文本摘要的任务是创建文章的简短、准确、流畅的摘要。
一个流行且免费的数据集,可用于深度学习方法的文本摘要实验,是 CNN 新闻故事数据集。
在本教程中,您将学习如何准备 CNN 新闻数据集以进行文本摘要。
完成本教程后,您将了解:
- 关于 CNN 新闻数据集以及如何将故事数据下载到您的工作站。
- 如何加载数据集并将每篇文章分成故事文本和亮点。
- 如何清理数据集以进行建模并保存清理后的数据以备后用。
通过我的新书《自然语言处理深度学习》**启动您的项目**,其中包括**分步教程**和所有示例的**Python 源代码**文件。
让我们开始吧。

如何为文本摘要准备新闻文章
照片由 DieselDemon 拍摄,保留部分权利。
教程概述
本教程分为5个部分,它们是:
- CNN 新闻故事数据集
- 检查数据集
- 加载数据
- 数据清洗
- 保存干净的数据
需要深度学习处理文本数据的帮助吗?
立即参加我的免费7天电子邮件速成课程(附代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
CNN 新闻故事数据集
DeepMind 问答数据集是 CNN 和《每日邮报》的大量新闻文章合集,并附有相关问题。
该数据集是为深度学习问答任务而开发的,并于 2015 年在论文《教会机器阅读和理解》中提出。
此数据集已用于文本摘要,其中新闻文章中的句子被摘要。值得注意的例子是以下论文:
- 使用序列到序列 RNN 及其他方法的抽象文本摘要, 2016.
- 直奔主题:使用指针生成器网络的摘要, 2017.
纽约大学的学者 Kyunghyun Cho 提供了该数据集供下载。
在本教程中,我们将使用 CNN 数据集,特别是此处可用的新闻故事 ASCII 文本下载
- cnn_stories.tgz (151 兆字节)
此数据集包含超过 93,000 篇新闻文章,每篇文章存储在一个单独的“* .story *”文件中。
将此数据集下载到您的工作站并解压缩。下载后,您可以在命令行上按如下方式解压缩存档
|
1 |
tar xvf cnn_stories.tgz |
这将创建一个充满 `.story` 文件的 `cnn/stories/` 目录。
例如,我们可以在命令行上按如下方式计算故事文件的数量
|
1 |
ls -ltr | wc -l |
这表明我们总共有 92,580 个故事。
|
1 |
92580 |
检查数据集
使用文本编辑器,查看一些故事并记录一些准备这些数据的想法。
例如,下面是一个故事的示例,为简洁起见,正文已截断。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
(CNN)——如果你乘坐飞机,并且准时到达很重要,那就尝试预订夏威夷航空公司。根据周一发布的一项研究,2012年,搭乘该航空公司的乘客十次中有九次以上都准时到达目的地,没有延误。 事实上,夏威夷航空从2011年开始表现更佳,当时准点率达92.8%。去年,它提高到93.4%。 [...] @highlight 夏威夷航空公司再次荣登准点率第一 @highlight 航空质量排名报告调查了美国最大的 14 家航空公司 @highlight ExpressJet 和美国航空公司的准点率最差 @highlight 维珍美国航空的行李处理最佳;西南航空的投诉率最低 |
我注意到数据集的总体结构是先有故事文本,然后是若干“**亮点**”点。
查看 CNN 网站上的文章,我发现这种模式仍然很常见。
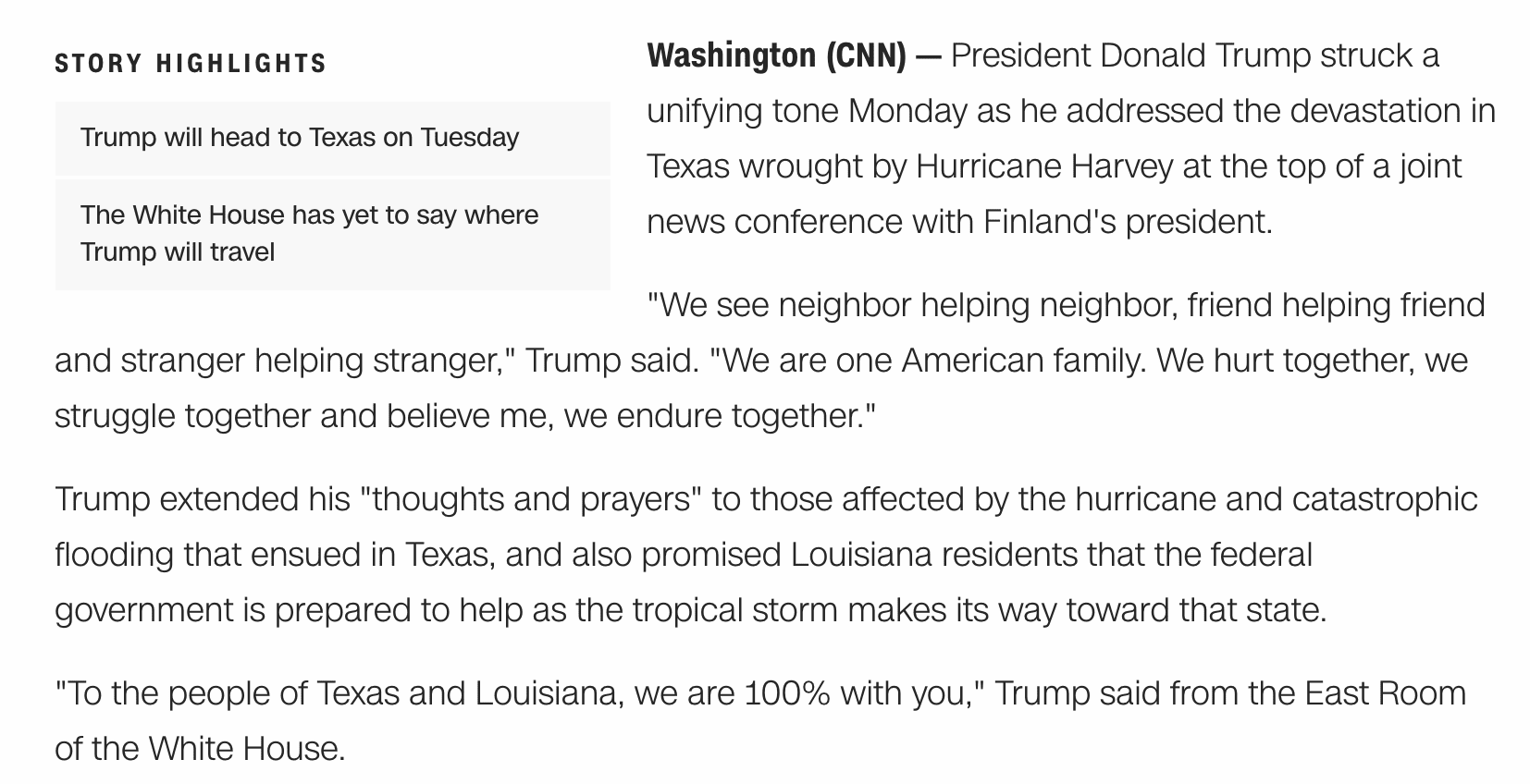
附有亮点内容的 CNN 新闻文章示例,来自 cnn.com
ASCII 文本不包含文章标题,但我们可以将这些人工编写的“*亮点*”作为每篇新闻文章的多个参考摘要。
我还可以看到许多文章以来源信息开头,大概是制作故事的 CNN 办公室;例如
|
1 2 3 |
(CNN) -- 加沙城 (CNN) -- 洛杉矶 (CNN) -- |
这些可以完全删除。
数据清洗是一个具有挑战性的问题,必须根据系统的具体应用进行调整。
如果我们普遍对开发新闻文章摘要系统感兴趣,那么我们可以清洗文本以通过减少词汇量来简化学习问题。
此数据的一些数据清理思路包括。
- 将大小写规范化为小写(例如“An Italian”)。
- 删除标点符号(例如“on-time”)。
我们还可以进一步减少词汇量以加快测试模型,例如
- 删除数字(例如“93.4%”)。
- 删除低频词,例如姓名(例如“Tom Watkins”)。
- 将故事截断为前 5 或 10 个句子。
加载数据
第一步是加载数据。
我们可以从编写一个函数开始,根据文件名加载单个文档。数据中包含一些 Unicode 字符,因此我们将强制编码为 UTF-8 来加载数据集。
下面名为 `load_doc()` 的函数将根据文件名将单个文档加载为文本。
|
1 2 3 4 5 6 7 8 9 |
# 加载文档到内存 def load_doc(filename): # 以只读方式打开文件 文件 = 打开(文件名, 编码='utf-8') # 读取所有文本 文本 = 文件.读取() # 关闭文件 file.close() 返回 文本 |
接下来,我们需要遍历故事目录中的每个文件名并加载它们。
我们可以使用 `listdir()` 函数加载目录中的所有文件名,然后依次加载每个文件。下面名为 `load_stories()` 的函数实现了此行为,并提供了准备已加载文档的起点。
|
1 2 3 4 5 6 |
# 加载目录中的所有故事 def load_stories(directory): for name in listdir(directory): filename = directory + '/' + name # 加载文档 doc = load_doc(filename) |
每份文档都可以分为新闻故事文本和亮点或摘要文本。
这两个点的分割是“@highlight”标记的首次出现。一旦分割,我们就可以将亮点整理成一个列表。
下面名为 `split_story()` 的函数实现了此行为,并将给定的已加载文档文本拆分为故事和亮点列表。
|
1 2 3 4 5 6 7 8 9 |
# 将文档拆分为新闻故事和亮点 def split_story(doc): # 查找第一个亮点 index = doc.find('@highlight') # 分割成故事和亮点 story, highlights = doc[:index], doc[index:].split('@highlight') # 去除每个亮点周围的额外空白 highlights = [h.strip() for h in highlights if len(h) > 0] return story, highlights |
现在我们可以更新 `load_stories()` 函数,使其为每个加载的文档调用 `split_story()` 函数,然后将结果存储在一个列表中。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 加载目录中的所有故事 def load_stories(directory): 所有故事 = 列表() for name in listdir(directory): filename = directory + '/' + name # 加载文档 doc = load_doc(filename) # 分割成故事和亮点 故事, 亮点 = split_story(doc) # 存储 all_stories.append({'story':story, 'highlights':highlights}) return all_stories |
将所有这些整合在一起,下面列出了加载整个数据集的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
from os import listdir # 加载文档到内存 def load_doc(filename): # 以只读方式打开文件 文件 = 打开(文件名, 编码='utf-8') # 读取所有文本 文本 = 文件.读取() # 关闭文件 file.close() return text # 将文档拆分为新闻故事和亮点 def split_story(doc): # 查找第一个亮点 index = doc.find('@highlight') # 分割成故事和亮点 story, highlights = doc[:index], doc[index:].split('@highlight') # 去除每个亮点周围的额外空白 highlights = [h.strip() for h in highlights if len(h) > 0] 返回 故事, 亮点 # 加载目录中的所有故事 def load_stories(directory): 故事 = 列表() for name in listdir(directory): filename = directory + '/' + name # 加载文档 doc = load_doc(filename) # 分割成故事和亮点 故事, 亮点 = split_story(doc) # 存储 故事.追加({'故事':故事, '亮点':亮点}) 返回 故事 # 加载故事 目录 = 'cnn/stories/' 故事 = load_stories(目录) 打印('加载的故事 %d' % len(故事)) |
运行示例会打印加载的故事数量。
|
1 |
已加载故事 92,579 |
我们现在可以访问已加载的故事和亮点数据,例如
|
1 2 |
print(stories[4]['story']) print(stories[4]['highlights']) |
数据清洗
现在我们可以加载故事数据,我们可以通过清洗文本来对其进行预处理。
我们可以逐行处理故事,并对每行突出显示使用相同的清理操作。
对于给定的一行,我们将执行以下操作
删除 CNN 办公室信息。
|
1 2 3 4 |
# 如果存在,剥离 CNN 来源办公室信息 index = line.find('(CNN) -- ') if index > -1: line = line[index+len('(CNN)'):] |
使用空白标记分割行
|
1 2 |
# 根据空白符进行分词 行 = 行.split() |
将大小写规范化为小写。
|
1 2 |
# 转换为小写 行 = [词.小写() for 词 in 行] |
从每个标记中删除所有标点符号(Python 3 特定)。
|
1 2 3 4 |
# 准备一个翻译表来删除标点符号 表 = str.maketrans('', '', string.punctuation) # 从每个令牌中去除标点符号 行 = [w.translate(table) for w in 行] |
删除任何包含非字母字符的单词。
|
1 2 |
# 删除包含数字的标记 行 = [词 for 词 in 行 if 词.isalpha()] |
综合所有这些,下面是一个名为 `clean_lines()` 的新函数,它接收一个文本行列表并返回一个清理后的文本行列表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 清理行列表 def clean_lines(lines): 清理过的 = 列表() # 准备一个翻译表来删除标点符号 table = str.maketrans('', '', string.punctuation) for line in lines: # 如果存在,剥离 CNN 来源办公室信息 index = line.find('(CNN) -- ') if index > -1: line = line[index+len('(CNN)'):] # 根据空白符进行分词 line = line.split() # 转换为小写 line = [word.lower() for word in line] # 从每个标记中删除标点符号 line = [w.translate(table) for w in line] # 删除包含数字的标记 line = [word for word in line if word.isalpha()] # 存储为字符串 cleaned.append(' '.join(line)) # 删除空字符串 cleaned = [c for c in cleaned if len(c) > 0] 返回 清理过的 |
我们可以对故事调用此函数,首先将其转换为文本行。该函数可以直接在亮点列表上调用。
|
1 2 |
示例['故事'] = clean_lines(示例['故事'].split('\n')) 示例['亮点'] = clean_lines(示例['亮点']) |
下面列出了加载和清理数据集的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
from os import listdir import string # 加载文档到内存 def load_doc(filename): # 以只读方式打开文件 文件 = 打开(文件名, 编码='utf-8') # 读取所有文本 文本 = 文件.读取() # 关闭文件 file.close() return text # 将文档拆分为新闻故事和亮点 def split_story(doc): # 查找第一个亮点 index = doc.find('@highlight') # 分割成故事和亮点 story, highlights = doc[:index], doc[index:].split('@highlight') # 去除每个亮点周围的额外空白 highlights = [h.strip() for h in highlights if len(h) > 0] 返回 故事, 亮点 # 加载目录中的所有故事 def load_stories(directory): 故事 = 列表() for name in listdir(directory): filename = directory + '/' + name # 加载文档 doc = load_doc(filename) # 分割成故事和亮点 故事, 亮点 = split_story(doc) # 存储 故事.追加({'故事':故事, '亮点':亮点}) 返回 故事 # 清理行列表 def clean_lines(lines): 清理过的 = 列表() # 准备一个翻译表来删除标点符号 table = str.maketrans('', '', string.punctuation) for line in lines: # 如果存在,剥离 CNN 来源办公室信息 index = line.find('(CNN) -- ') if index > -1: line = line[index+len('(CNN)'):] # 根据空白符进行分词 line = line.split() # 转换为小写 line = [word.lower() for word in line] # 从每个标记中删除标点符号 line = [w.translate(table) for w in line] # 删除包含数字的标记 line = [word for word in line if word.isalpha()] # 存储为字符串 cleaned.append(' '.join(line)) # 删除空字符串 cleaned = [c for c in cleaned if len(c) > 0] 返回 清理过的 # 加载故事 目录 = 'cnn/stories/' 故事 = load_stories(目录) 打印('加载的故事 %d' % len(故事)) # 清理故事 for example in stories: 示例['故事'] = clean_lines(示例['故事'].split('\n')) 示例['亮点'] = clean_lines(示例['亮点']) |
请注意,故事现在以清理后的行列表的形式存储,通常以句子分隔。
保存干净的数据
最后,现在数据已经清理完毕,我们可以将其保存到文件中。
保存清理后的数据的简单方法是将故事和亮点的列表 Pickle 化。
例如:
|
1 2 3 |
# 保存到文件 from pickle import dump dump(stories, open('cnn_dataset.pkl', 'wb')) |
这将创建一个名为 `cnn_dataset.pkl` 的新文件,其中包含所有清理后的数据。该文件的大小约为 374 兆字节。
然后我们可以在以后加载它并将其与文本摘要模型一起使用,如下所示
|
1 2 3 |
# 从文件加载 stories = load(open('cnn_dataset.pkl', 'rb')) 打印('加载的故事 %d' % len(故事)) |
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
- DeepMind 问答数据集
- 教会机器阅读和理解, 2015.
- 使用序列到序列 RNN 及其他方法的抽象文本摘要, 2016.
- 直奔主题:使用指针生成器网络的摘要, 2017.
总结
在本教程中,您学习了如何准备 CNN 新闻数据集以进行文本摘要。
具体来说,你学到了:
- 关于 CNN 新闻数据集以及如何将故事数据下载到您的工作站。
- 如何加载数据集并将每篇文章分成故事文本和亮点。
- 如何清理数据集以进行建模并保存清理后的数据以备后用。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发文本数据的深度学习模型!

在几分钟内开发您自己的文本模型
...只需几行python代码
在我的新电子书中探索如何实现
用于自然语言处理的深度学习
它提供关于以下主题的自学教程:
词袋模型、词嵌入、语言模型、标题生成、文本翻译等等...
最终将深度学习应用于您的自然语言处理项目
跳过学术理论。只看结果。

")




在 Windows 系统上执行“加载数据”代码片段时出现以下错误:“‘utf-8’编解码器无法解码位置 12 的字节 0xc0:无效的起始字节”。
有趣,也许尝试更改编码,尝试“ascii”?
或者尝试将最终文件加载为二进制,然后将文本转换为 ascii?
你可以尝试这样做——
嗨 Jason,您有关于文本摘要的教程吗?
目前还没有,但我有一些关于模型想法
https://machinelearning.org.cn/encoder-decoder-models-text-summarization-keras/
更多内容在此
https://machinelearning.org.cn/encoder-decoder-deep-learning-models-text-summarization/
您好,感谢您提供本教程,请问到现在为止是否有关于构建文本摘要器的教程发布?
对于“数据清理”部分,当您在文本中查找源(CNN)时,您使用了两个不同的字符串(查找“(CNN) — ”并过滤掉“(CNN)”)。
它们都应该只是“(CNN)”,因为那是加载故事后显示的内容。否则 CNN 会与故事的第一个单词混在一起。
是的,这可能是一个改进,尝试一下看看。当然,还有很大的改进空间!
你好,杰森,
感谢您的帖子。但我有一些问题
1. 您认为这种文本摘要技术也适用于其他欧洲语言吗?
2. 我们的词汇存储是否只包含出现在我们数据集中的词?如果我们包含从未出现在我们数据集中的词怎么办?在进行抽象文本摘要时,即使从未训练过这些词,它们也能被识别出来吗?谢谢
我看不出为什么不。
只对您预计在数据中遇到的单词进行建模是有意义的。
你好,Jason Brownlee,
我们能否将清理后的数据作为编码器块的输入,在不进行词级分词的情况下用于 seq2seq 模型?
当然,您可以根据自己的意愿设计模型。
您好,非常感谢您的博客。它真的帮助我理解了许多概念。我只需要再一点帮助,请问您能解释一下论文“直奔主题:使用指针生成器网络的摘要,2017”中文本摘要的完整实现吗?如果您已经做过,请提供给我链接。
谢谢你。
也许直接联系作者并询问他们的论文?
好的,谢谢!
你好,先生,
我一直在尝试使用抽象技术创建文本摘要器。而且,我真的是这个领域的新手。我学习了上面的文章,并且能够以 pickle 格式清理数据。我想知道接下来该怎么做。
谢谢!
是的,我有一些建议
https://machinelearning.org.cn/?s=text+summarization&post_type=post&submit=Search
嘿,你有没有为这个数据集构建 Keras 模型?
我在这里有一些建议
https://machinelearning.org.cn/encoder-decoder-models-text-summarization-keras/
谢谢你
我正在进行抽取式摘要。我找不到 CNN Daily Mail 数据集的黄金(人工制作)抽取式摘要。你能告诉我哪里可以找到吗?
不,对不起,也许可以尝试谷歌搜索?
我也面临同样的问题,你找到 cnn/dailymai 文章的参考摘要了吗?
爱你们
谢谢,很高兴本教程有所帮助!
@JustGlowing 几周前正在使用 NLTK 文本摘要器
几周前
嗨,非常有用的信息,我刚刚在这里找到了这些细节
但我有一个问题
阅读并分割数据后,我发现句子数量远低于预期
我的意思是,这里每篇文章的平均句子数是 22 句
对于摘要,我必须在它们之间进行选择
是我做错了什么还是正常?
摘要与文章是分开的。
也许我不理解你的问题?
我的意思是文章的平均长度是 22 个句子,这正常吗?
不知道,最好关注您面前的数据。
感谢您的帖子!我有一个问题。在一个文件中,高亮显示是每个故事的多个摘要,还是每个高亮显示是摘要的一个句子?
我相信每个故事都有多个“摘要”。
感谢您的回复。我感到很困惑。我们的目标是获得一个摘要作为模型的输出,因此训练数据中的目标应该是一个摘要。我们是否应该在训练模型之前将“高亮显示”进行划分?
模型性能将通过困惑度或 BLEU 分数报告。
您花了多长时间将清理后的数据保存为 pickle 文件?对我来说,这花了很多时间。
应该只需几秒钟。
确保您是从命令行而不是笔记本运行。
嗨,杰森,谢谢你的帖子!
你提到我们可以通过减少词汇量来加速测试模型,例如
删除数字(例如“93.4%”)。
删除低频词,例如姓名(例如“Tom Watkins”)。
但是,我认为数字和姓名对于某些类型的文档来说是重要信息。例如数字代表利润、准确性、犯罪率,姓名是“乔·拜登”。那么我们如何决定是否需要删除这些信息呢?谢谢!
不客气。
好问题,这实际上是您项目目标的问题。首先要对您的模型需要做什么有一个清晰的认识,然后删除对该目标不重要的元素。或者也可以尝试一些试错法。
嗨,Jason,
如果我们要使用“https://machinelearning.org.cn/encoder-decoder-models-text-summarization-keras/”中的任何算法,我们是否需要在每个故事/亮点的开头和结尾添加“BOS”和“EOS”?
这取决于模型,在某些情况下是的。
你好。想寻求一点帮助。我想计算故事和亮点之间的 Rouge 分数?该怎么做?
请查看这个 Python 包:https://pypi.ac.cn/project/rouge-score/
或者你也可以实现自己的评分函数。
嗨,我已经完成了如上所示的数据清理。
现在我的任务是比较故事和亮点,并根据故事中的句子是否也存在于亮点中,将故事评分0或1。
您能建议一下如何进行吗?
嗨 Tanya…请看我之前的回复。
https://machinelearning.org.cn/multi-label-classification-with-deep-learning/
嗨,我已经完成了如上所示的数据清理。
现在我的任务是比较故事和亮点,并根据故事中的句子是否也存在于亮点中,将故事评分0或1。
您能建议一下如何进行吗?
嗨,sh…以下内容可能有助于澄清后续步骤
https://machinelearning.org.cn/multi-label-classification-with-deep-learning/