
图片来源:编辑 | Midjourney
强化学习(RL)是一种机器学习类型。它通过与环境交互来训练一个智能体做出决策。本文将介绍RL的基本概念,包括状态、动作、奖励、策略以及马尔可夫决策过程(MDP)。读完本文,您将理解RL的工作原理,并学会如何在Python中实现它。
强化学习中的关键概念
强化学习(RL)包含几个核心思想,这些思想塑造了机器如何从经验中学习并做出决策。
- 智能体(Agent):它是与环境交互的决策者。
- 环境(Environment):智能体与之交互的外部系统。
- 状态(State):对环境当前情况的表示。
- 动作(Action):智能体在给定状态下可以采取的选择。
- 奖励(Reward):智能体在某个状态下采取某个动作后获得的即时反馈。
- 策略(Policy):智能体根据状态来决定其动作的一组规则。
- 价值函数(Value Function):估算在特定策略下,从某个特定状态获得的预期长期回报。
马尔可夫决策过程
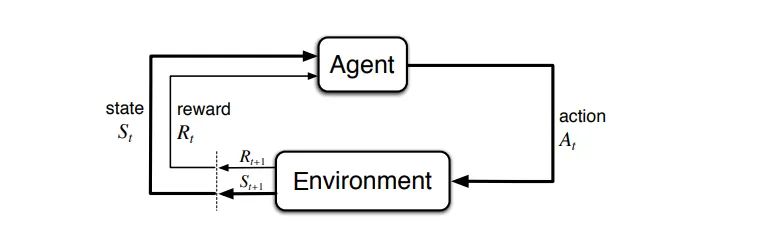
马尔可夫决策过程 | 图片来源
马尔可夫决策过程(MDP)是一个数学框架。MDP为强化学习中的环境描述提供了一种结构化方法。
MDP由元组(S,A,T,R,γ)定义。元组的组成部分如下所述。
- 状态(States):环境中所有可能状态的集合。
- 动作(Actions, A):智能体可能采取的所有可能动作的集合。
- 转移模型(Transition Model, T):从一个状态转移到另一个状态的概率。
- 奖励函数(Reward Function, R):从一个状态转移到另一个状态后获得的即时奖励。
- 折扣因子(Discount Factor, γ):一个介于0到1之间的因子,表示未来奖励的重要性。
贝尔曼方程
贝尔曼方程根据预期的未来回报来计算处于某个状态或采取某个动作的价值。
它将总预期回报分解。第一部分是获得的即时奖励。第二部分是未来奖励的折扣值。该方程帮助智能体做出决策以最大化其长期收益。
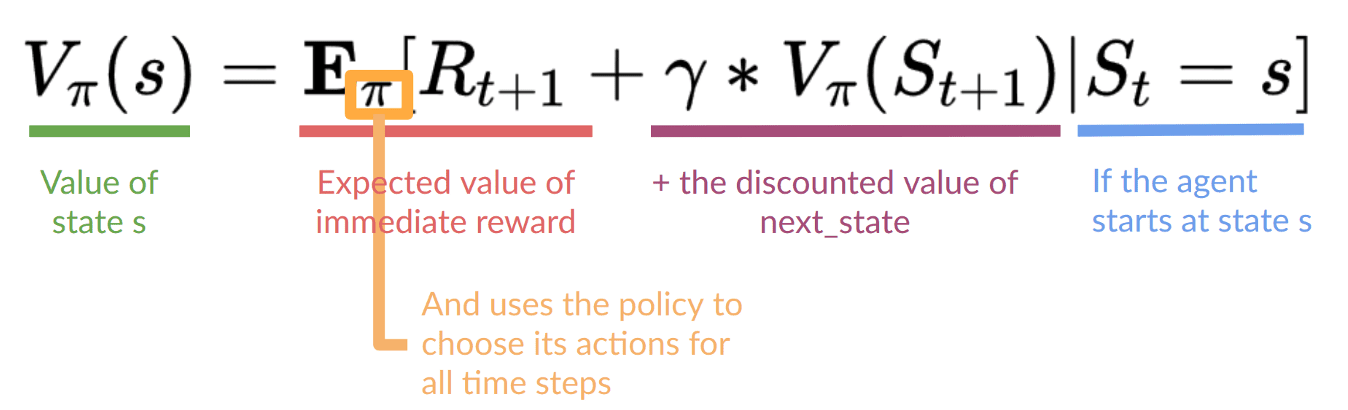
贝尔曼方程 | 图片来源
强化学习的步骤
- 定义环境:指定状态、动作、转移规则和奖励。
- 初始化策略和价值函数:为决策制定和价值估算设定初始策略。
- 观察初始状态:收集有关环境初始条件的信息。
- 选择动作:根据当前策略决定一个动作。
- 观察结果:从环境中以新的状态和奖励的形式接收反馈。
- 更新策略:根据接收到的反馈调整决策策略和价值估算。
强化学习算法
强化学习中有几种常用的算法。
- Q-Learning:一种无模型算法,用于学习状态-动作空间中动作的价值。
- 深度Q网络(DQN):Q-Learning的扩展,使用深度神经网络来处理大的状态空间。
- 策略梯度方法(Policy Gradient Methods):通过梯度上升调整策略参数直接优化策略。
- Actor-Critic方法:结合了基于价值和基于策略的方法。Actor更新策略,Critic评估动作。
Q-Learning算法
Q-Learning是强化学习中的一项关键算法。它是一种无模型方法,这意味着它不需要环境的模型。Q-Learning通过直接与环境交互来学习动作。其主要目标是找到最大化累积奖励的最佳动作选择策略。
关键概念
- Q值(Q-Value):Q值,表示为Q(s,a),代表在特定状态下采取特定动作并遵循该策略之后的预期累积奖励。
- Q表(Q-Table):一个表格,其中每个单元格Q(s,a)对应于一个状态-动作对的Q值。当智能体从经验中学习时,该表格会不断更新。
- 学习率(Learning Rate, α):一个决定新信息应在多大程度上覆盖旧信息的因子。它介于0和1之间。
- 折扣因子(Discount Factor, γ):一个降低未来奖励价值的因子。它也介于0和1之间。
使用Python实现Q-Learning
导入所需的库
导入必要的库。`gym`用于创建和交互环境。此外,`numpy`用于数值运算。
|
1 2 |
import gym import numpy as np |
初始化环境和Q表
创建`FrozenLake`环境并用零初始化Q表。
|
1 2 |
env = gym.make("FrozenLake-v1", is_slippery=False) Q = np.zeros((env.observation_space.n, env.action_space.n)) |
定义超参数
为Q-Learning算法定义超参数。
|
1 2 3 4 5 |
learning_rate = 0.8 discount_factor = 0.95 epsilon = 0.1 episodes = 10000 max_steps = 100 |
实现Q-Learning
在上述设置上实现Q-Learning算法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
for episode in range(episodes): state = env.reset() done = False for _ in range(max_steps): # 选择动作(epsilon-greedy策略) if np.random.uniform(0, 1) < epsilon: action = env.action_space.sample() else: action = np.argmax(Q[state, :]) # 执行动作并观察结果 next_state, reward, done, _ = env.step(action) # 使用贝尔曼方程更新Q值 Q [state, action] = Q [state, action] + learning_rate * (reward + discount_factor * np.max(Q [next_state, :]) - Q [state, action]) # 转移到下一个状态 state = next_state # 如果回合结束,则跳出循环 if done: break |
评估训练好的智能体
计算智能体与环境交互时收集到的总奖励。
|
1 2 3 4 5 6 7 8 9 10 |
state = env.reset() done = False total_reward = 0 while not done: action = np.argmax(Q[state, :]) next_state, reward, done, _ = env.step(action) total_reward += reward state = next_state env.render() |
结论
本文介绍了强化学习的基本原理,并提供了一个初学者友好的实现示例。随着您深入学习,将接触到更高级的方法,如深度强化学习。这种方法将RL与神经网络结合,以有效地管理复杂的状态和动作空间。







你好,解释和代码都很棒。
我想问一下,是不是有可能你忘记了对Q值进行平均?
嗨 Panagiotis……不客气!请澄清您的问题。您是否遇到了代码问题?
你好,James,
谢谢您的回复。
代码运行正常。对于使用最新版本gym的用户,需要做一些小的调整,但它能运行。
我的问题是关于Q学习部分。在第16行,Q值是如何更新的。我认为每次回合结束后更新的值应该是观察到的Q值的平均值,但也许我遗漏了什么。
嗨 Jayita,
首先,这篇文章写得太棒了!对我来说,这是对强化学习很好的初步介绍,而且从一开始就能够上手非常有帮助。
话虽如此,但与Jason写的《Python中的第一个机器学习项目(分步教程)》相比,我发现他的文章更具解释性和洞察力,他花时间解释了代码的每一个细节。而在这里,我有时会想知道某些东西是什么,或者我们为什么要这样做,例如当你介绍代码中的“episodes”和“max steps”时,却没有解释它们。当然,稍后阅读其余代码时,它们会变得更清楚,但即便如此。
再说一遍,这篇文章非常有帮助!但我想给像我这样的新手一些建议,让它稍微更清楚一些。
继续写这样的文章🙂
Mark,非常感谢您的反馈!感谢您参与我们的讨论!