在本教程中,您将学习朴素贝叶斯算法,包括它的工作原理以及如何用Python从头开始实现它(无需库)。
我们可以使用概率来做出机器学习预测。也许最广泛使用的例子就是朴素贝叶斯算法。它不仅易于理解,而且在各种问题上都能取得惊人的好成绩。
完成本教程后,您将了解
- 如何计算朴素贝叶斯算法所需的概率。
- 如何从头开始实现朴素贝叶斯算法。
- 如何将朴素贝叶斯应用于现实世界的预测建模问题。
通过我的新书《从头开始的机器学习算法》来启动您的项目,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 更新 2014 年 12 月:原始实现。
- 更新 2019 年 10 月:从头开始重写了教程和代码。
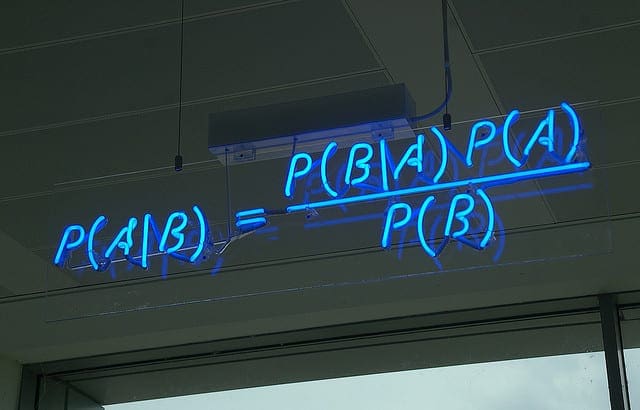
从头开始用Python编写朴素贝叶斯分类器(无需库)
照片由 Matt Buck 拍摄,保留部分权利
概述
本节将简要介绍朴素贝叶斯算法以及我们将在本教程中使用的鸢尾花数据集。
朴素贝叶斯
贝叶斯定理提供了一种方法,可以根据我们先前的知识来计算一段数据属于给定类别的概率。贝叶斯定理的陈述如下:
- P(类别|数据) = (P(数据|类别) * P(类别)) / P(数据)
其中 P(类别|数据) 是给定提供的数据后,该类别属于该数据的概率。
有关贝叶斯定理的深入介绍,请参阅教程
朴素贝叶斯是一种用于二分类(两类)和多分类问题的分类算法。它被称为朴素贝叶斯或傻瓜贝叶斯,是因为每个类别的概率计算被简化了,使其计算易于处理。
它们被假定为在给定类别值的情况下条件独立,而不是尝试计算每个属性值的概率。
这是一个非常强的假设,在真实数据中不太可能成立,即属性之间不相互作用。尽管如此,该方法在不满足此假设的数据上表现仍然相当好。
有关朴素贝叶斯算法的深入介绍,请参阅教程
鸢尾花物种数据集
在本教程中,我们将使用鸢尾花种类数据集。
鸢尾花数据集涉及根据鸢尾花的测量值来预测花卉的种类。
这是一个多类分类问题。每个类别的观测数量是均衡的。有 150 个观测值,包含 4 个输入变量和 1 个输出变量。变量名称如下:
- 花萼长度(厘米)。
- 花萼宽度(厘米)。
- 花瓣长度(厘米)。
- 花瓣宽度(厘米)。
- 类别
下面是前 5 行的样本。
|
1 2 3 4 5 6 |
5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa ... |
该问题的基线性能约为 33%。
下载数据集并将其以iris.csv 文件名保存在当前工作目录中。
朴素贝叶斯教程(分 5 个简单步骤)
首先,我们将在本节中开发算法的每个部分,然后在下一节中将其整合到一个实际应用的数据集中。
此朴素贝叶斯教程分为 5 个部分
- 第一步:按类别分隔。
- 第二步:汇总数据集。
- 第三步:按类别汇总数据。
- 第四步:高斯概率密度函数。
- 第五步:类别概率。
这些步骤将为您从头开始实现朴素贝叶斯并将其应用于您自己的预测建模问题奠定基础。
注意:本教程假设您使用的是Python 3。如果您需要安装 Python 的帮助,请参阅本教程
注意:如果您使用的是Python 2.7,则必须将字典对象上对items() 函数的所有调用更改为iteritems()。
第一步:按类别分隔
我们需要按它们所属的类别来计算数据的概率,也就是所谓的基率。
这意味着我们首先需要按类别分离我们的训练数据。这是一个相对直接的操作。
我们可以创建一个字典对象,其中每个键是类别值,然后将所有记录的列表作为值添加到字典中。
下面是一个名为separate_by_class() 的函数,它实现了这种方法。它假定每行中的最后一列是类别值。
|
1 2 3 4 5 6 7 8 9 10 |
# 按类别值分割数据集,返回一个字典 def separate_by_class(dataset): separated = dict() for i in range(len(dataset)): vector = dataset[i] class_value = vector[-1] if (class_value not in separated): separated[class_value] = list() separated[class_value].append(vector) return separated |
我们可以构建一个小数据集来测试这个函数。
|
1 2 3 4 5 6 7 8 9 10 11 |
X1 X2 Y 3.393533211 2.331273381 0 3.110073483 1.781539638 0 1.343808831 3.368360954 0 3.582294042 4.67917911 0 2.280362439 2.866990263 0 7.423436942 4.696522875 1 5.745051997 3.533989803 1 9.172168622 2.511101045 1 7.792783481 3.424088941 1 7.939820817 0.791637231 1 |
我们可以绘制这个数据集,并为每个类别使用不同的颜色。
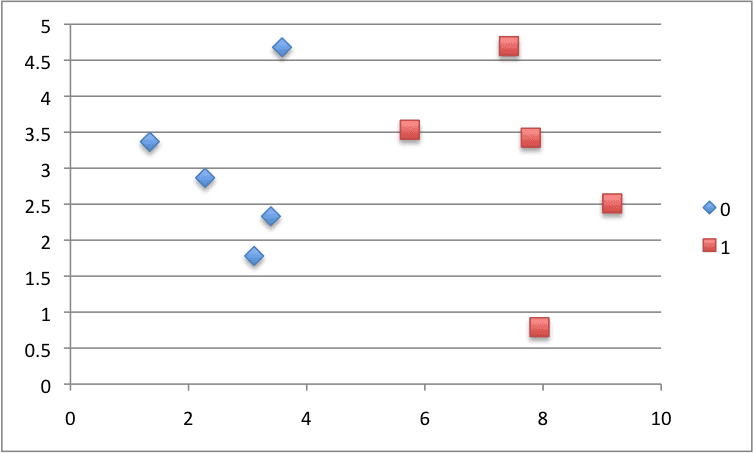
用于测试朴素贝叶斯算法的小型构造数据集的散点图
将所有这些放在一起,我们可以测试我们的separate_by_class() 函数在构造的数据集上的效果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 按类别值分隔数据的示例 # 按类别值分割数据集,返回一个字典 def separate_by_class(dataset): separated = dict() for i in range(len(dataset)): vector = dataset[i] class_value = vector[-1] if (class_value not in separated): separated[class_value] = list() separated[class_value].append(vector) return separated # 测试分隔数据按类别 dataset = [[3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0], [3.582294042,4.67917911,0], [2.280362439,2.866990263,0], [7.423436942,4.696522875,1], [5.745051997,3.533989803,1], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [7.939820817,0.791637231,1]] separated = separate_by_class(dataset) for label in separated: print(label) for row in separated[label]: print(row) |
运行该示例会按其类别值对数据集中的观测值进行排序,然后打印类别值以及所有识别出的记录。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
0 [3.393533211, 2.331273381, 0] [3.110073483, 1.781539638, 0] [1.343808831, 3.368360954, 0] [3.582294042, 4.67917911, 0] [2.280362439, 2.866990263, 0] 1 [7.423436942, 4.696522875, 1] [5.745051997, 3.533989803, 1] [9.172168622, 2.511101045, 1] [7.792783481, 3.424088941, 1] [7.939820817, 0.791637231, 1] |
接下来,我们可以开始开发收集统计数据所需的功能。
第二步:汇总数据集
我们需要从给定数据集中获取两项统计数据。
我们将在几步之后看到这些统计数据如何用于计算概率。我们需要从给定数据集中获取的两项统计数据是均值和标准差(与均值的平均偏差)。
均值是平均值,可以计算为:
- 均值 = sum(x)/n * count(x)
其中 *x* 是值列表或我们正在查看的列。
下面是一个名为mean() 的小型函数,用于计算数字列表的均值。
|
1 2 3 |
# 计算数字列表的均值 def mean(numbers): return sum(numbers)/float(len(numbers)) |
样本标准差是根据与均值的平均差异计算的。它可以计算为:
- 标准差 = sqrt((sum i to N (x_i – mean(x))^2) / N-1)
您可以看到,我们对均值与给定值之间的差值进行平方,计算与均值的平均平方差,然后取平方根,将单位恢复到其原始值。
下面是一个名为standard_deviation() 的小型函数,用于计算数字列表的标准差。您会注意到它会计算均值。一次性计算数字列表的均值,并将其作为参数传递给standard_deviation() 函数可能更有效。如果您感兴趣,以后可以探索此优化。
|
1 2 3 4 5 6 7 |
from math import sqrt # 计算数字列表的标准差 def stdev(numbers): avg = mean(numbers) variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) return sqrt(variance) |
我们需要为每个输入属性或数据列计算均值和标准差统计数据。
我们可以通过将每列的所有值收集到一个列表中,然后对该列表计算均值和标准差来实现这一点。计算完成后,我们可以将统计数据收集到一个统计信息列表或元组中。然后,对数据集中的每一列重复此操作,并返回统计信息元组列表。
下面是一个名为summarize_dataset() 的函数,它实现了这种方法。它使用一些 Python 技巧来减少所需的行数。
|
1 2 3 4 5 |
# 计算数据集中每列的均值、标准差和计数 def summarize_dataset(dataset): summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)] del(summaries[-1]) return summaries |
第一个技巧是使用 zip() 函数,它将聚合来自每个提供参数的元素。我们使用 * 运算符将数据集(它是一个列表的列表)传递给 zip() 函数,该运算符将数据集分成每行的单独列表。然后 zip() 函数迭代每行的每个元素,并以数字列表的形式返回数据集中的一列。一个巧妙的小技巧。
然后,我们计算每列的均值、标准差和行数。由这 3 个数字组成一个元组,并存储这些元组的列表。然后,我们删除类别变量的统计信息,因为我们不需要这些统计信息。
让我们用上面构造的数据集来测试所有这些函数。下面是完整的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 汇总数据集的示例 from math import sqrt # 计算数字列表的均值 def mean(numbers): return sum(numbers)/float(len(numbers)) # 计算数字列表的标准差 def stdev(numbers): avg = mean(numbers) variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) return sqrt(variance) # 计算数据集中每列的均值、标准差和计数 def summarize_dataset(dataset): summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)] del(summaries[-1]) return summaries # 测试汇总数据集 dataset = [[3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0], [3.582294042,4.67917911,0], [2.280362439,2.866990263,0], [7.423436942,4.696522875,1], [5.745051997,3.533989803,1], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [7.939820817,0.791637231,1]] summary = summarize_dataset(dataset) print(summary) |
运行示例会打印出每个输入变量的统计信息元组列表。
解释结果,我们可以看到 X1 的均值为 5.178333386499999,X1 的标准差为 2.7665845055177263。
|
1 |
[(5.178333386499999, 2.7665845055177263, 10), (2.9984683241, 1.218556343617447, 10)] |
现在我们准备在数据集中的每一组行上使用这些函数了。
第三步:按类别汇总数据
我们需要按类别组织的训练数据集的统计数据。
上面,我们开发了separate_by_class() 函数来将数据集按类别分割成行。并且我们开发了summarize_dataset() 函数来计算每列的汇总统计数据。
我们可以将所有这些放在一起,并按类别值组织的类别汇总数据集中的列。
下面是一个名为summarize_by_class() 的函数,它实现了此操作。数据集首先按类别分割,然后对每个子集计算统计数据。结果以统计信息元组列表的形式存储在按类别值划分的字典中。
|
1 2 3 4 5 6 7 |
# 按类别分割数据集,然后计算每行的统计数据 def summarize_by_class(dataset): separated = separate_by_class(dataset) summaries = dict() for class_value, rows in separated.items(): summaries[class_value] = summarize_dataset(rows) return summaries |
再次,让我们用构造的数据集测试所有这些行为。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
# 按类别值汇总数据的示例 from math import sqrt # 按类别值分割数据集,返回一个字典 def separate_by_class(dataset): separated = dict() for i in range(len(dataset)): vector = dataset[i] class_value = vector[-1] if (class_value not in separated): separated[class_value] = list() separated[class_value].append(vector) return separated # 计算数字列表的均值 def mean(numbers): return sum(numbers)/float(len(numbers)) # 计算数字列表的标准差 def stdev(numbers): avg = mean(numbers) variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) return sqrt(variance) # 计算数据集中每列的均值、标准差和计数 def summarize_dataset(dataset): summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)] del(summaries[-1]) return summaries # 按类别分割数据集,然后计算每行的统计数据 def summarize_by_class(dataset): separated = separate_by_class(dataset) summaries = dict() for class_value, rows in separated.items(): summaries[class_value] = summarize_dataset(rows) return summaries # 按类别测试汇总 dataset = [[3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0], [3.582294042,4.67917911,0], [2.280362439,2.866990263,0], [7.423436942,4.696522875,1], [5.745051997,3.533989803,1], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [7.939820817,0.791637231,1]] summary = summarize_by_class(dataset) for label in summary: print(label) for row in summary[label]: print(row) |
运行此示例将计算每个输入变量的统计数据,并按类别值组织打印它们。解释结果,我们可以看到类别 0 的行的 X1 值的均值为 2.7420144012。
|
1 2 3 4 5 6 |
0 (2.7420144012, 0.9265683289298018, 5) (3.0054686692, 1.1073295894898725, 5) 1 (7.6146523718, 1.2344321550313704, 5) (2.9914679790000003, 1.4541931384601618, 5) |
在开始计算概率之前,我们还需要最后一块。
第四步:高斯概率密度函数
计算像 X1 这样的给定实数值的概率或似然性是困难的。
我们可以做到的一点是假设 X1 值是从某个分布中抽取的,例如钟形曲线或高斯分布。
高斯分布仅用两个数字就可以概括:均值和标准差。因此,通过一点数学,我们可以估计给定值的概率。这部分数学被称为高斯 概率分布函数(或高斯 PDF),可以计算为:
- f(x) = (1 / sqrt(2 * PI) * sigma) * exp(-((x-mean)^2 / (2 * sigma^2)))
其中 *sigma* 是 *x* 的标准差,*mean* 是 *x* 的均值,*PI* 是 pi 的值。
下面是一个实现此功能的函数。我尝试将其拆分以使其更具可读性。
|
1 2 3 4 |
# 计算 x 的高斯概率分布函数 def calculate_probability(x, mean, stdev): exponent = exp(-((x-mean)**2 / (2 * stdev**2 ))) return (1 / (sqrt(2 * pi) * stdev)) * exponent |
让我们测试一下看看它是如何工作的。下面是一些计算示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 高斯 PDF 示例 from math import sqrt from math import pi from math import exp # 计算 x 的高斯概率分布函数 def calculate_probability(x, mean, stdev): exponent = exp(-((x-mean)**2 / (2 * stdev**2 ))) return (1 / (sqrt(2 * pi) * stdev)) * exponent # 测试高斯 PDF print(calculate_probability(1.0, 1.0, 1.0)) print(calculate_probability(2.0, 1.0, 1.0)) print(calculate_probability(0.0, 1.0, 1.0)) |
运行它会打印一些输入值的概率。您可以看到,当值为 1 且均值和标准差为 1 时,我们的输入最有可能(钟形曲线的顶部),概率为 0.39。
我们可以看到,当保持统计数据不变并将 x 值更改为均值两侧的 1 个标准差(2 和 0 或两侧与钟形曲线的距离相同)时,这些输入值的概率都相同,为 0.24。
|
1 2 3 |
0.3989422804014327 0.24197072451914337 0.24197072451914337 |
现在我们已经具备了所有必要条件,让我们看看如何计算朴素贝叶斯分类器所需的概率。
第五步:类别概率
现在是时候使用从训练数据中计算出的统计数据来计算新数据的概率了。
概率是为每个类别分别计算的。这意味着我们首先计算新数据属于第一个类别的概率,然后计算其属于第二个类别的概率,依此类推,直到所有类别。
数据属于某个类别的概率计算如下:
- P(类别|数据) = P(X|类别) * P(类别)
您可能会注意到这与上面描述的贝叶斯定理不同。
为简化计算,已移除除法。
这意味着结果不再严格是数据属于某个类别的概率。该值仍然被最大化,意味着计算产生最大值的类别被视为预测。这是一个常见的实现简化,因为我们通常更关心类别预测而不是概率。
输入变量被单独处理,这使得该技术得名“朴素”。对于我们有 2 个输入变量的上述示例,计算一行属于第一个类别 0 的概率可以计算为:
- P(类别=0|X1,X2) = P(X1|类别=0) * P(X2|类别=0) * P(类别=0)
现在您可以看到为什么我们需要按类别值分隔数据了。上一步中的高斯概率密度函数是我们计算 X1 这样的实数值的概率的方法,而我们准备的统计数据用于此计算。
下面是一个名为calculate_class_probabilities() 的函数,它将所有这些结合在一起。
它将一组准备好的摘要和一个新行作为输入参数。
首先,从存储在摘要统计信息中的计数计算训练记录的总数。这用于计算给定类别的概率或P(类别),作为具有给定类别的所有训练数据行的比率。
接下来,使用高斯概率密度函数以及该列和该类别的统计数据,为行中的每个输入值计算概率。在累积过程中,概率会相乘。
此过程对数据集中的每个类别重复进行。
最后,返回一个包含每个类别一个条目的概率字典。
|
1 2 3 4 5 6 7 8 9 10 |
# 计算给定行的每个类别预测的概率 def calculate_class_probabilities(summaries, row): total_rows = sum([summaries[label][0][2] for label in summaries]) probabilities = dict() for class_value, class_summaries in summaries.items(): probabilities[class_value] = summaries[class_value][0][2]/float(total_rows) for i in range(len(class_summaries)): mean, stdev, count = class_summaries[i] probabilities[class_value] *= calculate_probability(row[i], mean, stdev) return probabilities |
让我们用构造数据集中的一个示例来结合起来。
下面的示例首先为训练数据集计算按类别的汇总统计数据,然后使用这些统计数据计算第一个记录属于每个类别的概率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
# 计算类别概率的示例 from math import sqrt from math import pi from math import exp # 按类别值分割数据集,返回一个字典 def separate_by_class(dataset): separated = dict() for i in range(len(dataset)): vector = dataset[i] class_value = vector[-1] if (class_value not in separated): separated[class_value] = list() separated[class_value].append(vector) return separated # 计算数字列表的均值 def mean(numbers): return sum(numbers)/float(len(numbers)) # 计算数字列表的标准差 def stdev(numbers): avg = mean(numbers) variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) return sqrt(variance) # 计算数据集中每列的均值、标准差和计数 def summarize_dataset(dataset): summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)] del(summaries[-1]) return summaries # 按类别分割数据集,然后计算每行的统计数据 def summarize_by_class(dataset): separated = separate_by_class(dataset) summaries = dict() for class_value, rows in separated.items(): summaries[class_value] = summarize_dataset(rows) return summaries # 计算 x 的高斯概率分布函数 def calculate_probability(x, mean, stdev): exponent = exp(-((x-mean)**2 / (2 * stdev**2 ))) return (1 / (sqrt(2 * pi) * stdev)) * exponent # 计算给定行的每个类别预测的概率 def calculate_class_probabilities(summaries, row): total_rows = sum([summaries[label][0][2] for label in summaries]) probabilities = dict() for class_value, class_summaries in summaries.items(): probabilities[class_value] = summaries[class_value][0][2]/float(total_rows) for i in range(len(class_summaries)): mean, stdev, _ = class_summaries[i] probabilities[class_value] *= calculate_probability(row[i], mean, stdev) return probabilities # 测试计算类别概率 dataset = [[3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0], [3.582294042,4.67917911,0], [2.280362439,2.866990263,0], [7.423436942,4.696522875,1], [5.745051997,3.533989803,1], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [7.939820817,0.791637231,1]] summaries = summarize_by_class(dataset) probabilities = calculate_class_probabilities(summaries, dataset[0]) print(probabilities) |
运行示例会打印为每个类别计算出的概率。
我们可以看到,第一个行属于类别 0 的概率(0.0503)高于其属于类别 1 的概率(0.0001)。因此,我们可以正确地得出结论,它属于类别 0。
|
1 |
{0: 0.05032427673372075, 1: 0.00011557718379945765} |
现在我们已经看到了如何实现朴素贝叶斯算法,让我们将其应用于鸢尾花数据集。
鸢尾花种类案例研究
本节将朴素贝叶斯算法应用于鸢尾花数据集。
第一步是加载数据集,并将加载的数据转换为我们可以用于均值和标准差计算的数字。为此,我们将使用辅助函数load_csv() 来加载文件,str_column_to_float() 将字符串数字转换为浮点数,str_column_to_int() 将类别列转换为整数值。
我们将使用 5 折的 k 折交叉验证来评估该算法。这意味着每个折叠将包含 150/5=30 条记录。我们将使用辅助函数evaluate_algorithm() 来通过交叉验证评估算法,并使用accuracy_metric() 来计算预测的准确性。
开发了一个名为predict() 的新函数来管理计算新行属于每个类别的概率以及选择具有最大概率值的类别。
开发了一个名为naive_bayes() 的新函数来管理朴素贝叶斯算法的应用,首先从训练数据集中学习统计数据,并使用它们来为测试数据集做出预测。
如果您想了解更多关于下面使用的数据加载函数的帮助,请参阅教程
如果您想了解更多关于使用交叉验证评估模型的方法,请参阅教程
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 |
# 朴素贝叶斯在鸢尾花数据集上的应用 from csv import reader from random import seed from random import randrange from math import sqrt from math import exp from math import pi # 加载 CSV 文件 def load_csv(filename): dataset = list() with open(filename, 'r') as file: csv_reader = reader(file) for row in csv_reader: if not row: continue dataset.append(row) return dataset # 将字符串列转换为浮点数 def str_column_to_float(dataset, column): for row in dataset: row[column] = float(row[column].strip()) # 将字符串列转换为整数 def str_column_to_int(dataset, column): class_values = [row[column] for row in dataset] unique = set(class_values) lookup = dict() for i, value in enumerate(unique): lookup[value] = i for row in dataset: row[column] = lookup[row[column]] return lookup # 将数据集分成 k 折 def cross_validation_split(dataset, n_folds): dataset_split = list() dataset_copy = list(dataset) fold_size = int(len(dataset) / n_folds) for _ in range(n_folds): fold = list() while len(fold) < fold_size: index = randrange(len(dataset_copy)) fold.append(dataset_copy.pop(index)) dataset_split.append(fold) return dataset_split # 计算准确率百分比 def accuracy_metric(actual, predicted): correct = 0 for i in range(len(actual)): if actual[i] == predicted[i]: correct += 1 return correct / float(len(actual)) * 100.0 # 使用交叉验证分割评估算法 def evaluate_algorithm(dataset, algorithm, n_folds, *args): folds = cross_validation_split(dataset, n_folds) scores = list() for fold in folds: train_set = list(folds) train_set.remove(fold) train_set = sum(train_set, []) test_set = list() for row in fold: row_copy = list(row) test_set.append(row_copy) row_copy[-1] = None predicted = algorithm(train_set, test_set, *args) actual = [row[-1] for row in fold] accuracy = accuracy_metric(actual, predicted) scores.append(accuracy) 返回 分数 # 按类别值分割数据集,返回一个字典 def separate_by_class(dataset): separated = dict() for i in range(len(dataset)): vector = dataset[i] class_value = vector[-1] if (class_value not in separated): separated[class_value] = list() separated[class_value].append(vector) return separated # 计算数字列表的均值 def mean(numbers): return sum(numbers)/float(len(numbers)) # 计算数字列表的标准差 def stdev(numbers): avg = mean(numbers) variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) return sqrt(variance) # 计算数据集中每列的均值、标准差和计数 def summarize_dataset(dataset): summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)] del(summaries[-1]) return summaries # 按类别分割数据集,然后计算每行的统计数据 def summarize_by_class(dataset): separated = separate_by_class(dataset) summaries = dict() for class_value, rows in separated.items(): summaries[class_value] = summarize_dataset(rows) return summaries # 计算 x 的高斯概率分布函数 def calculate_probability(x, mean, stdev): exponent = exp(-((x-mean)**2 / (2 * stdev**2 ))) return (1 / (sqrt(2 * pi) * stdev)) * exponent # 计算给定行的每个类别预测的概率 def calculate_class_probabilities(summaries, row): total_rows = sum([summaries[label][0][2] for label in summaries]) probabilities = dict() for class_value, class_summaries in summaries.items(): probabilities[class_value] = summaries[class_value][0][2]/float(total_rows) for i in range(len(class_summaries)): mean, stdev, _ = class_summaries[i] probabilities[class_value] *= calculate_probability(row[i], mean, stdev) return probabilities # 预测给定行的类别 def predict(summaries, row): probabilities = calculate_class_probabilities(summaries, row) best_label, best_prob = None, -1 for class_value, probability in probabilities.items(): if best_label is None or probability > best_prob: best_prob = probability best_label = class_value return best_label # 朴素贝叶斯算法 def naive_bayes(train, test): summarize = summarize_by_class(train) predictions = list() for row in test: output = predict(summarize, row) predictions.append(output) return(predictions) # 在鸢尾花数据集上测试朴素贝叶斯 seed(1) filename = 'iris.csv' dataset = load_csv(filename) for i in range(len(dataset[0])-1): str_column_to_float(dataset, i) # 将类别列转换为整数 str_column_to_int(dataset, len(dataset[0])-1) # 评估算法 n_folds = 5 scores = evaluate_algorithm(dataset, naive_bayes, n_folds) print('Scores: %s' % scores) print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores)))) |
运行示例会打印每个交叉验证折叠上的平均分类准确性得分以及平均准确性得分。
我们可以看到,平均准确性约 95% 比基线准确性 33% 有了显著提高。
|
1 2 |
Scores: [93.33333333333333, 96.66666666666667, 100.0, 93.33333333333333, 93.33333333333333] Mean Accuracy: 95.333% |
我们可以在整个数据集上拟合模型,然后使用该模型对新观测值(数据行)进行预测。
例如,模型只是一组通过summarize_by_class() 函数计算出的概率。
|
1 2 3 |
... # 拟合模型 model = summarize_by_class(dataset) |
计算完成后,我们可以在调用 predict() 函数时使用它们,并传入代表我们新观测值的行来预测类别标签。
|
1 2 3 |
... # 预测标签 label = predict(model, row) |
我们也可能想知道预测的类别标签(字符串)。我们可以更新 str_column_to_int() 函数以打印字符串类别名称到整数的映射,这样我们就可以通过模型来解释预测。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 将字符串列转换为整数 def str_column_to_int(dataset, column): class_values = [row[column] for row in dataset] unique = set(class_values) lookup = dict() for i, value in enumerate(unique): lookup[value] = i print('[%s] => %d' % (value, i)) for row in dataset: row[column] = lookup[row[column]] return lookup |
将所有这些结合起来,下面列出了在一个完整示例中,在整个数据集上拟合朴素贝叶斯模型并为新观测值做出单个预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
# 在鸢尾花数据集上使用朴素贝叶斯进行预测 from csv import reader from math import sqrt from math import exp from math import pi # 加载 CSV 文件 def load_csv(filename): dataset = list() with open(filename, 'r') as file: csv_reader = reader(file) for row in csv_reader: if not row: continue dataset.append(row) return dataset # 将字符串列转换为浮点数 def str_column_to_float(dataset, column): for row in dataset: row[column] = float(row[column].strip()) # 将字符串列转换为整数 def str_column_to_int(dataset, column): class_values = [row[column] for row in dataset] unique = set(class_values) lookup = dict() for i, value in enumerate(unique): lookup[value] = i print('[%s] => %d' % (value, i)) for row in dataset: row[column] = lookup[row[column]] return lookup # 按类别值分割数据集,返回一个字典 def separate_by_class(dataset): separated = dict() for i in range(len(dataset)): vector = dataset[i] class_value = vector[-1] if (class_value not in separated): separated[class_value] = list() separated[class_value].append(vector) return separated # 计算数字列表的均值 def mean(numbers): return sum(numbers)/float(len(numbers)) # 计算数字列表的标准差 def stdev(numbers): avg = mean(numbers) variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) return sqrt(variance) # 计算数据集中每列的均值、标准差和计数 def summarize_dataset(dataset): summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)] del(summaries[-1]) return summaries # 按类别分割数据集,然后计算每行的统计数据 def summarize_by_class(dataset): separated = separate_by_class(dataset) summaries = dict() for class_value, rows in separated.items(): summaries[class_value] = summarize_dataset(rows) return summaries # 计算 x 的高斯概率分布函数 def calculate_probability(x, mean, stdev): exponent = exp(-((x-mean)**2 / (2 * stdev**2 ))) return (1 / (sqrt(2 * pi) * stdev)) * exponent # 计算给定行的每个类别预测的概率 def calculate_class_probabilities(summaries, row): total_rows = sum([summaries[label][0][2] for label in summaries]) probabilities = dict() for class_value, class_summaries in summaries.items(): probabilities[class_value] = summaries[class_value][0][2]/float(total_rows) for i in range(len(class_summaries)): mean, stdev, _ = class_summaries[i] probabilities[class_value] *= calculate_probability(row[i], mean, stdev) return probabilities # 预测给定行的类别 def predict(summaries, row): probabilities = calculate_class_probabilities(summaries, row) best_label, best_prob = None, -1 for class_value, probability in probabilities.items(): if best_label is None or probability > best_prob: best_prob = probability best_label = class_value return best_label # 使用鸢尾花数据集上的朴素贝叶斯进行预测 filename = 'iris.csv' dataset = load_csv(filename) for i in range(len(dataset[0])-1): str_column_to_float(dataset, i) # 将类别列转换为整数 str_column_to_int(dataset, len(dataset[0])-1) # 拟合模型 model = summarize_by_class(dataset) # 定义一条新记录 row = [5.7,2.9,4.2,1.3] # 预测标签 label = predict(model, row) print('Data=%s, Predicted: %s' % (row, label)) |
运行数据首先会总结类别标签到整数的映射,然后会在整个数据集上拟合模型。
然后定义一个新的观测值(在本例中,我采用了数据集中的一行),并计算预测标签。在这种情况下,我们的观测值被预测为属于类别 1,我们知道这是“Iris-versicolor”。
|
1 2 3 4 5 |
[Iris-virginica] => 0 [Iris-versicolor] => 1 [Iris-setosa] => 2 Data=[5.7, 2.9, 4.2, 1.3], Predicted: 1 |
扩展
本节列出了你可能希望探索的教程扩展。
- 对数概率:给定属性值的每个类别的条件概率都很小。当它们相乘时,会产生非常小的值,这可能导致浮点下溢(值太小而无法在 Python 中表示)。一个常见的解决方法是将概率的对数加在一起。研究并实现此改进。
- 名义属性:更新实现以支持名义属性。这非常相似,您可以为每个属性收集的摘要信息是每个类别类别值的比率。有关更多信息,请深入研究参考文献。
- 不同的密度函数(伯努利或多项式):我们已经看过高斯朴素贝叶斯,但您也可以查看其他分布。实现不同的分布,例如多项式、伯努利或核朴素贝叶斯,它们对属性值的分布和/或它们与类别值的关系做出不同的假设。
如果您尝试了任何这些扩展,请在下面的评论中告知我。
进一步阅读
教程
书籍
- 第 13.6 节 朴素贝叶斯,第 353 页,应用预测建模,2013。
- 第 4.2 节 统计建模,第 88 页,数据挖掘:实用机器学习工具和技术,第二版,2005。
总结
在本教程中,您学习了如何用 Python 从头开始实现朴素贝叶斯算法。
具体来说,你学到了:
- 如何计算朴素贝叶斯对贝叶斯定理的解释所需的概率。
- 如何使用概率对新数据进行预测。
- 如何将朴素贝叶斯应用于现实世界的预测建模问题。
下一步
采取行动!
- 遵循教程,从头开始实现朴素贝叶斯。
- 将示例改编到另一个数据集。
- 遵循扩展并改进实现。
留下评论并分享您的经验。
了解如何从零开始编写算法!

没有库,只有 Python 代码。
...附带真实世界数据集的逐步教程
在我的新电子书中探索如何实现
从零开始实现机器学习算法
它涵盖了 18 个教程,包含 12 种顶级算法的所有代码,例如
线性回归、k-近邻、随机梯度下降等等……
最后,揭开
机器学习算法的神秘面纱
跳过学术理论。只看结果。






统计方法应该从头开始开发,因为存在误解。谢谢。
Jason… 非常感谢… 您太棒了。
这是一篇很棒的文章。您的博客是我每天访问的博客之一。感谢分享这些内容。我有一个关于应该使用哪种编程语言从头开始构建这些算法的问题。我知道 Python 被广泛使用,因为它易于通过导入有用的现有库来编写代码。尽管如此,我是一个 C++ 爱好者。虽然我在实际 ML 方面是初学者,但在我开始学习和实现 ML 之前,我尝试编写了高效的代码。现在我意识到了使用 C++ 编程时涉及的复杂性:比 Python 需要更多的编码。考虑到这一点,您偏爱哪种语言以及在什么情况下?我知道询问编程语言偏好是很愚蠢的,因为它本质上是个人选择。但我仍然希望您能分享您的看法。也请尝试分享选择这些编程语言时的权衡。
谢谢你。
谢谢 Anurag。
当我在自己的数据集上尝试实现它时,我遇到了错误。
for classValue, classSummaries in summaries.iteritems()
AttributeError: ‘list’ object has no attribute ‘iteritems’
当我尝试用您的 csv 文件运行时,它显示:
ataset = list(lines)
错误:迭代器应该返回字符串,而不是字节(您是否以文本模式打开文件?)
该怎么办?
该代码是为 Python 2.7 编写的。您可能正在使用 Python 3 吗?
我正在使用 Python 3.6,您有更新的代码吗?
书中的朴素贝叶斯版本支持 Py2.7 和 Py3。
https://machinelearning.org.cn/machine-learning-algorithms-from-scratch/
使用 items 代替 iteritems。当您在 Google 上输入错误消息时,您可以找到很多解决方案,例如 stackoverflow。
嗨 Jason,我找到了您的网站,并花了一天时间阅读。谢谢,它真的帮助我理解了 ML 和要做的事情。
我做了这里的两个示例,我认为我现在要去看看 scikit-learn 了。
我有一个个人项目想使用 ML,我会随时向您汇报进展。
关于这篇帖子的一个小说明是,“1. 处理数据”中您引用了上一篇帖子的 iris.data。
非常感谢,示例真的很好地展示了如何做到这一点。请继续。
谢谢 Alcides 的好话。
已修复对鸢尾花数据集的引用。
嗨 Jason,我无法运行代码并获得输出,它说“No such file or directory: ‘pima-indians-diabetes.data.csv'”
确保您是从命令行运行代码,并且数据文件和代码文件在同一个目录中。
是否有可用的数据文件?
嗨 Jason,关于您帖子的又一个说明是,“1. 处理数据”中您引用了 iris.data。
谢谢,已修复!
很棒的文章。学到了很多。谢谢。谢谢。
谢谢
不客气!
感谢您的好文章。我非常欣赏分步说明。
您好先生,请告诉我如何使用朴素贝叶斯算法比较数据集。
为什么每次运行此代码时的准确性都会发生变化?
当我尝试运行此代码时,每次都会得到不同的准确性百分比,范围在 70-78% 之间。
为什么会这样?
为什么它不给出恒定的准确性百分比?
由于数据集的拆分是使用随机函数完成的,因此准确性会有所不同。
我对此概念非常陌生,请帮我解决这个查询。
算法每次都会将数据集拆分为相同的顶部 67% 和底部 33%。
测试集在每次运行时都相同。
因此,即使我们使用随机函数对顶部 67%(训练集)进行随机索引。
像这样的计算:
((4+2)/6) 和 ((2+4)/6) 每次都会得到相同的结果。这是如何产生不同结果的?
这与高斯概率密度函数中的计算顺序有关吗?
嗯……数学计算会在您一次又一次地获取相同样本时出现。
但这里的问题是……我们正在获取随机数据本身……就像……变量在每一行中不会相同,对吧……所以如果你随机更改行……最终准确性会改变……考虑到这一点……您可以在每次运行时取准确性的平均值来获得“无波动准确性”,以防您想要……
希望有所帮助。
嘿,不错的文章——一个问题——为什么你在 STD偏差过程中使用 N-1?
谢谢!
N-1 是样本(校正的或无偏的)标准差。请参阅此维基页面。
因为我只知道这些……
嘿!非常感谢!这非常有帮助。
如果您能就如何计算精度和召回率等其他指标提供一些想法,那就太好了。
谢谢!
先生
当我在 IDLE (python 2.7) 中运行相同的代码时——代码运行正常,但当我在 eclipse 中运行时,出现的错误是:
1) 警告 – 未使用的变量 dataset
2) for 循环中的未定义变量 dataset
为什么会有这种差异?
很棒的帖子,Jason。
对于 MBA/LLM,它使得朴素贝叶斯在法律编码中易于理解和实现。期待阅读更多。祝您一切顺利,Melvin
Jason,
很棒的例子。谢谢!一个小建议: “calculateProbability” 不是一个实际计算高斯概率密度的函数的好名字——PDF 值可能大于 1。
祝好,
-Igor
说得好,谢谢!
嗨,Jason,
很棒的帖子。我真的学到了很多。但我有一个问题?为什么您不在calculateClassProbabilities()中使用P(y)值?
如果我正确理解了这个模型,一切都基于贝叶斯定理
P(y|x1….xn) = P(x1…..xn|y) * P(y) / P(x1……xn)
P(x1……xn)将是一个常数,因此我们可以忽略它。
您的帖子很好地解释了如何计算P(x1……xn|y)(假设x1…..xn都独立,则我们有
P(x1……xn|y) = P(x1|y) * …. P(xn|y))
那p(y)呢?我假设我们应该计算训练集中y的观测频率,然后将其乘以probabilities[classValue],这样我们就有
P(y|x1…..xn) = frequency(classValue) * probabilities[classValue]
否则,让我们假设在500行的训练集中,我们有两个类0和1,但观察到0出现100次,1出现400次。如果我们不计算频率,那么概率可能会有偏差,对吗?我是否误解了什么?希望我的帖子清晰。我真的很希望您能回复,因为我有点困惑。
谢谢
Alex
我也有同样的问题——为什么会省略乘以p(y)?
还没有回答——互联网上没有人能回答这个问题。
只是不想接受没有理解的答案。
是的,我也同样的问题,也许P(y)是必要的,但为什么缺少P(y)时准确率不高呢?这是否证明了贝叶斯模型很强大?
你好,
我相信这是因为P(y) = 1,因为在计算P(x1…xn|Y)之前,类已经被分隔开了。
专家能否评论一下?
这个实现有重大错误;
首先,使用GaussianNB的实现给出了完全不同的答案。
为什么2个月后没有人回复。
我的担忧是,有太多糟糕的贝叶斯主义者有错误的概念。
我的领导读了这篇文章,现在他认为我是错的。
至少参数是正确的——计算概率有些错误。
def SplitXy(Xy)
Xy10=Xy[0:8]
Xy10 = Xy;
#print Xy10
#print “========”
zXy10=list(zip(*Xy10))
y= zXy10[-1]
del zXy10[-1]
z1=zip(*zXy10)
X=[list(t) for t in z1]
return X,y
from sklearn.naive_bayes import GaussianNB
X,y = SplitXy(trainingSet)
Xt,yt = SplitXy(testSet)
model = GaussianNB()
model.fit(X, y)
### 比较Python构建的模型
print (“Class: 0”)
for i,j in enumerate(model.theta_[0])
print (“({:8.2f} {:9.2f} {:7.2f} )”.format(j, model.sigma_[0][i], sqrt(model.sigma_[0][i])) , end=””)
print (“==> “, summaries[0][i])
print (“Class: 1”)
for i,j in enumerate(model.theta_[1])
print (“({:8.2f} {:9.2f} {:7.2f} )”.format(j, model.sigma_[1][i], sqrt(model.sigma_[1][i])) , end=””)
print (“==> “, summaries[1][i])
”’
Class: 0
( 3.18 9.06 3.01 )==> (3.1766467065868262, 3.0147673799630748)
( 109.12 699.16 26.44 )==> (109.11976047904191, 26.481293163857107)
( 68.71 286.46 16.93 )==> (68.712574850299404, 16.950414098038465)
( 19.74 228.74 15.12 )==> (19.742514970059879, 15.146913806453629)
( 68.64 10763.69 103.75 )==> (68.640718562874255, 103.90387227315443)
( 30.71 58.05 7.62 )==> (30.710778443113771, 7.630215185470916)
( 0.42 0.09 0.29 )==> (0.42285928143712581, 0.29409299864249266)
( 30.66 118.36 10.88 )==> (30.658682634730539, 10.895778423248444)
Class: 1
( 4.76 12.44 3.53 )==> (4.7611111111111111, 3.5365037952376928)
( 139.17 1064.54 32.63 )==> (139.17222222222222, 32.71833930500929)
( 69.27 525.24 22.92 )==> (69.272222222222226, 22.98209907114023)
( 22.64 309.59 17.60 )==> (22.638888888888889, 17.644143437447358)
( 101.13 20409.91 142.86 )==> (101.12777777777778, 143.2617649699204)
( 34.99 57.18 7.56 )==> (34.99388888888889, 7.5825893182809425)
( 0.54 0.14 0.37 )==> (0.53544444444444439, 0.3702077209795522)
( 36.73 112.86 10.62 )==> (36.727777777777774, 10.653417924304598)
”’
我认为他通过以下几行这样做。
probabilities[class_value] = summaries[class_value][0][2]/float(total_rows)
你好,
感谢这篇文章,它非常有帮助。我只是对您正在计算的概率P(x|Ck)有所评论,然后您进行预测,结果将是有偏差的,因为您没有乘以P(Ck),P(x)可以省略,因为它只是一个归一化常数。
哈哈,听起来你已经有了答案。谢谢你的言辞。也许可以分享你的实现代码给大家进一步澄清?先谢谢了。
非常感谢这个教程,Jason。
我有一个快速的问题,如果你能帮我的话。
在
separateByClass()定义中,我无法理解为什么vector[-1]是正确的用法,当vector是一个int类型对象时。如果我尝试在函数外逐个运行相同的命令,
vector[-1]的代码行显然会抛出TypeError: 'int' object has no attribute '__getitem__'。那么它在函数内部是如何工作的呢?
抱歉我的无知。我是Python新手。谢谢。
Jason你好!我只是想留言感谢你的网站。我正在为这个领域的工作做准备,它对我帮助很大。继续保持出色的工作!!:)
不客气!谢谢你留下了这么友善的评论,你真让我开心:)
嗨,Jason,
你的分类器很容易遵循。我尝试过,并且在你的数据上运行得很好,但是重要的是要注意它只适用于数值数据库,所以也许需要将数据从分类格式转换为数值格式。
另外,当我转换一个数据库时,有时算法会遇到除以零的错误,尽管我避免在特征和类中使用该数字。
有什么建议吗Jason?
谢谢,Jaime
谢谢
这是我找到的最好的材料,请继续帮助社区!
谢谢eduardo!
你好。
这一切都解释得很清楚,并且很好地描绘了机器学习的步骤。但是你计算P(y|X)的方式在这里是错误的,并且可能导致不必要的错误。
在这里,理论上,使用贝叶斯定律,我们知道:P(y|X) = P(y).P(X|y)/P(X)。由于我们想要最大化P(y|X)(给定X),我们可以忽略P(X),并选择最大化P(y).P(X|y)的结果。
有2点仍然不一致
——首先,你选择高斯分布来估计P(X|y)。但是在这里,你计算Probability会计算函数在特定点X、y的密度,以及相关的均值和偏差,而不是实际的概率。
——第二点是,你在估计P(y|X)时没有考虑到P(y)的计算。你的模型(具有正确的概率计算)可能只在所有样本在y的每个值中具有相同的数量(假设y是离散的),或者你运气好的话才有效。
总之,尽管存在这些数学问题,但这是一项很好的工作,也是机器学习的一个很好的入门。
感谢Jason提供的所有这些精彩内容。我喜欢你的一点是你的学术诚信、合作精神和简洁。
在我看来,你是机器学习方面最好的教学榜样之一。
也感谢Thibroll。但我希望能有一个真实的例子,用R、Python或任何其他语言来说明这个问题。
此致,
Emmanuel:。
嗨,Jason,
我一直在努力开始机器学习,你的文章给了我急需的第一个推动力。谢谢你的努力!:)
我需要这个代码的java版本..请帮帮我//
我正在使用这段代码——对它进行了一些调整——它在我从头开始实现NB时非常有帮助。我正在尝试进行下一步,并添加分类数据。您有什么建议在哪里可以找到添加这个想法的灵感?或者您能推荐Python中的任何特定函数/方法吗?我已经导入了所有属性,并将它们分成连续数据和分类数据两个数据集,以便在将它们的概率重新组合之前分别处理它们。我已经将分类数据放在同一个字典中,其中键是类,值是每个实例的属性列表。我不知道如何遍历这些值来计算频率,然后如何将它们存储起来,以便我拥有属性值以及它们的频率/概率。是嵌套字典吗?我是否应该走另一条路,而不使用类似的格式?
谢谢Jason,这个教程对我的博士论文中的NB算法实现非常有帮助。非常详细。
你好!谢谢!您尝试过对文本数据集做同样的事情吗,例如20Newsgroups http://qwone.com/~jason/20Newsgroups/?我很想得到一些提示或想法)
很棒的文章,但正如其他人指出的那样,存在一些数学上的错误,例如对单个值概率使用概率密度函数。
感谢这篇精彩的文章!我为葡萄酒和MNIST数据集实现了相同的功能,这些教程对我帮助很大!:)
第一个print语句出现了一个错误,因为您的括号会关闭print的调用(它返回None),然后您再调用format,所以代替
print(‘Split {0} rows into train with {1} and test with {2}’).format(len(dataset), train, test)
它应该是
print(‘Split {0} rows into train with {1} and test with {2}’.format(len(dataset), train, test))
总之,感谢这个教程,它真的很有用,干杯!
真诚地感谢这个优秀的网站。是的,我直到自己编写算法代码才能真正学会。这是一个非常重要的练习,可以将概念嵌入到大脑中。真是个了不起的努力!
为了测试算法,我将一些数据更改为其他类别,例如3或4(一行中的最后一位数字),并在计算方差时得到除以零的错误。我不确定为什么。这是否意味着这个特定程序只适用于2个类别?我没看到有什么限制它。
你好,我是一名日本学生。
在我看来,你正在计算p(X1|Ck)*p(X2|Ck)*…*p(Xm|Ck),并选择使此值最大的Ck。
然而,当我查看维基百科时,你应该计算p(X1|Ck)*p(X2|Ck)*…*p(Xm|Ck)*p(Ck)。
我不明白你什么时候计算了p(Ck)。
你能告诉我吗?
也有同样的想法,先验是怎么计算的?
这似乎是这个实现的一个错误。
我查看了scikitlearn的实现,他们似乎使用了正确的公式,
参考
https://github.com/scikit-learn/scikit-learn/blob/e41c4d5e3944083328fd69aeacb590cbb78484da/sklearn/naive_bayes.py#L432
你可以轻松添加先验。我把它留空是因为对于这个数据集来说它是一个常数。
这是和Alex Ubot上面的同一个问题。
计算参数是正确的。
但是预测实现是不正确的。
不幸的是,这篇文章排名很高,我认为每个人都在学习错误的做法。
非常好的教程。您能否也发布一个详细的RandomForest实现?如果您这样做,对我们来说将非常有帮助。
谢谢!!
好主意Swapnil。
您可能会发现这篇帖子很有用
https://machinelearning.org.cn/bagging-and-random-forest-ensemble-algorithms-for-machine-learning/
谢谢Jason……教程非常好。
你好,
我对这个朴素贝叶斯例子很感兴趣,下载了.csv数据和处理它的代码。
但是,当我在Pycharm IDE中使用Python 3.5运行它时,我遇到了无数的运行时错误。
其他人也成功运行过这段代码吗?如果成功了,他们使用了什么IDE/环境?
谢谢
Gary
你好Gary,
你可能想用Python 2.7运行它。
你好,
感谢出色的教程。我尝试用Go实现它。
这里有一个链接,有兴趣的人可以看看。
https://github.com/sudsred/gBay
这太棒了!!!谢谢Jason。
我在哪里能找到更多这样的内容?
因为没有特殊的库涉及,所以可以用任何语言实现。
你好,
“def splitDataset”中存在一些错误
在机器学习算法中,将数据集划分为训练集和测试集必须无重复(去重),因此index = random.randrange(len(copy))会生成重复数据。
例如,“index = 0 192 1 2 0 14 34 56 1……”
划分方法必须无数据重复。
这是一篇信息量大且解释详细的文章。虽然我认为这适用于Python 2.x版本,但在3.x中,我们的字典对象没有'iteritems'函数,我们现在在字典对象中有'items'。其次,format函数在很多print函数上都被调用了,本应在print函数中的字符串上调用,但不知何故却在print函数上调用,这会抛出错误,您能否检查一下?
嘿Jason
感谢您提供如此精彩的教程,我是这个概念的新手,并且想在电影评论上尝试朴素贝叶斯方法,针对我收集的文本文件中的单个电影评论。
您能否提供一些关于如何加载我的文件并对其进行正面或负面评论的提示?
您可能会从这个教程中受益,作为模板
https://machinelearning.org.cn/machine-learning-in-python-step-by-step/
您能否帮助我如何使用他们的分数和反馈来实现朴素贝叶斯来预测学生的表现?
抱歉,我很乐意回答您的问题,但我无法帮助您完成您的项目。我只是没有能力。
嗨,Jason,
非常感谢您如此好的文章,它在理解实现方面很有帮助,
我运行脚本时遇到问题。
我收到以下错误
”
if (vector[-1] not in separated)
IndexError: 列表索引超出范围
”
您能帮我弄对吗?
谢谢Vinay。
检查数据是否已成功加载。也许您的加载数据中有空行或空列?
嗨,Jason,
感谢这篇精彩的文章。您在测试集中使用了“?”(testSet = [[1.1, ‘?’], [19.1, ‘?’]])。您能否告诉我它指定了什么?
请给我一份用于朴素贝叶斯分类器的文本分类代码,使用Python。数据集分类为正面、负面或中性。
你好jeni,抱歉我没有准备这样的例子。
我是ML新手,今天发现了您的网站。它是互联网上最棒的ML资源之一。我已经收藏了它,谢谢您Jason,我以后每天都会访问您的网站。
谢谢,我很高兴你喜欢它。
def predict(summaries, inputVector)
probabilities = calculateClassProbabilities(summaries, inputVector)
bestLabel, bestProb = None, -1
for classValue, probability in probabilities.iteritems()
if bestLabel is None or probability > bestProb
bestProb = probability
bestLabel = classValue
return bestLabel
为什么预测结果不同
summaries = {‘A’ : [(1, 0.5)], ‘B’: [(20, 5.0)]} –预测为A
summaries = {‘0’ : [(1, 0.5)], ‘1’: [(20, 5.0)]} — 预测为0
summaries = {0 : [(1, 0.5)], 1: [(20, 5.0)]} — 预测为1
你好,有人能解释一下下面的代码片段吗?
def separateByClass(dataset)
separated = {}
for i in range(len(dataset))
vector = dataset[i]
if (vector[-1] not in separated)
separated[vector[-1]] = []
separated[vector[-1]].append(vector)
return separated
separated = {} 中的花括号是什么意思?
vector[-1]?
非常感谢!
花括号是Python中的集合或字典,您可以在此处了解有关集合的更多信息
https://docs.pythonlang.cn/3/tutorial/datastructures.html#sets
我正在尝试创建一个Android应用程序,其工作方式如下:
1)打开应用程序时,用户在文本框中输入数据并单击搜索。
2)然后应用程序通过互联网搜索输入的数据(使用机器学习算法),并返回一些答案。
我的数据集大约有17000个项目。
您能建议一下方法吗?Python/Java/等……?使用什么技术来实现机器学习算法和连接数据集?如何包含数据集以使Android应用程序的大小不增加?
基本上,我正在尝试实现一篇研究论文中描述的应用程序。
我可以在我的笔记本电脑上用Python实现机器学习(ML)算法来处理简单的ML示例。但是,我想开发一个Android应用程序,其中用户输入的数据将从网站和“数据集(使用ML)”中进行检查,然后根据两者的比较结果显示在应用程序中。问题是数据是40 MB,如何将ML结果从笔记本电脑反映到Android应用程序?顺便说一句,数据集也可以在线找到。我需要服务器吗?或者,我可以使用WAMP服务器通过localhost吗?
我应该使用哪个Python服务器?我还必须检查来自实时网站的数据。我能同时将我的Android应用程序连接到实时服务器和localhost吗?这样的场景对我的应用程序来说很常见吗?你有什么建议?Anaconda软件足够吗?
抱歉,我无法提供任何好的建议,我认为您需要咨询一些应用程序工程师,而不是ML人员。
你好 Jason,
lines = csv.reader(open(filename, “rb”))
IOError: [Errno 2] No such file or directory: ‘pima-indians-diabetes.data.csv’
我已下载csv文件,它与我的代码在同一个文件夹中。
我该怎么办?
你好Roy,
确认您目录中的文件名与脚本的预期完全匹配。
确认您是从命令行运行的,并且脚本和数据文件都在同一个目录中,并且您是从该目录运行的。
如果使用Python 3,请考虑将'rb'更改为'rt'(文本而不是二进制)。
这有帮助吗?
Jason你好。很棒的教程!但是,你为什么在calculateClassProbability()中遗漏了P(Y)?在我机器上的预测结果还可以……但上面有些人也提到了,你实际计算的是概率密度函数。而且你甚至没有回答他们的问题。
嗨,Jason,
您能帮我修复下面的错误吗?分割工作正常,但准确性给出了错误。
Split 769 rows into train=515 and test=254 rows
回溯(最近一次调用)
File “indian.py”, line 100, in
main()
File “indian.py”, line 95, in main
summaries = summarizeByClass(trainingSet)
File “indian.py”, line 45, in summarizeByClass
separated = separateByClass(dataset)
File “indian.py”, line 26, in separateByClass
if (vector[-1] not in separated)
IndexError: 列表索引超出范围
按类别选择训练和测试数据
例如
在Iris Dataset中:Species列有Setosa、versicolor和virginica这几个类别。
我想从每个类别值中选择80%的数据。
提前感谢
Shankru
shankar286@gmail.Com
您可以随机抽样或分层抽样,以确保训练集和测试集具有相同的类别混合。
朴素贝叶斯代码中的错误
IndexError:list index out of range
大家好
我是velmurugan,我在annauniversity tindivanam学习。
我有一个用于英文描述的java代码。
好吧,现在你让做什么
好吧,现在你让做什么
嗨,Jason,
这个例子奏效了。对朴素贝叶斯来说真的很好,但我一直在想联合概率分布的方法会是怎样的。给定一个数据集,如何在Python或R中构建一个贝叶斯网络?
你好 Jason,
我是Joelon。我是Python和机器学习的新手。在编译上面的脚本后,我一直收到运行时错误。我能把错误截图发给你,我们一步一步地解决吗?
你遇到了什么问题?
Jason你好!
感谢您的本教程。
我有一个问题:如果我们的x要预测的是一个向量呢?如何在calculateProbability函数中计算属于某个类的概率?
谢谢你
我不确定Bill是否理解。您能举个例子吗?
嗨 Jason,
感谢这篇精彩的文章。您的努力是无价的。关于处理单值概率案例的一个小问题。哪部分代码需要平滑处理?
抱歉,我不确定是否理解您的问题。您能重述一下吗?
你好 Jason,
首先,非常感谢您提供如此精彩的教程。
我有一个快速的问题,如果您能抽出宝贵时间回答。
问题:为什么summarizeByClass(dataset)只适用于特定模式的数据集,如您的示例数据集= [[2,3,1], [9,7,3], [12,9,0],[29,0,0]],而不适用于不同模式的数据集?
我认为它应该适用于所有不同的数据集。
谢谢,
Mohammed Ehteramuddin
只要最后一个变量是类别变量,它应该适用于任何数据集。
哦!您的意思是数据集(输入)的最后一个变量不能是我们将数据分类成的两个值以外的其他值,在我们的例子中,它应该是0或1。
非常感谢您。
是的。
getAccuracy函数中的
correct变量指的是什么?你能详细说明一下吗?抱歉,那是错误的问题。
编辑
理想情况下,高斯朴素贝叶斯具有lambda(阈值)值来设置边界。我想知道这段代码的哪一部分包含了阈值?
我没有包含阈值。
你能提供数据扩展吗?我因为某些原因无法下载。谢谢!
这是数据文件的直接链接
https://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data
有时UCI ML仓库会宕机几个小时。
我尝试运行程序,但它一直显示
File “nb.py”, line 102, in
main()
File “nb.py”, line 92, in main
dataset = loadCsv(filename)
File “nb.py”, line 11, in loadCsv
dataset[i] = [float(x) for x in dataset[i]]
ValueError: invalid literal for float(): 1,85,66,29,0,26.6,0.351,31,0
Jason你好…!
非常感谢您以非常清晰的方式对问题进行编码。由于我是机器学习的新手,并且以前也没有使用过Python,因此在修改它时遇到了一些困难。我想包含数据集的序号,然后显示哪个测试示例(例如,示例# 110)从类别0和类别1获得了多少概率。
您最好使用Weka
https://machinelearning.org.cn/start-here/#weka
嗨,Jason,
我一开始遇到了一个问题。加载文件并运行此测试后
filename = ‘pima-indians-diabetes.data.csv’
dataset = loadCsv(filename)
print(‘Loaded data file {0} with {1} rows’).format(filename, len(dataset))
我收到错误:“迭代器应返回字符串,而不是字节(您是否以文本模式打开文件?)”
顺便说一句,我正在使用python 3.6
谢谢你的帮助
将文件加载从二进制更改为文本(例如 'rt')
这段代码在Python 3.16上不起作用:S
3.6
谢谢Marcus。
Jason,您能否尝试修复它并使其在3.6下工作?
Jason,您能解释一下这段代码的作用吗?
是的,请看这里
https://machinelearning.org.cn/naive-bayes-for-machine-learning/
我在python 3.6.3中运行了代码,以下是更正。
—————————————————————————-
1. 将“rb”更改为“rt”
2. print(‘Split {0} rows into train={1} and test={2} rows’.format(len(dataset), len(trainingSet), len(testSet)))
3. 将所有.iteritems()更改为.items()
4. print(‘Accuracy: {0}%’.format(accuracy))
以下是一些结果
Split 768 rows into train=514 and test=254 rows
Accuracy: 71.25984251968504%
Split 768 rows into train=514 and test=254 rows
Accuracy: 76.77165354330708%
谢谢你的建议。
本教程中的代码错误百出……字符串输出格式甚至都没有做好!
这是2014年写的,随着版本的更新,python文档已经发生了巨大变化。
嘿Jason,我真的很喜欢这篇博文,因为它非常全面,即使对于像我这样的初学者来说,整体上也是可以理解的。但是,就像 Marcus 问的,您能否重写或指出如何编辑Python 3中具有新语法的那些部分?
此外,这个版本使用了高斯概率密度函数,我们如何使用其他的函数呢?数学或代码会不同吗?
Jason你好,感谢这篇博文,它非常有信息量,我刚上大学,很容易理解!我想知道这对于混合的二进制和分类数据该怎么做。例如,如果我想创建一个模型来确定汽车是否会发生故障,而一个类别中列出了10个汽车零件的名称,而另一个类别只是询问汽车是否过热(是或否)。再次感谢!
当然可以。
分类数据是否需要预处理?
不。朴素贝叶斯处理分类数据要简单得多。
https://machinelearning.org.cn/naive-bayes-tutorial-for-machine-learning/
你好!感谢这篇有用的文章。我有一个小问题:在您的calculateProbability()函数中,分母是应该乘以方差而不是标准差?
即
return (1 / (math.sqrt(2 * math.pi) * stdev)) * exponent应该改为
return (1 / (math.sqrt(2 * math.pi) * math.pow(stdev, 2))) * exponentJason你好。我访问过您的网站很多次。这真的很有帮助。我正在寻找Python中SVM的从头实现,就像您在此处实现朴素贝叶斯一样。您能给我SVM代码吗?
是的,我在我的书中提供了它:
https://machinelearning.org.cn/machine-learning-algorithms-from-scratch/
非常感谢您,Brownlee先生。我想请求您的许可,是否可以向我的学生展示您的实现?它们非常容易理解和遵循。再次非常感谢:)
没问题,只要您注明出处并链接回我的网站即可。
非常感谢:)
非常好的基础教程。谢谢。
谢谢。
嗨,Jason,
我本来会用joblib导出我的模型,并且我已经将分类数据转换为数字用于训练数据集来开发模型,现在我不知道如何将新的分类数据转换为使用训练模型进行预测。
新数据必须使用与用于训练模型的数据相同的方法进行准备。
有时这可能意味着将用于缩放或编码输入数据的对象/系数与模型一起保留。
这段代码中的学习在哪里?我认为这只是朴素贝叶斯分类。请指明学习过程。
好问题,概率是从数据中“学习”到的。
多么精美的文章。
谢谢,很高兴对您有帮助。
很棒的例子。您正在做一项伟大的工作,谢谢。请,我正在研究这个例子,但我对如何确定属性相关性分析感到困惑。也就是说,我如何确定哪个属性对我的模型是(将是)相关的?
也许你可以看看每个变量的独立概率?
非常感谢。感激不尽。
您能给我发送使用HOG和NAIVE BAYES进行行人检测的代码吗?
抱歉,我不能。
这段代码做什么?
while len(trainSet) < trainSize
index = random.randrange(len(copy))
trainSet.append(copy.pop(index))
return [trainSet, copy]
从数据集副本中随机选择行并将其添加到训练集中。
Jason
我对这个实现非常满意!我以它为灵感,制作了一个R语言版本。有一件事我不清楚。我理解训练集的均值和标准差是用来评估测试集的参数,但我不知道为什么这能奏效 lol。
如何用训练集数据和测试集实例属性来评估 GPDF 以“训练”模型?我可能是在过度字面地理解“训练”这个词。
我认为训练是多次重复某个过程,每次迭代都有改进,而这些迭代最终会产生一些提高预测能力的催化剂。似乎只有一个迭代来定义训练集的均值和标准差。不确定我的问题是否合理,如果不是,我很抱歉。
任何帮助都将是真正、由衷的感谢!
Scott Bishop
在这里,训练数据为模型使用的概率估计提供了基础。
嗨,Jason,
运行程序时,我有时会遇到“ZeroDivisionError: float division by zero”错误
分类完成后,有没有办法得到属于每个类别中的元素?
您是指混淆矩阵吗?
https://machinelearning.org.cn/confusion-matrix-machine-learning/
我添加了此函数
这可能有一个更优雅的写法,但我还是Python新手:)
返回的数组可以让你计算各种指标,如敏感度、特异度、预测值、似然比等。
哎呀,我发现我弄混了。FP 和 FN 必须颠倒过来,因为外部 if 子句检查的是真实条件。希望没有人复制了这个并遇到了麻烦……
总之,看起来混淆矩阵名副其实。
你好 Jason,
首先,感谢这个博客。我学到了很多关于Python(我对它相当陌生)以及这个特定分类器的知识!
我在一个包含胆固醇、年龄和心脏病的样本数据库上测试了这个算法,结果比逻辑回归更好。
然而,由于年龄明显不是正态分布,我不确定这个结果是否合法。
您能否解释一下如何将 calculateProbability 函数更改为不同的分布?
哦,还有:如何为我的回复添加代码标签,使其更具可读性?
这段代码仅用于学习目的,我建议在实际项目中还是使用 scikit-learn 中的内置函数。
https://machinelearning.org.cn/start-here/#python
嗨,杰森博士,
这是一篇非常好的文章。
我没有在这篇文章中看到 K 折交叉验证,就像我在您的从头开始的神经网络文章中看到的那样。这是否意味着朴素贝叶斯不需要 K 折交叉验证?或者不适用于 K 折交叉验证?
因为我尝试使用 K 折交叉验证和从头开始的朴素贝叶斯,但发现它很难,因为我们需要按类别分割数据来进行一些计算,如果我们有两类分类数据集,我们就会找到这两个数据集(但我们有一个 K 折交叉验证函数)。
我在理解 K 折交叉验证时遇到了严重的困难,看起来从头开始的实现取决于我们使用的分类器。
如果您对此方法(从头开始的朴素贝叶斯验证 - 使用 K 折交叉验证)有任何答案或建议,请告知我。
此致。
使用交叉验证来评估算法(包括朴素贝叶斯)是一个好主意。
如果方差为0,该如何处理?
如果方差为 0,则样本中的所有数据都具有相同的值。
如果‘stdev’为0,该如何处理?
如果标准差为0,则表示所有值都相同,该特征应被删除。
如何重新训练我的模型,而不必从头开始?
例如,如果我获得了一些新的实例标签,该如何处理?
许多模型都可以用新数据进行更新。
对于朴素贝叶斯,您可以跟踪离散值的频率和似然度,或者连续值的 PDF/质量函数,并使用新数据进行更新。
非常好的程序,它能正常工作。如何使用此 Pima Diabetes CSV 文件构建贝叶斯网络?
谢谢。
嘿,我能问一下为什么您没有使用 MLE 来估计先验概率吗?
MLE?
这是一个朴素贝叶斯分类器,但我们没有使用朴素贝叶斯定理,而是使用了高斯概率密度函数,为什么????
用来总结一个概率分布。
为什么输入向量是 [1.1,”?”]?它能正常工作,我用 [1.1] 试过了。为什么我们将 1.1 作为输入向量的参数?
看起来您的代码使用的是没有先验概率的高斯朴素贝叶斯。先验概率是通过训练集的 MLE 估计器获得的。它只是一个常数,乘以计算出的似然度。我两者都试过了(有/无先验概率),发现有先验概率的预测通常能获得更好的结果。
谢谢。
Jason,为什么我会收到这个错误消息
AttributeError: ‘dict’ object has no attribute ‘iteritems’ 当我尝试运行
# 根据类别值拆分数据集,在《Python 算法从头学》第 12 章的朴素贝叶斯示例中,返回一个字典?
谢谢
肯
听起来您正在将 Python 3 用于 Python 2.7 代码。
Jason,我解决了。Py 3.X 不理解 .interitem 函数,所以当我将其更改为 Py 2.7 .item 时,它运行正常。版本差异在 3.X 和 2.7 之间。
谢谢
很高兴听到这个消息。
你好,
感谢这篇有用的文章。
当我使用 Python 3.6 运行代码时,我遇到了
“ZeroDivisionError: float division by zero” 错误
有什么建议吗?
代码是为 Py2.7 编写的。
Jason,非常感谢您这篇精彩的文章。
我很高兴它能帮到你。
我想计算 F1 分数。对于二元分类问题,我可以做到。我对于多类别分类如何做到感到困惑。我已经为我的数据集计算了混淆矩阵。我的数据集包含三个不同的类值。
请提出建议。
sklearn 库可能支持此功能,更多信息请参见
https://scikit-learn.cn/stable/modules/generated/sklearn.metrics.f1_score.html
感谢您的精彩工作。附注:指向 Weka 朴素贝叶斯的外链显示 404。
诚挚的问候
谢谢。
你好先生
很棒的例子。您做得很棒,谢谢。请也上传与隐马尔可夫模型相关的类似帖子。
感谢您的建议。
感谢您发布这个很好的算法解释。尽管如此,我遇到了很多麻烦,直到我发现这是高斯朴素贝叶斯版本。我期望进行概率计算,包括先验、后验等。我花了一段时间才弄清楚。不过,我确实学到了很多东西。
谢谢。
如何在 python 2.7 中修复此错误
return sum(numbers) / (len(numbers))
TypeError: unsupported operand type(s) for +: ‘int’ and ‘str’
感谢您这篇精彩的文章……
嗨 Jason。我运行您的代码时遇到了这个错误
File “C:/Users/Mustajab/Desktop/ML Assignment/Naive Bayes.py”, line 191, in loadCsv
dataset = list(lines)
错误:迭代器应该返回字符串,而不是字节(您是否以文本模式打开文件?)
如何修复此错误?
P(A/B) = (P(B/A)P(A)) / P(B))
这是公式。
在公式的 RHS 中,我们仅使用分子,因为分母对于每个类都是相同的,并且不添加任何额外信息来确定哪个概率更大。
但我不认为 calculateProbability() 函数中的分子实现正确。
特别是 P(A) 需要与属于特定类的各个特征的条件概率的乘积相乘。
这里的 P(A) 是我们的类概率。该项没有乘以 calculateClassProbabilities() 函数中的最终乘积。
这里似乎有些不对劲。calculateProbability() 函数的输入是 x=71.5, mean=73.0, stdev=6.2。一些简单的数学计算会告诉您,x 距离均值有 0.24 个标准差。在高斯分布中,您很难找到比这更接近的值了。然而,属于该分布的概率只有 6%?这不应该接近 94% 吗?
你好 Jason,我尝试用我自己的文件运行这段代码,但是出现了“ValueError: could not convert string to float: wtdeer”。您知道如何修复它吗?
非常感谢你
也许可以尝试使用 scikit-learn 库作为起点。
https://machinelearning.org.cn/start-here/#python
Jason,您的教程很棒,但需要您关注打印语句中的拼写错误,希望很快能得到修复。
不过,再次感谢您提供了如此出色的解释!
谢谢。
File “C:/Users/user/Desktop/ss.py”, line 9, in
dataset = loadCsv(filename)
File “C:/Users/user/Desktop/ss.py”, line 4, in loadCsv
dataset = list(lines)
_csv.Error: iterator should return strings, not bytes (did you open the file in text mode?)
解决这个错误。
Jason,我有一个问题,我想预测心脏病,结果应该像这样:例如,有 9 种心脏病:心力衰竭、中风等,它会预测数据并生成结果,例如您患有中风疾病。所以我的问题是,哪种分类器最好?
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
在代码程序中,您能向我展示 P(H|E)、(P(E│H)、P(H) )、(P(E)) 是什么吗?如我们所知,这是朴素贝叶斯分类器的公式。您能告诉我吗?因为我需要这个参考来展示给我的讲师。谢谢。
Jason,
我喜欢您“从头开始构建”的机器学习算法方法,这与“理解算法”同样重要。您的实现满足了“构建部分”,这在大学课程中有时被低估了。
谢谢。
这是非常详细的分步指南,您的博客是机器学习编码的最佳博客之一。朴素贝叶斯是一个非常强大的算法,但我发现它最常与其他分类器结合使用,并通过投票来选择最终分类器。
好建议!
我收到一个错误
could not convert string to float: id
在 load Csv 函数中
我相信该示例需要 Python 2。您能否确认您的 Python 版本?
为什么这个模型预测的值全部是 1 或全部是 0?
该模型预测概率和类别值。
感谢您深入的教程。
我重新实现了代码,但只能获得 60% 左右的准确率。到目前为止最好的是 70%,而且是偶然的。您 76.8% 的结果似乎有些遥不可及。训练/测试数据集是随机选择的,所以很难精确。我只是想知道 60% 的准确率是否符合预期,还是我做错了什么。
我的错,忽略我之前的帖子。代码有误。76% 是平均结果。
干得好。
仔细检查您是否准确复制了所有代码?
它不起作用,您能帮帮我吗?
当我执行代码时,它显示以下错误,您能帮帮我吗?
Split{0}rows into train={1} and test={2} rows
—————————————————————————
AttributeError Traceback (最近一次调用)
in
98 accuracy = getAccuracy(testSet, predictions)
99 print(‘Accuracy: {0}%’).format(accuracy)
--> 100 main()
in main()
91 dataset = loadCsv(data)
92 trainingSet, testSet = splitDataset(dataset, splitRatio)
---> 93 print(‘Split{0}rows into train={1} and test={2} rows’).format(len(dataset), len(trainingSet), len(testSet))
94 # prepare model
95 summaries = summarizeByClass(trainingSet)
AttributeError: ‘NoneType’ object has no attribute ‘format’
很抱歉听到这个消息,也许可以尝试 sklearn 提供的实现。
https://scikit-learn.cn/stable/modules/naive_bayes.html
一个问题
计算贝叶斯函数时,我们使用(先验概率 * 密度函数)/ 总概率,但在您的算法中,您只计算密度函数并用它来做预测。为什么?我很困惑。
感谢您的倾听。
我意识到分母可以省略,但先验概率呢?我是否也应该计算?
是的,总的来说这是一个好主意。
我移除了先验概率,因为它在这种情况下是一个常数。
这是因为数据集的常数吗?
是的,即使每个类别的观测值数量相等,例如,固定先验概率。
感谢您的解释。🙂
不客气。
嗨,很棒的例子。您做得很好,谢谢。
我有一个问题,您能帮我修改代码来计算精确率和召回率吗?
抱歉,我无法为您更改代码。
您可以在此处访问一系列指标。
https://scikit-learn.cn/stable/modules/classes.html#module-sklearn.metrics
好的,非常感谢。
恐怕您的回复表明您从根本上误解了先验概率。您确实需要在计算中包含先验概率,因为先验概率对于每个类别都是不同的,并且取决于您的训练数据——它是属于该类别的案例的比例,即如果使用整个数据集,结果为 0 的比例为 500/768,结果为 1 的比例为 268/700。想象一下,您有一个特征变量,其正态分布对于每个类别都相同——您在进行预测时仍需要考虑不同类别之间的比例。
只有当训练数据中每个类别的样本数量相等时,您才会省略先验概率,但在此实例中获得 257(=floor(768 * 0.67)/2)个每个类别的概率实际上为零。
要检查这一点是否属实很容易——只需在训练数据上拟合 scikit-learn 的 GaussianNB,并在训练数据和测试数据上检查其得分。如果您不包括每个类别的先验概率,您的结果将不匹配。
谢谢 Matthew。
嗨 Jason…我需要使用朴素贝叶斯来获取僧伽罗语(斯里兰卡使用的语言)的情感分析结果。我已经有一个预处理和标记好的数据集,其中包含句子。我能否使用上面的代码获得结果?
上面的代码仅用于学习。
可以考虑使用这个模型。
https://scikit-learn.cn/stable/modules/naive_bayes.html
你好,如何在 Debian 的 Raspberry Pi 上使用它,特别是文件夹路径?
我不知道 Raspberry Pi,抱歉。
你好,杰森
在您的 separateByClass 函数中
instead of separated[vector[-1]].append(vector) 应该是
separated[vector[-1]].append(vector[:-1])
否则您会将类别名称附加到特征中。
我实现了具有相同思想但自己实现的分类器,并且使用了不同的数据集。通过比较类条件密度,我的准确率超过 70%。但是,当我尝试比较后验概率时,准确率仅接近 50%。是我做错了什么,还是应该会降低?
也许可以尝试使用 scikit-learn 作为一部分开发的实现。
https://scikit-learn.cn/stable/modules/naive_bayes.html
感谢这篇精彩的文章。
我可能错过了这一点。
但你是如何计算边际概率的?
我们跳过了先验概率,因为类别是均等的,即它是一个常数。
多么精彩的基础文章……
非常感谢 Jason。
谢谢。
一如既往的精彩。谢谢!
谢谢。
我是 Python 新手,我很想学它,感谢作者发布了这份博客列表,帮助我更好地学习 Python。
再次感谢。
谢谢,很高兴它有帮助!
如何使用朴素贝叶斯算法处理文本数据而不是二进制数据?
您能将 Python 代码转换为 C# 吗?
文本可以通过词袋模型进行编码,然后可以使用朴素贝叶斯模型。
抱歉,我没有 C# 的教程。
你好,Jason!
恭喜您发表了这篇文章,但我在这里遇到了一个错误……
我正在尝试运行代码,但总是出现“IndexError: list index out of range”
行列表只有四个数字:row = [5.7, 2.9, 4.2, 1.3]
然而,在 calculate_class_probabilities 函数中,下面的“for”会引发错误,因为 class_summaries 的长度结果是 5,而 range 迭代让“i”的值为 0、1、2、3 和 4。
因此,当“i”获得值 4 时,row[ 4 ] 超出范围…
row[0] = 5.7
row[1] = 2.9
row[2] = 4.2
row[3] = 1.3
for i in range(len(class_summaries))
mean, stdev, _ = class_summaries[j]
probabilities[class_value] *= calculate_probability(row[ i ], mean, stdev)
请问您能帮我修复吗?
提前感谢
谢谢。
很抱歉听到这个消息,也许可以确认您是否完全复制了代码?您使用的是 Python 3 吗?
我还有一些建议。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
精彩的文章,对我帮助很大。
我的问题是,我们到底从训练集中使用了什么来测试模型?我的意思是,我明白了从训练集中得到的是“摘要”(每个类别中属性的平均值、标准差和长度),但我们如何确切地使用这些信息来预测测试集的类别?
请看最后的代码示例,它展示了如何进行单次预测。
并查看 predict() 函数。
我查看了所有内容,但我毕竟是编码新手,需要一些帮助。
我想我试图理解的是这些行
for i in range(len(class_summaries))
mean, stdev, _ = class_summaries[i]
probabilities[class_value] *= calculate_probability(row[i], mean, stdev)
我假设是这样:借助这些来自训练集的信息(每个类别的所有点的属性的平均值和标准差),我们计算新点属于该类别的 SAME 属性的概率。
然后将这些概率相乘(对于所有属性),并与类别概率相乘,最终得到新点属于该类别的概率。
我无法更好地解释了,我希望我所说的能够说清楚。
那么,这是正确的吗?
差不多。我在下面有更详细的解释:
https://machinelearning.org.cn/classification-as-conditional-probability-and-the-naive-bayes-algorithm/
感谢分享。但是……你为什么不提及代码所有者?
提及一下会很好
https://dzone.com/articles/naive-bayes-tutorial-naive-bayes-classifier-in-pyt
是的!人们应该停止窃取我的代码/帖子。
他们未经许可就复制了我的代码。这种情况时有发生。
我的帖子最初写于 2014 年,然后于 2019 年更新。
以下是我从 2015 年开始的帖子的独立备份:
https://web.archive.org/web/20150201000000*/https://machinelearning.org.cn/naive-bayes-classifier-scratch-python/
你好…
非常感谢这篇博文……我有一个问题……
对于 MNIST 数据集的数字分类问题,我能否使用二项分布或多项二项分布,而不是应用正态分布?
在 MNIST 数据集中,有 0 到 9 的数字。所以我想有 10 个类别。
谢谢
您可以使用多项分布,例如多项回归而不是逻辑回归。
不过也可以试试 LDA。
精彩的文章,对我帮助很大,成功实现了 Pima Indian 数据集。
谢谢,很高兴听到这个!
我需要理解这个公式。
P(类别=0|X1,X2) = P(X1|类别=0) * P(X2|类别=0) * P(类别=0)
我正在尝试使用链式法则和贝叶斯定理,但我卡住了。
任何帮助不胜感激。
您在这个公式上遇到了什么具体问题?
你好,
如果我的 y 变量是离散的(因变量),而我的三个变量 x1、x2、x3(自变量)是连续的,那么如何应用朴素贝叶斯模型?
高斯朴素贝叶斯(如上所述)是适用的。
如何在训练阶段找到 P(y/x1,x2,x3),其中 y 是离散的(包含 2 个类别),而 x1,x2,x3(独立向量)是连续的?
我们使用每个 P(y_i|x_i) 的独立概率来估计它。
正如您在文章中解释的那样,我是否必须在这里使用这个公式 P(class=0|X1,X2,x3) = P(X1|class=0) * P(X2|class=0) * P(x3|class=0)* P(class=0)?有没有哪个 Python 函数可以直接给我这个条件概率分布?感谢您回复每一个简单的问题。
是的,请使用此类
https://scikit-learn.cn/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html
当我尝试修剪或更改 CSV 中的数据时,我收到“ZeroDivisionError: float division by zero”。我看到其他人写道这与 Python 版本有关。是这样吗?如果是,我想这不是一个问题。
谢谢,
Derek
也许在计算频率时尝试添加一个很小的数字,例如 1e-15,或者使用 sklearn。
我有一个关于概率密度函数更普遍的问题。您写道:
“运行它会打印出某些输入值的概率。您可以看到,当值为 1 且均值和标准差为 1 时,我们的输入是最有可能的(钟形曲线的顶部),概率为 0.39。”
但在连续环境中(对于高斯分布而言),一个特定值的概率总是为零,因此 0.39 不能被解释为概率。我是否有什么地方理解错了,或者这只是为了简化而使用的术语?
PDF 总结了域中所有可能事件的概率。一旦知道,我们就可以估计域中单个事件的概率,而不是孤立的事件。
很棒的教程和指南……
我可以得到 R 版本的代码吗??或者有人知道可以获得帮助的网站吗?
抱歉,我没有。
我在 str_column_to_float 函数中遇到“无法将字符串转换为浮点数:‘Id’”类型的错误。如何解决这个问题?
很抱歉听到这个消息,这些提示可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Jason,
我正在对 Pima Indians 文件使用相同的代码。我遇到了 ZeroDivisionError。
实际错误指向——
—-> 8 variance=sum([pow(x-avg,2) for x in numbers])/float(len(numbers)-1)
9 print(“variance at stdevfunction=”,variance)
10 return math.sqrt(variance)
ZeroDivisionError: float division by zero
很抱歉您遇到问题,这些提示可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
您好,我遇到了这个错误。你能帮帮我吗?
回溯(最近一次调用)
File “C:/Users/W10X64_PLUS-OFFICE/Desktop/IRIS PROJECT/Predict.py”, line 100, in
str_column_to_float(dataset, i)
File “C:/Users/W10X64_PLUS-OFFICE/Desktop/IRIS PROJECT/Predict.py”, line 21, in str_column_to_float
row[column] = float(row[column].strip())
ValueError: could not convert string to float: ‘sepal_length’
另外,我有一个问题。我正在从事一个使用混合推荐方法的酒店推荐系统项目。请看我的数据集 -> https://drive.google.com/file/d/1jGdcZ2yEbHh-JnXl4eAowyUQaPwebiW8/view?usp=sharing 。这个算法适合我吗?
很抱歉听到您遇到了麻烦,这些提示会有帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
这个过程将帮助你完成你的项目。
https://machinelearning.org.cn/start-here/#process
博士您好,
我正在攻读硕士学位,我的论文是关于基于机器学习(朴素贝叶斯)的 DDoS 检测,我创建了一个基于高斯 NB 的模型,但我使用了 sklearn 库来实现该算法,我的导师要求我设计一个贝叶斯算法并与我从 sklearn 库中使用的传统贝叶斯算法进行比较。我发现很难修改算法并使其成为我自己的,您对此有什么建议吗?
提前感谢。
什么是“传统贝叶斯算法”?
就像 scikit-learn 库中的(高斯 NB)一样。
请参阅上面关于此内容的教程。
非常感谢您的详细解释和代码。
“将对数似然加到对数先验以计算后验”的建议可以在这里找到
https://github.com/j-dhall/ml/blob/gh-pages/notebooks/Gaussian%20Naive%20Bayes%20for%20Iris%20Flower%20Species%20Classification.ipynb
这主要是为了避免将非常小的数相乘导致更小的数和舍入误差。
干得好!
也许您可以引用并链接回您基于代码的教程。
非常感谢您,这很有帮助。这段代码只用于连续数据集吗?顺便问一下,您能否就如何处理离散数据的问题给我一些建议?运行此代码时,我由于数据集中的离散数据(我的数据集是分类和连续的混合)而收到 float division zero。
再次感谢!
不客气。
是的,您可以使用二项分布或多项分布而不是高斯分布。
是的,在组合概率时添加 1 来处理零情况是一个好主意。
谢谢 Jason。您能否展示一个如何为离散数据执行多项概率的示例?我已经查看了您其他的文章,但看起来并不清楚。
这会有帮助
https://machinelearning.org.cn/discrete-probability-distributions-for-machine-learning/
谢谢,但文章显示的是使用库——如果您有任何想法,我想了解如何从头开始做。
嗨,您能告诉我如何为这段代码生成混淆矩阵和 F1 分数吗?我尝试使用 sklearn 库,但无法弄清楚如何或应该传递什么作为所需的两个位置参数,我的意思是,对于这个模型,“y_test”、“y_prediction”将是什么?
例如。
f1score=f1_score(y_test, y_prediction)
cm=confusion_matrix(y_test, y_prediction)
是的,请看这个
https://machinelearning.org.cn/confusion-matrix-machine-learning/
谢谢回复,我读了那篇文章,我没有问题理解混淆矩阵,我只是不知道在这段代码中,我应该将什么参数传递给混淆矩阵函数,这些参数等同于(y_test, y_prediction)?我的意思是,当我写下面的代码时,根据您的模型,我应该传递什么作为我的两个参数?
cm = confucion_matrix(? , ?)
print (cm)
您将您的数据集的预期值和预测值传递进去。
更多帮助请点击此处
https://scikit-learn.cn/stable/modules/generated/sklearn.metrics.confusion_matrix.html
谢谢,您看,我刚开始接触机器学习,我一直在重写您的代码以便更好地理解它,我知道您必须将预期值和预测值传递给函数才能得到混淆矩阵,而这正是我遇到的问题,我不知道您的代码中的预期值和预测值是什么。是否需要编写更多代码,或者上面的代码中是否已经有可以传递给 confusion_matrix(expected?, predicted?) 函数的预期值和预测值?
上面的示例使用 k 折交叉验证来多次评估模型。
首先,简化示例,使其能对一个训练集和一个测试集拟合模型一次。
然后使用模型对测试集进行预测,来自测试集的 target 值是“预期”值,预测是“预测”值。
抱歉,我无法为您进行这些更改——如果这太具挑战性,我建议从一个使用库实现的算法的更简单的教程开始,并将重点放在该算法的评估上。
很棒的文章……!非常好的解释……!谢谢
谢谢!
这是一篇有用的文章,我认为在其他评论中很容易看到,所以这篇文章写得很好并且很有用。继续保持良好的工作。
谢谢。
你好,Jason。一如既往,这是一篇很棒的文章。请问,您能就如何在 Python 中调整 GaussianNB 给出建议吗?通过哪些参数?您的一些帖子?其他信息来源?谢谢。
谢谢。
这可能是一个好的开始。
https://scikit-learn.cn/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html
你好 Jason,谢谢您的教程。您有 R 版本吗?谢谢
一个简短的例子在这里:https://machinelearning.org.cn/non-linear-classification-in-r/
—————————————————————————
你好 Jason Brownlee
我在使用 Jupyter Notebook 和 Python 3.9 时遇到了这个错误。有什么修复建议吗?
TypeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_8620/3280026982.py in
97 filename = ‘iris.csv’
98 dataset = load_csv(filename)
—> 99 for i in range(len(dataset[0])-1)
100 str_column_to_float(dataset, i)
101 # convert class column to integers
TypeError: ‘NoneType’ object is not subscriptable
检查您的 iris.csv,这应该意味着 load_csv() 返回 None,即无法加载 CSV 数据。
非常感谢,非常有帮助。
很高兴收到您的好评,Robbiek!
嗨,Jason,
您能否帮助解决以下请求?
我不确定 row[i] 在以下部分中的值是什么意思。
probabilities[class_value] *= calculate_probability(row[i], mean, stdev)
它在每次迭代中是否返回数据集的第一行的每个元素,例如,对于 iris 数据集的值 5.1,3.5,1.4,0.2,它是否返回 5.1, 3.5,依此类推?
或者它在每次迭代中返回每个行的每个元素,或者它是其他东西?
Please suggest.
您好 Kumar… 感谢您的提问。
我很想帮忙,但我实在没有能力为您调试代码。
我很乐意提出一些建议
考虑将代码积极削减到最低要求。这将帮助您隔离问题并专注于它。
考虑将问题简化为一个或几个简单的例子。
考虑寻找其他可行的类似代码示例,并慢慢修改它们以满足您的需求。这可能会暴露您的失误。
考虑在 StackOverflow 上发布您的问题和代码。
如此漂亮的教程!对我帮助很大。
关于缺失的 PRIOR 项,我不同意。它已包含在这些行中
for class_value, class_summaries in summaries.items()
probabilities[class_value] = log(summaries[class_value][0][2]/float(total_rows))
我已通过 Scikit API GaussianNB 仔细检查了我的结果。完全匹配!
感谢您的反馈,Alexandre!
嗨 Jason
感谢这个很棒的教程!
只是一个愚蠢的问题,这是
• mean = sum(x)/n * count(x)
正确的吗?
难道不应该是
• mean = sum(x)/count(x)
?
在我看来,代码
# 计算数字列表的均值
def mean(numbers)
return sum(numbers)/float(len(numbers))
实现了后者。
谢谢!
你好 Antonio…以下可能有助于阐明平均值(mean)的计算
https://guru99.com.cn/find-average-list-python.html
嗨 James,
n 在
mean = sum(x)/n * count(x)?
我认为应该是
mean = sum(x)/count(x)
中的意思是?正如在“Python Average – 使用 sum() 和 len() 内置函数”部分所指出的。
作为一个刚开始学习 Python 的人,我渴望深入学习它。感谢作者分享这个博客列表;它非常有帮助,一定会增强我的 Python 学习之旅。再次感谢您的贡献!
Maya,不客气!如果您对我们的内容有任何疑问,请随时告知我们。
我绘制了将此应用于网格的结果。显示了分类之间的边界。
from sklearn import datasets
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
...其余代码...
# 只使用前 2 列和目标
iris = datasets.load_iris()
dataset = iris.data[:, :2]
target = iris.target[:, np.newaxis]
dataset_with_target = np.hstack((dataset, target))
# 拟合模型
model = summarize_by_class(dataset_with_target)
# 创建一个网格,x 轴为第一个特征,y 轴为第二个特征
h= 0.2
x_min, x_max = dataset[:, 0].min() - 1, dataset[:, 0].max() + 1
y_min, y_max = dataset[:, 1].min() - 1, dataset[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 预测网格中每个点处的响应
Z = [[predict(model, [x, y]) for x, y in zip(row_x, row_y)] for row_x, row_y in zip(xx, yy)]
Z = np.reshape(Z, xx.shape)
# 浅色表示边界,粗色表示点
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
plt.figure()
# 绘制边界
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# 绘制点
plt.scatter(dataset[:, 0], dataset[:, 1], c=iris.target, cmap=cmap_bold)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("Bayes")
plt.show()
您好 Michael…感谢您的反馈!如果您有任何可以帮助您的问题,请告知我们!
谢谢!感谢这些信息。不错的机器学习文章
您好 se Tel…不客气!我们非常感谢您的反馈和支持!