随着智能电表和太阳能电池板等发电技术的广泛应用,大量的用电数据可供使用。
这些数据代表了一个与电力相关的多元时间序列,进而可以用于建模甚至预测未来的用电量。
机器学习算法预测的是单个值,不能直接用于多步预测。有两种策略可用于使用机器学习算法进行多步预测:递归方法和直接方法。
在本教程中,您将学习如何使用机器学习算法开发递归和直接多步预测模型。
完成本教程后,您将了解:
- 如何为线性、非线性以及集成机器学习算法的多步时间序列预测制定评估框架。
- 如何使用递归多步时间序列预测策略评估机器学习算法。
- 如何使用直接的每日和每前瞻时间步的多步时间序列预测策略评估机器学习算法。
开始您的项目,阅读我的新书《深度学习时间序列预测》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

面向家庭用电量的机器学习模型的多步时间序列预测
照片由 Sean McMenemy 拍摄,部分权利保留。
教程概述
本教程分为五个部分;它们是:
- 问题描述
- 加载并准备数据集
- 模型评估
- 递归多步预测
- 直接多步预测
问题描述
“家庭用电量”数据集是一个多元时间序列数据集,描述了四年内单个家庭的用电量。
数据收集于 2006 年 12 月至 2010 年 11 月期间,每分钟收集一次家庭用电量的观测值。
它是一个多元序列,包含七个变量(除了日期和时间);它们是
- global_active_power:家庭消耗的总有功功率(千瓦)。
- global_reactive_power:家庭消耗的总无功功率(千瓦)。
- voltage:平均电压(伏特)。
- global_intensity:平均电流强度(安培)。
- sub_metering_1:厨房的有功电能(瓦时有功电能)。
- sub_metering_2:洗衣房的有功电能(瓦时有功电能)。
- sub_metering_3:气候控制系统的有功电能(瓦时有功电能)。
有功电能和无功电能指的是交流电的技术细节。
第四个子计量变量可以通过将三个定义的子计量变量的总和从总有功电能中减去来创建,如下所示
|
1 |
sub_metering_remainder = (global_active_power * 1000 / 60) - (sub_metering_1 + sub_metering_2 + sub_metering_3) |
加载并准备数据集
该数据集可以从 UCI 机器学习仓库下载,为一个 20 兆字节的 .zip 文件
下载数据集并将其解压缩到当前工作目录。现在您将拥有文件“household_power_consumption.txt”,其大小约为 127 兆字节,并包含所有观测值。
我们可以使用 read_csv() 函数加载数据,并将前两列合并为一个日期时间列,我们可以将其用作索引。
|
1 2 |
# 加载所有数据 dataset = read_csv('household_power_consumption.txt', sep=';', header=0, low_memory=False, infer_datetime_format=True, parse_dates={'datetime':[0,1]}, index_col=['datetime']) |
接下来,我们可以将用“?”字符表示的所有缺失值标记为 NaN 值,这是一个浮点数。
这将允许我们以一个浮点值数组而不是混合类型(效率较低)来处理数据。
|
1 2 3 4 |
# 标记所有缺失值 dataset.replace('?', nan, inplace=True) # 使数据集数值化 dataset = dataset.astype('float32') |
现在我们需要填补已标记的缺失值。
一个非常简单的方法是复制前一天同一时间的观测值。我们可以在一个名为 fill_missing() 的函数中实现这一点,该函数将接收数据的 NumPy 数组并复制 24 小时前的值。
|
1 2 3 4 5 6 7 |
# 用一天前同一时间的值填充缺失值 def fill_missing(values): one_day = 60 * 24 for row in range(values.shape[0]): for col in range(values.shape[1]): if isnan(values[row, col]): values[row, col] = values[row - one_day, col] |
我们可以直接将此函数应用于 DataFrame 中的数据。
|
1 2 |
# 填充缺失值 fill_missing(dataset.values) |
现在我们可以创建一个新列,其中包含子计量的剩余部分,使用上一节中的计算。
|
1 2 3 |
# 添加一个用于子计量剩余部分的新列 values = dataset.values dataset['sub_metering_4'] = (values[:,0] * 1000 / 60) - (values[:,4] + values[:,5] + values[:,6]) |
现在我们可以将清理后的数据集保存到一个新文件中;在这种情况下,我们只需将文件扩展名更改为 .csv 并将数据集保存为“household_power_consumption.csv”。
|
1 2 |
# 保存更新后的数据集 dataset.to_csv('household_power_consumption.csv') |
将所有这些串联起来,加载、清理和保存数据集的完整示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 加载和清理数据 from numpy import nan from numpy import isnan from pandas import read_csv from pandas import to_numeric # 用一天前同一时间的值填充缺失值 def fill_missing(values): one_day = 60 * 24 for row in range(values.shape[0]): for col in range(values.shape[1]): if isnan(values[row, col]): values[row, col] = values[row - one_day, col] # 加载所有数据 dataset = read_csv('household_power_consumption.txt', sep=';', header=0, low_memory=False, infer_datetime_format=True, parse_dates={'datetime':[0,1]}, index_col=['datetime']) # 标记所有缺失值 dataset.replace('?', nan, inplace=True) # 使数据集数值化 dataset = dataset.astype('float32') # 填充缺失值 fill_missing(dataset.values) # 添加一个用于子计量剩余部分的新列 values = dataset.values dataset['sub_metering_4'] = (values[:,0] * 1000 / 60) - (values[:,4] + values[:,5] + values[:,6]) # 保存更新后的数据集 dataset.to_csv('household_power_consumption.csv') |
运行示例会创建一个新的文件“household_power_consumption.csv”,我们可以将其作为建模项目的起点。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
模型评估
在本节中,我们将考虑如何为家庭用电数据集开发和评估预测模型。
本节分为四个部分;它们是
- 问题构建
- 评估指标
- 训练集和测试集
- 逐时验证
问题构建
有许多方法可以利用和探索家庭用电量数据集。
在本教程中,我们将使用数据来探索一个非常具体的问题;那就是
鉴于最近的用电量,未来一周的预期用电量是多少?
这要求预测模型预测未来七天每天的总有功功率。
技术上,这种问题框架被称为多步时间序列预测问题,因为它涉及多个预测步骤。利用多个输入变量的模型可以被称为多元多步时间序列预测模型。
这种类型的模型可能有助于家庭规划开支。它也可能有助于供应方规划特定家庭的电力需求。
这种数据集的框架还表明,将每分钟的用电量观测值下采样到每日总计可能很有用。这不是必需的,但考虑到我们关注的是每天的总功率,这样做是合理的。
我们可以很容易地使用 pandas DataFrame 上的 resample() 函数来实现这一点。使用参数‘D’调用此函数,可以按天对按日期时间索引加载的数据进行分组(参见所有偏移别名)。然后,我们可以计算每天所有观测值的总和,并为八个变量中的每一个创建每日电力消耗数据的新数据集。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 将分钟数据重新采样为每天的总量 from pandas import read_csv # 加载新文件 dataset = read_csv('household_power_consumption.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) # 将数据重新采样为每日数据 daily_groups = dataset.resample('D') daily_data = daily_groups.sum() # 总结 print(daily_data.shape) print(daily_data.head()) # 保存 daily_data.to_csv('household_power_consumption_days.csv') |
运行示例将创建一个新的每日总用电量数据集,并将结果保存到一个名为“household_power_consumption_days.csv”的单独文件中。
我们可以将其用作拟合和评估所选问题框架的预测模型的数据集。
评估指标
预测将由七个值组成,未来一周的每一天一个值。
在多步预测问题中,通常会单独评估每个预测时间步长。这有几个原因
- 评论特定提前期(例如,+1 天与 +3 天)的技能。
- 根据模型在不同提前期(例如,+1 天擅长的模型与 +5 天擅长的模型)的技能来对比模型。
总功率的单位是千瓦,拥有一个也是相同单位的误差度量将非常有用。均方根误差 (RMSE) 和平均绝对误差 (MAE) 都符合这一要求,尽管 RMSE 更常用,并且将在本教程中使用。与 MAE 不同,RMSE 对预测误差的惩罚更大。
此问题的性能指标将是第 1 天到第 7 天每个提前期的 RMSE。
作为一种捷径,为了帮助模型选择,使用单个分数来总结模型的性能可能很有用。
可以使用的一个可能分数是所有预测天的 RMSE。
下面的 evaluate_forecasts() 函数将实现此行为,并根据多个七天预测返回模型的性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 针对期望值评估一个或多个每周预测 def evaluate_forecasts(actual, predicted): scores = list() # 计算每一天的 RMSE 分数 for i in range(actual.shape[1]): # 计算 mse mse = mean_squared_error(actual[:, i], predicted[:, i]) # 计算 rmse rmse = sqrt(mse) # 存储 scores.append(rmse) # 计算整体 RMSE s = 0 for row in range(actual.shape[0]): for col in range(actual.shape[1]): s += (actual[row, col] - predicted[row, col])**2 score = sqrt(s / (actual.shape[0] * actual.shape[1])) return score, scores |
运行函数将首先返回与日期无关的整体 RMSE,然后返回每天的 RMSE 分数数组。
训练集和测试集
我们将使用前三年的数据进行预测模型训练,并使用最后一年进行模型评估。
给定数据集中的数据将划分为标准周。这些周以周日开始,以周六结束。
这是使用所选模型框架的一种现实且有用的方法,可以预测下周的用电量。这也有助于建模,其中模型可用于预测特定日期(例如,星期三)或整个序列。
我们将把数据划分为标准周,从测试数据集倒序进行。
数据的最后一年是 2010 年,2010 年的第一个星期日是 1 月 3 日。数据于 2010 年 11 月中旬结束,数据中最近的最后一个星期六是 11 月 20 日。这提供了 46 周的测试数据。
下面提供了测试数据集的每日数据的起始行和结束行以供确认。
|
1 2 3 |
2010-01-03,2083.4539999999984,191.61000000000055,350992.12000000034,8703.600000000033,3842.0,4920.0,10074.0,15888.233355799992 ... 2010-11-20,2197.006000000004,153.76800000000028,346475.9999999998,9320.20000000002,4367.0,2947.0,11433.0,17869.76663959999 |
每日数据始于 2006 年末。
数据集中的第一个星期日是 12 月 17 日,这是数据的第二行。
将数据组织成标准周后,用于训练预测模型的完整标准周有 159 个。
|
1 2 3 |
2006-12-17,3390.46,226.0059999999994,345725.32000000024,14398.59999999998,2033.0,4187.0,13341.0,36946.66673200004 ... 2010-01-02,1309.2679999999998,199.54600000000016,352332.8399999997,5489.7999999999865,801.0,298.0,6425.0,14297.133406600002 |
下面的 split_dataset() 函数将每日数据拆分为训练集和测试集,并将每个数据集组织成标准周。
使用数据集的已知信息,使用特定的行偏移量来分割数据。然后使用 NumPy split() 函数将分割后的数据集组织成周数据。
|
1 2 3 4 5 6 7 8 |
# 将单变量数据集拆分为训练/测试集 def split_dataset(data): # 拆分为标准周 train, test = data[1:-328], data[-328:-6] # 重构为每周数据的窗口 train = array(split(train, len(train)/7)) test = array(split(test, len(test)/7)) return train, test |
我们可以通过加载每日数据集并打印训练集和测试集的第一行和最后一行数据来测试此函数,以确认它们符合上述预期。
完整的代码示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 拆分为标准周 from numpy import split from numpy import array from pandas import read_csv # 将单变量数据集拆分为训练/测试集 def split_dataset(data): # 拆分为标准周 train, test = data[1:-328], data[-328:-6] # 重构为每周数据的窗口 train = array(split(train, len(train)/7)) test = array(split(test, len(test)/7)) return train, test # 加载新文件 dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) train, test = split_dataset(dataset.values) # 验证训练数据 print(train.shape) print(train[0, 0, 0], train[-1, -1, 0]) # 验证测试数据 print(test.shape) print(test[0, 0, 0], test[-1, -1, 0]) |
运行示例表明,训练集确实有 159 周的数据,而测试集有 46 周的数据。
我们可以看到,训练集和测试集的第一行和最后一行的总有功功率与我们定义为每个集合标准周边界的特定日期的数据相匹配。
|
1 2 3 4 |
(159, 7, 8) 3390.46 1309.2679999999998 (46, 7, 8) 2083.4539999999984 2197.006000000004 |
逐时验证
模型将使用一种称为“前向验证”的方案进行评估。
在这种情况下,模型需要进行一周的预测,然后该周的实际数据将提供给模型,以便模型可以作为后续一周预测的基础。这在实践中与模型的用法相符,并且对模型有益,可以使它们利用最佳可用数据。
我们可以在下面通过分离输入数据和输出/预测数据来演示这一点。
|
1 2 3 4 5 |
输入,预测 [第1周] 第2周 [第1周 + 第2周] 第3周 [第1周 + 第2周 + 第3周] 第4周 ... |
下面定义的函数 `evaluate_model()` 提供了评估此数据集上的预测模型的“前向验证”方法。
函数作为参数接收一个 scikit-learn 模型对象,以及训练和测试数据集。还提供了一个额外的参数 `n_input`,该参数用于定义模型将用于预测的先前观测值的数量。
scikit-learn 模型如何拟合和预测的细节将在后续章节中介绍。
然后,使用先前定义的 evaluate_forecasts() 函数,根据测试数据集评估模型所做的预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 评估单个模型 def evaluate_model(model, train, test, n_input): # 历史数据是每周数据的列表 history = [x for x in train] # 对每一周进行前向验证 predictions = list() for i in range(len(test)): # 预测这一周 yhat_sequence = ... # 存储预测结果 predictions.append(yhat_sequence) # 获取实际观测值并添加到历史记录中,用于预测下一周 history.append(test[i, :]) predictions = array(predictions) # 评估每周的预测天数 score, scores = evaluate_forecasts(test[:, :, 0], predictions) return score, scores |
在对模型进行评估后,我们可以汇总其性能。
下面名为 `summarize_scores()` 的函数将模型的性能显示为一行,以便与其他模型进行轻松比较。
|
1 2 3 4 |
# 总结得分 def summarize_scores(name, score, scores): s_scores = ', '.join(['%.1f' % s for s in scores]) print('%s: [%.3f] %s' % (name, score, s_scores)) |
我们现在拥有所有要素,可以开始评估数据集上的预测模型。
递归多步预测
大多数预测建模算法需要一定数量的观测值作为输入,并预测一个输出值。
因此,它们不能直接用于进行多步时间序列预测。
这适用于大多数线性、非线性以及集成机器学习算法。
一种可以使用机器学习算法进行多步时间序列预测的方法是递归使用它们。
这包括进行一个时间步的预测,然后将预测值作为输入反馈给模型,以预测下一个时间步。重复此过程,直到预测完所需步数。
例如
|
1 2 3 4 5 6 7 8 9 10 |
X = [x1, x2, x3] y1 = model.predict(X) X = [x2, x3, y1] y2 = model.predict(X) X = [x3, y1, y2] y3 = model.predict(X) ... |
在本节中,我们将使用递归模型进行多步预测,为拟合和评估 scikit-learn 提供的机器学习算法开发一个测试框架。
第一步是将准备好的每周多变量数据转换为单个单变量系列。
下面的 `to_series()` 函数将每周多变量数据列表转换为每日总用电量的单变量系列。
|
1 2 3 4 5 6 7 |
# 将每周多变量数据的窗口转换为总用电量系列 def to_series(data): # 提取每周的总用电量 series = [week[:, 0] for week in data] # 展平成一个系列 series = array(series).flatten() return series |
接下来,需要将每日用电量的序列转换为适合拟合监督学习问题的输入和输出。
预测将是先前日期总用电量的某个函数。我们可以选择用于输入的先前日期的数量,例如一周或两周。输出将始终是单个值:下一天的总用电量。
模型将在先前时间步的真实观测值上拟合。我们需要遍历每日用电量序列,并将其分割为输入和输出。这被称为滑动窗口数据表示。
下面的 `to_supervised()` 函数实现了此行为。
它以每周数据列表作为输入,以及用于每个创建的样本的先前日期的数量作为输入。
第一步是将历史记录转换为单个数据系列。然后对该系列进行枚举,为每个时间步创建一个输入和输出对。这种问题框架将允许模型学习在给定先前日期的观测值的情况下预测一周中的任何一天。该函数返回用于训练模型的输入(X)和输出(y)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 将历史数据转换为输入和输出 def to_supervised(history, n_input): # 将历史记录转换为单变量系列 data = to_series(history) X, y = list(), list() ix_start = 0 # 遍历整个历史记录,每次一个时间步长 for i in range(len(data)): # 定义输入序列的结束位置 ix_end = ix_start + n_input # 确保此实例有足够的数据 if ix_end < len(data): X.append(data[ix_start:ix_end]) y.append(data[ix_end]) # 前进一步 ix_start += 1 return array(X), array(y) |
scikit-learn 库允许模型作为管道的一部分使用。这允许在拟合模型之前自动应用数据转换。更重要的是,转换的准备方式是正确的,即它们在训练数据上准备或拟合,并在测试数据上应用。这可以防止在评估模型时发生数据泄露。
在评估模型时,我们可以通过在训练数据集上拟合每个模型之前创建管道来利用此功能。在将模型用于数据之前,我们将对数据进行标准化和归一化。
下面的 `make_pipeline()` 函数实现了此行为,它返回一个 Pipeline,该 Pipeline 的用法与模型类似,即它可以被拟合,也可以进行预测。
标准化和归一化操作是按列进行的。在 `to_supervised()` 函数中,我们实际上是将一列数据(总功率)拆分为多列,例如,七天输入观测值对应七列。这意味着输入数据中的七列中的每一列将具有不同的均值和标准差用于标准化,以及不同的最小值和最大值用于归一化。
鉴于我们使用了滑动窗口,几乎所有值都会出现在每一列中,因此这不太可能是一个问题。但需要注意的是,在将数据拆分为输入和输出之前,将其作为一列进行缩放会更严谨。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 为模型创建特征预处理管道 def make_pipeline(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline |
我们可以将这些元素组合到一个名为 `sklearn_predict()` 的函数中,如下所示。
该函数接受一个 scikit-learn 模型对象、训练数据(称为 history)以及指定用于输入的先前日期的数量。它将训练数据转换为输入和输出,将模型包装在管道中,对其进行拟合,并使用它进行预测。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 拟合模型并进行预测 def sklearn_predict(model, history, n_input): # 准备数据 train_x, train_y = to_supervised(history, n_input) # 创建管道 pipeline = make_pipeline(model) # 拟合模型 pipeline.fit(train_x, train_y) # 递归预测一周 yhat_sequence = forecast(pipeline, train_x[-1, :], n_input) return yhat_sequence |
模型将使用训练数据集的最后一行作为输入来做出预测。
`forecast()` 函数将使用该模型进行递归多步预测。
递归预测包括迭代七天中的每一天,这需要进行多步预测。
模型的数据输入取自 `input_data` 列表的最后几个观测值。此列表以训练数据最后一行中的所有观测值作为种子,并且在我们使用模型进行预测时,将它们添加到此列表的末尾。因此,我们可以从列表中获取最后 `n_input` 个观测值,以达到在下一次迭代中将先前输出作为输入的效果。
该模型用于对准备好的输入数据进行预测,输出既添加到我们将返回的实际输出序列的列表中,也添加到我们将从中提取观测值作为模型输入的输入数据的列表中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 进行递归多步预测 def forecast(model, input_x, n_input): yhat_sequence = list() input_data = [x for x in input_x] for j in range(7): # 准备输入数据 X = array(input_data[ # 进行单步预测 yhat = model.predict(X)[0] # 添加到结果中 yhat_sequence.append(yhat) # 将预测值添加到输入中 input_data.append(yhat) return yhat_sequence |
现在我们拥有了使用递归多步预测策略拟合和评估 scikit-learn 模型的所有要素。
我们可以更新上一节中定义的 `evaluate_model()` 函数来调用 `sklearn_predict()` 函数。更新后的函数如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 评估单个模型 def evaluate_model(model, train, test, n_input): # 历史数据是每周数据的列表 history = [x for x in train] # 对每一周进行前向验证 predictions = list() for i in range(len(test)): # 预测这一周 yhat_sequence = sklearn_predict(model, history, n_input) # 存储预测结果 predictions.append(yhat_sequence) # 获取实际观测值并添加到历史记录中,用于预测下一周 history.append(test[i, :]) predictions = array(predictions) # 评估每周的预测天数 score, scores = evaluate_forecasts(test[:, :, 0], predictions) return score, scores |
一个重要的最终函数是 `get_models()`,它定义了一个字典,其中包含 scikit-learn 模型对象,并映射到一个可用于报告的简写名称。
我们将首先评估一系列线性算法。我们期望它们的性能类似于自回归模型(例如,如果使用七天输入,则为 AR(7))。
下面定义了包含十个线性模型的 `get_models()` 函数。
这是一个抽样检查,我们感兴趣的是各种算法的总体性能,而不是优化任何特定算法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 准备要评估的机器学习模型列表 def get_models(models=dict()): # 线性模型 models['lr'] = LinearRegression() models['lasso'] = Lasso() models['ridge'] = Ridge() models['en'] = ElasticNet() models['huber'] = HuberRegressor() models['lars'] = Lars() models['llars'] = LassoLars() models['pa'] = PassiveAggressiveRegressor(max_iter=1000, tol=1e-3) models['ranscac'] = RANSACRegressor() models['sgd'] = SGDRegressor(max_iter=1000, tol=1e-3) print('已定义 %d 个模型' % len(models)) 返回 models |
最后,我们可以将所有这些内容联系起来。
首先,加载数据集并将其分为训练集和测试集。
|
1 2 3 4 |
# 加载新文件 dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) # 分割成训练集和测试集 train, test = split_dataset(dataset.values) |
然后,我们可以准备模型字典并定义要用作模型输入的先前观测值的数量。
|
1 2 3 |
# 准备要评估的模型 模型 = 获取_模型() n_input = 7 |
然后,枚举字典中的模型,评估每个模型,汇总其得分,并将结果添加到折线图中。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 |
# 使用线性算法进行递归多步预测 from math import sqrt from numpy import split from numpy import array from pandas import read_csv from sklearn.metrics import mean_squared_error from matplotlib import pyplot from sklearn.preprocessing import StandardScaler 从 sklearn.预处理 导入 MinMaxScaler from sklearn.pipeline import Pipeline 来自 sklearn.linear_model 导入 LinearRegression 来自 sklearn.linear_model 导入 Lasso from sklearn.linear_model import Ridge 来自 sklearn.linear_model 导入 ElasticNet from sklearn.linear_model import HuberRegressor from sklearn.linear_model import Lars from sklearn.linear_model import LassoLars from sklearn.linear_model import PassiveAggressiveRegressor from sklearn.linear_model import RANSACRegressor from sklearn.linear_model import SGDRegressor # 将单变量数据集拆分为训练/测试集 def split_dataset(data): # 拆分为标准周 train, test = data[1:-328], data[-328:-6] # 重构为每周数据的窗口 train = array(split(train, len(train)/7)) test = array(split(test, len(test)/7)) return train, test # 针对期望值评估一个或多个每周预测 def evaluate_forecasts(actual, predicted): scores = list() # 计算每一天的 RMSE 分数 for i in range(actual.shape[1]): # 计算 mse mse = mean_squared_error(actual[:, i], predicted[:, i]) # 计算 rmse rmse = sqrt(mse) # 存储 scores.append(rmse) # 计算整体 RMSE s = 0 for row in range(actual.shape[0]): for col in range(actual.shape[1]): s += (actual[row, col] - predicted[row, col])**2 score = sqrt(s / (actual.shape[0] * actual.shape[1])) return score, scores # 总结得分 def summarize_scores(name, score, scores): s_scores = ', '.join(['%.1f' % s for s in scores]) print('%s: [%.3f] %s' % (name, score, s_scores)) # 准备要评估的机器学习模型列表 def get_models(models=dict()): # 线性模型 models['lr'] = LinearRegression() models['lasso'] = Lasso() models['ridge'] = Ridge() models['en'] = ElasticNet() models['huber'] = HuberRegressor() models['lars'] = Lars() models['llars'] = LassoLars() models['pa'] = PassiveAggressiveRegressor(max_iter=1000, tol=1e-3) models['ranscac'] = RANSACRegressor() models['sgd'] = SGDRegressor(max_iter=1000, tol=1e-3) print('已定义 %d 个模型' % len(models)) 返回 模型 # 为模型创建特征预处理管道 def make_pipeline(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 进行递归多步预测 def forecast(model, input_x, n_input): yhat_sequence = list() input_data = [x for x in input_x] for j in range(7): # 准备输入数据 X = array(input_data[ # 进行单步预测 yhat = model.predict(X)[0] # 添加到结果中 yhat_sequence.append(yhat) # 将预测值添加到输入中 input_data.append(yhat) return yhat_sequence # 将每周多变量数据的窗口转换为总用电量系列 def to_series(data): # 提取每周的总用电量 series = [week[:, 0] for week in data] # 展平成一个系列 series = array(series).flatten() return series # 将历史数据转换为输入和输出 def to_supervised(history, n_input): # 将历史记录转换为单变量系列 data = to_series(history) X, y = list(), list() ix_start = 0 # 遍历整个历史记录,每次一个时间步长 for i in range(len(data)): # 定义输入序列的结束位置 ix_end = ix_start + n_input # 确保此实例有足够的数据 if ix_end < len(data): X.append(data[ix_start:ix_end]) y.append(data[ix_end]) # 前进一步 ix_start += 1 return array(X), array(y) # 拟合模型并进行预测 def sklearn_predict(model, history, n_input): # 准备数据 train_x, train_y = to_supervised(history, n_input) # 创建管道 pipeline = make_pipeline(model) # 拟合模型 pipeline.fit(train_x, train_y) # 递归预测一周 yhat_sequence = forecast(pipeline, train_x[-1, :], n_input) return yhat_sequence # 评估单个模型 def evaluate_model(model, train, test, n_input): # 历史数据是每周数据的列表 history = [x for x in train] # 对每一周进行前向验证 predictions = list() for i in range(len(test)): # 预测这一周 yhat_sequence = sklearn_predict(model, history, n_input) # 存储预测结果 predictions.append(yhat_sequence) # 获取实际观测值并添加到历史记录中,用于预测下一周 history.append(test[i, :]) predictions = array(predictions) # 评估每周的预测天数 score, scores = evaluate_forecasts(test[:, :, 0], predictions) return score, scores # 加载新文件 dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) # 分割成训练集和测试集 train, test = split_dataset(dataset.values) # 准备要评估的模型 模型 = 获取_模型() n_input = 7 # 评估每个模型 days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat'] for name, model in models.items(): # 评估并获取分数 score, scores = evaluate_model(model, train, test, n_input) # 汇总分数 summarize_scores(name, score, scores) # 绘制分数 pyplot.plot(days, scores, marker='o', label=name) # 显示图 pyplot.legend() pyplot.show() |
运行此示例将评估十个线性算法并汇总结果。
在评估每个算法时,性能会以一行的摘要形式报告,包括总 RMSE 以及每时间步的 RMSE。
注意:您的结果可能因算法或评估过程的随机性,或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
我们可以看到,大多数评估的模型表现都很好,整个星期的误差都低于 400 千瓦,其中随机梯度下降 (SGD) 回归器表现最好,总体 RMSE 约为 383。
|
1 2 3 4 5 6 7 8 9 10 11 |
已定义 10 个模型 lr: [388.388] 411.0, 389.1, 338.0, 370.8, 408.5, 308.3, 471.1 lasso: [386.838] 403.6, 388.9, 337.3, 371.1, 406.1, 307.6, 471.6 ridge: [387.659] 407.9, 388.6, 337.5, 371.2, 407.0, 307.7, 471.7 en: [469.337] 452.2, 451.9, 435.8, 485.7, 460.4, 405.8, 575.1 huber: [392.465] 412.1, 388.0, 337.9, 377.3, 405.6, 306.9, 492.5 lars: [388.388] 411.0, 389.1, 338.0, 370.8, 408.5, 308.3, 471.1 llars: [388.406] 396.1, 387.8, 339.3, 377.8, 402.9, 310.3, 481.9 pa: [399.402] 410.0, 391.7, 342.2, 389.7, 409.8, 315.9, 508.4 ranscac: [439.945] 454.0, 424.0, 369.5, 421.5, 457.5, 409.7, 526.9 sgd: [383.177] 400.3, 386.0, 333.0, 368.9, 401.5, 303.9, 466.9 |
还创建了每个分类器七天 RMSE 得分的折线图。
我们可以看到,除两种方法外,大多数方法都聚集在一起,并且在七天的预测中表现良好。
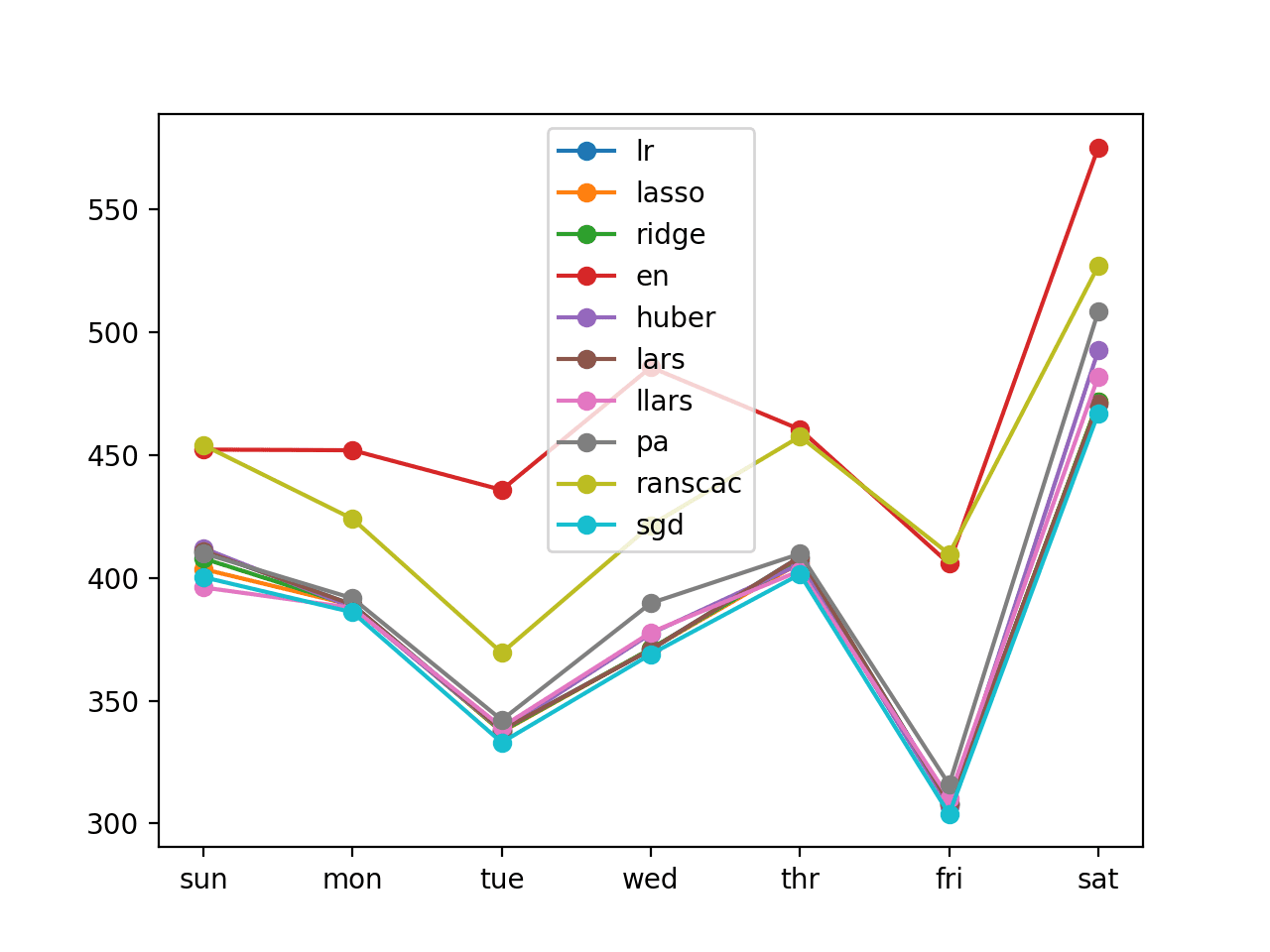
线性算法递归多步预测折线图
通过调整某些表现较好的算法的超参数,可能会获得更好的结果。此外,更新示例以测试一系列非线性算法和集成算法可能会很有趣。
一个有趣的实验可能是评估一个或几个表现较好的算法在更多或更少先前日期作为输入时的性能,例如使用两周的数据而不是一周。
直接多步预测
递归策略的一种替代多步预测方法是为要预测的每一天使用不同的模型。
这称为直接多步预测策略。
由于我们有七天的预测目标,这需要准备七个不同的模型,每个模型都专门用于预测不同的一天。
有两种方法可以训练此类模型
- 预测日期。可以准备模型来预测标准周的特定日期,例如星期一。
- 预测前瞻时间。可以准备模型来预测特定前瞻时间,例如第一天。
预测一天会更具体,但这意味着每个模型可以使用的训练数据更少。预测前瞻时间利用了更多的训练数据,但要求模型能够泛化到一周中的不同日期。
我们将在本节中探讨这两种方法。
直接日期方法
首先,我们必须更新 `to_supervised()` 函数来准备数据,例如用作输入的先前一周的观测值,以及用作输出的下一周特定日期的观测值。
下面列出了实现此行为的更新后的 `to_supervised()` 函数。它接受一个参数 `output_ix`,该参数定义了下一周中用于输出的日期 [0,6]。
|
1 2 3 4 5 6 7 8 |
# 将历史数据转换为输入和输出 def to_supervised(history, output_ix): X, y = list(), list() # 遍历整个历史记录,每次一个时间步长 for i in range(len(history)-1): X.append(history[i][:,0]) y.append(history[i + 1][output_ix,0]) return array(X), array(y) |
此函数可以调用七次,每次对应七个模型之一。
接下来,我们可以更新 `sklearn_predict()` 函数来为每个预测日创建一个新的数据集和一个新模型。
函数的主体基本保持不变,只是它在一个循环中针对输出序列中的每一天使用,其中一天“i”的索引被传递给 `to_supervised()` 调用,以准备用于训练模型预测该特定的数据集。
该函数不再接受 `n_input` 参数,因为我们将输入固定为先前一周的七天。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 拟合模型并进行预测 def sklearn_predict(model, history): yhat_sequence = list() # 为每个预测日期拟合模型 for i in range(7): # 准备数据 train_x, train_y = to_supervised(history, i) # 创建管道 pipeline = make_pipeline(model) # 拟合模型 pipeline.fit(train_x, train_y) # 预测 x_input = array(train_x[-1, :]).reshape(1,7) yhat = pipeline.predict(x_input)[0] # 存储 yhat_sequence.append(yhat) return yhat_sequence |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 |
# 通过日期进行直接多步预测 from math import sqrt from numpy import split from numpy import array from pandas import read_csv from sklearn.metrics import mean_squared_error from matplotlib import pyplot from sklearn.preprocessing import StandardScaler 从 sklearn.预处理 导入 MinMaxScaler from sklearn.pipeline import Pipeline 来自 sklearn.linear_model 导入 LinearRegression 来自 sklearn.linear_model 导入 Lasso from sklearn.linear_model import Ridge 来自 sklearn.linear_model 导入 ElasticNet from sklearn.linear_model import HuberRegressor from sklearn.linear_model import Lars from sklearn.linear_model import LassoLars from sklearn.linear_model import PassiveAggressiveRegressor from sklearn.linear_model import RANSACRegressor from sklearn.linear_model import SGDRegressor # 将单变量数据集拆分为训练/测试集 def split_dataset(data): # 拆分为标准周 train, test = data[1:-328], data[-328:-6] # 重构为每周数据的窗口 train = array(split(train, len(train)/7)) test = array(split(test, len(test)/7)) return train, test # 针对期望值评估一个或多个每周预测 def evaluate_forecasts(actual, predicted): scores = list() # 计算每一天的 RMSE 分数 for i in range(actual.shape[1]): # 计算 mse mse = mean_squared_error(actual[:, i], predicted[:, i]) # 计算 rmse rmse = sqrt(mse) # 存储 scores.append(rmse) # 计算整体 RMSE s = 0 for row in range(actual.shape[0]): for col in range(actual.shape[1]): s += (actual[row, col] - predicted[row, col])**2 score = sqrt(s / (actual.shape[0] * actual.shape[1])) return score, scores # 总结得分 def summarize_scores(name, score, scores): s_scores = ', '.join(['%.1f' % s for s in scores]) print('%s: [%.3f] %s' % (name, score, s_scores)) # 准备要评估的机器学习模型列表 def get_models(models=dict()): # 线性模型 models['lr'] = LinearRegression() models['lasso'] = Lasso() models['ridge'] = Ridge() models['en'] = ElasticNet() models['huber'] = HuberRegressor() models['lars'] = Lars() models['llars'] = LassoLars() models['pa'] = PassiveAggressiveRegressor(max_iter=1000, tol=1e-3) models['ranscac'] = RANSACRegressor() models['sgd'] = SGDRegressor(max_iter=1000, tol=1e-3) print('已定义 %d 个模型' % len(models)) 返回 模型 # 为模型创建特征预处理管道 def make_pipeline(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # 将历史数据转换为输入和输出 def to_supervised(history, output_ix): X, y = list(), list() # 遍历整个历史记录,每次一个时间步长 for i in range(len(history)-1): X.append(history[i][:,0]) y.append(history[i + 1][output_ix,0]) return array(X), array(y) # 拟合模型并进行预测 def sklearn_predict(model, history): yhat_sequence = list() # 为每个预测日期拟合模型 for i in range(7): # 准备数据 train_x, train_y = to_supervised(history, i) # 创建管道 pipeline = make_pipeline(model) # 拟合模型 pipeline.fit(train_x, train_y) # 预测 x_input = array(train_x[-1, :]).reshape(1,7) yhat = pipeline.predict(x_input)[0] # 存储 yhat_sequence.append(yhat) return yhat_sequence # 评估单个模型 def evaluate_model(model, train, test): # 历史数据是每周数据的列表 history = [x for x in train] # 对每一周进行前向验证 predictions = list() for i in range(len(test)): # 预测这一周 yhat_sequence = sklearn_predict(model, history) # 存储预测结果 predictions.append(yhat_sequence) # 获取实际观测值并添加到历史记录中,用于预测下一周 history.append(test[i, :]) predictions = array(predictions) # 评估每周的预测天数 score, scores = evaluate_forecasts(test[:, :, 0], predictions) return score, scores # 加载新文件 dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) # 分割成训练集和测试集 train, test = split_dataset(dataset.values) # 准备要评估的模型 模型 = 获取_模型() # 评估每个模型 days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat'] for name, model in models.items(): # 评估并获取分数 score, scores = evaluate_model(model, train, test) # 汇总分数 summarize_scores(name, score, scores) # 绘制分数 pyplot.plot(days, scores, marker='o', label=name) # 显示图 pyplot.legend() pyplot.show() |
运行此示例会首先汇总每个模型的性能。
注意:您的结果可能因算法或评估过程的随机性,或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
我们可以看到,在该问题上,性能略逊于递归模型。
|
1 2 3 4 5 6 7 8 9 10 11 |
已定义 10 个模型 lr: [410.927] 463.8, 381.4, 351.9, 430.7, 387.8, 350.4, 488.8 lasso: [408.440] 458.4, 378.5, 352.9, 429.5, 388.0, 348.0, 483.5 ridge: [403.875] 447.1, 377.9, 347.5, 427.4, 384.1, 343.4, 479.7 en: [454.263] 471.8, 433.8, 415.8, 477.4, 434.4, 373.8, 551.8 huber: [409.500] 466.8, 380.2, 359.8, 432.4, 387.0, 351.3, 470.9 lars: [410.927] 463.8, 381.4, 351.9, 430.7, 387.8, 350.4, 488.8 llars: [406.490] 453.0, 378.8, 357.3, 428.1, 388.0, 345.0, 476.9 pa: [402.476] 428.4, 380.9, 356.5, 426.7, 390.4, 348.6, 471.4 ranscac: [497.225] 456.1, 423.0, 445.9, 547.6, 521.9, 451.5, 607.2 sgd: [403.526] 441.4, 378.2, 354.5, 423.9, 382.4, 345.8, 480.3 |
还创建了每个模型每日期 RMSE 得分的折线图,显示了与递归模型相似的模型分组。

直接按日预测线性算法的多步预测折线图
直接前瞻时间方法
直接前瞻时间方法是相同的,只是 `to_supervised()` 利用了更多的训练数据集。
该函数与递归模型示例中的定义相同,只是它接受一个额外的 `output_ix` 参数来定义下一周中用于输出的日期。
下面列出了用于直接每前瞻时间策略的更新后的 `to_supervised()` 函数。
与按日策略不同,此函数确实支持可变大小的输入(不仅仅是七天),允许您随意试验。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 将历史数据转换为输入和输出 def to_supervised(history, n_input, output_ix): # 将历史记录转换为单变量系列 data = to_series(history) X, y = list(), list() ix_start = 0 # 遍历整个历史记录,每次一个时间步长 for i in range(len(data)): # 定义输入序列的结束位置 ix_end = ix_start + n_input ix_output = ix_end + output_ix # 确保此实例有足够的数据 if ix_output < len(data): X.append(data[ix_start:ix_end]) y.append(data[ix_output]) # 前进一步 ix_start += 1 return array(X), array(y) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 |
# 通过前瞻时间进行直接多步预测 from math import sqrt from numpy import split from numpy import array from pandas import read_csv from sklearn.metrics import mean_squared_error from matplotlib import pyplot from sklearn.preprocessing import StandardScaler 从 sklearn.预处理 导入 MinMaxScaler from sklearn.pipeline import Pipeline 来自 sklearn.linear_model 导入 LinearRegression 来自 sklearn.linear_model 导入 Lasso from sklearn.linear_model import Ridge 来自 sklearn.linear_model 导入 ElasticNet from sklearn.linear_model import HuberRegressor from sklearn.linear_model import Lars from sklearn.linear_model import LassoLars from sklearn.linear_model import PassiveAggressiveRegressor from sklearn.linear_model import RANSACRegressor from sklearn.linear_model import SGDRegressor # 将单变量数据集拆分为训练/测试集 def split_dataset(data): # 拆分为标准周 train, test = data[1:-328], data[-328:-6] # 重构为每周数据的窗口 train = array(split(train, len(train)/7)) test = array(split(test, len(test)/7)) return train, test # 针对期望值评估一个或多个每周预测 def evaluate_forecasts(actual, predicted): scores = list() # 计算每一天的 RMSE 分数 for i in range(actual.shape[1]): # 计算 mse mse = mean_squared_error(actual[:, i], predicted[:, i]) # 计算 rmse rmse = sqrt(mse) # 存储 scores.append(rmse) # 计算整体 RMSE s = 0 for row in range(actual.shape[0]): for col in range(actual.shape[1]): s += (actual[row, col] - predicted[row, col])**2 score = sqrt(s / (actual.shape[0] * actual.shape[1])) return score, scores # 总结得分 def summarize_scores(name, score, scores): s_scores = ', '.join(['%.1f' % s for s in scores]) print('%s: [%.3f] %s' % (name, score, s_scores)) # 准备要评估的机器学习模型列表 def get_models(models=dict()): # 线性模型 models['lr'] = LinearRegression() models['lasso'] = Lasso() models['ridge'] = Ridge() models['en'] = ElasticNet() models['huber'] = HuberRegressor() models['lars'] = Lars() models['llars'] = LassoLars() models['pa'] = PassiveAggressiveRegressor(max_iter=1000, tol=1e-3) models['ranscac'] = RANSACRegressor() models['sgd'] = SGDRegressor(max_iter=1000, tol=1e-3) print('已定义 %d 个模型' % len(models)) 返回 模型 # 为模型创建特征预处理管道 def make_pipeline(model): steps = list() # 标准化 steps.append(('standardize', StandardScaler())) # 归一化 steps.append(('normalize', MinMaxScaler())) # 模型 steps.append(('model', model)) # 创建管道 pipeline = Pipeline(steps=steps) return pipeline # # 将每周多变量数据的窗口转换为总用电量系列 def to_series(data): # 提取每周的总用电量 series = [week[:, 0] for week in data] # 展平成一个系列 series = array(series).flatten() return series # 将历史数据转换为输入和输出 def to_supervised(history, n_input, output_ix): # 将历史记录转换为单变量系列 data = to_series(history) X, y = list(), list() ix_start = 0 # 遍历整个历史记录,每次一个时间步长 for i in range(len(data)): # 定义输入序列的结束位置 ix_end = ix_start + n_input ix_output = ix_end + output_ix # 确保此实例有足够的数据 if ix_output < len(data): X.append(data[ix_start:ix_end]) y.append(data[ix_output]) # 前进一步 ix_start += 1 return array(X), array(y) # 拟合模型并进行预测 def sklearn_predict(model, history, n_input): yhat_sequence = list() # 为每个预测日期拟合模型 for i in range(7): # 准备数据 train_x, train_y = to_supervised(history, n_input, i) # 创建管道 pipeline = make_pipeline(model) # 拟合模型 pipeline.fit(train_x, train_y) # 预测 x_input = array(train_x[-1, :]).reshape(1,n_input) yhat = pipeline.predict(x_input)[0] # 存储 yhat_sequence.append(yhat) return yhat_sequence # 评估单个模型 def evaluate_model(model, train, test, n_input): # 历史数据是每周数据的列表 history = [x for x in train] # 对每一周进行前向验证 predictions = list() for i in range(len(test)): # 预测这一周 yhat_sequence = sklearn_predict(model, history, n_input) # 存储预测结果 predictions.append(yhat_sequence) # 获取实际观测值并添加到历史记录中,用于预测下一周 history.append(test[i, :]) predictions = array(predictions) # 评估每周的预测天数 score, scores = evaluate_forecasts(test[:, :, 0], predictions) return score, scores # 加载新文件 dataset = read_csv('household_power_consumption_days.csv', header=0, infer_datetime_format=True, parse_dates=['datetime'], index_col=['datetime']) # 分割成训练集和测试集 train, test = split_dataset(dataset.values) # 准备要评估的模型 模型 = 获取_模型() n_input = 7 # 评估每个模型 days = ['sun', 'mon', 'tue', 'wed', 'thr', 'fri', 'sat'] for name, model in models.items(): # 评估并获取分数 score, scores = evaluate_model(model, train, test, n_input) # 汇总分数 summarize_scores(name, score, scores) # 绘制分数 pyplot.plot(days, scores, marker='o', label=name) # 显示图 pyplot.legend() pyplot.show() |
运行此示例将汇总每个评估的线性模型的总体和每日 RMSE。
注意:您的结果可能因算法或评估过程的随机性,或数值精度的差异而有所不同。请考虑运行示例几次并比较平均结果。
我们可以看到,通常每前瞻时间方法比按日方法获得了更好的性能。这可能是因为该方法为模型提供了更多的训练数据。
|
1 2 3 4 5 6 7 8 9 10 11 |
已定义 10 个模型 lr: [394.983] 411.0, 400.7, 340.2, 382.9, 385.1, 362.8, 469.4 lasso: [391.767] 403.6, 394.4, 336.1, 382.7, 384.2, 360.4, 468.1 ridge: [393.444] 407.9, 397.8, 338.9, 383.2, 383.2, 360.4, 469.6 en: [461.986] 452.2, 448.3, 430.3, 480.4, 448.9, 396.0, 560.6 huber: [394.287] 412.1, 394.0, 333.4, 384.1, 383.1, 364.3, 474.4 lars: [394.983] 411.0, 400.7, 340.2, 382.9, 385.1, 362.8, 469.4 llars: [390.075] 396.1, 390.1, 334.3, 384.4, 385.2, 355.6, 470.9 pa: [389.340] 409.7, 380.6, 328.3, 388.6, 370.1, 351.8, 478.4 ranscac: [439.298] 387.2, 462.4, 394.4, 427.7, 412.9, 447.9, 526.8 sgd: [390.184] 396.7, 386.7, 337.6, 391.4, 374.0, 357.1, 473.5 |
同样创建了每日期 RMSE 得分的折线图。
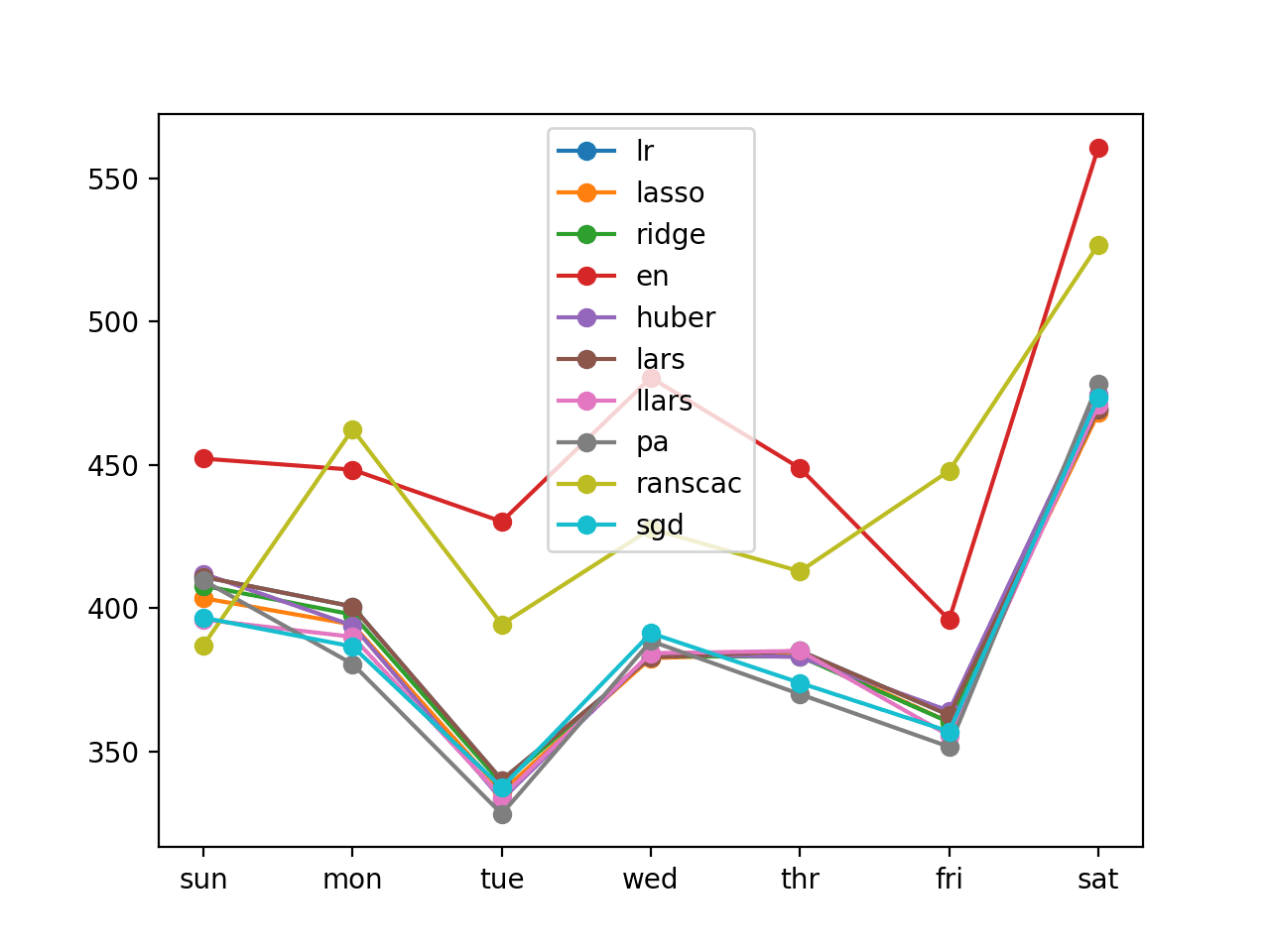
直接按前瞻时间预测线性算法的多步预测折线图
探索按日和按前瞻时间方法相结合的建模方法可能很有趣。
探索增加用于前瞻时间预测的先前日期数量,例如使用两周的数据而不是一周,可能也会很有趣。
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 调整模型。选择一个表现良好的模型,并调整模型超参数以进一步提高性能。
- 调整数据准备。在拟合每个模型之前,对所有数据进行了标准化和归一化;探索这些方法是否是必需的,以及是否更多或不同的数据缩放方法组合可以带来更好的性能。
- 探索输入大小。输入大小限制为七天的先前观测值;探索更多或更少的天数作为输入及其对模型性能的影响。
- 非线性算法。探索一系列非线性算法和集成机器学习算法,看看它们是否能提高性能,例如 SVM 和随机森林。
- 多元直接模型。开发利用先前一周所有输入变量的直接模型,而不仅仅是每日总用电量。这将需要将七天八个变量的二维数组展平成一维向量。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
API
- pandas.read_csv API
- pandas.DataFrame.resample API
- 重采样偏移别名
- sklearn.metrics.mean_squared_error API
- numpy.split API
文章
总结
在本教程中,您学习了如何使用机器学习算法开发递归和直接多步预测模型。
具体来说,你学到了:
- 如何为线性、非线性以及集成机器学习算法的多步时间序列预测制定评估框架。
- 如何使用递归多步时间序列预测策略评估机器学习算法。
- 如何使用直接的每日和每前瞻时间步的多步时间序列预测策略评估机器学习算法。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






机器学习在时间序列中使用时,如何处理季节性?
您可以计算季节性差值,或者让模型学习这种关系。
当模型使用递归预测策略时,我认为 history 应该使用
“ history.append(yhat)”
您能否解释一下为什么在您的模型中使用:“ history.append(test[i, :])”?
我在那里解释了不同的策略和何时使用它们
https://machinelearning.org.cn/multi-step-time-series-forecasting/
嗨 Jason,感谢您提供这篇精彩而有信息量的文章。我们如何观察每天的(46)个预测值?
此外,目标是回答这个问题:“鉴于近期的用电量,下周的预期用电量是多少?”
因此,我们如何从这些模型中创建为期 7 天的未来预测?
您可以选择一个模型和配置,训练一个最终模型,并开始使用它进行预测。
也许我没明白,你具体遇到什么问题了?
我只能看到每个模型的 RSME 值,我认为看到预测值也会很有益。例如,SGD 模型可能不如其他模型那样捕捉趋势,尽管它的整体 RSME 最低。
我该如何使用这些模型中的一个进行未来预测?这只是脚本的扩展,还是我们需要在其他地方创建单独的代码?
您可以通过调用 `model.predict()` 来进行预测
实际上,我展示了如何做到这一点,并提供了一个函数。
哪个部分有挑战?我会尽力帮忙。
我尝试在绘制完所有模型后,在单元格中输入以下内容:
for model in models.items()
model.predict(test)
但它返回错误:AttributeError: ‘tuple’ object has no attribute ‘predict’。
我不知道在哪里可以插入 `model.predict()`,因为每个“部分”都依赖于它上面的“部分”。未来的预测也是如此。
我建议在所有可用数据上拟合一个新的最终模型,并使用它来进行预测。
更多信息在这里
https://machinelearning.org.cn/make-predictions-scikit-learn/
在 `predictions = array(predictions)` 代码行下方添加:`print predictions` 可以得到预测值,但由于预测值太多,输出结果混乱。是否有办法获得每周的平均预测值?
抱歉打扰了。在 `predictions = array(predictions)` 行下方插入:`print(sum(predictions)/len(test))` 可以完成任务。但我仍然不确定如何实现未来预测。
嗨,Jason,
这里的内容真是太棒了,很有趣!恭喜你做得这么好!
你对你提到的“多元直接模型”有什么参考资料吗?
非常感谢。
是的,我这里有一些直接模型的例子
https://machinelearning.org.cn/multi-step-time-series-forecasting-with-machine-learning-models-for-household-electricity-consumption/
谢谢你的建议,Jason。我差不多完成了……
from sklearn.linear_model import SGDRegressor
from pandas import read_csv
df = read_csv(‘household_power_consumption_days.csv’, header=0, infer_datetime_format=True, parse_dates=[‘datetime’], index_col=[‘datetime’])
X_train = df.drop([‘Global_active_power’],axis=1)
Y_train = df[‘Global_active_power’]
model = SGDRegressor(max_iter=1000, tol=1e-3)
model.fit(X_train, Y_train)
Y_new = model.predict(X_new)
# 显示输入和预测输出
for i in range(len(X_new))
print(“X_train=%s, Predicted=%s” % (X_new[i], Y_new[i]))
我不知道如何定义 X_new?比如说,我想预测未来3天(2010年11月27日、2010年11月28日和2010年11月29日)的预测值。另外,我是否需要从 Y_train 中删除 datetime 列?
链接的预测文章是针对回归的。它肯定不能用于时间序列的未来预测,因为我们不知道任何特征的未来值?
Xnew 是任何用于进行预测的输入数据。
我在这里准确地解释了如何进行预测
https://machinelearning.org.cn/faq/single-faq/how-do-i-make-predictions
但我们可能没有输入数据可以设置为 X_new。未来预测仅依赖于当前数据。
您必须以一种方式构建您的问题,使您拥有的数据可以用来进行预测。
嗨,Jason,
感谢这些很棒的帖子——我刚接触 Python 和 ML,几乎所有知识都是通过您提供的示例学到的。
关于这一篇,我尝试了 3 种非线性 sklearn 模型(RandomForestReg、SVR、ExtraTreesReg),结果相似(RSME ~400),因此没有一种比 SGD 更好。
我想知道您是否为“多步多元时间序列预测”做过这样的示例,其中可以获取输入变量的预测值。
例如,有 10 天的天气预报(风、雨、温度等),模型应该预测有多少人去看电影;或者类似的情况。
如果您还没有做过这样的示例,如果您能考虑做一个,那就太好了。
我认为我在时间序列深度学习这本书中包含了一些示例。
另外,请查看这里的“空气污染”示例
https://machinelearning.org.cn/start-here/#deep_learning_time_series
感谢这些很棒的帖子。我遇到了一个错误
回溯(最近一次调用)
File “”, line 159, in
models = get_models()
File “”, line 70, in get_models
models[‘pa’] = PassiveAggressiveRegressor(max_iter=1000, tol=1e-3)
TypeError: __init__() got an unexpected keyword argument ‘max_iter’
因此,我该怎么办?
我在这里有一些建议
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
感谢您的博客,它对我的研究帮助很大。
这里有一个关于此博客 def get_models() 函数的问题。我可以使用自己构建的 LSTM 模型吗?因为我想将不同模型的预测结果与实际值进行比较。
谢谢!
最好为评估 LSTM 开发一个单独的框架。
我有很多博客上的示例。从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好 Jason,
非常感谢您精彩的教程。我有一个问题,如果我想使用这些机器学习模型,但输入是多元的。
我修改了代码,使其能够拟合不同的变量,方法是重塑数组。但是,
def forecast(model, input_x, n_input, n_features)
yhat_sequence = list()
input_data = [x for x in input_x]
for j in range(7)
# prepare the input data
X = array(input_data[-n_input:]).reshape(1, n_input*n_features)
# 进行一步预测
yhat = model.predict(X)
# add to the result
yhat_sequence.append(yhat[0])
# add the prediction to the input
input_data.append(yhat)
return yhat_sequence
有些东西我没弄懂,因为调用 model.predict(X) 后,X 是一个 (7,7) 重塑后的数组,我现在得到一个 7 个值的数组,并将第一个值 'yhat[0]' 作为我们想要预测的全球能源消耗。
但是,在更新 input_data 并且在第二次循环期间,我的新 X 只是一个数组 (7,)。但我的 input_data 列表包含了新添加的向量。我很难理解。
您知道问题可能出在哪里吗?似乎创建的 X 的新数组包含了所有 7 个观测值的数组。
谢谢你的帮助。
也许这篇教程能帮助你开始
https://machinelearning.org.cn/how-to-develop-lstm-models-for-time-series-forecasting/
嗨,Jason,
感谢您提供出色的教程。我读了一篇题为“基于居民行为学习的短期居民负荷预测”的文章,作者们将每分钟收集的当前读数转换为每 30 分钟的安培小时。
我的问题是,如果我们有每分钟的当前读数,那么如何将其转换为每 30 分钟的安培小时?
我联系了文章的作者,但没有收到回复。
我将非常感谢您在这方面的帮助。
这是文章的链接 https://ieeexplore.ieee.org/document/7887751
也许他们重新采样了观测值?
在论文中,作者们使用了这样的句子:“我们将每分钟的当前读数转换为每 30 分钟的安培小时,以模拟常用的智能电表数据。”
您从这句话中得出什么结论?
谢谢。
暂时不确定,也许可以联系作者?
要应用多元直接模型。您说需要将七天八个变量的二维数组展平成一维向量。这是否意味着
train_x = train_x.reshape((train_x.shape[0],train_x.shape[1]*train_x.shape[2]))
您是否有应用多元直接模型的示例?
谢谢!
是的,我相信那是正确的。
我不确定博客上是否有示例,也许有。尝试搜索一下。
我尝试了,但没有找到任何多元直接模型的示例。我之所以怀疑,是因为对于每个时间步长和每个单独的模型,在拟合模型时,model.fit(train_x, train_y),我在 model.coef_ 中得到 (7*n_features) 个系数(例如对于 lm),而我应该只得到 7 个系数(每个时间步长 1 个),对吗?谢谢!
您将为每个时间步长的每个时间序列拥有一个输入。
如果您有 7 天的输入和 3 个时间序列,那就是 21 个输入,需要 21 个系数才能组成一个线性模型。
你好 Jason,
我的训练数据形状如下:(100, 3, 11),显然是多元的。您说过在这种情况下,我们必须将二维数组展平成一维,如果我们这样做是否正确
train_x = train_x.reshape((train_x.shape[0], train_x.shape[1]*train_x.shape[2])) 在拟合模型之前??
但是,如果我们这样做,数据将具有形状:(100, 33),然而特征的数量只有 11 个。
我尝试了无数次在线搜索,但可惜没有找到。
提前感谢。
是的,因为每个时间步长有 11 个特征,有 3 个时间步长,所以 3*11 就是 33。
嗨,Jason,
我尝试按照您关于直接超前时间的方法的教程进行,但得到了不同的值
已定义 10 个模型
lr: [410.927] 463.8, 381.4, 351.9, 430.7, 387.8, 350.4, 488.8
lasso: [408.440] 458.4, 378.5, 352.9, 429.5, 388.0, 348.0, 483.5
ridge: [403.875] 447.1, 377.9, 347.5, 427.4, 384.1, 343.4, 479.7
en: [454.263] 471.8, 433.8, 415.8, 477.4, 434.4, 373.8, 551.8
huber: [409.500] 466.8, 380.2, 359.8, 432.4, 387.0, 351.3, 470.9
lars: [410.927] 463.8, 381.4, 351.9, 430.7, 387.8, 350.4, 488.8
llars: [406.490] 453.0, 378.8, 357.3, 428.1, 388.0, 345.0, 476.9
pa: [403.339] 437.0, 379.9, 364.0, 427.4, 391.8, 350.9, 460.1
ranscac: [491.196] 588.3, 454.6, 403.1, 522.8, 443.4, 403.7, 583.7
sgd: [403.982] 450.3, 377.0, 347.6, 427.8, 381.1, 345.6, 478.5
为什么即使我复制了所有代码,我得到的值也不同?此外,我注意到我的 ranscac 值和您的值之间有很大差异。您能解释一下为什么值会偏离吗?谢谢!
这是可以预期的,我在这里解释得更详细
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
你好 Jason,我是这个领域的新手,所以请原谅我的愚蠢问题。什么是目录?我在哪里编写您在此处提供的所有代码?谢谢
您可以将代码复制到一个文本文件中,并将其保存为带有 .py 扩展名的文件。
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
然后您可以打开命令提示符并运行脚本。
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
当前工作目录是您保存文件的目录。
希望这能有所帮助。
嗨,Jason,
感谢您提供这篇有用的文章。我也购买了您的时间序列套装。
我正在尝试理解这个模型的一个扩展
假设我们有以下可用数据集
1) 1000 个家庭一年的每小时用电量,
2) 这些家庭每千瓦时的价格,从固定的每千瓦时价格变为基于时间的定价,在前半段每天变化,在后半段也发生变化,
3) 每个家庭的人口统计数据和电器数量,
4) 测量用电量那一年的每小时温度。
我们想预测一个家庭在新的基于时间的定价方案下的下个月的每小时用电量,给出了固定定价下该家庭一年的每小时用电数据、人口统计数据和电器数量。
您对如何解决这个问题有什么建议吗?您能推荐一些可能有所帮助的资源吗?
是的,我建议探索问题的多种不同构建方式,以发现最适合您特定数据集的方法。
也许可以尝试按客户/按客户组建模/以及跨所有客户建模,并评估模型的性能,以确认跨客户建模可以提高技能的假设?
也许可以尝试线性与非线性方法来证明复杂方法能够增加技能?
也许可以尝试单变量与多变量数据来确认额外数据可以提高技能?
这有帮助吗?
是的,我将从每个客户的线性模型和单变量数据开始,然后继续。
听起来不错!
嗨,Jason,
感谢这篇教程。
我的数据是多元的(列 = 日期、建筑1消耗、建筑2消耗、建筑3消耗)
我想预测每个建筑物的每周消耗量,然后在同一张图上进行比较。
我该如何修改这个函数来预测每个变量然后进行比较?
def to_series(data)
# 提取每周的总功率
series = [week[:, 0] for week in data]
# 展平成一个序列
series = array(series).flatten()
return series
谢谢
诚挚的问候
我很乐意提供帮助,但我没有能力为您编写代码。
好的,感谢回复。
函数名称是错误的,它与完整的示例不同。
模型进行的预测然后使用先前定义的 evaluate_forecasts() 函数against the test dataset 进行评估。
你具体指的是什么?
您能详细说明一下吗?
布朗利博士,首先感谢您发布的所有作品。我从零开始,现在我能理解什么是时间序列预测以及如何处理它(或多或少:)。
2 个问题
1) 当您调用 pipeline 时,您强制将“make_pipeline(model)”中的数据集进行标准化和归一化。同时使用两者是否正确,或者我只能选择其中一个?
2) 当您返回预测值和 RMSE 时,它们是否已按原始数据集重新缩放,还是您不使用 inverse_transform,它们仍处于缩放后的形状?
先谢谢您了。
通常只需要一种缩放。
总的来说,我建议对转换进行反向操作,以恢复到原始单位。
嗨 Jason,感谢分享这篇文章。
我仍在试图找出对 Salvatore 上述问题的答案。
看起来标准化和归一化都在您的代码中使用了。为什么我们同时使用这两种过程?
第二件事是,RMSE 值是否以标准化形式生成,还是已恢复到原始形式?
是的,我们标准化为单位高斯分布,然后将值归一化为 [0,1]。
尝试包含和不包含缩放的模型,并比较性能。
是的,预测值是经过缩放的,必须对缩放进行反向操作才能恢复到原始单位。
嗨 Jason,感谢您的快速回复。
我尝试了从 scikit_predict 函数中的预测进行反向转换(我正在将此代码用于 30 天的多步预测,而不是 7 天)。是否有可以用来反向转换预测值的代码片段或函数?
提前感谢。
是的,我在本帖中提供了一个示例
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
嗨,Jason,
我们是否可以使用这些相同的模型(线性回归、Lasso、Ridge 等)来制作一次性多步预测?
也许如果它们以直接模式使用,例如每个序列一个模型,或者您编写了自定义代码来实现所需的结果。
你好 Jason,谢谢回复,是否有任何教程处理使用您在此帖中使用的线性模型进行多元多步时间序列预测?
不是线性模型,但我确实展示了如何使用 MLP、CNN 和 LSTM。
https://machinelearning.org.cn/start-here/#deep_learning_time_series
你好 Jason,
我注意到在这里,我们没有将测试数据拆分为常规的:X_test & y_test,而是将最后一个窗口的 X_train 传递给 model.predict()。我们可以将测试数据拆分为 X_test & y_test,然后进行 model.predict(X_test) 吗?或者这种方法不适用于此类问题?
是的,您可以拟合模型并使用它来预测数据集末尾之后的值。
model.predict() 使用最后的观测集作为输入。
你好 Jason,
在本帖的扩展部分,您谈到了开发多元直接模型。您不能开发多元递归模型,对吗?
我实际上正在尝试开发多元递归模型,但在递归的 forecast() 函数中,我们在最后 input_data.append(yhat),但是 yhat 是一个单一变量,而 input_data 是多元的,并且不期望单个值,对吗?有没有办法解决这个问题?
提前感谢 Jason,您的教程是独一无二且非常有帮助的。
您可以做到,但模型必须预测每个时间步长的所有特征。
你好 Jason,抱歉问了太多问题,
当我们的数据是单变量时,我们是否应该考虑对数据进行任何类型的归一化/标准化,然后在预测后进行反向归一化/标准化?或者这无关紧要,因为数据是单变量的,我们只有一列?
是的,这可能会有帮助。
嗨,Jason,
我有一个时间序列数据集,包含 3 个输入和 1 个输出,持续 6 个月(1 月至 6 月),间隔为 30 秒,
有没有办法预测 7 月和 8 月的月份?
是的,也许从这里开始
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
嗨,Jason,
我是一名学生,我正在考虑参加您的课程。
我的课程中能否找到关于使用 SVR/SVM 或 LS-SVM 进行多步预测家庭消费的介绍??
抱歉,我没有关于使用 SVM 进行时间序列预测的示例。
关于 ANN 呢?
是的,我有一个关于这个的教程,请使用搜索框搜索“MLP”。
你好 Jason,
您是否有关于单步预测的教程?
是的,有很多,也许从这里开始
https://machinelearning.org.cn/start-here/#deep_learning_time_series
嗨,Jason,
在这里,由于要获取的先前时间步长数量等于要预测的时间步长数量,因此您使用相同的数字(即 7)来拆分训练集和测试集。
但是如果它们不同(不是都是 7),我们应该怎么做(例如,如果我们想用过去两周来预测未来一周)???
好问题。
您必须编写自己的修改函数来准备数据。
嗨 Jason,感谢您的精彩教程。我目前正在为我的学习项目做一个时间序列项目,所以我在这个主题上阅读了您很多资料。但是,我没有找到包含我目前面临问题的教程。
总结一下我的问题
任务是预测十种产品的销售量。
为此,我有一个包含一年销售数据的数据库。因此,数据集有 365 行(每天一行)。
此外,它还有一些特征,例如
- 是否为公共假日:指示相应日期是否为公共假日。
- 温度:指示当天的温度。
– 等等。
此外,数据集中有十种产品的每一列,对应每日销量。所以我正在寻找一个能提供输出向量的模型。此外,模型应该能够预测未来几天(多步)。
到目前为止,我找不到符合我要求的教程。您有什么建议吗?
您可以尝试分别建模每种产品,或者将所有产品一起建模。
您可以尝试将销售建模为单变量问题,或者使用所有变量。
我还鼓励您尝试经典线性时间序列方法以及机器学习和深度学习方法。
这个框架将会有帮助
https://machinelearning.org.cn/how-to-develop-a-skilful-time-series-forecasting-model/
从这里开始学习简单的时间序列
https://machinelearning.org.cn/start-here/#timeseries
从这里开始学习高级时间序列
https://machinelearning.org.cn/start-here/#deep_learning_time_series
这有帮助吗?
你好,Jason。
您的博客非常有帮助。我非常感激。
我有一个关于递归模型的问题。
我可以用递归方法来处理 LSTM 吗?
在上面的文章中,您使用了统计方法(例如 lasso、ridge)。
我可以用它来处理 LSTM 吗?
谢谢你
我看不出为什么不。
嗨,Jason
我的情况是过去一年的日数据点有 365 个(每天 1 个),需要预测未来 365 天的值。您能否就 X 和 Y 可能是什么给出一些指导?我们可以使用滚动时间窗口,如果是的话,窗口的长度是多少?
Atul
也许可以尝试 ARIMA 或 SARIMA 这样的线性模型。
https://machinelearning.org.cn/how-to-grid-search-sarima-model-hyperparameters-for-time-series-forecasting-in-python/
嗨,Jason,
为什么每次我们向初始历史追加一个新的测试时间步长时,都需要重新训练模型(见下文)?我们不能只在第一次训练模型(仅基于初始历史)吗?
谢谢
# 评估单个模型
def evaluate_model(model, train, test, n_input)
# history 是每周数据的列表
history = [x for x in train]
# 逐周进行前向验证
predictions = list()
for i in range(len(test))
# 预测本周
yhat_sequence = sklearn_predict(model, history, n_input)
# 存储预测值
predictions.append(yhat_sequence)
# 获取真实观测值并添加到历史记录中以预测下一周
history.append(test[i, :])
predictions = array(predictions)
# 评估每周的预测天数
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
这不是必需的,这是我选择使用的模型评估方案。
使用您认为更适合您问题的相应方法。
# 将单变量数据集拆分为训练/测试集
def split_dataset(data)
# 拆分为标准周
train, test = data[1:-328], data[-328:-6]
# 重构为每周数据窗口
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
Jason,请帮助我,我不明白您如何分割数据。数字 -328 是什么,哪个是 -1 和 -6?如果能解释一下,我将不胜感激。感谢您的辛勤工作。
我们删除了几天,以便我们处理完整的周。
然后我们使用大约最后 46 周作为测试数据,其余作为训练数据。
我仍然不清楚。您能告诉我您是如何计算 -328 的吗?或者假设我正在使用
训练集从 2017 年 4 月 16 日星期日开始到 2017 年 9 月 30 日星期六结束,共 24 周用于训练,测试集从 2017 年 10 月 1 日星期日到 2017 年 12 月 2 日星期六结束,共 9 周用于测试。您能告诉我用于分割的数字吗?它一直给我错误。请我在这方面不是很擅长,但您的教程真的让我在进步。请像新手一样向我解释。谢谢。
然而,整个数据集从 2017 年 4 月 15 日开始,到 2017 年 12 月 5 日结束。
我没有计算它。我看了数据并精确地指定了它。
这个分割有点随意。您可以选择自己分割数据。
好的,我也尝试指定了我的,但它一直给我
‘array split does not result in an equal division’)
ValueError: array split does not result in an equal division.
您能帮我指定我的数据吗?
数据从 2017 年 4 月 15 日开始,到 2017 年 12 月 5 日结束。我想使用 24 周进行训练,9 周进行测试。
而且由于我使用的是从星期日开始的标准周,所以我从 2017 年 4 月 16 日到 10 月 31 日(星期六)开始。测试从 10 月 1 日到 12 月 2 日(最后一个星期六)开始。我尝试了多种方法,但它一直报错。如果您能帮助我,我将非常感激。谢谢。
也许可以尝试试验您的数据,一次分配一周,直到找到错误的根源?
嘿,杰森!
这是一个优秀的分步帖子。
但是我对 Python 和 R 了解不多,但我愿意学习。
我想建立一个模型,该模型可以预测给定已实现的预测销售百分比,实际能实现多少百分比的销售预测。
例如,如果我本月预测销售 10000 件,而现在是本月的第 10 天,并且只售出了 2000 件(占 10000 件的 20%),我希望有一个模型能够预测,我能在月底实现预测的百分比。
我拥有大约 500 个 SKU 的 3 年每日需求数据。
您能帮我构建一个模型吗?
我还想告知模型某些每年会因半个月左右而变化的节假日,以便模型能够具备这种动态能力。
提前感谢!
听起来像一个有趣的项目。
也许您可以将问题构建为根据过去 n 天的销售额来预测本月总销售额,然后将预测值转换为百分比?
嗨,Jason,
您只使用了第一个列“global_active_power”进行训练和评估,对吗?那么为什么您还要创建额外的“column sub_metering_4”呢,它反正也没有被使用?
与其他关于同一数据集的教程保持一致。
你好,
感谢分享精彩的练习。我试图将它应用到我的用例中。
我需要预测未来 72 小时的数据,并且我有每小时级别的数据。
所以,我首先尝试预测 24 小时。为此,我将 n_input 设置为 24,以便预测未来 24 小时。我这样做对吗?
另外,运行所有 10 个模型需要多长时间?
或许可以试试看?
我尝试了,但它运行了一个多小时,所以我中途停止了,担心我可能做错了什么。
还有一个问题——我需要对多个变量进行未来预测。具体来说是 6 列。我需要对 6 列进行未来 72 小时的时间序列预测。那么这可以用于多元预测吗?
也许可以尝试为每个变量使用不同的模型,而不是为所有变量使用单个模型,看看哪种效果最好。
嗨,Jason,
非常感谢您提供如此好的资源和示例。使用这些资源,我从头开始构建了一个模型(感谢您!),但我觉得我还需要一些帮助。
我的目标与上面描述的类似,使用历史数据预测“今天的”产出。我正在尝试预测特定航班的持续时间,基于数值天气因素。
到目前为止,我一直在输入我的数据集,并手动将训练集设为从开始到 T-1 的所有数据,而测试集是今天日期的行。这在某种程度上是准确的,但我希望我的模型能够从我的数据中间开始,并“向前走”直到今天。
有一个小问题,每天跟踪和预测的航班都在变化。当您所预测的数据每天都在变化时,是否有可能创建前向多步预测模型?
例如,假设我们只跟踪 10 架飞机。飞机 1、3 和 9 今天正在飞行,我希望模型能够回溯到中间点,并根据它们过去的表现来预测 1、3 和 9 的时间。这有意义吗?每个航班的具体因素没有改变,只是每天飞行的飞机发生了变化。
谢谢,
约翰
我不确定我看到了问题,抱歉 John。
也许可以尝试试验不同的问题构建方式,以更好地理解预测任务的性质?
嗨,Jason,
感谢您提供这个信息丰富的教程。您能否帮我找到一个教程,其中包含(检查季节性、趋势等,然后应用(训练、验证和测试)拆分到数据中,然后拟合模型并对时间序列数据集进行预测)的所有步骤,请?
每个数据集和模型都不同,这可能会有所帮助。
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
嗨,Jason,
您能解释一下计算整体 RMSE 的行的确切含义吗?我的意思是以下部分
s = 0
for row in range(actual.shape[0])
for col in range(actual.shape[1])
s += (actual[row, col] – predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
此致,
Karolina
所有多步预测值上的 RMSE。
嗨,我们可以对 ARIMA 模型使用直接方法吗?
如果可以,是否有关于此的教程?
如果不行,我如何训练一个 ARIMA 模型来进行 4 步预测?
是的。
不,我认为我没有 ARIMA 的教程,但我有关于 ML 模型的内容。您可以在博客上搜索。
我为 ML 模型、MLP 和 LSTM 使用了直接方法。在这种情况下,我们将数据从“序列”重新组织为“监督”格式。因此,如何训练和测试 ML 模型非常直接。
但是,对于 ARIMA,我们提供整个序列作为训练集,并使用 predict 函数来获得一个或多个样本外预测。
所以,我的问题是,直接方法要求我们为不同的时间步长训练多个模型,那么如何为不同的模型组织数据呢?
在内部,ARIMA 正在创建一个带滞后输入的监督学习版本的问题。
每个模型可能需要自己的自定义数据准备。
你好,先生,
工作做得很好,感谢分享。当我尝试使用多元输入到单个模型来制作递归预测时,我感到非常困惑。任何帮助都将不胜感激。
假设我有 8 个输入特征(x 变量),和 1 个输出预测(y 变量),我计划以递归方式使用这个 1 个预测来预测接下来的 6 个值,就像您提到的那样,我会将输入移位 1 步以包含我当前的预测来做出下一次预测,对吗?但如果我想这样递归地进行预测呢?
输入特征(8 个值)——————————————————-> 预测(第 1 个值)
输入特征(8 个值)+ 预测(第 1 个值)—————————————-> 预测(第 2 个值)
输入特征(8 个值)+ 预测(第 1 个值)+ 预测(第 2 个值)————-> 预测(第 3 个值)
这将需要自定义代码才能在后续预测中使用预测输出作为输入。
布朗利博士您好!
我可能误解了“递归多步”的概念。在您与我们分享的代码中(def evaluate_model(train, test) ==> # get real observation and add to history for predicting the next week),不是应该使用 yhat 加上某种方式我不知道的预测输入来预测下一个 yhat 吗?
在真实数据的样本外预测中,我们如何执行递归多步预测?您能指出一个使用预测输出作为后续预测输入的自定义代码的方向吗?
提前感谢!
您可以根据预测时可用的任何数据(输入和预测)来配置模型的输入。
你好 Jason,感谢这篇信息丰富的文章。
我有一个问题:如果我们想在 7 个滞后量之外,还包含一些解释变量(如温度、能源价格……)来预测未来 7 天的总有功功率,我们应该如何进行?
不客气。
好问题,您可以将多元时间序列重新构建为监督学习问题,并使用数据来训练静态机器学习模型。
看这个关于数据准备的示例
https://machinelearning.org.cn/how-to-develop-lstm-models-for-multi-step-time-series-forecasting-of-household-power-consumption/
看这个关于使用临时机器学习算法进行预测的示例
https://machinelearning.org.cn/random-forest-for-time-series-forecasting/
希望这能作为第一步有所帮助。
非常感谢,我刚读了这两篇文章,我会使用的。
事实上,我曾尝试预测未来 24 小时的能源需求,并且我有诸如各来源的能源产量、每小时的能源价格以及每小时的气候变量(温度、风速、气压、降水……)等变量。通过您的文章,我现在对如何做有了一个大致的了解,但仍然存在一些不确定性,例如我应该使用多少滞后值。
干得不错。
也许可以尝试并发现最适合您的特定模型和数据集的方法。
你好 Jason!我目前正在对多元数据实施递归多步预测技术。它给了我非常好的结果,非常感谢!
但是,我担心过度拟合。我如何知道我的模型是否过度拟合?
干得好!
如果您在留出数据上的表现不佳——也许是过度拟合了。然后您可以使用学习曲线来研究/诊断模型(对于具有前向验证的时间序列数据,这可能很难做到)。
只需专注于优化样本外性能。
您说的“留出数据”是什么意思?
此外,在研究代码时,我有点困惑,因为我们拟合的是 train_x,然后我们使用 train_x[-1, :] 进行预测。这是否意味着我们正在预测我们已经用模型拟合过的数据?
留出数据是未用于训练模型的数据,例如,通常是测试集或验证集。
我们正在使用前向验证,您可以在此处了解有关此过程的更多信息。
https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
谢谢您的澄清!
那么我还有一个问题——在将数据设置为机器学习问题之前,是否有必要进行去趋势/去季节性处理?我之所以问这个问题,是因为通过将特征更改为滞后特征,我们似乎将相关性加回去了。
我在您对本文中一位名叫 Amin 的人的回答中看到:https://machinelearning.org.cn/time-series-forecasting-supervised-learning 我们应该进行去趋势/去季节性处理,但我现在不确定原因。
是的,在建模之前使时间序列平稳是一个好主意。
如果不确定,请尝试包含和不包含转换的模型,并使用最适合您数据集的方法。
您解释得很好,但从编码标准角度来看,您的写法非常糟糕。很难理解哪个方法调用哪个方法。您至少应该确保您以顺序方式消耗所有方法。
感谢您的反馈。
你好,
希望您一切都好。如何将预测从每周更改为每天?
我尝试使用每小时消耗量的数据集,并将其分成 24 个数据点帧。
也许您可以将模型拟合到每日数据上,然后调整模型和数据,使每个样本的输出部分包含一天的数据。
你好 Jason,在递归多步预测中,您建议在预测一天后重新拟合模型吗?
尝试有和没有重新拟合模型,并使用对您的数据和模型最有效的方法。
嗨,Jason博士,
跨所有多步预测值计算RMSE可以吗?也就是说,假设您想进行h+5的预测周期,您为每个h预测计算RMSE,然后取所有预测的平均RMSE(每个RMSE对应一个预测范围)。如果是这样,您能否为我提供一些研究过该方法的论文或资源?
谢谢
从数学上来说应该是可以的(我相信你知道如何实现这样的函数),但我不认为这有意义,因为对未来的预测越来越不准确。因此,您似乎是将不同的东西合并到一个指标中。
很棒的教程!
这是针对一个家庭的预测,我该如何扩展到成千上万甚至数百万个家庭呢?
你好 Henry……你可能会发现以下内容很有帮助
https://machinelearning.org.cn/multivariate-time-series-forecasting-lstms-keras/
嗨,Jason,
我刚买了您的书,并开始为电力消耗数据集处理单变量多步 LSTM。我正在尝试调整您的代码以适应我的任务。我有 48 个月的目标变量值序列(包含 6 个特征)。我需要根据 36 个月的训练集预测最后 12 个目标值。我应该如何重塑我的输入数据?我认为我应该使用 n_input=36、n_out=12 和 n_features=6。另一种变体是:n_input=12。请给出建议。
你好 Vladimir……以下内容可能对您有益
https://machinelearning.org.cn/reshape-input-data-long-short-term-memory-networks-keras/
Jason,非常感谢您的教程,这对像我这样的机器学习初学者非常有帮助。
作为一名电力工程师,我只有一点建议——在按天聚合初始数据时,您将所有千瓦(kW)的有功功率值相加,这在物理上没有意义。我们可以计算每天的平均有功功率值,或者计算每分钟的总消耗能量(千瓦时 kWh)(有功功率 [kW] / 60),然后按天聚合,从而得到每天实际消耗的总功率。
我实际上进行了与您的模型比较类似的操作,在每日数据集中创建了“总消耗量 [kWh]”列,并根据预测家庭每日用电量的准确性验证了所有模型。以下是我的结果
名称 RMSE [kWh] MAPE
LinearRegression 6.473 23.167%
Lasso 8.08 33.215%
Ridge 6.461 23.218%
ElasticNet 8.01 32.871%
HuberRegressor 6.542 22.032%
Lars 6.473 23.167%
LassoLars 8.08 33.215%
PassiveAggressiveRegressor 7.043 22.561%
RANSACRegressor 7.827 25.496%
SGDRegressor 6.451 23.093%
Michal,谢谢你的反馈!我们非常感激。