原始的机器学习数据包含多种属性,其中一些与进行预测相关。
你如何知道该使用哪些特征以及该删除哪些特征?在数据中选择特征以建模你的问题的过程称为特征选择。
在这篇文章中,你将了解如何在Weka中对机器学习数据执行特征选择。
阅读本文后,您将了解
- 关于在处理机器学习问题时特征选择的重要性。
- Weka平台如何支持特征选择。
- 如何在Weka中对你的数据集使用各种不同的特征选择技术。
使用我的新书《Weka机器学习精通》启动你的项目,其中包含所有示例的逐步教程和清晰的屏幕截图。
让我们开始吧。
- 2018年3月更新:添加了替代链接以下载数据集,因为原始链接似乎已被删除。

如何在 Weka 中对机器学习数据进行特征选择
图片由Peter Gronemann提供,保留部分权利。
预测糖尿病发病
本示例使用的数据集是Pima印第安人糖尿病发病数据集。
这是一个分类问题,每个实例代表一个患者的医疗详细信息,任务是预测该患者是否会在未来五年内患上糖尿病。
你可以在此处了解更多关于此数据集的信息:
你还可以在Weka安装的`data/`目录下找到名为`diabetes.arff`的此数据集。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
Weka中的特征选择
Weka支持许多特征选择技术。
在Weka中探索特征选择的一个好起点是Weka Explorer。
- 打开Weka GUI选择器。
- 点击“Explorer”按钮启动Explorer。
- 打开Pima印第安人数据集。
- 点击“Select attributes”选项卡以访问特征选择方法。
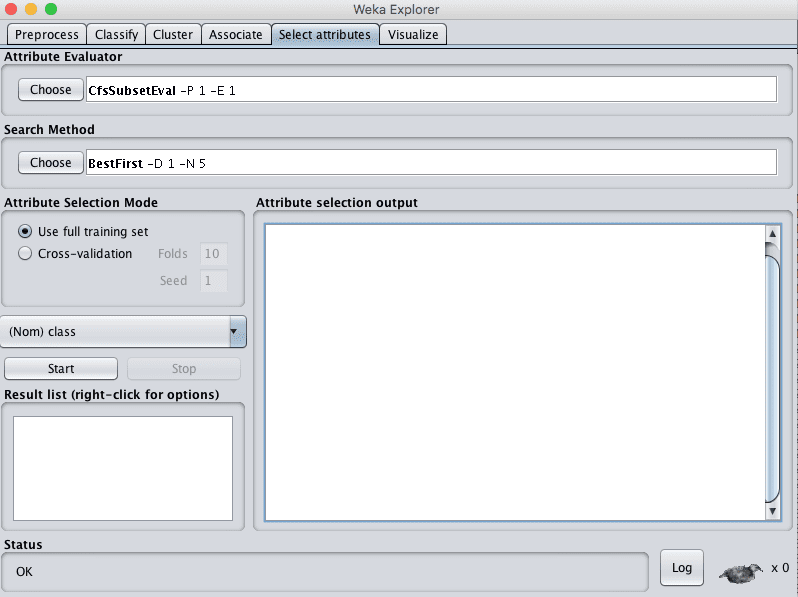
Weka特征选择
特征选择分为两个部分:
- 属性评估器
- 搜索方法。
每个部分都有多种技术可供选择。
属性评估器是评估数据集中每个属性(也称为列或特征)相对于输出变量(例如,类别)的技术。搜索方法是尝试或导航数据集中不同属性组合的技术,以便得出选定特征的简短列表。
一些属性评估器技术需要使用特定的搜索方法。例如,下一节中使用的CorrelationAttributeEval技术只能与Ranker搜索方法一起使用,后者评估每个属性并按排名顺序列出结果。在选择不同的属性评估器时,界面可能会要求你将搜索方法更改为与所选技术兼容的方法。
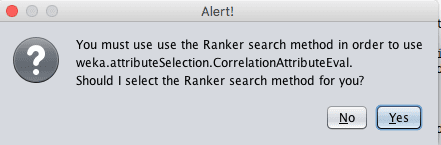
Weka特征选择警告
属性评估器和搜索方法技术都可以配置。选择后,点击技术名称即可访问其配置详情。
Weka特征选择配置
点击“更多”按钮以获取有关特征选择技术和配置参数的更多文档。将鼠标悬停在配置参数上会显示一个包含更多详细信息的工具提示。

Weka特征选择更多信息
现在我们知道如何在 Weka 中访问特征选择技术,接下来我们将学习如何在选定的标准数据集上使用一些流行方法。
基于相关性的特征选择
选择数据集中最相关属性的常用技术是使用相关性。
在统计学中,相关性更正式地称为皮尔逊相关系数。
你可以计算每个属性和输出变量之间的相关性,只选择那些具有中等到高正或负相关性(接近-1或1)的属性,并删除那些相关性较低(值接近零)的属性。
Weka通过CorrelationAttributeEval技术支持基于相关性的特征选择,该技术需要使用Ranker搜索方法。
在我们的Pima印第安人数据集上运行此操作表明,一个属性(plas)与输出类别的相关性最高。它还表明许多属性具有一定的适度相关性(mass,age,preg)。如果我们将0.2作为相关属性的截止值,则其余属性(pedi,insu,skin和pres)可能会被删除。
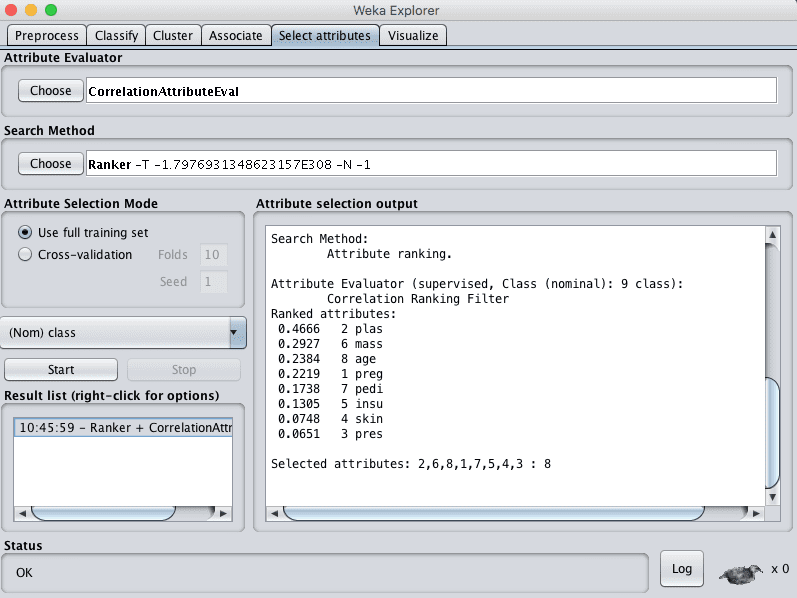
Weka基于相关性的特征选择方法
基于信息增益的特征选择
另一种流行的特征选择技术是计算信息增益。
你可以计算每个属性对于输出变量的信息增益(也称为熵)。熵值从0(无信息)到1(最大信息)不等。那些贡献更多信息的属性将具有更高的信息增益值并可以被选中,而那些没有添加太多信息的属性将具有较低的分数并可以被删除。
Weka使用InfoGainAttributeEval属性评估器支持通过信息增益进行特征选择。与上述相关性技术一样,必须使用Ranker搜索方法。
在我们的Pima印第安人数据集上运行此技术,我们可以看到一个属性(plas)比所有其他属性贡献了更多的信息。如果我们使用0.05的任意截止值,那么我们还将选择mass、age和insu属性,并从数据集中删除其余属性。
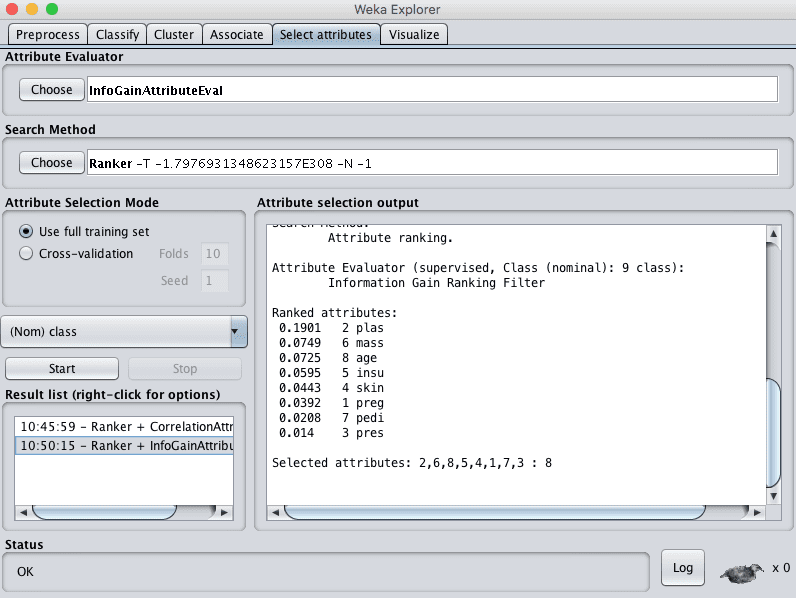
Weka基于信息增益的特征选择方法
基于学习器的特征选择
一种流行的特征选择技术是使用通用但功能强大的学习算法,并评估该算法在具有不同选定属性子集的数据集上的性能。
产生最佳性能的子集被视为选定的子集。用于评估子集的算法不一定是你打算用于建模问题的算法,但它应该训练速度快且功能强大,例如决策树方法。
在 Weka 中,这种类型的特征选择由 WrapperSubsetEval 技术支持,并且必须使用 GreedyStepwise 或 BestFirst 搜索方法。如果计算时间允许,后者 BestFirst 更受青睐。
1. 首先选择“WrapperSubsetEval”技术。
2. 点击“WrapperSubsetEval”名称打开该方法的配置。
3. 点击“分类器”的“选择”按钮,将其更改为“trees”下的J48。
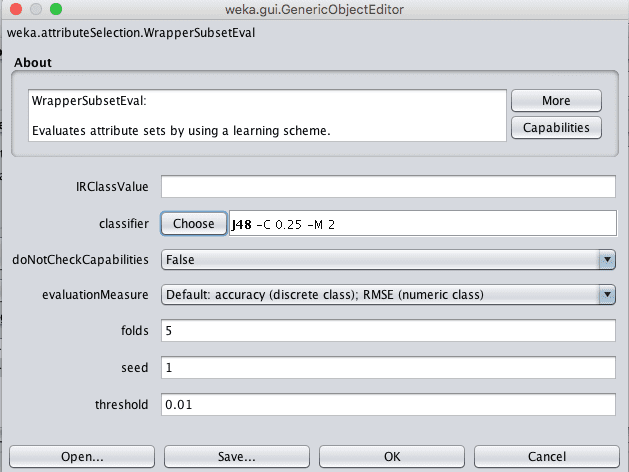
Weka Wrapper特征选择配置
4. 点击“确定”接受配置。
5. 将“搜索方法”更改为“BestFirst”。
6. 点击“开始”按钮评估特征。
在Pima印第安人数据集上运行此特征选择技术,选择了8个输入变量中的4个:plas、pres、mass和age。
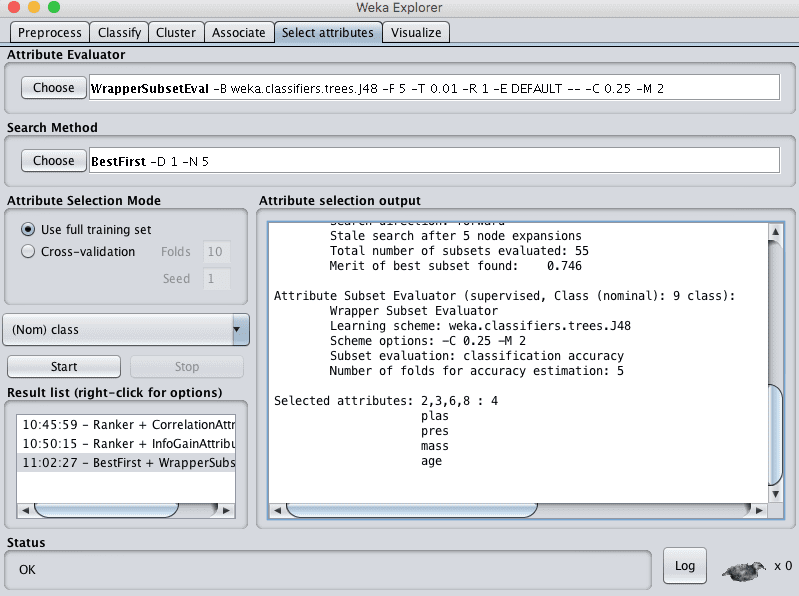
Weka Wrapper特征选择方法
在Weka中选择属性
回顾这三种技术,我们可以看到选定特征(例如plas)存在一些重叠,但也存在差异。
评估你的机器学习数据集的多个不同“视图”是个好主意。数据集的视图只不过是给定特征选择技术选择的特征子集。这是你可以在Weka中轻松创建的数据集副本。
例如,根据上次特征选择技术的结果,假设我们想创建Pima印第安人数据集的一个视图,只包含以下属性:plas、pres、mass和age。
1. 点击“预处理”选项卡。
2. 在“属性”选择中,勾选除plas、pres、mass、age和class属性以外的所有属性。
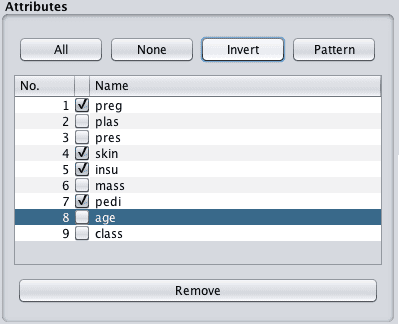
Weka从数据集中选择要删除的属性
3. 点击“移除”按钮。
4. 点击“保存”按钮并输入文件名。
你现在有了一个新的数据集视图可以探索。
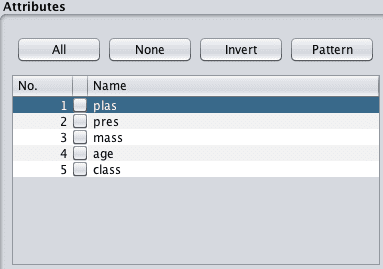
Weka从数据集中移除的属性
使用哪些特征选择技术
你无法知道哪种数据视图将产生最准确的模型。
因此,最好在数据上尝试多种不同的特征选择技术,进而创建数据的许多不同视图。
选择一个好的通用技术,比如决策树,并为你的数据的每个视图构建一个模型。
比较结果以了解哪种数据视图能带来最佳性能。这将让你了解哪些视图,或更具体地说,哪些特征最能向学习算法普遍揭示你问题的结构。
总结
在这篇文章中,你了解了特征选择的重要性以及如何在Weka中对数据使用特征选择。
具体来说,你学到了:
- 如何使用相关性执行特征选择。
- 如何利用信息增益进行特征选择。
- 如何通过在不同特征子集上训练模型来执行特征选择。
你对 Weka 中的特征选择或本文有任何疑问吗?请在评论中提出你的问题,我将尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。





 for Feature Selection in Python")
先生,Weka中的classifierattribute eval和wrapperattributeeval有什么区别。
所以,我在不使用任何应用程序(J48以及diabetes.arff数据集的所有实例和特征)的情况下获得的准确率为84.11%,错误率为15.88%。
应用CorrelationAttributeEval、InfoGain和WwrapperSubsetEval中的任何一种后,准确率都会降低。当然,这是显而易见的,因为我最终会删除一些特征,但这到底有什么好处呢?我正在丢失信息。这不好,我错了吗?
好问题,Mark。
我们只希望执行最终有利于模型性能的特征选择。
我将特征选择用作指导,每种方法都会对哪些特征可能重要提供不同的提示。每个集合/子集都可以用作训练新模型的输入,以与基线进行比较或组合在一起与基线竞争。
特征选择后性能变差仍然能教会你一些东西。不要丢弃这些特征,或者基于这种“新”的问题视图构建模型,并将其与基于其他智能选择的问题视图训练的模型结合起来。
我希望这能让你对你提出的一个非常重要的话题有更深入的了解。
嗨,Jason,
感谢这篇内容丰富的文章!
因此,您使用了任意的截止值来进行相关性和信息增益,以便选择特征子集。
有什么方法可以选取截止值吗?
我对特征选择还有另一个疑问。
为了从“信息增益 + Ranker”方法的输出中选择最佳特征子集,我逐一移除了低排名特征,并检查了每个子集分类器的准确性,然后选择了给出最大准确性的子集。
然而,对于某些数据集,我得到了2个特征子集的相同(最大)准确率值。
例如,我有一个包含21个特征的集合,其中10个特征和6个特征的子集在所有可能的子集中给出了相同的最大准确率。
所以我很困惑该选择哪个子集?
你能帮我吗?
谢谢!
谢谢 Shailesh。
我建议尝试使用每个值作为截止值来创建特征模型,并让模型技能决定要采用的特征。
是的,我喜欢你概述的方法。特征越少越好(复杂度越低,越容易理解)。另外,将这些结果与新的集成模型进行比较,该模型对具有不同特征数量的模型性能取平均值。
如果我使用IG进行特征选择,然后使用SVM进行交叉验证分类,那么特征选择将完全应用于整个数据集,而不仅仅是训练集……这不正确,我想……
尊敬的Jason Brownlee先生
我想请教您如何在weka中将PSO作为特征选择算法来执行?有没有办法将PSO添加到weka程序中?
提前感谢。
抱歉,Sadiq,我没有在Weka中使用PSO进行特征选择。我无法给你好的建议。
如果我使用信息增益来选择训练数据集的属性,并使用命令行将输出保存到另一个.arff文件中。现在我们有了带有选定属性的训练数据集。是否可能只使用这些选定属性来创建测试数据?因为我的数据维度非常大,手动删除属性非常困难。- 谢谢
我相信可能有一个数据过滤器可以应用特征选择并移除未选择的特征。
也许可以查看一些数据过滤器以找到这样的过滤器。
然后你可以将过滤后的特征保存到新文件中并直接使用它。
Jason,很棒的帖子。
我遇到了一个令人困惑的情况。我用我自己的数据集尝试了CorrelationAttributeEval,并在评估器的配置窗口中指定了outputDetailedInfo:true。Weka给我列出了每个特征的每个独立值的相关性。这很棒,但是有一个特征只有两个可能的值,并且两者具有相似的相关性。据我理解,这意味着这个特征不能以任何方式影响预测,因为相关性与任何可能的值都相似……即使该特征的总相关性是与其他特征相比最好的之一。我说的对吗?
嗨,Jason,
这是一个很好的解释。但我想知道,特征选择到底是什么?如果我把所有的属性值加起来,为什么总和不是1或100%?
特征选择是一种减少模型输入变量数量的方法,希望能够获得更简单的模型或更好的预测,或者两者兼而有之。
执行特征选择时,我们应该对整个数据集(训练集和测试集)执行,然后拆分数据吗?还是只在训练部分执行?
最好只在训练数据上执行数据预处理操作,然后使用训练数据中的系数/等将这些操作应用于测试数据。
嗨,Jason,
我有两个问题,
1. 我在特征选择和不进行特征选择时面临同样的问题。在没有任何特征选择方法的情况下,J48的准确率为99.10%,但使用CFS、卡方和IG以及不同的子集,我得到了较低的准确率,如98.70%、97%等。我哪里错了?
2. 这与Weka GUI和API有关,为什么我在使用GUI和API时对相同的算法得到不同的结果。我搜索了很多,但没有找到任何有用的东西。
谢谢
每次在相同数据上运行相同算法时,得到不同的结果是很常见的,考虑使用实验界面并在多次运行中取平均分。
请看这篇文章
https://machinelearning.org.cn/randomness-in-machine-learning/
尊敬的Jason,我正在使用三种机器学习算法,如GA进行特征选择,ANN和SVM对数据集进行分类。我想使用封装方法,您能告诉我如何在预处理中应用交叉和变异操作概念吗?
抱歉,我没有遗传算法用于特征选择的实际示例。
谢谢 Jason。
但是,为什么我在Weka GUI和API上对相同数据集使用相同算法时会得到不同的结果呢?
这是预料之中的,请看这篇文章。
https://machinelearning.org.cn/randomness-in-machine-learning/
亲爱的 Jason,
我想开发一个新的特征选择算法,我可以使用WEKA来完成吗?
是的,你可以自己实现它以在Weka中使用。
谢谢你的回复
你能给我一些建议或提供一个说明性示例的链接吗?
抱歉,我没有示例。
Jason,很棒的帖子。
我费了很大力气,但未能找到针对分类问题的一些问题的直接答案,您的观点将非常有帮助。
1) 信息增益和基尼系数似乎合理,但皮尔逊相关系数和卡方过滤器是否适用于二元变量/糖尿病数据集典型的分类问题?
2) 统计学教授和一些在线媒体强烈主张将属性选择作为交叉验证内循环的一部分。不这样做是一种作弊行为,因为训练数据已经用于属性选择,并会偏向估计以产生较小的误差。Ian Witten在他的MOOC中建议使用AttributeSelectedClassifier。在使用Weka中的属性选择选项卡时,这些过滤方法是否应该在测试/验证集上运行?
抱歉,我不知道。
亲爱的 Jason,
属性评估器和搜索方法的执行顺序是怎样的?我正在尝试使用蚁群搜索(默认评估器为模糊粗糙子集)和CfsSubsetEval作为属性评估器。在这种情况下,首先,CfsSubsetEval函数评估属性并给出信息子集(带有优点),然后蚁群搜索在所有这些子集上进行,通过模糊粗糙子集评估器进行评估;是这样吗?
谢谢
抱歉,我不能给你好的建议。
这篇帖子是关于从现有的CSV或ARFF文件(可以使用excel或一些python代码从原始数据中生成)中进行特征选择的。我们能否在WEKA中使用窗口化(1秒或更长)和重叠(50%左右)从任何CSV或ARFF或EXCEL文件中生成特征?
我不知道,抱歉。
尊敬的Jason博士
感谢您提供如此丰富的信息文章
我正在Weka中使用属性选择进行我的毕业研究,主题是视频场景中的异常行为。
我想知道是否需要为属性选择的每个搜索方法设置参数?
另外,我需要对属性评估器的结果进行一些解释。
可能需要进行一些实验。
嗨,Jason,
我的作业要求我使用属性选择并进行测试以查看最佳结果。
我应该使用attributeSelectionClassified还是attributeSelection?
有没有链接可以告诉我如何比较结果以获得最佳属性集?
你必须通过实验才能找出最适合你的预测建模问题的特征子集。
我可以在Weka中使用我的算法进行特征选择吗?
是的,但你可能需要自己实现。
在Weka Explorer中,当我们导入数据后使用相关属性评估器时,它会为每个特征分配与决策变量相关的相关系数。
我想知道Weka如何知道我把决策变量放在哪一列?
谢谢你,你给我打开了一个新世界!
我很高兴它帮助了Arman。
嗨
使用InfoGainAttributeEval -> 输出是熵。这是什么单位?它是如何计算的?(据我所知,熵通常以比特为单位衡量)
非常感谢
Don
好问题,我猜是“比特”。
https://zh.wikipedia.org/wiki/%E7%86%B5_(%E4%BF%A1%E6%81%AF%E7%90%86%E8%AE%BA)
我如何使用weka进行基于深度学习的网络入侵检测系统特征选择?
谢谢你
我不认为Weka支持深度学习。
嗨,Jason,这真是一篇很棒的帖子,解释得很有启发性。
一个简单的问题
1) 您提到了使用wrappersubsete eval来选择特征子集
我们可以使用Cfssubset eval来选择特征吗
2) 我们能否使用肘部法则(图表)来选择特征与类别相关值的最佳特征集?
也许可以。
亲爱的Jason,我正在研究使用机器学习分类从新闻文本中提取信息,如何在WEKA中应用?
抱歉,我没有在Weka中处理文本数据的示例。
有人知道在Weka中去哪里找PSO吗?
谢谢你
没有,抱歉。
如此有用的文章。谢谢
不客气。很高兴听到你这么说。
嗨,Jason,我如何使用新数据测试生成的规则(关联规则挖掘)?
这个可能会有帮助
https://machinelearning.org.cn/market-basket-analysis-with-association-rule-learning/
尊敬的Jason,我正在处理文本数据集,其中单词频率表示为属性(这意味着我面临高维度问题,数据集可能包含多达3000个特征)。
我尝试应用属性选择(信息增益和相关性)过滤器,但没有任何改变,属性数量仍然相同。这是否意味着所有属性都是必需的?我应该不应用特征选择方法继续吗?
3K不算多。尝试直接对问题进行建模。然后看看能否通过删除任何特征来获得提升。
一个属性评估器有很多搜索方法,不同的组合可以产生不同的属性子集。那么如何匹配属性评估器和搜索方法呢?
(例如:CfsSubseteval+bestfirts,CfsSubseteval+greddysteowise,CfsSubseteval+Genetic search)
也许是试错法?
你好,Jason
感谢您所有出色的文章,它们非常有用。
我不是数据科学家,所以我不确定如何正确解释 Weka 的结果。
我尝试用深度学习算法根据车辆特性(40个特征)预测车辆油耗,但精度对于业务来说过高,误差在3%左右。
所以,我使用CorrelationAttributeEval + Ranker算法在weka中检查了我的数据。我发现排名在-0.01和0.02之间。
这些低排名是否表明这些属性真的不相关?
非常感谢
Thierry
可能是这种情况。
嗨,Jason,
我正在进行特征选择。我的数据不平衡,我使用SMOTE来平衡数据。之后,我尝试通过信息增益和基于相关性的选择来查看属性的重要性。这两种方法没有给出相同的结果。我想知道是不是因为我使用了处理过的数据而不是原始数据?我还运行了数据中数值变量之间的相关性分析,结果没有相关性,我应该使用信息增益而不是基于相关性的特征吗?问题是,当查看树时,CorrelationAttributeEval + Ranke给出的重要性顺序给出了合理的结果。
谢谢你
此致
Minh-Trung
我预计SMOTE之后特征选择会不可靠。
也许可以尝试在不同的特征子集下拟合模型并比较模型性能?
嗨,Jason,
这真是一篇很棒的文章。我有一个数据集,其中所有标签都没有意义,有label1、2…30,并且有450条记录,它们都是二项式的,除了ID标签外都有缺失数据。我有两个问题,请问:
1. 对于二项式(是/否)数据,您对预处理阶段处理缺失数据的建议是什么?其中一个标签在120条记录中为空,其他标签有10-30个字段有缺失数据?
2. 在这种情况下,哪种属性选择方法最适合充分比较?
我非常感谢您的建议。
Mic
也许可以尝试几种方法,例如删除记录,用平均值、中位数、众数、线性模型等进行插补,使用支持缺失数据的模型,如xgboost等。
尝试一系列特征选择方法,看看哪种方法能带来最佳性能的模型。
https://machinelearning.org.cn/faq/single-faq/what-feature-selection-method-should-i-use
Jason,
感谢您的精彩文章,也感谢您坚持不懈地回复这个帖子。我正在参加Weka在线课程,我爱上了这个简单而强大的工具。
我有一个问题。
这3种能力是否属于特征选择范畴?
1) 前向选择:前向选择是一种迭代方法,我们从模型中没有特征开始。
2) 后向消除:在后向消除中,我们从所有特征开始,并在每次迭代中删除最不重要的特征
3) 递归特征消除:它是一种贪婪优化算法,旨在找到性能最佳的特征子集。
它们是特征选择的不同方法,可能还有更多。
如何在weka中应用水平和垂直特征选择
你说的水平和垂直具体是什么意思?
我可以在Weka中使用蚁群优化技术进行特征选择吗?
抱歉,我不知道。
先生,我将后向消除特征选择和信息增益与排序器方法应用于我们的数据集,并为机器学习模型选取了共同特征。后向消除技术是在Weka的预处理选项卡中手动完成的,而信息增益是自动选择特征的方式。我只是想知道这是一种好的特征选择方法吗?
只有当它在你的数据集上产生更熟练的模型时,这才是一种好的方法。
嗨 Jason
我的数据集都是数值型数据,一些算法(如J48)无法应用于它们(它们是灰色的)来测量准确率。当我在Weka中使用“交叉验证”或“百分比分割”时,我得到以下摘要报告:
• 相关系数 0.5755
• 平均绝对误差 1.1628
• 均方根误差 1.737
• 相对绝对误差 81.5909 %
• 相对均方根误差 81.9522 %
我应该报告模型预测的准确率。我如何获得确切的准确率?是准确率数字还是图表?
谢谢你
你无法报告回归问题的准确率,你必须报告误差。在此了解更多信息
https://machinelearning.org.cn/faq/single-faq/how-do-i-calculate-accuracy-for-regression
我正在使用这些算法;
高斯过程
K星
IBK
随机森林
听起来是个不错的开始。
你好 Jason!!!
我直接使用Python内置库中的特征选择技术。如果我使用Weka进行特征选择,结果会有什么不同?
没多大区别,用Python方法就行了,例如:
https://machinelearning.org.cn/feature-selection-with-real-and-categorical-data/
嗨,Jason,
这个博客很棒,对我的机器学习帮助很大。有一个有点不相关的问题,我正在测试当我降低置信度(使用J48和交叉验证)时我的数据会发生什么,令我惊讶的是,准确率上升了。
有什么想法为什么会这样吗?这完全与我预期的相反。
谢谢。
抱歉,我不太明白。也许你能详细说明一下?什么置信度?
谢谢您的指导。
先生,我在Weka中尝试了Wrapper特征选择与SMO,但有时没有得到选定的特征。只显示消息“评估了所有特征”。
很抱歉听到这个消息,我不确定发生了什么。
也许可以尝试发布到weka用户组
https://machinelearning.org.cn/help-with-weka/
我从weka得到的最佳准确率是44%,我应该如何处理我的excel数据集才能获得更好的准确率?
我使用了神经网络、Kstar、随机森林。
问题是数据分布不均。有没有什么技术可以处理数据集?
这里有一些建议。
https://machinelearning.org.cn/machine-learning-performance-improvement-cheat-sheet/
先生,我们如何使用weka工具制作特征模型???
什么是“特征模型”?
Jason,很棒的帖子。
我正在处理我的数据集的预处理阶段,我只想知道我是否可以随机选择一些特征选择方法,或者在选择时必须遵守一些标准?
谢谢你
好问题,请看这个
https://machinelearning.org.cn/faq/single-faq/what-feature-selection-method-should-i-use
我们可以在WEKA中使用RT3和RC4.5数据降维技术吗?
抱歉,我不能立即给出答案。
Jason,非常有用的帖子
我的问题是:有时单个特征可能不显示与输出的相关性,但是多个特征的组合会显示相关性。在这种情况下,您推荐哪种方法来选择特征?
可能是封装方法,例如RFE(或其他搜索方法)。
感谢您宝贵的帖子,
我想知道如何在Weka中使用基于粗糙集的特征选择
抱歉,我对粗糙集不了解。
亲爱的,
我用Weka运行了我的数据集。但是,如果我使用Explore,它不显示完整的输出结果(准确性等)(我点击完整的评估指标以显示所有输出结果),如下所示:
=== 测试分割评估 ===
测试模型在测试分割上花费的时间:0.28秒
=== 总结 ===
相关系数 0.6715
平均绝对误差 0.4936
均方根误差 0.6244
相对绝对误差 74.1773 %
根相对平方误差 76.5897 %
实例总数 36000
在使用Experimenter的情况下,提交数据集并开始后,Weka显示:
12:17:54: 已启动
12:17:55: 类属性不是标称型!
12:17:55: 已中断
12:17:55: 发生1个错误。
我的数据集像以下矩阵(属性类:0,1,2)
A0 A1 A2 A3 A4 A5
0.0122 0.0112 0.2134 0.10321 0.21984 1
....
Weka 似乎认为你的数据是一个回归问题。
尝试通过过滤器或手动在文件中将目标更改为名义型。
感谢这篇文章……对使用weka过滤器非常有帮助。
不客气。
我在使用特征选择技术时感到困惑。在weka中,我只能使用3种技术
1. 相关性
2. 信息增益
3. 决策树
我能得到至少5种其他特征选择技术的名称吗?
干得好!
是的,考虑数据预处理部分中的一套封装器和过滤器方法。
嗨,Jason。非常感谢您介绍了不同的特征选择工具——非常有帮助。
比较特征选择子集/排名很好,但我很难理解为什么会出现如此大的差异……
如果“pres”在相关性和信息增益技术中都排在8个属性的最后一位,那么该列及其值的哪些特征使得它对决策树方法如此有用(8个属性中的第二个选择)?
谢谢,
保罗
不同的特征选择技术对目标变量的“最重要”因素会有不同的“看法”。
最好的方法是使用一系列不同的特征选择方法和一系列不同的预测算法进行测试,以找出最适合你特定数据集的组合。
https://machinelearning.org.cn/faq/single-faq/what-feature-selection-method-should-i-use
感谢您的及时回复——以及全面的常见问题解答链接——不胜感激。
我对这些都比较陌生,但只是担心如果一个变量几乎完全不相关(就像pres似乎那样,与目标类别),而且没有信息增益,我就会被指责过于努力地寻找某种碰巧有效的方法,也许是随机的,也许只在这个数据集上有效(而不能很好地推广到未来的实例)。但我想这些也可以进行测试。
上面和其他地方的见解都很棒——非常感谢。
不客气。
嗨,Jason。非常感谢您提供的信息。
我对选择排名较高的特征感到困惑,所以请您帮帮我。
当应用信息增益过滤器时,通过计算最高排名来降低数据的维度。
如何从众多特征中保存选定的特征?
例如,我们有4000个特征,只需要200个,那么如何一次选择200个并删除1800个呢?
不客气。
特征选择方法可以作为模型管道的一部分使用。例如,无需保存。
或者,您可以预处理数据,使用特征选择方法选择特征并保存数组
https://machinelearning.org.cn/how-to-save-a-numpy-array-to-file-for-machine-learning/
亲爱的Jason Brownlee,
我想将通过信息增益过滤器选择的排名特征(例如200个特征)的输出作为输入,使用另一个程序将其输入到Wrapper FS中,这就是为什么我需要知道如何通过Weka保存所选的最高排名特征以创建新的数据集。
我的数据集格式是词频形式。
祝好
是的,您可以应用特征选择方法,然后直接保存结果数据集。
我使用了预处理选项卡,使用监督特征选择方法(分类器子集评估,随机森林)来选择特征,但是当我使用“选择属性”选项卡使用相同方法时,结果却不同。您能解释一下在Weka中使用“选择属性”选项卡和“预处理”选项卡进行特征选择有什么区别吗?谢谢!
猜测——这可能是由于学习算法的随机性质造成的
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
最后一个问题,当我使用“选择属性”选项卡时,建议从属性选择模式中选择什么?完全训练还是交叉验证?我希望有关于解释此选项卡结果的有用文档。
也许用户指南会有帮助?
也许内置的上下文帮助会有用?
也许这些资源会有所帮助
https://machinelearning.org.cn/help-with-weka/
嗨
Weka中选择属性的信息增益可以大于1吗?如果不能,是否应该删除该属性?
抱歉,我一时不确定。
你好……Weka中有使用果蝇优化算法进行特征选择的方法吗?
你好,Musa……以下内容可能会有所帮助
https://tutorialspoint.org.cn/weka/weka_feature_selection.htm
您好,
我有一个包含54个属性的数据集,但我希望Weka模型只对其中的46个进行分类。如何在分类阶段选择这46个属性?
你好,Lukumba 博士……要使用Weka进行特征选择,并确保在分类阶段只使用54个属性中的46个,您可以按照以下步骤操作
### 步骤1:加载数据集
1. 打开Weka。
2. 转到“Explorer”选项卡。
3. 单击“Open file…”按钮并加载您的数据集。
### 步骤2:选择属性
1. 转到“Select attributes”选项卡。
2. 选择一个属性选择方法
– 对于简单的手动选择,您可以使用“Remove”过滤器。
– 对于更高级的选择,您可以使用属性评估器和搜索方法。
#### 手动删除属性
1. 在“Filter”面板中,单击“Choose”按钮。
2. 选择
weka.filters.unsupervised.attribute.Remove。3. 单击“Remove”过滤器进行配置。
4. 在“Remove”过滤器选项中,将“attributeIndices”设置为您要删除的属性索引。例如,要删除前8个属性并保留剩余的46个,您可以将
attributeIndices设置为1-8。5. 单击“OK”应用过滤器。
#### 使用评估器和搜索方法进行属性选择
1. 在“Attribute Evaluator”面板中,单击“Choose”按钮。
2. 选择一个属性评估器,例如
weka.attributeSelection.CfsSubsetEval或weka.attributeSelection.InfoGainAttributeEval。3. 在“Search Method”面板中,单击“Choose”按钮。
4. 选择一个搜索方法,例如
weka.attributeSelection.BestFirst或weka.attributeSelection.Ranker。5. 根据需要配置评估器和搜索方法。
6. 单击“Start”按钮运行属性选择过程。Weka将根据您选择的评估器和搜索方法选择最相关的属性。
### 步骤3:将选定的属性应用于分类器
1. 转到“Classify”选项卡。
2. 在“Filter”面板中,单击“Choose”按钮。
3. 选择
weka.filters.unsupervised.attribute.Remove。4. 单击“Remove”过滤器进行配置。
5. 在“Remove”过滤器选项中,将“attributeIndices”设置为您要删除的属性索引,就像您在“Select attributes”选项卡中所做的那样。
6. 单击“OK”应用过滤器。
7. 在“Classifier”面板中,选择您的分类器(例如,J48、NaiveBayes等)。
8. 单击“Start”运行分类过程。
### 示例:删除特定属性
如果您想按索引手动删除特定属性,请更详细地按照以下步骤操作
1. **选择删除过滤器:**
– 在“Filter”面板中,单击“Choose”并选择
weka.filters.unsupervised.attribute.Remove。2. **配置删除过滤器:**
– 单击过滤器以打开其配置。
– 将“attributeIndices”字段设置为您要删除的属性索引。例如,要保留属性9到54(即删除前8个属性),请将
attributeIndices设置为1-8。3. **应用过滤器:**
– 单击“OK”应用过滤器。您现在应该看到数据集中只保留了所需的属性。
4. **保存过滤后的数据集(可选):**
– 如果您想以后重复使用,可以单击“Save”保存过滤后的数据集。
5. **运行分类器:**
– 转到“Classify”选项卡。
– 选择您想要的分类器并设置您的评估参数。
– 单击“Start”在过滤后的数据集上训练和评估分类器。
通过遵循这些步骤,您可以确保在Weka的分类阶段只使用选定的46个属性。
嗨
我有一个包含数值类进行回归的数据集,将其数值类转换为名义类并使用信息增益进行特征选择是否可以?
你好,faramak……为了使用信息增益进行特征选择,将数值类转换为名义类是可以的,但了解其含义和适用背景至关重要。以下是一些考虑因素
### 何时可能适用
1. **分类问题**:如果您打算解决分类问题而不是回归问题,将数值转换为分类类别(名义)可能是有意义的。例如,如果您的连续目标变量是年龄,并且您将其转换为年龄组(例如,儿童、青少年、成人、老年人),那么您可以使用信息增益等技术。
2. **离散区间**:如果您的数值目标可以有意义地划分为代表不同类别的离散区间,这种方法是合理的。例如,将温度读数转换为“冷”、“暖”、“热”等类别。
### 潜在问题
1. **信息丢失**:将数值数据转换为分类数据可能会导致信息丢失,特别是如果数值数据具有在分类形式中被平滑掉的有意义的变化。
2. **任意分箱**:将数值转换为类别的过程通常涉及对分箱阈值的任意决定,这可能会引入偏差并降低模型的预测能力。
3. **特征选择方法**:信息增益是分类任务中特征选择的合适方法,但如果您的原始问题是回归任务,它可能不合适。对于回归问题,相关系数、互信息回归或来自随机森林或梯度提升等模型的特征重要性等技术通常更合适。
### 替代方法
如果您的最终目标是执行回归并希望进行特征选择,请考虑使用专为回归任务设计的方法
– **互信息回归**:测量输入特征和目标变量之间的依赖关系。
– **相关性分析**:分析每个特征和目标变量之间的线性关系。
– **基于模型的特征重要性**:使用随机森林、梯度提升或Lasso回归等模型来评估特征重要性。
### 实际步骤
1. **分析数据性质**:了解您的数值目标变量的分布和性质。决定转换为分类类别是否会增加有意义的上下文。
2. **选择适当的方法**:如果您的主要任务是回归,请使用回归特定的特征选择方法。对于分类,将数值转换为名义并使用信息增益可能适用。
3. **验证您的方法**:如果您决定将数值类转换为名义类,请验证对模型性能的影响。将结果与其他特征选择技术获得的结果进行比较。
如果您需要有关特定数据集或问题的进一步指导,请随时分享更多详细信息,我可以提供更量身定制的建议。