从机器学习的角度来看,预测是一个单一的点,它隐藏了该预测的不确定性。
预测区间提供了一种量化和传达预测不确定性的方法。它们与置信区间不同,后者旨在量化总体参数(如均值或标准差)的不确定性。预测区间描述了单个特定结果的不确定性。
在本教程中,您将了解预测区间以及如何为简单的线性回归模型计算它。
完成本教程后,您将了解:
- 预测区间量化了单点预测的不确定性。
- 对于简单模型,预测区间可以进行分析估计,但对于非线性机器学习模型则更具挑战性。
- 如何计算简单线性回归模型的预测区间。
通过我的新书《机器学习统计学》启动您的项目,其中包括逐步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2019年6月更新:修正了显著性水平作为标准差的一部分。
- 2020年4月更新:修正了预测区间图中的拼写错误。

机器学习的预测区间
图片由Jim Bendon提供,保留部分权利。
教程概述
本教程分为5个部分,它们是:
- 点估计有什么问题?
- 什么是预测区间?
- 如何计算预测区间
- 线性回归的预测区间
- 实例演示
需要机器学习统计学方面的帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
为什么要计算预测区间?
在预测建模中,给定一些输入变量,预测或预报是一个单一的结果值。
例如:
|
1 |
yhat = model.predict(X) |
其中,yhat是训练模型对给定输入数据X做出的估计结果或预测。
这是一个点预测。
根据定义,它是一个估计或近似值,并包含一些不确定性。
不确定性来自于模型本身的误差和输入数据中的噪声。该模型是输入变量和输出变量之间关系的近似值。
鉴于选择和调整模型所使用的过程,它将是根据可用信息做出的最佳近似值,但它仍然会产生误差。领域中的数据自然会掩盖输入和输出变量之间潜在的未知关系。这将使模型拟合变得具有挑战性,并且也会使拟合模型进行预测变得具有挑战性。
鉴于这两个主要的误差来源,预测模型中的点预测不足以描述预测的真实不确定性。
什么是预测区间?
预测区间是对预测不确定性的量化。
它为结果变量的估计提供了概率上限和下限。
单个未来观测值的预测区间是一个区间,它将以指定的置信度包含从分布中随机选择的未来观测值。
— 第27页,《统计区间:从业者和研究人员指南》,2017年。
预测区间最常用于使用回归模型进行预测或预报时,其中正在预测一个数量。
预测区间的呈现示例如下:
给定'x'的'y'预测,有95%的可能性区间'a'到'b'覆盖了真实结果。
预测区间围绕着模型所做的预测,并有望覆盖真实结果的范围。
下图有助于直观地理解预测、预测区间和实际结果之间的关系。
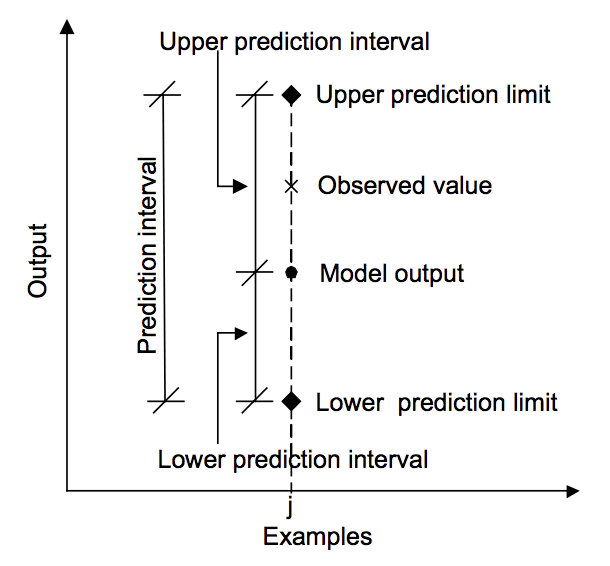
预测、实际值和预测区间之间的关系。
取自“用于估计模型输出预测区间的机器学习方法”,2006年。
预测区间与置信区间不同。
置信区间量化了估计总体变量(如均值或标准差)的不确定性。而预测区间则量化了从总体中估计的单个观测值的不确定性。
在预测建模中,置信区间可用于量化模型估计技能的不确定性,而预测区间可用于量化单个预测的不确定性。
预测区间通常比置信区间大,因为它必须将置信区间和正在预测的输出变量中的方差考虑在内。
预测区间总是比置信区间更宽,因为它们考虑了与e[误差]相关的不可约误差的不确定性。
— 第103页,《统计学习导论:R中的应用》,2013年。
如何计算预测区间
预测区间是模型估计方差和结果变量方差的某种组合。
预测区间易于描述,但在实践中难以计算。
在像线性回归这样的简单情况下,我们可以直接估计预测区间。
在非线性回归算法(如人工神经网络)的情况下,它更具挑战性,需要选择和实现专门的技术。可以使用自举重采样等通用技术,但计算成本高昂。
论文《基于神经网络的预测区间综合综述及新进展》对神经网络背景下的非线性模型预测区间进行了最近的研究。以下列表总结了可用于非线性机器学习模型预测不确定性的一些方法:
- Delta方法,来自非线性回归领域。
- 贝叶斯方法,来自贝叶斯建模和统计学。
- 均值-方差估计方法,使用估计统计量。
- 自举法,使用数据重采样和开发模型集成。
我们可以在下一节中通过一个实际示例来具体计算预测区间。
线性回归的预测区间
线性回归是一种描述输入线性组合以计算输出变量的模型。
例如,一个估计的线性回归模型可以写成:
|
1 |
yhat = b0 + b1 . x |
其中,yhat是预测值,b0和b1是根据训练数据估计的模型系数,x是输入变量。
我们不知道系数b0和b1的真实值。我们也不知道x或y的真实总体参数,如均值和标准差。所有这些元素都必须进行估计,这在模型用于进行预测时引入了不确定性。
我们可以做一些假设,例如x和y的分布以及模型产生的预测误差(称为残差)是高斯分布。
yhat周围的预测区间可以按如下方式计算:
|
1 |
yhat +/- z * sigma |
其中,yhat是预测值,z是高斯分布的标准差数(例如,95%区间为1.96),sigma是预测分布的标准差。
在实践中我们不知道。我们可以按如下方式计算预测标准差的无偏估计值(取自《用于估计模型输出预测区间的机器学习方法》):
|
1 |
stdev = sqrt(1 / (N - 2) * e(i)^2 for i to N) |
其中,stdev是预测分布标准差的无偏估计,n是做出的总预测数,e(i)是第i个预测与实际值之间的差异。
实例演示
让我们通过一个实际示例来具体说明线性回归预测区间。
首先,让我们定义一个简单的双变量数据集,其中输出变量(y)依赖于输入变量(x),并带有一些高斯噪声。
下面的示例定义了我们将用于此示例的数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 生成相关变量 from numpy import mean from numpy import std from numpy.random import randn from numpy.random import seed from matplotlib import pyplot # 设定随机数生成器种子 seed(1) # 准备数据 x = 20 * randn(1000) + 100 y = x + (10 * randn(1000) + 50) # 总结 print('x: mean=%.3f stdv=%.3f' % (mean(x), std(x))) print('y: mean=%.3f stdv=%.3f' % (mean(y), std(y))) # 绘图 pyplot.scatter(x, y) pyplot.show() |
运行示例首先打印两个变量的均值和标准差。
|
1 2 |
x: mean=100.776 stdv=19.620 y: mean=151.050 stdv=22.358 |
然后创建数据集的图表。
我们可以看到变量之间清晰的线性关系,散布的点突出了关系中的噪声或随机误差。
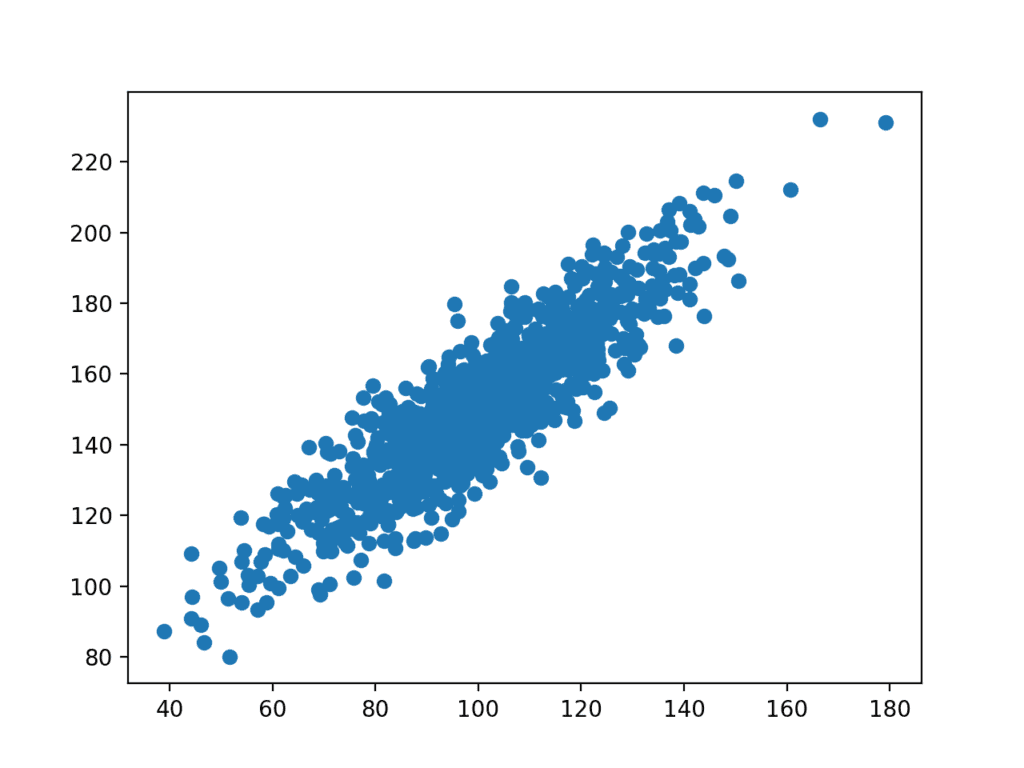
相关变量的散点图
接下来,我们可以开发一个简单的线性回归,给定输入变量x,它将预测y变量。我们可以使用linregress() SciPy函数来拟合模型并返回模型的b0和b1系数。
|
1 2 |
# 拟合线性回归模型 b1, b0, r_value, p_value, std_err = linregress(x, y) |
我们可以使用系数来计算每个输入变量的预测y值,称为yhat。结果点将形成一条代表学习关系线。
|
1 2 |
# 进行预测 yhat = b0 + b1 * x |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 简单线性回归模型 from numpy.random import randn from numpy.random import seed from scipy.stats import linregress from matplotlib import pyplot # 设定随机数生成器种子 seed(1) # 准备数据 x = 20 * randn(1000) + 100 y = x + (10 * randn(1000) + 50) # 拟合线性回归模型 b1, b0, r_value, p_value, std_err = linregress(x, y) print('b0=%.3f, b1=%.3f' % (b1, b0)) # 进行预测 yhat = b0 + b1 * x # 绘制数据和预测 pyplot.scatter(x, y) pyplot.plot(x, yhat, color='r') pyplot.show() |
运行示例拟合模型并打印系数。
|
1 |
b0=1.011, b1=49.117 |
然后使用数据集中的输入来预测。结果的输入和预测的y值作为一条线绘制在数据集的散点图上。
我们可以清楚地看到模型已经学习了数据集中的底层关系。
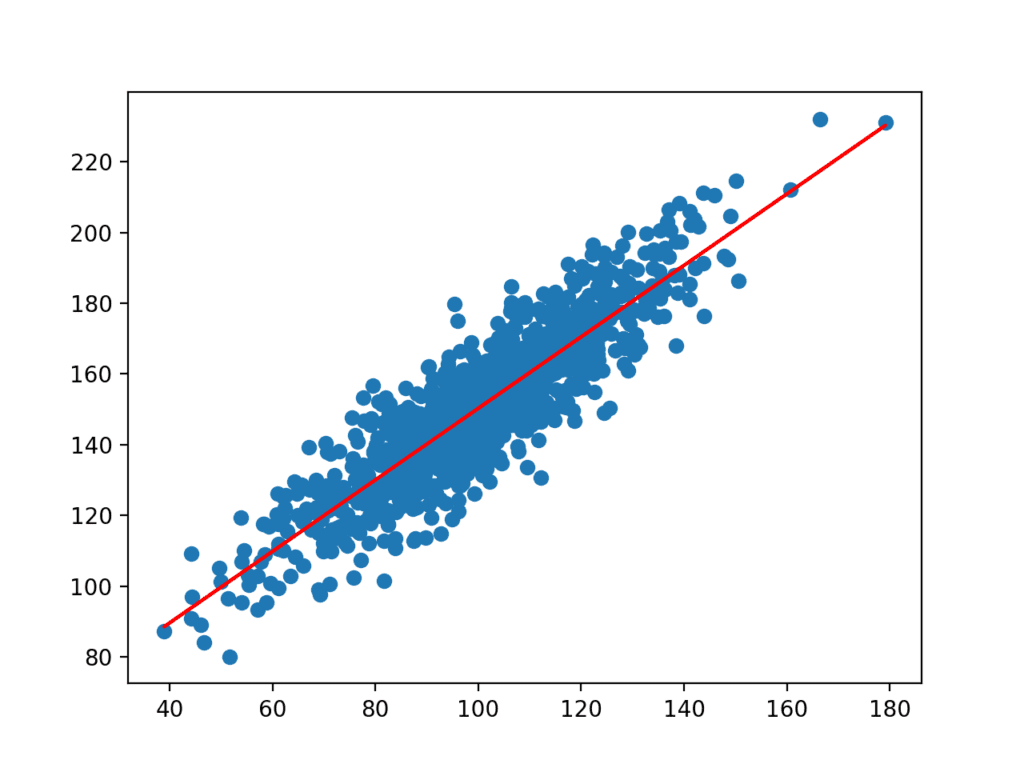
数据集散点图与简单线性回归模型线
我们现在准备使用我们的简单线性回归模型进行预测并添加预测区间。
我们将像以前一样拟合模型。这次我们将从数据集中抽取一个样本来演示预测区间。我们将使用输入进行预测,计算预测的预测区间,并将预测和区间与已知期望值进行比较。
首先,让我们定义输入、预测和期望值。
|
1 2 3 |
x_in = x[0] y_out = y[0] yhat_out = yhat[0] |
接下来,我们可以估计预测方向的标准差。
|
1 |
SE = sqrt(1 / (N - 2) * e(i)^2 for i to N) |
我们可以使用NumPy数组直接计算,如下所示:
|
1 2 3 |
# 估计yhat的标准差 sum_errs = arraysum((y - yhat)**2) stdev = sqrt(1/(len(y)-2) * sum_errs) |
接下来,我们可以计算我们选择的输入的预测区间:
|
1 |
interval = z . stdev |
我们将使用95%的显著性水平,即1.96个标准差。
一旦计算出区间,我们就可以向用户总结预测的界限。
|
1 2 3 |
# 计算预测区间 interval = 1.96 * stdev lower, upper = yhat_out - interval, yhat_out + interval |
我们可以将所有这些结合起来。完整的示例列于下方。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 带预测区间的线性回归预测 from numpy.random import randn from numpy.random import seed from numpy import power from numpy import sqrt from numpy import mean from numpy import std from numpy import sum as arraysum from scipy.stats import linregress from matplotlib import pyplot # 设定随机数生成器种子 seed(1) # 准备数据 x = 20 * randn(1000) + 100 y = x + (10 * randn(1000) + 50) # 拟合线性回归模型 b1, b0, r_value, p_value, std_err = linregress(x, y) # 进行预测 yhat = b0 + b1 * x # 定义新的输入、期望值和预测 x_in = x[0] y_out = y[0] yhat_out = yhat[0] # 估计yhat的标准差 sum_errs = arraysum((y - yhat)**2) stdev = sqrt(1/(len(y)-2) * sum_errs) # 计算预测区间 interval = 1.96 * stdev print('Prediction Interval: %.3f' % interval) lower, upper = yhat_out - interval, yhat_out +interval print('95%% likelihood that the true value is between %.3f and %.3f' % (lower, upper)) print('True value: %.3f' % y_out) # 绘制数据集和带区间的预测 pyplot.scatter(x, y) pyplot.plot(x, yhat, color='red') pyplot.errorbar(x_in, yhat_out, yerr=interval, color='black', fmt='o') pyplot.show() |
运行示例估计yhat标准差,然后计算预测区间。
计算完成后,将预测区间呈现给用户,用于给定的输入变量。由于我们是人为构建这个示例,我们知道真实结果,这也显示出来。我们可以看到,在这种情况下,95%的预测区间确实涵盖了真实的期望值。
|
1 2 3 |
预测区间:20.204 95%的几率真实值介于160.750和201.159之间 真实值:183.124 |
还创建了一个图,显示原始数据集为散点图,数据集的预测为红线,预测和预测区间分别为黑点和黑线。
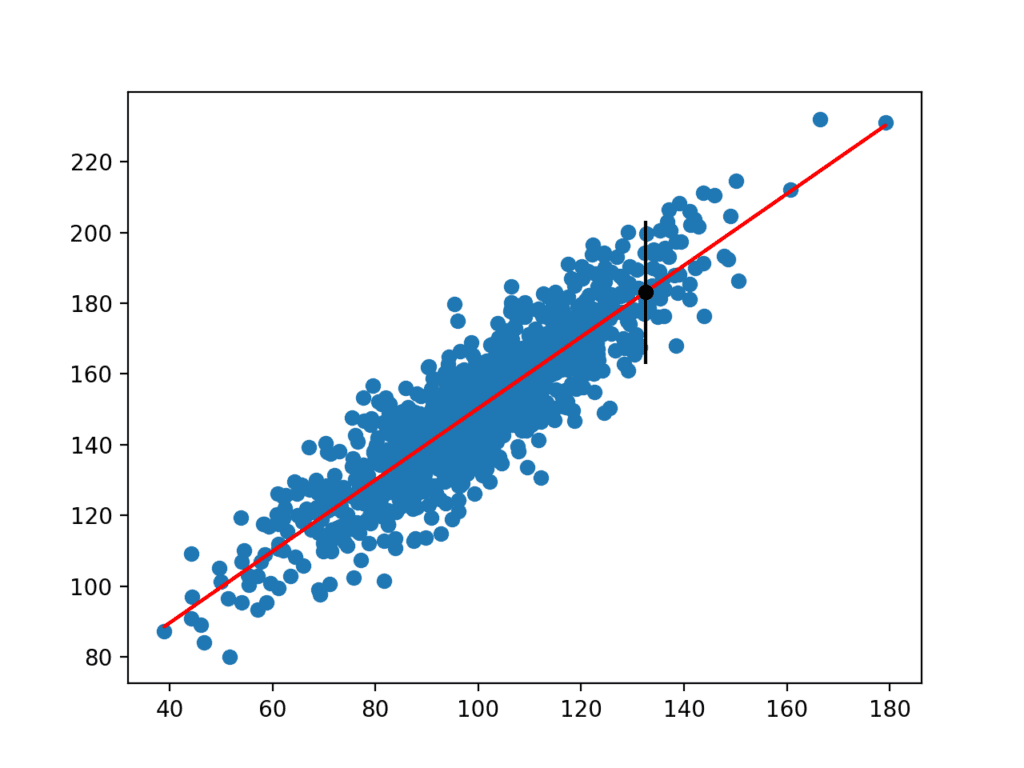
带有线性模型和预测区间的数据集散点图
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 总结容差、置信度和预测区间之间的区别。
- 为标准机器学习数据集开发线性回归模型,并计算小测试集的预测区间。
- 详细描述一种非线性预测区间方法的工作原理。
如果您探索了这些扩展中的任何一个,我很想知道。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
文章
书籍
- 理解新统计学:效应量、置信区间和元分析, 2017.
- 统计区间:从业者与研究者指南, 2017.
- 《统计学习导论:R语言应用》(An Introduction to Statistical Learning: with Applications in R), 2013.
- 新统计学导论:估算、开放科学及其他, 2016.
- 预测:原理与实践, 2013.
论文
- 神经网络模型的一些误差估计比较, 1995.
- 用于估计模型输出预测区间的机器学习方法, 2006.
- 基于神经网络的预测区间综合综述及新进展, 2010.
API
文章
总结
在本教程中,您了解了预测区间以及如何为简单的线性回归模型计算它。
具体来说,你学到了:
- 预测区间量化了单点预测的不确定性。
- 对于简单模型,预测区间可以进行分析估计,但对于非线性机器学习模型则更具挑战性。
- 如何计算简单线性回归模型的预测区间。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







嗨
关于如何在Keras中绘制时间序列的预测区间,有什么建议吗?
我不认为它们直接支持。
本文中描述的方法之一可能适用
http://alumnus.caltech.edu/~amir/pred-intv-2.pdf
受您建议扩展教程的启发,我可能会探索,我写了一些使用自举法计算线性和非线性回归模型的置信区间和预测区间的示例:https://vladgladkikh.wordpress.com/2018/06/08/confidence-and-prediction-intervals-using-the-bootstrap/
干得好,非常棒!
尊敬的Jason博士,
我已经在您的博客上的其他地方提到了pyplot.plot(x,y)和pyplot.scatter(x,y)之间的区别。
这是另一个例子,在执行散点图和上面描述的x和y图时要小心。
教训是,在使用pyplot.plot(x,y)和pyplot.scatter(x,y)时要小心,尤其是在数据不是时间顺序时。我已经在我的博客上其他地方描述过这个问题。
此致
贝尔菲尔德的安东尼
确实如此。
感谢您的帖子。
我运行了代码并尝试为每个数据点绘制区间。然后我意识到每个数据点的标准差是相同的,因此每个数据点的区间也是相同的。我有几点想请您详细阐述:
1)我们自然期望在训练示例密度较高的区域获得更高的置信度,从而获得更紧密的预测区间,那么如何将其考虑在内?
2)可能后者与推导PI的方法差异有关,即频率论方法与贝叶斯方法?
3)感觉用于计算区间的标准差是指标准误差。是这样吗?
我相信计算是正确的,您可以根据维基百科上的描述独立确认这一点
https://en.wikipedia.org/wiki/Prediction_interval
以及“预测原理”中
https://otexts.org/fpp2/prediction-intervals.html
不过,计算方法存在差异,您可能希望探索一下。
确实,标准差应该捕捉密度的描述,但这很粗糙。在实践中,我个人会采用非参数的基于百分位数的方法,因为我很少在具有挑战性的问题上使用线性回归。
嗨,Jason,
感谢这篇精彩的文章。它阐明了一个非常重要的概念。
这种方法可以应用于所有类型的预测模型,而不仅仅是线性回归吗?换句话说,我们可以插入任何黑盒预测模型,这种估计预测区间的方法仍然有效吗?
然而,我的直觉是输出yhat的置信区间应该依赖于输入x的值。由于训练数据集中x的密度不同,至少如果黑盒模型是KNN,当输入x处于高密度区域时,它应该对其估计更有信心。
我正在考虑,与其使用整个训练数据集e(i)来计算标准差,我们是否应该只使用e(j)的子集,其中j是输入x的邻域。换句话说,我们从测试数据集中提取输入x的邻域,并使用它们的局部标准误差来估计置信界限。这是否更有意义?
也许,如果输出变量的分布是高斯分布。
亲爱的Julian,
感谢您提供有关比较回归模型的有用链接。请问,我想做一日提前预测,您有这方面的教程吗?
非常感谢您的努力。
KJ
这篇文章可能会有帮助
https://machinelearning.org.cn/multi-step-time-series-forecasting/
嗨!
感谢这篇很棒的教程。
您知道是否存在您提到的用于构建非线性神经网络模型PI的四种方法的开源实现吗?
(Delta方法,来自非线性回归领域。
贝叶斯方法,来自贝叶斯建模和统计学。
均值-方差估计方法,使用估计统计量。
自举法,使用数据重采样和开发模型集成。)
此致
我的博客上有很多您可以改编的自举法示例。
你好,
感谢您的教程。一开始,您指出预测区间是预测上限 - 预测下限。然而,最后您得到了一个95%的预测区间为20,然后将其与预测值 ± 20 相关联,总区间为40。计算出的预测区间是给出双向范围还是只给单向范围?
通常,区间以点预测为中心(即双向)。
那为什么在您的示例中不是这样呢?您只收到单向区间,不得不乘以二才能得到总预测区间。
在示例中,区间是对称的。
嗨,Jason,
非常感谢这篇精彩的帖子!
您对如何计算决策树模型,尤其是LightGBM的预测区间有什么评论吗?任何想法都将非常有帮助。
一个不重要的打字错误:“高斯临界值1.69”。
谢谢
谢谢,已修正。
一个快速而粗糙的方法是使用多个并行模型所做预测的标准差。
嗨,Jason,
感谢这篇超棒的教程!
一个问题——我注意到您将95%置信区间的计算基于训练集预测的平方误差和(即您训练模型所用的相同y,以及该训练产生的yhat)。
为了生成与样本外数据预测(即95%的真实y将落在我们预测的样本外数据95%置信带内)良好吻合的置信区间,我期望我们将区间边界基于从训练中排除的某个验证数据集的y/yhat的ssr。您同意这种方法吗?
在这里,我们计算的是预测区间(用于点预测)。
如果您对置信区间(针对模型)感兴趣,我推荐这篇帖子
https://machinelearning.org.cn/confidence-intervals-for-machine-learning/
论文链接已失效。
谢谢,已修正。
嗨,Jason,
我可能已经找到了一种方法,可以使用Keras训练的LSTM进行时间序列预测的百分位数估计。
我刚刚发现了使用分位数损失函数训练模型的可能性。这样,通过训练3个模型——是的,这是一个缺点——我可以让每个模型预测一个四分位数,从而获得我的预测范围估计。
这是我读到的帖子:https://towardsdatascience.com/deep-quantile-regression-c85481548b5a
您对此有何看法?
我没读过那篇帖子,或许可以直接联系作者?
如果噪声不是高斯分布怎么办。我可以使用qqnorm并发现我的残差不是高斯分布。在这种情况下,predict()函数提供的置信区间和预测区间是否仍然相关?
如果它们接近高斯分布,线性方法可能仍然有用。
如果不是,可能需要更精细或特定于算法的技术。
嗨,Jason,一如既往的精彩阅读。感谢您持续的努力并免费向机器学习社区分享您的知识。
我想问您是否知道类似的方法可以为分类预测提供置信水平。是否存在这样的概念,如果存在,任何文献都将不胜感激。
先谢谢您了。
是的,就在这里。
https://machinelearning.org.cn/confidence-intervals-for-machine-learning/
或者,您是指预测类别的概率?
这可以通过scikit-learn中的model.predict_proba()实现。
我可能表达得不正确,因为我不知道是否存在这样的概念!
有没有办法在分类的预测输出旁边提供另一个指标,来描述模型产生该输出的百分比(或置信度)?我指的是一个不同于准确率、精确率或召回率的指标。
作为一个概念,它在下面的论文中讨论过,我在理解上有点困难,但您会明白一些:
https://arxiv.org/pdf/1706.04599.pdf
https://www.cs.cornell.edu/~alexn/papers/calibration.icml05.crc.rev3.pdf
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1262116&tag=1
此外,如果我可以添加一个非常粗略的例子,假设我们有一个狗品种分类器(没有“不是狗”的类别,请姑且这样认为)。当有人提供一张马的图片作为输入时,分类器会产生一个狗品种,很可能与马的图片相似,但实际上不真实。我试图谈论的指标是一个会为上述例子提供非常低的置信度,以表示上述输入与神经网络所知道的分类方式相去甚远。从而告诉模型的使用者不要依赖它对该输入进行分类。
我很抱歉解释得一团糟,但我的脑子里也一团糟……
是的,我相信您想使用预测概率,即输入属于每个类别的概率。
你好,
我认为对于95%的置信度,高斯值应该是1.64(“我们将使用95%的显著性水平,这是高斯临界值1.96”),如果我错了,请纠正我。
谢谢
是的,这不是临界值,而是标准差的数量。已修正。
这可能有帮助
https://en.wikipedia.org/wiki/1.96
嗨,Jason!
您将如何评估您的预测区间是否正确?
采用什么方法来做到这一点。
谢谢
很好的问题。
估计测试数据集的预测区间。然后确认真实测试值以所需分布落入区间内。
测量预测区间和其本身不都是一个有偏指标吗?我们通过比较真实值和预测值来确定标准差。我们从真实值中学习标准差,对吗?所以这变得令人困惑。
也许可以尝试一下。
嗨,Jason,
干得漂亮!感谢您的努力!
我对上面列出的所有扩展都感兴趣。我想知道您是否会添加这些。
谢谢!
谢谢。
是的,我希望将来能处理它们。
谢谢 Jason 🙂
如果有用的话……第30行中的拼写错误已经修复,但我认为第32行中的拼写错误仍然存在:真实期望值应该是“y_out”,而不是“yhat_out”(如当前代码所示)。
干得漂亮!感谢您的贡献!
哦,伙计,那真傻。
谢谢!已修复。
你好 Jason,
您能否建议一下您列出的非线性模型(Delta方法、贝叶斯方法、均值-方差和自举法)是否可以用于时间序列问题?
据我理解,时间序列的顺序至关重要,因此如果我们进行洗牌,我们将扭曲结果。
谢谢,
罗斯
不直接。时间序列模型使用定制方法——通常内置在库中。
机器学习预测结果中接受的最小和最大预测区间和置信区间(在95%和97.5%的情况下)是多少?
这取决于您的项目可以容忍的程度以及其他方法可以实现的目标。
你好 Jason,
感谢您的宝贵和有用的帖子!它们真的很有帮助和启发。我学到了很多。非常感谢您在博客中分享了这么多有趣的东西。
我不知道我是否错了,但我认为“实际示例”部分的代码中有一个小小的拼写错误:在第30行和第32行中,变量“y_out”和“yhat_out”可能应该互换,因为“lower”和“upper”应该使用“yhat_out”计算,而真实值是“y_out”。请纠正我,如果我错了。
再次感谢,祝贺您的有趣博客!🙂
谢谢,已修复!
你好,
确定深度学习模型(例如您在其他帖子中教授的基于LSTM的模型)的预测区间的良好方法是什么。
此外,您以简单的方式为许多人打开了机器学习的世界。我读了您的两本书,一本关于统计学,另一本关于从零开始的机器学习,它们都非常直接且易于理解!谢谢您!!我的学习时间从未如此有价值!
谢谢!
一个好的起点是拟合多个最终模型(final models),并使用它们来创建一组预测,从中可以描述一个区间。
另外,也许可以参阅“进一步阅读”部分中有关此主题的参考文献。
您好 Jason,我花了很多时间阅读您的帖子。统计学和概率学一直是一个即使在高级水平上多次教学,我最终总是重新学习的科目,因为我似乎从未真正内化其细微之处。它的语言非常特殊,空间的声明/定义,仅仅改变一个术语就可以改变陈述的整个含义。这使得它变得困难。
话虽如此,如果您能为我澄清一个过程,我将不胜感激。在多年阅读了置信区间和标准误差的多种解释之后,我想我开始更深入地理解它了。然而,我仍然不清楚的是量化模型“不确定性”的正确技术。您在这里写到了预测区间,即这个区间的构建将包含真实值X%的时间。简单来说,就是95%的可能性。它类似于置信区间,只是置信区间只能应用于特定分布的样本统计量(如均值、标准差,在N足够大以应用中心极限定理的情况下,表明其样本统计量在近似总体参数方面具有明确的关系)。
话虽如此(请原谅我啰嗦,这有助于我澄清统计细微之处)。话虽如此,我想进行一个简单的计算。我想计算模型预测值“波动性”(此处使用口语化的术语)的日常变化。我并不特别关心它是否“精确”或“准确”,即它与实际真实总体值的接近程度。我只是关心衡量这个估计值的波动性。例如,模型是否会产生一天上涨+5,第二天下降-5的预测。我就是这样定义“不确定性”的。
我知道获取这种方差的一种方法是计算预测值的标准差,它描述了预测值与预测均值之间的关系。我们甚至可以获取其累积密度函数并评估各种百分位数。
但是假设我们的预测空间不是正态分布。它实际上是(偏斜的),或者实际上,它显示出一种特定的函数形式,可能表明我们的预测存在潜在偏差。在这种情况下,报告这种“不确定性”的建议方法是什么?在这种情况下,“不确定性”甚至有意义吗?考虑到可能存在偏差/不同的数据问题。这是一个“模型稳定性”问题吗?有没有办法衡量给定预测值相对于其自身的方差,而不是相对于“真实”总体参数?
我正在考虑的一种方法是获取该天预测值在所有训练样本中的方差,并计算该值的标准差。
实际上,通过写下这些,我已经把问题提炼成两个问题:
1. 如何衡量模型日常的“波动性”?如果您的训练集-开发集与测试集(您正在评估的)的基础数据分布不同,是否有可能衡量模型日常的波动性?
2. 如何衡量其内部的波动性(“不确定性”)?当天所有潜在可能预测的样本空间。这本质上是一个模型“稳定性”问题吗?根据我的想法,您可以构建当天的30个预测,并像您上面概述的那样计算预测区间。(不是置信区间,对吗?因为它不是样本统计量)而且我假设这仍然属于“模型稳定性”的范畴?我也假设这就是为什么建议执行一些集成来减少固有的内部模型稳定性。
如果我解决了自己的问题,请告诉我!但是您能写下的任何东西(和/或链接资源)来帮助我澄清这些过程并更深入地内化它们都将有所帮助。
那是一条巨大的评论!
模型的不确定性取决于模型。一些模型本身会预测概率,例如逻辑回归,而另一些则不会,例如决策树。
波动性——对于时间序列——那不是我的专业领域,抱歉。这可能会有所帮助
https://machinelearning.org.cn/develop-arch-and-garch-models-for-time-series-forecasting-in-python/
对于平稳数据和随机模型,对相同数据拟合的多个模型的方差或标准差是衡量模型稳定性的有用指标
https://machinelearning.org.cn/how-to-reduce-model-variance/
不确定我是否回答了您的问题,也许您可以用一两句话重新表达?(抱歉,我每天有数百条评论要阅读/回复)
嗨,Jason,
好文章!
我正在使用一维CNN(类似于WaveNet的架构)来预测金融时间序列数据。我的直觉告诉我,今天一年后的预测应该比t+1的预测“准确度”低得多。
我研究了几种方法,例如高斯过程(gpflow库)甚至使用“dropout”模型来生成置信区间或预测区间。但是,我找不到使用一维CNN作为模型的良好实现。您会推荐查看哪些资源?
同意。
拟合多个(例如30个)最终模型,并使用点预测的分布作为预测区间是一种快速有效的方法。
非常感谢您的快速回复。明白了,我会尝试一下。
根据Gal和Ghahramani的说法,“优化任何带有Dropout的神经网络等同于一种近似的贝叶斯推断形式。”事实上,他们建议在测试时在每个权重层使用MC Dropout。因此,我们不是得到一个点估计,而是得到一个预测的均值和方差。Andrew Rowan的这个PyData演讲清楚地描述了这一过程 https://www.youtube.com/watch?v=I09QVNrUS3Q。您怎么看?
我不太了解它。也许可以尝试一下,看看它是否符合您的项目需求。
“在像线性回归这样的简单情况下,我们可以直接估计置信区间。”
您是指“预测区间”吗?
此外,“基于神经网络的预测区间综合综述及新进展”的链接已失效
谢谢,已修正。
是的。已修复,谢谢!
运行示例估计yhat标准差,然后计算置信区间。
=> 不是“计算预测区间”吗?
谢谢,已修复!
你好!感谢您的帖子。只有一个符号上的备注。我认为在您的代码中写“区间=数字”有点误导,甚至从数学上来说这样说是不正确的。实际上,z*stdev有它自己的名字,它被称为误差幅度(moe)。
谢谢 Elena。
嗨!
在分类问题中,有没有办法获得概率的预测区间?
嗯,我认为这还有更多。即兴来说,我建议查阅文献。
嗨,Jason,
您好!
我正在研究 KDE 模型,之后我想获得预测区间。我阅读了我领域的一些文献,并分享了论文“https://www.sciencedirect.com/science/article/pii/S0925231220315617”第555页,公式13和14的参考文献。
我无法判断他在这篇论文中应用了哪种方法来计算上限和下限,您能看看吗?
谢谢
你好 Ehtisham…你对别人的工作有疑问吗?
研究论文?
博文?
图表?
代码?
我很乐意帮忙,但是阅读一篇论文(或别人的材料)并达到可以向你解释的程度需要大量的时间和精力。我实在没有能力满足我收到的每一个请求。
我最好的建议是直接联系作者并提出你的问题。
我相信一位诚实的学者会希望他们的工作被阅读和理解。
如果你准备充分(例如,做好功课),如果你有礼貌(例如,谦逊、客气,不强求),并且如果你的问题清晰(例如,具体),我期望得到有益的回复。
你好!感谢您的帖子!
我正在做一个送货时间项目。我正在使用 LGBM 和 XGBoost 的预测区间。用后者我得到了更好的结果,但区间范围更大。有什么建议可以让我获得更小的预测区间但保持性能不变吗?
非常感谢!
你好 Ignacio…你可能想研究优化技术
https://machinelearning.org.cn/optimization-for-machine-learning-crash-course/
你好 James
请给我介绍一个学习预测模型限制边界计算的参考文献。我的意思是,如果我为一个不能代表更大群体的数据集训练一个预测模型,我们可能无法将其用于此范围之外的测试数据。例如,如果我们为 x 在 1 到 10 之间训练一个线性回归模型来预测 y,我们不能将其用于 x=100,如果我们使用该模型进行预测,它在 x=100 时会出现很大的误差。
谢谢你
抱歉,你好 Jason