在所有情况下,使用 Stable Diffusion 生成图片都涉及将提示提交给管道。这只是参数之一,但却是最重要的一个。不完整或构建不当的提示会导致生成的图像不符合您的预期。在本篇博文中,您将学习构建提示的关键技巧,并了解一个好的提示能在多大程度上创造出好的图像。
通过我的书 《用 Stable Diffusion 精通数字艺术》 来启动您的项目。它提供了自学教程和可运行的代码。
让我们开始吧。

Stable Diffusion 的提示技术
照片由 Sangga Rima Roman Selia 拍摄。部分权利保留。
概述
这篇文章分为三个部分;它们是
- 影响输出的参数
- 有效提示的特征
- 强调关键词
影响输出的参数
Stable Diffusion 中的输出受多个参数影响。模型对绘画风格有很大影响。采样器和步数对生成质量很重要。但提示指导着输出的内容。
基础 Stable Diffusion 模型是通用的,适用于多种用途。但有些模型是专门针对特定风格训练的。例如,“Anything”模型可以轻松生成日式动漫风格的图片,而“Realistic Vision”模型则能提供照片级逼真的输出。您可以从 Hugging Face Hub 或 Civitai(推荐)下载这些模型。
- Anything:https://civitai.com/models/9409,https://hugging-face.cn/stablediffusionapi/anything-v5
- Realistic Vision:https://civitai.com/models/4201,https://hugging-face.cn/SG161222/Realistic_Vision_V6.0_B1_noVAE
下载的模型应保存在 WebUI 安装目录下的 models/Stable-diffusion 文件夹中。下载模型时,除了模型本身的版本外,还要注意基础模型版本。最常见的有 SD 1.5 和 SDXL 1.0。使用不同的基础模型可能会导致与管道其他部分(包括提示的理解方式)的兼容性问题。
理论上,扩散模型需要数百步才能生成图像。但扩散模型实际上是一个可以用微分方程表示的数学模型;存在近似求解该方程的方法。采样器和步数控制着近似解的找到方式。总的来说,步数越多,结果越准确。然而,步数的效果取决于所选的采样器。粗略估计,大多数采样器使用 20 到 40 步可以达到质量和速度的最佳平衡。
提示会出于一个微不足道的原因影响输出。在每一步中,Stable Diffusion 中的 U-net 会使用提示来引导噪声细化为图像。不同的模型对提示的理解不同,就像人类对单词的理解带有不同的先入之见一样。然而,一个通用规则是,您应该以限制重新解释空间的方式编写提示。让我们通过一些例子来理解这一点。
有效提示的特征
提示应具体且明确地说明图片中需要包含的内容。手边有一份关键词列表可以使提示变得轻而易举。让我们来理解不同类别的关键词,然后看每个类别的示例。
主体或对象
提示的核心在于描述预期图像的细节。因此,首先想象它非常重要。让我们通过一个提示示例来理解这一点。
一位穿着巴塞罗那足球俱乐部球衣的年轻女子,在足球运动员和背景中的人群的欢呼下庆祝进球。
生成图像的各种设置如下所示
- 模型:Realistic Vision V6.0 B1 (VAE)
- 采样方法:DPM++ 2M Keras
- 采样步数:20
- CFG Scale:7
- 宽度 × 高度:512 × 512
- 负面提示:将在后续部分解释
- 批次大小和计数:1
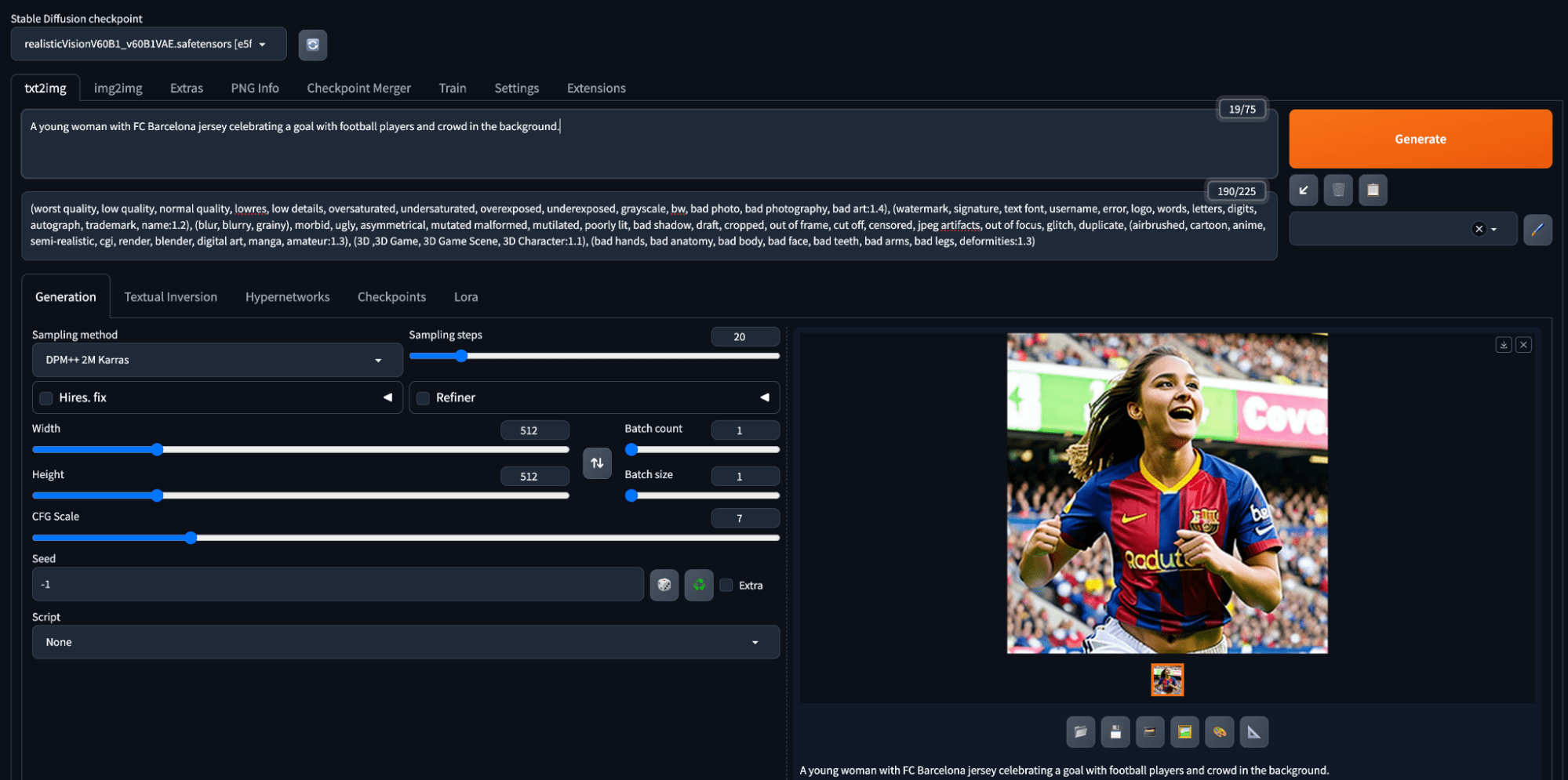
使用提示在 Stable Diffusion 中生成图像
第一次尝试,不算太差。

使用简单提示生成
让我们进一步优化。
注意:图像生成是一个随机过程。因此,您可能会看到截然不同的输出。实际上,除非您固定了随机种子,否则每次使用相同的提示和参数生成图像时都会有所不同。
媒介
图像是如何创建的?添加图像创建的媒介可以使提示更加具体。图像是照片、数字绘画、3D渲染还是油画,这称为媒介。
我们还可以为其添加形容词,例如
- 超写实照片
- 肖像数字绘画
- 概念艺术
- 水下油画
让我们在提示中添加一种媒介
一位穿着巴塞罗那足球俱乐部球衣的年轻女子,在足球运动员和背景中的人群的欢呼下庆祝进球的超写实摄影。
以下是结果。

包含摄影媒介的提示
差别不大,因为使用的模型默认假定为写实、类似照片的输出。如果使用了不同的模型,差异会更明显。
艺术风格
现代主义、印象派、波普艺术、超现实主义、新艺术风格、超写实主义等关键词为图像增添了艺术角度。让我们通过修改提示来理解这一点。
一位穿着巴塞罗那足球俱乐部球衣的年轻女子,在足球运动员和背景中的人群的欢呼下庆祝进球的波普艺术超写实肖像。
以下是结果

在提示中加入艺术风格生成的图像
受限于模型,使其保持照片般的风格,但波普艺术风格使输出使用了更多原色(红、黄、蓝),脸部颜色变化也更突兀。
著名艺术家姓名
添加艺术家姓名可以模仿艺术家的风格。可以提及多个艺术家姓名来结合他们的风格。让我们添加两位艺术家的名字:Stanley Artgerm Lau(一位超级英雄漫画艺术家)和 Agnes Martin(一位加拿大裔美国抽象画家)。您可以在此处找到艺术家姓名的良好参考。
一位穿着巴塞罗那足球俱乐部球衣的年轻女子,在足球运动员和背景中的人群的欢呼下庆祝进球的波普艺术超写实肖像,作者:Stanley Artgerm Lau 和 Agnes Martin。

在提示中添加了艺术家姓名
由于提供了多个艺术家姓名,输出可能富有创意。
网站
Artstation 和 Deviant Art 等网站拥有多种类型的图形。添加这些网站名称可以添加特定的风格。
让我们在提示中添加“artstation”。

通过为提示提供网站名称,可能会生成一些抽象背景。
分辨率
添加分辨率规格,如高度详细、HD、4K、8K、vray、unreal engine 或锐聚焦,有助于在图像中获得更多细节。让我们试试。
一位穿着巴塞罗那足球俱乐部球衣的年轻女子,在足球运动员和背景中的人群的欢呼下庆祝进球的波普艺术超写实肖像,作者:Stanley Artgerm Lau 和 Agnes Martin,artstation,4K,锐聚焦。

指定 4K 和锐聚焦将强调纹理细节
您可能会注意到,提示不一定是完整的句子。您也可以用逗号分隔关键词。嵌入引擎可以很好地理解它。
光照
添加光照关键词可以增强场景的外观和感觉。例如,包括边缘光、电影级光照、体积光、丁达尔效应、背光或昏暗的光线。因此,您可以将提示修改为
一位穿着巴塞罗那足球俱乐部球衣的年轻女子,在足球运动员和背景中的人群的欢呼下庆祝进球的波普艺术超写实肖像,作者:Stanley Artgerm Lau 和 Agnes Martin,artstation,4K,锐聚焦,边缘光。

包含“边缘光”的提示将增强轮廓
如果您不熟悉摄影,边缘光是指将灯光设置在主体后面,使主体的边缘被光线勾勒出来。
我们也可以使用 ControlNets 或 Regional Prompter 来获得更大的控制。
颜色
图像的整体色调可以通过任何颜色关键词来控制。
一位穿着巴塞罗那足球俱乐部球衣的年轻女子,在足球运动员和背景中的人群的欢呼下庆祝进球的波普艺术超写实肖像,作者:Stanley Artgerm Lau 和 Agnes Martin,artstation,4K,锐聚焦,边缘光,青色。

在提示中添加“青色”将使输出中出现更多此类颜色。
好的,我们现在可以在图像中看到一些青色了。但由于提示没有说“青色衬衫”或“青色染发”,您就留下了重新解释的空间,因此颜色可能会出现在任何地方。
使用负面提示
负面提示不是描述图片中应该有什么,而是描述图片中不应该有什么。这可以包括属性、对象或样式。我们可以使用如下所示的通用提示来完成所有图像生成任务。负面提示的好处在于您可以保留一个标准的负面提示模板,以便在许多任务中重复使用。但某些模型(如 SD 2.0 或 SD XL)对负面提示的依赖性较小。
(最差质量、低质量、正常质量、低分辨率、细节少、过饱和、低饱和、曝光过度、曝光不足、灰度、黑白、差照片、差摄影、差艺术:1.4), (水印、签名、文字字体、用户名、错误、徽标、文字、字母、数字、签名、商标、名称:1.2), (模糊、模糊、颗粒感), 病态、丑陋、不对称、变异畸形、残缺、光线差、阴影差、草稿、裁剪、画外、截断、审查、jpeg 伪影、失焦、故障、重复、(喷枪、卡通、动漫、半写实、CGI、渲染、Blender、数字艺术、漫画、业余:1.3), (3D、3D 游戏、3D 游戏场景、3D 角色:1.1), (手部糟糕、身体糟糕、面部糟糕、牙齿糟糕、手臂糟糕、腿部糟糕、畸形:1.3)
我们已经将此提示用于之前的生成。
强调关键词
我们可以让 stable diffusion 知道我们是否想在提示中强调某些关键词以及强调的程度。这可以通过以下方法实现
使用权重因子
我们可以使用 (keyword: factor) 语法来修改关键词的权重。factor 是数值。让我们在示例中试试。
一位穿着巴塞罗那足球俱乐部球衣的年轻女子的波普艺术超写实肖像,(庆祝: 2) 进球,有足球运动员和背景中的人群,作者:Stanley Artgerm Lau 和 Agnes Martin,artstation,4K,锐聚焦,边缘光,青色。

在提示中强调“庆祝”关键词
与之前的生成结果不符。也许模型对庆祝有不同的理解。这也是您需要尝试提示的原因之一。
添加强调的另一种方法是使用圆括号。它与使用 1.1 的因子效果相同。我们也可以使用双层或三层括号来获得更高的强调。
- (keyword) 等同于 (keyword: 1.1)
- ((keyword)) 等同于 (keyword: 1.21)
- (((keyword))) 等同于 (keyword: 1.33)
同样,使用多个方括号的效果是
- [keyword] 等同于 (keyword: 0.9)
- [[keyword]] 等同于 (keyword: 0.81)
- [[[keyword]]] 等同于 (keyword: 0.73)
关键词混合
顾名思义,关键词混合可以帮助一次性结合多个主题的效果。常见的关键词混合方式如下。
- [keyword1 : keyword2: factor]
- (keyword1: factor1), (keyword2: factor2)
让我们在提示中使用第二种格式。
一位年轻女子的波普艺术超写实肖像,(Gal Gadot: 0.9),(Scarlett Johansson: 1.1),穿着巴塞罗那足球俱乐部球衣,在足球运动员和背景中的人群的欢呼下庆祝进球,作者:Stanley Artgerm Lau 和 Agnes Martin,artstation,4K,锐聚焦,边缘光,青色。

通过提示控制面部外观
这是一个不错的混合。这是足球场上的漫威对 DC。然而,看起来模型在过程中完全忘记了庆祝、人群和球员。可以通过尝试以不同的方式创建提示或重新措辞来改进这一点。
最后,以下是将相同提示应用于 Anything XL v5.0 模型的效果。这是一个用于动漫或卡通风格的模型。差异应该非常明显

通过使用相同的提示但不同的模型获得的卡通风格
总而言之,在提示 stable diffusion 生成器方面有很多可以尝试的东西,熟能生巧。所以请继续练习!
进一步阅读
以下是一些可能有助于您进行提示的资源
总结
在本篇博文中,您学会了如何创建提示以使 Stable Diffusion 生成您喜欢的图片。您了解到关键在于提供图片的具体描述。您应该在提示中包含
- 主体:主要焦点看起来是什么样的。如果描述一个人,那么描述服装、动作和姿势将非常有帮助。
- 媒介和风格:例如,说明它是照片、素描还是水彩画
- 如果您希望它具有某种特定风格,可以加上一些艺术家的名字或网站
- 分辨率和光照:通过提供 4K 和锐聚焦可以获得更多细节。描述光照也会产生不同的效果。
- 其他细节:您可以向提示中添加更多描述性特征,包括主色调或角度
Stable Diffusion 提供的输出可能因许多其他参数(包括模型)而异。您需要进行实验才能找到最佳生成效果。
立即开始用 Stable Diffusion 精通数字艺术!

学习如何让 Stable Diffusion 为您服务
……通过学习图像生成过程中的一些关键要素
在我的新电子书中探索如何实现
使用 Stable Diffusion 精通数字艺术
这本书提供了自学教程,其中包含 Python 中的所有可运行代码,指导您从新手成长为图像生成专家。它教您如何设置 Stable Diffusion、微调模型、自动化工作流程、调整关键参数等等……所有这些都将帮助您创作令人惊叹的数字艺术。






暂无评论。