减少预测模型的输入变量数量被称为降维。
更少的输入变量可以生成更简单的预测模型,该模型在对新数据进行预测时可能具有更好的性能。
在机器学习中,最流行的降维技术可能就是主成分分析(Principal Component Analysis),简称 PCA。这是一种来自线性代数领域的技术,可以用作数据准备技术,在拟合模型之前创建数据集的投影。
在本教程中,您将学习如何在开发预测模型时使用 PCA 进行降维。
完成本教程后,您将了解:
- 降维涉及减少建模数据中的输入变量或列的数量。
- PCA 是一种线性代数技术,可用于自动执行降维。
- 如何评估使用 PCA 投影作为输入并使用新的原始数据进行预测的预测模型。
通过我的新书《机器学习数据准备》启动您的项目,其中包括逐步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2020 年 5 月更新:改进了代码注释。

Python 中的主成分分析(PCA)用于降维
图片来源:美国林业局(Forest Service, USDA),部分权利保留。
教程概述
本教程分为三个部分;它们是:
- 降维和 PCA
- PCA Scikit-Learn API
- PCA 用于降维的实际示例
降维和 PCA
降维指的是减少数据集的输入变量数量。
如果您的数据以行和列的形式表示,例如在电子表格中,那么输入变量就是作为模型输入以预测目标变量的列。输入变量也称为特征。
我们可以将数据列视为在 n 维特征空间中表示维度,将数据行视为该空间中的点。这是数据集的有用几何解释。
在具有 k 个数值属性的数据集中,您可以将数据可视化为 k 维空间中的点云……
— 第 305 页,《数据挖掘:实用机器学习工具和技术》,第 4 版,2016 年。
特征空间中维度数量过多可能意味着该空间的体积非常大,反过来,该空间中的点(数据行)通常代表一个很小且不具代表性的样本。
这会极大地影响在具有许多输入特征的数据上拟合的机器学习算法的性能,通常称为“维度灾难”。
因此,通常需要减少输入特征的数量。这会减少特征空间的维度数量,因此称为“降维”。
一种流行的降维方法是使用线性代数领域的技术。这通常被称为“特征投影”,所使用的算法被称为“投影方法”。
投影方法旨在减少特征空间中的维度数量,同时保留数据中观察到的变量之间最重要的结构或关系。
在处理高维数据时,通过将数据投影到捕获数据“本质”的低维子空间来降低维度通常很有用。这被称为降维。
— 第 11 页,《机器学习:概率视角》,2012 年。
生成的投影数据集可以作为输入来训练机器学习模型。
本质上,原始特征不再存在,而是从可用数据中构建新的特征,这些新特征与原始数据不直接可比,例如,没有列名。
将来在进行预测时,任何输入到模型的新数据,例如测试数据集和新数据集,也必须使用相同的技术进行投影。
主成分分析(PCA)可能是最流行的降维技术。
最常见的降维方法称为主成分分析或 PCA。
— 第 11 页,《机器学习:概率视角》,2012 年。
它可以被视为一种投影方法,其中具有 m 列(特征)的数据被投影到具有 m 或更少列的子空间中,同时保留了原始数据的本质。
PCA 方法可以使用线性代数工具来描述和实现,特别是像特征分解或SVD这样的矩阵分解。
PCA 可以定义为将数据正交投影到较低维度的线性空间(称为主子空间),使得投影数据的方差最大化。
— 第 561 页,《模式识别与机器学习》,2006 年。
有关 PCA 如何详细计算的更多信息,请参阅教程
现在我们熟悉了 PCA 用于降维,接下来看看如何使用 scikit-learn 库来应用这种方法。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
PCA Scikit-Learn API
我们可以使用 PCA 来计算数据集的投影,并选择投影的维度或主成分数量作为模型的输入。
scikit-learn 库提供了 PCA 类,可以将其拟合到数据集上,并用于转换训练数据集以及未来任何额外的数据集。
例如:
|
1 2 3 4 5 6 7 8 |
... 数据 = ... # 定义转换 pca = PCA() # 准备对数据集进行转换 pca.拟合(数据) # 对数据集应用转换 转换后的数据 = pca.转换(数据) |
PCA 的输出可以用作训练模型的输入。
也许最好的方法是使用管道(Pipeline),其中第一步是 PCA 转换,下一步是学习算法,它将转换后的数据作为输入。
|
1 2 3 4 |
... # 定义管道 步骤 = [('pca', PCA()), ('m', 逻辑回归())] 模型 = 管道(步骤=步骤) |
如果输入变量具有不同的单位或尺度,在执行 PCA 转换之前对数据进行归一化也是一个好主意;例如:
|
1 2 3 4 |
... # 定义管道 步骤 = [('norm', MinMaxScaler()), ('pca', PCA()), ('m', LogisticRegression())] 模型 = 管道(步骤=步骤) |
现在我们熟悉了 API,让我们来看一个实际的例子。
PCA 用于降维的实际示例
首先,我们可以使用 make_classification() 函数来创建一个合成二元分类问题,其中包含 1,000 个示例和 20 个输入特征,其中 15 个输入是 有意义的。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 测试分类数据集 从 sklearn.数据集 导入 生成_分类 # 定义数据集 X, y = 生成_分类(样本数=1000, 特征数=20, 信息特征数=15, 冗余特征数=5, 随机状态=7) # 汇总数据集 打印(X.形状, y.形状) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
接下来,我们可以在这个数据集上使用降维,同时拟合逻辑回归模型。
我们将使用一个管道,其中第一步执行 PCA 转换并选择 10 个最重要的维度或组件,然后根据这些特征拟合一个逻辑回归模型。我们不需要在这个数据集上归一化变量,因为所有变量的尺度设计上是相同的。
该管道将使用重复分层交叉验证进行评估,其中包含三次重复和每次重复 10 折。性能以平均分类准确度表示。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 使用逻辑回归算法评估 PCA 用于分类 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline 从 sklearn.分解 导入 PCA 从 sklearn.线性模型 导入 LogisticRegression # 定义数据集 X, y = 生成_分类(样本数=1000, 特征数=20, 信息特征数=15, 冗余特征数=5, 随机状态=7) # 定义管道 步骤 = [('pca', PCA(n_components=10)), ('m', LogisticRegression())] 模型 = 管道(步骤=步骤) # 评估模型 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) n_scores = cross_val_score(模型, X, y, 评分='准确度', cv=cv, n_jobs=-1, 错误评分='raise') # 报告表现 打印('准确度: %.3f (%.3f)' % (平均值(n_scores), 标准差(n_scores))) |
运行示例会评估模型并报告分类准确率。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到 PCA 转换与逻辑回归结合使用实现了大约 81.8% 的性能。
|
1 |
准确度:0.816 (0.034) |
我们怎么知道将 20 维输入降至 10 维是好还是我们能做到的最好?
我们不知道;10 是一个任意选择。
一个更好的方法是使用不同数量的输入特征来评估相同的转换和模型,并选择能带来最佳平均性能的特征数量(降维程度)。
下面的示例执行了这个实验,并总结了每个配置的平均分类准确率。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 比较 PCA 组件数量与逻辑回归算法用于分类 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline 从 sklearn.分解 导入 PCA from sklearn.linear_model import LogisticRegression from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = 生成_分类(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): 模型 = 字典() 对于 i 在 范围(1,21): 步骤 = [('pca', PCA(n_components=i)), ('m', LogisticRegression())] 模型[字符串(i)] = 管道(步骤=步骤) 返回 模型 # 使用交叉验证评估给定模型 定义 评估_模型(模型, X, y): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) 分数 = cross_val_score(模型, X, y, 评分='准确度', cv=cv, n_jobs=-1, 错误评分='raise') 返回 分数 # 定义数据集 X, y = 获取_数据集() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 结果, 名称 = 列表(), 列表() 对于 名称, 模型 在 模型.项(): 分数 = 评估_模型(模型, X, y) results.append(scores) names.append(name) 打印('>%s %.3f (%.3f)' % (名称, 平均值(分数), 标准差(分数))) # 绘制模型性能以供比较 pyplot.箱线图(结果, 标签=名称, 显示平均值=真) pyplot.xticks(旋转=45) pyplot.show() |
运行该示例首先报告每个选定组件或特征数量的分类准确性。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们看到,随着维度数量的增加,性能普遍呈上升趋势。在这个数据集上,结果表明维度数量与模型的分类准确性之间存在权衡。
有趣的是,超过 15 个组件后,性能没有任何改善。这与我们对问题的定义相符,即只有前 15 个组件包含有关类别的信息,其余五个是冗余的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
>1 0.542 (0.048) >2 0.713 (0.048) >3 0.720 (0.053) >4 0.723 (0.051) >5 0.725 (0.052) >6 0.730 (0.046) >7 0.805 (0.036) >8 0.800 (0.037) >9 0.814 (0.036) >10 0.816 (0.034) >11 0.819 (0.035) >12 0.819 (0.038) >13 0.819 (0.035) >14 0.853 (0.029) >15 0.865 (0.027) >16 0.865 (0.027) >17 0.865 (0.027) >18 0.865 (0.027) >19 0.865 (0.027) >20 0.865 (0.027) |
为每个配置的维度数量的准确度分数分布创建了一个箱线图。
我们可以看到分类准确性随着组件数量的增加而增加的趋势,并在 15 个组件处达到极限。
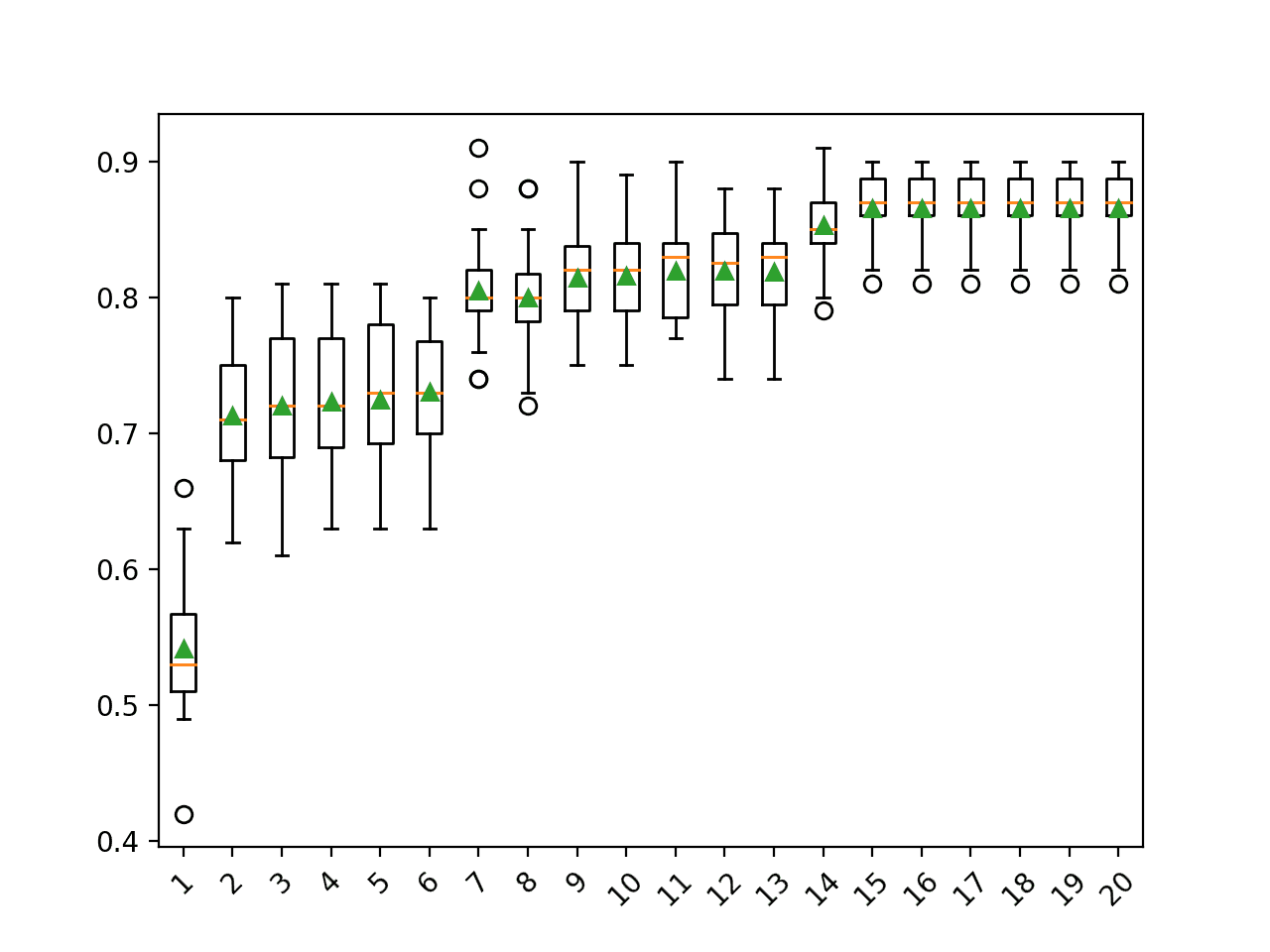
PCA 组件数量与分类准确率的箱线图
我们可能会选择使用 PCA 转换和逻辑回归模型组合作为我们的最终模型。
这涉及在所有可用数据上拟合管道,并使用管道对新数据进行预测。重要的是,必须对这些新数据执行相同的转换,这通过管道自动处理。
下面的示例提供了一个在 P C A 转换的新数据上拟合和使用最终模型的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 使用 PCA 和逻辑回归进行预测 from sklearn.datasets import make_classification from sklearn.pipeline import Pipeline 从 sklearn.分解 导入 PCA 从 sklearn.线性模型 导入 LogisticRegression # 定义数据集 X, y = 生成_分类(样本数=1000, 特征数=20, 信息特征数=15, 冗余特征数=5, 随机状态=7) # 定义模型 步骤 = [('pca', PCA(n_components=15)), ('m', LogisticRegression())] 模型 = 管道(步骤=步骤) # 在整个数据集上拟合模型 模型.拟合(X, y) # 进行单次预测 行 = [[0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]] yhat = 模型.预测(行) 打印('预测类别: %d' % yhat[0]) |
运行示例会在所有可用数据上拟合管道,并对新数据进行预测。
这里,转换使用 PCA 转换中最重要的 15 个组件,正如我们从上面测试中发现的。
提供了一个包含 20 列的新数据行,该数据行会自动转换为 15 个组件并输入到逻辑回归模型中,以预测类别标签。
|
1 |
预测类别:1 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
书籍
- 机器学习:概率视角, 2012.
- 《数据挖掘:实用机器学习工具和技术》,第 4 版,2016 年。
- 模式识别与机器学习, 2006.
API
文章
总结
在本教程中,您学习了如何在开发预测模型时使用 PCA 进行降维。
具体来说,你学到了:
- 降维涉及减少建模数据中的输入变量或列的数量。
- PCA 是一种线性代数技术,可用于自动执行降维。
- 如何评估使用 PCA 投影作为输入并使用新的原始数据进行预测的预测模型。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。

 from Scratch in Python")





你好
我们可以将 PCA 称为特征选择方法吗?
我不会称之为“选择”,因为 PCA 不是从原始特征集中进行选择,而是将原始特征转换到新的特征空间,这样新的特征就包含了所有原始特征的一些信息。所以“特征转换”是准确的术语。
同意。
更准确的说法是降维。它不选择特征,它选择一个投影。
我会说“有时”。如果你看看最重要的主成分解释了多少变异性,并且这与你对特征空间的看法不同,那可以促使你回去检查你的特征空间。我确实有一些 PCA 结果是令人惊讶的,这让我回去查看了特征。
我最喜欢的特征选择工具之一是递归特征消除(RFE),sklearn 中 RFE 的实现对于 Python 工具用户来说非常棒。
我很想听听其他人对“PCA 用于特征选择”这个问题的看法。
PCA 是原始数据的投影,而不是特征选择方法——至少在我看来是这样。
我是 RFE 的忠实粉丝。
我在一个项目上假设很少/没有东西,并列举所有我能想到的创建原始数据不同“视图”或视角的方法,然后将其投入模型并查看结果。这有助于我非常快速地学习如何最好地向学习算法展示问题的结构。这不是 PCA 特定的,但可能会有所帮助……
同意。如果自变量的数量不是太大,我几乎总是从散点图开始,然后进行某种聚类以查看可能出现的关系,接着是 PCA 并查看转换后的空间是什么样子,前 4-6 个主成分中有多少变异性。
如果你有一个非常大的降维挑战,我的一个同事在 t-SNE 方面取得了一些有趣的成功。
太棒了!
大约 20 年前,我喜欢萨蒙斯映射,以及科诺宁自组织映射,在当时这被认为是高维的。投影变得非常有趣 🙂
我们如何比较降维后得到的最终主成分与初始数据集?
我们不比较,它们就像从旧特征中衍生出的新特征。
我认为我们不能。PCA 从可用的特征集中生成新特征,或者我们可以说是投影。它减少了特征的数量,但减少后的特征集并不是原始特征集的子集。
同意。
您好,Jason:感谢您的教程,我一直很欣赏您的工作。我只是想知道,使用相同的数据集,我们是否有办法比较基于神经网络的深度自编码器和 PCA 之间的降维性能。那么,是否可以在这里进行,或者下次在另一个课程中进行?谢谢
是的,准备不同的输入,在其上拟合模型,产生最佳性能模型的输入是最有用的。
您好 Jason,请在 R 或 Python 中提供一个 PLS(偏最小二乘法)用于降维的示例。
好建议,谢谢!
主成分分析的补充资源,包含过程的逐步解释
https://www.neuraldesigner.com/blog/principal-components-analysis
感谢分享。
还有一篇
https://learnche.org/pid/latent-variable-modelling/principal-component-analysis/geometric-explanation-of-pca
感谢分享。
嗨,Jason,
我是在 R 中学习 PCA 的,我对 PCA 的理解是它有助于发现输入变量之间的相关性。R 中有一些库可以帮助可视化地呈现输入变量之间的相关性。例如,下面是:
但您在这篇文章中没有谈到输入变量的相关性以及在 Python 中表示输入变量相关性的可能性。您是否有关于 PCA 和 Python 中输入变量相关性的链接或文章?
感谢您分享的所有知识。
Dominique
PCA 消除了输入变量之间的线性依赖关系。
是的,这可能会有帮助。
https://machinelearning.org.cn/calculate-principal-component-analysis-scratch-python/
过滤方法(如 PCA)的主要兴趣之一是无需进一步分类即可发挥作用。
而不是这种贪婪的方法,(1)计算其他 PC 的累积方差,(2)选择一个阈值以保留 80/90/95% 的方差,(3)选择相应的 PC。
然后转换您的数据并检查准确性。
它更快,消耗更少!
好建议!
尊敬的Jason博士,
您会在未来的博客中介绍独立成分分析(‘ICA’)吗?ICA 可用于分离信号,例如将许多语音信号分离成独立的组件。ICA 甚至用于图像处理,以分离恼人的干扰,例如图片中的反射——例如,窗户反射光线,而不是窗户后面的图像。
谢谢你,
悉尼的Anthony
感谢您的建议。目前还没有计划,但我会将其添加到不断增长的列表中。
先生,当我运行上述代码时,它给了我一个错误,因为
cross_val_score() 得到了一个意外的关键字参数 'error_score'
很抱歉听到这个消息,也许您可以更新您的库,比如 scikit-learn。
先生,在 PCA LDA 和 RFE 中,哪个特征选择算法最好?
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/what-feature-selection-method-should-i-use
到目前为止,这是一篇很棒的文章!
我来自孟加拉国,从去年开始关注您的博客文章。
您能否分享一些关于如何在 python 中应用分段 PCA (SPCA) 或折叠 PCA (FPCA) 的想法
感谢您的建议,我未来可能会写关于这些主题的文章。
先生,您能否提供一个在优化预测模型之后应用特征选择或增强技术的示例。
你到底是什么意思?也许你可以详细说明一下?
尊敬的Jason博士,
在特征约简方法中,有一些方法可以告诉我们选择了哪些特征。
有时它是一个真值和假值数组
我尝试为 PCA 找到类似的方法来确定 X 的所有特征中哪个“子集”已被选择。
有没有一种方法可以确定 X 的所有特征中哪些特征被确定为对 X 具有显著性?
谢谢你,
悉尼的Anthony
我给你一个 RFE 的清晰例子
换句话说,对于 PCA,有没有一种或多种方法可以像 RFE 那样确定哪些特征是重要的以及它们的排名。
为什么?如果你有几个特征,但一个简洁的模型可以用更少的特征来解释,你如何确定 PCA 中选择了哪些特征?
谢谢你,
悉尼的Anthony
PCA 不会输出相同的特征,它将数据投影到较低维度的空间中。例如,它们不再是相同的特征,也没有名称。
也许可以看看这个教程:
https://machinelearning.org.cn/calculate-principal-component-analysis-scratch-python/
PCA 不选择子集,它将数据投影到一个新的低维空间。
输出不能直接与输入相关联。
尊敬的Jason博士,
我还是不清楚。
是的,我知道 PCA 是从高维到低维的投影。
在您最新的电子书《机器学习数据准备》中,清单 29.6 使用了 PCA。
假设模型是使用这些步骤确定的。
我们如何知道使用了 X 的哪些子集特征,即使在使用 PCA 时也使用了图形技术。
谢谢你,
悉尼的Anthony
PCA 不选择特征子集。
它从输入数据创建“新”特征。这被称为投影。
尊敬的Jason博士,
我使用了受 https://towardsdatascience.com/pca-clearly-explained-how-when-why-to-use-it-and-feature-importance-a-guide-in-python-7c274582c37e 启发的文章。
使用“iris”数据,我想看看有多少组件解释了 y 的大部分方差。
从上面可以看出,y 96% 的变异由前两个分量解释,分别为 73% 和 23%。
问题:这些“新”特征,即新的组件,如何帮助我决定选择 X 的哪些原始特征。
谢谢你,
悉尼的Anthony
尊敬的Jason博士,
我问题的答案可以在 https://stackoverflow.com/questions/50796024/feature-variable-importance-after-a-pca-analysis 的第一个答案部分 1 中找到。
以下矩阵的每一行代表一个分量。例如,第 0 行是第一个主成分,第 1 行是第二个主成分。
回想一下,前两个 PCA 组件解释了 96% 的变异。
第 0 行 = 第 1 个主成分,第 1 个(第 0 列)、第 3 个和第 4 个特征可以使用
第 1 行 = 第二个主成分,第二个特征可以使用(0.923)。
回想一下,数据集中有四个特征。
总体而言,“萼片长度”、“花瓣长度”和“花瓣宽度”解释了数据集中大部分的变异。看起来“花瓣长度”对解释样本属于“山鸢尾”、“变色鸢尾”或“维吉尼亚鸢尾”没有贡献。
选择使用哪些特征的结论
* 获取 PCA 成分矩阵的绝对值。
* 知道矩阵的前两行是解释变异的前两个成分,确定哪些特征对第一和第二成分贡献最大。
* 因为第二个成分并不那么显著(22%),而且第二个特征解释了第二个成分而不是第一个成分,所以不要使用它。
谢谢你,
悉尼的Anthony
尊敬的Jason博士,
抱歉。
我之前说过
“总的来说,‘萼片长度’、‘花瓣长度’和‘花瓣宽度’解释了数据集中大部分的变异。看起来‘花瓣长度’对解释样本属于‘山鸢尾’、‘变色鸢尾’或‘维吉尼亚鸢尾’没有贡献。”
我的意思是
“总的来说,‘萼片长度’、‘花瓣长度’和‘花瓣宽度’解释了数据集中大部分的变异。似乎‘萼片宽度’对于解释样本属于‘setosa’、‘versicolor’或‘virginica’没有贡献。”
谢谢你,
悉尼的Anthony
这里也解释了数学原理
https://machinelearning.org.cn/calculate-principal-component-analysis-scratch-python/
PCA 不会帮助您选择数据集中的特征。
它通过将数据投影到较低维空间来降低数据的维度。
尊敬的Jason博士,
谢谢你的回复。
*是的,我理解 PCA 通过将数据投影到较低维空间来降低数据的维度。
*是的,我已经在你的博客上从头开始尝试了 PCA 的计算。
*是的,我可以看到 P = vectors.T.dot(C.T) 是特征向量的转置与中心化列的投影/点积,我们只需要第一个特征向量来解释大部分变异。
*是的,投影矩阵并不能告诉我们应该使用哪些特征。完全同意。
也许我应该更清楚一点。关于 pca.components_
* 您可以使用 pca.components_ 将主成分与特征关联起来
* pca.components_ 关联 C
pca.components_ 是一个形状为 n_components 乘 n_features 的矩阵。也就是说,行是主成分,列是特征。
也就是说,您可以找到每个特征对每个主成分的贡献
结论
虽然您无法通过 PCA 确定要使用哪些特征,因为它是一个投影,但您可以将特定的主成分与特征关联起来!!!!
从程序中可以看出:由于第一个主成分 PC1 解释了 76% 的变异,我们可以得出结论,特征 1、3、4 最重要。也就是说,“萼片长度 (cm)”、“萼片宽度 (cm)”、“花瓣宽度 (cm)”。“花瓣长度 (cm)”则不那么重要。
来源/灵感:来自 https://stackoverflow.com/questions/50796024/feature-variable-importance-after-a-pca-analysis 的第一个答案第一部分
谢谢你,
悉尼的Anthony
不错的总结,感谢分享。
尊敬的Jason博士,
如果我的数据集有800个样本。每个样本有65536个特征,我只想将这些特征减少到1024个。当我使用PCA时,我收到这个错误
ValueError: n_components=1024 必须介于 0 和 min(n_samples, n_features)=4 之间,svd_solver='full'
请问,您有什么建议可以帮助我吗?
谢谢,
特征数量可能太少,不适合 PCA。
也许可以尝试其他方法?
尊敬的Jason博士,
抱歉,错误信息是
ValueError: n_components=1024 必须介于 0 和 min(n_samples, n_features)=800 之间,svd_solver='full'
如果 n_components 的数量大于 min(n_samples, n_features),我该怎么办?
谢谢你的帮助
也许你可以尝试其他方法,比如这里描述的那些
https://machinelearning.org.cn/dimensionality-reduction-algorithms-with-python/
尊敬的Jason博士,
我有一个关于数据集的问题,其中每个特征都有3个数值。例如,每个特征都是一个包含 x,y,z 值的点坐标。
在这种情况下,我们也可以应用 PCA 吗?
例如:我有 100 个样本,每个样本有 400 个特征,每个特征包含 [[[1, 8, 9]]....] 或 [ [[1],[8],[9]] ... [[3],[5],[4]] ]。
提前感谢
也许可以,但是坐标的每个轴都会成为任何数据准备或模型的一个新“特征”。
如何将PCA用于包含数百张图像的卫星图像?
抱歉,我没有在图像上使用 PCA 的示例。
如何对包含200多个波段的高光谱图像进行降维?
抱歉,我对这种用例没有经验。我无法给你直接的建议。
嗨,Jason,
再次感谢您的回复!我真的很佩服您所做的一切。我已经看完了您的预处理帖子,我有一个关于 PCA 的问题:您只调整了与成分相关的超参数。是不是因为没有必要调整其他参数?
谢谢您一直以来的关照
是的,调整所有参数是个好主意。
在本教程中,我们专注于调整 PCA,因为本教程是关于 PCA 的。
嘿,Jason,又是我!我的意思是,您会调整 PCA 的所有超参数(例如 iterated_power 或 svd_solver),还是只关注组件的数量很重要?
当专注于降维时,我们调整组件的数量。
嗨,Jason博士,
非常感谢您有用的网站。我从您那里学到了很多。
它是否使用 PCA 特征选择作为数据集(训练和测试重塑数据)来输入 ANN 神经网络以预测(AC)?
我使用 Lasso 回归进行特征选择,结果可以接受。然而,我想使用 PCA 模型作为替代。
我这样做了,但我的误差显著增加了。考虑到 PCA 专注于标准差和方差,而 Lasso 则作用于系数。
请告诉我,PCA 特征选择是否可以用在监督模型(如回归模型)中?
谢谢,
Mehdi
不客气。
PCA 是一种转换,而不是特征选择。
您可以将其应用于数值数据,并与您喜欢的任何模型一起使用。
也许在应用转换之前尝试标准化数据?
精彩的文章;非常感谢分享实践方法。我已在以下文章中分享了我对 PCA 的看法。请随意浏览。
https://medium.com/analytics-vidhya/principal-component-analysis-pca-part-1-fundamentals-and-applications-8a9fd9de7596
感谢分享。
好文章!不过我有个问题,你觉得解释方差的百分比有多重要?假设我们有一个无监督任务,即无法进行交叉验证。一般来说,是保持维度低还是解释方差高更好?
卢卡
如果您对分析感兴趣,解释方差可能是一个有用的工具。
如果您只关注预测技能,我就不太确定了。
你好,我有2个问题
1- 什么时候应该进行 PCA?我对 48 个主要变量进行了初步预处理,现在我有 126 个变量可用于建模。PCA 可以对这 126 个变量进行吗?还是必须在 48 个主要变量上运行?
2- PCA 中变量间的线性假设是否应该被检查?因为我没有检查假设,但我有很好的准确性。我的模型有效吗?
谢谢
https://stats.stackexchange.com/questions/332297/linear-relationship-between-variables-using-principal-component-analysis-pca
https://datascience.stackexchange.com/questions/93734/can-someone-clarify-what-the-linear-assumption-of-pca-is
如果您关注模型性能(我们大多数人都是),那么当 PCA 能够为您的数据集带来更好的性能时,就使用它。
你好 Jason,
感谢如此详细的解释。
不过,我想了解更多关于 PCA 在目标排序方面的用法。
我的意思是:如果我们的目标是汽车名称……那么如果数据集包含汽车的详细信息,我们如何利用 PCA 对汽车进行排名?
不确定 PCA 能否在这方面提供帮助。
你好,
感谢您直观的文章!
是否可以仅对部分特征执行 PCA?
例如,仅对两个高度相关的特征?
谢谢你
是的,您可以从完整数据集中创建一个子矩阵,并将其传递给 PCA。
亲爱的 Adrian,
感谢您的回复。但是,如果我们只对部分特征应用 PCA,那么它们还能与其他特征进行比较吗?
换句话说,将一些经过 PCA 转换和一些未经转换的特征输入到机器学习算法中有意义吗?
谢谢你
如果您将 PCA 应用于部分 *样本*,它们可能与其余样本可比。如果您将 PCA 应用于部分 *特征*,则肯定不能,因为我们假设输入到 PCA 的特征通过某种线性组合映射以生成主成分。对于未见的特征,我们一无所知,因此我们无法从 PCA 中得出任何结论。
非常感谢你
先生,关于这篇文章。
这是少数几个能清晰解释机器学习概念并提供详细示例的网站之一。
谢谢先生
非常欢迎你,泰戈尔!我们感谢您的反馈和支持!
既然 PCA 是一种降维方法,我们如何才能知道哪些特征是重要的,哪些不重要呢?这样我们就可以从数据集中删除这些特征了吗?
嗨,gul khan……以下资源应该能帮你理清思路
https://www.keboola.com/blog/pca-machine-learning
PCA 作为一种降维方法,我们如何知道特征的重要性,例如哪些特征应该删除,哪些应该使用?
我读到 PCA 应该拟合在训练集上,然后使用相同的组件应用于测试集,而不是将 PCA 应用于整个数据集,以避免数据泄露。这种说法有道理吗?
选项 1
pca = PCA(n_components = 2)
pca.fit_transform(X_train)
pca.transform(X_test)
而不是
选项
pca = PCA(n_components = 2)
pca.fit_transform(X)
嗨,Johnny……以下内容可能会让您感兴趣
https://medium.com/data-science-365/how-to-avoid-data-leakage-in-data-preprocessing-f2d0357979eb
有没有办法对分类变量进行降维?
谢谢!