为新的数据集开发神经网络预测模型可能具有挑战性。
一种方法是首先检查数据集并构思可能适用的模型,然后探索简单模型在数据集上的学习动态,最后使用健壮的测试框架开发和调整模型以适应数据集。
这个过程可以用于开发有效的神经网络模型,用于分类和回归预测建模问题。
在本教程中,您将了解如何为纸币二分类数据集开发多层感知机(MLP)神经网络模型。
完成本教程后,您将了解:
- 如何加载和汇总纸币数据集,并利用结果来建议数据准备和模型配置。
- 如何探索简单MLP模型在数据集上的学习动态。
- 如何开发模型性能的稳健估计,调整模型性能并对新数据进行预测。
让我们开始吧。
- 更新于2021年10月:predict_classes() 语法已弃用

为钞票认证开发一个神经网络
照片来自 Lenny K Photography,部分权利保留。
教程概述
本教程分为4个部分,它们是:
- 纸币分类数据集
- 神经网络学习动态
- 稳健的模型评估
- 最终模型及预测
纸币分类数据集
第一步是定义和探索数据集。
我们将使用“纸币”标准二分类数据集。
纸币数据集涉及根据从照片中获得的多个测量值来预测给定纸币是否为真。
该数据集包含 1,372 行,具有 5 个数值变量。这是一个具有两个类别(二分类)的分类问题。
以下是数据集中五种变量的列表。
- 小波变换图像的方差(连续)。
- 小波变换图像的偏度(连续)。
- 小波变换图像的峰度(连续)。
- 图像的熵(连续)。
- 类别(整数)。
下面是数据集中前 5 行的样本
|
1 2 3 4 5 6 7 |
3.6216,8.6661,-2.8073,-0.44699,0 4.5459,8.1674,-2.4586,-1.4621,0 3.866,-2.6383,1.9242,0.10645,0 3.4566,9.5228,-4.0112,-3.5944,0 0.32924,-4.4552,4.5718,-0.9888,0 4.3684,9.6718,-3.9606,-3.1625,0 ... |
你可以在此处了解更多关于此数据集的信息:
我们可以直接从 URL 将数据集加载为 pandas DataFrame;例如:
|
1 2 3 4 5 6 7 8 |
# 加载纸币数据集并汇总其形状 from pandas import read_csv # 定义数据集位置 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv' # 加载数据集 df = read_csv(url, header=None) # 总结形状 print(df.shape) |
运行示例将直接从 URL 加载数据集并报告数据集的形状。
在这种情况下,我们可以确认数据集有 5 个变量(4 个输入和 1 个输出),并且数据集有 1,372 行数据。
对于神经网络来说,这并不算很多行数据,这表明使用小型网络,可能带有正则化,会是比较合适的。
这也表明使用 k 折交叉验证会是一个好主意,因为它能比训练/测试分割提供更可靠的模型性能估计,并且因为单个模型可以在几秒钟内完成训练,而不是像处理大型数据集那样需要数小时或数天。
|
1 |
(1372, 5) |
接下来,我们可以通过查看摘要统计信息和数据图来进一步了解数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 显示纸币数据集的摘要统计信息和图 from pandas import read_csv from matplotlib import pyplot # 定义数据集位置 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv' # 加载数据集 df = read_csv(url, header=None) # 显示摘要统计信息 print(df.describe()) # plot histograms df.hist() pyplot.show() |
运行示例首先加载数据,然后打印每个变量的摘要统计信息。
我们可以看到值具有不同的均值和标准差,可能需要在建模之前进行一些归一化或标准化。
|
1 2 3 4 5 6 7 8 9 |
0 1 2 3 4 count 1372.000000 1372.000000 1372.000000 1372.000000 1372.000000 mean 0.433735 1.922353 1.397627 -1.191657 0.444606 std 2.842763 5.869047 4.310030 2.101013 0.497103 min -7.042100 -13.773100 -5.286100 -8.548200 0.000000 25% -1.773000 -1.708200 -1.574975 -2.413450 0.000000 50% 0.496180 2.319650 0.616630 -0.586650 0.000000 75% 2.821475 6.814625 3.179250 0.394810 1.000000 max 6.824800 12.951600 17.927400 2.449500 1.000000 |
然后为每个变量创建直方图。
我们可以看到前两个变量可能具有类高斯分布的形状,而后两个输入变量可能具有偏斜高斯分布或指数分布的形状。
我们可能可以通过对每个变量使用幂变换来获得一些好处,以使概率分布的偏斜程度降低,这可能会提高模型性能。
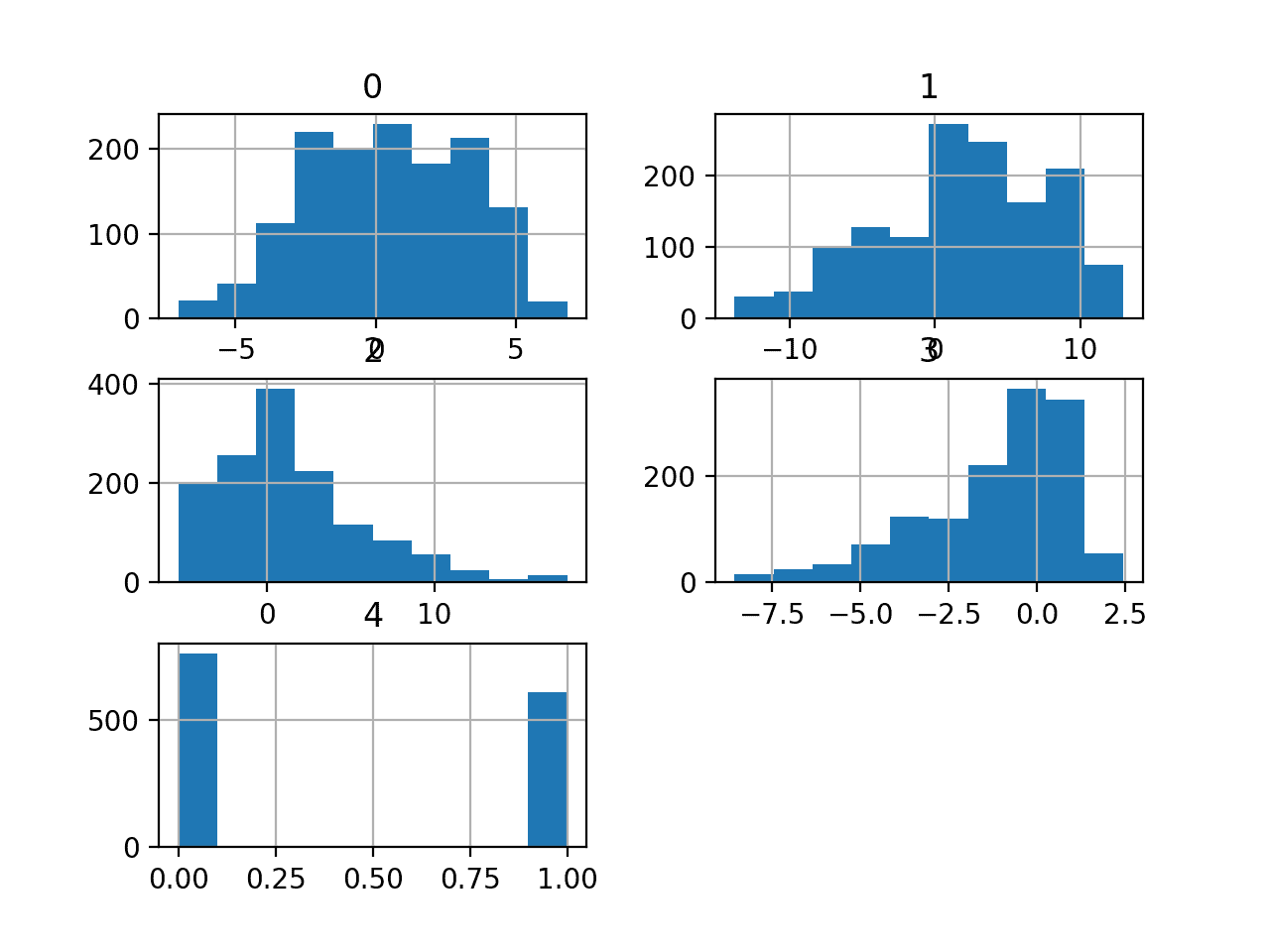
纸币分类数据集的直方图
现在我们熟悉了数据集,让我们探索一下如何开发神经网络。
神经网络学习动态
我们将使用 TensorFlow 为数据集开发多层感知机 (MLP) 模型。
我们无法知道什么模型架构或学习超参数最适合这个数据集,因此我们必须进行实验和探索,找出有效的方法。
考虑到数据集很小,使用小型批次大小可能是个好主意,例如 16 或 32 行。当开始时,使用 Adam 版本的随机梯度下降是个好主意,因为它会自动调整学习率,并且在大多数数据集上效果都很好。
在我们认真评估模型之前,最好回顾学习动态并调整模型架构和学习配置,直到我们获得稳定的学习动态,然后再考虑如何充分利用模型。
我们可以通过使用简单的数据训练/测试分割并回顾 学习曲线图来做到这一点。这将帮助我们看到是否出现过拟合或欠拟合;然后我们可以相应地调整配置。
首先,我们必须确保所有输入变量都是浮点值,并将目标标签编码为整数值 0 和 1。
|
1 2 3 4 5 |
... # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 y = LabelEncoder().fit_transform(y) |
接下来,我们可以将数据集分割为输入和输出变量,然后分割为 67/33 的训练集和测试集。
|
1 2 3 4 5 |
... # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) |
我们可以定义一个最小的 MLP 模型。在此案例中,我们将使用一个具有 10 个节点的隐藏层和一个输出层(任意选择)。我们将在隐藏层中使用 ReLU 激活函数和“he_normal”权重初始化,因为它们结合起来是很好的实践。
模型的输出是用于二分类的 sigmoid 激活,我们将最小化二元交叉熵损失。
|
1 2 3 4 5 6 7 8 9 |
... # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') |
我们将模型训练 50 个 epoch(任意选择),批次大小为 32,因为这是一个小型数据集。
我们使用原始数据来拟合模型,我们认为这可能是个好主意,但这只是一个重要的起点。
|
1 2 3 |
... # 拟合模型 history = model.fit(X_train, y_train, epochs=50, batch_size=32, verbose=0, validation_data=(X_test,y_test)) |
训练结束后,我们将评估模型在测试集上的性能,并报告分类准确率作为性能指标。
|
1 2 3 4 5 6 7 |
... # 预测测试集并转换为类别标签 ypred = model.predict(X_test) yhat = (ypred > 0.5).flatten().astype(int) # 评估预测 score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) |
最后,我们将绘制训练过程中训练集和测试集上交叉熵损失的学习曲线。
|
1 2 3 4 5 6 7 8 9 |
... # 绘制学习曲线 pyplot.title('学习曲线') pyplot.xlabel('Epoch') pyplot.ylabel('交叉熵') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='val') pyplot.legend() pyplot.show() |
总而言之,下面列出了在纸币数据集上评估第一个 MLP 的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# 在纸币上拟合一个简单的 MLP 模型并查看学习曲线 from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.metrics import accuracy_score from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from matplotlib import pyplot # 加载数据集 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv' df = read_csv(path, header=None) # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 y = LabelEncoder().fit_transform(y) # 分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') # 拟合模型 history = model.fit(X_train, y_train, epochs=50, batch_size=32, verbose=0, validation_data=(X_test,y_test)) # 预测测试集并转换为类别标签 ypred = model.predict(X_test) yhat = (ypred > 0.5).flatten().astype(int) # 评估预测 score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) # 绘制学习曲线 pyplot.title('学习曲线') pyplot.xlabel('Epoch') pyplot.ylabel('交叉熵') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='val') pyplot.legend() pyplot.show() |
运行示例首先在训练数据集上拟合模型,然后报告测试数据集上的分类准确率。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的 结果可能有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型达到了 100% 的准确率。这可能表明预测问题很简单,并且/或者神经网络非常适合该问题。
|
1 |
Accuracy: 1.000 |
然后创建训练集和测试集上损失的学习曲线图。
我们可以看到模型似乎收敛良好,并且没有显示出任何过拟合或欠拟合的迹象。
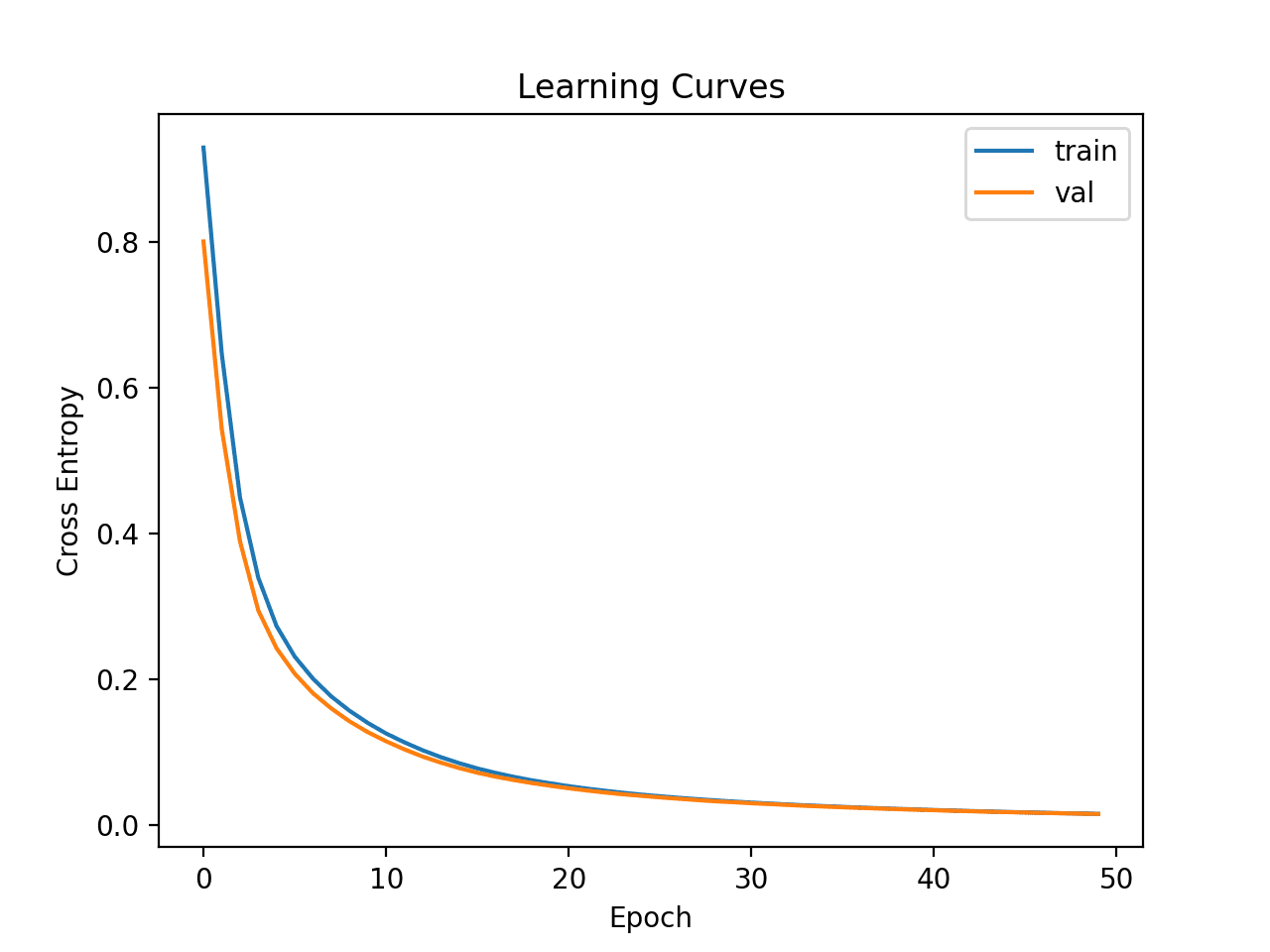
基于纸币数据集的简单多层感知机的学习曲线
我们第一次尝试就做得非常出色。
现在我们对简单 MLP 模型在数据集上的学习动态有了一些了解,我们可以着手开发更稳健的模型性能评估。
稳健的模型评估
k 折交叉验证过程可以提供更可靠的 MLP 性能估计,尽管它可能非常耗时。
这是因为必须拟合和评估 k 个模型。当数据集大小较小(例如纸币数据集)时,这不是问题。
我们可以使用 StratifiedKFold 类并手动枚举每个折叠,拟合模型,评估它,然后在过程结束时报告评估分数的平均值。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 准备交叉验证 kfold = KFold(10) # 枚举划分 scores = list() for train_ix, test_ix in kfold.split(X, y): # 拟合和评估模型... ... ... # 汇总所有分数 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
我们可以使用这个框架来为基础配置开发可靠的 MLP 模型性能估计,甚至可以针对一系列不同的数据准备、模型架构和学习配置进行评估。
在开始使用 k 折交叉验证 来估计性能之前,在上一节中首先了解模型在数据集上的学习动态是很重要的。如果我们直接开始调整模型,我们可能会得到不错的结果,但如果没有,我们可能不知道原因,例如模型是过拟合还是欠拟合。
如果我们再次对模型进行大的更改,最好回到并确认模型正在正确收敛。
下面列出了使用此框架评估上一节中基础 MLP 模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 基础模型在纸币数据集上的 k 折交叉验证 from numpy import mean from numpy import std from pandas import read_csv from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder from sklearn.metrics import accuracy_score from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from matplotlib import pyplot # 加载数据集 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv' df = read_csv(path, header=None) # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 y = LabelEncoder().fit_transform(y) # 准备交叉验证 kfold = StratifiedKFold(10) # 枚举划分 scores = list() for train_ix, test_ix in kfold.split(X, y): # 分割数据 X_train, X_test, y_train, y_test = X[train_ix], X[test_ix], y[train_ix], y[test_ix] # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') # 拟合模型 model.fit(X_train, y_train, epochs=50, batch_size=32, verbose=0) # 预测测试集并转换为类别标签 ypred = model.predict(X_test) yhat = (ypred > 0.5).flatten().astype(int) # 评估预测结果 score = accuracy_score(y_test, yhat) print('>%.3f' % score) scores.append(score) # 汇总所有分数 print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
运行示例将报告每次评估过程的模型的性能,并在运行结束时报告分类准确率的平均值和标准差。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的 结果可能有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到 MLP 模型达到了约 99.9% 的平均准确率。
这证实了我们关于基础模型配置在此数据集上效果极佳的预期,并且该模型确实很适合这个问题,甚至可能这个问题非常容易解决。
这出乎我的意料,因为我本来预期需要进行一些数据缩放,甚至可能需要进行幂变换。
|
1 2 3 4 5 6 7 8 9 10 11 |
>1.000 >1.000 >1.000 >1.000 >0.993 >1.000 >1.000 >1.000 >1.000 >1.000 Mean Accuracy: 0.999 (0.002) |
接下来,我们看看如何拟合最终模型并使用它来做出预测。
最终模型及预测
选择模型配置后,我们可以使用所有可用数据训练最终模型,并用它来对新数据进行预测。
在此案例中,我们将使用带有 dropout 和小型批次大小的模型作为我们的最终模型。
我们可以像以前一样准备数据并拟合模型,但这次是在整个数据集上,而不是在一个训练子集上。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
... # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 le = LabelEncoder() y = le.fit_transform(y) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') |
然后,我们可以使用此模型对新数据进行预测。
首先,我们可以定义一个新数据行。
|
1 2 3 |
... # 定义一行新数据 row = [3.6216,8.6661,-2.8073,-0.44699] |
注意:我从数据集中取了第一行,期望的标签是 '0'。
然后我们可以进行预测。
|
1 2 3 4 |
... # 进行预测并转换为类别标签 ypred = model.predict([row]) yhat = (ypred > 0.5).flatten().astype(int) |
然后对预测结果进行逆变换,以便我们可以使用或解释正确标签下的结果(对于此数据集,它只是一个整数)。
|
1 2 3 |
... # 逆变换以获得类别标签 yhat = le.inverse_transform(yhat) |
在这种情况下,我们将只报告预测结果。
|
1 2 3 |
... # 报告预测结果 print('Predicted: %s' % (yhat[0])) |
总而言之,下面列出了拟合最终模型以用于纸币数据集并使用它对新数据进行预测的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# 拟合最终模型并对纸币数据集的新数据进行预测 from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.metrics import accuracy_score from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout # 加载数据集 path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv' df = read_csv(path, header=None) # 分割成输入和输出列 X, y = df.values[:, :-1], df.values[:, -1] # 确保所有数据都是浮点值 X = X.astype('float32') # 将字符串编码为整数 le = LabelEncoder() y = le.fit_transform(y) # 确定输入特征的数量 n_features = X.shape[1] # 定义模型 model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy') # 拟合模型 model.fit(X, y, epochs=50, batch_size=32, verbose=0) # 定义一行新数据 row = [3.6216,8.6661,-2.8073,-0.44699] # 进行预测并转换为类别标签 ypred = model.predict([row]) yhat = (ypred > 0.5).flatten().astype(int) # 逆变换以获得类别标签 yhat = le.inverse_transform(yhat) # 报告预测结果 print('Predicted: %s' % (yhat[0])) |
运行示例会将模型拟合到整个数据集,并为新数据的单行进行预测。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的 结果可能有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到模型为输入行预测了“0”标签。
|
1 |
预测:0.0 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
总结
在本教程中,您学习了如何为纸币二元分类数据集开发多层感知器神经网络模型。
具体来说,你学到了:
- 如何加载和汇总纸币数据集,并利用结果来建议数据准备和模型配置。
- 如何探索简单MLP模型在数据集上的学习动态。
- 如何开发模型性能的稳健估计,调整模型性能并对新数据进行预测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。






谢谢……
不客气。
尊敬的Jason博士,
再次感谢您的教程。
问题是关于测试和验证数据的学习曲线,以及模型是拟合还是过拟合。
当测试和验证数据的学习曲线合并时,模型是否拟合?如果曲线不合并,它们是过拟合还是欠拟合?
谢谢你,
悉尼的Anthony
这可以帮助您解读学习曲线
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
尊敬的Jason博士,
再次感谢。我看到了引用的文档 https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/ 。
在欠拟合、过拟合、正确拟合和无代表性的示例中,Y 轴和 X 轴的标签是什么?X 是轮次或迭代次数,而 Y 是熵吗?
谢谢你,
悉尼的Anthony
在学习曲线图中,x 轴是学习迭代(通常是轮次,有时是批次),y 轴是损失。
尊敬的Jason博士,
谢谢你,
悉尼的Anthony
不客气。
好帖子
Aymeric inpong
谢谢!
AttributeError: ‘Sequential’ 对象没有属性 ‘predict_classes’
这是由于 keras 的版本更改。尝试使用 predict,然后使用 numpy.argmax() 来查找类。
ValueError: 分类指标无法处理二元和连续目标值的混合
这个错误从哪里来?
您将如何从图像中提取这 4 个特征?
嗨 Max……您可能会发现以下内容有帮助
https://vitalflux.com/machine-learning-feature-selection-feature-extraction/