在上一篇文章中,你了解到OpenCV可以使用一种称为方向梯度直方图(HOG)的技术从图像中提取特征。简而言之,就是将图像的“补丁”转换为数值向量。如果设置得当,这个向量可以识别该补丁中的关键特征。虽然你可以使用HOG来比较图像的相似性,但一个实际应用是将其作为分类器的输入,这样你就可以检测图像中的对象。
在这篇文章中,你将学习如何使用HOG创建一个分类器。具体来说,你将学习:
- 如何准备用于分类器训练的输入数据
- 如何在OpenCV中运行训练并保存模型以供重复使用
通过我的书《OpenCV 机器学习》启动您的项目。它提供了带有可用代码的自学教程。
让我们开始吧。

如何在 OpenCV 中使用 HOG 训练目标检测引擎
照片由Neil Thomas拍摄。保留部分权利。
概述
这篇博文分为三部分;它们是:
- 用于分类的HOG
- 准备数据
- 使用HOG特征训练分类器
用于分类的HOG
在上一篇文章中,你了解到HOG是一种从图像区域生成特征向量的技术。这些区域中的对象很可能在很大程度上决定了特征向量。
对象检测是在更大的图像中找到特定对象所在的区域。通常,目标是在大图像中找到一个矩形**边界框**,使得对象紧密地包含在该框内。
使用HOG进行对象检测并不困难:你只需从图像中随机绘制多个边界框。然后,你可以使用HOG找到边界框的特征向量,并将该向量与你期望的目标对象进行比较。
然而,你需要处理多个细节:首先,HOG有多个参数,包括窗口、块和单元格的大小。这还决定了边界框的大小和纵横比。如果你的边界框大小不同,你可能需要调整其大小。其次,HOG对旋转敏感。因此,如果图像倾斜,从HOG获得的特征向量可能对对象检测没有用。
最后,即使所有边界框都识别出相同的对象,每个边界框也会产生不同的HOG向量。你需要一种巧妙的方法来判断是否检测到对象,这通常是一个机器学习模型。
可以使用几种模型来比较候选边界框的HOG。在这篇文章中,你将使用支持向量机(SVM)。OpenCV有一个内置的人物检测器,它也是作为SVM实现的。
准备数据
让我们考虑**猫检测**任务。对于一张有猫的图像,你希望在猫的脸周围画一个正方形。你将使用OpenCV为此任务构建一个SVM。
与所有机器学习项目一样,第一步是获取数据集。你可以从Oxford-IIIT Pet Dataset获取猫图像数据集,位置如下:
这是一个800MB的数据集,在计算机视觉数据集的标准中算是小的。图像以Pascal VOC格式进行标注。简而言之,每张图像都有一个对应的XML文件,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
<?xml version="1.0"?> <annotation> <folder>OXIIIT</folder> <filename>Abyssinian_100.jpg</filename> <source> <database>OXFORD-IIIT Pet Dataset</database> <annotation>OXIIIT</annotation> <image>flickr</image> </source> <size> <width>394</width> <height>500</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>cat</name> <pose>Frontal</pose> <truncated>0</truncated> <occluded>0</occluded> <bndbox> <xmin>151</xmin> <ymin>71</ymin> <xmax>335</xmax> <ymax>267</ymax> </bndbox> <difficult>0</difficult> </object> </annotation> |
XML文件会告诉你它指的是哪个图像文件,以及它包含什么对象,边界框在`<bndbox></bndbox>`标签之间。
有一些Python库可以用来处理Pascal VOC XML文件。但对于这种简单的情况,你只需使用Python内置的XML解析器。下面是一个函数,给定XML文件名,它会读取内容并返回一个Python字典,告诉你它包含的所有对象以及相应的边界框。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import xml.etree.ElementTree as ET def read_voc_xml(xmlfile: str) -> dict: root = ET.parse(xmlfile).getroot() boxes = {"filename": root.find("filename").text, "objects": []} for box in root.iter('object'): bb = box.find('bndbox') obj = { "name": box.find('name').text, "xmin": int(bb.find("xmin").text), "ymin": int(bb.find("ymin").text), "xmax": int(bb.find("xmax").text), "ymax": int(bb.find("ymax").text), } boxes["objects"].append(obj) return boxes |
上述函数返回的字典示例如下:
|
1 2 |
{'filename': 'yorkshire_terrier_160.jpg', 'objects': [{'name': 'dog', 'xmax': 290, 'xmin': 97, 'ymax': 245, 'ymin': 18}]} |
在此数据集中,每张图像只有一个对象(猫或狗)。边界框指定为像素坐标。通过上面获得的文件名,你可以使用OpenCV读取图像。图像是一个numpy数组。因此,你可以使用数组切片提取部分。如下所示:
|
1 2 |
img = cv2.imread(path) portion = img[ymin:ymax, xmin:xmax] |
让我们专注于训练分类器的目标。首先,你需要设计HOG计算的参数。让我们考虑一个不太长的向量,即:
- 窗口大小:(64,64)
- 块大小:(32, 32)
- 块步长:(16, 16)
- 单元格大小:(16, 16)
- 方向直方图分箱数:9
换句话说,你将考虑图像上一个64x64像素的正方形窗口,单元格大小为16x16像素。每个块有2x2个单元格。
由于窗口是正方形的,并且你不想改变图像的纵横比,你将调整数据集中边界框的大小为正方形。之后,你应该裁剪调整后的边界框,将其大小调整为64x64像素,并将其保存为**正样本**。你还需要负样本进行训练。由于你想要制作一个猫检测器,你可以利用狗图像作为负样本。你希望负样本覆盖图像的背景。与其遵循边界框,不如简单地从这些图像中随机裁剪一个正方形区域并将其大小调整为64x64像素作为负样本。
在代码中,下面是如何从数据集中收集1000个正样本和负样本。假设你已下载数据集并将两个tar文件解压到`oxford-iiit-pet`目录。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
def make_square(xmin, xmax, ymin, ymax): """缩小边界框至正方形形状""" xcenter = (xmax + xmin) // 2 ycenter = (ymax + ymin) // 2 halfdim = min(xmax-xmin, ymax-ymin) // 2 xmin, xmax = xcenter-halfdim, xcenter+halfdim ymin, ymax = ycenter-halfdim, ycenter+halfdim return xmin, xmax, ymin, ymax # 定义HOG参数 winSize = (64, 64) blockSize = (32, 32) blockStride = (16, 16) cellSize = (16, 16) nbins = 9 num_samples = 1000 base_path = pathlib.Path("oxford-iiit-pet") img_src = base_path / "images" ann_src = base_path / "annotations" / "xmls" # 通过从数据集中裁剪图像来收集样本 positive = [] negative = [] # 收集正样本 for xmlfile in ann_src.glob("*.xml"): # 加载xml ann = read_voc_xml(str(xmlfile)) # 只使用猫的图片 if ann["objects"][0]["name"] != "cat": continue # 调整边界框为正方形 box = ann["objects"][0] xmin, xmax, ymin, ymax = box["xmin"], box["xmax"], box["ymin"], box["ymax"] xmin, xmax, ymin, ymax = make_square(xmin, xmax, ymin, ymax) # 裁剪正样本 img = cv2.imread(str(img_src / ann["filename"])) sample = img[ymin:ymax, xmin:xmax] sample = cv2.resize(sample, winSize) positive.append(sample) if len(positive) > num_samples: break # 收集负样本 for xmlfile in ann_src.glob("*.xml"): # 加载xml ann = read_voc_xml(str(xmlfile)) # 只使用狗的图片 if ann["objects"][0]["name"] == "cat": continue # 随机边界框:至少目标大小以避免放大 height, width = img.shape[:2] boxsize = random.randint(winSize[0], min(height, width)) x = random.randint(0, width-boxsize) y = random.randint(0, height-boxsize) sample = img[y:y+boxsize, x:x+boxsize] sample = cv2.resize(sample, winSize) negative.append(sample) if len(negative) > num_samples: break |
使用HOG特征训练分类器
OpenCV自带`cv2.ml`中的SVM模块,其工作方式与scikit-learn类似。本质上,你只需执行以下操作即可进行训练:
|
1 2 3 4 5 6 |
svm = cv2.ml.SVM_create() svm.setType(cv2.ml.SVM_C_SVC) svm.setKernel(cv2.ml.SVM_RBF) svm.setTermCriteria((cv2.TERM_CRITERIA_MAX_ITER + cv2.TERM_CRITERIA_EPS, 10000, 1e-8)) svm.train(data, cv2.ml.ROW_SAMPLE, labels) svm.save('svm_model.yml') |
你首先使用`cv2.ml.SVM_create()`创建一个SVM对象。然后配置SVM,因为有许多变体。在上面,你使用`SVM_C_SVC`作为类型,因为它是一个C-支持向量分类器(允许不完美分离的分类SVM)。你使用径向基函数核(`SVM_RBF`),因为它通常效果很好。如果任务简单,你也可以选择使用更简单的线性核(`SVM_LINEAR`)。SVM还有许多其他参数。例如,如果使用RBF核,你可以使用`svm.setGamma()`设置gamma值,并且由于你使用C-SVC,你可以使用`svm.setC()`设置参数C的值。在上面,你将所有参数保留为OpenCV的默认值。
SVM的训练需要一个终止条件。在上面,你使用`svm.setTermCritera()`使训练在10000次迭代时停止,或者当损失函数降至$10^-8$以下时停止,以先达到者为准。所有操作完成后,你只需将数据和标签传递给训练例程。
训练数据以numpy数组的形式呈现。你将其设置为数组中的每一行都是一个样本。所需的标签只是整数标签,0或1。由于你正在使用SVM训练HOG分类器,你需要将样本转换为HOG特征。这在OpenCV中并不困难。以下是如何使用你收集的正样本和负样本创建numpy数组:
|
1 2 3 4 5 6 7 8 9 10 |
images = positive + negative labels = ([1] * len(positive)) + ([0] * len(negative)) hog = cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins) data = [] for img in images: features = hog.compute(img) data.append(features.flatten()) data = np.array(data, dtype=np.float32) labels = np.array(labels, dtype=np.int32) |
从数据收集到训练的完整代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |
import pathlib import random import xml.etree.ElementTree as ET import cv2 import numpy as np def read_voc_xml(xmlfile): """读取Pascal VOC XML""" root = ET.parse(xmlfile).getroot() boxes = {"filename": root.find("filename").text, "objects": []} for box in root.iter('object'): bb = box.find('bndbox') obj = { "name": box.find('name').text, "xmin": int(bb.find("xmin").text), "ymin": int(bb.find("ymin").text), "xmax": int(bb.find("xmax").text), "ymax": int(bb.find("ymax").text), } boxes["objects"].append(obj) return boxes def make_square(xmin, xmax, ymin, ymax): """缩小边界框至正方形形状""" xcenter = (xmax + xmin) // 2 ycenter = (ymax + ymin) // 2 halfdim = min(xmax-xmin, ymax-ymin) // 2 xmin, xmax = xcenter-halfdim, xcenter+halfdim ymin, ymax = ycenter-halfdim, ycenter+halfdim return xmin, xmax, ymin, ymax # 定义HOG参数 winSize = (64, 64) blockSize = (32, 32) blockStride = (16, 16) cellSize = (16, 16) nbins = 9 num_samples = 1000 # 加载数据集和相应的边界框标注 base_path = pathlib.Path("oxford-iiit-pet") img_src = base_path / "images" ann_src = base_path / "annotations" / "xmls" # 通过从数据集中裁剪图像来收集样本 positive = [] negative = [] # 收集正样本 for xmlfile in ann_src.glob("*.xml"): # 加载xml ann = read_voc_xml(str(xmlfile)) # 只使用猫的图片 if ann["objects"][0]["name"] != "cat": continue # 调整边界框为正方形 box = ann["objects"][0] xmin, xmax, ymin, ymax = box["xmin"], box["xmax"], box["ymin"], box["ymax"] xmin, xmax, ymin, ymax = make_square(xmin, xmax, ymin, ymax) # 裁剪正样本 img = cv2.imread(str(img_src / ann["filename"])) sample = img[ymin:ymax, xmin:xmax] sample = cv2.resize(sample, winSize) positive.append(sample) if len(positive) > num_samples: break # 收集负样本 for xmlfile in ann_src.glob("*.xml"): # 加载xml ann = read_voc_xml(str(xmlfile)) # 只使用狗的图片 if ann["objects"][0]["name"] == "cat": continue # 随机边界框:至少目标大小以避免放大 height, width = img.shape[:2] boxsize = random.randint(winSize[0], min(height, width)) x = random.randint(0, width-boxsize) y = random.randint(0, height-boxsize) sample = img[y:y+boxsize, x:x+boxsize] assert tuple(sample.shape[:2]) == (boxsize, boxsize) sample = cv2.resize(sample, winSize) negative.append(sample) if len(negative) > num_samples: break images = positive + negative labels = ([1] * len(positive)) + ([0] * len(negative)) # 为每张图像创建HOG描述符和HOG特征 hog = cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins) data = [] for img in images: features = hog.compute(img) data.append(features.flatten()) # 将数据和标签转换为numpy数组 data = np.array(data, dtype=np.float32) labels = np.array(labels, dtype=np.int32) # 训练SVM svm = cv2.ml.SVM_create() svm.setType(cv2.ml.SVM_C_SVC) svm.setKernel(cv2.ml.SVM_RBF) svm.setTermCriteria((cv2.TERM_CRITERIA_MAX_ITER + cv2.TERM_CRITERIA_EPS, 100000, 1e-8)) svm.train(data, cv2.ml.ROW_SAMPLE, labels) # 保存SVM模型 svm.save('svm_model.yml') print(svm.getSupportVectors()) |
上面代码的最后一行是打印训练后的SVM的支持向量。它是可选的,因为你已经将模型保存到`svm_model.yml`文件中。
以下是如何使用训练好的模型:首先创建一个HOG对象,一个SVM对象,然后将SVM对象作为检测器分配给HOG。当你有一张图像时,使用HOG的`detectMultiScale()`方法查找检测到的对象的位置。此函数会多次缩放图像,这样你为HOG设置的窗口大小就不需要与对象完全匹配。这非常有用,因为你不知道目标对象在图像中有多大。由于SVM是根据特定的HOG特征配置进行训练的,因此你必须使用与训练中相同的参数(窗口、块、单元格和bin)创建HOG对象。检测函数的输出将是多个边界框,但你可以简单地根据分数选择最佳匹配的一个。
代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
winSize = (64, 64) blockSize = (32, 32) blockStride = (16, 16) cellSize = (16, 16) nbins = 9 svm = cv2.ml.SVM_load('svm_model.yml') hog = cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins) hog.setSVMDetector(svm.getSupportVectors()[0]) locations, scores = hog.detectMultiScale(img) x, y, w, h = locations[np.argmax(scores.flatten())] cv2.rectangle(img, (x, y), (x + w, y + h), (255,0,0), 5) |
假设训练好的SVM已经保存到文件`svm_model.yml`中。你直接使用保存的文件创建SVM对象。`hog.detectMultiScale()`的输出`scores`是一个N×1的numpy数组。因此,你应该将其展平为向量并找到最大值。`locations`数组中对应的边界框是最佳匹配的边界框。此函数返回的边界框是以左上角的坐标以及宽度和高度表示的。上面代码的最后一行是在图像上直接标注此类框。
你确实可以在同一个数据集上运行它。完整的代码如下,其中原始边界框和SVM检测到的边界框都在图像上绘制并用OpenCV显示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
import pathlib import xml.etree.ElementTree as ET import cv2 import numpy as np def read_voc_xml(xmlfile: str) -> dict: """读取Pascal VOC XML并返回(文件名,对象名,边界框) 其中边界框是(xmin,ymin,xmax,ymax)的向量。像素 坐标是从1开始的。 """ root = ET.parse(xmlfile).getroot() boxes = {"filename": root.find("filename").text, "objects": [] } for box in root.iter('object'): bb = box.find('bndbox') obj = { "name": box.find('name').text, "xmin": int(bb.find("xmin").text), "ymin": int(bb.find("ymin").text), "xmax": int(bb.find("xmax").text), "ymax": int(bb.find("ymax").text), } boxes["objects"].append(obj) return boxes # 加载SVM winSize = (64, 64) blockSize = (32, 32) blockStride = (16, 16) cellSize = (16, 16) nbins = 9 svm = cv2.ml.SVM_load('svm_model.yml') hog = cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins) hog.setSVMDetector(svm.getSupportVectors()[0]) base_path = pathlib.Path("oxford-iiit-pet") img_src = base_path / "images" ann_src = base_path / "annotations" / "xmls" for xmlfile in ann_src.glob("*.xml"): # 加载xml ann = read_voc_xml(str(xmlfile)) # 标注 img = cv2.imread(str(img_src / ann["filename"])) bbox = ann["objects"][0] start_point = (bbox["xmin"], bbox["ymin"]) end_point = (bbox["xmax"], bbox["ymax"]) annotated_img = cv2.rectangle(img, start_point, end_point, (0,0,255), 2) # 检测并绘制 locations, scores = hog.detectMultiScale(img) x, y, w, h = locations[np.argmax(scores.flatten())] cv2.rectangle(img, (x, y), (x + w, y + h), (255,0,0), 5) cv2.imshow(f"{ann['filename']}: {ann['objects'][0]['name']}", annotated_img) key = cv2.waitKey(0) cv2.destroyAllWindows() if key == ord('q'): break |
OpenCV将逐个显示数据集中带标注的图像。数据集的边界框是红色的,而SVM报告的边界框是蓝色的。请注意,这是一个猫检测器,所以如果是一张狗的图像,理想情况下不应该检测到任何东西。然而,使用HOG特征的SVM在这方面表现不佳。
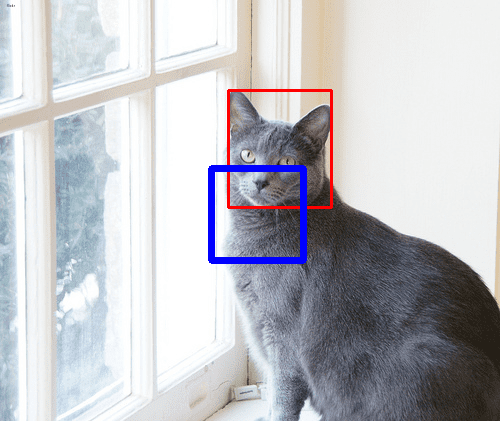
数据集中的边界框(红色)与训练模型的检测输出(蓝色)的比较。
事实上,这个检测器不是很准确。如上例所示,检测到的边界框与猫的脸部相差甚远。即便如此,它也不是一个糟糕的模型。你可以通过调整模型参数(如C和gamma)以及提供更好的训练数据来提高SVM的质量。
想开始学习 OpenCV 机器学习吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 精通 OpenCV 4, 2019.
网站
- OpenCV
- StackOverflow:OpenCV HOG特征解释
- OpenCV:支持向量机简介
总结
在这篇文章中,你学习了如何完全使用OpenCV库训练一个带有HOG特征的SVM进行目标检测。具体来说,你学习了:
- 如何准备训练数据,因为SVM只接受特征作为numpy数组
- 如何在OpenCV中保存和加载SVM
- 如何在OpenCV中将SVM对象附加到HOG对象以进行多尺度检测
开始使用 OpenCV 进行机器学习!

学习如何在图像处理项目中使用机器学习技术
...以高级方式使用 OpenCV,超越像素处理
在我的新电子书中探索如何实现
OpenCV 机器学习
它提供带有所有可用 Python 代码的自学教程,让您从新手成长为专家。它为您提供了
逻辑回归、随机森林、支持向量机、k 均值聚类、神经网络等等……所有这些都使用 OpenCV 中的机器学习模块






结果太差了。我明白它不是完美的,但为什么会这么差呢?
你好 emre……请详细说明你遇到的问题,以便我们更好地帮助你。