情感分析是一个自然语言处理问题,旨在理解文本并预测其潜在意图。
在本帖中,您将了解如何使用 Keras 深度学习库在 Python 中预测电影评论的情感,将其分为正面或负面。
阅读本文后,你将了解:
- 关于用于自然语言处理的 IMDB 情感分析问题以及如何在 Keras 中加载它
- 如何在 Keras 中为自然语言问题使用词嵌入
- 如何为 IMDB 问题开发和评估多层感知器模型
- 如何为 IMDB 问题开发一维卷积神经网络模型
开始您的项目,阅读我的新书《Python 深度学习》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2016 年 7 月:首次发布
- 更新 2016 年 10 月:已更新以适应 Keras 1.1.0 和 TensorFlow 0.10.0
- 2017 年 3 月更新:更新至 Keras 2.0.2、TensorFlow 1.0.1 和 Theano 0.9.0
- 更新 2019 年 7 月:如果您使用的是 Keras 2.2.4 和 NumPy 1.16.2+ 并遇到“ValueError: Object arrays cannot be loaded when allow_pickle=False”(对象数组在 allow_pickle=False 时无法加载),请尝试更新 NumPy 至 1.16.1,更新 Keras 至 GitHub 版本,或使用此处描述的修复方法
- 更新 2019 年 9 月:已更新以适应 Keras 2.2.5
- 2022 年 7 月更新:更新至 TensorFlow 2.x API

使用深度学习从电影评论预测情绪
照片由 SparkCBC 提供,保留部分权利。
IMDB 电影评论情感问题描述
该数据集是大型电影评论数据集,通常称为 IMDB 数据集。
IMDB 数据集包含 25,000 条高度极化的电影评论(好评或差评)用于训练,另外 25,000 条用于测试。问题是确定给定的电影评论是正面还是负面情绪。
该数据由斯坦福大学的研究人员收集,并在2011 年的一篇论文[PDF] 中使用,该论文将数据 50/50 分割用于训练和测试。准确率达到了 88.89%。
该数据也作为 2014 年底至 2015 年初题为“词袋模型遇上爆米花袋”的 Kaggle 竞赛的基础。准确率达到了 97% 以上,获胜者达到了 99%。
Python 深度学习需要帮助吗?
参加我的免费为期两周的电子邮件课程,发现 MLP、CNN 和 LSTM(附代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
使用 Keras 加载 IMDB 数据集
Keras 提供了对IMDB 数据集的内置访问。
keras.datasets.imdb.load_data() 允许您以可用于神经网络和深度学习模型格式加载数据集。
单词已被整数替换,这些整数表示单词在数据集中出现的绝对流行度。因此,每条评论中的句子由整数序列组成。
首次调用 imdb.load_data() 将把 IMDB 数据集下载到您的计算机,并将其存储在您的主目录下的 ~/.keras/datasets/imdb.pkl 中,作为一个 32MB 的文件。
有用的地方在于,imdb.load_data() 提供了额外的参数,包括要加载的顶级单词数量(其中整数值较低的单词在返回的数据中被标记为零)、要跳过的顶级单词数量(以避免重复使用“the”),以及支持评论的最大长度。
让我们加载数据集并计算它的一些属性。您将从加载一些库和整个 IMDB 数据集作为训练数据集开始。
|
1 2 3 4 5 6 7 8 |
import numpy as np from tensorflow.keras.datasets import imdb import matplotlib.pyplot as plt # 加载数据集 (X_train, y_train), (X_test, y_test) = imdb.load_data() X = np.concatenate((X_train, X_test), axis=0) y = np.concatenate((y_train, y_test), axis=0) ... |
接下来,您可以显示训练数据集的形状。
|
1 2 3 4 5 |
... # 总结大小 print("Training data: ") print(X.shape) print(y.shape) |
运行此代码片段,您可以看到有 50,000 条记录。
|
1 2 3 |
训练数据 (50000,) (50000,) |
您还可以打印唯一的类别值。
|
1 2 3 4 |
... # 总结类别数量 print("Classes: ") print(np.unique(y)) |
您可以看到这是一个二元分类问题,用于评论中的好评和差评。
|
1 2 |
类别 [0 1] |
接下来,您可以了解数据集中唯一单词的总数。
|
1 2 3 4 |
... # 总结单词数量 print("Number of words: ") print(len(np.unique(np.hstack(X)))) |
有趣的是,您可以看到整个数据集中有近 100,000 个单词。
|
1 2 |
单词数量 88585 |
最后,您可以了解平均评论长度。
|
1 2 3 4 5 6 7 8 |
... # 总结评论长度 print("Review length: ") result = [len(x) for x in X] print("Mean %.2f words (%f)" % (np.mean(result), np.std(result))) # 绘制评论长度 plt.boxplot(result) plt.show() |
您可以看到平均评论长度接近 300 个单词,标准差略高于 200 个单词。
|
1 2 |
评论长度 平均 234.76 个单词 (172.911495) |
查看评论长度(以单词为单位)的箱线图,您可以看到这是一个指数分布,您可以通过截断长度在 400 到 500 个单词之间覆盖大部分分布。
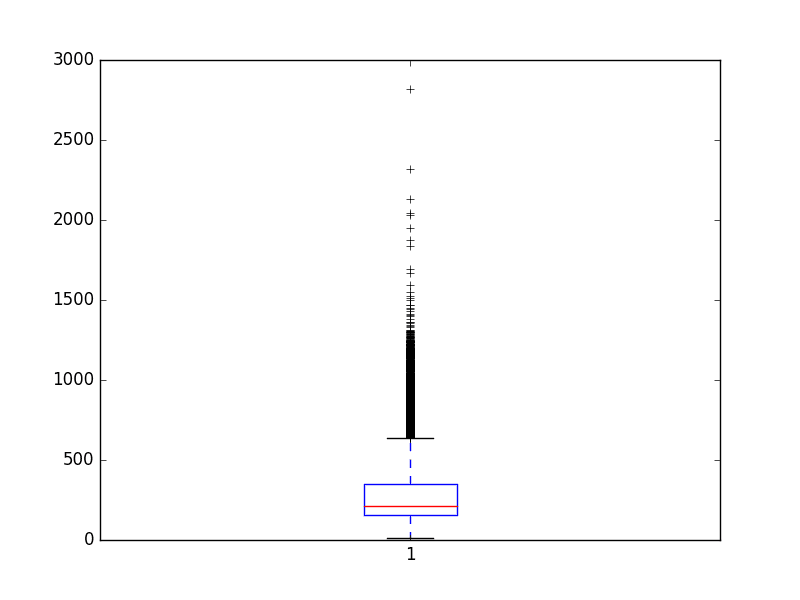
IMDB 数据集的评论长度(以单词为单位)
词嵌入
自然语言处理领域最近的一项突破是词嵌入。
这项技术是将单词编码为高维空间中的实值向量,其中单词在意义上的相似性转化为向量空间中的接近度。
离散的单词被映射到连续数字的向量。这在使用神经网络和深度学习模型的自然语言处理问题时非常有用,因为它们需要数字作为输入。
Keras 提供了一种便捷的方式,通过Embedding 层将单词的正整数表示转换为词嵌入。
该层接收定义映射的参数,包括预期的最大单词数,也称为词汇量大小(例如,将作为整数看到的整数值的最大值)。该层还允许您指定每个单词向量的维度,称为输出维度。
您希望为 IMDB 数据集使用词嵌入表示。
假设您只对数据集中使用频率前 5,000 个单词感兴趣。因此,您的词汇量大小将是 5,000。您可以选择使用 32 维向量来表示每个单词。最后,您可能希望将最大评论长度限制为 500 个单词,截断超过该长度的评论,并用 0 值填充短于该长度的评论。
您将按如下方式加载 IMDB 数据集
|
1 2 |
... imdb.load_data(nb_words=5000) |
然后,您将使用 Keras 工具,通过 `sequence.pad_sequences()` 函数将数据集截断或填充到每个观测值的长度为 500。
|
1 2 3 |
... X_train = sequence.pad_sequences(X_train, maxlen=500) X_test = sequence.pad_sequences(X_test, maxlen=500) |
最后,稍后,您的模型的第一个层将是一个使用 Embedding 类创建的词嵌入层,如下所示
|
1 2 |
... Embedding(5000, 32, input_length=500) |
这个第一层的输出将是一个矩阵,对于给定的评论训练或测试模式,其大小为 32x500。
现在您知道如何在 Keras 中加载 IMDB 数据集以及如何为它使用词嵌入表示,让我们来开发和评估一些模型。
IMDB 数据集的简单多层感知器模型
您可以从开发一个具有单个隐藏层 的简单多层感知器模型开始。
词嵌入表示是一项真正的创新,您将展示在 2011 年被认为是世界一流的结果,只需付出相对简单的神经网络。
让我们开始导入此模型所需的类和函数,并将随机数生成器初始化为一个常量值,以确保您可以轻松重现结果。
|
1 2 3 4 5 6 7 8 9 |
# IMDB 问题的 MLP from tensorflow.keras.datasets import imdb from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Embedding from tensorflow.keras.preprocessing import sequence ... |
接下来,您将加载 IMDB 数据集。您将如词嵌入部分所讨论的那样简化数据集——只加载前 5,000 个单词。
您还将使用 50/50 的数据集分割成训练集和测试集。这是一个很好的标准分割方法。
|
1 2 3 4 |
... # 加载数据集,但只保留前 n 个单词,其余置零 top_words = 5000 (X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words) |
您将评论长度限制为 500 个单词,截断较长的评论,并用零填充较短的评论。
|
1 2 3 4 |
... max_words = 500 X_train = sequence.pad_sequences(X_train, maxlen=max_words) X_test = sequence.pad_sequences(X_test, maxlen=max_words) |
现在,您可以创建模型了。您将使用 Embedding 层作为输入层,将词汇量设置为 5,000,词向量大小设置为 32 维,input_length 设置为 500。如前一节所述,此第一层的输出将是一个 32x500 大小的矩阵。
您将嵌入层的输出展平成一维,然后使用一个具有 250 个单元和整流激活函数的密集隐藏层。输出层有一个神经元,并将使用 sigmoid 激活来输出 0 和 1 的预测值。
该模型使用对数损失,并通过高效的 ADAM 优化过程进行优化。
|
1 2 3 4 5 6 7 8 9 |
... # 创建模型 model = Sequential() model.add(Embedding(top_words, 32, input_length=max_words)) model.add(Flatten()) model.add(Dense(250, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary() |
您可以拟合模型,并在训练时使用测试集作为验证集。此模型过拟合得非常快,因此您将使用很少的训练轮次,在本例中为 2 轮。
数据量很大,因此您将使用 128 的批次大小。在模型训练完成后,您将在测试数据集上评估其准确率。
|
1 2 3 4 5 6 |
... # 拟合模型 model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=2, batch_size=128, verbose=2) # 模型的最终评估 scores = model.evaluate(X_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1]*100)) |
将所有这些结合起来,完整的代码清单如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# IMDB 问题的 MLP from tensorflow.keras.datasets import imdb from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Embedding from tensorflow.keras.preprocessing import sequence # 加载数据集,但只保留前 n 个单词,其余置零 top_words = 5000 (X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words) max_words = 500 X_train = sequence.pad_sequences(X_train, maxlen=max_words) X_test = sequence.pad_sequences(X_test, maxlen=max_words) # 创建模型 model = Sequential() model.add(Embedding(top_words, 32, input_length=max_words)) model.add(Flatten()) model.add(Dense(250, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary() # 拟合模型 model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=2, batch_size=128, verbose=2) # 模型的最终评估 scores = model.evaluate(X_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1]*100)) |
运行此示例,将拟合模型并总结估计的性能。
注意:您的结果可能会有所不同,这取决于算法或评估程序的随机性质,或数值精度的差异。考虑运行示例几次并比较平均结果。
您可以看到,这个非常简单的模型以最小的努力达到了 87% 的分数,这接近于原始论文。
|
1 2 3 4 5 |
第 1 轮/2 轮 196/196 - 4s - loss: 0.5579 - accuracy: 0.6664 - val_loss: 0.3060 - val_accuracy: 0.8700 - 4s/epoch - 20ms/step 第 2 轮/2 轮 196/196 - 4s - loss: 0.2108 - accuracy: 0.9165 - val_loss: 0.3006 - val_accuracy: 0.8731 - 4s/epoch - 19ms/step 准确率:87.31% |
如果您训练这个网络,您很可能会做得更好,也许可以使用更大的嵌入并添加更多隐藏层。
让我们尝试一种不同的网络类型。
IMDB 数据集的一维卷积神经网络模型
卷积神经网络旨在保留图像数据中的空间结构,同时对场景中学习对象的 {*位置*}和 {*方向*}具有鲁棒性。
这种相同的原理可以应用于序列,例如电影评论中的一维单词序列。使 CNN 模型对学习识别图像对象有吸引力的相同属性也有助于学习段落中的结构,即 {*特征*}{*位置*} {*不变性*}。
Keras 分别通过 `Conv1D` 和 `MaxPooling1D` 类支持一维卷积和池化。
再次,让我们导入此示例所需的类和函数,并将随机数生成器初始化为常量值,以便您可以轻松重现结果。
|
1 2 3 4 5 6 7 8 9 |
# IMDB 问题的 CNN from tensorflow.keras.datasets import imdb from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Conv1D from tensorflow.keras.layers import MaxPooling1D from tensorflow.keras.layers import Embedding from tensorflow.keras.preprocessing import sequence |
您也可以像以前一样加载和准备 IMDB 数据集。
|
1 2 3 4 5 6 7 8 |
... # 加载数据集,但只保留前 n 个单词,其余置零 top_words = 5000 (X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words) # 将数据集填充到最大评论长度(以单词为单位) max_words = 500 X_train = sequence.pad_sequences(X_train, maxlen=max_words) X_test = sequence.pad_sequences(X_test, maxlen=max_words) |
现在您可以定义您的卷积神经网络模型了。这次,在 Embedding 输入层之后,插入一个 Conv1D 层。这个卷积层有 32 个特征图,一次读取词嵌入的三个向量元素。
卷积层后面是一个 1D 最大池化层,长度和步长都为 2,它将卷积层的特征图大小减半。网络的其余部分与上面神经网络相同。
|
1 2 3 4 5 6 7 8 9 10 11 |
... # 创建模型 model = Sequential() model.add(Embedding(top_words, 32, input_length=max_words)) model.add(Conv1D(filters=32, kernel_size=3, padding='same', activation='relu')) model.add(MaxPooling1D(pool_size=2)) model.add(Flatten()) model.add(Dense(250, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary() |
您将像以前一样拟合网络。
|
1 2 3 4 5 6 |
... # 拟合模型 model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=2, batch_size=128, verbose=2) # 模型的最终评估 scores = model.evaluate(X_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1]*100)) |
将所有这些结合起来,完整的代码清单如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# IMDB 问题的 CNN from tensorflow.keras.datasets import imdb from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Conv1D from tensorflow.keras.layers import MaxPooling1D from tensorflow.keras.layers import Embedding from tensorflow.keras.preprocessing import sequence # 加载数据集,但只保留前 n 个单词,其余置零 top_words = 5000 (X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words) # 将数据集填充到最大评论长度(以单词为单位) max_words = 500 X_train = sequence.pad_sequences(X_train, maxlen=max_words) X_test = sequence.pad_sequences(X_test, maxlen=max_words) # 创建模型 model = Sequential() model.add(Embedding(top_words, 32, input_length=max_words)) model.add(Conv1D(32, 3, padding='same', activation='relu')) model.add(MaxPooling1D()) model.add(Flatten()) model.add(Dense(250, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary() # 拟合模型 model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=2, batch_size=128, verbose=2) # 模型的最终评估 scores = model.evaluate(X_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1]*100)) |
运行此示例,您会首先看到网络结构的摘要。您可以看到卷积层保留了您嵌入输入层 32 维输入和最多 500 个单词的维度。池化层将该表示减半以压缩它。
注意:您的结果可能会有所不同,这取决于算法或评估程序的随机性质,或数值精度的差异。考虑运行示例几次并比较平均结果。
运行此示例,与上面的神经网络模型相比,准确率略有提高,达到了 87%。
|
1 2 3 4 5 |
第 1 轮/2 轮 196/196 - 5s - loss: 0.4661 - accuracy: 0.7467 - val_loss: 0.2763 - val_accuracy: 0.8860 - 5s/epoch - 24ms/step 第 2 轮/2 轮 196/196 - 5s - loss: 0.2195 - accuracy: 0.9144 - val_loss: 0.3063 - val_accuracy: 0.8764 - 5s/epoch - 24ms/step 准确率:87.64% |
同样,还有很大的优化空间,例如使用更深和/或更大的卷积层。
一个有趣的思路是将最大池化层设置为使用 500 的输入长度。这将把每个特征图压缩成一个 32 长度的向量,并可能提高性能。
总结
在本帖中,您了解了用于自然语言处理的 IMDB 情感分析数据集。
您学习了如何开发情感分析的深度学习模型,包括:
- 如何在 Keras 中加载和查看 IMDB 数据集
- 如何开发用于情感分析的大型神经网络模型
- 如何开发用于情感分析的一维卷积神经网络模型
您对情感分析或本帖有任何疑问吗?请在评论中提问,我将尽力回答。
")
")
")



imdb.load_data(nb_words=5000, test_split=0.33)
TypeError: load_data() got an unexpected keyword argument ‘test_split’
Keras 1.08 中似乎不存在 test_split 参数,也许我做错了什么?
API 已更改,抱歉。我将更新示例。您可以删除“test_split”参数。
我已将示例更新为匹配 Keras 1.1.0 和 TensorFlow 0.10.0 的 API 更改。
您好,感谢您的教程。但我想知道您是否有关于基于方面的情感分析的教程?
什么是基于方面的情感分析?
一个多类别分类问题,其中每个句子都与一个“方面”相关联。有两种形式;分类和基于术语。可用数据集
SemEval-2014 http://alt.qcri.org/semeval2014/task4/index.php?id=data-and-tools
SemEval-2015 http://alt.qcri.org/semeval2015/task12/
值得回顾的两篇论文
Bo Wang 和 Min Liu 的《基于方面的情感分析的深度学习》
S Jebbara 和 P Cimiano 的《基于方面的情感分析:一种双步神经网络架构》。
也有它的无监督版本(术语提取),但分类可能更受欢迎。这个数据集需要标记。
感谢分享。
嗨,Jason,
感谢您的精彩教程!我该如何修改它以进行用户输入的评论分析?或者从 Twitter 流进行分析?
祝好
您需要使用相同的字符到整数映射来编码推文。
我现在没有相关代码。
1. 嵌入是可训练的,对吗?我的意思是,嵌入是动态的,并且在训练过程中会发生变化?
2. 如何将嵌入保存到文件?我们需要加载嵌入以便将来预测新数据。
3. 我有一个名为 predict.py 的文件。我知道如何从这里加载模型和图形架构:https://machinelearning.org.cn/save-load-keras-deep-learning-models/
但是如何在 predict.py 中加载嵌入以预测新数据?
你好 Jie,提得好。
嵌入是一种映射,可以从数据中准备。我不会说它们是学习到的,但也许你可以这么说。
我相信它们可以确定性地准备,这样我们就无需将它们保存到文件。我可能错了,但这是我的直觉。
Jason,非常感谢您的课程!它们太棒了!!!!
也许我问了一个非常愚蠢的问题,但我无法理解一件事。什么是嵌入层?你能举个例子吗?我的意思是这是维度为 500X32 的词向量。它是怎么样的?
[0,0,1,….0,0,0] X 32
.
X500
.
[0,1,0,….0,0,0] X 32
里面是什么数字?为什么如果我们将其维度提高到 64,准确率就会上升?
谢谢!
test_split = 0.33
这是定义的,但代码中没有使用。为什么呢?
这是一个拼写错误,应该删除,谢谢 Martin。我将很快更新示例。
为了实现您在文章最后提到的提高准确性的目标,您通常会更改哪些参数?
引用您的话:“将最大池化层设置为使用输入长度 500。这将把每个特征图压缩成一个长度为 32 的向量”
您能否帮助我确定需要更改哪些参数(哪些行)?
你好 Anand,尝试并进行一些试错,然后为问题调整方法。
我正在使用 model.predict(X_test) 和 model.predict_classes(X_test) 来测试预测的概率和值
我注意到 0 类的预测概率都为 0.5,而中位数预测概率为 0.9673。
我是否可以假设 model.predict 总是返回 1 类的概率,并且当该概率低于 50% 时预测为 0 类?
你好 Jim,
我期望 model.predict() 正在对概率执行 arg max(选择具有最高概率的类)。
如果仔细研究代码,就可以知道这一点
https://github.com/fchollet/keras/tree/master/keras
Jim,你能把你的测试文件发给我吗?
当数据中的一个元素被标记为整数时,比如说 4,它是否可以代表任何出现 4 次的词,还是它是唯一词的表示?
你好 brent,每个整数代表一个唯一的词。
嗨,Jason,
感谢这次很棒的教程,一如既往地精彩!
您提到“每个整数代表一个唯一的词”,为什么?
我的假设是我们已将每个词映射到其在整个语料库中的频率。如果我的假设成立,那么两个词的频率可能会相同。例如,“狗”和“猫”在语料库中都可能重复 10 次。
如果我的假设是错误的,您能否纠正我?
谢谢,
单词按频率排序,然后根据该频率分配整数。
Jason,您好,最近我熟悉了机器学习和深度学习的基础知识,部分得益于本网站提供的信息,我发现这些信息非常有见地。
但是,最近我遇到了一个自动从文本生成简单简短问题的难题。由于我缺乏知识和专业知识,我无法评估这个问题是否可以用深度学习或其他方法来解决。目前我有一个数据库,其中包含数千个基于大约一百个语料库的问题,可以用作训练数据。您认为我能取得任何成功的结果吗?如果可以,哪种方法最好?(考虑到即使有一半时间它会产生无意义的内容,它仍然可以节省大量工作)
Agustin,这听起来确实是一个很好的深度学习问题。
我建议阅读一些关于该主题的论文,以激发关于方法和问题表示方式的想法。
尝试在 google scholar 和 arvix 上搜索。
你好,感谢这个例子!你知道你在例子中使用的 NumPy 和 matplotlib 的版本吗?我在使用 mean、std 和 box plot 等几种方法时遇到问题。
你好 Chris,
这可能是 Python 2 与 Python 3 的问题,我使用的是 Python 2。
实际上,我認為是 map() 的調用。您使用的是哪個版本的 Python?
抱歉發送垃圾信息。這在 Python 3 中有效
# 总结评论长度
print(“Review length: “)
result = list(map(len, X))
print(type(result))
print(result)
Python 3.5.2 :: Anaconda 4.1.1 (x86_64)
Keras (1.2.1)
tensorflow (0.12.1)
numpy (1.11.2)
matplotlib (1.5.3)
嗨,
您能否给我一些关于如何实现其他深度学习技术,如递归自动编码器(RAE)、RBM深度学习算法进行情感分析的思路?
任何帮助都将不胜感激 :)
此致
你好 Akshit,
我没有 RAE 或 RBM 的例子。
这篇帖子有一个情感分析的例子,你可以作为起点。
你好,谢谢这个例子。我真的很感激你能告诉我为什么会出现这个错误。
File “C:\Anaconda\lib\site-packages\theano-0.9.0.dev4-py2.7.egg\theano\gof\cmodule.py”, line 2236, in compile_str
raise MissingGXX(“g++ not available! We can’t compile c code.”)
MissingGXX: (‘The following error happened while compiling the node’, Shape_i{1}(embedding_2_W), ‘\n’, “g++ not available! We can’t compile c code.”, ‘[Shape_i{1}(embedding_2_W)]’)
@Zhang,看起来你使用的是 Theano 的测试版本。如果你只是想开始,也许你想尝试一个稳定的频道?看起来你从源代码安装,你的环境设置不太对。
感谢 Chri 的提示。
你好 Zhang,
看起来 g++ 不可用。我不是 Windows 用户,我不确定如何解释这个消息。
考虑在 stack overflow 上搜索或发帖。
@Jason,谢谢你的回复,再次感谢你的帖子!
我在这方面结果的改进遇到了困难。我更改了 pool_length(500,250,125,375,5,10,15,20),尝试添加另一个大小为 250 和 500 的密集层,并更改了 epoch 的数量(25,50)。
您对调整模型有什么建议吗?我尝试了建议(更深、更大、pool_length,以及 epoch 的数量)。您对提高整体性能有任何技巧或阅读建议吗?这似乎是我真正能够做机器学习的最后一个“障碍”。
谢谢!
Chris,实验得很好。
也许需要改变问题本身的结构。
这篇帖子可能会带来更多关于如何提高性能的想法
https://machinelearning.org.cn/improve-deep-learning-performance/
你好 Jason,我移除了带有 250 个神经元的密集层,它极大地减少了需要训练的参数数量,并且在 5 个 epoch 中精度提高了约 1%。您是否知道为什么在 flatten 层之后添加了 2 个密集层?
Kiran,做得好。
我通过一些简短的试错得出了这个配置。它没有经过优化。
如果我们稍后在 scores 函数中评估模型,在 fit 函数中将 validation_data 指定为 X_test,y_test 有意义吗?还是我们可以跳过在 model.fit(...) 中指定 validation_data?
不,您将在拟合模型时免费获得此信息。验证数据应与训练数据不同,并且是完全可选的。
这种方法的准确性是多少?哪种方法能获得至少 0.89 的准确率更好?
准确率:88.28%
我尝试了使用卷积神经网络和 LSTM 进行情感分析,发现 CNN 的准确率更高。您对此有何见解?
一些想法
也许 CNN 更擅长捕捉空间关系。
也许 LSTM 需要更大并且训练更长时间才能达到相同的技能。
请将以下内容添加到导入中
from keras.preprocessing import sequence
from keras.layers.embeddings import Embedding
这些已列在标题为“IMDB 数据集的 1D 卷积神经网络模型”的部分的导入中
你好 Jason,我和 Maxim 有同样的问题。你能告诉我为什么吗?谢谢。
也许我问了一个非常愚蠢的问题,但我无法理解一件事。什么是嵌入层?你能举个例子吗?我的意思是这是维度为 500X32 的词向量。它是怎么样的?
[0,0,1,….0,0,0] X 32
.
X500
.
[0,1,0,….0,0,0] X 32
里面是什么数字?为什么如果我们将其维度提高到 64,准确率就会上升?
谢谢!
很好的问题。
嵌入层是将整数映射到更高维度的空间。参见此处
https://keras.org.cn/layers/embeddings/
还有这里
https://en.wikipedia.org/wiki/Word_embedding
我希望在专门的帖子中更详细地介绍这一点。
非常感谢这个精彩的教程。
但是,我问的是如何使用它来预测观点
我仍然不知道,例如,我想知道电影是好还是坏,或者如果我使用 Twitter 数据集,我想知道公众对某个标签或话题的意见总结。
我试了很多次但都失败了,因为我仍然是初学者
提前感谢 <3
好吧,非常感谢您的这项伟大工作。
我有一个问题。我不明白为什么我们使用 ReLU 而不是 tanh 作为激活函数。大多数人使用 SGD 或反向传播进行训练。我们在这里使用了什么?我不知道 ADAM。您能解释一下为什么在训练中使用它吗?
ReLU 比 sigmoid 或 tanh 具有更好的特性,并且已成为新的事实标准。
我们确实使用了 SGD 来拟合模型,只是使用了一个更高级的版本,称为 Adam。
你好,非常感谢这个有用的教程。我有一个问题,可能有点奇怪。如果我们使用预训练的 word2vec 模型怎么办?我的意思是,如果我们只使用预训练的 word2vec 模型并用电影评论数据训练我们的神经网络。如果我说错了,请纠正我!
或者最好的方法是使用电影评论数据训练 word2vec,然后使用相同的电影评论数据训练神经网络,然后进行尝试。
请指导我。谢谢
听起来不错,试试吧。
但是,我应该使用预训练的 word2vec 模型(用 wiki 数据训练),还是从头开始训练(使用电影评论数据或亚马逊产品评论数据)?谢谢
尝试这两种方法,看看哪种最适合您的问题。
嗨,Jason,
我正试图将 tfidf 矩阵作为输入传递给我的 cnn 进行文档分类。我不想使用嵌入层。你能帮我实现这个吗?我还没有看到任何示例显示 tfidf 作为 Keras 中的 Cov1d 层的输入。请帮助
抱歉,我没有将 tfidf 作为 CNN 的输入。
Jason 尊敬的,我非常感谢您提供的这篇很棒的帖子。您能否给我一些关于如何将此方法扩展到多类别分类的指示?
将输出层中的节点数设置为类的数量,并将激活函数更改为 softmax。
我看到您没有在模型中使用任何正则化器。如何避免过拟合?
在这里,通过欠指定模型和欠训练模型。
您也可以尝试 dropout 和权重正则化。
嘿 Jason,很棒的评论,但我正在想如何使用创建的模型来预测新输入文本的情感。
您可以使用与问题中相同的方法对测试数据进行编码,以便进行预测。
我希望很快会有更多 NLP 示例。
5000 是什么意思?
这是训练集和测试集中的样本数量。
我收到一个错误:在行“X_train = sequence.pad_sequences(X_train, maxlen=500)”中,“sequence”未定义。
确保您复制了所有代码,包括这一行
嗨,Jason,
感谢这篇精彩的帖子。我有一个关于如何使用该模型来预测新文本情感的问题。
myText=”Hello, this is a my review”
如何将此文本结构化到模型中?并使用 predict 函数。
我有一系列关于这个主题的帖子将在接下来的几周内发布,您能否等等?
我也被卡在进行新预测上。
问题究竟是什么?
我很难编码新的输入文本。我能否直接将[“我讨厌计算机错误”]传递给pad_sequences()?还是有其他方法?非常感谢您能提供一些建议!
单词必须先编码为整数,请参阅这篇博文
https://machinelearning.org.cn/prepare-text-data-deep-learning-keras/
嗨,Jason,
感谢您的博客和教程。既然您谈到了IMDB标准数据集,我刚刚写了一篇博客,提到了IMDB数据集上情感分析的最新模型的准确性。您可以在这里看到:http://blog.paralleldots.com/technology/nlp/breakthrough-research-papers-and-models-for-sentiment-analysis/
感谢分享。
你好 jason,
您做得很棒。我赞赏您的努力。实际上,我想知道,在“用于IMDB数据集的一维卷积神经网络模型”中,我如何知道这些问题的答案。
1)本次教程使用的神经元数量?
2)隐藏层数量?
3)输出层数量?
4)如果隐藏层数量最大化和最小化,输出是否会受到影响?
5)使用了多少参数?
6)如何使用代码或库在Python中绘制网络图?
请简要回答。谢谢
我们无法确切知道,这些配置超参数无法通过分析来确定。您必须通过实验来发现什么最适合特定的问题。
您可以在Keras中绘制网络图,这是API的详细信息
https://keras.org.cn/visualization/
我该如何进行实验?我应该根据什么来进行实验?您是否有教程,其中您手动将数据集输入任何NN进行情感分析?
是的,我计划在本月晚些时候发布一些帖子。
嗨,jason
我想知道如何将此模型用于我自己的数据集,该数据集在csv文件中。数据集包含习语句子的极性。
我很快会在博客上提供一个示例。
好的,Jason,我等着……请也给我发送通知。因为在您的博客上,我没有收到关于任何回复的通知或电子邮件。
嗨Jason,很棒的帖子!我从您之前的帖子中学到了很多。非常感谢!
对于情感分析,如果我们更改输出层的softmax激活,可以获得更好的结果(在此情况下为0.8822)。
非常棒的提示,谢谢!
你好,Jason。
我使用了CNN模型进行情感分析。
我有一组自己的字符串来测试该模型。
我需要对我的字符串进行哪些转换才能将它们输入到模型中?
谢谢。
您可以使用词袋模型或词嵌入。
我在这两方面都有帖子,也许可以从这里开始
https://machinelearning.org.cn/start-here/#nlp
谢谢。
我会仔细阅读的。
告诉我进展如何。
你好,Conv2D的准确率更高吗?在这种情况下,输入形状是多少?您在关于深度学习用于NLP的书中有介绍Conv2D吗?
谢谢。
这不是准确率的问题,而是对数据是否合适的问题。
像单词序列这样的1D数据需要一维卷积神经网络。
Jason您好,在您书中NLP(文本分类章节)的一个示例中,model.predict需要三个输入数组,因为我们处理的是三个通道。虽然model.evaluate运行正常,但我还是不明白在predict.sentiment函数中在哪里定义了三个输入。
如果您能指导一下,那将非常有帮助。
您可以将3个输入作为数组传递给predict函数
这有帮助吗?
嗨,Jason,
您使用了预构建的数据集,但如果我想在我的数据集上运行此模型(例如,在我的情况下,我想在我的推文数据集上运行它),我该如何使我的数据集与此博客代码兼容?请提供一些建议或参考,以便我能使推文数据集与此模型保持一致。
此致,
这篇博文展示了如何操作
https://machinelearning.org.cn/develop-word-embedding-model-predicting-movie-review-sentiment/
谢谢 Jason,
我从您的帖子中学到了很多。
此模型在二元分类上表现良好,但在多类分类上表现不佳。我的问题是,在多类(例如10个或更多类别)的情况下,对层或其参数进行什么更改可以提高准确性?
我建议尝试一系列配置,看看在您的特定数据上哪种效果最好。
嘿Jason,您好,非常棒的教程,但我不知道为什么pad.sequences那一行会出错,它说名称sequence未定义,我不明白为什么会收到这个错误?您能帮忙吗?
很抱歉听到这个。您能检查一下是否复制了所有代码吗?
嘿,感谢您的辛勤工作,我只是想知道如何打印出这个预测结果,哪些是正面评论,哪些是负面评论?
你到底遇到了什么问题?
我也有这个错误:NameError Traceback (most recent call last)
in ()
—-> 1 X_train = sequence.pad_sequences(X_train, maxlen=500)
2 X_test = sequence.pad_sequences(X_test, maxlen=500)
NameError: name ‘sequence’ is not defined
确保您已复制所有必需的代码。
嘿Jason,我如何使用“predict”来使用模型?例如,我有一段文本,我想根据模型查看结果。提前致谢
您可以使用model.predict()并以新数据作为参数。
请注意,新数据需要与训练数据以相同的方式进行准备。
您能分享如何使用模型进行预测吗?
当然
嗨,Jason,
如何根据用户在评论中使用的词语类型来判断用户是否生气?
首先收集生气和不生气的电影评论示例。
Jason先生您好……您能告诉我如何进行这个模型的测试吗……谢谢!
您说的“文件测试”是什么意思?
非常好的文章!清晰且精确。我只是对使用深度学习进行情感分类有一些保留。当然,这似乎是未来某种方式,但就目前而言,我们只能通过贝叶斯方法获得更好的结果。例如,我使用了相同的数据集(见http://www.ml-hack.com/bayesian-features-machines/),并通过贝叶斯学习获得了91.6%的准确率。您认为深度学习表现不佳是因为任务太简单了吗?还是因为数据集太小?
我很想听听您的想法
我看到CNN也表现得很好
https://machinelearning.org.cn/best-practices-document-classification-deep-learning/
嘿Jason。我想说的是,作为我的第一次尝试,我使用了多层感知机,但我遇到了这个问题,即是否可以使用相同的数据进行验证和测试?如果我们用测试数据验证我们的训练,结果是否会有偏见??
而且,每当我增加epoch数量时,损失就同时增加,而准确率总是在86%左右。请指导我。
在未用于训练的数据上评估模型的技能是一个好主意,请在此了解更多信息
https://machinelearning.org.cn/faq/single-faq/how-do-i-evaluate-a-machine-learning-algorithm
Jason您好!!!
对于推特情感分析,x_train、x_test、y_train和y_test将是什么?
其中标签是浮点数值?
我不明白这些列表是什么?
您能解释一下吗?
输入将是文本,输出将是情感类别标签。
训练和测试将是对数据进行拆分,以分别拟合和评估模型。
我想知道第二个epoch后验证损失增加的原因??是我有什么错误吗?
也许模型过拟合了?
这是您示例中的MLP代码,我该怎么做才能提高准确率并消除过拟合?Dropout层有用吗?
可能有用。这里有更多想法
https://machinelearning.org.cn/improve-deep-learning-performance/
Jason,谢谢!
我刚开始接触深度学习和NLP。
我有一些基础问题:
– 您为什么选择32作为参数?
– 我们现在可以使用这个学习到的模型来预测其他任何文本数据吗?例如,我想评估客户的反馈数据,我可以使用相同的模型来做到这一点吗?如果可以,如何做?
– 您是如何处理这个文本中的停用词和其他不相关词语的?
提前感谢🙂
我使用实验测试来配置模型。您可以在这里了解更多信息
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
是的,在合理范围内(例如,来自同一领域)。
我经常删除停用词。这是一个更完整的例子
https://machinelearning.org.cn/develop-word-embedding-model-predicting-movie-review-sentiment/
嗨,Jason,
IMDB电影评论分类的当前基准准确率是多少?
我不确定,准确率在88%以上就是很好的。
Jason,谢谢您的及时回复🙂 我真的很感激。
不客气。
嘿,杰森!
出色的工作。如何使用您的代码来预测相同的语料库和模型来预测员工反馈信息?我不明白如何将此用于其他数据。如何将您的代码作为起点?
这个过程将帮助您处理新的预测建模问题
https://machinelearning.org.cn/start-here/#process
您的教程对像我这样的初学者非常有帮助。我有一个疑问,如果我们使用一个只有两个标签(类和文本)的数据集,那么我应该创建多少个输入神经元?是1个还是多个?
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
Flatten()有什么用?
在某些模型中,网络将具有2D或3D的内部数据形状。Flatten将此压扁为1D,因为全连接层需要。
谢谢……
嗨,Jason,
非常感谢。很棒的帖子!
我有一些问题
1.您很好地解释了为什么maxlen设置为500。有没有一种简单的方法来检查其他长度(就像我们对模型超参数进行网格搜索一样),而不是手动检查?它重要吗?
2.在“一维CNN”部分,您在maxpool函数中使用了pool_size=2。这是什么原因/好处?
3.它紧随其后的Flatten层是正确的吗,因为pool_size是2?我的意思是——如果我只使用默认值,我是否就不需要它了?
您可以尝试其他长度。
Max pool of 2将filter map的大小减小到原来的1/4。这是一种常用的配置。
Flatten是为了减小filter map的结构,将其变为Dense层可以接受的向量。
好的,谢谢
不客气。
您好。
我有一个问题,假设我想将一些手工制作的特征注入CNN层进行情感分析。
首先我想知道是否可能?
然后如何使用全连接层来完成这个?我不想使用任何像SVM或其他方法,只想直接在CNN中使用深度特征和手工特征的组合。谢谢
是的,您可以拥有一个多输入模型,一个输入是文本,另一个输入是新特征。
我在博客上有很多这类模型的示例,也许可以从这里开始
https://machinelearning.org.cn/keras-functional-api-deep-learning/
我如何预测我新评论的结果?
例如 = “这部电影太棒了”
您必须以相同的方式准备数据并调用model.predict()。
也许可以试试这个教程
https://machinelearning.org.cn/develop-word-embedding-model-predicting-movie-review-sentiment/
你好
感谢本教程
我有一个关于如何使用交叉验证的问题?
这篇博文展示了如何操作
https://machinelearning.org.cn/k-fold-cross-validation/
你好,如何修改学习率?
好问题,本教程解释了如何操作
https://machinelearning.org.cn/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks/
Jason您好,再次感谢您提供这些教程。我在这里学到了很多东西。
在CNN的情况下,我从模型摘要中看到第一个Embedding层的参数数量是160000 (5000*32),我对此表示理解。但是为什么第一个Conv1D层的参数数量是3104?我猜想500个输入单词在Embedding层被转换为500 * 32个输出值,然后卷积是通过这个500*32的输入值和核大小为3进行的。我的理解正确吗?
我发现唯一的计算方法是3*32*32+32,但我无法想到1D卷积参数是如何应用于输入值的。您能否详细说明一下在这种情况下的一维卷积?(我阅读了https://blog.goodaudience.com/introduction-to-1d-convolutional-neural-networks-in-keras-for-time-sequences-3a7ff801a2cf,但解释很令人困惑……)
一个好的起点是总结模型并查看每一层的输出形状。
Jason您好,这是我之前问题的后续问题。
我想3104 = (32+1) * (3*32),所以对于每个32个输入值有3个核参数,这些核值在每个32个输入上都不同(3*32),并且所有32个输入值都被用来生成32个输出值中的每一个(加上偏置,因此乘以(32+1))。希望您能理解我的意思……🙂
嗨,Jason,
我遇到了命令(X_train, y_train), (X_test, y_test) = imdb.load_data()的错误
使用Python 3.6.8 [Anaconda],Windows 10上的win32版本
回溯(最近一次调用)
文件“”,第2行,在
File “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\keras\datasets\imdb.py”, line 59, in load_data
x_train, labels_train = f[‘x_train’], f[‘y_train’]
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\numpy\lib\npyio.py”,第 262 行,在 __getitem__ 中
pickle_kwargs=self.pickle_kwargs)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\numpy\lib\format.py”,第 692 行,在 read_array 中
raise ValueError(“Object arrays cannot be loaded when ”
ValueError: Object arrays cannot be loaded when allow_pickle=False
听到您遇到困难,我感到很抱歉,也许可以尝试更新 NumPy?
好的,我已从 ‘1.16.3’ 升级到 ‘1.16.4’,但仍然遇到了相同的错误。
Does (X_train, y_train), (X_test, y_test) = imdb.load_data() still work for you?
这是一个有趣的教程,如果它不能再使用了,那将是一个遗憾!
我有一个解决方法,在代码示例的开头添加以下几行:
基于
https://stackoverflow.com/questions/55890813/how-to-fix-object-arrays-cannot-be-loaded-when-allow-pickle-false-for-imdb-loa
太棒了,谢谢,这让我们取得了进展!但在欢呼之前,又出现了两个不兼容的问题。
1)
print(“Mean %.2f words (%f)” % (numpy.mean(result), numpy.std(result)))
回溯(最近一次调用)
File “”, line 1, in
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\numpy\core\fromnumeric.py”,第 3118 行,在 mean 中 out=out, **kwargs)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\numpy\core\_methods.py”,第 87 行,在 _mean 中 ret = ret / rcount
TypeError: unsupported operand type(s) for /: ‘map’ and ‘int’
2)
pyplot.boxplot(result)
pyplot.hist(result)
回溯(最近一次调用)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\matplotlib\units.py”,第 168 行,在 get_converter 中
if not np.all(xravel.mask)
AttributeError: ‘numpy.ndarray’ object has no attribute ‘mask’
处理上述异常时,发生了另一个异常
回溯(最近一次调用)
File “”, line 1, in
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\matplotlib\pyplot.py”,第 2659 行,在 hist 中
**({“data”: data} if data is not None else {}), **kwargs)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\matplotlib\__init__.py”,第 1810 行,在 inner 中
return func(ax, *args, **kwargs)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\matplotlib\axes\_axes.py”,第 6534 行,在 hist 中
self._process_unit_info(xdata=x[0], kwargs=kwargs)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\matplotlib\axes\_base.py”,第 2135 行,在 _process_unit_info 中
kwargs = _process_single_axis(xdata, self.xaxis, ‘xunits’, kwargs)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\matplotlib\axes\_base.py”,第 2118 行,在 _process_single_axis 中
axis.update_units(data)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\matplotlib\axis.py”,第 1467 行,在 update_units 中
converter = munits.registry.get_converter(data)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\matplotlib\units.py”,第 181 行,在 get_converter 中
converter = self.get_converter(next_item)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\matplotlib\units.py”,第 187 行,在 get_converter 中
thisx = safe_first_element(x)
文件 “C:\Users\XXX\AppData\Local\Continuum\anaconda3\envs\env_python_3.6\lib\site-packages\matplotlib\cbook\__init__.py”,第 1635 行,在 safe_first_element 中
raise RuntimeError(“matplotlib does not support generators ”
RuntimeError: matplotlib does not support generators as input
听到这个消息我很难过。
我可以确认,代码示例在 Keras 2.2.4 和 TensorFlow 1.14.0 下可以正常工作。
您能确认您复制了所有代码并且您的库是最新的吗?
1) 现在可以了,非常感谢。您可能想在上面的示例中包含这段代码,这样其他人也能正常运行
import numpy as np
np_load_old = np.load
np.load = lambda *a,**k: np_load_old(*a, allow_pickle=True, **k)
2) 错误消息是由于以下代码(在“# Summarize review length”下方)引起的:
result = map(len, X) # Bad version
result = [len(x) for x in X] # Good version which creates no errors.
您是刚刚修正了这个问题吗?否则我无法解释为什么复制粘贴会先引入“result = map(len, X)”。
出色的工作!
谢谢。我希望 Keras 会很快发布新版本,其中已包含此修复。
该代码在 Python 3.6 中从命令行运行时可以正常工作。您是否可能在 IDE/Notebook 中运行,或者使用了旧版本的 Python?
我使用的是 Windows 10 命令行模式下的 python 3.6.8。
我从未遇到过如此致力于支持其在线学习服务的人。我感到很惊讶。
总而言之,感谢您的指导,现在示例运行正常。
– Royal Truman 博士
谢谢,我很高兴听到它现在工作正常!
你好,Jason。
我正在尝试为此实现 Conv2D。我将核大小保持为 (3,3),但这似乎不起作用。但当我看到您的示例后切换到 Conv1D 时,它就成功了。您能告诉我为什么您决定使用 1D 以及两者是否有特定的用例吗?
谢谢
Swarupa
我认为 conv2d 不适用于文本输入。
我们使用 conv1d 是因为我们处理的是单词的一维序列。
Jason 先生,您能告诉我如何使用该模型对数据集中单个评论进行预测吗?
是的,您可以有一个样本输入并调用 predict()。
这会有帮助
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
Jason,感谢您精彩的课程。我注意到在此示例中,您没有为 LSTM 模型输入使用任何滑动窗口或时间步。然而,在其他 LSTM 示例和互联网上,我看到在 LSTM 模型中使用时间步转换数据集很有用?是真的吗?我何时需要用时间步预处理数据?提前感谢!
不客气。
这是文本数据,不是时间序列。如果您想查看时间序列的 LSTM 示例,请从这里开始:
https://machinelearning.org.cn/start-here/#deep_learning_time_series
感谢您的本教程
在这个数据集上使用 lstm 或 cnn-lstm 是否合适?
不客气。
对于这类问题,带有词嵌入的 CNN 或 LSTM 可能最合适。
嗨,Jason,
非常感谢您的博客/教程/书籍,它们非常棒。
我一直在努力让一个类似的笔记本(使用 keras.datasets 的 imdb 数据)在 Google Colab 中通过 TPU 工作。
有没有关于如何使本教程中的代码在 TPU 上工作的建议?
谢谢你,
Alex
不客气。
抱歉,我不知道 colab。
https://machinelearning.org.cn/faq/single-faq/do-code-examples-run-on-google-colab
我建议在您的工作站上运行示例。
作为比较,使用 CountVectorizer 和 TfidfTransformer 的传统方法可以达到 84.26% 的准确率(使用前 5k 个词),使用 MultinomialNB 和 88.68% 的准确率(使用 LinearSVC)。
干得好!感谢分享。
我一直在尝试让代码(MLP 用于 IMDB 问题)访问从源下载的本地保存的存档(imdb.npz)。
但每次我都会得到相同的结果(准确率:50%)。
输出显示
Train on 25000 samples, validate on 25000 samples
第 1 轮/2 轮
– 93s – loss: 7.9342 – acc: 0.4999 – val_loss: 7.9712 – val_acc: 0.5000
第 2 轮/2 轮
– 108s – loss: 7.9712 – acc: 0.5000 – val_loss: 7.9712 – val_acc: 0.5000
Accuracy: 50.00%
我在这里做错了什么?
如果能对以上内容有所指点,将非常感激。
你好 Pique… 你的模型的性能在训练过程中可能会卡住。
这可能会发生在神经网络中,它们达到特定的损失、误差或准确率后不再改进,在每个后续的epoch结束时显示相同的分数。
在最简单的情况下,如果你的代码示例有一个固定的随机数种子,那么尝试更改随机种子,或者不指定种子,以便每次运行代码时都使用不同的随机数。
然后尝试运行该示例几次。
要了解更多关于机器学习中的随机性,请参阅这篇博文
在机器学习中拥抱随机性
要了解更多关于机器学习中的伪随机数生成器,请参阅这篇博文
Python 机器学习中的随机数生成器简介
如果问题不是随机性,则可能是你的模型已收敛。如果模型在收敛后的技能不好,则称之为过早收敛。
你可以通过减慢模型的学习速度来解决过早收敛问题。你可以通过更改学习过程的不同超参数来做到这一点,例如
使用较小的学习率。
使用更大的网络(节点或层)。
使用包含更多示例的训练数据集。
等等……
过早收敛是一个重要的研究领域,如果你需要更多想法,我建议你进一步阅读该主题。