这是与 Artem Yankov 的项目聚焦。
您能介绍一下自己吗?
我叫 Artem Yankov,在过去 3 年里我一直在 Badgeville 担任软件工程师。我在那里使用 Ruby 和 Scala,尽管我之前的工作背景包括使用各种语言,如:汇编、C/C++、Python、Clojure 和 JS。
我喜欢捣鼓小项目和探索不同领域,例如我研究过的两个几乎不相关的领域是机器人和恶意软件分析。我不能说我成为了专家,但我确实玩得很开心。我建造的一个小型机器人看起来非常丑陋,但它可以通过 MS Kinect“看到”我的手臂动作并模仿我的手臂运动。
直到去年我完成了 Coursera 上 Andrew Ng 的课程,我才真正接触机器学习,我非常喜欢它。
你的项目叫什么名字?它做什么?
该项目名为 hapsradar.com,它是一个事件推荐网站,专注于当前或近期发生的事件。
我是一个糟糕的周末计划者,我常常发现自己不知道该做什么,如果我突然决定做一些家门外的活动。我寻找活动信息的典型算法是去 meetup.com 和 eventbrite 等网站,浏览大量的类别,点击许多按钮,阅读当前活动的列表。
因此,当我完成机器学习课程并开始寻找项目来练习我的技能时,我认为我可以真正自动化这个事件搜索过程,通过抓取这些网站的事件列表,然后根据我喜欢的内容构建推荐。
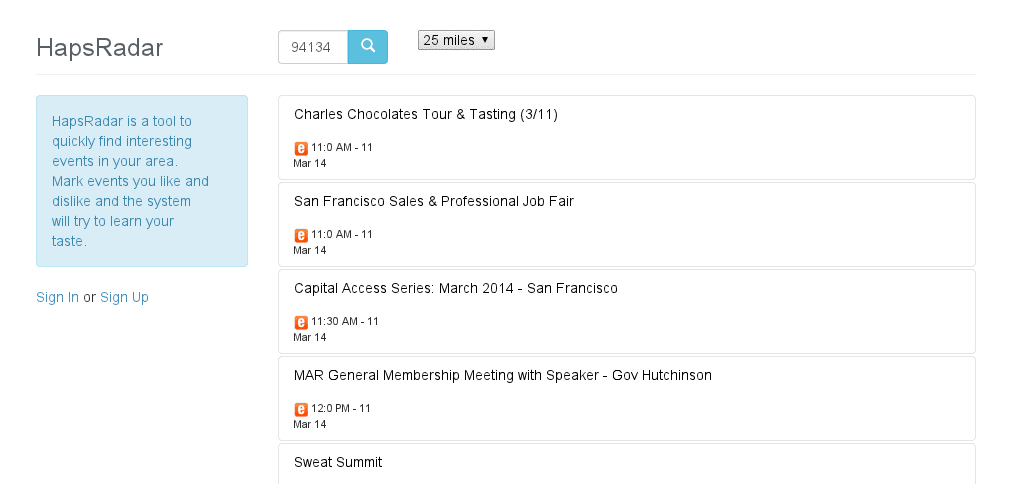
Artem Yankov 的 HapsRadar
该网站非常简洁,目前仅提供来自两个网站的事件:meetup.com 和 eventbrite.com。用户需要评价至少 100 个事件后,推荐引擎才会启动。然后它每晚运行,并使用用户的喜好/不喜欢进行训练,然后尝试预测用户可能喜欢的事件。
您是如何开始的?
我开始这个项目只是因为我想练习我的机器学习技能,为了让它更有趣,我选择了解决我遇到的一个实际问题。经过一些评估,我决定为我的推荐器使用 Python。以下是我使用的工具:
- Pandas
- Scikit-Learn
- PostgreSQL
- Scala / PlayFramework(用于事件抓取器和网站)
事件使用 meetup.com 和 eventbrite.com 提供的标准 API 进行抓取并存储在 postgresql 中。在开始我的爬虫之前,我给他们发了邮件,以核实我是否可以这样做,特别是我想每天运行这些爬虫来保持我的数据库更新所有事件。
他们对此非常友好,eventbrite 甚至在没有任何问题的情况下提高了我的 API 速率限制。meetup.com 有一个很棒的流式 API,允许你在事件发生变化时订阅所有变化。我想爬取 yelp.com,因为他们有活动列表,但他们完全禁止这样做。
当我有了第一批数据后,我建立了一个简单的网站,可以显示给定邮政编码(我目前只抓取美国的事件)附近一定范围内的事件。
现在是推荐器部分。用于构建我的特征的主要材料是事件标题和事件描述。我决定像事件发生的时间、离你家有多远等因素不会增加太多价值,因为我只想简单地回答这个问题:这个事件与我的兴趣相关吗?
想法 #1。预测主题
一些抓取的事件有标签或类别,有些则没有。
起初,我以为我应该尝试使用有标签的事件来预测无标签事件的标签,然后将它们用作训练特征。花了一些时间研究之后,我发现这可能不是一个好主意。大多数有标签的事件只有 1-3 个标签,而且它们通常非常不准确,甚至完全是随机的。
我认为 eventbrite 允许客户输入任何内容作为标签,而人们并不擅长想出好的词语。此外,每个事件的标签数量通常很少,即使你使用了人类的智能,也足以判断事件了。
当然,可以找到已经准确分类的文本并用它来预测主题,但这又带来了许多额外的问题:如何获取分类文本?它与我的事件描述的相关性如何?我应该使用多少个标签?所以我想到了其他主意。
想法 #2。LDA 主题建模
经过一些研究,我发现了一个很棒的 Python 库,名为 gensim,它实现了用于主题建模的 LDA(潜在狄利克雷分配)。
值得注意的是,这里的主题使用并不是指英文中的“体育”、“音乐”或“编程”等主题。LDA 中的主题是词语的概率分布。粗略地说,它找到了以一定概率一起出现的词语的集群。每个这样的集群就是一个“主题”。然后,你将新文档输入模型,模型也会推断出它的主题。
使用 LDA 非常直接。首先,我清理了文档(在我的例子中,文档是事件的描述和标题),方法是删除停止词、逗号、html 标签等。然后,我根据所有事件的描述构建了一个词典。
from gensim import corpora, models
dct = corpora.Dictionary(clean_documents)
然后我过滤掉非常罕见的词语
dct.filter_extremes(no_below=2)
要训练模型,所有文档都需要转换为词袋模型。
corpus = [dct.doc2bow(doc) for doc in clean_documents]
然后模型创建如下:
lda = ldamodel.LdaModel(corpus=corpus, id2word=dct, num_topics=num_topics)
其中 num_topics 是需要在文档上建模的主题数量。在我的例子中是 100。然后,将任何文档从词袋模型转换为其稀疏矩阵格式的主题表示。
x = lda[doc_bow]
所以现在我可以得到任何给定事件的特征矩阵,并且可以轻松地获得用户已评价事件的训练矩阵。
docs_bow = [dct.doc2bow(doc) for doc in rated_events]
X_train = [lda[doc_bow] for doc_bow in docs_bow]
这看起来是一个还不错的解决方案,使用 SVM(支持向量机)分类器,我获得了大约 85% 的准确率,当我查看我预测的事件时,它看起来相当准确。
注意:并非所有分类器都支持稀疏矩阵,有时你需要将其转换为密集矩阵。Gensim 有一种方法可以做到这一点。
gensim.matutils.sparse2full(sparse_matrix, num_topics)
想法 #3。TF-IDFVectorizer
我想要尝试的另一个构建特征的想法是 TF-IDFVectorizer。
Scikit-learn 开箱即用地支持它,它的作用是为文档中的每个词分配一个权重,该权重基于该词在文档中的频率除以该词在文档语料库中的频率。因此,如果一个词出现的频率很高,它的权重就会很低,这有助于过滤掉噪音。要使用所有文档构建 Vectorizer:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(max_df=0.5, sublinear_tf = True, stop_words='english')
vectorizer.fit(all_events)
然后将给定的文档集转换为它们的 TF-IDF 表示:
X_train = vectorizer.transform(rated_events)
现在,当我尝试将这个输入到分类器时,它花费了很长时间,而且结果也很糟糕。这实际上并不奇怪,因为在这种情况下,几乎每个词都是一个特征。所以我想找一种方法来选择表现最佳的特征。
Scikit-learn 提供了 SelectKBest 方法,你可以将一个评分函数和一个要选择的特征数量传递给它,它就会为你完成魔鬼般的转换。对于评分,我使用了 chi2(卡方检验),我不会具体告诉你原因。我只是凭经验发现它在我的案例中表现更好,并将“研究卡方背后的理论”放到了我的待办事项列表中。
from sklearn.feature_selection import SelectKBest, chi2
num_features = 100
ch2 = SelectKBest(chi2, k=num_features)
X_train = ch2.fit_transform(X_train, y_train).toarray()
就是这样。X_train 是我的训练集。
训练分类器
我不情愿地承认,在选择分类器方面并没有多少科学依据。我只是尝试了几种,然后选择了表现最好的。在我的例子中是 SVM。至于参数,我使用了 Grid Search 来选择最佳参数,所有这些 scikit-learn 都提供了开箱即用的功能。在代码中是这样的:
clf = svm.SVC()
params = dict(gamma=[0.001, 0.01,0.1, 0.2, 1, 10, 100],C=[1,10,100,1000], kernel=["linear", "rb"])
clf = grid_search.GridSearchCV(clf,param_grid=params,cv=5, scoring='f1')
我选择 f1-score 作为评分方法,仅仅因为它是我或多或少理解的一种。Grid Search 将尝试所有上述参数的组合,执行交叉验证,并找到表现最佳的参数。
我尝试将 LDA 主题建模的 X_train 和 TF-IDF + Chi2 都输入这个分类器。两者表现相似,但主观上 TF-IDF + Chi2 解决方案产生的预测更好。我对 v1 的结果相当满意,并将剩余的时间花在了修复网站的 UI 上。
你有什么有趣的发现吗?
我学到的其中一件事是,如果你正在构建一个推荐系统,并期望用户会一次性过来评价很多东西以便系统运行——那就错了。
我在朋友身上测试过这个网站,虽然对我来说评价过程看起来非常简单快捷,但让他们花几分钟点击“喜欢”按钮却很困难。虽然这还可以,因为我的主要目标是练习技能并为自己构建一个工具,但我认为如果我想让它变得更大,我需要弄清楚如何使评价过程更简单。
另一件事是,为了更有效率,我需要更深入地理解算法。当你了解你在做什么时,调整参数会更有趣。
你接下来想在项目上做什么?
我目前的主要问题是 UI。我想保持它的简洁,但我需要弄清楚如何使评价过程更有趣和更方便。事件浏览也可以做得更好。
完成这部分后,我正在考虑寻找新的事件来源:会议、音乐会等。也许我还会为此添加一个移动应用程序。
了解更多
- 项目:hapsradar.com
谢谢 Artem。
你有什么机器学习的副项目吗?
如果你有一个使用机器学习的副项目,并希望像 Artem 一样被专题报道,请联系我。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。






但我们可以获取数据来尝试代码吗?可以将代码下载到一个文件中吗?
太棒了!我发现这个想法太酷了。它启发了我开发自己的副项目!感谢分享这个故事,Jason!
很高兴听到这个消息。
嗨,Jason,
我一直在寻找关于使用深度学习/神经网络的推荐系统的想法。我没能在你的博客上找到。如果你能在博客上讨论一下那就太好了。
感谢您的建议。
嗨,Jason,
我想问一下,当提供的文档中包含训练时未见过的词语时,LDA 和 TFIDF 模型将如何表现?当然,未来会有包含新词的事件。当然,我们会定期重新训练模型,但我们也不能每晚都这样做。
谢谢!