人工神经网络是一个引人入胜的研究领域,尽管初学者可能会觉得它令人生畏。
在描述该领域使用的数据结构和算法时,会用到许多专业术语。
在这篇文章中,您将快速了解多层感知器人工神经网络领域中使用的术语和过程。阅读本文后,您将了解:
- 神经网络的构建模块,包括神经元、权重和激活函数
- 如何利用这些构建模块在层中创建网络
- 如何从示例数据训练网络
通过我的新书《使用Python进行深度学习》来启动您的项目,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

神经网络速成班
照片由Joe Stump拍摄,保留部分权利。
速成班概览
本文将快速涵盖大量内容。以下是即将介绍的内容:
- 多层感知器
- 神经元、权重和激活
- 神经元网络
- 训练网络
让我们首先概述多层感知器。
1. 多层感知器
人工神经网络领域通常被称为神经网络或多层感知器,因为它们可能是最有用的神经网络类型。感知器是一种单一神经元模型,是更大规模神经网络的先驱。
这是一个研究如何使用生物大脑的简单模型来解决困难计算任务的领域,例如我们在机器学习中看到的预测建模任务。目标不是创建逼真的大脑模型,而是开发我们可以用来建模困难问题的鲁棒算法和数据结构。
神经网络的强大之处在于它们能够学习训练数据中的表示,以及如何最好地将其与您想要预测的输出变量相关联。从这个意义上说,神经网络学习映射。从数学上讲,它们能够学习任何映射函数,并已被证明是一种通用近似算法。
神经网络的预测能力来自于网络的层次或多层结构。数据结构可以提取(学习表示)不同尺度或分辨率的特征,并将它们组合成更高阶的特征,例如,从线条到线条集合再到形状。
2. 神经元
神经网络的构建块是人工神经元。
这些是简单的计算单元,具有加权输入信号,并使用激活函数产生输出信号。
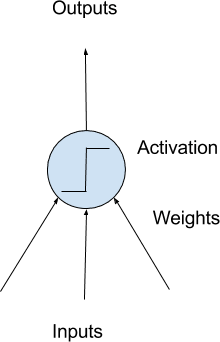
简单神经元模型
神经元权重
您可能熟悉线性回归,其中输入上的权重非常类似于回归方程中使用的系数。
与线性回归一样,每个神经元也有一个偏置,可以将其视为一个始终具有值1.0的输入,它也必须被加权。
例如,一个神经元可能有两个输入,这需要三个权重——一个用于每个输入,一个用于偏置。
权重通常初始化为小的随机值,例如0到0.3之间的值,尽管可以使用更复杂的初始化方案。
与线性回归一样,较大的权重表示复杂性和脆弱性增加。保持网络中的权重是可取的,并且可以使用正则化技术。
激活
加权输入求和并通过激活函数,有时称为传输函数。
激活函数是将加权输入求和简单映射到神经元输出的函数。它被称为激活函数,因为它控制神经元被激活的阈值和输出信号的强度。
历史上,当求和输入超过0.5的阈值时,例如,使用简单的阶跃激活函数。然后神经元将输出值1.0;否则,它将输出0.0。
传统上,使用非线性激活函数。这使得网络能够以更复杂的方式组合输入,进而提供更丰富的功能建模能力。诸如逻辑函数(也称为sigmoid函数)之类的非线性函数被用于输出0到1之间的值,并具有S形分布。双曲正切函数(也称为tanh)在-1到+1的范围内输出相同的分布。
最近,修正线性单元(ReLU)激活函数已被证明能提供更好的结果。
3. 神经元网络
神经元被组织成神经元网络。
一排神经元被称为一层,一个网络可以有多个层。网络中神经元的架构通常被称为网络拓扑。
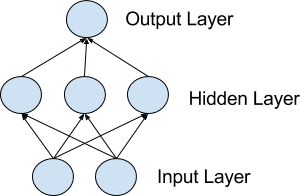
简单网络模型
输入层或可见层
从数据集获取输入的底层被称为可见层,因为它是网络的暴露部分。通常,神经网络的可见层会绘制成每个输入值或数据集中的列对应一个神经元。这些不是上述描述的神经元,它们只是将输入值传递给下一层。
隐藏层
输入层之后的层称为隐藏层,因为它们不直接暴露于输入。最简单的网络结构是在隐藏层中有一个单一的神经元,直接输出值。
随着计算能力的提高和高效库的出现,可以构建非常深的神经网络。深度学习可以指神经网络中拥有许多隐藏层。它们之所以深,是因为在历史上训练它们的速度是不可想象的慢,但使用现代技术和硬件可能只需几秒或几分钟即可训练。
输出层
最后一个隐藏层称为输出层,它负责输出一个值或值向量,该值或向量与问题所需的格式相对应。
输出层中激活函数的选择受到您正在建模的问题类型的强烈限制。例如:
- 回归问题可能有一个输出神经元,该神经元可能没有激活函数。
- 二元分类问题可能有一个输出神经元,并使用 Sigmoid 激活函数输出一个介于 0 和 1 之间的值,以表示预测类别 1 的概率。这可以通过使用 0.5 的阈值将值转换为清晰的类别值:小于阈值的值为 0,否则为 1。
- 多类分类问题可能在输出层有多个神经元,每个类一个(例如,著名的鸢尾花分类问题中有三个类,对应三个神经元)。在这种情况下,可以使用 Softmax 激活函数输出网络预测每个类值的概率。选择概率最高的输出可以产生清晰的类分类值。
4. 训练网络
配置完成后,神经网络需要根据您的数据集进行训练。
数据准备
您必须首先为神经网络训练准备数据。
数据必须是数值型,例如实数值。如果您有分类数据,例如具有“男性”和“女性”值的性别属性,您可以将其转换为称为one-hot编码的实数值表示。这意味着为每个类别值添加一个新列(在性别为男性和女性的情况下为两列),并根据该行的类别值添加0或1。
在分类问题中,如果有一个以上的类别,也可以对输出变量使用相同的独热编码。这将从一个单列创建一个二进制向量,可以很容易地直接与网络输出层中神经元的输出进行比较。如上所述,这将为每个类别输出一个值。
神经网络要求输入以一致的方式进行缩放。您可以将其重新缩放至0到1的范围,这称为归一化。另一种流行的技术是将其标准化,使每列的分布平均值为零,标准差为1。
缩放也适用于图像像素数据。文字等数据可以转换为整数,例如单词在数据集中的流行度排名,以及其他编码技术。
随机梯度下降
经典的、仍然受青睐的神经网络训练算法称为随机梯度下降。
这是指一次将一行数据作为输入暴露给网络。网络向上处理输入,激活神经元,最终产生一个输出值。这称为网络的正向传播。它也是在网络训练完成后用于对新数据进行预测的传播类型。
网络输出与预期输出进行比较,并计算误差。然后,此误差通过网络逐层反向传播,并根据它们对误差的贡献量更新权重。这种巧妙的数学方法称为反向传播算法。
这个过程会针对训练数据中的所有示例重复进行。对整个训练数据集更新网络一轮称为一个时期(epoch)。一个网络可能会训练数十、数百甚至数千个时期。
权重更新
网络中的权重可以根据每个训练样本计算的误差进行更新,这称为在线学习。它可能导致网络快速但混乱的变化。
或者,可以将所有训练样本的误差保存下来,并在最后更新网络。这称为批量学习,通常更稳定。
通常,由于数据集庞大且计算效率的原因,批次大小(在更新之前展示给网络的样本数量)通常会减少到一个较小的数字,例如数十或数百个样本。
权重的更新量由一个称为学习率的配置参数控制。它也被称为步长,控制着给定误差对网络权重所做的步长或改变。通常使用较小的权重大小,例如0.1或0.01或更小。
更新方程可以补充您可设置的额外配置项。
- 动量是一个项,它结合了先前权重更新的属性,允许权重即使在计算出的误差较小的情况下也能继续沿同一方向变化。
- 学习率衰减用于在训练周期中降低学习率,以允许网络在训练开始时对权重进行大幅度更改,并在训练计划后期进行较小的微调更改。
预测
一旦神经网络经过训练,就可以用于进行预测。
您可以对测试或验证数据进行预测,以评估模型在未见过数据上的技能。您还可以将其投入实际运行并持续进行预测。
网络拓扑和最终的权重集是您需要从模型中保存的所有内容。通过向网络提供输入并执行前向传播来进行预测,从而生成您可以作为预测使用的输出。
Python 深度学习需要帮助吗?
参加我的免费为期两周的电子邮件课程,发现 MLP、CNN 和 LSTM(附代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
更多资源
关于人工神经网络的主题有数十年的论文和书籍。
如果您是该领域的新手,请查阅以下资源作为进一步阅读:
总结
在这篇文章中,您了解了用于机器学习的人工神经网络。
阅读本文后,您现在知道了:
- 神经网络并非大脑模型,而是用于解决复杂机器学习问题的计算模型
- 神经网络由具有权重和激活函数的神经元组成
- 网络被组织成神经元层,并使用随机梯度下降进行训练
- 在训练神经网络模型之前,最好先准备好数据。
您对神经网络或本文有任何疑问吗?请在评论中提出您的问题,我将尽力回答。






这是一篇不错的文章,但有一些错别字需要更正。感谢您的时间。
谢谢,哪些错别字?
感谢您的文章,非常容易理解。我同意错别字,它们在您关于时期的陈述和其他地方。
谢谢。
很棒的文章!我正在上数据科学课,这篇文章让我明白了这个问题!谢谢!
很高兴它有帮助。
嗨,Jason;
CNN、RNN 和 MLP 是监督学习还是无监督学习方法?请说明每种情况下使用哪种。
此致
它们都是监督学习。
这是一篇很棒的文章,我在大学里学习大数据,这篇文章概括地让我明白了许多。
谢谢,很高兴对您有帮助。
我想说,读了这篇文章后,我的深度学习训练是反向传播加上随机梯度下降的。
我之前的所有阅读和训练,在阅读了这篇最先进、易于理解的文章后,都变得更加清晰。
谢谢,丹尼斯。
感谢您的这篇文章@Jason。非常有用 :D。
我有一个问题,谢谢。
既然MLP可以有很多隐藏层,那么MLP和DNN有什么区别呢?或者它们是同一枚硬币的两面?!
哦,我刚刚意识到MLP是DNN中的一种架构。
谢谢你:)。
DNN是具有许多层的MLP。实际上是一回事,只是营销上的不同。
亲爱的杰森,这篇文章很棒,解释也很清楚!关于数据输入,我有两个问题。您提到“性别”等特征应该进行独热编码,这样您就得到了两列性别而不是一列。然后您提到特征需要进行缩放或标准化。您需要在独热编码的分类特征上进行这种缩放吗?还是只在连续特征上进行?
谢谢,
戴夫
一、独热编码的特征可以直接使用。
嗨
我有与此主题相关的问题
我开始阅读有关深度学习和文本分类方法的博客和科学论文
我正在努力区分 1-DNN 和 2-浅层神经网络以及 3-MLP
它们之间有什么区别,其中哪些被认为是深度学习算法或架构?
它们都是一样的,深度只是指更多的层。
亲爱的 Jason,
所有方法都在谈论“隐藏层”,请稍微关注一下。
谨致,
Ankit
隐藏层是指所有不用于模型输入或输出的层。
如果隐藏层不用于模型的输入或输出,那么它们在进行任何模型时重要吗?如果重要,为什么重要?
是的。
它们提供了一种类似“抽象级别”的功能。所谓的“分层学习”。这是我们能说的最好的了——我们还没有很好的理论来解释这些东西。
亲爱的 Jason,
感谢这篇精彩的文章!但我还有一个问题。每次我在SPSS中运行MLP(我知道这不是最好的软件,但目前我只能用它)时,都会得到不同的结果。我知道这与随机数生成有关,如果我使用相同的初始值,我会得到相同的结果。但是,我想知道在选择最佳模型之前是否需要进行多次尝试?另外,平方误差和是判断哪个模型最好的好方法吗?在选择最佳模型之前,您应该运行MLP多少次?初始随机数是否由我选择重要吗?或者不重要?希望问题不会太多!提前感谢。
祝好!
是的,这是意料之中的。
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
对于MLP第03天
更多的层数和神经元数量可以提高性能。此外,似乎最小化“mae”比使用“adam”求解器最小化“mse”能获得更好的性能(尚不确定原因)。
# 单变量 MLP 示例
from numpy import array
来自 keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
# 定义数据集
X = np.array(input_df['x'].to_list())
y = np.array(input_df['y'].to_list())
x_train = X[:300]
x_test = X[300:]
y_train = y[:300]
y_test = y[300:]
# 定义模型
model = Sequential()
model.add(Dense(100, activation='relu', input_dim=4))
model.add(Dense(200, activation='relu', input_dim=4))
model.add(Dense(400, activation='relu', input_dim=4))
model.add(Dense(100, activation='relu', input_dim=4))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mae')
# 拟合模型
model.fit(X, y, epochs=3000, verbose=0)
# 演示预测
yhat = model.predict(x_test, verbose=0)
y_pred = yhat.flatten()
print ("平均绝对误差: %2f"%metrics.mean_absolute_error(y_test, y_pred))
plt.plot(y_test)
plt.plot(y_pred, color='r')
>> 平均绝对误差: 1.370448
干得好!
先生您好,您能告诉我们关于多热编码吗?
您是指独热编码吗?
如果是这样,请参阅此处:
https://machinelearning.org.cn/one-hot-encoding-for-categorical-data/
亲爱的 Jason,
感谢您的帖子。如果数据集有名义变量大约80%,我可以使用多层感知器神经网络吗?如果我将所有名义变量都更改为虚拟变量,使用多层感知器神经网络可以吗?
此致
我看不出为什么不行。但是您会看到多少对输出的影响是无法保证的。您应该进行实验并判断这是否是个好主意。
也许这些问题对于速成班来说不公平,但我很好奇。
1. 决定网络层数的因素有哪些?
2. 决定每层神经元数量的因素有哪些?
3. 自2011年以来,实践中是否总是使用修正线性单元(rectifier)激活函数,或者有哪些因素会指示使用双曲正切(hyperbolic tangent)或Sigmoid函数?
你好,Mark,
以下资源可能对您有所帮助
https://machinelearning.org.cn/how-to-configure-the-number-of-layers-and-nodes-in-a-neural-network/
https://machinelearning.org.cn/choose-an-activation-function-for-deep-learning/
为什么在数据准备部分没有提到标注(labelling)?
嗨 Nikhil…以下资源可能对您有所帮助
https://machinelearning.org.cn/start-here/#dataprep
感谢布朗利博士,感谢这篇有用的文章。
我有一个问题。
我用这个模型来预测学生的表现(一个简单的问题)。我该如何称呼它,以及这个模型的局限性是什么?
python
def create_model():
mlp = Sequential()
mlp.add(Dense(5, input_dim=5, activation='relu'))
mlp.add(Dense(1, activation='sigmoid'))
mlp.compile(loss='binary_crossentropy', optimizer=Adam())
return mlp
嗨,阿卜杜拉……您的模型目标是什么?也就是说,您具体在预测什么?这将有助于我们更好地指导您。