我们之前已经了解了如何为神经机器翻译任务训练 Transformer 模型。在继续对训练好的模型进行推理之前,我们先来探讨如何稍微修改训练代码,以便能够绘制在学习过程中生成的训练和验证损失曲线。
训练和验证损失值提供了重要信息,因为它们能让我们更深入地了解学习性能如何随训练轮数(epochs)变化,并帮助我们诊断可能导致模型欠拟合或过拟合的学习问题。它们还会告诉我们,在推理阶段应该使用哪个训练轮次的模型权重。
在本教程中,您将学习如何绘制 Transformer 模型的训练和验证损失曲线。
完成本教程后,您将了解:
- 如何修改训练代码,以便在数据集的训练分割之外,还包含验证和测试分割
- 如何修改训练代码,以存储计算出的训练和验证损失值,以及训练好的模型权重
- 如何绘制已保存的训练和验证损失曲线
用我的书《使用注意力机制构建 Transformer 模型》来**启动您的项目**。它提供了**自学教程**和**可运行的代码**,指导您构建一个功能完备的 Transformer 模型,该模型可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...
让我们开始吧。

绘制 Transformer 模型的训练和验证损失曲线
照片由 Jack Anstey 拍摄,保留部分权利。
教程概述
本教程分为四个部分;它们是
- Transformer 架构回顾
- 准备数据集的训练、验证和测试分割
- 训练 Transformer 模型
- 绘制训练和验证损失曲线
先决条件
本教程假设您已熟悉以下内容:
Transformer 架构回顾
回顾一下,我们已经知道 Transformer 架构遵循编码器-解码器结构。左侧的编码器负责将输入序列映射为一系列连续表示;右侧的解码器则接收编码器的输出以及前一个时间步的解码器输出来生成一个输出序列。
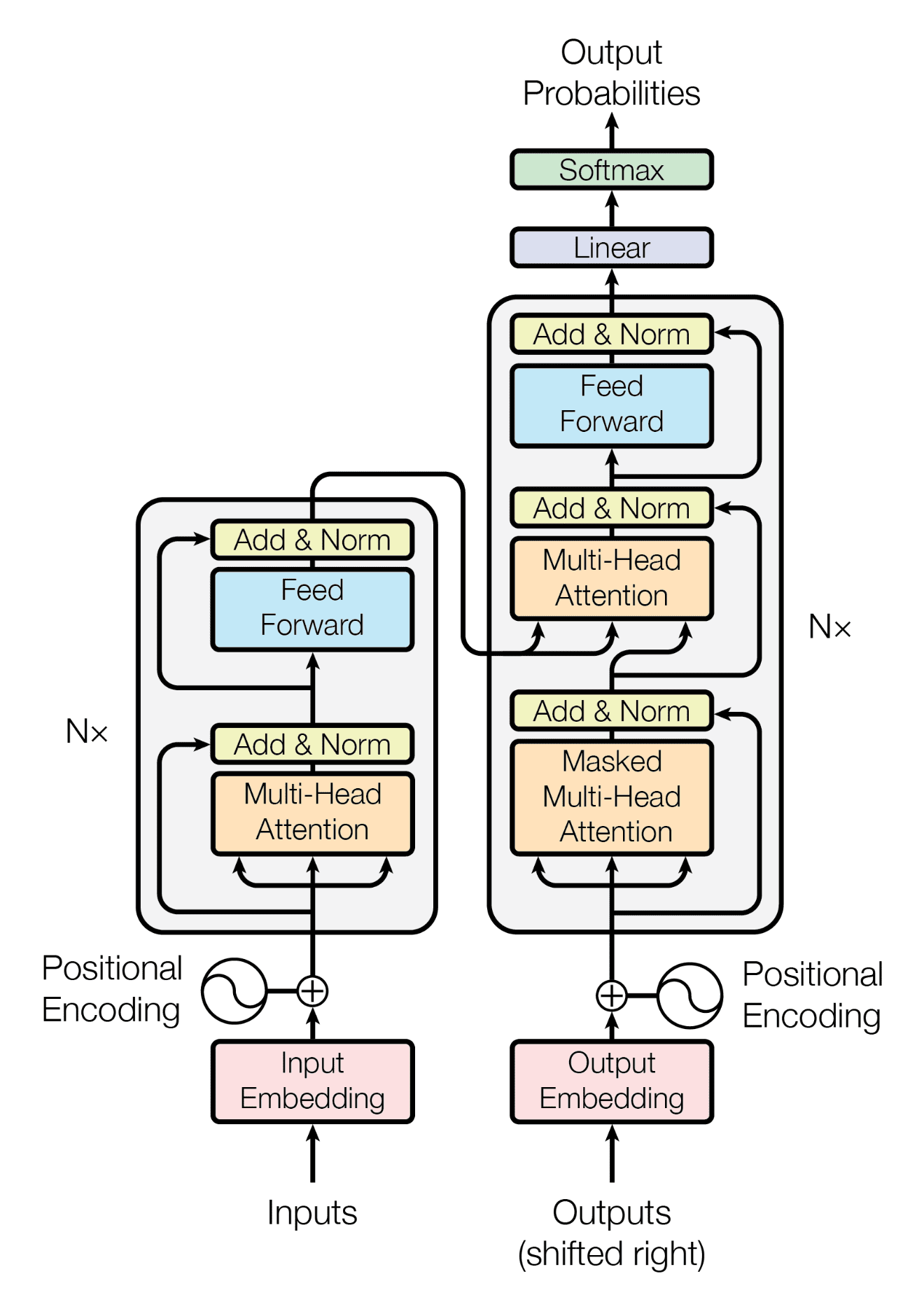
Transformer 架构的编码器-解码器结构
摘自“Attention Is All You Need”
在生成输出序列时,Transformer 不依赖于循环和卷积。
您已经了解了如何训练完整的 Transformer 模型,现在您将学习如何生成并绘制训练和验证损失值,这将帮助您诊断模型的学习性能。
想开始构建带有注意力的 Transformer 模型吗?
立即参加我的免费12天电子邮件速成课程(含示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
准备数据集的训练、验证和测试分割
为了能够包含数据的验证和测试分割,您需要修改准备数据集的代码,引入以下几行代码,它们的作用是:
- 指定验证数据分割的大小。这反过来决定了训练和测试数据分割的大小,我们将数据按 80:10:10 的比例划分为训练集、验证集和测试集
|
1 |
self.val_split = 0.1 # 验证数据分割的比例 |
- 除了训练集外,将数据集分割为验证集和测试集
|
1 2 |
val = dataset[int(self.n_sentences * self.train_split):int(self.n_sentences * (1-self.val_split))] test = dataset[int(self.n_sentences * (1 - self.val_split)):] |
- 通过分词、填充和转换为张量来准备验证数据。为此,您将把这些操作集合到一个名为
encode_pad的函数中,如下面的完整代码清单所示。这将避免在对训练数据执行这些操作时出现过多的代码重复
|
1 2 |
valX = self.encode_pad(val[:, 0], enc_tokenizer, enc_seq_length) valY = self.encode_pad(val[:, 1], dec_tokenizer, dec_seq_length) |
- 将编码器和解码器的分词器保存到 pickle 文件中,并将测试数据集保存到文本文件中,以便稍后在推理阶段使用
|
1 2 3 |
self.save_tokenizer(enc_tokenizer, 'enc') self.save_tokenizer(dec_tokenizer, 'dec') savetxt('test_dataset.txt', test, fmt='%s') |
完整的代码清单现在更新如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
from pickle import load, dump, HIGHEST_PROTOCOL from numpy.random import shuffle from numpy import savetxt from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from tensorflow import convert_to_tensor, int64 class PrepareDataset: def __init__(self, **kwargs): super(PrepareDataset, self).__init__(**kwargs) self.n_sentences = 15000 # 数据集中要包含的句子数量 self.train_split = 0.8 # 训练数据分割的比例 self.val_split = 0.1 # 验证数据分割的比例 # 拟合一个分词器 def create_tokenizer(self, dataset): tokenizer = Tokenizer() tokenizer.fit_on_texts(dataset) return tokenizer def find_seq_length(self, dataset): return max(len(seq.split()) for seq in dataset) def find_vocab_size(self, tokenizer, dataset): tokenizer.fit_on_texts(dataset) return len(tokenizer.word_index) + 1 # 对输入序列进行编码和填充 def encode_pad(self, dataset, tokenizer, seq_length): x = tokenizer.texts_to_sequences(dataset) x = pad_sequences(x, maxlen=seq_length, padding='post') x = convert_to_tensor(x, dtype=int64) return x def save_tokenizer(self, tokenizer, name): with open(name + '_tokenizer.pkl', 'wb') as handle: dump(tokenizer, handle, protocol=HIGHEST_PROTOCOL) def __call__(self, filename, **kwargs): # 加载一个干净的数据集 clean_dataset = load(open(filename, 'rb')) # 减小数据集大小 dataset = clean_dataset[:self.n_sentences, :] # 包含字符串开始和结束的标记 for i in range(dataset[:, 0].size): dataset[i, 0] = "<START> " + dataset[i, 0] + " <EOS>" dataset[i, 1] = "<START> " + dataset[i, 1] + " <EOS>" # 随机打乱数据集 shuffle(dataset) # 将数据集分割为训练集、验证集和测试集 train = dataset[:int(self.n_sentences * self.train_split)] val = dataset[int(self.n_sentences * self.train_split):int(self.n_sentences * (1-self.val_split))] test = dataset[int(self.n_sentences * (1 - self.val_split)):] # 为编码器输入准备分词器 enc_tokenizer = self.create_tokenizer(dataset[:, 0]) enc_seq_length = self.find_seq_length(dataset[:, 0]) enc_vocab_size = self.find_vocab_size(enc_tokenizer, train[:, 0]) # 为解码器输入准备分词器 dec_tokenizer = self.create_tokenizer(dataset[:, 1]) dec_seq_length = self.find_seq_length(dataset[:, 1]) dec_vocab_size = self.find_vocab_size(dec_tokenizer, train[:, 1]) # 对训练输入进行编码和填充 trainX = self.encode_pad(train[:, 0], enc_tokenizer, enc_seq_length) trainY = self.encode_pad(train[:, 1], dec_tokenizer, dec_seq_length) # 对验证输入进行编码和填充 valX = self.encode_pad(val[:, 0], enc_tokenizer, enc_seq_length) valY = self.encode_pad(val[:, 1], dec_tokenizer, dec_seq_length) # 保存编码器分词器 self.save_tokenizer(enc_tokenizer, 'enc') # 保存解码器分词器 self.save_tokenizer(dec_tokenizer, 'dec') # 将测试数据集保存到文本文件 savetxt('test_dataset.txt', test, fmt='%s') return trainX, trainY, valX, valY, train, val, enc_seq_length, dec_seq_length, enc_vocab_size, dec_vocab_size |
训练 Transformer 模型
我们将对训练 Transformer 模型的代码进行类似的修改,以
- 准备验证数据集批次
|
1 2 |
val_dataset = data.Dataset.from_tensor_slices((valX, valY)) val_dataset = val_dataset.batch(batch_size) |
- 监控验证损失指标
|
1 |
val_loss = Mean(name='val_loss') |
- 初始化字典以存储训练和验证损失,并最终将损失值存储在各自的字典中
|
1 2 3 4 5 |
train_loss_dict = {} val_loss_dict = {} train_loss_dict[epoch] = train_loss.result() val_loss_dict[epoch] = val_loss.result() |
- 计算验证损失
|
1 2 |
loss = loss_fcn(decoder_output, prediction) val_loss(loss) |
- 在每个 epoch 结束时保存训练好的模型权重。您将在推理阶段使用这些权重,以研究模型在不同 epoch 产生的结果差异。在实践中,更有效的方法是引入一个回调方法,根据训练期间监控的指标来停止训练过程,然后才保存模型权重
|
1 2 |
# 保存训练好的模型权重 training_model.save_weights("weights/wghts" + str(epoch + 1) + ".ckpt") |
- 最后,将训练和验证损失值保存到 pickle 文件中
|
1 2 3 4 5 |
with open('./train_loss.pkl', 'wb') as file: dump(train_loss_dict, file) with open('./val_loss.pkl', 'wb') as file: dump(val_loss_dict, file) |
修改后的代码清单现在变为
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 |
from tensorflow.keras.optimizers import Adam from tensorflow.keras.optimizers.schedules import LearningRateSchedule from tensorflow.keras.metrics import Mean from tensorflow import data, train, math, reduce_sum, cast, equal, argmax, float32, GradientTape, function from keras.losses import sparse_categorical_crossentropy from model import TransformerModel from prepare_dataset import PrepareDataset from time import time from pickle import dump # 定义模型参数 h = 8 # 自注意力头的数量 d_k = 64 # 线性投影查询(queries)和键(keys)的维度 d_v = 64 # 线性投影值(values)的维度 d_model = 512 # 模型层输出的维度 d_ff = 2048 # 内部全连接层的维度 n = 6 # 编码器堆栈中的层数 # 定义训练参数 epochs = 20 batch_size = 64 beta_1 = 0.9 beta_2 = 0.98 epsilon = 1e-9 dropout_rate = 0.1 # 实现一个学习率调度器 class LRScheduler(LearningRateSchedule): def __init__(self, d_model, warmup_steps=4000, **kwargs): super(LRScheduler, self).__init__(**kwargs) self.d_model = cast(d_model, float32) self.warmup_steps = warmup_steps def __call__(self, step_num): # 在最初的 warmup_steps 中线性增加学习率,之后再减小 arg1 = step_num ** -0.5 arg2 = step_num * (self.warmup_steps ** -1.5) return (self.d_model ** -0.5) * math.minimum(arg1, arg2) # 实例化一个 Adam 优化器 optimizer = Adam(LRScheduler(d_model), beta_1, beta_2, epsilon) # 准备训练数据集 dataset = PrepareDataset() trainX, trainY, valX, valY, train_orig, val_orig, enc_seq_length, dec_seq_length, enc_vocab_size, dec_vocab_size = dataset('english-german.pkl') print(enc_seq_length, dec_seq_length, enc_vocab_size, dec_vocab_size) # 准备训练数据集批次 train_dataset = data.Dataset.from_tensor_slices((trainX, trainY)) train_dataset = train_dataset.batch(batch_size) # 准备验证数据集批次 val_dataset = data.Dataset.from_tensor_slices((valX, valY)) val_dataset = val_dataset.batch(batch_size) # 创建模型 training_model = TransformerModel(enc_vocab_size, dec_vocab_size, enc_seq_length, dec_seq_length, h, d_k, d_v, d_model, d_ff, n, dropout_rate) # 定义损失函数 def loss_fcn(target, prediction): # 创建掩码,以便零填充值不被包含在损失计算中 padding_mask = math.logical_not(equal(target, 0)) padding_mask = cast(padding_mask, float32) # 对未掩码的值计算稀疏分类交叉熵损失 loss = sparse_categorical_crossentropy(target, prediction, from_logits=True) * padding_mask # 计算未掩码值的平均损失 return reduce_sum(loss) / reduce_sum(padding_mask) # 定义准确率函数 def accuracy_fcn(target, prediction): # 创建掩码,以便零填充值不被包含在准确率计算中 padding_mask = math.logical_not(equal(target, 0)) # 找到相等的预测和目标值,并应用填充掩码 accuracy = equal(target, argmax(prediction, axis=2)) accuracy = math.logical_and(padding_mask, accuracy) # 将 True/False 值转换为 32 位精度的浮点数 padding_mask = cast(padding_mask, float32) accuracy = cast(accuracy, float32) # 计算未掩码值的平均准确率 return reduce_sum(accuracy) / reduce_sum(padding_mask) # 包含指标监控 train_loss = Mean(name='train_loss') train_accuracy = Mean(name='train_accuracy') val_loss = Mean(name='val_loss') # 创建一个检查点对象和管理器来管理多个检查点 ckpt = train.Checkpoint(model=training_model, optimizer=optimizer) ckpt_manager = train.CheckpointManager(ckpt, "./checkpoints", max_to_keep=None) # 初始化字典以存储训练和验证损失 train_loss_dict = {} val_loss_dict = {} # 加速训练过程 @function def train_step(encoder_input, decoder_input, decoder_output): with GradientTape() as tape: # 运行模型的前向传播以生成预测 prediction = training_model(encoder_input, decoder_input, training=True) # 计算训练损失 loss = loss_fcn(decoder_output, prediction) # 计算训练准确率 accuracy = accuracy_fcn(decoder_output, prediction) # 获取可训练变量相对于训练损失的梯度 gradients = tape.gradient(loss, training_model.trainable_weights) # 通过梯度下降更新可训练变量的值 optimizer.apply_gradients(zip(gradients, training_model.trainable_weights)) train_loss(loss) train_accuracy(accuracy) for epoch in range(epochs): train_loss.reset_states() train_accuracy.reset_states() val_loss.reset_states() print("\n开始第 %d 轮训练" % (epoch + 1)) start_time = time() # 遍历数据集批次 for step, (train_batchX, train_batchY) in enumerate(train_dataset): # 定义编码器和解码器输入,以及解码器输出 encoder_input = train_batchX[:, 1:] decoder_input = train_batchY[:, :-1] decoder_output = train_batchY[:, 1:] train_step(encoder_input, decoder_input, decoder_output) if step % 50 == 0: print(f'第 {epoch + 1} 轮 第 {step} 步 损失 {train_loss.result():.4f} 准确率 {train_accuracy.result():.4f}') # 在每轮训练后运行一个验证步骤 for val_batchX, val_batchY in val_dataset: # 定义编码器和解码器输入,以及解码器输出 encoder_input = val_batchX[:, 1:] decoder_input = val_batchY[:, :-1] decoder_output = val_batchY[:, 1:] # 生成一个预测 prediction = training_model(encoder_input, decoder_input, training=False) # 计算验证损失 loss = loss_fcn(decoder_output, prediction) val_loss(loss) # 在每轮结束时打印轮数以及准确率和损失值 print("第 %d 轮: 训练损失 %.4f, 训练准确率 %.4f, 验证损失 %.4f" % (epoch + 1, train_loss.result(), train_accuracy.result(), val_loss.result())) # 每轮后保存一个检查点 if (epoch + 1) % 1 == 0: save_path = ckpt_manager.save() print("在第 %d 轮保存检查点" % (epoch + 1)) # 保存训练好的模型权重 training_model.save_weights("weights/wghts" + str(epoch + 1) + ".ckpt") train_loss_dict[epoch] = train_loss.result() val_loss_dict[epoch] = val_loss.result() # 保存训练损失值 with open('./train_loss.pkl', 'wb') as file: dump(train_loss_dict, file) # 保存验证损失值 with open('./val_loss.pkl', 'wb') as file: dump(val_loss_dict, file) print("总耗时: %.2fs" % (time() - start_time)) |
绘制训练和验证损失曲线
为了能够绘制训练和验证损失曲线,您首先需要加载之前训练 Transformer 模型时保存的、包含训练和验证损失字典的 pickle 文件。
然后,您将从各自的字典中检索训练和验证损失值,并将它们绘制在同一张图上。
代码清单如下,您应该将其保存到一个单独的 Python 脚本中
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
从 pickle 导入 加载 from matplotlib.pylab import plt from numpy import arange # 加载训练和验证损失字典 train_loss = load(open('train_loss.pkl', 'rb')) val_loss = load(open('val_loss.pkl', 'rb')) # 检索每个字典的值 train_values = train_loss.values() val_values = val_loss.values() # 生成一个整数序列来表示轮数 epochs = range(1, 21) # 绘制并标记训练和验证损失值 plt.plot(epochs, train_values, label='训练损失') plt.plot(epochs, val_values, label='验证损失') # 添加标题和坐标轴标签 plt.title('训练和验证损失') plt.xlabel('轮数 (Epochs)') plt.ylabel('损失') # 设置刻度位置 plt.xticks(arange(0, 21, 2)) # 显示图例 plt.legend(loc='best') plt.show() |
运行上面的代码会生成一张与下图类似的训练和验证损失曲线图
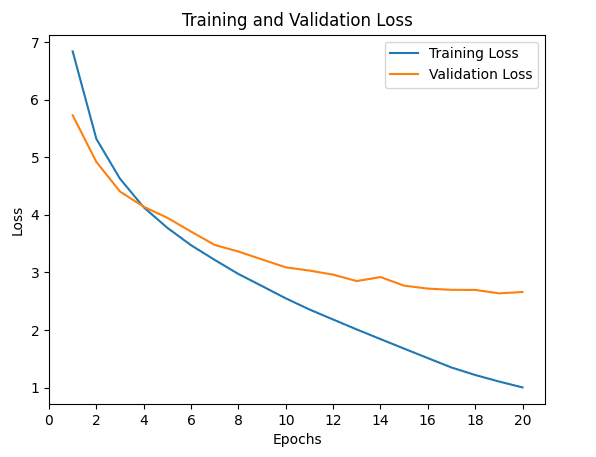
在多个训练轮次中训练和验证损失值的折线图
请注意,尽管您可能会看到类似的损失曲线,但它们不一定与上图完全相同。这是因为您是从头开始训练 Transformer 模型的,最终的训练和验证损失值取决于模型权重的随机初始化。
尽管如此,这些损失曲线能让我们更深入地了解学习性能如何随训练轮数变化,并帮助我们诊断可能导致模型欠拟合或过拟合的学习问题。
有关使用训练和验证损失曲线诊断模型学习性能的更多详细信息,您可以参考 Jason Brownlee 的这篇教程。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 使用 Python 进行高级深度学习, 2019
- 用于自然语言处理的 Transformer, 2021
论文
- 注意力就是你所需要的一切, 2017
网站
- 如何使用学习曲线诊断机器学习模型性能,https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
总结
在本教程中,您学习了如何绘制 Transformer 模型的训练和验证损失曲线。
具体来说,你学到了:
- 如何修改训练代码,以便在数据集的训练分割之外,还包含验证和测试分割
- 如何修改训练代码,以存储计算出的训练和验证损失值,以及训练好的模型权重
- 如何绘制已保存的训练和验证损失曲线
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
学习 Transformer 和注意力!

教您的深度学习模型阅读句子
...使用带有注意力的 Transformer 模型
在我的新电子书中探索如何实现
使用注意力机制构建 Transformer 模型
它提供了自学教程和可运行代码,指导您构建一个可以
将句子从一种语言翻译成另一种语言的完整 Transformer 模型...






为了让代码正常工作,我必须将这两个项目转换为列表(第 6 行和第 7 行),像这样
# 检索每个字典的值
train_values = list(train_loss.values())
val_values = list(val_loss.values())
很棒的系列文章,谢谢!
训练后如何绘制图像分类中每个类别的准确率图
你好 khatija……以下资源可能对你有帮助
https://machinelearning.org.cn/learning-curves-for-diagnosing-machine-learning-model-performance/
你好,非常感谢。我正在尝试将其应用于 PyTorch。请问我该如何定义权重
你好 Olufunke……以下讨论可能对你有帮助
https://stackoverflow.com/questions/74754493/plot-training-and-validation-loss-in-pytorch
https://medium.datadriveninvestor.com/visualizing-training-and-validation-loss-in-real-time-using-pytorch-and-bokeh-5522401bc9dd
感谢您提供的这个优秀系列!它对我非常有帮助。
我认为这篇文章中有两个小笔误
– prepare-dataset 代码中的第 70 行应该是“dataset”而不是“train”。
– training 代码中的第 51 行,所用数据集的名称中缺少了“-both”。
做了这些修改后,我得到了相同的验证损失曲线。
再次感谢您,祝一切顺利!
你好 Oliver……不客气!感谢您的反馈!