传统的神经网络模型称为多层感知器。它们通常由一系列相互连接的层组成。输入层是数据进入网络的入口,输出层是网络输出结果的地方。
输入层通常连接到一个或多个隐藏层,这些隐藏层在数据到达输出层之前对其进行修改和处理。隐藏层是使神经网络如此强大的原因:它们可以学习复杂的函数,而这些函数可能很难由程序员在代码中指定。
在上一个教程中,我们构建了一个只有几个隐藏神经元的神经网络。在这里,您将通过向其中添加更多隐藏神经元来构建一个神经网络。这将为我们估计更复杂的函数以拟合数据。
在实现过程中,您将学到:
- 如何在 PyTorch 中构建具有更多隐藏神经元的神经网络。
- 如何通过向网络添加更多隐藏神经元来使用神经网络估计复杂函数。
- 如何在 PyTorch 中训练神经网络。
通过我的《用PyTorch进行深度学习》一书来启动你的项目。它提供了包含可用代码的自学教程。
让我们开始吧。

拥有更多隐藏神经元的神经网络。
图片来自 Kdwk Leung。部分权利保留。
概述
本教程分为三个部分;它们是
- 准备数据
- 构建模型架构
- 训练模型
准备数据
让我们构建一个 `Data` 类,它继承自 PyTorch 的 `Dataset` 类。您可以使用它来创建包含 100 个介于 -50 到 50 之间的合成值的数据集。 `x` 张量存储指定范围内的值,而 `y` 张量是具有与 `x` 相同形状的对应零张量。
接下来,您将使用一个 for 循环,根据 `x` 中的值来设置 `x` 和 `y` 张量中的值。如果 `x` 中的一个值在 -20 和 20 之间,则 `y` 中的相应值设置为 1;如果 `x` 中的一个值在 -30 和 -20 之间,或者在 20 和 30 之间,则 `y` 中的相应值设置为 0。同样,如果 `x` 中的一个值在 -40 和 -30 之间,或者在 30 和 40 之间,则 `y` 中的相应值设置为 1。否则,`y` 中的相应值设置为 0。
在 `Data` 类中,`__getitem__()` 方法用于检索数据集中指定索引处的 `x` 和 `y` 值。`__len__()` 方法返回数据集的长度。使用它们,您可以通过 `data[i]` 从数据集中获取一个样本,并通过 `len(data)` 获取数据集的大小。此类可用于创建可以传递给 PyTorch 数据加载器来训练机器学习模型的数据对象。
请注意,我们正在构建这个复杂的数据对象,以查看我们的具有更多隐藏神经元的神经网络对函数的估计效果如何。数据对象的代码如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import torch from torch.utils.data import Dataset, DataLoader class Data(Dataset): def __init__(self): # 创建一个包含 100 个从 -50 到 50 的值的张量 self.x = torch.zeros(100, 1) # 创建一个形状与 x 相同的零张量 self.y = torch.zeros(self.x.shape) # 使用 for 循环设置 x 和 y 的值 for i in range(100): self.x[i] = -50 + i if self.x[i,0] > -20 and self.x[i,0] < 20: self.y[i] = 1 elif (self.x[i,0] > -30 and self.x[i,0] < -20) or (self.x[i,0] > 20 and self.x[i,0] < 30): self.y[i] = 0 self.y[i] = 1 self.y[i] = 1 else: self.y[i] = 0 # 存储数据集长度 self.len = self.x.shape[0] def __getitem__(self, index): # 返回指定索引处的 x 和 y 值 return self.x[index], self.y[index] def __len__(self): # 返回数据集长度 return self.len |
实例化一个数据对象。
|
1 2 |
# 创建 Data 对象 dataset = Data() |
并编写一个函数来可视化此数据,该函数在稍后训练模型时也很有用。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import pandas as pd import matplotlib.pyplot as plt def plot_data(X, Y, model=None, leg=False): # 从 Data 对象中获取 x 和 y 值 x = dataset.x y = dataset.y # 将 x 和 y 值转换为带有索引的 Pandas Series x = pd.Series(x[:, 0], index=range(len(x))) y = pd.Series(y[:, 0], index=range(len(y))) # 绘制 x 和 y 值的散点图,根据标签为点着色 plt.scatter(x, y, c=y) if model!=None: plt.plot(X.numpy(), model(X).detach().numpy(), label='神经网络') # 显示图表 plt.show() |
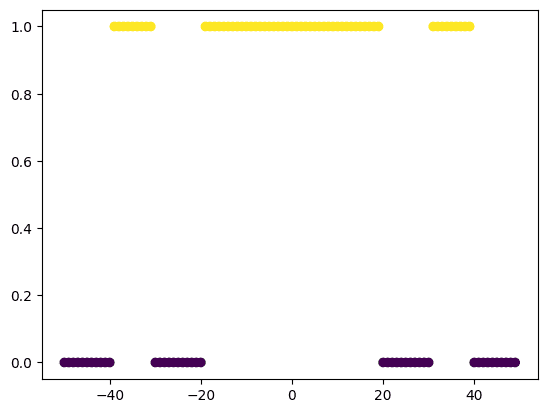
运行此函数后,您可以看到数据如下图所示。
|
1 |
plot_data(dataset.x, dataset.y, leg=False) |
想开始使用PyTorch进行深度学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
构建模型架构
下面,您将定义一个 `NeuralNetwork` 类,使用 PyTorch 的 `nn.Module` 来构建自定义模型架构。此类代表一个简单的神经网络,包含输入层、隐藏层和输出层。
`__init__()` 方法用于通过定义网络中的层来初始化神经网络。forward 方法用于定义通过网络的正向传播。在这种情况下,对输入层和输出层都应用了 sigmoid 激活函数。这意味着网络的输出将是 0 到 1 之间的值。
最后,您将创建一个 `NeuralNetwork` 类的实例并将其存储在 `model` 变量中。该模型初始化为具有 1 个输入神经元的输入层、15 个隐藏神经元的隐藏层和 1 个输出神经元的输出层。该模型现在已准备好在某些数据上进行训练。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import torch.nn as nn # 定义神经网络 class NeuralNetwork(nn.Module): def __init__(self, input_size, hidden_size, output_size): super().__init__() # 定义神经网络中的层 self.input_layer = nn.Linear(input_size, hidden_size) self.output_layer = nn.Linear(hidden_size, output_size) def forward(self, x): # 定义网络前向传播 x = torch.sigmoid(self.input_layer(x)) x = torch.sigmoid(self.output_layer(x)) return x # 初始化神经网络 model = NeuralNetwork(input_size=1, hidden_size=20, output_size=1) |
训练模型
让我们定义损失函数、优化器和数据加载器。由于数据集是二分类问题,因此应使用二元交叉熵损失。使用 Adam 优化器,批次大小为 32。学习率设置为 0.01,它决定了在训练期间如何更新模型权重。损失函数用于评估模型性能,优化器用于更新权重,数据加载器将数据分成批次以进行有效处理。
|
1 2 3 4 |
learning_rate = 0.01 criterion = nn.BCELoss() optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) data_loader = DataLoader(dataset=dataset, batch_size=32) |
现在,让我们构建一个为期 7000 个 epoch 的训练循环,并在训练期间可视化结果。您将看到随着训练的进行,我们的模型如何很好地估计数据点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
n_epochs = 7000 # 训练模型的 epoch 数量 LOSS = [] # 用于存储每个 epoch 后损失值的列表 # 训练模型 n_epochs 次 for epoch in range(n_epochs): total = 0 # 用于存储此 epoch 总损失的变量 # 遍历数据加载器中的数据 for x, y in data_loader: # 清零模型梯度 optimizer.zero_grad() # 使用模型进行预测 yhat = model(x) # 计算预测值与真实值之间的损失 loss = criterion(yhat, y) # 计算模型相对于损失的梯度 loss.backward() # 更新模型参数 optimizer.step() # 将损失值添加到此 epoch 的总损失中 total += loss.item() # 每个 epoch 后,检查 epoch 号是否能被 200 整除 if epoch % 1000 == 0: # 如果是,则使用 PlotData 函数绘制当前数据和模型 plot_data(dataset.x, dataset.y, model) # 打印当前损失 print(f"已完成 Epoch: {epoch+1}/{n_epochs}, Loss: {loss.item():.4f}") # 将此 epoch 的总损失添加到 LOSS 列表中 LOSS.append(total) |
当您运行此循环时,您会发现在第一个 epoch,神经网络对数据集的建模效果很差,如下图所示: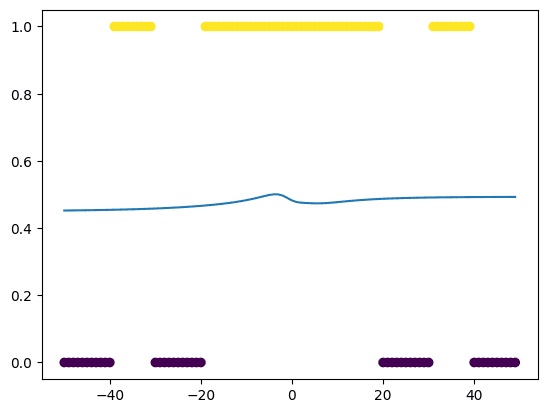
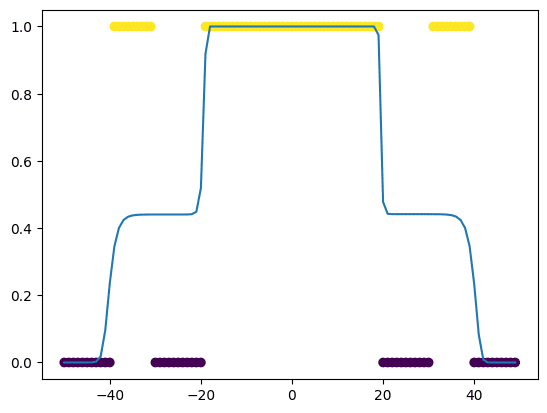
但随着训练的进行,准确率有所提高。训练循环完成后,我们可以看到结果,神经网络对数据的建模如下所示:
|
1 2 |
# 训练循环结束后绘制 plot_data(dataset.x, dataset.y, model) |
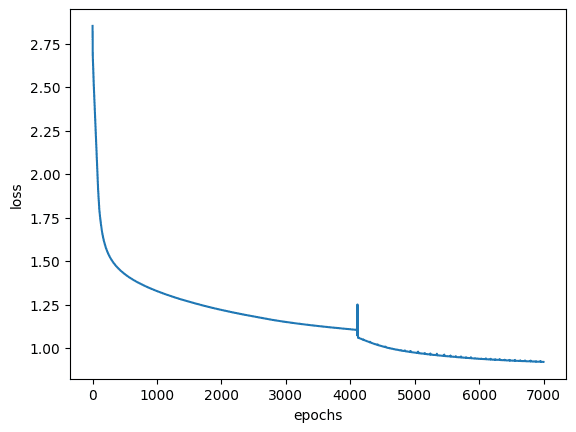
以及相应的损失度量历史记录可以绘制如下:
|
1 2 3 4 5 6 7 |
# 绘制每个 epoch 的损失图 plt.figure() plt.plot(LOSS) plt.xlabel('epochs') plt.ylabel('loss') # 显示绘图 plt.show() |
正如你所见,我们的模型相当好地估计了该函数,但并非完美。例如,20到40范围内的输入预测得并不准确。你可以尝试扩展网络,添加一个额外的层,例如下面这样,看看是否会有所不同。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 定义神经网络 class NeuralNetwork(nn.Module): def __init__(self, input_size, hidden1_size, hidden2_size, output_size): super(NeuralNetwork, self).__init__() # 定义神经网络中的层 self.layer1 = nn.Linear(input_size, hidden1_size) self.layer2 = nn.Linear(hidden1_size, hidden2_size) self.output_layer = nn.Linear(hidden2_size, output_size) def forward(self, x): # 定义网络前向传播 x = torch.sigmoid(self.layer1(x)) x = torch.sigmoid(self.layer2(x)) x = torch.sigmoid(self.output_layer(x)) return x # 初始化神经网络 model = NeuralNetwork(input_size=1, hidden1_size=10, hidden2_size=10, output_size=1) |
把所有东西放在一起,下面是完整的代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 |
import torch.nn as nn import pandas as pd import matplotlib.pyplot as plt import torch from torch.utils.data import Dataset, DataLoader class Data(Dataset): def __init__(self): # 创建一个包含 100 个从 -50 到 50 的值的张量 self.x = torch.zeros(100, 1) # 创建一个形状与 x 相同的零张量 self.y = torch.zeros(self.x.shape) # 使用 for 循环设置 x 和 y 的值 for i in range(100): self.x[i] = -50 + i if self.x[i,0] > -20 and self.x[i,0] < 20: self.y[i] = 1 elif (self.x[i,0] > -30 and self.x[i,0] < -20) or (self.x[i,0] > 20 and self.x[i,0] < 30): self.y[i] = 0 self.y[i] = 1 self.y[i] = 1 else: self.y[i] = 0 # 存储数据集长度 self.len = self.x.shape[0] def __getitem__(self, index): # 返回指定索引处的 x 和 y 值 return self.x[index], self.y[index] def __len__(self): # 返回数据集长度 return self.len # 创建 Data 对象 dataset = Data() def plot_data(X, Y, model=None, leg=False): # 从 Data 对象中获取 x 和 y 值 x = dataset.x y = dataset.y # 将 x 和 y 值转换为带有索引的 Pandas Series x = pd.Series(x[:, 0], index=range(len(x))) y = pd.Series(y[:, 0], index=range(len(y))) # 绘制 x 和 y 值的散点图,根据标签为点着色 plt.scatter(x, y, c=y) if model!=None: plt.plot(X.numpy(), model(X).detach().numpy(), label='神经网络') # 显示图表 plt.show() # 定义神经网络 class NeuralNetwork(nn.Module): def __init__(self, input_size, hidden_size, output_size): super().__init__() # 定义神经网络中的层 self.input_layer = nn.Linear(input_size, hidden_size) self.output_layer = nn.Linear(hidden_size, output_size) def forward(self, x): # 定义网络前向传播 x = torch.sigmoid(self.input_layer(x)) x = torch.sigmoid(self.output_layer(x)) return x # 初始化神经网络 model = NeuralNetwork(input_size=1, hidden_size=20, output_size=1) learning_rate = 0.01 criterion = nn.BCELoss() optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) data_loader = DataLoader(dataset=dataset, batch_size=32) n_epochs = 7000 # 训练模型的 epoch 数量 LOSS = [] # 用于存储每个 epoch 后损失值的列表 # 训练模型 n_epochs 次 for epoch in range(n_epochs): total = 0 # 用于存储此 epoch 总损失的变量 # 遍历数据加载器中的数据 for x, y in data_loader: # 清零模型梯度 optimizer.zero_grad() # 使用模型进行预测 yhat = model(x) # 计算预测值与真实值之间的损失 loss = criterion(yhat, y) # 计算模型相对于损失的梯度 loss.backward() # 更新模型参数 optimizer.step() # 将损失值添加到此 epoch 的总损失中 total += loss.item() # 每个 epoch 后,检查 epoch 号是否能被 200 整除 if epoch % 1000 == 0: # 如果是,则使用 PlotData 函数绘制当前数据和模型 plot_data(dataset.x, dataset.y, model) # 打印当前损失 print(f"已完成 Epoch: {epoch+1}/{n_epochs}, Loss: {loss.item():.4f}") # 将此 epoch 的总损失添加到 LOSS 列表中 LOSS.append(total) plot_data(dataset.x, dataset.y, model) # 绘制每个 epoch 的损失图 plt.figure() plt.plot(LOSS) plt.xlabel('epochs') plt.ylabel('loss') # 显示绘图 plt.show() |
总结
在本教程中,您学习了如何通过在神经网络中引入更多神经元来估计复杂函数。特别是,您学习了
- 如何在 PyTorch 中构建具有更多隐藏神经元的神经网络。
- 如何通过向网络添加更多隐藏神经元来使用神经网络估计复杂函数。
- 如何在 PyTorch 中训练神经网络。
开始使用PyTorch进行深度学习!

学习如何构建深度学习模型
...使用新发布的PyTorch 2.0库
在我的新电子书中探索如何实现
使用 PyTorch进行深度学习
它提供了包含数百个可用代码的自学教程,让你从新手变成专家。它将使你掌握:
张量操作、训练、评估、超参数优化等等...






如何选择隐藏层的数量?