离群值或异常值是稀有的示例,与其余数据不符。
识别数据中的离群值被称为离群值或异常检测,而机器学习中专注于此问题的一个子领域被称为单类分类。这些是无监督学习算法,它们试图建模“正常”示例,以便将新示例分类为正常或异常(例如离群值)。
单类分类算法可用于具有严重倾斜类分布的二元分类任务。这些技术可以根据训练数据集中多数类的输入示例进行拟合,然后在保留测试数据集上进行评估。
尽管单类分类算法并非为此类问题设计,但对于少数类示例很少甚至没有,或者数据集没有连贯结构可以被监督算法学习以分离类的不平衡分类数据集,它们可以非常有效。
在本教程中,您将学习如何将单类分类算法用于具有严重倾斜类分布的数据集。
完成本教程后,您将了解:
- 单类分类是机器学习的一个领域,它提供用于离群值和异常检测的技术。
- 如何将单类分类算法应用于具有严重倾斜类分布的不平衡分类。
- 如何拟合和评估单类分类算法,例如SVM、孤立森林、椭圆包络和局部离群因子。
通过我的新书《使用 Python 进行不平衡分类》启动您的项目,其中包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。

不平衡分类的单类分类算法
图片由 Kosala Bandara 拍摄,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 不平衡数据的单类分类
- 单类支持向量机
- 孤立森林
- 最小协方差行列式
- 局部异常因子
不平衡数据的单类分类
离群值既罕见又异常。
稀有性表明它们相对于非离群数据(即正常数据)的频率较低。异常性表明它们不完全符合数据分布。
离群值的存在可能会导致问题。例如,单个变量可能有一个远离大多数示例的离群值,这会扭曲均值和方差等汇总统计数据。
拟合机器学习模型可能需要识别和删除离群值作为数据准备技术。
识别数据集中离群值的过程通常被称为异常检测,其中离群值是“异常”,其余数据是“正常”。离群值检测或异常检测是一个具有挑战性的问题,包含一系列技术。
在机器学习中,解决异常检测问题的一种方法是单类分类。
单类分类,简称 OCC,涉及在“正常”数据上拟合模型,并预测新数据是正常数据还是离群值/异常。
单类分类器旨在捕捉训练实例的特征,以便能够区分它们与可能出现的潜在离群值。
— 第 139 页,从不平衡数据集学习,2018 年。
单类分类器在仅包含正常类示例的训练数据集上进行拟合。准备好后,模型用于将新示例分类为正常或非正常,即离群值或异常。
单类分类技术可用于二元(两类)不平衡分类问题,其中负案例(类别 0)被视为“正常”,正案例(类别 1)被视为离群值或异常。
- 负案例:正常或内点。
- 正案例:异常或离群值。
鉴于这种方法的性质,单类分类最适合那些正例在特征空间中没有一致模式或结构的任务,使得其他分类算法难以学习类边界。相反,将正例视为离群值,它允许单类分类器忽略判别任务,而是专注于偏离正常或预期值的情况。
当少数类缺乏任何结构,主要由小的分离点或噪声实例组成时,此解决方案已被证明特别有用。
— 第 139 页,从不平衡数据集学习,2018 年。
当训练集中的正例数量非常少,以至于不值得包含在模型中时,例如几十个或更少的示例,或者在训练模型之前无法收集到正例时,此方法也可能适用。
需要明确的是,这种将单类分类算法用于不平衡分类的改编并不常见,但可以在某些问题上有效。这种方法的缺点是,我们在训练过程中拥有的任何离群值(正例)都不会被单类分类器使用并被丢弃。这表明也许可以并行尝试问题的逆向建模(例如,将正例建模为正常)。它还表明单类分类器可以为算法集成提供输入,其中每个算法都以不同的方式使用训练数据集。
必须记住,单类分类器的优势是以丢弃所有可用多数类信息为代价的。因此,此解决方案应谨慎使用,可能不适用于某些特定应用。
— 第 140 页,从不平衡数据集学习,2018 年。
scikit-learn 库提供了一些常见的单类分类算法,旨在用于离群值或异常检测和变化检测,例如 One-Class SVM、Isolation Forest、Elliptic Envelope 和 Local Outlier Factor。
在接下来的部分中,我们将逐一介绍。
在此之前,我们将设计一个二元分类数据集来演示这些算法。我们将使用 make_classification() scikit-learn 函数创建 10,000 个示例,其中少数类有 10 个示例,多数类有 9,990 个示例,即 0.1% 对 99.9%,或大约 1:1000 的类别分布。
下面的示例创建并总结了这个数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 生成并绘制一个合成的不平衡分类数据集 from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # 定义数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.999], flip_y=0, random_state=4) # 总结类别分布 counter = Counter(y) print(counter) # 按类别标签绘制样本散点图 for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
运行示例首先总结了类分布,确认了不平衡如预期般创建。
|
1 |
计数器({0: 9990, 1: 10}) |
接下来,创建散点图,并将示例作为按其类标签着色的点进行绘制,显示多数类(蓝色)的大量点和少数类(橙色)的几个点。
这种严重的类不平衡,正类中的示例很少,以及正类中少数示例的非结构化性质,可能为使用单类分类方法奠定良好的基础。
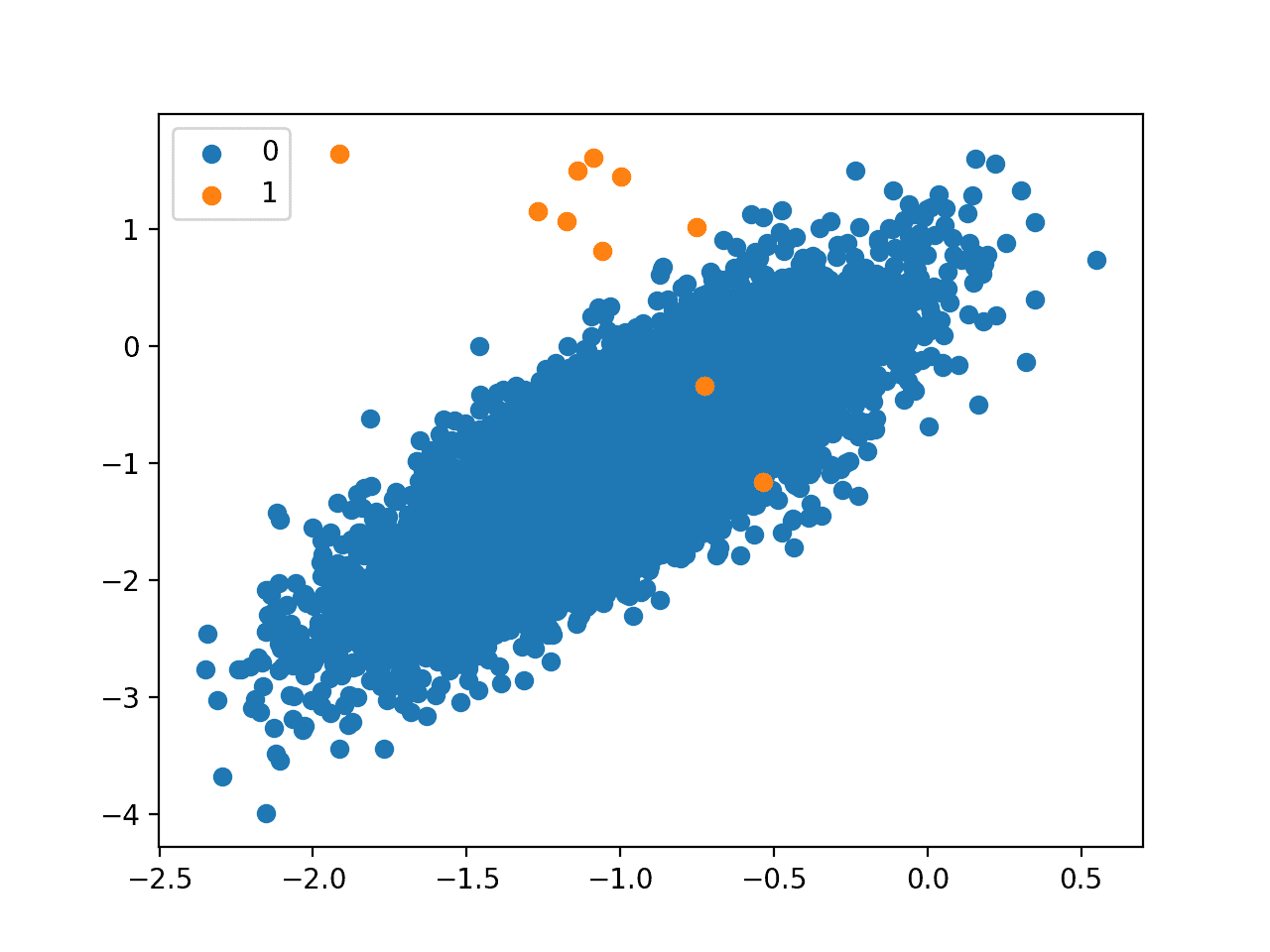
二元分类问题中 1 比 1000 类不平衡的散点图
想要开始学习不平衡分类吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
单类支持向量机
支持向量机(SVM)算法最初是为二元分类开发的,但也可用于单类分类。
如果用于不平衡分类,建议在测试单类版本之前,先在您的数据集上评估标准 SVM 和加权 SVM。
在建模一个类时,算法会捕捉多数类的密度,并将密度函数极端的示例分类为离群值。这种对 SVM 的修改被称为单类 SVM。
……一种计算二元函数的算法,该函数旨在捕获输入空间中概率密度存在的区域(其支持),即一个函数,使得大多数数据将存在于该函数非零的区域。
— 估算高维分布的支持度,2001。
scikit-learn 库在 OneClassSVM 类中提供了单类 SVM 的实现。
与标准 SVM 的主要区别在于,它以无监督方式进行拟合,并且不提供用于调整边缘的常规超参数,例如 C。相反,它提供了一个超参数“nu”,用于控制支持向量的敏感度,应根据数据中离群值的近似比例进行调整,例如 0.01%。
|
1 2 3 |
... # 定义离群值检测模型 model = OneClassSVM(gamma='scale', nu=0.01) |
该模型可以拟合训练数据集中的所有示例,也可以只拟合多数类中的示例。也许可以在您的问题上尝试两者。
在这种情况下,我们将尝试仅对训练集中属于多数类的示例进行拟合。
|
1 2 3 |
# 拟合多数类 trainX = trainX[trainy==0] model.fit(trainX) |
一旦拟合,该模型就可以用于识别新数据中的离群值。
当调用模型的 predict() 函数时,它将为正常示例(即内点)输出 +1,为离群值输出 -1。
- 内点预测: +1
- 离群值预测: -1
|
1 2 3 |
... # 检测测试集中的离群值 yhat = model.predict(testX) |
如果我们要评估模型作为二元分类器的性能,我们必须将测试数据集中的标签从多数类和少数类的 0 和 1 分别更改为 +1 和 -1。
|
1 2 3 4 |
... # 标记内点为 1,离群值为 -1 testy[testy == 1] = -1 testy[testy == 0] = 1 |
然后我们可以将模型的预测与预期的目标值进行比较并计算分数。鉴于我们有清晰的类标签,我们可能会使用诸如精确度、召回率或两者的组合(例如 F 度量(F1-score))之类的分数。
在这种情况下,我们将使用 F 度量分数,它是精确度和召回率的调和平均值。我们可以使用 f1_score() 函数计算 F 度量,并通过“pos_label”参数将少数类的标签指定为 -1。
|
1 2 3 4 |
... # 计算分数 score = f1_score(testy, yhat, pos_label=-1) print('F1 Score: %.3f' % score) |
综上所述,我们可以在合成数据集上评估单类 SVM 算法。我们将数据集分成两部分,一半用于无监督训练模型,另一半用于评估。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 用于不平衡二元分类的单类 SVM from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score from sklearn.svm import OneClassSVM # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.999], flip_y=0, random_state=4) # 划分为训练/测试集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2, stratify=y) # 定义离群值检测模型 model = OneClassSVM(gamma='scale', nu=0.01) # 拟合多数类 trainX = trainX[trainy==0] model.fit(trainX) # 检测测试集中的离群值 yhat = model.predict(testX) # 标记内点为 1,离群值为 -1 testy[testy == 1] = -1 testy[testy == 0] = 1 # 计算分数 score = f1_score(testy, yhat, pos_label=-1) print('F1 Score: %.3f' % score) |
运行示例,模型在训练集中多数类的输入示例上进行拟合。然后使用该模型将测试集中的示例分类为内点和离群值。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,F1 分数为 0.123。
|
1 |
F1 分数:0.123 |
孤立森林
孤立森林(Isolation Forest),简称 iForest,是一种基于树的异常检测算法。
……孤立森林(iForest)纯粹基于孤立的概念来检测异常,不使用任何距离或密度度量
— 基于孤立的异常检测,2012 年。
它基于对正常数据进行建模,以隔离数量少且特征空间不同的异常。
……我们提出的方法利用了异常的两个定量特性:i) 它们是少数,由较少实例组成;ii) 它们的属性值与正常实例的属性值非常不同。
— 孤立森林,2008 年。
创建树结构以隔离异常。结果是,孤立的示例在树中具有相对较短的深度,而正常数据隔离程度较低,在树中具有更大的深度。
……可以有效地构建树结构来隔离每个实例。由于易于隔离,异常离树根更近;而正常点则在树的更深处被隔离。
— 孤立森林,2008 年。
scikit-learn 库在 IsolationForest 类中提供了孤立森林的实现。
模型最重要的超参数可能是“n_estimators”参数(设置要创建的树的数量)和“contamination”参数,后者用于帮助定义数据集中离群值的数量。
我们知道污染率大约是正例对负例的 0.01%,因此我们可以将“contamination”参数设置为 0.01。
|
1 2 3 |
... # 定义离群值检测模型 model = IsolationForest(contamination=0.01, behaviour='new') |
该模型最好在排除离群值的示例上进行训练。在这种情况下,我们仅在多数类示例的输入特征上拟合模型。
|
1 2 3 4 |
... # 拟合多数类 trainX = trainX[trainy==0] model.fit(trainX) |
与单类 SVM 类似,模型将预测内点标签为 +1,离群点标签为 -1,因此,在评估预测之前必须更改测试集的标签。
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 用于不平衡分类的孤立森林 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score from sklearn.ensemble import IsolationForest # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.999], flip_y=0, random_state=4) # 划分为训练/测试集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2, stratify=y) # 定义离群值检测模型 model = IsolationForest(contamination=0.01, behaviour='new') # 拟合多数类 trainX = trainX[trainy==0] model.fit(trainX) # 检测测试集中的离群值 yhat = model.predict(testX) # 标记内点为 1,离群值为 -1 testy[testy == 1] = -1 testy[testy == 0] = 1 # 计算分数 score = f1_score(testy, yhat, pos_label=-1) print('F1 Score: %.3f' % score) |
运行示例,孤立森林模型以无监督方式在训练数据集上进行拟合,然后将测试集中的示例分类为内点和离群值并对结果进行评分。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,F1 分数为 0.154。
|
1 |
F1 分数:0.154 |
注意:污染率非常低,可能导致许多运行的 F1 分数为 0.0。
为了提高该方法在该数据集上的稳定性,请尝试将污染率提高到 0.05 甚至 0.1,然后重新运行示例。
最小协方差行列式
如果输入变量具有高斯分布,那么可以使用简单的统计方法来检测离群值。
例如,如果数据集有两个输入变量且都呈高斯分布,则特征空间形成多维高斯分布,可以利用这种分布的知识来识别远离该分布的值。
这种方法可以通过定义一个包含正常数据的超球面(椭球体)来推广,超出此形状的数据被视为离群值。对于多变量数据,这种技术的有效实现被称为最小协方差行列式(Minimum Covariance Determinant),简称 MCD。
拥有如此良好的数据是不常见的,但如果您的数据集就是这种情况,或者您可以使用幂变换使变量呈高斯分布,那么这种方法可能适用。
最小协方差行列式(MCD)方法是一种对多变量位置和散布的高度鲁棒的估计器,并且有一个快速算法可用。 [...] 它也是一种方便有效的离群值检测工具。
— 最小协方差行列式及其扩展,2017。
scikit-learn 库通过 EllipticEnvelope 类提供了访问此方法的途径。
它提供了“contamination”参数,该参数定义了实际观察到的离群值的预期比例。我们知道在我们的合成数据集中,这个比例是 0.01%,因此我们可以相应地设置它。
|
1 2 3 |
... # 定义离群值检测模型 model = EllipticEnvelope(contamination=0.01) |
模型可以仅在多数类的输入数据上进行拟合,以便以无监督方式估计“正常”数据的分布。
|
1 2 3 4 |
... # 拟合多数类 trainX = trainX[trainy==0] model.fit(trainX) |
然后,该模型将用于将新示例分类为正常 (+1) 或离群值 (-1)。
|
1 2 3 |
... # 检测测试集中的离群值 yhat = model.predict(testX) |
综上所述,下面列出了在我们的合成二元分类数据集上使用椭圆包络离群值检测模型进行不平衡分类的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 用于不平衡分类的椭圆包络 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score from sklearn.covariance import EllipticEnvelope # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.999], flip_y=0, random_state=4) # 划分为训练/测试集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2, stratify=y) # 定义离群值检测模型 model = EllipticEnvelope(contamination=0.01) # 拟合多数类 trainX = trainX[trainy==0] model.fit(trainX) # 检测测试集中的离群值 yhat = model.predict(testX) # 标记内点为 1,离群值为 -1 testy[testy == 1] = -1 testy[testy == 0] = 1 # 计算分数 score = f1_score(testy, yhat, pos_label=-1) print('F1 Score: %.3f' % score) |
运行示例,椭圆包络模型以无监督方式在训练数据集上进行拟合,然后将测试集中的示例分类为内点和离群值并对结果进行评分。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,F1 分数为 0.157。
|
1 |
F1 分数:0.157 |
局部异常因子
识别异常值的一个简单方法是找到那些在特征空间中与其他示例相距甚远的示例。
这对于低维度的特征空间(少数特征)可能效果很好,但随着特征数量的增加,其可靠性会降低,这被称为维度诅咒。
局部离群因子(Local Outlier Factor,简称 LOF)是一种利用最近邻居概念进行离群值检测的技术。每个示例都会根据其局部邻域的大小被赋予一个分数,表示其孤立程度或成为离群值的可能性。得分最高的示例更有可能是离群值。
我们为数据集中的每个对象引入一个局部异常值 (LOF),以表明其异常程度。
— LOF:识别基于密度的局部离群值,2000。
scikit-learn 库在 LocalOutlierFactor 类中提供了此方法的实现。
可以定义模型,并且需要指明数据集中离群值的预期百分比,例如在我们的合成数据集中为 0.01%。
|
1 2 3 |
... # 定义离群值检测模型 model = LocalOutlierFactor(contamination=0.01) |
模型未拟合。相反,通过调用 fit_predict(),将“正常”数据集用作识别新数据中离群值的基础。
要使用此模型识别测试数据集中的离群值,我们必须首先准备训练数据集,使其仅包含来自多数类的输入示例。
|
1 2 3 |
... # 只获取多数类的示例 trainX = trainX[trainy==0] |
接下来,我们可以将这些示例与测试数据集中的输入示例连接起来。
|
1 2 3 |
... # 创建一个大型数据集 composite = vstack((trainX, testX)) |
然后我们可以通过调用 fit_predict() 进行预测,并只检索测试集中示例的标签。
|
1 2 3 4 5 |
... # 对复合数据集进行预测 yhat = model.fit_predict(composite) # 只获取测试集上的预测 yhat yhat[len(trainX):] |
为了使事情更简单,我们可以将此封装到一个名为 lof_predict() 的新函数中,如下所示。
|
1 2 3 4 5 6 7 8 |
# 使用 lof 模型进行预测 def lof_predict(model, trainX, testX): # 创建一个大型数据集 composite = vstack((trainX, testX)) # 对复合数据集进行预测 yhat = model.fit_predict(composite) # 只返回测试集上的预测 return yhat[len(trainX):] |
像 scikit-learn 中的其他离群值检测算法一样,预测标签将是 +1 表示正常,-1 表示离群值。
综上所述,下面列出了使用 LOF 离群值检测算法进行具有偏斜类分布的分类的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# 用于不平衡分类的局部离群因子 from numpy import vstack from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score from sklearn.neighbors import LocalOutlierFactor # 使用 lof 模型进行预测 def lof_predict(model, trainX, testX): # 创建一个大型数据集 composite = vstack((trainX, testX)) # 对复合数据集进行预测 yhat = model.fit_predict(composite) # 只返回测试集上的预测 return yhat[len(trainX):] # 生成数据集 X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.999], flip_y=0, random_state=4) # 划分为训练/测试集 trainX, testX, trainy, testy = train_test_split(X, y, test_size=0.5, random_state=2, stratify=y) # 定义离群值检测模型 model = LocalOutlierFactor(contamination=0.01) # 只获取多数类的示例 trainX = trainX[trainy==0] # 检测测试集中的离群值 yhat = lof_predict(model, trainX, testX) # 标记内点为 1,离群值为 -1 testy[testy == 1] = -1 testy[testy == 0] = 1 # 计算分数 score = f1_score(testy, yhat, pos_label=-1) print('F1 Score: %.3f' % score) |
运行示例使用局部离群因子模型以无监督方式在训练数据集上对测试集中的示例进行分类,将其分为内点和离群值,然后对结果进行评分。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,F1 分数为 0.138。
|
1 |
F1 分数:0.138 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 高维分布的支持度估计, 2001.
- 孤立森林, 2008.
- 基于隔离的异常检测, 2012.
- 最小协方差行列式估计器的快速算法, 2012.
- 最小协方差行列式及其扩展, 2017.
- LOF:识别基于密度的局部异常值, 2000.
书籍
- 从不平衡数据集中学习 (Learning from Imbalanced Data Sets), 2018.
- 不平衡学习:基础、算法与应用 (Imbalanced Learning: Foundations, Algorithms, and Applications), 2013.
API
- 新奇与异常检测,scikit-learn API.
- sklearn.svm.OneClassSVM API.
- sklearn.ensemble.IsolationForest API.
- sklearn.covariance.EllipticEnvelope API.
- sklearn.neighbors.LocalOutlierFactor API.
文章
总结
在本教程中,您学习了如何将单类分类算法用于类分布严重倾斜的数据集。
具体来说,你学到了:
- 单类分类是机器学习的一个领域,它提供用于离群值和异常检测的技术。
- 如何将单类分类算法应用于具有严重倾斜类分布的不平衡分类。
- 如何拟合和评估单类分类算法,例如 SVM、隔离森林、椭圆包络和局部异常因子。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌控不平衡分类!

在几分钟内开发不平衡学习模型
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 处理不平衡分类问题
它提供了关于以下内容的自学教程和端到端项目:
性能指标、欠采样方法、SMOTE、阈值移动、概率校准、成本敏感算法
以及更多...


")

")
")
不错的文章…
我是机器学习新手…
如何在图像中实现异常检测/单类分类?
或许可以尝试使用上述方法——尽管是原样,没有两类数据集。
能否请您解释超参数“nu”的选择?超参数“nu”控制支持向量的敏感性,应根据数据中异常值的近似比例进行调整,例如 0.01%。一类与另一类的比例是 1:999,即 0.001 或 0.1%。为什么选择 0.01%?
好问题。
它应该与异常值的比例有关,尽管这可能很难估计,我建议测试不同的值以发现适用于您的数据集的值。
f1_score 返回一个介于 0 和 1 之间的值,f1_score 的高值意味着更好的结果,
此外,pos_label 参数允许您指定在此计算中应将哪个类视为“正”类。您将参数 pos_label 定义为 -1,而在您的示例中,大多数数据都用 1 标记。
所以我认为结果不真实,您应该将 pos_label 参数的值更改为 1
score = f1_score(testy, yhat, pos_label=-1)
score = f1_score(testy, yhat, pos_label=1)
少数类是异常值,并被标记为 -1,因此在计算 F1 时我们将 pos_label 设置为 -1。
如果我们将 pos_label 设置为 1,那么我们将颠倒正负类关系并给出不正确的结果。
感谢您分享您的宝贵经验。
我正在尝试从一个包含 60 个特征和 180 个观测值的数据集中查找异常值。使用隔离森林方法,它是无监督的
1- 我对实际异常值一无所知,所以无法将它们分为正常值和异常值,我可以在混合观测值上运行模型吗?您有什么建议?
2/ 如何确定污染率?
2- 当我没有任何目标来测试模型时,如何确信报告的异常值是准确的?
抱歉问题很多,再次感谢。
这种方法确实假设您的数据中存在一些异常值,并且当模型提出建议时可以确认/否认它们。
也许你没有异常值?
谢谢你。
我没有异常值。
我使用隔离随机森林来查找异常值。接下来,将数据集拆分为训练集和测试集。接下来,删除异常值并在纯训练集上训练模型。然后,使用训练好的模型从测试集中查找异常值,并估计 F 分数。
电离层不确定这是否是最好的方法。
如果你没有异常值,为什么要寻找它们?
我不确定这是否是最好的方法。
没有“最好”的方法,只有在可用时间和资源下我们测试的方法。
亲爱的 Jason,
存在异常值,我使用了无监督隔离随机森林来查找它们。
我发现了一些异常值。
我如何检查它们是否真的是异常值?
这是一个难题!
也许可以尝试绘制正常值与异常值的数据?
也许可以尝试查看正常值与异常值的统计数据?
也许可以咨询领域专家?
感谢您的建议
不客气。
感谢您这有用的教程!
我有一个问题:我如何将这些方法中的任何一种应用于少数类呢?似乎上述所有分类器都有一个介于 [0,1) 范围内的异常值或污染率。但是,如果应用于少数类,这个比率会大于 1。所提到的分类器能否应用于少数类,或者我应该尝试其他方法来解决这个问题?谢谢!
将多数类建模为少数类的异常值对我来说没有意义,你为什么要这样做?
根据我拥有的数据,异常类是多数类。它的分布是无序的,没有一致的模式。我的正常类数据较少,在特征空间中分散程度较低。这就是为什么我认为将模型拟合到少数类(在我的情况下是正常类)更有意义。您对此有什么看法?
太棒了!
好的,尝试翻转标签/模型,看看它是否适用于您的数据。很期待听到您的进展。
您好。我的数据中有 1% 被丢弃,其余为正常数据。
召回率非常低。这些步骤之后应该怎么做?
我不明白您得出了什么结论。工作会到此为止吗?
这个框架将帮助您处理不平衡分类数据集。
https://machinelearning.org.cn/framework-for-imbalanced-classification-projects/
正如我之前提到的,我的问题是如何在单类 SVM 中定义像“nu”这样的超参数,或者在其他方法中定义“污染”因子。这些超参数在 (0,1) 范围内。但是,如果我想在正常数据上进行训练,这些数据在特征空间中具有更一致的模式,那么异常与正常的比率将高于 1(正如我提到的,我异常数据多于正常数据)。这里有没有其他方法可以尝试?
不知道,从未做过。你必须进行实验并发现哪些方法或问题框架是合适的。这可能需要一些创造性思维……
在LOF方法中,您达到了F1-score=0.13。从这个输出中可以得出什么结论?
LOF 方法是否合适?
总的来说,您如何评估您在本节中提到的这些方法?
没什么,我只是在演示这些方法,而不是试图有效地解决一个问题。
好问题!选择一个指标并用它来解释你的所有方法。
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
在这种情况下,能否解释一下您对 LOF 输出和性能的解读?
因为我的数据非常不平衡,Fscore 非常非常低。
我建议在您的数据集上测试每种方法,并发现哪种方法最适合您的具体情况。
亲爱的 Jason,
我正在尝试使用单类分类,但我的少数类只有标签!在这种情况下,有没有可用的算法?
谢谢!
是的,将所有数据交给算法,它会尽力识别异常值。
感谢您提供这份有用的教程。
我有一个疑问,在提问之前我想简单介绍一下我的数据。我正在研究信号分类问题,其中我有两种类型的信号,它们的包络几乎相同,异常类与正常类相比存在时延和衰减。我一直在尝试实现 OCSVM 和单类 CNN (OCCNN),如本文 (https://arxiv.org/pdf/1901.08688.pdf) 中所述。我正在使用少量(8 到 12 千个)属于正常类的信号初始化网络,并且在测试阶段使用 OCSVM 获得了一些令人满意的结果。但我无法使用 OCCNN 预测异常信号。
这里我简要介绍一下 OCCNN:它使用预训练的 AlexNet 或 VggNet 模型与 ImageNet 模型,直到特征提取阶段,通过冻结密集网络。对于这些半网络,输入单类数据(例如正常类数据)以提取特征,并将这些特征与从零均值高斯分布生成的伪负类数据附加,并作为二元分类问题输入到密集层。
您能建议我如何使用 OCCNN 进行分类吗?
谢谢你。
抱歉,我对这种技术不熟悉,不确定我能具体提供什么帮助。听起来您需要调试您的实现或找到可以采用的现有实现。
我们也可以将单类分类用于多标签数据吗?
不确定这是否合适。
抱歉,我说的多标签是指多类...
是否可以将单类支持向量机与一对一/一对多结合起来解决多类问题?
也许吧。那会怎么运作呢?
恭喜您的材料内容丰富且引人入胜!
我只是对 F-1 分数低的问题有疑问。这些分数真的应该那么低吗?
此外,还有其他指标来评估模型的性能吗?
此致。
谢谢!
本教程将帮助您了解指标
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
在这种情况下(正类百分比),PR-AUC 曲线的无技能基线是 0.01。
这与 ROC-AUC 曲线不同,后者的无技能基线是 0.5。因此,任何
高于 0.01 的精度值都优于朴素分类器。
https://machinelearning.org.cn/roc-curves-and-precision-recall-curves-for-imbalanced-classification/
我们能否将单类分类算法用于音频信号的分类。音频信号是从燃气轮机燃烧器收集的。音频信号主要指正常运行条件。我们希望开发一个用于检测异常的系统。
我看不出为什么不。
你好…
能否解释一下您写的这句话?
(它还表明单类分类器可以作为算法集成(每个算法以不同方式使用训练数据集)的输入。)
也就是说,要用作元分类器?如何?您有示例吗?
我建议您可以使用单类模型的输出作为集成的输入。
我的博客上有很多集成示例,也许可以从堆叠集成开始。
https://machinelearning.org.cn/stacking-ensemble-machine-learning-with-python/
您好,这是一个很棒的教程和可用方法的概述!您是否碰巧知道如何使用 Keras 或 Tensorflow 实现类似方法?在我的项目中,TFX (Tensorflow Extended) 被用作创建和部署 ML 模型的框架,因此在构建模型时我受限于此。或者您能帮我了解如何在 Keras/Tensorflow API 中实现单类 SVM 或隔离森林吗?
不行。
为什么不直接使用这些方法呢?
我会的,但 TFX 框架强制模型采用 Tensorflow 的 Estimator 或 Keras 的 Model 格式——我找不到(或者我不知道)将使用 sklearn 构建的模型转换为 TFX 管道接受的模型的方法。
抱歉,我没有听说过“TFX”,我无法就此向您提供建议。
很棒的文章。谢谢你的课程。
谢谢!
嗨,Jason,
感谢这些精彩的文章,并将许多内容总结在一页中。
1) 对于像聚类这样的无监督方法,我们不需要任何训练数据,也不需要目标变量。但在这种单类分类问题中,看起来我们需要训练数据和目标类。有点困惑,为什么当我们仍然需要训练时,它却属于无监督学习。
2) 您提到——“单类分类器是在仅包含正常类示例的训练数据集上拟合的。”
这意味着我们必须确保训练数据中没有任何异常值。也就是说,如果训练数据中有 1000 个样本,我们必须确保这 1000 个样本中没有任何异常值?
是的,这些是无监督方法,我们正在强制它们进行监督。您不必以这种方式使用它们,例如
https://machinelearning.org.cn/model-based-outlier-detection-and-removal-in-python/
您能否告诉我如何找到一个用于此类应用的人工神经网络的 Python 示例代码?
当然,就在这里。
https://machinelearning.org.cn/cost-sensitive-neural-network-for-imbalanced-classification/
嗨,Jason,
非常感谢这篇文章。我有一个未标记的数据集,我正在运行单类 SVM 来检测正常值和异常值。您知道在这种没有真实值的情况下如何验证模型吗?谢谢!
是的,您可以找到您领域的主题专家,并征求他们对结果的专家意见。
快速提示:对于隔离森林,我收到警告“252: FutureWarning: ‘behaviour’ 在 0.22 中已弃用,并将在 0.24 中移除。您不应传递或设置此参数。”
您目前可以安全地忽略它。
嘿,贾森!
很棒的文章。
我正在训练一个单类 SVM 模型,但测试数据也只有一个类。我如何使用真阳性和假阴性值来衡量模型的性能。谢谢!
也许您可以从您的领域获取两类的示例来训练和评估您的模型。
也许这会帮助您选择一个指标
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
我读过这篇文章。但在我的情况下,我只有一类数据用于训练和测试。那么,我如何衡量我的 OneClassSVM 模型的性能呢?
选择一个最能捕捉对您或您的项目利益相关者来说最重要的模型指标。
也许它是正确检测到的异常值的数量?
如果您没有异常值的示例,您如何知道您有问题需要建模?
您好,我刚开始学习机器学习,现在我有一个不平衡的数据集,包含大约 15 个特征;
少数类(+)对我来说很重要,但我没有发现特征和标签之间有任何有意义的相关性。
我可以用 OCC 进行分类吗?
也许可以尝试一下,并与其他方法的结果进行比较。
嗨,先生!
这些技术也可以应用于多元时间序列数据吗?
不,我不认为它们适合时间序列。
嗨,Jason,
感谢这篇有用的文章。
我是机器学习新手。我正在尝试开发一个用于异常检测(网络攻击)的模型,但如果我考虑二元分类,数据集包含的正常数据少于攻击(异常数据)。正常数据用 0 表示,攻击用 1 表示。
在这种情况下,我可以从 CSV 文件中提取一个子集,其中包含 99% 的正常数据和 1% 的异常数据用于训练集吗?
如果可以,对于测试集,正常数据和异常数据应该使用多少百分比?
谢谢。
测试集应该足够大,以代表问题。
也许可以尝试重复的分层 k 折交叉验证。
谢谢你
不客气。
先生,您好,
感谢这篇文章。
你能给出一个单类图像数据的例子吗?
谢谢你
感谢您的建议。
嗨,Jason,
感谢您的精彩教程。
如果我的数据集有 4 或 5 个特征,我如何将它们导入上述算法?
谢谢你
你正在进行二元分类吗?如果是,相同的算法就可以正常工作。示例代码中的 X 不一定是单列矩阵。
您能建议一个从 excel 文件或 csv 文件读取我的数据集的函数吗:行表示样本,列是特征,一个 200*6 的矩阵。将其作为 trainsX 导入到上述代码中。
它的类型是 numpy.ndarray
关于将我的数据集导入模型而不是使用 make_classification 和 train_test_split 生成的上述数据集,因为我将我的数据集(训练)导入到 model.fit 中。我无法理解如何将标签分配给样本。
换句话说,如何在代码中放置我的标签,我有训练(1000)和测试(1000)样本(6 个特征),我生成一个零向量来标记训练样本,以及一个零和一向量来标记测试数据,但我认为代码没有识别我的标记,因为我总是收到 f1_score 1.000
你不应该将训练样本标记为 1,而应该将某些类别标记为 1。例如,如果你的数据是根据学生的家庭作业分数预测他们的考试分数,那么你需要将考试分数转换为标签,例如,分数 > 50 是 1(及格),否则是 0。通过这种方式,你正在构建两类学生。
最简单的方法是使用 pandas 的 read_csv() 或 read_excel() 函数;然后你可以使用 dataframe.values 属性将 pandas DataFrame 转换回 numpy 数组
您能建议如何优化单类 SVM 的学习参数(nu)和多项式次数吗?
nu 应该大约是数据中异常值的比例。但是你应该进行实验来验证最佳值。对于多项式次数,这是欠拟合和过拟合之间的权衡。首先尝试较低的次数,只有当准确性不足时才增加它。
感谢您精彩的解释!
我有一个问题,我的数据集已经分成训练集和测试集,训练集没有任何异常样本。测试集包含正常和异常样本。这属于单类分类吗?我应该直接用我的模型在数据集上进行训练,还是重新划分训练集和测试集?
训练集应该包含任何属于异常类的样本吗?或者我可以在训练集中只使用正常样本进行单类分类吗?
是的,这是单类分类。至于你问题的其余部分,最好你自己尝试一下,看看准确性。如果你的训练数据不能代表测试数据,你会发现你的验证分数很低,而你的训练分数很好。
感谢您一如既往的支持
关于主函数属性
sklearn.svm.OneClassSVM(*, kernel='rbf', degree=3, gamma='scale', coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=- 1)
既然优化是机器学习的主要概念,那么 max iteration 字段会影响 OCC 吗?
换句话说,OCC 中的迭代我认为总是 1,因为这里的概念是指定异常值的百分比。这里没有需要调整的权重(没有要优化的成本函数)。
这正确吗?
成本函数在此处说明(更多详细信息请阅读原始论文):https://stats.stackexchange.com/questions/346322/sch%C3%B6lkopfs-one-class-svm-role-of-rho-in-the-cost-function
所以简单地说,这是不正确的。有你可以优化的成本(即边界),只要成本仍然可以提高,最大迭代次数就是无限的。
好的
我能否打印迭代次数和边界(来自 sklearn.svm.OneClassSVM 函数),看看它们是如何收敛的?
我认为这有点困难,因为 scikit-learn 不允许您在其训练迭代中注入评分函数。但是,您可以复制 scikit-learn 的代码并修改它以添加打印语句。
我如何为这类模型进行特征选择?
嗨,Francisco…以下资源可能对您有用
https://machinelearning.org.cn/feature-selection-for-regression-data/
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
你好,
感谢详细的解释!
我有一个问题——我的数据集只有一个单类目标变量,我想找到重要的变量。
对于这类数据集,有没有办法找到变量的重要性?
嗨,Abhijit…以下内容有望提供更多清晰信息
https://machinelearning.org.cn/feature-selection-with-categorical-data/
嗨!
感谢这篇文章。我正在进行异常检测。我得到了类似的结果。
为什么 F1 分数这么低?请问如何改进?
嗨,Tarek…以下内容应能更清楚地说明如何进行改进。
https://www.analyticsvidhya.com/blog/2020/10/improve-class-imbalance-class-weights/
谢谢!!!!
嗨,James Carmichael,
感谢您在机器学习方面发表的信息丰富的文章。
我听从了您的建议,使用单类分类的集成来获得更好的结果。我使用了这里发布的堆叠集成 https://machinelearning.org.cn/stacking-ensemble-machine-learning-with-python/。
具体来说,我使用单类分类器(OSVM、IF、LOF 等)作为单一分类器,并使用逻辑回归(LogisticRegression())作为元分类器。
然而,经过多次尝试,我遇到了很多错误。根据错误判断,我认为逻辑回归可能与单类分类器不兼容,无法作为其元分类器。我的方法正确吗?您有什么建议?
提前非常感谢。
你好 shSam…你遇到了什么错误?
我得到了以下单一分类器的结果(准确率平均值和标准差)
>OCSVM 0.403 (0.019)
>IF 0.384 (0.024)
>EE 0.394 (0.019)
>堆叠
ValueError:估计器 OneClassSVM 应该是一个分类器。
为了清楚地解释错误,当我在模型评估方法中仅用 train_x 拟合单一分类器(model.fit(train_X))时,对于单一分类器来说运行良好,因为它们是单类分类器,但随后堆叠方法给出了这个错误(“fit() 缺少 1 个必需的位置参数:'y'”),这意味着堆叠集成需要(train_x 和 train_y)进行训练,当我将其更改为(model.fit(train_X, train_y))为了集成,我得到了错误(“ValueError:估计器 OneClassSVM 应该是一个分类器。”)。希望我已经解释清楚了,并期待您的建议。谢谢。
感谢这篇文章。帮助很大。
不客气,Anil!
嗨,Jason。我对异常类有一个疑问。如果我只有一个类可以训练,但要泛化两个类怎么办?
感谢您的这篇文章。
你知道单类 CNN 吗?你能做一个关于它的教程吗?
嗨 Shamsheer…以下资源可能对您有用
https://stackoverflow.com/questions/61048870/can-i-build-a-one-class-cnn-in-keras
https://arxiv.org/abs/1901.08688
这里为什么要使用 F1 系数?它不适用于不平衡的类别。MCC 分数更“适合”。此外,演示的结果相当微薄。请您根据我的研究更新这篇文章和您对该主题的知识。我知道这样问有点“糟糕”,但我可以在 KDDCUP 99 数据集上获得超过 0.8 的 F1 分数,同时仅使用“自”数据包进行训练。
如果感兴趣,请尝试搜索 Marin E. Pamukov 的负选择神经网络 (NSNN)。我很乐意阅读您撰写的关于我的算法的 HOWTO 指南。
感谢您的反馈,Marin!我们很 appreciate!