函数。(如果我想开车到悬崖边,走得太远比差一点点到达要糟糕得多。)
谢谢
也许您可以填充时间步长以使其长度相同?
您可以定义模型来接受任意数量的输入时间步长,例如
https://machinelearning.org.cn/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
您有很多选择,请参阅此处
https://machinelearning.org.cn/data-preparation-variable-length-input-sequences-sequence-prediction/
感谢 Jason 提供精彩的博文。您能否提示一下如何为此多元输入进行多步预测?
是的,我这里有一个例子
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
我已经尝试了上面的博文。我能理解如何传递多元输入。但我仍然无法进行多步预测。您能帮忙吗?
问题究竟是什么?
我需要预测一个应用程序的性能。输入将是应用程序过去性能数据的时序列、托管应用程序的服务器的CPU使用率数据、内存使用率数据、网络带宽使用率等。我正在尝试使用LSTM构建一个解决方案,该解决方案将接收这些输入数据并预测该应用程序未来一周的性能。我遵循了您的博文“https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/”,并理解了如何处理多元数据。我现在卡在了预测未来多个时间步的部分,也就是应用程序未来一周的性能。尽管多步预测在单变量时间序列示例中对我来说是有效的,但在这里却不起作用。不确定我遗漏了什么。您能否就此提供一些指导?
具体问题是什么?您在哪里遇到了困难?
预测结果中只有一个数据点,而我期望的是一周的数据点。
嗨,Jason,
感谢您提供如此出色的博文!我有一个关于多步预测的普遍问题。据我理解,您对 t+3 的预测与 t+2 的预测是独立的,而 t+2 的预测又与 t+1 的预测是独立的。
考虑将之前的预测反馈到网络中是否有意义?如果有,这样的模型叫什么?
您可以这样组织模型,它被称为递归预测
https://machinelearning.org.cn/multi-step-time-series-forecasting/
在这篇博文中,我们直接预测多个时间步。
嗨,Jason,
感谢精彩的教程!我对预测有几个问题。如果我处理的数据集大约有6000个观测值,那么进行从 t+1 到 t+500 的预测(如果 n_test=1)是否有意义?
顺便说一句,在绘制预测时,最后一个数据点有一个小的偏移。这是从序列到监督转换的结果吗?也许我弄错了什么。
谢谢
你好,
将我们要预测的时间步长(t+k)也作为模型的输入是否会更有益?因为目前我们考虑n_seq指定的范围内的所有数据点,将它们视为“离预测起点相同的时间步长”。
致以最诚挚的问候和感谢,
Andreas
也许吧。试试看。
嗨 Jason
非常感谢您非常有用的教程。我将非常乐意获得有关此问题的帮助
给定一个有20个输入变量和一个输出变量的时间序列。
序列长度约为500个样本。对于20个变量中的5个,也有未来样本可用。(50个样本)。我想知道如何利用这5个变量的未来值来改进预测。
非常感谢您的有用提示。
此致
您所说的“未来样本”是什么意思?
嗨 Jason
对于20个输入变量中的5个(x1..x5),我已经有了未来50个时间步的值。(这些值是给定的)。所以不需要预测它们,但我想利用它们来改进(一个)输出变量y的预测。(也不需要预测其他15个输入值x6-x20)
x1….x5, x6..x20, y
t0 1, .. 2, 4, .. 7, 10
t1 1, .. 3, 4, .. 5, 11
..
t500 2, … 5, 5, … 8, 14
t501 2, … 4, ?????? ?
..
t550 2, … 3, ?????? ?
提前感谢
马丁
亲爱的 Jason,感谢您提供的精彩代码和解释,我有一个问题想问您。在这种情况下,一个人想要估计未来多步预测,对吗?例如提前10步。但是这10个步骤都是未知的。模型应该在不使用实际值的情况下找到它们。但在这里,我在测试集或训练集中看到的是,模型在考虑实际值而不是预测值的情况下估算数据点。
让我们一起看一些数据
[[ 342.3 339.7 440.4 315.9]
[ 339.7 440.4 315.9 439.3]
[ 440.4 315.9 439.3 401.3]]
假设模型预测第一行 [ 342.3 339.7 440.4 315.9] 的预测值为439.4,但实际的正确值为439.3(我们不知道!)。所以在第二行,我们应该考虑 [ 339.7 440.4 315.9 439.4],而不是 [ 339.7 440.4 315.9 439.3]。
请向我详细说明。
当然,具体问题是什么?
问题是这样的,当您说这种方法能够进行多步预测时,您指的是以下哪一种?
1) 这种方法不使用未来信息(无实际值),只使用自己的预测
2) 这种方法预测下一步的一个点并计算误差,但忽略该预测,并使用该点的实际值(真实值)进行后续步骤的预测。
我相信这里的模型是第二种,对吗?
我想确保。
我担心这里显示的好结果是因为模型看到了测试集中的结果。
换句话说,模型预测一月份的洗发水价格为1000,但实际价格为1200。对于二月份的预测,模型使用的是1200(正确价格),而不是它预测的1000。
一段时间后,差异会变得很大。
它可以直接预测多个时间步,而无需使用先前的预测。这被称为直接方法。
这里是不同多步预测方法的总结
https://machinelearning.org.cn/multi-step-time-series-forecasting/
嗨,Jason,
感谢您发布这个精彩的教程。您能否检查一下在完整代码的第172行和第174行中使用(n_test + 2)的计算是否正确?
我认为应该是(n_test-n_lag+2)。这将是11而不是12。
举个例子
d: 差值,其中 d[i] = d[i+1] – d[i]
f: 预测
s: 原始序列
训练数据是
d0 : d1,d2,d3
d1: d2,d3,d4
.
.
d21: d22,d23,d24
测试数据
d22: d23,d24,d25
.
.
d31:d32,d33,d34
forecast[0] = f_d23,f_d24,f_d25
f_d23 应该是 s24-s23 => s24 = f_d23 + s23
所以 last_ob 的值是 s23,但您的代码给出 s22。
这可以通过使用 (n_test – n_lag + 2) 来纠正。
如果我有什么误解,请告诉我。
感谢您的时间!
Lak
实际上,通用形式应该是 inverse_transform 的 (n_test+n_seq),plotting 的 (n_test+n_seq-n_lag)。
您能展示如何添加另一层LSTM吗?我试着只复制Model.Add(LSTM line),但会收到一个关于期望3维但只得到2维的错误
另外,我正在参加您的7天课程(尽管比7天慢一些)
谢谢
是的,请看这篇文章
https://machinelearning.org.cn/stacked-long-short-term-memory-networks/
Jason,非常感谢您的辛勤工作!它在过去几个月里给了我很大的帮助。
然而,我在我使用的其他LSTM模型中成功地添加了层。不过,我无法在上面的代码中添加层,因为LSTM的拟合被包装在一个单独的函数中。每次我向代码中添加LSTM层时,都会出现
”
IndentationError: unindent does not match any outer indentation level
”
错误。
有什么想法吗?我可以重写代码并解决您的“def fit_lstm”,尽管这会让代码变得很难看。那么,如何在不这样做的情况下实现更多层呢?
提前感谢……
请继续,您正在做一件很棒的事情!
Sebastian
看起来您没有使用 Tab 来缩进您的 Python 代码。
也许可以复习一下Python编码基础知识?
我在这里也有关于如何从教程中复制代码的帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
这个例子只使用了一个时间步来预测接下来的3个时间步?要使用更多时间步进行预测,series_to_supervised的n_in参数是否应该大于1?另外,n_in和n_out参数是否对应于您在其他LSTM预测文章中的lag和seq参数?谢谢。
是的。您可以在此处了解有关此函数的更多信息
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
嗨,Jason,
我尝试调整您的代码中的参数以优化结果。首先,我检查是否有欠拟合或过拟合。
我在您的程序中添加了以下代码。
history = model.fit(X, y, epochs=1, batch_size=n_batch, verbose=1, shuffle=False, validation_data=(X_test, y_test))
loss.append(history.history[‘loss’])
val_loss.append(history.history[‘val_loss’])
22/22 [==============================] – 0s 2ms/step – loss: 0.0988 – val_loss: 0.2584
t+1 RMSE: 90.210739
t+2 RMSE: 79.713680
t+3 RMSE: 107.812684
看起来验证损失远高于训练损失。我做了一个测试,使用线性激活函数将数据重缩放到(0, 1)。
scaler = MinMaxScaler(feature_range=(0, 1))
model.add(LSTM(n_neurons, activation=’linear’, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(y.shape[1], activation=’linear’))
我运行了两次。结果大相径庭。请允许我在此提出两个问题?
1. 为什么结果与相同代码相比非常不稳定?
运行 1 t+2 RMSE: 123.765729 几乎是运行 2 t+2 RMSE: 69.944902 的两倍。
2. 指标显示了更好的改进(更改后的版本 loss: 0.0248 – val_loss: 0.0709 vs loss: 0.0988 – val_loss: 0.2584),但 RMSE 没有显示太大改进(更改后的版本 t+2 RMSE: 69.944902 vs t+2 RMSE: 79.713680)。
运行 1
22/22 [==============================] – 0s 2ms/step – loss: 0.0241 – val_loss: 0.0651
t+1 RMSE: 158.873657
t+2 RMSE: 123.765729
t+3 RMSE: 186.785670
运行 2
22/22 [==============================] – 0s 2ms/step – loss: 0.0248 – val_loss: 0.0709
t+1 RMSE: 93.477638
t+2 RMSE: 69.944902
t+3 RMSE: 113.995648
提前感谢。
关于模型技能的高方差,也许模型对于问题来说指定不足。也许模型对问题拟合得很差。
差分反差会不会导致数据少一个?例如,对 [5,4,3,2,1] 进行差分会产生 [1,1,1,1],但反差只会产生 [4,3,2,1]。
是的,第一个观测值丢失了(我想)。
如何只预测最后一个时间步?看起来你只预测到 t-2 时间步(从图中看)。谢谢!
根据上面一些评论的阅读,似乎 n_test+2 应该是 n_test+n_seq-1(无论 n_seq 是多少)。这看起来像是预测从最后一步开始的。你能确认一下吗?
嗨,Jason,
对于在线训练,如何用最新数据更新模型?谢谢。
我可以输入最新一个月的 new_X 和 new_y 来拟合模型,并且永不重置模型的 states 吗?或者有更好的方法吗?谢谢。
例如,模型是用一年前到五月的数据训练的。
在七月,我有六月的销售数据。New_X 是五月的销售额,new_y 是六月的销售额。
model.fit(new_X, new_y, epochs=1, batch_size=1, verbose=0, shuffle=False)
July_sales = model.predict(new_y, 1) # new_y 是六月的销售额。
这篇文章提供了一些更新模型的例子。
https://machinelearning.org.cn/update-lstm-networks-training-time-series-forecasting/
嗨,Jason,
非常感谢您的发布。我有一个快速的问题。我正在将此模型用于一些市场数据。当我使用 n_seq = 3 时,“实际”值与我的数据一致。当我将 n_seq 更改为 5 时,“实际”值的输出与我的数据集中任何内容都不对应,尽管它很相似。可能是什么原因造成的?
再次感谢,
Mark Stevenson
模型需要针对您的具体问题进行调整。
我也想将其应用于多元时间序列预测,并已阅读了您的多元文章(https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/)。
我感兴趣的是预测天然气价格。因此,我感兴趣的输出只有一个变量,但我输入了大约 15 个变量。为了预测一个以上的时间周期,我是否需要训练 LSTM 来预测所有变量(输入和输出),而不仅仅是我的输出变量天然气价格?
非常感谢。
不,您可以根据自己的意愿构建问题。
在另一篇文章中,我们使用多个输入来预测一个输出,您可以将其扩展为预测单个输出特征的序列。
谢谢回复!
为了做到这一点,我会将问题设置为每行数据分别为天然气价格的 t、t+1、t+2 等,然后是所有输入变量的 t-1 吗?
您是否有详细介绍此输出序列方法的帖子?
是的,这篇帖子(上面)展示了如何输出序列。
嗨 Jason!感谢这篇精彩的文章!
我想知道在使用 LSTM 之前是否需要去除季节性。
我推荐这样做。任何使问题更容易建模的事情都是好事。
嗨 Jason,在您的代码中,您使用了批量大小为 1,因为您只有少量数据。在我的情况下,我有更多的数据,所以我希望使用更大的批量大小。我只是想了解一件事,如果我使用的批量大小为 72,例如,我是否也必须更改 make forecast 函数,因为在您的示例中,我使用了一个 for 循环来一次进行一个示例的预测,而在我的情况下,我应该一次进行 72 个示例的预测?这是正确的吗?
批量是样本的集合。
也许您指的是给定样本/序列的时间步长?
嗨,Jason,
感谢所有精彩的内容——非常有帮助且全面。
我正在尝试理解如何推广输入整形以适应变化的 1)特征数量和 2)滞后。
在上面的例子中,您执行
X = X.reshape(X.shape[0], 1, X.shape[1])
其中 X.shape[0] 代表 X 中的行数(样本),1 是硬编码的,因为我们只查看前一个时间步进行预测,而 X.shape[1] 代表 X 中的列数(仅当我们查看 1 个前时间步时,它才代表特征数量)。
如果我们考虑的滞后时间超过一个时间步,我们将不得不更改重塑的第二和第三个组件,对吗?例如,假设在上面的示例中我们考虑滞后 3。那么我们的监督 X 数据集将有 3 列。但这仍然是技术上一个原始特征(洗发水销量),只是分布在 3 个时间步上。所以我们需要的重塑应该是 X.reshape(X.shape[0],3,1),对吗?
谢谢!
你好,布朗利博士!
感谢您的分享。这非常有帮助。
我最近在尝试使用多步 LSTM 进行预测时遇到一个问题。
我的训练集中的时间序列大约有 3000 天。但是,我需要预测未来 600 天。此外,还需要考虑每天的另外 8 个有用特征。
我使用了您介绍的递归多步预测(t-3, t-2, t-1 用于 t+1),但结果非常糟糕。
您能否给我一些关于这个问题的建议?
预测这么多未来时间步是一个非常困难的问题。
也许可以与持久性进行比较,以确保您增加了价值?
也许可以尝试更多或不同的模型?
也许可以尝试调整您的模型?
也许可以尝试模型集成?
这里有更多想法:
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
你好!我认为您已经做出了我所见过(我见过一些)的最好、最易读、最可扩展的 LSTM RNN 示例!
只有一个建议:我认为最好在代码中更改以下行
plot_forecasts(mid_prices, forecasts, n_test+2)
推广到
plot_forecasts(mid_prices, forecasts, n_test + (n_seq – 1))
因为它现在考虑了为任何数量的预测(n_seq)保留的观测数量。
再次感谢!
谢谢。
嗨,Jason,
非常感谢您的教程。
它们非常有用且具有教育意义。
我有一个问题,这可能很愚蠢,但我不太明白 LSTM 如何实际评估预测。
我可以看到您设置了 n_lag=1,并且该值用于在 make_forecasts 方法中分割测试集。
您写道:
>X, y = test[i, 0:n_lag], test[i, n_lag:]
>forecast = forecast_lstm(model, X, n_batch)
这是否意味着 LSTM 只能从一个单独的值开始预测未来三个月?
提前感谢您的时间。
是的。
你好 Jason,
我的数据样本是这样的!
样本 时间 w d ywn
1 0 -0.10056 0.18784 -0.032737
1 1 -0.039381 0.97014 -0.049748
1 2 0.12412 -0.77848 0.029185
1 3 0.019026 0.13856 0.013822
1 4 -0.23032 0.84811 0.058235
1 5 0.97489 0.24698 0.01231
2 0 -0.59973 0.34736 -0.013221
2 1 0.32069 0.11464 0.074709
2 2 -0.12189 0.75243 -0.022599
2 3 -0.63586 0.04404 0.056563
2 4 -0.84312 0.17943 0.051038
2 5 -0.28347 -0.34718 0.01531
……以此类推。像这样我有 500 个样本,w、d 是输入,ywn 是输出。我该如何训练和测试我的输出?请帮忙。太困惑了。顺便说一下,需要使用 Keras 和 tensorflow 的 RNN。
这篇文章将向您展示如何准备数据。
https://machinelearning.org.cn/reshape-input-data-long-short-term-memory-networks-keras/
嗨,Jason,
请问为什么数据缩放和反向缩放的形状不同?在缩放中,它使用 (len(diff_values), 1)。在反向缩放中,它变成 (1, len(forecast))。提前感谢。
def prepare()
diff_values = diff_values.reshape(len(diff_values), 1)
# 将值重新缩放到 -1, 1
scaler = MinMaxScaler(feature_range=(-1, 1))
scaled_values = scaler.fit_transform(diff_values)
def inverse_transform()
inverted = list()
for i in range(len(forecasts))
# 从 forecast 创建数组
forecast = array(forecasts[i])
forecast = forecast.reshape(1, len(forecast))
# 反向缩放
inv_scale = scaler.inverse_transform(forecast)
你确定吗?
嗨,Jason,
感谢您的教程,它非常有帮助!我运行了上面的模型代码,有几个问题。(与此数据集有关)
1) 每次运行后的 RMSE 变化很大。这正常吗?
2) 我删除了 reset_states(),似乎每次运行都得到更低的 RMSE 分数。难道不应该是相反的吗?
3) 我需要做哪些更改才能利用 LSTM 不需要固定的采样窗口来学习,并且可以随着时间的推移不断地纳入更大的窗口进行学习的事实?
是的,了解更多请点击这里。
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
也许内部状态在这个问题上没有增加价值。不使用 MLP 也可以。根据我的经验,神经网络在时间序列方面通常表现不佳。
填充和截断序列是一种方法。
嗨,Jason,
感谢您的教程!我的问题是关于批量大小。为什么它固定为 1?是因为我们必须每次都进行预测吗?如果我只想在数据末尾进行多步预测,我必须更改批量大小吗?我的理解是批量大小是将样本放入网络中的数量,对吗?
我正在尝试解决一个多元多步预测问题。我有 7 个变量,其中一个是目标。我对如何设置批量大小感到困惑。如果我想预测每个时间步,它仍然设置为 1 吗?
正确。
无需更改批量大小,但您可以这样做。
更多关于批量大小的内容请点击这里。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-a-batch-and-an-epoch
如果批量大小固定为 1,它会影响网络的性能吗?在这种情况下我该如何调整网络?
当然会,试试看。
还可以看看这篇关于批量大小对学习影响的文章。
https://machinelearning.org.cn/gentle-introduction-mini-batch-gradient-descent-configure-batch-size/
嗨,Jason,
我正在尝试为价格变动时间序列构建一个 LSTM 网络,目前我正在尝试使用多步 LSTM,最近的 3 个输入,但我希望创建一个网络,其中第 i 个层的输入是直到 (i-1)th 层的所有序列。例如,如果序列是 10,9,5,2,6,7……。
我现在正在训练我的模型,
我会输入 10 到第一层,10,9 到第二层,10,9,5 到第三层,依此类推。
创建这样的网络在逻辑上是否可行?
试试看吧。
这是一个不错的教程。是否有用于多元情况的代码?
是的,请看这里
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
嗨,Jason,
我在 LSTM 模型中遇到了验证损失小于训练损失的情况。请问您是否有链接或文章讨论这个问题?提前感谢。
我在这里讨论了这个问题。
https://machinelearning.org.cn/faq/single-faq/what-if-model-skill-on-the-test-dataset-is-better-than-the-training-dataset
嗨,Jason,
感谢您精彩的教程。
Shamsul 问道我们如何进行 MIMO(多个变量作为输入和多个变量作为输出)。您建议使用链接 https://machinelearning.org.cn/multi-step-time-series-forecasting-long-short-term-memory-networks-python/ 作为模板。据我所理解,您建议的教程展示了如何通过给定 t 来预测 t+1、t+2、t+3。它不适合我的 MIMO 用例。
以您在 https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/ 中写的例子为例。例如,在时间 t,我有输入 PM2.5 浓度、露点和温度(多个输入变量)。我想在时间 t+1 预测 PM2.5 浓度、露点和温度(多个输出变量)。我们该如何做?
您可以将模型更改为 seq2seq,例如编码器-解码器模型或 RNN 自动编码器。
嗨 Jason – 首先,这是一篇很棒的文章。我尝试在不同的数据集上使用它。
当 n_seq = 1 时,它似乎工作正常。但是,一旦我将其更改为 n_seq = 3 或更高的数字,我就会收到如下错误:
ValueError: cannot reshape array of size 3 into shape (1,1)。
我认为代码会处理这个问题,所以它在洗发水数据集上运行得很好。我尝试修改代码,特别是下面的部分,但没有效果。
# reshape training into [samples, timesteps, features]
X, y = train[:, 0:n_lag], train[:, n_lag:]
X = X.reshape(X.shape[0], 1, X.shape[1])
您能指导我一下吗?
完整错误在此。
/opt/conda/lib/python3.6/site-packages/sklearn/utils/validation.py:560: DataConversionWarning: Data with input dtype object was converted to float64 by MinMaxScaler。
warnings.warn(msg, DataConversionWarning)
—————————————————————————
ValueError 回溯 (最近一次调用)
in ()
34 #forecasts = forecasts.reshape((len(forecasts), 1))
35
—> 36 forecasts = inverse_transform(series, forecasts, scaler, n_test+2)
in inverse_transform(series, forecasts, scaler, n_test)
115 # create array from forecast
116 forecast = numpy.array(forecasts[i])
–> 117 forecast = forecast.reshape(1, len(forecast))
118 # invert scaling
119 inv_scale = scaler.inverse_transform(forecast)
ValueError: cannot reshape array of size 3 into shape (1,1)
你好 Jason-
感谢又一篇精彩的文章。今年我学到了很多东西。我仍然在概念上难以理解多变量时间序列数据以及如何将其输入神经网络。
这是我的数据的一个非常简化的例子(为方便理解而格式化),我正试图根据以下内容预测未来两小时不同房屋(成千上万)的用电负荷:当前天气观测值、前三个小时的平均负荷以及房屋信息。
房屋/时间/温度/阳光 负荷(t-2) 负荷(t-1) 负荷(t) y_load(t+2)
1 1 28 610 5 6 5 3
1 2 28 599 6 5 4 3
1 3 27 587 5 4 3 2
1 4 26 576 4 3 3 1
1 5 26 565 3 3 2 1
2 1 23 587 7 7 6 5
2 2 23 576 7 6 5 4
2 3 22 565 6 5 5 3
2 4 22 576 5 5 4 1
2 5 22 565 5 4 3 1
3 1 33 565 4 4 4 2
3 2 34 503 4 4 3 1
3 3 34 492 4 3 2 1
3 4 35 481 3 2 1 1
3 5 35 469 2 1 1 1
————–
我甚至难以将此类复杂的多变量股票预测的例子与我联系起来,因为用这种类比,我试图使用多变量时间序列数据来预测一套股票(或此处指房屋),而不是仅仅预测一套股票。
使用 train_test_split(),我想在 X_num 房屋的完整数据集上进行训练,然后在 y_num 房屋的完全未见过的数据上进行测试。
我知道我想要 shuffle = False,以便时间是顺序的,但模型如何区分不同的房屋?使用 batch_size = 5(对应于房屋的 5 个时间间隔)会有用吗?这样做是否意味着一次将一个房屋的完整每日配置文件输入并作为时间序列进行训练。
在处理了非时间序列相关数据的机器学习之后,我最困惑的是模型如何捕捉那个顺序时间元素,然后在我的例子中,它们如何学习对应于独特元素(房屋)的不同时间序列?
非常感谢任何建议或解释。
-Alex
也许可以从时间序列数据处理的基础知识开始。
https://machinelearning.org.cn/start-here/#timeseries
先尝试逐个建模每个序列。
然后,也许探索具有监督学习框架的机器学习方法。
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
然后,一旦您尝试了这些方法,也许可以考虑 MLP、CNN、LSTM——它们实际上在经典的自回归类型问题(输出是近期滞后观测值的函数)方面表现相当糟糕。
嗨,Jason,
我需要从特征 x1 和 x2 预测 y(t+1) .. y(t+n)。
x1 是历史数据。
x2 是外部来源提供的未来数据。
f(x1(t) … x1(t-m), x2(t+1) … x2(t+n)) = y(t+1) .. y(t+n)
您是否建议哪种算法适用于这种情况?我能否参考此 LSTM 多步实现?非常感谢。
尝试一套方法,找出最适合您特定数据集的方法。
我有一个问题。
在您的示例中,预测仅取决于一个前时间步和各种特征。
如果我没记错的话,您试图根据许多过去的时间步来预测 1 个变量(1 个特征)。
如果“[samples, timesteps, features]”是 LSTM 模型 3D 输入的含义。
我想理解为什么时间步数是 1 且特征数大于 1?
这只是一个简单单变量问题的例子。您可以根据需要更改模型。
嗨,Jason,
感谢这篇文章。
我有一个基于这篇文章的问题。假设我们有多个洗发水而不是只有一个,并且我们有每个洗发水的销售记录和每个洗发水的信息。
我们应该使用什么模型来解决这个问题?
谢谢,
雷
尝试一套方法,看看哪种效果最好。
您能提供更多信息吗?您说的“一套”是什么意思?
谢谢,
尝试多种方法,看看哪种效果好。
嗨 Jason
非常感谢您非常有帮助的教程。我阅读了您所有的 LSTM 预测相关教程。我对预测中的 batch_size 感到困惑。我知道在训练模型时,batch_size 是模型将要处理的样本集合,用于更新权重。但是为什么在模型训练完成后,当我们进行预测时,我们仍然需要 batch_size,并且与训练模型时相同的 batch_size?您能否解释一下 batch_size 在模型训练后的预测中是如何发挥作用的?再次感谢。
通常,模型定义时会有一个固定的批量大小,这意味着它一次处理这么多记录。这是实现上的效率,而不是算法固有的。
是的。在训练模型时,它期望一次处理一个批次大小的记录。假设我们有1-8个时间序列,如果时间步长是2,我们只向前预测一步,批次大小是3,那么我们将重新格式化数据为:
X1 X2 Y
1 2 3
2 3 4
3 4 5
4 5 6
5 6 7
6 7 8
模型将计算前3个Y(Y=3 4 5)估计值的损失,然后更新权重,接着计算最后3个Y(Y=6 7 8)估计值的损失来再次更新权重。这是一个epoch。经过一定数量的epoch后,模型就训练好了。然后权重和架构就固定了。现在我们知道X1=7, X2=8,我们可以使用模型进行一步预测,我们只需要知道X1, X2(这两个时间步长)、权重和模型架构。我们应该能够在没有批次的情况下进行预测。但是为什么在Keras中,我使用你的代码“forecast = model.predict(X, batch_size=n_batch)”时,必须将相同的batch_size传递给model.predict呢?我知道有些人会保存权重和模型架构,就像他构建另一个模型一样,然后他就可以使用不同的batch_size来解决这个问题。我只是不明白为什么batch_size在model.predict中很重要。你能解释一下,或者给我一些论文或教程吗?非常感谢你的时间和帮助。
这不是理论,而是实现上的一个限制。仅此而已。
该实现正在努力提高速度,而固定批次大小对某些模型来说是我们要付出的代价。
我在这里有一些解决方法
https://machinelearning.org.cn/use-different-batch-sizes-training-predicting-python-keras/
明白了,非常感谢你的回答。
不客气。
嗨,Jason,
感谢分享这些关于LSTM的文章。
我在预测未来数据时遇到了一个问题。
在进行预测时,我只将第一个实际值作为输入。然后使用输出进行下一次预测。预测值在几个步骤后变得几乎恒定。
你对这种预测有什么看法吗?
谢谢!
此致,
埃里克
您可能需要根据具体问题进一步调整模型。
你好,Gou,我也有同样的问题。你现在解决了它吗?
嗨,Jason,
我一直在关注你的教程。我正在做一个使用LSTM和softmax分类器的时间序列分类问题。
我的数据形状如下:(3154, 30, 6) (3154, 30) (1352, 30, 6) (1352, 30)。
我的模型包含一个LSTM层和一个dense(30)。
但是当我运行模型时,我收到错误:“ValueError: Error when checking target: expected dense_2 to have shape (1,) but got array with shape (30,)”。
这是因为我的模型吗?我该如何解决这个错误?
非常感谢!
也许输出形状需要是 [n, 30, 1]?
你好,Jason博士,
感谢您精彩的博客文章。
但是,我仍然不明白如何预测未来(例如,某个产品未来三个月的销量),其中我的输入变量是该产品的历史销量+收到的报价数量+价格点……+其他数值变量。说LSTM可以用来预测这类问题(考虑所有输入)是否公平?提前感谢。
我推荐使用ARIMA等经典时间序列方法。
https://machinelearning.org.cn/start-here/#timeseries
你好,Jason博士,
感谢您的推荐。但是您提供的链接谈论的是单变量ARIMA,我是否应该搜索MARIMA(多变量)?
是的,我建议也许可以先对单变量序列进行建模,看看能达到什么效果。
你好,感谢教程,它让我对LSTM有了更清晰的认识。但我对序列数量和滞后数量感到困惑。目前,我有一个单变量时间序列数据集,包含547个每日销售数据。我想通过LSTM预测未来3个月(91天)。我已经将n_lags设置为3、5和7。据我所知,这是预测时我们回顾的数据量。但是,我无法理解序列数量是什么,以及我应该如何设置它。如果您能回答我的问题,我将非常感激。谢谢!
也许这篇文章会有所帮助
https://machinelearning.org.cn/prepare-univariate-time-series-data-long-short-term-memory-networks/
Jason先生
非常感谢您的文章,它给了我很大的帮助,但是我的数据具有周期性和复杂的序列,它是sinx和cosx的组合。我想预测一个周期或更多周期,我拥有100,000个数据,每个周期500个数据,我该如何预测相同类型的数据?
也许可以先从SARIMA和ETS等经典方法开始,然后尝试一些ML方法,然后尝试MLP、CNN,最后是LSTM。
嗨,Jason,
感谢这篇好文章。
我可以在以下函数中问一下
# 使用 LSTM 进行一次预测,
def forecast_lstm(model, X, n_batch)
# 重塑输入模式为[样本,时间步长,特征]
X = X.reshape(1, 1, len(X))
# 进行预测
forecast = model.predict(X, batch_size=n_batch)
# 转换为数组
return [x for x in forecast[0, :]]
为什么是 X = X.reshape(1, 1, len(X)) 而不是 X = X.reshape(X.shape(0), 1, X.shape(1))?
虽然文章中的结果没有改变,但我无法理解其中的逻辑。
提前感谢您的时间
你可以根据自己的喜好进行重塑。
Jason 博士您好,
非常感谢您的精彩教程。
我不确定为什么我的预测结果是错误的。
https://ibb.co/nc1jV9
我应该在哪里得到?
https://3qeqpr26caki16dnhd19sv6by6v-wpengine.netdna-ssl.com/wp-content/uploads/2017/03/Line-Plot-of-Shampoo-Sales-Dataset-with-Multi-Step-LSTM-Forecasts.png
源代码和数据集来源于此网站。
我使用的是tensorflow 1.10.0和keras 2.2.2。
谢谢
您可能需要多次运行示例?
Jason 博士您好,
抱歉,是我的错。
我复制了代码的错误部分。
谢谢
不客气。
嗨,Jason,
非常感谢这篇好文章。
我可以在以下函数中问一下
# 评估每个预测时间步的 RMSE
def evaluate_forecasts(test, forecasts, n_lag, n_seq)
for i in range(n_seq)
actual = test[:,(n_lag+i)]
predicted = [forecast[i] for forecast in forecasts]
rmse = sqrt(mean_squared_error(actual, predicted))
print(‘t+%d RMSE: %f’ % ((i+1), rmse))
该函数为测试数据输出t+1, t+2, t+3……的RMSE。
[[ 342.3 339.7 440.4 315.9]
[ 339.7 440.4 315.9 439.3]
[ 440.4 315.9 439.3 401.3]
[ 315.9 439.3 401.3 437.4]
[ 439.3 401.3 437.4 575.5]
[ 401.3 437.4 575.5 407.6]
[ 437.4 575.5 407.6 682. ]
[ 575.5 407.6 682. 475.3]
[ 407.6 682. 475.3 581.3]
[ 682. 475.3 581.3 646.9]]
但是,我如何评估总测试值和预测值之间的RMSE呢?
谢谢
对整个测试集进行预测,然后计算预测值的RMSE。
嗨,Jason,
我也一直在尝试遵循本指南以及您在此链接的指南:https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/,但遇到了一些问题。
首先,我的最终目标是实现一个多变量多步预测时间序列LSTM。具体来说,我使用的是一个按日期索引/排序的数据集,类似于您的pollution.csv,它每行有9个其他字段,我希望在训练中使用。通过训练,我的目标是能够为模型提供目标日以及前2天(总共3个滞后日)的数据,然后让它对未来7天进行预测。如果数据集的大小/行数有影响的话,这个数据集有6375个条目。
不幸的是,我无法弄清楚如何将上面链接的示例转换为多步模式,也无法在多变量环境中运行本文中的示例。您能否展示如何转换这两个示例中的一个?
谢谢!另外,您在文章发布一年多后仍然坚持回复新问题,这真的很棒🙂
我将在很快的帖子上介绍这个,它们已经安排好了。
我在新书中提供了MLP、CNN和LSTM的特定示例。
https://machinelearning.org.cn/deep-learning-for-time-series-forecasting/
具体来说,我展示了如何从多变量系列预测一个因变量系列,以及如何预测并行系列,它们是不同的情况。
感谢这个信息丰富的教程。我有一个问题。如何更新LSTM?正如您的文章中所解释的那样。
更新LSTM。将示例更改为在有新数据可用时重新拟合或更新LSTM。10个训练周期应该足以用新的观测值重新训练。
基本上,我想让新的观测值输入模型以进行下一次预测,或者您的文章在任何地方都有提到吗?
我在这里有一个更新LSTM的示例。
https://machinelearning.org.cn/update-lstm-networks-training-time-series-forecasting/
嗨,Jason,
感谢您发布所有这些内容。我使用您几个教程的汇编创建了一个模型,该模型根据数十年的每日最高温度、每日最低温度、一年中的月份和降水来预测未来3天的最高温度。对于我生成的模型,当我在t+1(第二天)进行预测时,该值最终非常紧密地模仿了前一天的值(图形基本上看起来像同一图形被复制,引入了1步的时间滞后)。我可以调整哪些参数来帮助处理这个问题?
谢谢!
这是一个常见问题。
https://machinelearning.org.cn/faq/single-faq/why-is-my-forecasted-time-series-right-behind-the-actual-time-series
试试这个
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
嘿!我如何预测未来一周?因为上述过程似乎仅适用于测试数据。我的意思是“make_forecasts”函数考虑了测试数据,这从(X, y = test[i, 0:n_lag], test[i, n_lag:])可以看出。我只想问的是,没有测试数据。我只有训练数据。那么,我现在如何预测未来一周呢?
调用model.predict()并将最后的n个观测值传递进去。
但这会导致单步预测,而我关心的是多步预测。
如果您的模型预测多个时间步长,那将是多步预测。
嗨,Jason。我是一名新的学习者。但是,我仍然不知道如何进行多变量多步时间序列预测与LSTM?你能帮我吗?
我在我的新书中有详细介绍。
https://machinelearning.org.cn/deep-learning-for-time-series-forecasting/
我也有关于这个主题的博客文章将在下个月发布。
嗨 Jason
你什么时候会发布这个话题?
谢谢
这是一个例子
https://machinelearning.org.cn/how-to-develop-lstm-models-for-multi-step-time-series-forecasting-of-household-power-consumption/
感谢您所有精彩的教程。但是,对于这个教程,我不明白为什么有些部分写得很难!
例如,为什么您不使用
numpy.diff(dataset, n= interval)?
谢谢你的反馈。
解决一个问题有很多方法,我尽量不假设读者知道太多。
嗨,Jason,
谢谢您将我引向此页面。代码运行良好。
将预测长度(例如从3个月改为12个月)是否像将n_seq值更改为12一样简单?
可能是的,时间有点久了。也许试试看。
我们如何为未来值获得RMSE?RMSE是基于我们的预测值和实际值,但在这个例子中我们是为未来预测,我们不知道实际值。
只有当您拥有地面真实值时,才能计算模型的误差。
您可以通过在历史数据上评估模型来估算模型预期的性能。
嗨
为什么我们需要对测试数据进行逆缩放?我认为第二行不是必需的。
actual = [row[n_lag:] for row in test]
actual = inverse_transform(series, actual, scaler, n_test+2)
此致,
Jing
我们进行逆缩放是为了能够以数据集的原始单位来评估模型的误差。
嗨,Jason,
谁能给我解释一下这一行?
n_vars = 1 if type(data) is list else data.shape[1]
谢谢!
saravana
如果输入是列表,它会将变量设置为1,否则对于numpy数组,它会将变量设置为第二个维度(列)的形状。
嗨,Jason,
“模型将被用于对时间步长进行预测,然后从测试集中取下一月实际期望的值,并使其可用于模型对下一个时间步长的预测。”
您能否指出方法中模型在包含前一个数据点后的下一个时间步长被更新(重新训练)的位置?
我期望测试数据集中的每个数据点都可以用于重新训练。
模型在进行前向验证的每一步都不会重新训练,通常计算成本太高。
相反,数据会被添加到历史记录中,用于输入以进行下一次预测。例如,我们模拟了实际观测值在预测后被制作的事实,并使用该观测值而不是预测值来制作后续的预测。
非常感谢!
我对一些方面感到困惑。time_steps是否等于batch_size?而且我看到过您的一些关于LSTM将time_step设置为1的博客,如果我将time_step更改为另一个数字,对样本会有什么影响?
我只是不清楚time_steps和samples在[samples,time_steps,features]中的关系。谢谢你的帮助。
不,时间步长与批次大小不同。
一个批次是1个或多个样本,一个样本是1个或多个时间步长,一个时间步长是1个或多个特征。
在我看来,时间步长决定了LSTM的记忆,那么将时间步长设置为1有意义吗?换句话说,我们如何选择更好的时间步长?
谢谢你的帮助!
LSTM 具有在批次之间重置的记忆,或者根据您的选择手动重置。
概念上,这种记忆与一个样本中的时间步长数量是分开的。
嗨,Jason,
感谢博客。
我有一个关于您代码的问题。运行“prepare_data(series, n_test, n_lag, n_seq)”中的代码后,我遇到了以下问题
TypeError Traceback (most recent call last)
in
8 n_test = 10
9 # 准备数据
—> 10 train, test = prepare_data(series, n_test, n_lag, n_seq)
11 print(test)
12 print(‘Train: %s, Test: %s’ % (train.shape, test.shape))
TypeError: ‘NoneType’ object is not iterable。
有一点要说明的是,我没有使用您提供的“parser”函数,因为它会引发另一个关于 %Y-%M 格式的错误。所以我只是删除了 parser 函数中的最后一个参数。
ValueError: 时间数据“190Sales of shampoo over a three year period”与格式“%Y-%m”不匹配
提前感谢您的帮助!
尝试从这里下载数据集
https://raw.githubusercontent.com/jbrownlee/Datasets/master/shampoo.csv
嗨,
感谢您发布这个教程。
对于“多个主体内部”设计,如何轻松地进行适应?例如,在每个月的时间测量点有 100 种不同的洗发水。
我这里有一些建议可能相关
https://machinelearning.org.cn/faq/single-faq/how-to-develop-forecast-models-for-multiple-sites
感谢您的回复。我曾考虑使用嵌入来降低高维因素。我只在表示单词的向量上使用过嵌入。我没有找到将嵌入与时间序列结合的例子。您有吗?
我确实记得有关此事的某些信息。我不记得是哪里了,抱歉。
嗨,jason
我有一个问题。在电力预测或使用时间序列数据进行估算方面,CNN 还是 LSTM 更好?
尝试两者,并找出最适合您特定数据集的方法。
您会推荐任何关于这两种技术的电力预测的链接吗?
是的,我的博客上有很多示例,请尝试使用搜索框。
层数,如何设置多层LSTM?您能否给我一些
您的帖子?
好问题,我在这里回答
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
我有一个想法。代替 LSTM
步骤 1:在每个层中随机将序列中的值替换为 0
步骤 2:使用 resnet 保持信息完整
请指出不合理之处。
试试看吧。
你好,Jason。
最近,我一直在尝试使用 LSTM 进行递归预测,但结果非常糟糕。事实上,我预测的模型非常简单,就是一个指数函数。您有什么相关的建议和指导吗?
尝试另一个模型,例如 CNN?
如何修改代码来预测未来?这里预测停止在“十二月”。如何预测未来三个月?
是的,这篇帖子将帮助您进行预测
https://machinelearning.org.cn/make-predictions-long-short-term-memory-models-keras/
嗨,感谢您提供的精彩教程。
我有一些关于多步 LSTM 与正常 LSTM 的问题,我遵循了:https://machinelearning.org.cn/time-series-prediction-lstm-recurrent-neural-networks-python-keras/
我认为这两个模型的主要区别在于输出值的数量。在本教程中是 3,而上一教程是 1。
1. 与正常 LSTM 相比,这个多步 LSTM 的主要目的(优点)是什么?例如,为了提高准确性,还是提前预测 t+2、t+1 值的好处?
2. 在这个 3 步 LSTM 的例子中,训练模型时,三个输出值是否每次都会影响记忆的权重?
3. 多步 LSTM 的 t+1 RMSE 通常比正常 LSTM 的 t+1 RMSE 更好吗?
如果其他变量对目标变量具有预测性,那么多元模型可能有用。
性能差异确实取决于预测问题的具体情况和模型的选择。
所以您的意思是,性能不仅取决于模型给出多少输出,还取决于数据的具体情况(预测问题)。
1. 那么,这是否意味着我必须同时使用正常(1 步)LSTM 和 3 步 LSTM,然后比较这两个模型的评估结果并选择更好的一个?
2. 此外,我对于验证和评估感到困惑。您计算的 RMSE 分数是验证方法,而不是评估。我理解得对吗?
如果可能,请分别回答问题 1 和 2。谢谢!!
是的,这就是我们发现什么最适合特定数据集的方法。
您可以在保留的测试数据集上估算模型的性能。更多关于训练/测试/验证数据集的信息,请参见此处
https://machinelearning.org.cn/difference-test-validation-datasets/
尊敬的教授
在学习了其他文章后,我发现我们可以对以下代码进行一些小改动
第 77 行:model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True))
改为
model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True, dropout=0.5, recurrent_dropout=0.5))
根据文章,这两个 dropout 有助于避免过拟合。
此外,我想知道为什么第 172、174 和 178 行有 ‘n_test+2’ 而不是 ‘n_test’?
我非常感谢这个教程!
谢谢,我认为这个教程已经过时了,也许可以看看这些示例
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨,Jason,
您所有的教程都非常有帮助!谢谢!我有一个问题,我有一个从 2016 年 1 月到 2018 年 12 月(36 个值)的月度数据。我将数据分割为 24(2016-2017):12(2018)个值。我遇到的问题是,在现实场景中,假设我在 2018 年 1 月 1 日收到 2017 年 12 月的需求数据,那么我将进行的预测实际上是针对 2018 年 2 月。在这种情况下,我需要对上述模型进行哪些更改?
上述场景的唯一原因是“反应时间”。如果我在 2018 年 1 月 1 日发布 2018 年 1 月的预测,那么我们就没有时间进行准备。因此,当我有截至 2017 年 12 月的数据时,我将进行的第一次预测将是针对 2018 年 2 月的。
谢谢!
好问题。
如果模型稳健且问题简单,则可以在没有新观测值的情况下直接使用。
一种方法可能是使用一月份的预测作为观测值来做出下一次预测。
另一种方法可能是使用基于真实数据的关于一月份的估计值作为下一次预测的观测值。
据我理解,您有 10 个示例,将它们分成 7 个和 3 个训练和测试集。然后尝试从前 7 个示例中预测最后 3 个示例。但在现实世界中,我们想预测明天和后天、大后天,而我们没有他们的示例。所以请提供一个对未来未知示例有效的代码(或文章),而不仅仅是针对先前已知的示例!
致以最诚挚的问候。
是的,这叫做多步预测,有很多示例,您可以在这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
先生您好,感谢您的工作,我想使用 LSTM 来预测每日时间序列。我阅读了您的文章和代码,我明白了您在训练和测试数据上进行预测的原理,但我的
问题是,我无法对未来 10 天进行预测,例如?
请帮助我,先生,提前致谢
Selmi
也许这篇文章会有所帮助
https://machinelearning.org.cn/make-predictions-long-short-term-memory-models-keras/
还有这个。
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
嗨,Jason,
这是一篇很棒的文章,有助于理解持久性和 LSTM 实现。我想将 ARIMA 的性能与这些方法进行比较。正如您在文章中所提到的,您将数据集转换为监督学习以进行多步预测。因此,您在这里使用了 1 个先前的时间步来预测接下来的 3 个时间步。例如,以下矩阵,第一列是单个输入,接下来的 3 列是预测。
[[ 342.3 339.7 440.4 315.9]
[ 339.7 440.4 315.9 439.3]
[ 440.4 315.9 439.3 401.3]
[ 315.9 439.3 401.3 437.4]
[ 439.3 401.3 437.4 575.5]
[ 401.3 437.4 575.5 407.6]
[ 437.4 575.5 407.6 682. ]
[ 575.5 407.6 682. 475.3]
[ 407.6 682. 475.3 581.3]
[ 682. 475.3 581.3 646.9]]
要将 ARIMA 应用于此类问题,我是否应该以相同的方式进行监督学习?我的意思是,如果我们只考虑这个示例矩阵,我们有 10 次迭代。并且每次迭代,ARIMA 模型都应该将第一个值作为输入,并预测接下来的 3 个时间步?假设这是真的,我应该如何定义 p、d、q 值?并且拟合过程对我来说也不清楚。如果您能回答,我将非常感激。
此致,
古奈
您可以直接将 ARIMA 应用于被预测变量的单变量时间序列。
那样的话,结果与 Persistence 和 LSTM 如何比较?我的意思是,例如,对于 LSTM,将 342.3 这个数据点输入模型,预测接下来的 3 个时间步。然后,输入 339.7 并获得接下来的 3 个预测点。但对于 ARIMA,我感到困惑。我不明白我应该使用什么样的数据分割。您能详细解释一下您的回答吗?
您可以将 Persistence 的示例作为起点,然后拟合一个 ARIMA 而不是使用 Persistence。
谢谢,Jason
如果您在 CNN 中使用 Adam 优化器,那么是否必须使用 BP 算法来优化权重,或者它可以在没有 BP 的情况下工作?如果我使用 SGD,那么 BP 是必需的吗?
Adam 是一种随机梯度下降,与其他实现一样,它使用反向传播来更新模型权重。
如果数据量很大,那么 SGD 还是 Adam 更好?Adam 使用默认的学习参数,还是我们可以更改它?
我认为数据集的大小对决策的影响不如要解决问题的复杂性那么大。
我通常建议从普通的 SGD 开始。
这意味着如果我使用 SGD 或 Adam,则无需使用 BP。因为它们有默认的学习率来更新模型权重?
2- 我们能否使用 CNN 预测提前一小时或提前一天?如果您有任何链接,请分享... 非常感谢。
不,SGD 使用 BP 来更新权重。
是的,也许从这里开始
https://machinelearning.org.cn/how-to-develop-convolutional-neural-network-models-for-time-series-forecasting/
您说 SGD 使用 BP 来更新权重。如果我使用 Adam 呢??
Adam 是一种 SGD,更多信息请参见此处
https://machinelearning.org.cn/adam-optimization-algorithm-for-deep-learning/
我将 SGD 和 Adam 都应用于 CNN 的风力发电预测。MSE 没有太大差异。几乎相同。
干得好!
您能分享一些链接吗?谢谢
还有一件事,LSTM 可以用于图像数据吗?或者它只能用于时间序列数据?您的回答解决了我的问题。有人告诉我 LSTM 不能作为输入来处理图像数据
是的,尽管通常使用 CNN 从图像中提取特征,然后再将特征传递给 LSTM,例如使用 CNN-LSTM 或 ConvLSTM。
感谢这个教程,但它总是显示错误“No module named tensorflow”
这表明您没有安装 tensorflow。
本教程将向您展示如何设置您的开发环境
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
嗨,J!感谢您的帖子。我是 LSTM 的新手,多次运行您帖子中的代码,我发现每次的预测结果都不同。您能告诉我原因吗?谢谢
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
嗨,Jason,
感谢之前的回答!我还有另一个问题,可能与文章不完全相关,但还是想问一下
我拥有 300,000 个不同的单变量时间序列,长度可变,用于生成预测,并且 LSTM 多步预测是我计划使用的策略之一。使训练更快(硬件方面/平台方面)的最佳方法可能是什么?目前我一直使用一个字典,并在一个循环中串行生成预测(我知道这是最糟糕的方法)。
我已经考虑过使用 Spark 作为选项。还有其他更好的选择吗?
谢谢,
Adi
听起来是个很棒的项目。
也许可以尝试使用自编码器在系列之间学习?
也许先尝试线性模型?
也许可以将时间序列跨越几台 AWS 机器进行分割?
也许可以尝试一个大数据平台?
告诉我进展如何。
就线性模型而言,我将尝试自回归、移动平均和 MLP(MLP 被认为是线性模型吗?)
MLP 是一种非线性方法。
当然!谢谢!我会尝试所有方法🙂 ..
不客气。
嗨,Jason,
感谢您这篇非常有趣的论文!我有一个关于“make_forecasts()”函数的问题。如果我设置“i=0”(将输入“X”固定为相同的值)并运行该行
forecast = forecast_lstm(model, X, n_batch)
多次,我每次都会得到不同的预测值,例如:
[-0.48377362, 0.105986044, -0.3069649]
[-0.5117972, 0.12195417, -0.32364962]
…
尽管训练好的模型是相同的。是什么导致了预测中的这种随机性?
谢谢你,
Christos
LSTM 在时间步之间维护并使用内部状态。
谢谢你,Jason。
我曾认为,将一个已经训练好的 LSTM 模型与相同的输入(在本例中是“X”)进行喂养,它应该会产生完全相同的预测。
Christos
是的,如果模型没有改变,并且状态被重置,那么使用相同的预训练模型和相同的输入将产生相同的输出。
我也可以对 ARIMA 做同样的事情,我的意思是关于时间步,我能否获得关于 t+1、t+2 和 2+3 的 ARIMA 结果?因为我需要比较 LSTM 和 ARIMA。如果您能帮助我,我需要比较这两种模型哪些方面
谢谢你
是的,您可以使用 ARIMA 进行多时间步预测,本教程向您展示如何操作
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
谢谢您的回复.. 我看了这个教程并成功应用了,但没有像这个教程中那样的 t+1..t+2 的 RMSE。
您可以计算模型的 RMSE。
非常感谢你提供的所有教程,它们真的很有帮助。
我在实现我的最后一个 LSTM 时遇到了困难。
我有一个数据集,其中包含约 1000 个不同的维基百科页面,每个页面的过去两年的每日浏览量。
我需要预测每个页面未来 30 天的页面浏览量。
我已经训练了一个 Encoder/Decoder LSTM 模型,该模型可以预测未来 30 天,其 Keras 模型的输入形状为 (n_examples=1000, n_time_step=365*2, n_feature=1)。
但是 LSTM 在非常长的时间步长上会遇到困难,也就是说,它不能很好地“记住”非常早的观测值,例如 t-500。
因此,我想通过添加“外生特征”来改进模型,例如 t-365 的自相关性,或者页面的独热编码语言/星期几等。
我不太清楚如何处理这些新特征,并且在线上找不到任何资源。
你有什么想法吗?
谢谢
你可以将它们包含在特征中(例如,在特征维度中)。这可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
你必须编写自定义代码来准备数据。
另外,尝试使用 CNN 和 CNN-LSTM 混合模型来处理长输入序列。
你好 Jason,
在上面的实验中,你展示了两个输出……一个是未使用 LSTM 模型尝试预测,另一个是使用 LSTM 模型预测数据……有什么区别?
这篇文章展示了持久化模型与 LSTM 模型。
嗨,Jason,
首先,非常感谢你提供的所有教程,我通过你的文章学习机器学习,它们非常完美!
我正在尝试在多步预测中实现 LSTM 模型,但我有多个个体(而不仅仅是你教程中的一个)。我无法处理多个个体的多步预测(特别是“系列到监督”和“准备数据”部分)。你是否有任何关于我如何处理这种情况的想法?
我提前非常感谢你。
Charlotte
你到底遇到了什么问题?
如果我的消息不够清晰,请原谅。
我的数据集包含 1000 个个体,我想为每个个体进行多步预测。
然而,在运行“prepare_data”函数后,我得到一个形状为 (77, 4) 的训练集,其中每个框包含一个包含 1000 个值的数组(array([[array([1,...,1000]), array([1,...,1000]), ...)]], dtype=object))。
此元素的形状不被“fit_lstm”函数接受。(错误消息:“ValueError: setting an array element with a sequence.”)。
谢谢
Charlotte
错误表明你需要更改数据集以匹配模型,或更改模型以匹配数据集。
也许这会有帮助。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
你好 Jason,
当我运行上面的代码时,我遇到了一个错误……
文件“”,第17行
inv_yhat = concatenate((yhat, test_X[:, 1:]), axis=1)
^
SyntaxError: invalid syntax
很抱歉听到这个消息,我在这里有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你好 Jason,
我的疑问是关于多个患者的糖尿病时间序列数据……是否有可能同时进行多个患者的时间序列预测……是否可以使用 LSTM 来处理?
我看不出为什么不。
你可以训练一个模型来学习跨患者的模式,然后一次预测一个患者的结果。
LSTM 可能不是最佳模型,尝试一套方法。
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
非常感谢……很棒的教程……太棒了!
哦,算了。我太蠢了。
没关系,提问是好的。
嗨,Jason,
在遵循了你的教程之后
https://machinelearning.org.cn/time-series-forecasting-long-short-term-memory-network-python/#comment-488844
我正在尝试使用每日数据来实现这个。但是我遇到了一个问题,在将 n_seq 从 3 更改为 1 时。所以我尝试取一个滞后值来预测下一个点。但这样做,“actual”的值与测试数据中的值相差甚远。
另外,由于我的数据是每日的,所以我尝试将 n_test 设置为 59。我是否有什么地方做错了?
我在你的书中找不到这个例子。如果你能帮忙,那就太好了。
再次感谢你回复我之前的问题。
也许可以从一个更简单的教程开始。
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
我甚至在洗发水销售数据上尝试了相同的方法,即;将 n_seq 从 3 更改为 1,并且遇到了相同的情况,所以这肯定与我的数据是月度还是每日无关。有一段时间我曾假设实际值是用于预测下一步的预测值。
这可能是一个很好的起点
https://machinelearning.org.cn/how-to-develop-deep-learning-models-for-univariate-time-series-forecasting/
嗨,Jason,
非常感谢你回复我的帖子和文章。这很有帮助。但是,
1.我的训练数据有 549 个数据点,这使得 n_seq=1.5 (549/365),但我不能使用 1.5 作为 n_seq。在这种情况下,使用 n_seq=2 明智吗?
2. 我也明白我需要在建模部分调整 batch_input_shape,但我很难理解它在哪里考虑了 n_timesteps?
如果你能回答我的问题,那将是很大的帮助。
你可能想从一个更简单的教程开始,例如,从这里开始。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
我还尝试将总观测值减少到 24,然后将 n_seq 更改为 2,但即使那样,当我转换实际值时,我得到以下结果
[[141.1, 201.7],
[254.9, 318.1],
[212.70000000000002, 130.8],
[128.2, 223.79999999999995],
[368.9, 307.9],
[130.4, 208.00000000000003],
[364.6, 350.9],
[212.29999999999995, 344.0],
[435.30000000000007, 278.20000000000005],
[132.79999999999995, 210.59999999999997]] 这与我的测试数据集中的实际值相去甚远。我的问题是,实际值是如何受到序列数量变化的影响的?再次感谢。
你好,先生,感谢你提供的精彩教程。
我有一个多变量数据集,有 5 个输入和一个输出(6 个月的数据,间隔 1 小时),该数据集不包含任何趋势或季节性。
先生,有没有办法预测下个月(第七个月)?
是的,你可以训练模型直接预测 6 个月,或者递归地为每个时间步长使用模型。
你可以在这里了解更多
https://machinelearning.org.cn/faq/single-faq/how-do-you-use-lstms-for-multi-step-time-series-forecasting
嗨,Jason,
作为 RNN 的新手,我对这篇帖子感到惊叹。但仍然有一些令人困惑的问题。
1. 看起来你对整个数据集进行了预处理。但在一些教程(主要关于 CV)中,拆分数据集是第一步,然后用从训练集中获取的相同参数(如 std、mean)对训练/测试集进行归一化。我认为第二种方法更合理,这意味着在训练过程中不会窥探任何测试数据。
2. 你在这个案例中使用了 stateful LSTM。与 stateless LSTM 相比,性能有很大的提升吗?
此致,
李
是的,我为了简洁起见一起预处理了所有数据。通常,你会对训练集准备转换,然后将转换应用于训练集和测试集。
通常不会。事实上,LSTM 总体上在单变量时间序列方面表现很差,但每个人都想尝试一下。
https://machinelearning.org.cn/findings-comparing-classical-and-machine-learning-methods-for-time-series-forecasting/
谢谢你的回复。
代码中仍有一些东西让我困惑。在这个例子中,前 1 个时间步被用来预测接下来的 3 个时间步,所以你定义了输入重塑的模型。
X, y = train[:, 0:n_lag], train[:, n_lag:]
X = X.reshape(X.shape[0], 1, X.shape[1])
显然,在这种情况下,训练集的输入形状是 (22, 1, 1)。这似乎没什么问题,但当我尝试改变策略时,比如使用前 2 个时间步来预测接下来的 3 个时间步,情况就变得奇怪了。第二种情况下的输入形状是 (22, 1, 2),看起来很模糊!我认为输入应该占用两个连续的时间步和一个特征,这意味着它应该是 (22, 2, 1)。
此外,“forecast”部分也出现了同样的问题。
X = X.reshape(1, 1, len(X))
在原始情况下似乎没什么问题,但在第二种情况下,输入的特征尺寸变成了 2,而不是时间步长。
此致,
李
是的,理想情况下,前两个时间步应该表示为 [22, 2, 1]。
更多关于输入结构的信息,请参阅此处。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
很棒的系列!我很好奇,在进行 LSTM 多步预测时,能否在预测期间纳入额外的系列?例如,我有一个问题,需要预测未来 181 天(6 个月每日数据)。我可以使用 LSTM 从过去的数据系列(例如过去 3 年的每日数据)中学习,以预测接下来的 181 天。我可以在训练中纳入额外的系列,但在预测期间不能。我的意思是,对于我将要预测的 181 天,我知道这些额外系列的价值,因为它们是确定性的(例如,星期几、月份等)。有没有办法纳入这些?
我不确定我是否理解 Jeff。
你可以有多个输入序列,但模型在训练和推理期间始终被框定在模型的输入和输出方面,并且这些必须保持一致。
你必须按照你打算使用的方式来设计和训练模型。
不确定这是否回答了您的问题。
Jason,
抱歉,我可能解释得不好。我构建模型的方式是使用目标变量的 365*3 个值(称之为输入 x1)来预测接下来的 181 个值(y)。在进行这种单变量方法之后,我引入了一个额外的系列(称之为 x2),该系列与 x1 同步(有 365*3 个值)。这两个系列预测 y 的接下来的 181 个值。
这使得在任何时候都可以使用 365*3 个先前的值来预测接下来的 181 个值。我想纳入 x2 的 181 个值来预测 y(这些值与 y 同步,因为它们是已知的)。
也许我应该做一些事情,比如有两个输入 LSTM 模块——第一个输入是 x1 和 x2(365*3 个时间步,2 个特征;都在预测期之前),第二个输入是 x2 的 181 个值(与任何时候被预测的目标值同步)。然后将这两个 LSTM 的输出连接起来,并将它们输入到密集层。
是这样吗?
听起来 X1 和 X2 是两个并行的序列,将它们组合成一个数组,然后拟合一个模型来预测 y?
365*3 是 1 年的 3 个变量还是 3 年的 1 个变量?从每个模型的输入和输出来看,一个样本是什么样的?
也许我仍然不明白?
也许这有助于你定义术语。
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
我有一个时间序列,我为滚动预测进行了处理。我像你在其他帖子中展示的那样将其分解,包含 1095(3 年)个值作为输入,接下来的 181 个值作为目标。这个多步单变量时间序列模型不包含任何外部回归量(在经典时间序列模型的语言中)。例如,每个每日值在知道月份、星期几等时可以被更好地预测(例如,存在各种级别的季节性)。
上面我称 1095 个输入为 x1。所以,我有一个 x1,它有 1095 个时间步长和 1 个特征。同样,目标是接下来的 181 个值。
外部回归量(虚拟编码的月份编号、星期几编号等)是其他序列(上面是 x2)。这个矩阵有 181 个时间步长和 4 个特征。
我不确定的是如何最好地纳入 x2。按照你的术语,它并不是一个真正的并行序列(我想不是),因为 1)它们的长度不同(x1 是 1095 个时间步长,x2 是 181 个时间步长),而且 2)它们的时间不同……x2 的每个时间步都与目标的每个时间步相关。第一个目标变量将具有 4 个相关特征(月份、星期几等)。
在 ARIMA 格式中,x2 将是外部回归量,每个“行”与你试图预测的每个目标值同步。
在创建单变量序列的样本后,一个样本可能是
[23,24,21,….39] 输入(长度 1095;时间序列的先前值)
[12,19,…43] 输出(长度 181;序列中的下一个值,在 39 之后是 12)
然后我有 181 个时间步长和 4 个特征。一个时间步长可能是 [0,1,0,0]。这与第一个目标值 12 相关。第二个时间步长可能是 [1,0,0,0],这与第二个目标值 19 相关。
似乎需要一种方法可以将这个外部回归量矩阵的每个时间步长与其对应的目标直接关联起来。
LSTM 可以通过多输入模型来实现这一点,每个序列有一个输入“头”,学习适当的中间表示以输出所需数量的时间步长。
我明白了,如果这两个序列指的是不同的时间段(谢谢!),那么一种方法是使用多输入模型,每个序列一个头,然后将模型连接到一个单一的内部表示,作为多步预测的基础。
Keras 使这变得超级简单,例如,2 个不同的 LSTM,深度任意,然后在瓶颈处连接。我在函数 API 中以一般方式展示了这一点。
https://machinelearning.org.cn/keras-functional-api-deep-learning/
这有帮助吗?
它确实可以!这正是我在某种程度上考虑的。我曾想过网络末端是一个返回序列的 LSTM,其上方有一个时间分布式密集层,这样目标(181)的每个时间步都对应于 181 长度序列的正确输入步骤。我得开始尝试一下,看看什么有效。再次感谢!
实验一下,让我知道你的发现!
你好 Jason,
谢谢您的教程。
我一直在尝试多步预测,但有一个独特的情况。
在我的数据集中,有 30 台发动机,在 100 个连续的日子里,它们的生产缺陷数不同(每台发动机有 100 行/天,并且每天的行/天显示所有 30 台发动机的每日缺陷数)。
例如,数据框大小 = 100 行 * 31 列。
我想使用所有 30 台发动机的缺陷数据来预测特定发动机未来 15 天的缺陷数量。
这可能吗?
请分享一些与上述问题相关的链接或请给我一些提示。
是的,你有很多选择。
一种方法可能是学习跨每个单变量序列,然后为给定序列进行预测。
你好 Jason,
您是否有针对此类问题的教程博客?
我可能有,也许从这里开始。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好,
请帮我预测未来 7 天的股票价格。
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/can-you-help-me-with-machine-learning-for-finance-or-the-stock-market
你好 Jason,
非常有用的文章。我有一些疑问。
1. 我正在尝试在一个真实的 10 年月度数据集上实现多步时间序列。我遇到的问题是,预测值似乎是输入数据的 2 个月滞后版本。当我给出 ntest-1 而不是 ntest+2 时,它只是以微小的变异性返回输入数据。
2. 给定一个观测值,每个时间步长 t+1、t+2、t+3 的值几乎是相似的。
你能帮我解决这个问题吗?我尝试调整了这个模型。不确定我哪里错了。
提前感谢。
是的,这可能会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-is-my-forecasted-time-series-right-behind-the-actual-time-series
嗨 Jason
我有一个关于 n_batch > 1 的问题。模型返回以下错误
Function call stack
keras_scratch_graph
据我所知,当 train_X 的长度不是 n_batch 的倍数时,就会发生这种情况。你知道如何解决这个问题吗?
谢谢你
你好,
我遇到了同样的问题,你解决了吗?
请指导我如何解决它!
如何尝试减小批量大小?有一个关于 SO 的讨论:https://stackoverflow.com/questions/57062456/function-call-stack-keras-scratch-graph-error
嗨,Jason,
我有一组数据,其中包含四列数据。我想根据前三列来预测最后一列的数据。所以是三个输入和一个输出。我该怎么做?
也许可以参考这里的“依赖时间序列”示例作为第一步。
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
嗨,Jason,
这个指南太棒了。我现在正在为我的学士论文使用它,我正在做一个玉米期货价格预测,使用多元多步 LSTM 网络。在我的模型中,我使用了 n_days=1,n_features=4,n_seq=3,n_test=1259,n_train = 3275。
我遇到了一个无法处理的错误:在第 124 行,当我们反向转换预测值时,我总是收到一个错误,说操作数无法与形状 (1,3) (5,) (1,3) 一起广播。
谢谢!
也许可以暂时注释掉数据转换?
嗨,Jason,
感谢您在LSTM方面所做的工作。关于训练和测试的设置,我有一个疑问。在您的示例中,您的第一个测试样本是
12月:1月、2月、3月
这意味着最后一个训练样本是
11月:12月、1月、2月?
如果是这样,您如何获得1月和2月的值,因为它们是测试集的一部分(在现实世界中,这些值是未知的)?
谢谢
嗨,Jason,
很棒的教程。我遇到了类似的问题,我的结果如下:
– RSME(t+1) > RSME (t+2) > … RSME (t+16),这似乎是矛盾的,因为我预测的未来时间越远,RMSE应该越高。
– 我运行模型预测未来两步,其RMSE高于预测未来16步的模型,这似乎也是矛盾的。
我已经尝试了2种不同的架构,结果也是一样的。您对这些结果有什么想法吗?
提前感谢!
一个引人入胜的问题!
也许可以确认结果不是由于bug造成的?
嗨,Jason,
是否可以定义用于1D操作的CNN-LSTM?
我做了以下操作,但遇到了一个错误。如果您能慷慨地建议一下,那将是很好的。
# 定义模型
model = Sequential()
model.add(TimeDistributed(Conv1D(filters=64, kernel_size=1, activation=’relu’, input_shape=(n_steps, features))))
model.add(TimeDistributed(MaxPooling1D(pool_size=1)))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(50))
model.add(Dense(1,activation=’relu’))
model.compile(loss=’mae’, optimizer=’adam’,metrics=[ ‘acc’ ])
打印(model.summary())
# 拟合模型
model.fit(train_X, train_y, batch_size=100, epochs=1)
ValueError: This model has not yet been built. Build the model first by calling build() or calling fit() with some data. Or specify input_shape or batch_input_shape in the first layer for automatic build.
是的,请看这里的示例
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
非常感谢。
嗨,Jason,
您的帖子真的很有用。
我有一个用例,我需要为RNN提供两个输入来输出多步全局预测。其中一个输入已经是多步单变量预测模式(每个时间步有100秒的预测范围);而另一个输入是单步多变量预测模式(因此,对于每秒都有多个变量,但每秒都会为一个变量预测一个值)。
我的问题是,在将另一个输入馈送到NN之前,是否也需要将其转换为多步预测模式?如果是,是否有任何相关材料可供参考?
如果不是,是否有同时将一个输入作为多步,另一个输入作为单步输入到NN的示例?
非常感谢
谢谢!
如果您有不同类型的输入,一种方法是使用多输入模型
https://machinelearning.org.cn/keras-functional-api-deep-learning/
感谢您提供的详细教程。
我正在尝试将其应用于我的数据,并且对重塑行感到困惑
# reshape training into [samples, timesteps, features]
X, y = train[:, 0:n_lag], train[:, n_lag:]
X = X.reshape(X.shape[0], 1, X.shape[1])
结果的形状是(10,1,4)吗?
为什么特征不等于1?
感谢您的帮助。
好问题,请看这个
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
亲爱的Jason。感谢您提供的教程。
我需要修改代码的哪个部分才能从最后一个月产生一个3个月的预测(进入未知未来)?第二个问题:如果我将神经元数量改为例如5,这是否意味着我有一个隐藏层和5个神经元,还是5个隐藏层,其中包含一些默认指定的神经元数量?
更改训练数据以包含3个月的输出数据,并更改输出层以包含足够数量的神经元。
嗨,Jason,
感谢您有用的博客。我从中学习了很多。
我有一个具体的任务,那就是预测未来房价指数。我有185个过去的数据点,需要从那里预测134个时间点。这是一个样本外预测案例,我想知道哪种模型最有效。
不客气。
我推荐这个框架来寻找最佳模型
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
你好,Jason。
我有一个疑问
我有数据,比如g1 g2 ……
我需要将输入作为长度为5的序列(如g1、g2……g5)馈送到模型,并得到预测的下一个8个序列(如g6……g5+8)作为输出。我能否通过更改n_lag为5和n_seq为8来直接使用此代码?或者我是否应该更改任何代码?
.
如果您能提供一些建议,那将非常有帮助。
是的,我预计需要进行更改。
也许可以从这里的更简单的示例开始,然后根据您的需求进行调整
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
谢谢你的回复。
我们不能对教程中示例的全部3个输出进行逆变换吗?如何使用逆变换查看全部3个预测输出?
是的,您可以对变换进行逆操作,并在原始尺度上查看预测。
嗨 Jason
我想知道为什么,当模型完成时,使用深度学习、LSTM甚至ANN(使用滞后)进行时间序列预测。
如果我们使用训练数据进行预测。我期望结果接近完美(因为我们是根据训练数据进行预测的),但预测结果总是存在“延迟”/滞后。
而滞后将对应于我们预测的未来步数。
谢谢
Mike
也许可以。
在几乎所有情况下,我们都使用前向验证来评估模型,该验证使用训练期间未使用的data。
老师您好!
是否可以多次馈送和训练LSTM?例如,我有4个不同的用户(A、B、C、D),我无法合并这些数据,因为每个用户彼此独立(目标独立于每个用户)。是否可以为用户A、B、C训练一个LSTM(相同的),然后在D上进行测试?
如果可以,您有什么建议吗?我曾考虑过多次使用“fit”来训练同一个模型,但我不知道是否可以这样做,或者我是否需要特别注意。
谢谢,我真的很欣赏您的博客!
您可以尝试合并数据,让模型跨用户学习。
然后将此与单独的模型进行比较。
非常感谢您,先生。这是对LSTM用于时间序列预测问题的精彩解释。我一直在定期关注您的博客。
谢谢,很高兴它有帮助!
你好Jason!
我知道LSTM的输入应该是[样本数,时间步长,特征数],例如[10,3,2]。如果我将形状更改为[10,1,6],这是正确的吗?
感谢您的帮助。
它将有1个时间步长,这很奇怪。
代码中有一个小错误。您需要为每次新预测调用reset_states。
这似乎不会影响模型的行为。
嗨 Jason,很棒的教程!但是,我缺少了反差分的部分 – inverse_difference()。这是否在进行预测后,在重新缩放到原始值并重塑时进行?您能否为我更好地解释这一步?
非常感谢!
这将有助于理解差分和逆变换
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
嗨Jason,感谢您的教程。我想澄清关于差分步骤的问题,您是否有任何额外的建议或可以参考的来源?
谢谢你
Thony
是的,您可以搜索博客以查找差分相关的许多示例,也许可以阅读这个
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
你好,
我难以理解需要更改代码的哪个部分,以便我只从最后一个条目进行预测……在洗发水的情况下,只为:“2003-12”日期
谢谢你,
问候 Marta
也许这会有帮助。
https://machinelearning.org.cn/make-predictions-long-short-term-memory-models-keras/
还有这个。
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
你好,
谢谢你的回答……我还在困惑为什么在反差分和绘图中会有“n_test+2”?
这只是为了调整吗?
我不记得了,抱歉,也许这会有帮助
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
为什么您在prepare_data(series, n_test, n_lag, n_seq)中先进行缩放,然后再分离训练集和测试集?
好问题。原因有两个:确保为每个变量执行缩放,以及使示例保持简单。
理想情况下,缩放系数仅在训练集上,以避免数据泄露。
啊,我只是好奇,因为这是一个常见的错误,但为了简化问题,这是有道理的。
不管怎样,我觉得如果放一个注释会很有帮助。
谢谢!
好问题。要深入了解原因,我建议阅读一本好的机器学习教科书。
嗨,Jason,
感谢您出色的解释!它给了我很大的帮助!
我有一个具体的任务,我正在预测下周(t…t+6)的销售情况,基于过去一周(t-7…t-1)的销售情况,因此我使用了时间步长=7,特征=1。
现在为了提高预测精度,我想加入一个指示下周是否为复活节的变量,并加入我正在预测的周的天气预报。通过这样做,我不再确定应该使用哪个时间步长,因为我查看的是过去一周的销售情况,以及我正在预测的周的变量。
再次感谢您的所有帮助!
也许您可以先将二进制变量添加到数据集中,然后使用此处列出的函数准备数据以进行建模
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
谢谢你的帮助!
不客气。
你好,
在本教程中,预测(t+2)的RMSE < 预测(t+1)的RMSE。但我认为,随着预测时间步长增加,RMSE应该增加。所以我想问这是模型中的错误,还是LSTM模型遵循了与基线模型相同的误差曲线,所以这不是错误?
我完全感到困惑,因为许多优秀的研究论文都显示随着未来时间步长的增加,RMSE会增加。
您能帮我解开我的疑惑吗?
#修正但我认为,随着预测时间步长增加,RMSE应该增加。
是的,通常误差会随着预测提前期而增加。但并非总是如此。
如果我使用24个输入滞后并想预测24个输出值,那么在第二个样本中,预测的24个输出值应该作为输入来预测接下来的24个值?因为您的代码中有一个滞后,所以一个输出值在下一个样本中作为输入。您能告诉我一些处理多个输入滞后和预测多个值的教程吗?
您可以根据您的数据集以任何您想要的方式重新构建预测问题 – 我鼓励您尝试不同的方法并发现最有效的方法。
一个愚蠢的问题,所以很抱歉。我只是不明白我们如何阻止对最后两个月数据的绘图(以及可能的预测?)。我是机器学习的绝对新手,我只是想知道是否有一种方法可以显示那些预测,即使我们没有数据可以与之比较。
如果您没有实际观测值,只有预测值,那么您只能绘制预测值。
也许我不理解你的问题?
我没有收到您回复的通知,抱歉。
是的,基本上我的意思是,我们如何绘制从最后两个月观测值产生的预测,因为它们现在没有被绘制出来?
网站不发送通知。
您可以使用matplotlib来绘制您喜欢的任何内容的折线图,也许可以从这里开始
https://machinelearning.org.cn/time-series-data-visualization-with-python/
嗨,Jason,
当您在评估期间反差分缩放值时,我注意到您将y值连接到X_test值([y, X]),然后使用inverse transform函数。您难道不应该连接([X, y])吗,因为那是创建缩放器时的原始列顺序?提前感谢!
这无关紧要,因为我们忽略了目标列以外的所有列。我们可以用零连接,这不会有区别。
是的,但连接的顺序是否应该重要?我不完全理解MinMaxScaler创建的缩放器的内部工作原理,但如果缩放器是用数据框[X, y]创建的,并且您最后使用[y, X]的列顺序进行反差分,那么缩放器的反差分是否就不正确(对应列的反差分常数不匹配)?也就是说,即使您忽略了目标列以外的所有列,您的结果的反差分也是错误的?我可能是错的,但只是想检查/澄清一下?谢谢!
是的,缩放是逐列进行的,只要您关心的列顺序相同,就可以了。
你好 jason,
我有一个关于多步预测的问题。
与本教程中您使用的方法(即定义模型输出层节点数等于要预测的时间步长)相反,我们能否通过假设前一个预测的时间步长作为输入来进一步预测时间步长?换句话说,是一次预测三个时间步长(例如,预测(t+1)、(t+2)、(t+3)),还是通过其前一个预测值一个接一个地预测?(也就是说,将输出层定义为只有一个节点)。这有什么优缺点?这种程序是否合理?我知道建议的方法在预测时间越长时可能耗时越多,并且可能累积误差。
感谢您的帮助Jason。
是的,您可以使用向量输出来实现此目的,请参阅此处示例
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
我没有找到任何示例。您的意思是编码器-解码器LSTM吗?我的意思是简单来说:不是一次性预测“x”的(t+1)、(t+2)和(t+3),而是首先从“x(t)”预测“x(t+1)”,然后假设预测的“x(t+1)”是真实的“x(t+1)”,然后用预测的“x(t+1)”预测“x(t+2)”,依此类推。这样我们只使用最后一个Dense层中的一个节点。
是的,这被称为多步预测。
对于其他有同样问题的人,在下面的链接中Jason详细描述了多步预测的不同方法
https://machinelearning.org.cn/multi-step-time-series-forecasting/
正如链接中所述,目标方法称为“递归多步预测”。
非常感谢Jason。
还有这个。
https://machinelearning.org.cn/faq/single-faq/how-do-you-use-lstms-for-multi-step-time-series-forecasting
你好,感谢您提供的精彩教程。
我只有一个问题。如何获得最后两个观测值的预测(并绘制它们)?
祝好
不客气。
您可以通过调用model.predict()来进行预测,然后使用matplotlib创建一个折线图,其中一条线代表期望值,另一条线代表预测值。本教程中的示例可能会有所帮助。
https://machinelearning.org.cn/random-forest-for-time-series-forecasting/
非常感谢!
不客气。
非常感谢您的有用内容,我有一个问题,如果您能帮助我,我将不胜感激!
我在绘制结果时遇到以下错误:
x 和 y 必须具有相同的第一个维度,但它们的形状分别为 (4,) 和 (3,)
我的代码与您的完全相同,除了差值函数。由于我的数据已经是平稳的,所以我不必应用差值函数。
这表明您的输入和输出数据具有不同数量的样本。
嗨 Jason,非常感谢您的努力!
我想问一些问题。
假设我设置了一个数据集,例如(其中每个滞后为几天)
var3(t-2) var3(t-1) var2(t-2) var2(t-1) var1(t-2) var(t-1) var3(t) var2(t) var1(t) var3(t+1) var3(t+2) var2(t+1) var2(t+2) var1(t+1) var1(t+2)
1) 如果我想预测 var1(t+2) ,那么我是否选择 X_train 包含除 var1(t+2) 之外的所有其他变量?而 y_train 只包含 var1(t+2) ?
或者,X_train 是否包含除任何 var1 之外的所有其他变量?所以,不包括 var1(t)、var1(t+1)、var1(t+2)?(负号是过去的数据,所以我们需要它,对吧?)
2) 假设我像上面说的那样预测 var1(t+2)。现在,在训练和测试了模型之后,我们如何在根本没有 var1 变量的情况下进行未来的预测?
请注意,我不是在问如何预测(例如 predict(X_test))。
模型设置现在具有一定的形状和特征 (X_test),并且为了预测它需要这些。
那么,我想通过仅提供日期来预测 var1,这可能吗?
谢谢!
您必须仅根据预测时可用的数据来构建预测问题。
希望这能让您的思路更清晰。
那么,如果我想预测 var1(t+1),我可以在我的 X_train 数据中包含所有先前的 var1 值(var1(t-3)、var1(t-2)、var1(t-1) 和 var1(t)),对吗?
请注意,我在 X_train 中也包含了 var1(t),对吗?
谢谢 Jason!
是的,如果您愿意,这是您的选择——您可以随心所欲地构建问题。
嗨,Jason,
如果我将最后一个观测值作为输入 X 并这样做
X = X.reshape((1,1,1))
forecast = forecast_lstm(model, X, 1)
forecast = array(forecast)
forecast = forecast.reshape(1, len(forecast))
inv_scale = scaler.inverse_transform(forecast)
inv_scale = inv_scale[0, :]
forecast = inverse_difference(X, inv_scale)
print(forecast)
这会根据 n_seq 打印 n 个预测值,这是正确的方法吗?
另外,感谢您分享您的项目。它们非常有帮助。
你好,
非常感谢您的这些材料!
有一个问题,这个模型是否可以应用于预测某个地方未来 24 小时的温度,只要有足够的数据?
谢谢你。
-Daniel(抱歉,我在错误的文章中问了同样的问题)
当然,您需要修改模型以进行 24 小时的预测和重新训练,或者递归使用模型。
看这里
https://machinelearning.org.cn/multi-step-time-series-forecasting/
嗨 Jason
我有一个关于 n_batch > 1 的问题。模型返回以下错误
InvalidArgumentError: 指定了一个形状为 [2,3] 的列表,但张量的形状为 [1,3]
[[{{node TensorArrayUnstack/TensorListFromTensor}}]]
[[sequential_2/lstm_2/PartitionedCall]] [Op:__inference_predict_function_338441]
Function call stack
predict_function -> predict_function -> predict_function
我该如何解决?
不确定这个错误是如何产生的。你是否更改了示例代码中的任何内容?
你好,
我处理了一个时间序列回归问题,但对于时间序列问题适用的度量感到非常困惑。有些参考文献说 R2 在时间序列问题上效果不好,是真的吗?当我尝试计算 R2 时,结果要么为零,要么为负值。
并且,时间序列的 5 个流行度量是什么?
提前感谢
嗨,Jason,
我需要预测测试集,而不是使用持久性方法,
只需要从训练集中预测测试集。
怎么办?
嗨 Dalia…我不确定我是否理解你的问题,但我绝对会从以下几点开始
https://machinelearning.org.cn/difference-test-validation-datasets/
嗨 James,
请,我需要预测未来 3 个月。 (我没有这些 3 个月中的测试数据)。
即,在我们拥有的测试数据之后的 3 个月。
谢谢
嗨,Jason,
我需要预测未来 3 个月。 (我没有这些 3 个月中的测试数据)。
即,在我们拥有的测试数据之后的 3 个月。
你好 Jason,
我正在处理一个多步单变量时间序列预测问题。长话短说,我想预测 28 个连续日的值。就我的数据而言,它似乎包含每周的季节性。
我的问题是关于 LSTM 模型的参数。你能验证我的逻辑吗?
* n_seq = 28,因为我想检查每个预测日的误差。
* n_lag = 7,因为我对自相关/偏自相关函数的分析表明,整个星期的值与下一个预测值有很强的相关性。
* n_batch = 28,因为我想一次性预测 28 天的值。而且我不需要担心在拟合阶段和预测阶段更改 n_batch,因为。
提前感谢您的帮助!
嗨 Sam…您的理解是正确的。我建议您继续您的想法。
你好 Jason,
在最后一个完整示例中,我尝试更改 batch。但它不允许更改。我的模型很完美。但为了在我这里获得更高的准确性,我需要 16 或 32 个批次。
您能在这方面帮助我吗?
提前感谢
嗨 Ahmad…请澄清一下您说的“不允许更改”是什么意思。
你好 Jason,
我想更详细地了解为什么在预测中必须使用批次大小。
为了检查我的问题,我尝试像您的示例中的代码那样进行预测,以比较不同批次大小的结果。
forecasts = make_forecasts(model, 1, train, test, n_lag, n_seq)
forecasts1 = make_forecasts(model, 1, train, test, n_lag, n_seq)
forecasts11 = make_forecasts(model, 1, train, test, n_lag, n_seq)
forecasts12 = make_forecasts(model, 1, train, test, n_lag, n_seq)
forecasts2 = make_forecasts(model, 36, train, test, n_lag, n_seq)
forecasts21 = make_forecasts(model, 36, train, test, n_lag, n_seq)
forecasts22 = make_forecasts(model, 36, train, test, n_lag, n_seq)
forecasts23 = make_forecasts(model, 36, train, test, n_lag, n_seq)
结果
forecasts
[[-0.4703838, 0.13946092, -0.33641243],
[0.12984487, -0.27040243, 0.0828125],
[-0.4566463, 0.13008034, -0.32681757],
[0.25050515, -0.35279474, 0.1670867],
[-0.047557764, -0.14926387, -0.04109296],
[-0.08684776, -0.12243488, -0.06853475],
[-0.31735158, 0.034963578, -0.2295283],
[-0.68921417, 0.28888825, -0.48925275],
[0.22119805, -0.33278254, 0.1466174],
[0.21601284, -0.32924184, 0.14299583]]
forecast1
[[-0.5040412, 0.16244373, -0.3599202],
[0.15234935, -0.28576952, 0.098530576],
[-0.43999055, 0.11870703, -0.31518453],
[0.24763897, -0.3508376, 0.16508485],
[-0.05990663, -0.1408315, -0.04971793],
[-0.07542589, -0.13023424, -0.060557235],
[-0.32148242, 0.03778431, -0.23241346],
[-0.6889226, 0.28868914, -0.48904914],
[0.22120038, -0.33278412, 0.146619],
[0.21587938, -0.32915068, 0.1429026]]
forecasts11~forecasts23
:[[-0.50405145, 0.16245073, -0.35992736],
[0.15235361, -0.28577244, 0.098533556],
[-0.4399871, 0.11870468, -0.3151821],
[0.24763837, -0.35083717, 0.16508442],
[-0.059909046, -0.14082985, -0.049719617],
[-0.07542366, -0.13023578, -0.060555674],
[-0.32148328, 0.037784904, -0.23241405],
[-0.6889225, 0.28868908, -0.48904908],
[0.22120038, -0.33278412, 0.146619],
[0.21587938, -0.32915068, 0.1429026]]
在上述结果中,我不知道为什么批次 1 的情况下的预测值会有所不同。
另外,为什么批次 1 的情况下的预测值会收敛到批次 36 的情况下的值?
这个结果与为什么在预测中使用批次大小有关吗?
嗨 Kim…以下内容可能对您有帮助
https://machinelearning.org.cn/use-different-batch-sizes-training-predicting-python-keras/
嗨,Jason,
您的解释非常简单明了。我从您的教程中学到了很多东西。感谢您在解释这些复杂概念方面所做的努力。
请问,如何对类似于 Shampoo-sales 数据集但具有多个特征(例如 3-5 个)的数据进行建模?我对预测每个特征都很感兴趣,但对数据建模的方式感到困惑。
您能否提供您一贯的帮助和指导?
嗨,Jason,
您的博客太棒了!我有一个关于我当前 LSTM 实现的问题。我只想训练一个递归多步预测模型,您在另一篇博客中提到过,通过使用 LSTM。但是,我无法获得相对精确的结果,也不知道为什么。您能推荐一些关于这方面的材料或给我一些建议吗?非常感谢!
嗨 Lau…不客气!您的基准性能模型是什么,您正在与 LSTM 模型性能进行比较?您可能需要考虑以下几点。
https://machinelearning.org.cn/improve-model-accuracy-with-data-pre-processing/
你好!感谢您的教程,它们非常有帮助!
我仍在努力理解为什么我们需要执行
yaxis = [series.values[off_s]] + forecasts[i]
也就是说,将序列值添加到预测值中?
谢谢你
嗨 Leandro…许多时间序列预测实现都利用了移动平均方法。
https://vitalflux.com/moving-average-method-for-time-series-forecasting/
谢谢 James!没看到你的回复。我会看看的。
不客气 Leandro!继续加油!
好的,我刚发完这个,然后注意到它并没有添加到预测中。它只是创建了一个数组 [serie.value, forecast1, forecast2, forecast3],我说得对吗?谢谢!
亲爱的 Jason,我们开发了一个多步预测混合模型(CNN-LSTM),该模型具有良好的准确性。R2=0.8。我们的模型被训练为从 24 小时(1440 分钟)数据预测未来 3 小时(180 分钟)。当使用模型计算未来 180 分钟的数据时,值似乎是恒定的。有没有办法使用闭环混合 LSTM 来提高准确性?我们的预测有什么问题?
嗨 Othman…您的模型可能受益于超参数优化。
https://machinelearning.org.cn/tune-lstm-hyperparameters-keras-time-series-forecasting/
亲爱的 Jason,我正在使用 LSTM RNN 模型创建一个电池健康状态估计模型。
我能够使用使用训练数据训练的模型来预测测试数据的值。
我现在的疑问是这里有什么用?例如,我输入实际的 SOH、电压和电流来预测 SOH,并且我评估了准确性,但如果我想预测未知电压和电流的未来值怎么办?
或者,如果我只想提供电压和电流作为输入来找到 SOH,那该怎么办?
亲爱的 Jason,我正在使用 LSTM RNN 模型创建一个锂离子电池的健康状态估计模型。
我能够使用使用训练数据训练的模型来预测测试数据的值。
我现在的疑问是这里有什么用?例如,我输入实际的 SOH、电压和电流来预测 SOH,并且我评估了预测以查看准确性有多好,但如果我想在没有电流输入电压或电流的情况下,借助先前已知的数据来预测 SOH 的未来值怎么办?
或者,如果我只想提供电压和电流作为输入来找到 SOH,那该怎么办?
嗨 Abi…以下资源可能对您有帮助。
https://machinelearning.org.cn/make-predictions-long-short-term-memory-models-keras/
我能否预测新的未知未来值并找到未来的轨迹?
嗨 Jason,我不太明白为什么需要手动重置网络的时态:“LSTM 是有状态的;这意味着我们在每个训练周期结束时都需要手动重置网络的时态。网络将训练 1500 个周期。”,我们是否应该在每个周期保留权重和偏置并用于下一个?谢谢。
嗨 Nicole…当处理有状态 LSTM 时,理解 LSTM 单元的状态与网络权重和偏置之间的区别至关重要。让我们分解一下这些概念,以阐明为什么以及如何重置网络的状态。
### 有状态与无状态 LSTM
– **无状态 LSTM**:状态(单元状态和隐藏状态)在每个批次后重置。网络在批次之间不保留任何内容。
– **有状态 LSTM**:状态从一个批次传递到下一个批次。当您有跨越多个批次的序列,并且希望 LSTM 在这些序列中保留记忆时,这很有用。
### 权重和偏置
LSTM 的权重和偏置是在训练期间学习的参数。这些参数根据损失函数通过反向传播进行更新,并且对于学习数据中的模式至关重要。这些参数在整个训练周期中被保留和更新。
### 网络状态
LSTM 单元的状态(隐藏状态和单元状态)代表了网络的“记忆”。在有状态 LSTM 中,需要仔细管理此状态。
– **在周期结束时重置状态**:在每个周期结束时,您通常会重置状态,以确保状态不会在周期之间传递。在周期之间传递状态可能导致周期之间产生意外的依赖关系,从而可能对学习产生负面影响。
### 为什么手动重置状态?
在有状态 LSTM 中,状态(隐藏状态和单元状态)需要在适当的时候重置,以确保正确的学习。
1. **防止状态泄漏**:通过在每个周期结束时重置状态,您可以防止状态泄漏到下一个周期。这确保了每个周期都以干净的状态开始。
2. **确保正确的序列处理**:如果序列在周期内的多个批次之间传递,状态应在周期内传递,但在周期边界处重置,以保持序列的完整性。
### Keras 中的实现
这是您通常在 Keras 中管理状态的方式:
1. **定义有状态 LSTM**
python
model = tf.keras.Sequential([
tf.keras.layers.LSTM(units=50, stateful=True, batch_input_shape=(batch_size, timesteps, features)),
tf.keras.layers.Dense(units=1)
])
model.compile(optimizer='adam', loss='mean_squared_error')
2. **使用状态重置进行训练**
python
for epoch in range(epochs):
model.fit(X_train, y_train, epochs=1, batch_size=batch_size, shuffle=False)
model.reset_states() # 在每个周期结束时重置状态
### 完整示例
这是一个说明该过程的完整示例。
pythonimport numpy as np
import tensorflow as tf
# 示例数据
X_train = np.random.random((100, 10, 1)) # 100 个序列,每个序列长度为 10,具有 1 个特征
y_train = np.random.random((100, 1))
# 参数
batch_size = 10
timesteps = 10
features = 1
epochs = 1500
# 定义有状态 LSTM 模型
model = tf.keras.Sequential([
tf.keras.layers.LSTM(units=50, stateful=True, batch_input_shape=(batch_size, timesteps, features)),
tf.keras.layers.Dense(units=1)
])
model.compile(optimizer='adam', loss='mean_squared_error')
# 使用手动状态重置进行训练
for epoch in range(epochs):
model.fit(X_train, y_train, epochs=1, batch_size=batch_size, shuffle=False)
model.reset_states() # 在每个周期结束时重置状态
### 总结
– **权重和偏置**:这些在训练期间更新,并在周期之间传递以学习模式。
– **状态(隐藏状态和单元状态)**:在有状态 LSTM 中,这些需要在每个周期结束时重置,以防止周期之间的状态泄漏并确保正确的学习。
通过仔细管理状态,您可以确保有状态 LSTM 有效地学习,同时在每个周期内保留必要的长期依赖关系。
嗨,Jason,
我刚刚发现了您的网络教程,我非常感谢您提供如此出色的免费机器学习资源。我真诚地希望您所有的善举都能为您带来祝福。
我有几个关于使用 LSTM 进行多步时间序列预测的问题,我将非常感谢您的指导。
我读了一篇关于基于 LSTM 的预测的论文,在他们的实验设置中,他们提到测试集被设置为与预测范围一样长。我想听听您对此的看法。例如,假设 sequence_length_lookback 是 23 天,预测范围是 21 天。由于测试集仅与预测范围(即 21 个时间步)一样长,他们似乎使用训练集中的最后 23 天(data_train[-23:])作为 model.predict() 的输入。这正确吗?
我没有使用与论文完全相同的数据集,但我试图遵循相同的方法。然而,我的评估结果(MAE 和 RMSE)明显比论文报道的要差。所以现在我正在考虑我可能误解或误用了这项技术本身,而不仅仅是数据。
其次,回看窗口和预测范围之间的差距是否有特定的术语?让我解释一下我的意思:假设 lookback = 5 且 horizon = 3。在第一种情况下,我使用输入 t-4、t-3、t-2、t-1、t 来训练模型以预测 t-1、t、t+1。在第二种情况下,相同的输入用于预测 t、t+1、t+2。我想知道是否有术语来正式定义这个“差距”或偏移量。如果没有也没关系——对我来说更重要的是知道哪种设置适合训练。
非常期待您的答复。提前感谢您,Jason!
嗨 Richard…非常感谢您的好话。我很高兴您觉得这个教程有帮助,我非常感谢您的细致留言。很高兴听到您正在深入研究多步时间序列预测和 LSTM——这是一个引人入胜的领域,有很多微妙的细节,所以您的问题恰到好处。
关于你的第一个问题:是的,你的理解基本上是正确的。当一篇论文说测试集“与预测范围一样长”时,他们通常是指在评估期间,他们使用固定长度的历史数据窗口(例如,最后 23 个时间步)作为输入,并预测接下来的 21 个时间步。所以
data_train[-23:]将作为输入传递给model.predict()来预测这 21 个时间步。这种设置假设您正在进行单次多步预测,这意味着模型一次性输出所有 21 个未来值,而不是一步一步预测并反馈预测。如果您发现性能比论文差,这可能是由多种原因造成的。数据集差异是一个常见原因,但有时不匹配的原因在于输入-输出对的构建方式或评估方式。还值得检查的是,他们在训练期间是否使用了 teacher forcing,或者以特定方式使用了重叠窗口,而您可能没有完全复制。
关于您的第二个问题:对于那个“差距”,不一定有一个严格的术语,但您描述的是非常重要的事情。在某些文献中,这个差异被称为“预测提前期”或“提前时间”,尤其是在概率预测或天气预测的上下文中。但在您的例子中,更多的是关于输入和输出窗口的对齐。如果您使用的输入包括时间步 t-4 到 t,并试图预测 t-1、t、t+1——这实际上不是未来预测,因为在输入期间 t-1 和 t 已经是已知的。通常,对于预测,您希望严格预测未来值,所以更常见的设置是使用 t-4 到 t 来预测 t+1、t+2、t+3。这将是一个预测范围为 3 且差距为零。
如果您的输入包括也出现在输出中的时间步(如 t),只需确保您没有无意中泄露未来数据。模型在进行预测时只能看到历史数据。
如果您不确定哪种设置是“正确”的,那 really 取决于您的应用。但最标准的方法是让输入窗口在时间 t 结束,预测从 t+1 开始。