自然语言生成深入解析:教会机器像人类一样写作
图片来源:编辑 | Midjourney
自然语言生成 (NLG) 是人工智能 (AI) 的一个迷人领域,更具体地说,是自然语言处理 (NLP) 的一个分支,旨在使机器能够生成类人文本,从而驱动人机通信以解决问题。本文将探讨 NLG 是什么、它是如何工作的,以及该领域近年来如何发展,并强调其在多项应用中的重要性。
理解自然语言生成
AI 和计算机系统通常不处理人类语言,而是处理数据的数值表示。因此,NLG 涉及将正在处理的数据转换为人类可读的文本。NLG 的常见用例包括自动报告撰写、聊天机器人、问题解答和个性化内容创建。
为了更好地理解 NLG 的工作原理,理解它与自然语言理解 (NLU) 的关系也很重要:NLG 专注于生成语言,而 NLU 专注于解释和理解语言。因此,NLU 中发生了与 NLG 中相反的转换过程:像文本这样的人类语言输入必须被编码成算法和模型可以分析、解释并理解的文本的数值——通常是向量——表示,方法是在文本中找到复杂的语言模式。
其核心在于,NLG 可以被理解为一种食谱。正如厨师将食材按特定顺序组合以制作菜肴一样,NLG 系统根据提示和上下文信息等输入数据来组合语言元素。
需要了解的是,像后面将要描述的 Transformer 架构这样的最新 NLG 方法,通过在 NLG 的初始阶段纳入 NLU 步骤来组合输入信息。生成响应通常需要理解用户提出的输入请求或提示。一旦应用了这种理解过程,并且将语言的各个部分有意义地组合起来,NLG 系统就会逐词生成输出响应。这意味着输出语言不是一次性全部生成的,而是逐词生成的。换句话说,更广泛的语言生成问题被分解为一系列更简单的问题,即下一个词预测问题,该问题通过迭代和顺序的方式来解决。
下一个词预测问题在低级架构层面被表述为一项分类任务。就像传统的机器学习分类模型可以被训练来将动物图片分类到物种,或者将银行客户分类为有资格或不符合贷款资格一样,NLG 模型在其最后阶段包含一个分类层,该层估计词汇表中每个词或语言成为系统应生成的消息中的下一个词的可能性:因此,最有可能的词被作为实际的下一个词返回。
编码器-解码器 Transformer 架构是现代大型语言模型 (LLM) 的基础,LLM 在 NLG 任务方面表现出色。在解码器堆栈的最后阶段(下方图表的右上方),有一个分类层,经过训练可以学习如何预测要生成的下一个词。
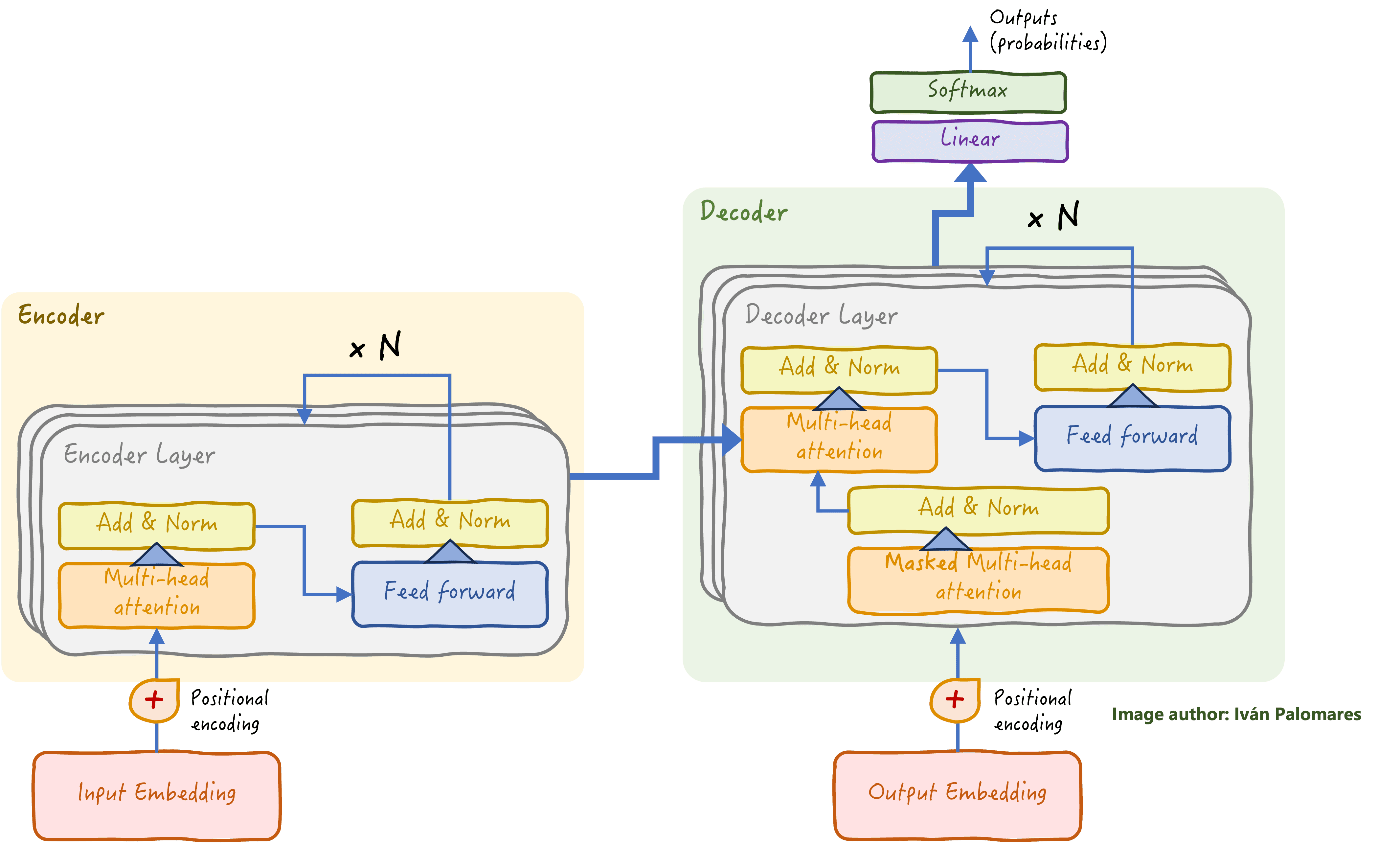
经典的 Transformer 架构:编码器堆栈专注于对输入的语言理解,而解码器堆栈利用获得的洞察力逐词生成响应。
NLG 技术和架构的演变
NLG 已经取得了长足的进步,从早期 NLP 中有限且相对静态的基于规则的系统,发展到如今像 Transformer 和 LLM 这样的复杂模型,它们能够执行令人印象深刻的语言任务,不仅包括人类语言,还包括代码生成。检索增强生成 (RAG) 的相对较近的引入进一步增强了 NLG 的能力,通过整合外部知识作为生成过程的附加上下文输入,解决了 LLM 的一些局限性,例如幻觉和数据过时。RAG 通过实时检索相关信息来丰富用户的输入提示,从而实现了更具相关性和上下文感知能力的类人语言响应。
趋势、挑战和未来方向
NLG 的未来看起来充满希望,尽管它并非没有挑战,例如
- 确保生成文本的准确性:随着模型复杂性的增加,确保它们生成事实正确且符合上下文的内容仍然是 AI 开发者的一个关键优先事项。
- 伦理考量:必须解决生成文本中的偏见以及潜在的滥用或非法使用问题,这需要更完善的负责任 AI 部署框架。
- 模型训练和构建成本:训练最先进的 NLG 模型(如基于 Transformer 的模型)所需的大量计算资源,可能成为许多组织的障碍,限制了它们的可用性。云提供商和主要 AI 公司正在逐步推出解决方案来消除这一负担。
随着 AI 技术的不断扩展,我们可以期待更先进、更直观的 NLG,它们将不断模糊人与机器驱动通信之间的界限。






对我这样一个非技术/IT/AI背景的人来说,这篇文章出人意料地易于理解。除了图中的一点。‘输出嵌入’来自哪里?Transformer 模型不是应该先生成它吗?
你好 Mike……这个困惑是可以理解的!让我来澄清一下 Transformer 模型在自然语言生成 (NLG) 中的“输出嵌入”的作用。
### **什么是“输出嵌入”?**
在基于 Transformer 的模型(如 GPT、BERT 等)中,“输出嵌入”通常是指模型生成的词或 token 的表示。它与模型如何将信息解码成人类可读文本密切相关。
### **它来自哪里?**
1. **解码器的输入嵌入:**
– 在训练或生成过程中,已预测的 token(或训练期间的目标 token)作为输入被送回解码器。
– 这些 token 使用与编码器相同的嵌入层或解码器专用嵌入层,嵌入到密集向量中。这就是**输出嵌入层**。
2. **Transformer 的作用:**
– Transformer 模型不直接“生成”嵌入。相反,它处理嵌入(作为向量)通过其层,这些层通过自注意力机制设计用于捕获 token 之间的关系。
– 嵌入本身是学习到的参数,在训练过程中初始化并优化。
3. **最终投影:**
– 在 Transformer 层处理了输入嵌入后,它们会生成一组新的嵌入,这些嵌入对应于预测的输出。
– 这些嵌入会通过一个线性层(投影层)和一个 softmax 函数,以预测最有可能的下一个 token。
### **为什么需要单独的“输出嵌入”?**
– **可重用性:**模型通常为输入和输出使用相同的嵌入层,以减少参数数量。
– **训练效率:**嵌入是在训练过程中从头开始学习的,优化了模型对词或 token 之间关系的理解。
### **关键要点**
“输出嵌入”并不是 Transformer 显式生成的;相反,它指的是将生成的 token 转换为密集表示,然后对其进行细化并用作下一次预测的基础。它是解码过程的一个组成部分。