
为你的问题选择正确算法的实用指南:从回归到神经网络
图片来自:Editor | Ideogram
本文通过清晰的指导方针,解释了如何为不同类型的现实世界和业务问题选择合适的机器学习(ML)算法或模型。了解如何选择正确的 ML 算法至关重要,因为任何 ML 项目的成功都取决于该选择的正确性。
文章首先提供了一个基于问题的模板,最后以表格形式列出了一些示例用例以及选择每个用例最佳算法的理由。示例涵盖了从简单问题到需要语言模型等现代人工智能功能的更复杂问题。
注意:为简化起见,本文将泛泛地使用“ML 算法”一词来指代所有类型的 ML 算法、模型和技术。大多数 ML 技术都基于模型,模型是通过应用算法构建的,用于推理。因此,在更深层的技术语境中,这些术语应加以区分。
基于问题的模板
以下关键问题旨在引导人工智能、机器学习和数据分析项目负责人选择合适的 ML 算法来解决其特定问题。
关键问题 1:您需要解决什么类型的问题?
- 1.A. 您需要预测某件事吗?
- 1.B. 如果是,是预测数值,还是分类到类别?
- 1.C. 如果您想预测数值,是基于其他变量或特征吗?还是根据过去的历史数据预测未来的值?
以上三个问题与预测性或监督学习方法有关。回答了问题 1.A 的是意味着您正在寻找监督学习算法,因为您需要预测有关新数据或未来数据的一些未知信息。根据您想预测的内容以及预测方式,您可能面临分类、回归或时间序列预测任务。具体是哪种?这正是问题 1.B 和 1.C 将帮助您确定的。
如果您想预测或分配类别,您就面临着一个分类任务。如果您想预测一个数值变量,例如房价,而这个预测是基于房屋特征等其他特征的,那么这就是一个回归任务。最后,如果您想根据过去的值预测未来的数值,例如根据过去每日平均价格的历史预测航班的商务座位价格,那么您就面临着一个时间序列预测任务。
回到 1.A,如果您回答了否,而是想更好地理解您的数据或从中发现隐藏的模式,那么您很可能正在寻找无监督学习算法。例如,如果您想发现数据中的隐藏分组(例如,寻找客户细分),您的目标任务是聚类;如果您希望识别异常交易或异常登录高安全性系统的尝试,那么异常检测算法是您的首选方法。
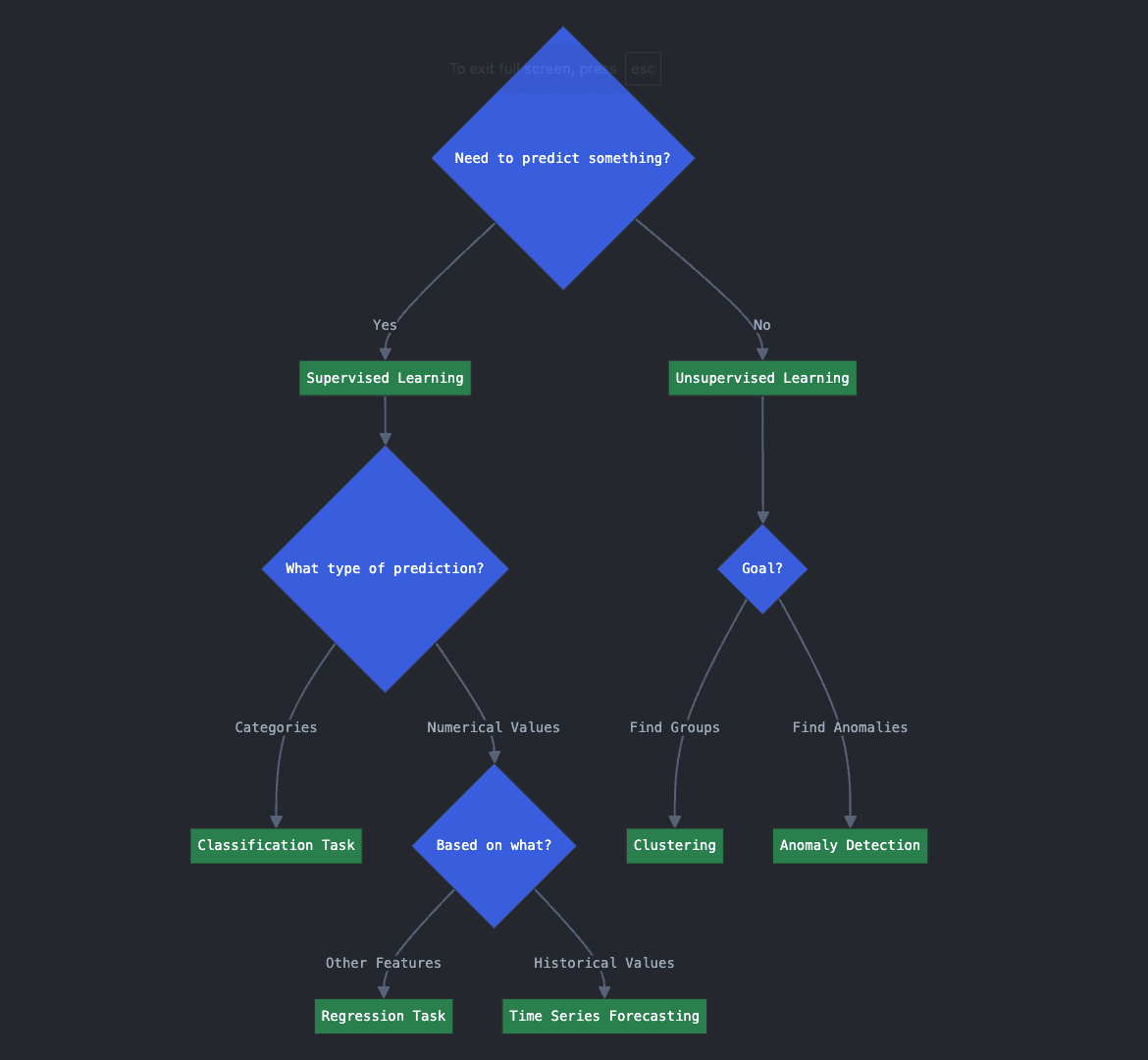
关键问题 1 的决策流程图(点击放大)
图片由编辑提供
关键问题 2:您拥有什么类型的数据?
即使您对上一组问题的回答很明显,并且您心中有一个明确的目标任务,但某些 ML 任务也有多种可用的算法。您会选择哪种?答案的一部分在于您的数据、其数量和复杂性。
2.A. 结构化且更简单的数据,以具有少量属性的表格形式排列,可以利用线性回归、决策树分类器、K-均值聚类等简单 ML 算法。
2.B. 中等复杂性的数据,例如仍然是结构化的,但具有数十个属性,或低分辨率图像,可能需要使用集成方法进行分类和回归,这些方法将多个 ML 模型实例组合成一个模型,以获得更好的预测结果。集成方法的例子有随机森林、梯度提升和 XGBoost。对于聚类等其他任务,可以尝试DBSCAN 或谱聚类等算法。
2.C. 最后,高度复杂的数据,如图像、文本和音频,通常需要更高级的架构,例如深度神经网络:它们训练起来更困难,但当它们接触到大量的学习数据样本时,在解决挑战性问题方面更有效。对于理解和生成大量语言(文本)数据等非常高级的用例,您甚至可能需要考虑像大型语言模型 (LLM) 这样的强大基于 Transformer 的架构。
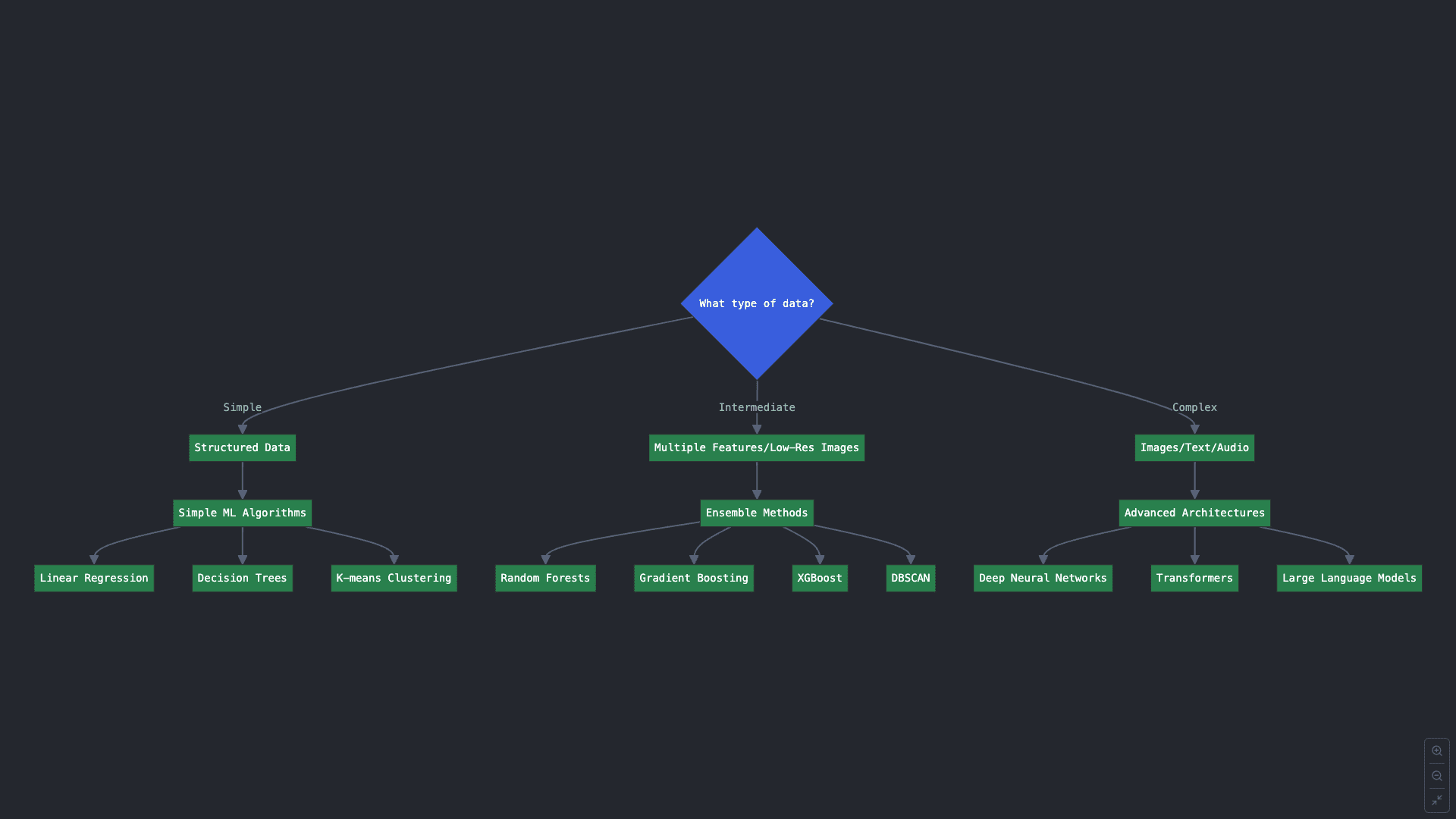
关键问题 2 的决策流程图(点击放大)
图片由编辑提供
关键问题 3:您需要多大程度的可解释性?
在某些情况下,了解 ML 算法如何做出决策(例如预测)、哪些输入因素会影响决策以及如何影响决策很重要,可解释性是可能影响您算法选择的另一个重要方面。经验法则是,算法越简单,可解释性越强。因此,线性回归和小型决策树是最具可解释性的解决方案,而具有复杂内部架构的深度神经网络通常被称为黑盒模型,因为其决策难以解释且行为难以理解。如果需要在可解释性和处理复杂数据的高效性之间取得平衡,则决策树的集成方法(如随机森林)通常是一个不错的折衷方案。
关键问题 4:您处理的数据量有多大?
这个问题与关键问题 2 密切相关。一些 ML 算法比其他算法更有效,这取决于用于训练它们的数据量。另一方面,神经网络等复杂选项通常需要大量数据才能学习以完成其构建的任务,即使以牺牲训练效率为代价。这里的经验法则是,在选择正确的算法类型时,数据量在大多数情况下与数据复杂度密切相关。
应用示例
为了总结并补充本指南,这里有一个表格,其中包含一些现实世界的用例,并概述了本文中考虑的决策因素。
| 用例 | 问题类型 | 推荐算法 | 数据 | 关键考虑因素 |
|---|---|---|---|---|
| 预测月销售额 | 回归 | 线性回归 | 结构化数据 | 可解释、快速、对小数据有效 |
| 交易欺诈检测 | 二元分类 | 逻辑回归、SVM | 结构化数据 | 精度和速度之间的平衡 |
| 图像中的产品分类 | 图像分类 | 卷积神经网络 (CNN) | 图像(非结构化数据) | 高精度、高计算成本 |
| 产品评论的情感分析 | 文本分类 (NLP) | Transformer 模型 (BERT, GPT) | 文本(非结构化数据) | 需要高级资源,准确度高 |
| 大数据集上的客户流失预测 | 分类或回归 | 随机森林、梯度提升 | 结构化和大数据集 | 可解释性较差,对大数据非常有效 |
| 自动文本生成或回答查询 | 高级 NLP | 大型语言模型 (GPT, BERT) | 大量文本 | 高计算成本,结果精确 |







非常信息,谢谢
谢谢您的反馈,Ibrahem!我们非常感谢!