过拟合是预测模型性能不佳的常见解释。
通过分析学习动态,可以帮助识别模型是否过拟合了训练数据集,并可能建议使用替代配置以获得更好的预测性能。
对于像神经网络这样增量学习的算法,执行学习动态分析很简单,但对于像决策树、k-近邻和其他 scikit-learn 机器学习库中的通用算法这类不增量学习的算法,如何进行相同的分析尚不清楚。
在本教程中,您将了解如何在 Python 中识别机器学习模型的过拟合。
完成本教程后,您将了解:
- 过拟合是预测模型泛化性能不佳的可能原因。
- 可以通过改变关键模型超参数来分析机器学习模型的过拟合。
- 尽管过拟合是分析的有用工具,但它不应与模型选择混淆。
让我们开始吧。

使用 Scikit-Learn 识别过拟合的机器学习模型
照片作者:Bonnie Moreland,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 什么是过拟合
- 如何进行过拟合分析
- Scikit-Learn 中过拟合的示例
- Scikit-Learn 中过拟合的反例
- 将过拟合分析与模型选择分开
什么是过拟合
过拟合是指用于预测建模的机器学习算法的一种不受欢迎的行为。
即模型在训练数据集上的性能有所提高,但代价是模型在训练期间未见过的数据(例如保留的测试数据集或新数据)上的性能变差。
我们可以通过首先在训练数据集上评估模型,然后在保留的测试数据集上评估同一模型来识别机器学习模型是否过拟合。
如果模型在训练数据集上的性能明显优于在测试数据集上的性能,则该模型可能过拟合了训练数据集。
我们关心过拟合,因为它通常是模型“泛化能力差”的原因,这通过较高的“泛化误差”来衡量。即模型在对新数据进行预测时产生的误差。
这意味着,如果我们的模型性能不佳,可能是因为它过拟合了。
但是,如果模型在训练集上的性能比在测试集上的性能“明显更好”意味着什么?
例如,模型在训练集上的性能优于在测试集上的性能是很常见甚至可能正常的。
因此,我们可以对算法在数据集上的表现进行分析,以更好地揭示过拟合行为。
如何进行过拟合分析
过拟合分析是一种探索特定模型在特定数据集上如何以及何时发生过拟合的方法。
它是一种可以帮助您更多地了解机器学习模型学习动态的工具。
这可以通过审查像神经网络这样在训练数据集上增量拟合的算法在单次运行期间的模型行为来实现。
可以计算模型在训练集和测试集上的性能图,并在训练的每个点进行绘制。此图通常称为学习曲线图,为每个学习增量显示训练集上的模型性能曲线和测试集上的模型性能曲线。
如果您想了解更多关于增量学习算法的学习曲线,请参阅教程
过拟合的常见模式可以在学习曲线图上看到,其中模型在训练数据集上的性能持续提高(例如,损失或错误持续下降,或准确率持续上升),而在测试集或验证集上的性能先是提高然后开始变差。
如果观察到此模式,则对于增量学习的算法,应在测试集或验证集性能开始变差的点停止训练。
这对于像神经网络这样的增量学习算法是合理的,但对于其他算法呢?
- 如何对 scikit-learn 中的机器学习算法进行过拟合分析?
对于不增量学习的算法进行过拟合分析的一种方法是改变关键的模型超参数,并为每种配置评估模型在训练集和测试集上的性能。
为了说清楚这一点,让我们在下一节中探讨一个分析模型过拟合的案例。
Scikit-Learn 中过拟合的示例
在本节中,我们将研究一个机器学习模型过拟合训练数据集的示例。
首先,让我们定义一个合成分类数据集。
我们将使用 make_classification() 函数 来定义一个具有 10,000 个示例(行)和 20 个输入特征(列)的二分类(两类)预测问题。
下面的示例创建了数据集,并总结了输入和输出组件的形状。
|
1 2 3 4 5 6 |
# 合成分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=5, n_redundant=15, random_state=1) # 汇总数据集 print(X.shape, y.shape) |
运行示例创建了数据集并报告了形状,确认了我们的预期。
|
1 |
(10000, 20) (10000,) |
接下来,我们需要将数据集划分为训练集和测试集。
我们将使用 train_test_split() 函数,并将数据划分为 70% 用于训练模型,30% 用于评估。
|
1 2 3 4 5 6 7 8 9 |
# 将数据集划分为训练集和测试集 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split # 创建数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=5, n_redundant=15, random_state=1) # 拆分为训练测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 总结训练集和测试集的形状 print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) |
运行示例将数据集划开,我们可以确认我们有 7000 个训练样本和 3000 个评估样本。
|
1 |
(7000, 20) (3000, 20) (7000,) (3000,) |
接下来,我们可以探索一个机器学习模型过拟合训练数据集的场景。
我们将使用 DecisionTreeClassifier 来构建决策树,并通过“max_depth”参数测试不同的树深度。
浅决策树(例如,层数少)通常不会过拟合,但性能较差(高偏差,低方差)。而深决策树(例如,层数多)通常会过拟合,并且性能良好(低偏差,高方差)。理想的树是不那么浅以至于技能低下,也不那么深以至于过拟合训练数据集。
我们评估深度为 1 到 20 的决策树。
|
1 2 3 |
... # 定义要评估的树深度 values = [i for i in range(1, 21)] |
我们将遍历每个树深度,用给定深度的树在训练数据集上拟合,然后评估该树在训练集和测试集上的表现。
预期是随着树深度的增加,在训练集和测试集上的性能都会有所提高,直到树变得太深,它会开始过拟合训练数据集,导致在保留的测试集上的性能变差。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
... # 评估每个深度的决策树 for i in values: # 配置模型 model = DecisionTreeClassifier(max_depth=i) # 在训练数据集上拟合模型 model.fit(X_train, y_train) # 在训练数据集上评估 train_yhat = model.predict(X_train) train_acc = accuracy_score(y_train, train_yhat) train_scores.append(train_acc) # 在测试数据集上评估 test_yhat = model.predict(X_test) test_acc = accuracy_score(y_test, test_yhat) test_scores.append(test_acc) # 总结进度 print('>%d, train: %.3f, test: %.3f' % (i, train_acc, test_acc)) |
运行结束后,我们将绘制所有模型在训练集和测试集上的准确率得分,以便进行可视化比较。
|
1 2 3 4 5 6 |
... # 训练和测试得分与树深度的关系图 pyplot.plot(values, train_scores, '-o', label='Train') pyplot.plot(values, test_scores, '-o', label='Test') pyplot.legend() pyplot.show() |
将所有内容整合在一起,探索合成二分类数据集上不同树深度的完整示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 评估决策树在不同树深度下的训练集和测试集性能 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier from matplotlib import pyplot # 创建数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=5, n_redundant=15, random_state=1) # 拆分为训练测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 定义用于收集得分的列表 train_scores, test_scores = list(), list() # 定义要评估的树深度 values = [i for i in range(1, 21)] # 评估每个深度的决策树 for i in values: # 配置模型 model = DecisionTreeClassifier(max_depth=i) # 在训练数据集上拟合模型 model.fit(X_train, y_train) # 在训练数据集上评估 train_yhat = model.predict(X_train) train_acc = accuracy_score(y_train, train_yhat) train_scores.append(train_acc) # 在测试数据集上评估 test_yhat = model.predict(X_test) test_acc = accuracy_score(y_test, test_yhat) test_scores.append(test_acc) # 总结进度 print('>%d, train: %.3f, test: %.3f' % (i, train_acc, test_acc)) # 训练和测试得分与树深度的关系图 pyplot.plot(values, train_scores, '-o', label='Train') pyplot.plot(values, test_scores, '-o', label='Test') pyplot.legend() pyplot.show() |
运行示例,对每个树深度在训练集和测试集上拟合和评估决策树,并报告准确率得分。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的 结果可能会有所不同。请考虑运行示例几次并比较平均结果。
在这种情况下,我们可以看到训练数据集上的准确率随着树深度的增加而增加,直到大约 19-20 个层级,此时树完美拟合训练数据集。
我们还可以看到,测试集上的准确率随着树深度的增加而提高,直到大约八九个层级,之后随着树深度的增加,准确率开始变差。
这正是我们期望在过拟合模式中看到的。
我们将在模型开始过拟合训练数据集之前选择一个八到九个层级的树深度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
>1, train: 0.769, test: 0.761 >2, train: 0.808, test: 0.804 >3, train: 0.879, test: 0.878 >4, train: 0.902, test: 0.896 >5, train: 0.915, test: 0.903 >6, train: 0.929, test: 0.918 >7, train: 0.942, test: 0.921 >8, train: 0.951, test: 0.924 >9, train: 0.959, test: 0.926 >10, train: 0.968, test: 0.923 >11, train: 0.977, test: 0.925 >12, train: 0.983, test: 0.925 >13, train: 0.987, test: 0.926 >14, train: 0.992, test: 0.921 >15, train: 0.995, test: 0.920 >16, train: 0.997, test: 0.913 >17, train: 0.999, test: 0.918 >18, train: 0.999, test: 0.918 >19, train: 1.000, test: 0.914 >20, train: 1.000, test: 0.913 |
还创建了一个图,显示了模型在不同树深度下在训练集和测试集上的准确率的折线图。
该图清楚地显示,在早期阶段增加树深度会导致训练集和测试集上的准确率相应提高。
这种情况持续到大约 10 个层级的深度,之后模型显示出过拟合训练数据集,但代价是保留数据集上的性能变差。
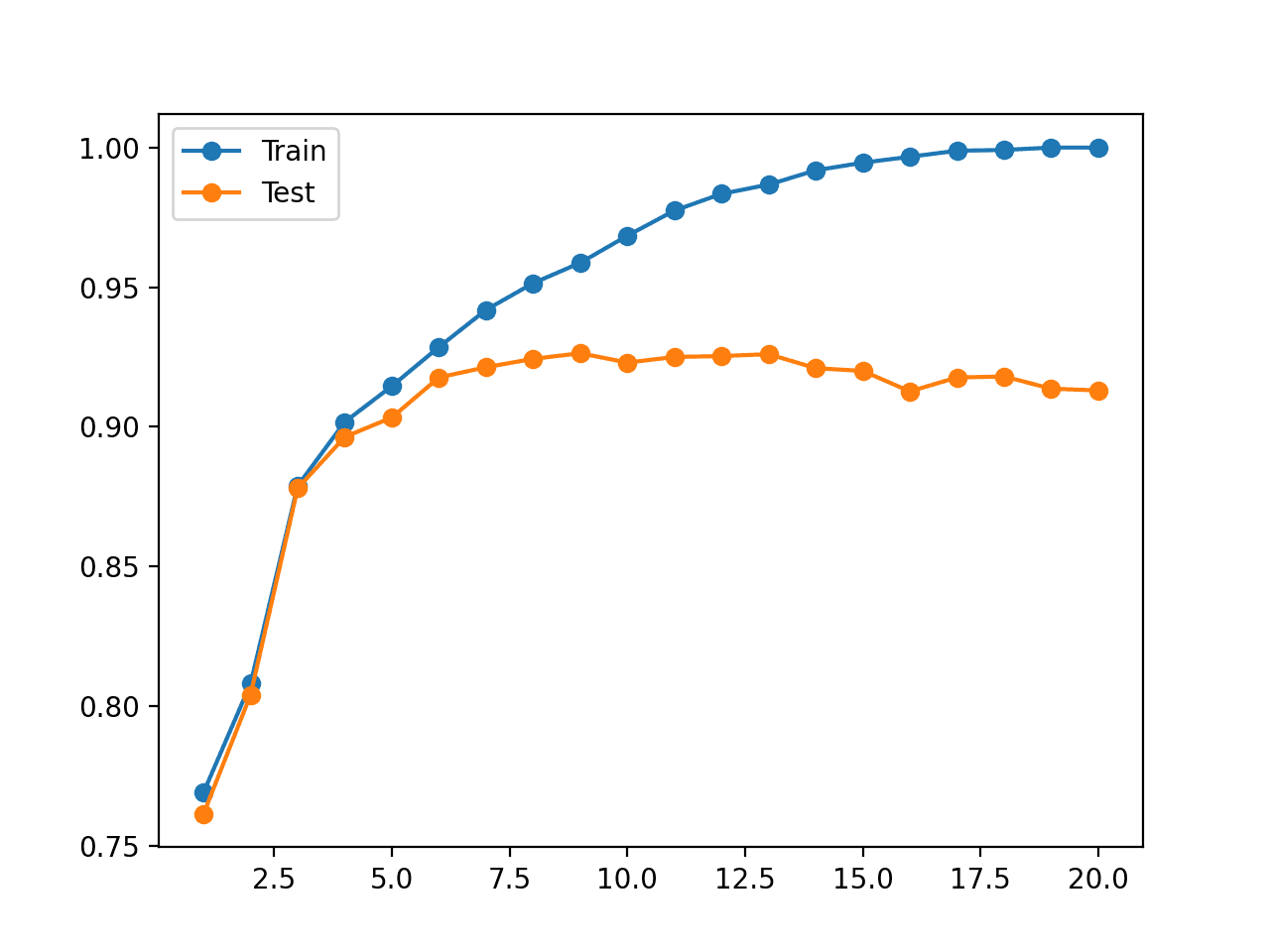
不同树深度下决策树在训练集和测试集上的准确率折线图
这个分析很有趣。它说明了为什么当“max_depth”设置为较大值时,模型在保留的测试集上的性能会变差。
但这并非必需。
我们可以通过网格搜索轻松选择“max_depth”,而无需分析为什么某些值会产生更好的性能,而另一些值会产生更差的性能。
事实上,在下一节中,我们将展示此分析可能具有误导性。
Scikit-Learn 中过拟合的反例
有时,我们可能会对机器学习模型行为进行分析,但被结果所欺骗。
一个很好的例子是改变 k-近邻算法的邻居数量,我们可以使用 KNeighborsClassifier 类来实现,并通过“n_neighbors”参数进行配置。
暂时忘记 KNN 是如何工作的。
我们可以像在上一节为决策树所做的那样,对 KNN 算法进行相同的分析,看看我们的模型是否会在不同的配置值下过拟合。在这种情况下,我们将邻居数量从 1 更改为 50,以获得更明显的效果。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 评估 KNN 在不同邻居数量下的训练集和测试集性能 from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.neighbors import KNeighborsClassifier from matplotlib import pyplot # 创建数据集 X, y = make_classification(n_samples=10000, n_features=20, n_informative=5, n_redundant=15, random_state=1) # 拆分为训练测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 定义用于收集得分的列表 train_scores, test_scores = list(), list() # 定义要评估的树深度 values = [i for i in range(1, 51)] # 评估每个深度的决策树 for i in values: # 配置模型 model = KNeighborsClassifier(n_neighbors=i) # 在训练数据集上拟合模型 model.fit(X_train, y_train) # 在训练数据集上评估 train_yhat = model.predict(X_train) train_acc = accuracy_score(y_train, train_yhat) train_scores.append(train_acc) # 在测试数据集上评估 test_yhat = model.predict(X_test) test_acc = accuracy_score(y_test, test_yhat) test_scores.append(test_acc) # 总结进度 print('>%d, train: %.3f, test: %.3f' % (i, train_acc, test_acc)) # 邻居数量与训练集和测试集得分的折线图 pyplot.plot(values, train_scores, '-o', label='Train') pyplot.plot(values, test_scores, '-o', label='Test') pyplot.legend() pyplot.show() |
运行示例,对每个邻居数量在训练集和测试集上拟合和评估 KNN 模型,并报告准确率得分。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的 结果可能会有所不同。请考虑运行示例几次并比较平均结果。
回想一下,我们正在寻找一种模式,即测试集上的性能先是提高,然后开始变差,而训练集上的性能则持续提高。
我们没有看到这种模式。
相反,我们看到训练数据集上的准确率从完美准确率开始,并随着邻居数量的增加而下降。
我们还看到,模型在保留的测试集上的性能在大约五个邻居时有所提高,然后保持平稳,之后开始下降。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
>1, train: 1.000, test: 0.919 >2, train: 0.965, test: 0.916 >3, train: 0.962, test: 0.932 >4, train: 0.957, test: 0.932 >5, train: 0.954, test: 0.935 >6, train: 0.953, test: 0.934 >7, train: 0.952, test: 0.932 >8, train: 0.951, test: 0.933 >9, train: 0.949, test: 0.933 >10, train: 0.950, test: 0.935 >11, train: 0.947, test: 0.934 >12, train: 0.947, test: 0.933 >13, train: 0.945, test: 0.932 >14, train: 0.945, test: 0.932 >15, train: 0.944, test: 0.932 >16, train: 0.944, test: 0.934 >17, train: 0.943, test: 0.932 >18, train: 0.943, test: 0.935 >19, train: 0.942, test: 0.933 >20, train: 0.943, test: 0.935 >21, train: 0.942, test: 0.933 >22, train: 0.943, test: 0.933 >23, train: 0.941, test: 0.932 >24, train: 0.942, test: 0.932 >25, train: 0.942, test: 0.931 >26, train: 0.941, test: 0.930 >27, train: 0.941, test: 0.932 >28, train: 0.939, test: 0.932 >29, train: 0.938, test: 0.931 >30, train: 0.938, test: 0.931 >31, train: 0.937, test: 0.931 >32, train: 0.938, test: 0.931 >33, train: 0.937, test: 0.930 >34, train: 0.938, test: 0.931 >35, train: 0.937, test: 0.930 >36, train: 0.937, test: 0.928 >37, train: 0.936, test: 0.930 >38, train: 0.937, test: 0.930 >39, train: 0.935, test: 0.929 >40, train: 0.936, test: 0.929 >41, train: 0.936, test: 0.928 >42, train: 0.936, test: 0.929 >43, train: 0.936, test: 0.930 >44, train: 0.935, test: 0.929 >45, train: 0.935, test: 0.929 >46, train: 0.934, test: 0.929 >47, train: 0.935, test: 0.929 >48, train: 0.934, test: 0.929 >49, train: 0.934, test: 0.929 >50, train: 0.934, test: 0.929 |
还创建了一个图,显示了模型在不同邻居数量下在训练集和测试集上的准确率的折线图。
这些图使情况更加清晰。看起来训练集的折线图正在下降以与测试集的折线图趋同。事实上,这正是发生的情况。
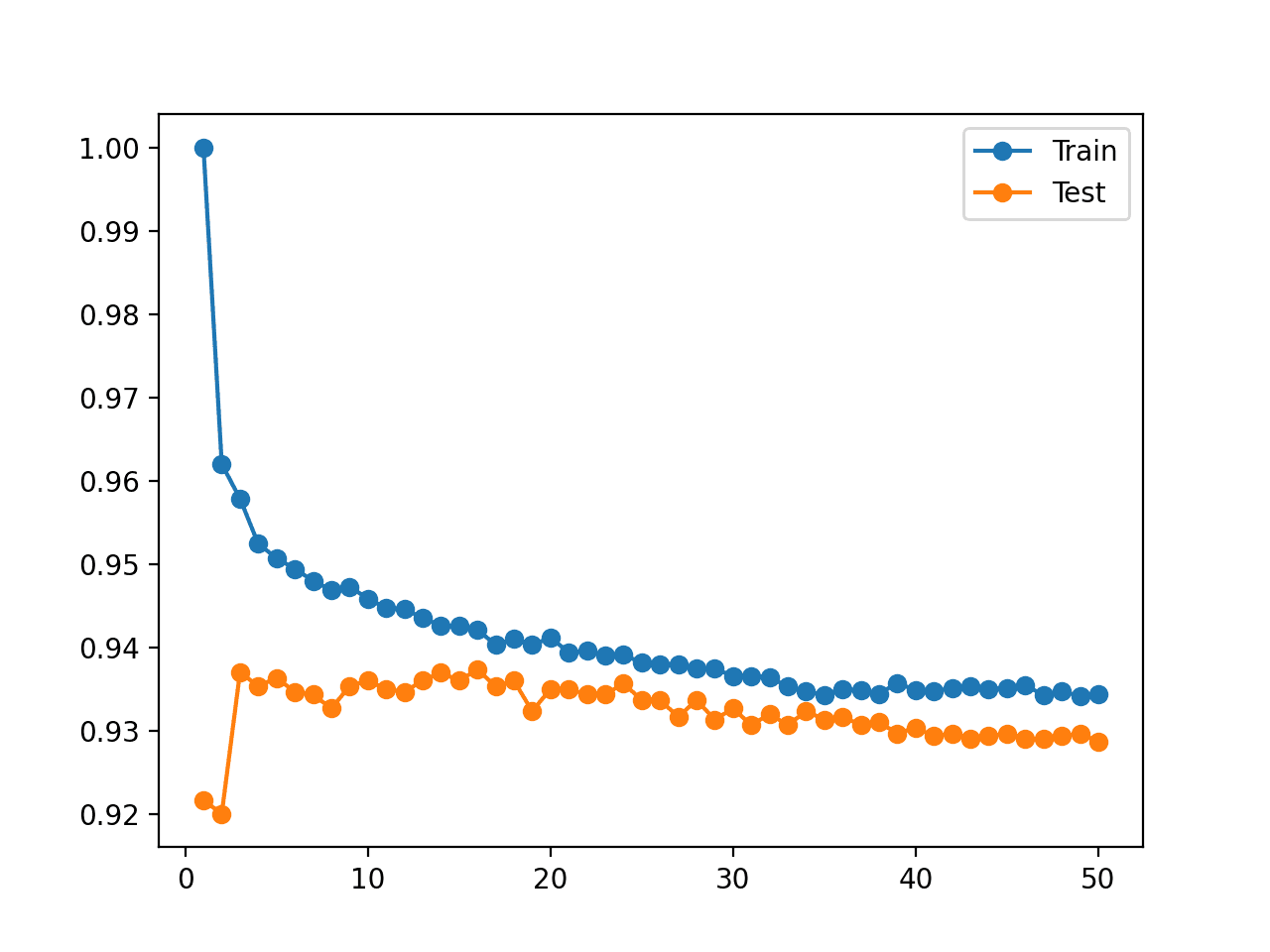
不同邻居数量下 KNN 在训练集和测试集上的准确率折线图
现在,回想一下 KNN 的工作原理。
“模型”实际上只是将整个训练数据集存储在一个高效的数据结构中。模型在训练数据集上的技能应该是 100%,任何更低都是不可原谅的。
事实上,这个论点对于任何机器学习算法都成立,并且触及了初学者对过拟合的困惑的核心。
将过拟合分析与模型选择分开
过拟合可能是预测模型性能不佳的解释。
创建学习曲线图,显示模型在训练集和测试集上的学习动态,对于更多地了解模型在数据集上的表现很有帮助。
但是不应将过拟合与模型选择混淆。
我们根据预测模型的样本外性能来选择模型或模型配置。也就是说,它在训练期间未见过的新数据上的性能。
我们这样做的原因是,在预测建模中,我们主要关心的是能够做出有技能的预测的模型。我们希望在可用时间和计算资源的情况下,能够做出最佳预测的模型。
这可能意味着我们选择一个看起来过拟合了训练数据集的模型。在这种情况下,过拟合分析可能具有误导性。
这也可能意味着模型在训练数据集上的性能很差或非常差。
总的来说,如果我们在模型选择中关心模型在训练数据集上的性能,那么我们期望模型在训练数据集上具有完美的性能。这是我们可用的数据;我们不应容忍任何低于此的。
正如我们在上面的 KNN 示例中所看到的,我们可以通过存储训练集并使用一个邻居返回预测来实现训练集的完美性能,但代价是任何新数据上的性能不佳。
- 一个在训练集和测试集上都表现良好的模型是否会是更好的模型?
也许。但也许不是。
这个论点基于这样的想法:一个在训练集和测试集上都表现良好的模型对底层问题有更好的理解。
一个推论是,一个在测试集上表现良好但在训练集上表现不佳的模型是幸运的(例如,统计上的偶然),而一个在训练集上表现良好但在测试集上表现不佳的模型是过拟合的。
我相信这是初学者经常问如何修复他们 scikit-learn 机器学习模型过拟合问题的症结所在。
令人担心的是,模型必须在训练集和测试集上都表现良好,否则他们就麻烦了。
事实并非如此.
在模型选择过程中,训练集上的性能并不重要。在选择预测模型时,您必须只关注样本外性能。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
API
- sklearn.datasets.make_classification API.
- sklearn.model_selection.train_test_split API.
- sklearn.tree.DecisionTreeClassifier API.
- sklearn.neighbors.KNeighborsClassifier API.
文章
总结
在本教程中,您了解了如何在 Python 中识别机器学习模型的过拟合。
具体来说,你学到了:
- 过拟合是预测模型泛化性能不佳的可能原因。
- 可以通过改变关键模型超参数来分析机器学习模型的过拟合。
- 尽管过拟合是分析的有用工具,但它不应与模型选择混淆。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。






嗨,Jason,
一个关于梯度下降的问题。它适用于分类和回归吗?它也适用于机器学习(浅层)和深度学习吗?
谢谢,
Marco
是的,SGD 可用于分类和回归。
嗨,Jason,
使用机器学习或深度学习可以对声音进行分类吗?您有示例吗?
您有 Keras 函数式 API 的示例吗?
谢谢,Marco
是的。
抱歉,我没有这方面的例子。
是的,这里有一个关于函数式 API 的教程
https://machinelearning.org.cn/keras-functional-api-deep-learning/
我觉得这句话有点问题
“如果观察到此模式,则对于增量学习的算法,应在训练集性能开始变差的点停止训练”
摘自“如何进行过拟合分析”部分
我认为我们应该在测试集性能开始下降时停止训练,而不是如上所述的训练集。
如果我的理解是错误的,请告诉我。
同意。看起来是个笔误。已修正,谢谢。
您的博客非常棒,内容也非常丰富。我很好奇,想知道为什么您的博客很少使用真实世界的数据集。在我看来,真实世界的数据集更有意义,能提供更宏观的视角。大多数博主会使用鸢尾花数据集或一些随机数 0 到 10000,这些如何能与现实世界的情景相关联呢?您是博士,我相信您能做得更好。
感谢您的反馈。
在简单的人工数据集上解释和理解算法更容易。博客上也有很多关于真实数据集的项目——或许可以尝试搜索一下博客。
我认为测试误差总是高于训练误差。请检查您的图示。请记住,在未见过的数据上,误差肯定会更高。我随时接受指正。
嗨,Jason!我真的很喜欢这篇帖子。感谢您的辛勤工作。
我完全同意您关于在模型选择过程中训练集上的性能无关紧要的观点。
但是,您认为在什么情况下它会非常相关呢?也许,当您试图发现过拟合时。
但是,假设您的学习曲线中 e_test<e_train,如果您的 e_test 已经足够好,您是否仍然会关心并尝试降低 e_train?
如果您的 e_test 已经足够好,您是否仍然会关心并尝试降低 e_train?您能否想到其他应该关注的情况?
当 e_test 已经足够好时,您应该关注尝试改进 e_train 的其他情况?您何时应该关注 e_train?
谢谢。
在拟合增量学习模型(如神经网络)时,它很重要。请看这篇。
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
“运行示例会拆分数据集,我们可以确认我们有 70,000 个样本用于训练和 30,000 个用于评估模型。”
您一定修改了代码,因为它是 7,000 个和 3,000 个,是吧?
谢谢!已修复。
嘿,杰森!
我正在处理一个多类分类问题,我应该先进行模型选择,然后检查选定的模型是欠拟合还是过拟合,然后可能进行特征选择或添加一些新特征,最后进行超参数调优并在测试集上测试最终模型吗?您有什么建议?
嗨 Asiwach……以下资源或许能通过示例来帮助您阐明。
https://machinelearning.org.cn/multi-label-classification-with-deep-learning/
您好!如果我考虑,比如说,1000 个模型,那么在测试集上表现最好的模型是否有可能偶然地过拟合了测试集?而我会在另一个未见过的数据集上选择了不同的模型?
这是有可能的。
尝试重复的 k 折交叉验证来代替模型选择。
谢谢!
不客气!
嗨,Jason!
人们常说机器学习的黄金法则是测试数据不应以任何方式影响学习过程。但在涉及决策树分类器的示例中,您使用了测试集来调整 max_depth 超参数。这是否违反了那个黄金法则?
如果我有什么误解,请告诉我!谢谢!
是的,我特意在某些情况下重用了数据,以使算法示例简单易懂。
https://machinelearning.org.cn/faq/single-faq/why-do-you-use-the-test-dataset-as-the-validation-dataset
非常好的文章,谢谢!我想知道这对于 DecisionTreeRegressor 而不是分类问题会是什么样的。
您会改变树的深度。
您好!非常感谢这篇有用的文章。我想知道如何评估 SVM 模型的过拟合和欠拟合,您有涵盖这方面的内容的文章吗?
也许您可以为您选择的模型调整上述示例。
您好!首先,感谢这篇文章。它对我的帮助很大!
我正在处理一个在训练数据集上严重过拟合的模型(ROC AUC 和 PR AUC 接近 1.0),并在测试集上略有下降,在两者上都得到约 0.70 的结果。对于我正在处理的问题,这些 PR AUC 和 ROC AUC 的测试值是可以的,但因为训练数据上的高指标我需要担心吗?我正在使用 extra
trees classifier,并且它们非常深。
谢谢!
高指标不是问题,但测试指标与训练指标相差甚远才是。应该说,测试指标是我们预期在实际部署模型时会看到的值。训练指标仅用于指导您的训练过程。我们不希望的是,我们不断训练和改进训练指标,而测试指标却越来越差。
嗨,Jason。我创建了一个 CNN 模型来预测云图像,它过拟合了。但我对您的陈述感到有些困惑
“在模型选择过程中,训练集上的性能并不重要。在选择预测模型时,您必须只关注样本外性能。”
您能向我解释一下吗?为什么在模型选择过程中训练集上的性能不重要?这是否意味着我们需要使测试集比训练集更好?
嗨 Fikri……有些模型可以很好地学习训练数据,但在实际应用中表现不佳。模型必须根据其在测试和验证数据上的性能来选择。
嗨,Jason,
我读过您以前的许多博客,您通过这些博客所做的内容和工作的质量非常值得称赞。
但是这篇博客的阅读和理解难度很大,我认为您在 KNN 和模型选择方面的一些描述缺乏图示,这给我带来了很多困惑。即使在我认为自己已经超越初学者,拥有数据科学行业的教育背景、技能和经验的情况下也是如此。
如果您计划逐步改进这篇博客,请告诉我,因为我认为有很多疑问和高质量的面试问题可能会围绕这些概念出现。
嗨 Achint……感谢您的反馈!
非常棒的文章。测试集的大小对测试学习曲线有什么影响?我猜想,测试集越大,您对模型泛化能力的评估就越准确。
嗨 Ben……您说得对。如果处理得当,更大的数据集可能有助于您的模型更好地泛化。
以下内容可能有助于阐明。
https://machinelearning.org.cn/improve-model-accuracy-with-data-pre-processing/
感谢这篇文章。我想知道是否可以为回归问题绘制它?并且我正在努力比较不同的回归模型。比如说,我们在同一个数据集上尝试了 linearregression、decisiontreeregression、randomforestregression 和 GradientBoostingRegressor 模型,并决定了哪个模型性能更好,但由于笔记本上的代码可能很长,人们可能不会去读,或者根本不 bother。我们如何将它们一起绘制,或许作为时间线?我看到很多 TensorFlow 模型训练的例子,但没有找到 Scikit-learn 或这些模型的例子。谢谢您的回复。
嗨 Elandil2……要比较回归模型的性能,您可能需要考虑各种指标,例如以下资源中的。
https://machinelearning.org.cn/regression-metrics-for-machine-learning/
嗨 Jason,我正在使用 1D CNN,输入是 1D 波形,输出是两个数字的数组。训练准确率在每个 epoch 后都在增加,但无论我怎么做,验证准确率都无法从大约 0.5 提高。我尝试了各种方法,例如增加数据集、不同的架构等等,但都没有用。
嗨 Chinthak……以下内容可能对您有帮助。
https://machinelearning.org.cn/improve-deep-learning-performance/
https://machinelearning.org.cn/how-to-improve-deep-learning-model-robustness-by-adding-noise/
很棒的材料,Jason!
这篇(文章)太棒了,就像您网站上的所有其他文章一样。
您的网站对我来说就像一个金矿。
非常有帮助,阐明了困难的概念。
非常感谢您的慷慨!
感谢您的支持和反馈!我们非常感谢!