我们刚刚了解了 ControlNet。现在,让我们来探索如何根据人体姿势最有效地控制你的角色。OpenPose 是一个强大的工具,可以检测图像和视频中的人体关键点位置。通过将 OpenPose 与 Stable Diffusion 集成,我们可以指导 AI 生成符合特定姿势的图像。
在本帖中,您将了解 ControlNet 的 OpenPose,以及如何使用它来生成相似姿势的角色。具体来说,我们将涵盖:
- 什么是 OpenPose,它是如何工作的?
- 如何使用 Hugging Face Spaces 中的 ControlNet,通过参考图像生成精确的图像。
- 如何在 Stable Diffusion WebUI 中设置 OpenPose,并使用它来创建高质量的图像。
- 各种 OpenPose 处理器专注于身体的特定部分。
通过我的书籍《使用 Stable Diffusion 精通数字艺术》,**开启你的项目**。它提供了带有**可运行代码**的**自学教程**。
让我们开始吧。

在 Stable Diffusion 中使用 OpenPose
图片来自 engin akyurt。部分权利保留。
概述
本帖共分为四个部分:
- 什么是 ControlNet OpenPose?
- Hugging Face Space 中的 ControlNet
- Stable Diffusion Web UI 中的 OpenPose 编辑器
- 图像到图像生成
什么是 ControlNet OpenPose?
OpenPose 是一个用于从图像检测人体姿势的深度学习模型。其输出是图像中人体**关键点**(如肘部、手腕和膝盖)的位置。ControlNet 中的 OpenPose 模型接受关键点作为扩散模型的附加条件,并生成与这些关键点对齐的人体姿势的输出图像。一旦您能够指定关键点的精确位置,它就可以让您根据骨骼图像生成写实的人体姿势图像。您可以将其用于创作不同姿势的艺术照片、动画或插图。
Hugging Face Spaces 中的 ControlNet
要尝试 ControlNet OpenPose 模型的功能,您可以使用 Hugging Face Spaces 上的免费在线演示。
首先,您需要创建姿势关键点。这可以通过上传图像并让 OpenPose 模型检测它们来轻松完成。首先,您可以下载 Yogendra Singh 的照片,然后将其上传到 ControlNet Spaces。此 ControlNet 帮助您固定姿势,但您仍需要提供文本提示来生成图片。让我们编写简单的提示“一个女人正在雨中跳舞。”,然后按运行按钮。
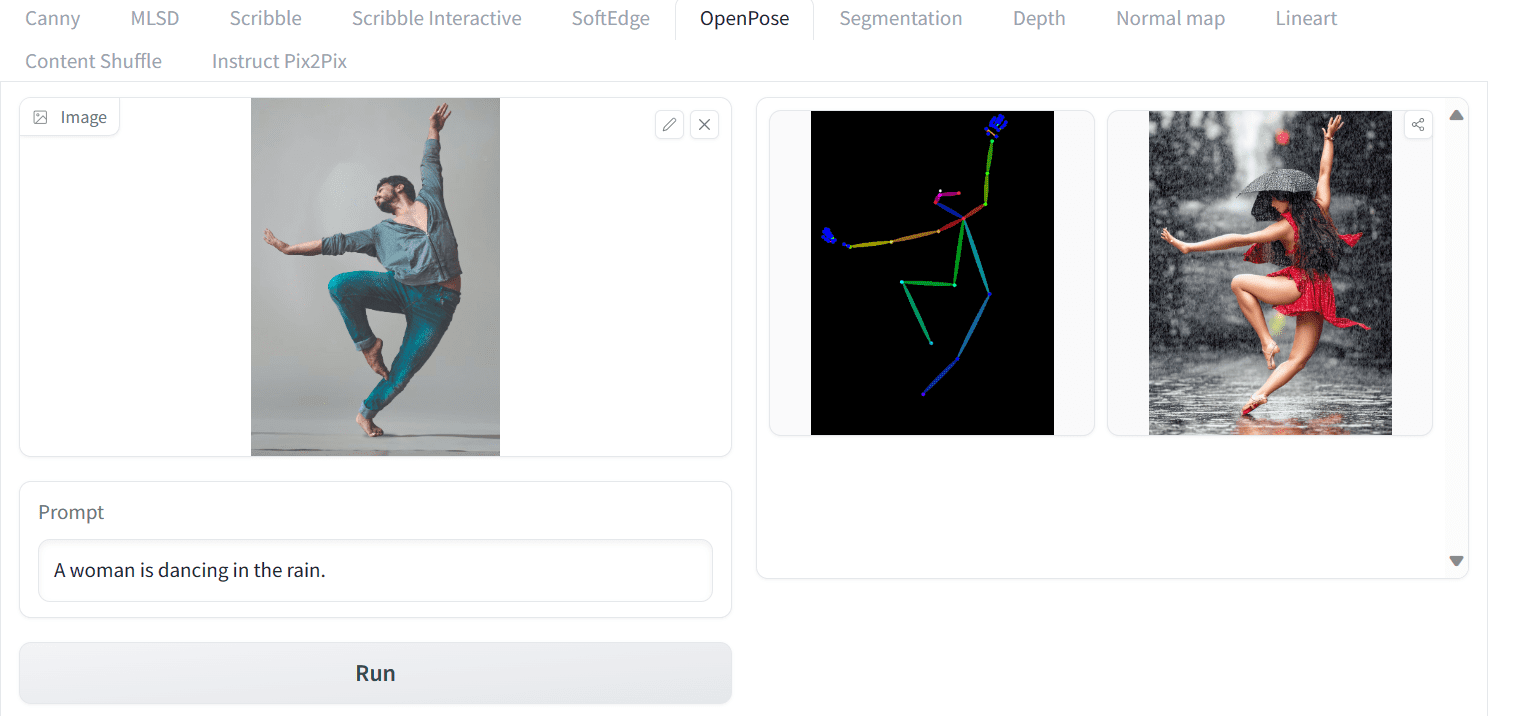
在 Hugging Face Spaces 上使用 OpenPose ControlNet 模型
由于图像生成的随机性,您可能需要进行多次尝试。您还可以润饰提示以提供更多细节,例如灯光、场景以及女人穿着的服装。您甚至可以展开底部的“高级选项”面板以提供更多设置,例如负面提示。
“高级选项”面板中的设置
在上面的示例中,您可以看到,根据骨骼图像生成了一张雨中跳舞的女人高品质图像,姿势与您上传的图像相似。以下是使用相同提示生成的另外三张图像,它们都很出色,并准确地遵循了参考图像的姿势。

来自同一提示的其他生成图像
Stable Diffusion Web UI 中的 OpenPose 编辑器
您还可以使用 Stable Diffusion Web UI 中的 OpenPose ControlNet 模型。实际上,您不仅可以上传图像来获取姿势,还可以在将其应用于扩散模型之前编辑姿势。在本节中,您将学习如何本地设置 OpenPose 并使用 OpenPose 编辑器生成图像。
在使用 OpenPose 编辑器之前,您必须安装它并下载模型文件。
- 请确保您已安装 ControlNet 扩展,如果没有,请查看之前的帖子。
- 安装 OpenPose Editor 扩展:在 WebUI 的“扩展”选项卡上,点击“从 URL 安装”并输入以下 URL 进行安装:
- https://github.com/fkunn1326/openpose-editor
- 访问 Hugging Face 仓库:https://hugging-face.cn/lllyasviel/ControlNet-v1-1/tree/main
- 下载 OpenPose 模型“control_v11p_sd15_openpose.pth”
- 将模型文件放在 SD WebUI 目录中的 stable-diffusion-webui/extensions/sd-webui-controlnet/models 或 stable-diffusion-webui/models/ControlNet 目录中。
现在您已经准备好所有设置,并且 Web UI 中会新增一个名为“OpenPose Editor”的选项卡。导航到“OpenPose Editor”选项卡,并根据您的喜好调整画布的宽度和高度。接下来,您可以使用鼠标修改右侧的骨骼图像。这是一个简单的过程。
让我们尝试创建一个男人持枪的图片。您可以修改骨骼图像,使其看起来像这样:
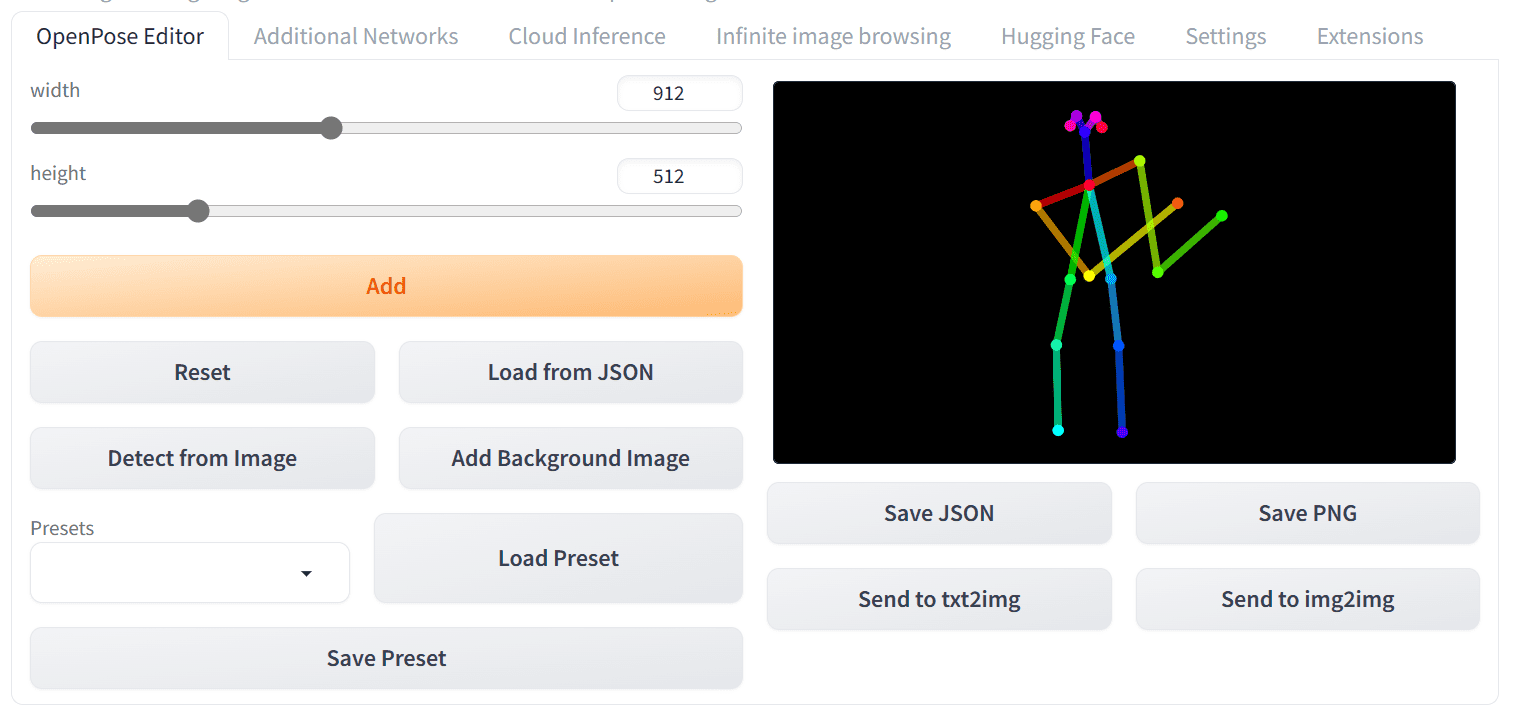
使用 OpenPose 编辑器创建姿势
然后,单击“发送到 text2img”按钮。它会将您带到 text2img 页面,并将骨骼图像添加到 ControlNet 面板中。
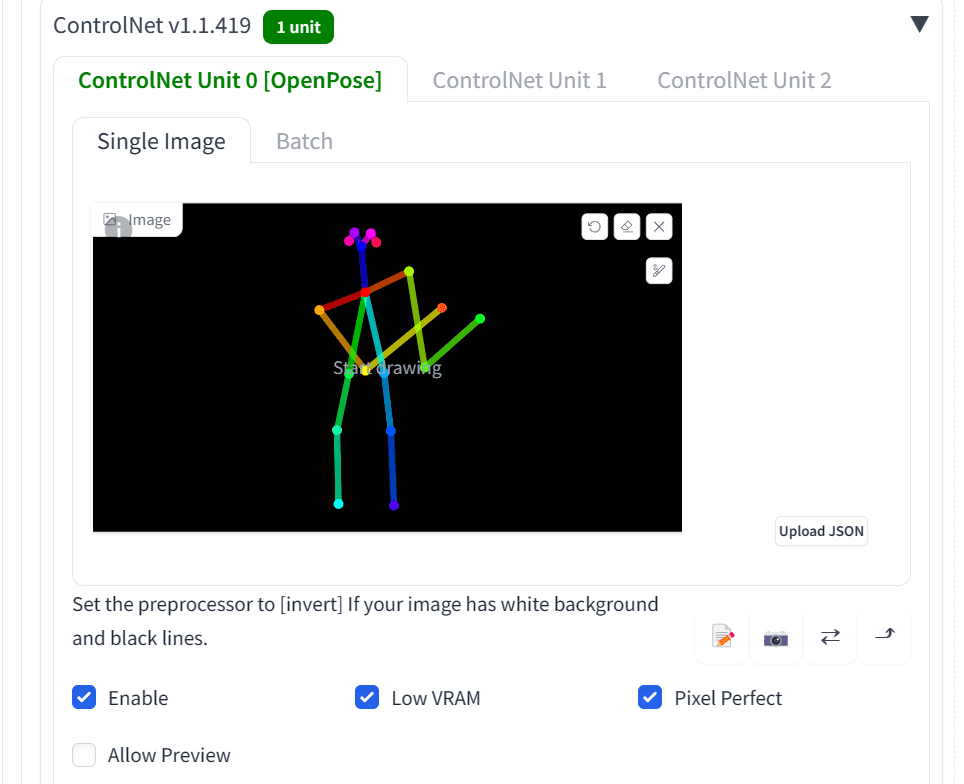
创建的姿势在 ControlNet 面板中
然后,选择此 ControlNet 模型的“启用”,并确保选中“OpenPose”选项。您还可以选中“低 VRAM”和“Pixel Perfect”。前者在您的计算机 GPU 内存不足时很有用,后者用于要求 ControlNet 模型使用最佳分辨率来匹配输出。
接下来,设置正面和负面提示,调整输出图像的大小、采样方法和采样步数。例如,正面提示可以是:
细节丰富,杰作,最佳质量,惊艳,迷人,引人注目,汤姆·克兰西的《全境封锁》,男人_持枪,美国海军陆战队员,海滩背景
负面提示可以是:
最差质量,低质量,低分辨率,单色,灰度,多视角,漫画,草图,解剖错误,变形,毁容,水印,多视角,手部变异,水印,面部不好
下图使用 912×512 的尺寸和 DDIM 采样器进行 30 步采样,生成了完美匹配相似姿势的图像,细节也很丰富。
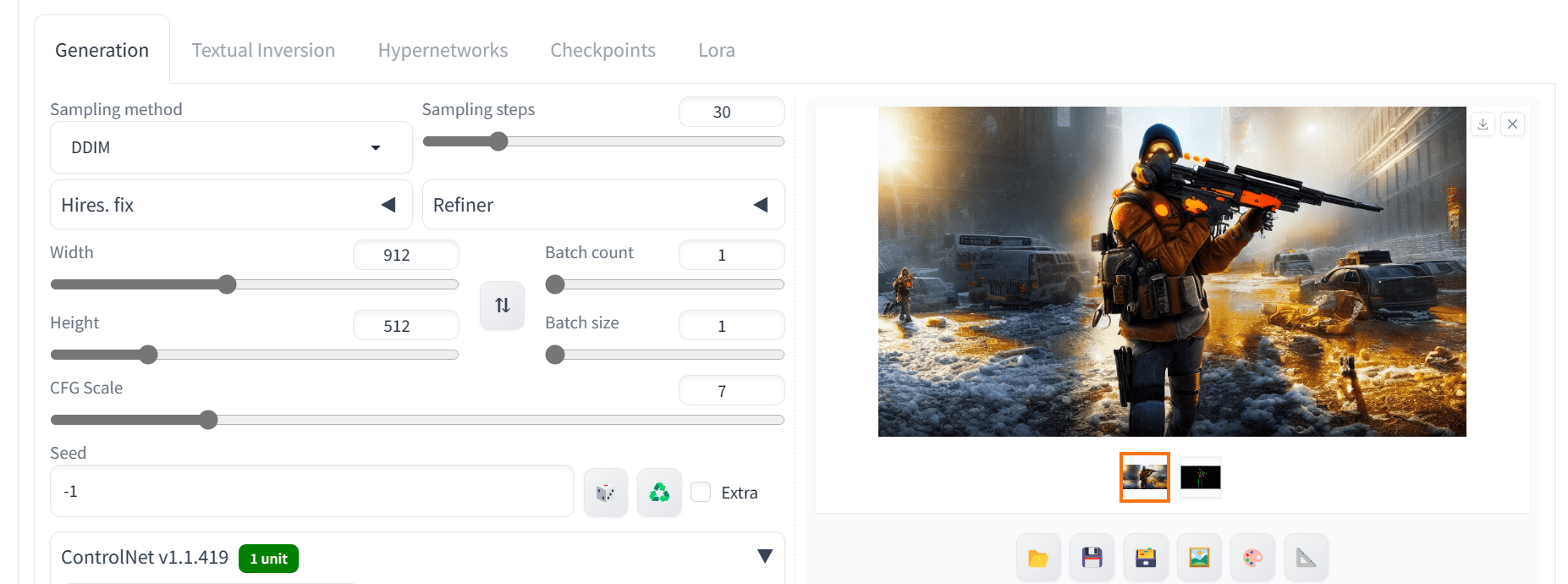
使用 OpenPose ControlNet 模型输出
图像到图像生成
如果您尝试了 Web UI 中的 ControlNet 模型,您应该会注意到有多个 OpenPose 预处理器。接下来,让我们探索其中的一些,以专注于面部和上半身。
我们将使用 Pexels.com 上的 Andrea Piacquadio 的照片作为参考图像。在 Web UI 中,切换到“img2img”选项卡并上传参考图像。然后在 ControlNet 面板中,启用并选择“OpenPose”作为控制类型。默认情况下,在 img2img 中,您会将参考图像共享给 ControlNet。接下来,在 ControNet 面板中,将预处理器更改为“openpose_face”,如下所示:
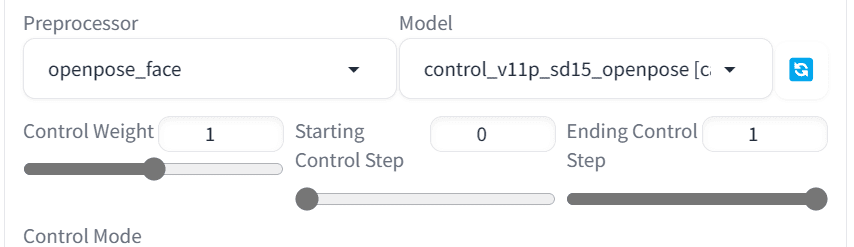
使用“openpose_face”作为预处理器
之后,设置正面提示以匹配参考图像的风格并生成图像。让我们让这个女人拿着手机,而不是拿着平板电脑。
细节丰富,最佳质量,惊艳,迷人,引人注目,纽约,建筑,城市,手机在耳边
下面是您可能会得到的结果:
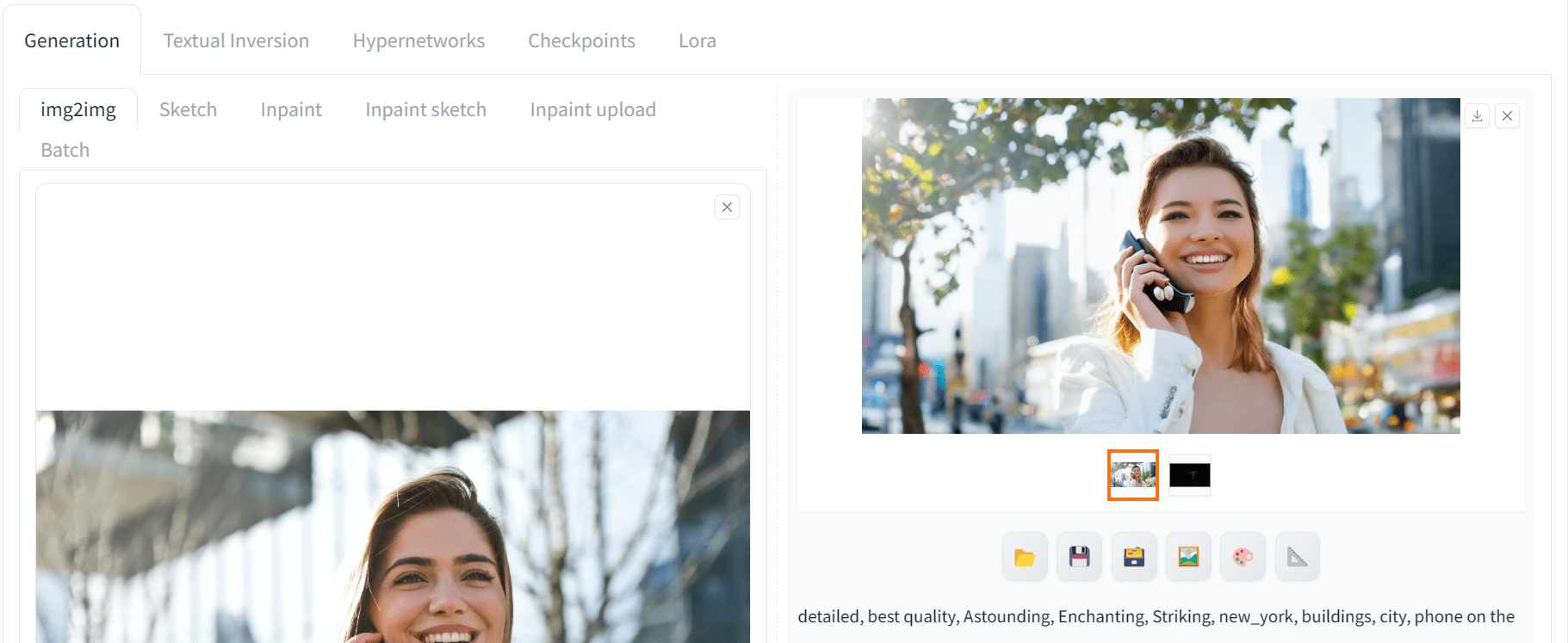
使用 img2img 生成的图像
我们获得了高质量的结果,姿势相似。您需要尝试不同的提示来匹配姿势。这里使用的预处理器是“openpose_face”,这意味着姿势和面部。因此,生成的图片在四肢位置和面部表情方面都与参考图像匹配。
让我们将预处理器更改为“openpose_faceonly”,以仅关注面部特征。这样,只有面部关键点会被识别,并且 ControlNet 模型不会应用任何关于身体姿势的信息。现在,将提示设置为:
细节丰富,最佳质量,惊艳,迷人,引人注目,纽约,建筑,城市
生成了改进后的结果,准确地遵循了提示中的每个关键字,但身体姿势与之前的图像大不相同。
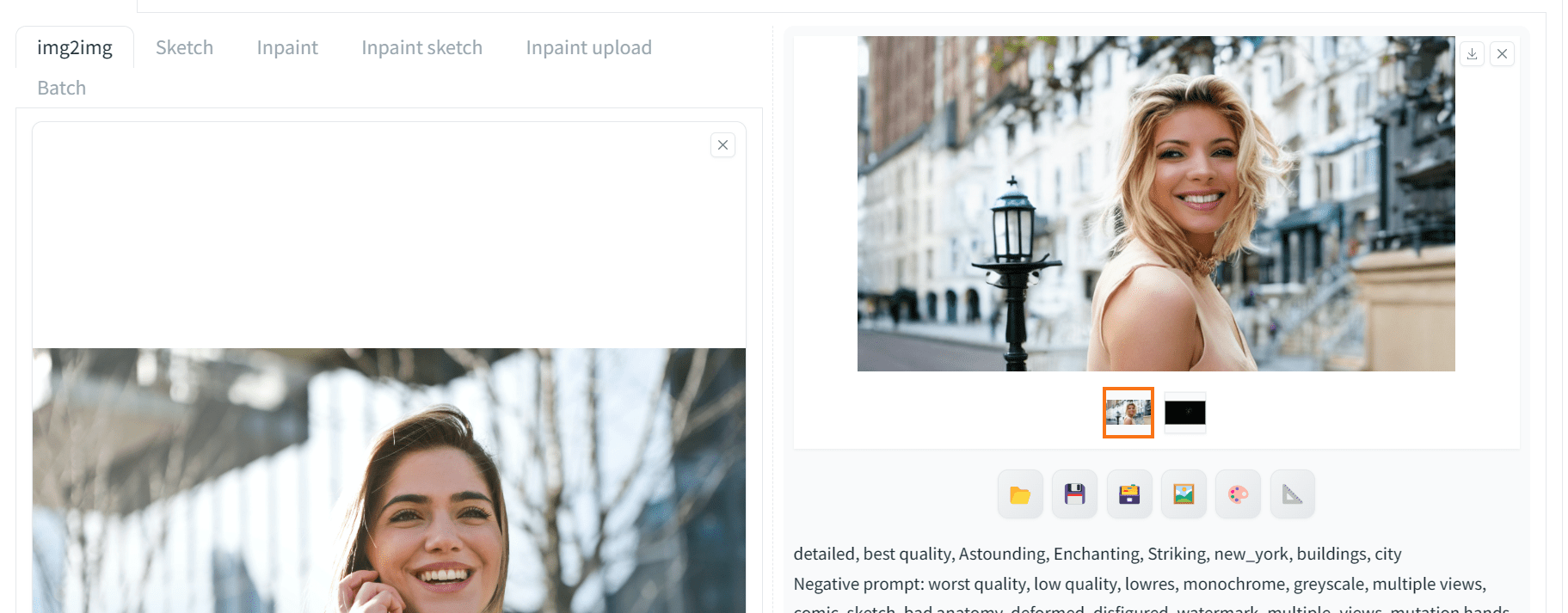
仅提供了面部关键点的 ControlNet 生成的图像
为了理解为什么会这样,您可以检查预处理器的输出图像,如下所示。上面的图像是使用“openpose_face”预处理器生成的,而下面的图像是使用“openpose_faceonly”生成的。同样,您可以通过分析骨骼结构来理解各种预处理器的输出。

来自不同 OpenPose 预处理器的关键点生成
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
- Cao 等人 (2019) 的 《OpenPose:使用部位亲和性字段进行实时多人二维姿势估计》
- GitHub 上的 OpenPose
- Hugging Face 上的 Controlnet – 人体姿势版本
- Openpose Controlnets (V1.1):使用姿势和生成新姿势
总结
在本帖中,我们深入探讨了 ControlNet OpenPose 的世界,以及如何使用它来获得精确的结果。具体来说,我们涵盖了:
- 什么是 OpenPose,以及它如何无需任何设置即可立即生成图像?
- 如何使用 Stable Diffusion WebUI 和 OpenPose 编辑器,通过修改提示和骨骼图像来生成自定义姿势的图像。
- 多种 OpenPose 预处理器,用于在 Stable Diffusion WebUI 中使用全脸和仅脸部预处理器生成图像。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
这本书提供了**自学教程**,包含所有**可运行的 Python 代码**,指导您从新手成长为图像生成专家。它教您如何*设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数*等等……所有这些都是为了帮助您创作令人惊叹的数字艺术。






暂无评论。