从开发者到机器学习实践者,只需14天
Python 是应用机器学习领域发展最快的平台之一。
在本迷你课程中,您将了解如何在14天内使用 Python 开始、构建准确的模型并自信地完成预测建模机器学习项目。
这是一篇内容丰富且重要的文章。您可能想把它加入书签。
使用我的新书《使用 Python 进行机器学习精通》**启动您的项目**,其中包括所有示例的**分步教程**和**Python 源代码文件**。
让我们开始吧。
- **2016年10月更新**:更新了 sklearn v0.18 的示例。
- **2018年2月更新**:更新了 Python 和库版本。
- **2018年3月更新**:添加了下载某些数据集的备用链接。
- **2019年5月更新**:修复了最新版 scikit-learn 的警告信息。
- **2020年10月更新**:更新了 Anaconda 的失效链接。

Python 机器学习迷你课程
图片由 Dave Young 拍摄,部分权利保留。
本迷你课程适合谁?
在开始之前,让我们确保您来对了地方。
以下列表提供了一些关于本课程设计对象的一般性指导。
如果您不完全符合这些要点,请不要惊慌,您可能只需要在某个领域稍作补充即可跟上。
- **懂一点代码的开发者**。这意味着一旦您掌握了基本语法,学习一门新的编程语言(如 Python)对您来说不是什么大问题。这并不意味着您是一位编程奇才,只是说您能毫不费力地遵循一门基本的类 C 语言。
- **懂一点机器学习的开发者**。这意味着您了解机器学习的基础知识,如交叉验证、一些算法和偏差-方差权衡。这并不意味着您是机器学习博士,只是说您知道一些基本概念或知道在哪里查找它们。
本迷你课程既不是 Python 教科书,也不是机器学习教科书。
它将帮助您从一个略懂机器学习的开发者,成长为一个能够使用 Python 生态系统(专业的机器学习平台)取得成果的开发者。
需要 Python 机器学习方面的帮助吗?
参加我为期 2 周的免费电子邮件课程,探索数据准备、算法等等(附带代码)。
立即点击注册,还将免费获得本课程的 PDF 电子书版本。
迷你课程概述
本迷你课程分为14节课。
您可以每天完成一节课(推荐),或者一天内完成所有课程(硬核!)。这取决于您可用的时间和您的热情程度。
以下是14节课程,将帮助您开始并高效地进行 Python 机器学习
- **第1课**:下载并安装 Python 和 SciPy 生态系统。
- **第2课**:熟悉 Python、NumPy、Matplotlib 和 Pandas。
- **第3课**:从 CSV 加载数据。
- **第4课**:使用描述性统计理解数据。
- **第5课**:使用可视化理解数据。
- **第6课**:通过数据预处理为建模做准备。
- **第7课**:使用重采样方法评估算法。
- **第8课**:算法评估指标。
- **第9课**:快速检查算法。
- **第10课**:模型比较和选择。
- **第11课**:通过算法调优提高准确性。
- **第12课**:通过集成预测提高准确性。
- **第13课**:最终确定并保存您的模型。
- **第14课**:Hello World 端到端项目。
每节课可能需要60秒到30分钟不等。请慢慢来,按照自己的节奏完成课程。在下面的评论中提问,甚至发布结果。
这些课程期望您自己去探索如何完成任务。我将为您提供提示,但每节课的重点之一是迫使您学习在哪里寻找 Python 平台上的帮助(提示:我的博客上直接有所有答案,请使用搜索功能)。
在早期的课程中,我确实提供了更多的帮助,因为我希望你建立一些信心和惯性。
坚持下去,不要放弃!
第1课:下载并安装 Python 和 SciPy
在获得 Python 平台之前,您无法开始进行机器学习。
今天的课程很简单,您必须在您的计算机上下载并安装 Python 3.6 平台。
访问 Python 主页,下载适用于您的操作系统(Linux、OS X 或 Windows)的 Python。将 Python 安装到您的计算机上。您可能需要使用平台特定的包管理器,例如 OS X 上的 macports 或 RedHat Linux 上的 yum。
您还需要安装 SciPy 平台和 scikit-learn 库。我建议使用与安装 Python 相同的方法。
您可以使用 Anaconda 一次性安装所有内容(简单得多)。推荐给初学者。
首次启动 Python,在命令行中输入“python”。
使用以下代码检查您将需要的所有版本
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# Python version import sys print('Python: {}'.format(sys.version)) # scipy import scipy print('scipy: {}'.format(scipy.__version__)) # numpy import numpy print('numpy: {}'.format(numpy.__version__)) # matplotlib import matplotlib print('matplotlib: {}'.format(matplotlib.__version__)) # pandas import pandas print('pandas: {}'.format(pandas.__version__)) # scikit-learn import sklearn print('sklearn: {}'.format(sklearn.__version__)) |
如果出现任何错误,请停止。现在是解决它们的时候了。
需要帮助?请参阅本教程。
第2课:熟悉 Python、NumPy、Matplotlib 和 Pandas。
您需要能够读写基本的 Python 脚本。
作为开发人员,您可以很快学会新的编程语言。Python 区分大小写,使用哈希符号 (#) 进行注释,并使用空白来指示代码块(空白很重要)。
今天的任务是在 Python 交互式环境中练习 Python 编程语言的基本语法和重要的 SciPy 数据结构。
- 练习在 Python 中使用列表和流控制。
- 练习使用 NumPy 数组。
- 练习在 Matplotlib 中创建简单的绘图。
- 练习使用 Pandas Series 和 DataFrame。
例如,下面是一个创建 Pandas **DataFrame** 的简单示例。
|
1 2 3 4 5 6 7 8 |
# 数据框 import numpy import pandas myarray = numpy.array([[1, 2, 3], [4, 5, 6]]) rownames = ['a', 'b'] colnames = ['one', 'two', 'three'] mydataframe = pandas.DataFrame(myarray, index=rownames, columns=colnames) print(mydataframe) |
第3课:从 CSV 加载数据
机器学习算法需要数据。您可以从 CSV 文件加载自己的数据,但当您开始使用 Python 进行机器学习时,您应该练习使用标准机器学习数据集。
您今天课程的任务是熟悉将数据加载到 Python 中,并查找和加载标准机器学习数据集。
在 UCI 机器学习存储库中有许多优秀的标准机器学习数据集(CSV 格式),您可以下载并练习。
- 练习使用标准库中的 CSV.reader() 将 CSV 文件加载到 Python 中。
- 练习使用 NumPy 和 numpy.loadtxt() 函数加载 CSV 文件。
- 练习使用 Pandas 和 pandas.read_csv() 函数加载 CSV 文件。
为了帮助您入门,下面是一个代码片段,它将使用 Pandas 直接从 UCI 机器学习存储库加载 Pima Indians 糖尿病数据集。
|
1 2 3 4 5 6 |
# 使用 Pandas 从 URL 加载 CSV import pandas url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) print(data.shape) |
能坚持到这里,做得很好!继续努力。
到目前为止有什么问题吗?在评论中提问。
第4课:使用描述性统计理解数据
将数据加载到 Python 后,您需要能够理解它。
您越能理解您的数据,您就能构建越好、越准确的模型。理解数据的第一步是使用描述性统计。
今天您的课程是学习如何使用描述性统计来理解您的数据。我建议使用 Pandas DataFrame 提供的辅助函数。
- 使用 **head()** 函数查看前几行来理解您的数据。
- 使用 **shape** 属性检查数据的维度。
- 使用 **dtypes** 属性查看每个属性的数据类型。
- 使用 **describe()** 函数查看数据的分布。
- 使用 **corr()** 函数计算变量之间的成对相关性。
下面的示例加载 Pima Indians 糖尿病数据集并汇总了每个属性的分布。
|
1 2 3 4 5 6 7 |
# 统计摘要 import pandas url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) description = data.describe() print(description) |
试试看!
第5课:使用可视化理解数据
继续昨天的课程,您必须花时间更好地理解您的数据。
第二种提高您对数据理解的方法是使用数据可视化技术(例如绘图)。
今天,您的课程是学习如何在 Python 中使用绘图来理解单个属性及其交互。同样,我建议使用 Pandas DataFrame 提供的辅助函数。
- 使用 **hist()** 函数为每个属性创建直方图。
- 使用 **plot(kind='box')** 函数为每个属性创建箱线图。
- 使用 **pandas.scatter_matrix()** 函数创建所有属性的成对散点图。
例如,下面的代码片段将加载糖尿病数据集并创建数据集的散点图矩阵。
|
1 2 3 4 5 6 7 8 9 |
# 散点图矩阵 import matplotlib.pyplot as plt import pandas from pandas.plotting import scatter_matrix url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pandas.read_csv(url, names=names) scatter_matrix(data) plt.show() |
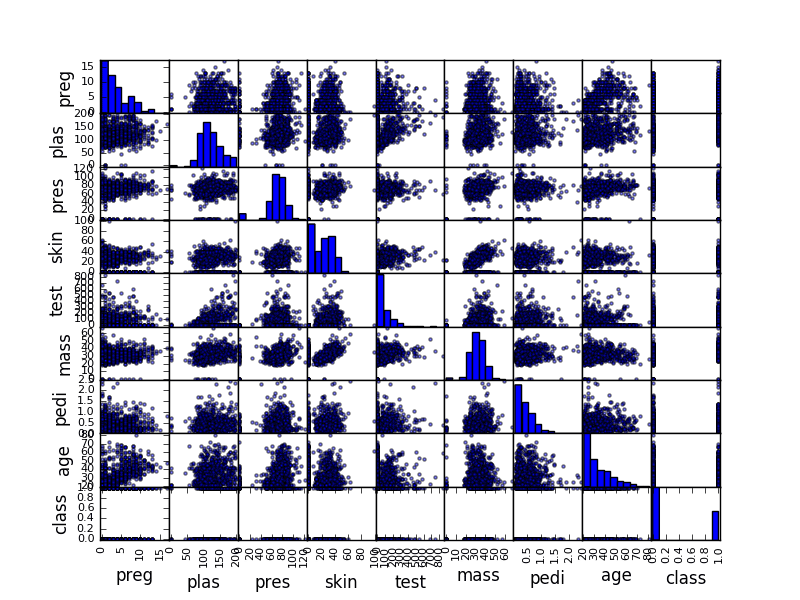
散点图矩阵示例
第6课:通过数据预处理为建模做准备
您的原始数据可能没有以最佳形式设置以进行建模。
有时您需要预处理您的数据,以便最好地将问题固有的结构呈现在数据中,供建模算法使用。在今天的课程中,您将使用 scikit-learn 提供的预处理功能。
scikit-learn 库提供了两种标准的数据转换范例。每种转换在不同情况下都很有用:拟合和多重转换以及组合拟合-转换。
您可以使用许多技术来为建模准备数据。例如,尝试以下一些方法:
- 使用 scale 和 center 选项标准化数值数据(例如,均值为0,标准差为1)。
- 使用 range 选项归一化数值数据(例如,到 0-1 的范围)。
- 探索更高级的特征工程,例如二值化。
例如,下面的代码片段加载 Pima Indians 糖尿病数据集,计算标准化数据所需的参数,然后创建输入数据的标准化副本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 标准化数据(均值为0,标准差为1) from sklearn.preprocessing import StandardScaler import pandas import numpy url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = pandas.read_csv(url, names=names) array = dataframe.values # 将数组分离为输入和输出组件 X = array[:,0:8] Y = array[:,8] scaler = StandardScaler().fit(X) rescaledX = scaler.transform(X) # 汇总转换后的数据 numpy.set_printoptions(precision=3) print(rescaledX[0:5,:]) |
第7课:使用重采样方法评估算法
用于训练机器学习算法的数据集称为训练数据集。用于训练算法的数据集不能用于可靠地估计模型在新数据上的准确性。这是一个大问题,因为创建模型的全部目的是在新数据上进行预测。
您可以使用称为重采样方法的统计方法将您的训练数据集分成子集,其中一些用于训练模型,另一些则保留下来用于估计模型在未见数据上的准确性。
您今天课程的目标是练习使用 scikit-learn 中可用的不同重采样方法,例如
- 将数据集拆分为训练集和测试集。
- 使用 k 折交叉验证估计算法的准确性。
- 使用留一法交叉验证估计算法的准确性。
下面的代码片段使用 scikit-learn 通过10折交叉验证估计 Logistic Regression 算法在 Pima Indians 糖尿病数据集上的准确性。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 使用交叉验证进行评估 from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(url, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] kfold = KFold(n_splits=10, random_state=7, shuffle=True) model = LogisticRegression(solver='liblinear') results = cross_val_score(model, X, Y, cv=kfold) print("Accuracy: %.3f%% (%.3f%%)" % (results.mean()*100.0, results.std()*100.0)) |
您获得了多少准确率?请在评论中告诉我。
您是否意识到这已经是中点了吗?做得很好!
第8课:算法评估指标
有许多不同的指标可用于评估机器学习算法在数据集上的性能。
您可以通过 scikit-learn 中的 **cross_validation.cross_val_score()** 函数指定用于测试工具的指标,并且可以使用回归和分类问题的默认值。您今天课程的目标是练习使用 scikit-learn 包中可用的不同算法性能指标。
- 练习在分类问题上使用准确率和 LogLoss 指标。
- 练习生成混淆矩阵和分类报告。
- 练习在回归问题上使用 RMSE 和 RSquared 指标。
下面的代码片段演示了在 Pima Indians 糖尿病数据集上计算 LogLoss 指标。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 交叉验证分类 LogLoss from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(url, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] kfold = KFold(n_splits=10, random_state=7) model = LogisticRegression(solver='liblinear') scoring = 'neg_log_loss' results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring) print("Logloss: %.3f (%.3f)") % (results.mean(), results.std()) |
您获得了多少 LogLoss?请在评论中告诉我。
第9课:快速检查算法
您不可能事先知道哪种算法在您的数据上表现最好。
您必须通过试错过程来发现它。我称之为快速检查算法。scikit-learn 库提供了许多机器学习算法的接口和比较这些算法估计准确性的工具。
在本课程中,您必须练习快速检查不同的机器学习算法。
- 在数据集上快速检查线性算法(例如,线性回归、逻辑回归和线性判别分析)。
- 在数据集上快速检查一些非线性算法(例如,KNN、SVM 和 CART)。
- 在数据集上快速检查一些复杂的集成算法(例如,随机森林和随机梯度提升)。
例如,下面的代码片段在波士顿房价数据集上快速检查 K-近邻算法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# KNN 回归 from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.neighbors import KNeighborsRegressor url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.data" names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV'] dataframe = read_csv(url, delim_whitespace=True, names=names) array = dataframe.values X = array[:,0:13] Y = array[:,13] kfold = KFold(n_splits=10, random_state=7) model = KNeighborsRegressor() scoring = 'neg_mean_squared_error' results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring) print(results.mean()) |
您获得了多少均方误差?请在评论中告诉我。
第10课:模型比较和选择
既然您已经知道如何在数据集上快速检查机器学习算法,那么您需要知道如何比较不同算法的估计性能并选择最佳模型。
在今天的课程中,您将练习使用 scikit-learn 在 Python 中比较机器学习算法的准确性。
- 在数据集上比较线性算法。
- 在数据集上比较非线性算法。
- 比较相同算法的不同配置。
- 创建比较算法结果的图表。
下面的示例在 Pima Indians 糖尿病数据集上比较了逻辑回归和线性判别分析。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# 比较算法 from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # 加载数据集 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(url, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] # 准备模型 models = [] models.append(('LR', LogisticRegression(solver='liblinear'))) models.append(('LDA', LinearDiscriminantAnalysis())) # 依次评估每个模型 results = [] names = [] scoring = 'accuracy' for name, model in models: kfold = KFold(n_splits=10, random_state=7) cv_results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring) results.append(cv_results) names.append(name) msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std()) print(msg) |
哪个算法获得了更好的结果?您能做得更好吗?请在评论中告诉我。
第11课:通过算法调优提高准确性
一旦您找到了一到两种在您的数据集上表现良好的算法,您可能希望提高这些模型的性能。
提高算法性能的一种方法是根据您的特定数据集调整其参数。
scikit-learn 库提供了两种搜索机器学习算法参数组合的方法。您今天课程的目标是分别练习这两种方法。
- 使用您指定的网格搜索调整算法的参数。
- 使用随机搜索调整算法的参数。
下面的代码片段是使用网格搜索对 Pima Indians 糖尿病数据集上的 Ridge 回归算法进行调优的示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 算法调优的网格搜索 from pandas import read_csv import numpy from sklearn.linear_model import Ridge from sklearn.model_selection import GridSearchCV url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(url, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] alphas = numpy.array([1,0.1,0.01,0.001,0.0001,0]) param_grid = dict(alpha=alphas) model = Ridge() grid = GridSearchCV(estimator=model, param_grid=param_grid, cv=3) grid.fit(X, Y) print(grid.best_score_) print(grid.best_estimator_.alpha) |
哪些参数取得了最佳结果?您能做得更好吗?请在评论中告诉我。
第12课:通过集成预测提高准确性
提高模型性能的另一种方法是结合多个模型的预测。
一些模型内置了此功能,例如用于 Bagging 的随机森林和用于 Boosting 的随机梯度提升。另一种称为投票的集成方法可用于将多个不同模型的预测结合起来。
在今天的课程中,您将练习使用集成方法。
- 使用随机森林和极端随机树算法练习 Bagging 集成。
- 使用梯度提升机(Gradient Boosting Machine)和AdaBoost算法练习提升集成(Boosting Ensembles)。
- 通过组合来自多个模型的预测来实践投票集成(Voting Ensembles)。
下面的代码片段演示了如何在Pima印第安人糖尿病发病数据集上使用随机森林算法(一种决策树的bagging集成)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 随机森林分类 from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.ensemble import RandomForestClassifier url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(url, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] num_trees = 100 max_features = 3 kfold = KFold(n_splits=10, random_state=7) model = RandomForestClassifier(n_estimators=num_trees, max_features=max_features) results = cross_val_score(model, X, Y, cv=kfold) print(results.mean()) |
你能想出一个更好的集成方法吗?请在评论中告诉我。
第13课:最终确定并保存你的模型
一旦你在你的机器学习问题上找到了一个表现良好的模型,你就需要对其进行最终确定。
在今天的课程中,你将练习与最终确定模型相关的任务。
练习使用你的模型在新数据(训练和测试期间未见过的数据)上进行预测。
练习将训练好的模型保存到文件并再次加载它们。
例如,下面的代码片段展示了如何创建一个逻辑回归模型,将其保存到文件,然后稍后加载并对未见过的数据进行预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# 使用Pickle保存模型 from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression import pickle url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv" names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(url, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] test_size = 0.33 seed = 7 X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=test_size, random_state=seed) # 在67%的数据上拟合模型 model = LogisticRegression(solver='liblinear') model.fit(X_train, Y_train) # 将模型保存到磁盘 filename = 'finalized_model.sav' pickle.dump(model, open(filename, 'wb')) # 一段时间后... # 从磁盘加载模型 loaded_model = pickle.load(open(filename, 'rb')) result = loaded_model.score(X_test, Y_test) print(result) |
第14课:端到端项目“Hello World”
你现在已经知道如何完成预测建模机器学习问题中的每个任务。
在今天的课程中,你需要练习将这些部分组合起来,并从头到尾完成一个标准的机器学习数据集。
从头到尾完成Iris数据集(机器学习的“Hello World”)。
这包括以下步骤:
- 使用描述性统计和可视化理解你的数据。
- 预处理数据以最好地揭示问题的结构。
- 使用你自己的测试工具对一些算法进行初步检查。
- 通过算法参数调优改进结果。
- 使用集成方法改进结果。
- 最终确定模型,以便将来使用。
慢慢来,并记录你沿途的结果。
你使用了什么模型?你得到了什么结果?请在评论中告诉我。
结束!
(看看您取得了多大的进步)
您做到了。干得好!
花点时间回顾一下您已经走了多远。
- 你一开始对机器学习感兴趣,并强烈渴望能够使用Python实践和应用机器学习。
- 你下载、安装并启动了Python,也许是第一次,并开始熟悉该语言的语法。
- 在一些课程中,你缓慢而稳步地学习了预测建模机器学习项目的标准任务如何映射到Python平台。
- 在常见机器学习任务的“食谱”基础上,你使用Python从头到尾解决了你的第一个机器学习问题。
- 利用标准模板、你收集的“食谱”和经验,你现在能够独立解决新的、不同的预测建模机器学习问题。
不要轻视这一点,您在短时间内取得了长足的进步。
这只是你Python机器学习之旅的开始。继续练习和发展你的技能。
总结
您对这个迷你课程感觉如何?
您喜欢这个迷你课程吗?
您有任何问题吗?有没有遇到什么难点?
告诉我。在下面留言。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。






准确率:76.951% (4.841%)
干得好!
请在第8课中解释LogLoss到底是什么?
你可以在这里了解更多
https://en.wikipedia.org/wiki/Loss_functions_for_classification
这份关于损失函数的维基百科材料对于没有数学背景的人来说太复杂了。有没有为小白准备的材料?
是的,这个可能会有帮助
https://machinelearning.org.cn/loss-and-loss-functions-for-training-deep-learning-neural-networks/
嗨,Jason!
非常感谢这些课程。它们让我很快入门了Python。我目前正在学习第7课。我尝试了LeaveOneOut重采样方法,得到了:准确率:76.823% (42.196%)。
我有一个问题:我们如何判断一个模型比其他模型更好:似乎准确率不够,我们还应该考虑交叉验证中的较低方差,不是吗?
谢谢!
Sarra
很好的问题。
一个好的模型是相对于问题上基线模型的技能而言的,比如Zero Rule算法。
你好 Jason,
继续努力!你的课程非常有帮助!!
只是为了检查,我正在学习第9课,想知道我的结果是否正确
最近邻 – 负均方误差:-107.287
支持向量机 – 负均方误差:-91.048
决策树 – 负均方误差:-40.102
线性回归 – 负均方误差:-34.705
逻辑回归 – 负均方误差:-40.419
随机森林 – 负均方误差:-22.546
随机梯度提升 – 负均方误差:-18.711
此外,我在LDA上有一些问题(错误:未知标签类型)。我读到它是一个分类器,但由于我们的输出变量不是一个类别,我们不能在波士顿房价数据集的情况下使用LDA,对吗?
谢谢!
干得不错。
LDA不能用于回归,它是一个分类算法。
嗨,Jason,
首先,感谢您的快速回复!随着我学习到后面的课程,我总是有这样一个问题:如果我们在cross_val_score中不指定“scoring”的值会发生什么?文档说默认值是“None”,但是如果没有指定评分,我们如何解释results.mean()的值呢?
谢谢!
Sarra
好问题,我不知道默认行为。对于分类/回归,它可能是准确率/MSE,但这只是猜测。我建议指定一些东西。
嗨,Jason,
第12课:max_feature代表什么?你为什么在示例中选择3?
model = RandomForestClassifier(n_estimators=num_trees, max_features=max_features)
谢谢!
Sarra
嗨 Sarra,我在示例中任意选择了3个特征。
准确率:76.951% (4.841%)
在第7课中,这个对我有效
accu = (“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0)
print(accu)
谢谢。我遇到了同样的问题。
Dominique
第7课:准确率:77.086% (5.091%)
第8课:对数损失:-0.494 (0.042)
第9课:平均值:-38.85
你好 Jason。感谢你所做的一切。我在运行Python 35和sklearn VERSION 0.18时,在“第7课:使用重采样方法进行算法评估”中遇到了以下挑战。
c:\python35\lib\site-packages\sklearn\cross_validation.py:44: DeprecationWarning: 此模块在版本0.18中已弃用,取而代之的是model_selection模块,所有重构的类和函数都已移入其中。另请注意,新CV迭代器的接口与此模块不同。此模块将在0.20中删除。
“此模块将在0.20中删除。”,DeprecationWarning)
还有
TypeError Traceback (most recent call last)
in ()
51 done results = cross_val_score
52 “””
—> 53 print(“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0)
TypeError: 不支持的操作数类型:%的操作数不能为“NoneType”和“tuple”
上述回复的延续
Jason,我认为你的print语句
print(“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0)
应该像这样
print(“Accuracy: %.3f (%.3f)” % (results.mean()*100.0, results.std()*100.0))
再次感谢您的精彩信息。
爱与和平,
Joe
很高兴听到你解决了。也许这是Python 3的问题?代码在Python 2.7中运行正常
我将尽快查看弃用警告。
谢谢回复,Jason。
爱与和平,
Joe
在Python 3上对我不起作用
print(“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0))
多了一个“)”,我删掉了它
print(“Accuracy: %.3f%% (%.3f%%)” % (results.mean()*100.0, results.std()*100.0))
谢谢!已修复。
嗨,Jason,
这是我为逻辑回归模型计算的对数损失==‘neg_log_loss’得分
模型:逻辑回归 – 评分:neg_lo_loss
– 结果摘要:-49.255 平均值 (4.705) 标准差
– sorted(results)
[-0.57565879615204196, -0.52778706048371593, -0.52755866512803806, -0.51792016214361636, -0.5127963295718494, -0.49019538734940965, -0.47043507959473152, -0.4514763172464305, -0.44345852864232038, -0.40816890220694385]
感谢您的出色工作。我完成这个后会参加您的电子邮件课程。
爱与和平,
Joe
谢谢 Joe,干得好。
亲爱的 Jason,
关于“第9课:初步检查算法”,我想知道如何将数据准备用于各种(数据集、模型(算法)、评分)组合,以及哪些(数据集、模型(算法)、评分)组合是完全不兼容的?
我在我的博客上发表了一篇题为“AI算法的初步检查”的文章,其中引用了您的工作。该文章使用(3个数据集 x 4个模型(算法) x 3个评分)生成了36个初步检查案例。其中有11个案例返回了数值结果。其他25个案例返回了错误或警告。
再次,我想知道如何将数据准备用于各种(数据集、模型(算法)、评分)组合,以及哪些(数据集、模型(算法)、评分)组合是完全不兼容的?
感谢您的出色工作。
爱与和平,
Joe
这是我的文章“AI算法的初步检查”的链接,
https://joecodeswell.wordpress.com/2016/10/28/naive-spot-check-of-ai-algorithms/
再次感谢,Jason。
爱与和平,
Joe
好文章,好问题 Joe。
初步检查是为了发现哪些算法在一个给定数据集上表现良好。而不是跨数据集。
你可能需要根据算法的期望对它们进行分组,然后为每个组准备数据。
大多数机器学习算法期望数据具有数值输入值,以及分类的整数编码或独热编码输出值。这是一个很好的规范化数据集视图。
这里有一个教程,展示了如何用Python在一个问题上初步检查7种机器学习算法
https://machinelearning.org.cn/spot-check-regression-machine-learning-algorithms-python-scikit-learn/
嗨 Jason,感谢您的帖子。我在执行第7课时遇到了问题
from sklearn.model_selection import KFold
回溯(最近一次调用)
File “”, line 1, in
from sklearn.model_selection import KFold
ImportError: 没有名为“sklearn.model_selection”的模块
我还更新了我的Spyder版本,根据一些在线帖子,这应该能解决问题,但问题依然存在。请帮忙!谢谢!
嗨 Sooraj,你必须将scikit-learn更新到v0.18或更高版本。
谢谢 Jason!我照做了,它奏效了。我实际上使用的是Anaconda,这样我就不必单独安装软件包,但由于它使用的是最新的Python (3.5.2),而您使用的是以前的版本,所以运行起来不那么顺畅。
这次我遇到了一个不支持的操作数的问题 (TypeError: unsupported operand type(s) for %: ‘NoneType’ and ‘tuple’),试图打印准确率结果,类似于Joe Dorocak,但他的解决方案对我不起作用。我会再研究一下,希望我能找到一个修复方法。
尽管如此,我得到了以下未格式化的准确率
(76.951469583048521, 4.8410519245671946)
解决方案
print语句需要将格式和值都包含在自身中
print(“Accuracy: %.3f%% (%.3f%%)” %(results.mean()*100.0, results.std()*100.0))
准确率:76.951% (4.841%)
很高兴听到你解决了,Sooraj。
附言:您回复时我没有收到任何电子邮件。难道不应该有一个选择加入的选项吗?我记得我的博客有这个选项。
准确率:76.951% (4.841%)
‘neg_mean_squared_error’: -107.28683898
#算法比较
LR: 0.769515 (0.048411)
LDA: 0.773462 (0.051592)
请问这行代码具体是做什么的
KFold(n_splits=10, random_state=7)?
这配置了10折交叉验证。
好的,我假设random_state=7从整个数据的70%创建训练数据。
不,Ignatius,它只是为随机数生成器设置种子,这样我们每次运行代码都能得到相同的结果。
在这里了解更多关于机器学习中的随机性
https://machinelearning.org.cn/randomness-in-machine-learning/
还有这一行
cv_results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)?
这行代码使用10折交叉验证评估模型并返回一个分数列表。
现在完成了。非常有趣,而且语言通俗易懂。谢谢 Jason。我渴望更多。
嗨,Jason,
我似乎无法访问您的数据样本
https://goo.gl/vhm1eU
无法访问https://archive.ics.uci.edu/上的任何内容。
数据是否也在其他地方托管?
你好 Tobias,
抱歉,托管数据集的UCI机器学习仓库目前似乎已关闭。
这里有包含所有数据集的网站备份
http://mlr.cs.umass.edu/ml/
谢谢 Jason 的迷你课程——这是一个很好的入门!
我完成了端到端项目,并选择了QDA作为我的算法,准确率结果如下。
QDA:0.973333 (0.032660)
我测试了许多验证指标和算法,发现QDA始终是表现最好的,LDA通常紧随其后。
再次感谢——这让我大开眼界,原来我还有这么多东西要学!
祝好
marco
干得好 marco,很高兴听到QDA(它过去对我也很有效)。
感谢您的课程,布朗利先生。
我有一个通过您的课程完成的工作示例
https://www.kaggle.com/mohamedl/d/uciml/pima-indians-diabetes-database/79-17-pima-indians-diabetes-log-regression
再次感谢您分享您的知识。
干得好,Mohamed。
我得到了以下准确率
Logreg的准确率:76.69685577580314 (3.542589693856446)
KNeighbors的准确率:74.7470950102529 (5.575841908065769)
DSG干得好。
results={}
for name,model in models
results[name] = cross_val_score(model, X, Y, cv = 10, scoring=’accuracy’)
print(‘{} score:{}’.format(name, results[name].mean()))
logreg score:0.7669685577580314
lda score:0.7734962406015038
嘿,这是对这个主题非常好的介绍。
关于第7课……我在导入KFold时出现错误
ImportError: 无法导入名称stable_cumsum
希望您能帮我解决这个问题
您可能需要确认已安装 sklearn 0.18 或更高版本。
尝试运行此脚本
你好,Jason!。
Python 3 在机器学习环境中表现如何?
Python 2.7 永远是最好的选择吗?
谢谢!
根据我的经验,Python 3 运行良好。
Jason 的帖子太棒了。请继续发布更多高质量的教程。
谢谢你,Madhav。
嗨,Jason,
首先,非常好的网站和教程,干得漂亮!
其次,你为什么要将标签保留在 X 中??
第三,我正在实现自己的评分函数,以便同时计算多个评分指标。除了对数损失之外,它对所有指标都有效。我获得了很高的值(大约 7.8)。这是代码
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import log_loss
url = “https://goo.gl/vhm1eU”
names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
dataframe = read_csv(url, names=names)
array = dataframe.values
X = array[:,0:7]
Y = array[:,8]
kfold = KFold(n_splits=10, random_state=7)
model = LogisticRegression()
def my_scorer(estimator, x, y)
yPred = estimator.predict(x)
return log_loss(y, yPred)
results = cross_val_score(model, X, Y, cv=kfold, scoring=my_scorer)
print results.mean()
有什么解释吗?
谢谢你!!
祝好
准确率:76.432% (2.859%)
干得好,Pratyush!
对数损失:-49.266 误差:4.689
第9课
-107.28683898
你好 Jason,我已经看完了这篇帖子中的大部分课程,我必须感谢你。我想深入研究机器学习已经有一段时间了,你的博客从现在开始一定会对我有帮助。
我的结果是
第7课:准确率:77.996% (5.009%)
第8课:对数损失:-0.484 (0.061)
第9课:均方误差 = -28.5854635294
我所有的分析都使用了重新缩放和标准化的矩阵 X。
我的问题是:我怎么知道重新缩放是否真的有效?这是否由上下文决定?我猜你的代码是使用尽可能原始和未处理的数据计算统计数据的……
我应该何时预处理数据?
哇!!这么多问题!!。
再次感谢
做得很好。
决定使用什么/如何准备数据的重要筛选条件是模型技能。你根据模型在新数据上做出预测的技能,来决定整套程序。
请看这篇文章
https://machinelearning.org.cn/a-data-driven-approach-to-machine-learning/
请尽管提问。我在这里提供帮助。
嗨,Jason!
很棒的课程!对于我这个刚接触机器学习但懂编码的人来说,这课程简直是量身定制。
我有一个小问题。我正在研究 Iris 数据集,并按照你演示的方式(results = cross_val_score(model, rescaledX, Y, cv=kfold))对不同的算法进行抽样检查,我正在检查的算法之一是 Ridge 算法。
查看它返回的分数
Ridge Results: [ 0. 0. 0. 0.753 0. 0. 0.848 0. 0. 0. ],它有时表现不错,然后有时又得到 0。为什么测试结果的准确性变化如此之大?
很高兴听到这个消息,Alex。
岭回归通常不用于分类。
明白了,谢谢!
嗨,Jason,
在“第7课:使用重采样方法进行算法评估”中,下面的行似乎有错误?
print(“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0)
应该是——
print(“Accuracy: %.3f%% (%.3f%%)” % (results.mean()*100.0, results.std()*100.0))
此致,
AA
可能是 Python 2 与 Python 3 的问题。
嗨,Jason,
第8课也有同样的问题——
错误 –
对数损失:%.3f (%.3f)
回溯(最近一次调用)
File “./classification_logloss.py”, line 16, in
print(“Logloss: %.3f (%.3f)”) % (results.mean(), results.std())
TypeError: 不支持的操作数类型:%的操作数不能为“NoneType”和“tuple”
请改为 –
print(“Logloss: %.3f (%.3f)” % (results.mean(), results.std()))
此致,
AA
你好 Jason,非常棒的网站,非常感谢你组织了这门课程。
对于第7课,我使用Kfold得到了76.951%(4.841%),虽然我知道这是76%的准确率,但我不知道第二个数字是什么?
至于留一法,我得到76.823%(42.196%),42%看起来很奇怪
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
model = LogisticRegression()
results = cross_val_score(model, X, Y, cv=loo)
print’\n使用留一交叉验证的LR准确率?’
print(“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0)
我觉得我在使用LeaveOneOut处理拆分时漏掉了一个步骤,但我尝试了一些从网上找到的方法,都没有成功。
括号中的数字是模型技能的标准差——例如,每次模型在不同数据上运行时,技能与平均技能之间的方差有多大。
对于第7课
准确率:77.475% (5.206%)
但我用了
KFold(n_splits=9, random_state=7)
干得好,Steven。
我有个问题
如果我使用交叉验证,我怎么知道它是否过拟合?
很好的问题!
您可以选择您选择的模型,将您的训练数据集分成训练/验证集,并评估模型在这两个集上的技能。理想情况下,可以绘制方法学习随时间/迭代的诊断图。
嗨,Jason,
我还发现,对于KFold,如果我使用'n_split = 9',我可以获得比其他值(如'n_split = 10'或'n_split = 8')更好的准确性,而无需进行其他优化。(我的意思是,我只更改了参数'n_split'的值。)
那么,问题来了:我如何在K-Fold交叉验证期间保存找到的准确率最高的模型?(这意味着我想保存“n_split = 9”时找到的模型,以便将来用于生产)
因为根据我的理解,交叉验证包含两个功能:训练模型和评估模型。
诚挚地,
Steven
我不建议那样做。
交叉验证是一种评估方案,用于估算模型在未见过的数据上的表现。不同的折叠次数会给出不同且具有不同偏差的分数。
对于普通的机器学习模型(例如,非深度学习),我建议重新拟合一个最终模型。在此处了解更多信息
https://machinelearning.org.cn/train-final-machine-learning-model/
这有帮助吗?
如果“交叉验证是一种估计模型在未见数据上表现的评估方案”,那么我们应该使用在训练期间未接触过的数据集进行交叉验证吗?
诚挚地,
Steven
不完全是,CV 会作为过程的一部分,将您的训练数据分成训练/验证集。
您可以将原始数据集分成训练/测试集,并将测试集保留下来,用于评估您选择的最终模型。
这篇帖子可能会让事情更清楚
https://machinelearning.org.cn/difference-test-validation-datasets/
准确率:76.951% (4.841%)
太棒了!
LR: 0.769515 (0.048411)
LDA: 0.773462 (0.051592)
LDA 最佳
交叉验证结果平均值为0.775974025974
干得不错。
嗨,Jason博士
你能解释一下这行吗?
model = RandomForestClassifier(n_estimators=num_trees, max_features=max_features)
它拟合了一个随机森林分类器,并将结果存储在模型变量中。
嗨,Jason,
很棒的网站,很棒的入门方式。很享受学习迷你课程!
我对第9课有一个问题
KNN 按照你的例子编码,我的 kfold 参数的准确率是 -88
我可以使用逻辑回归和准确率评分吗?当我尝试在第9课中使用逻辑回归模型处理波士顿房价数据样本时,我得到了一堆错误——ValueError: Unknown label type: ‘continuous’
逻辑回归用于分类问题(预测标签),而波士顿房价问题是回归问题(预测数量)。
您不能将分类算法用于回归问题。
啊!明白了。谢谢!
嗨,Jason,
另一个问题——关于第11课
我尝试使用随机搜索来调整参数。因此,我从 GridSearchCV 切换到 RandomizedSearchCV,但在设置模型(尝试使用 GridSearchCV 示例中的 Ridge)以及尝试调整 RandomizedSearchCV 参数的分布参数时遇到了困难。
我应该如何设置 RandomizedSearchCV 的模型和 param_grid?
任何指点都将不胜感激。
谢谢!
通常,您必须指定一个函数来为参数生成随机值。
我在这里给出了一个例子
https://machinelearning.org.cn/how-to-tune-algorithm-parameters-with-scikit-learn/
你好 Jason,干得漂亮。我对第 6 课及以后的课程感到困惑。在第 6 课中,您创建了一个预处理数据集
rescaledX = scaler.transform(X)。
然而,我没有看到它在后续章节中使用。如果您能帮助我理解我遗漏了什么,我将不胜感激。谢谢
拉吉夫
当您的数据由具有不同测量单位或不同尺度观测值组成时,缩放数据在某些算法中很重要。
这对我帮助巨大!目前,所有算法在 scikit-learn 等机器学习包中都随时可用。构建和运行分类器以获取结果变得极其容易。
但要知道这些结果是否合法和有意义,并拥有理解问题的扎实方法,才是真正的知识所在。我想我现在在这方面有所进步了。谢谢 Jason。
我尝试在 Iris 数据集上使用这种方法,你可以在这里找到代码:https://www.kaggle.com/gautham11/building-a-scikit-learn-classification-pipeline
我发现带有 StandardScaler 和 LabelEncoder 的 SVC() 得到了最好的结果。
训练数据集的准确率:97.78%
测试数据集的准确率:95%
我很乐意讨论改进此方法的方法。
做得好,谢谢分享!
你好,Jason 博士。
在第3课中,我无法从url https://goo.gl/vhm1eU获取数据。但是我可以通过在chrome中输入url成功获取数据。在chrome控制台中,我发现此url是一个短链接,它重定向到 https://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data。
我使用实际的 URL,它起作用了!但我不知道为什么使用短链接时它不起作用。
我的 Python 版本是 3.6.3。
回溯是
回溯(最近一次调用)
文件“C:\Users\lidajun\AppData\Local\Programs\Python\Python36\lib\urllib\request.py”,第1318行,在do_open中
encode_chunked=req.has_header(‘Transfer-encoding’))
文件“C:\Users\lidajun\AppData\Local\Programs\Python\Python36\lib\http\client.py”,第1239行,在请求中
self._send_request(method, url, body, headers, encode_chunked)
文件“C:\Users\lidajun\AppData\Local\Programs\Python\Python36\lib\http\client.py”,第1285行,在_send_request中
self.endheaders(body, encode_chunked=encode_chunked)
文件“C:\Users\lidajun\AppData\Local\Programs\Python\Python36\lib\http\client.py”,第1234行,在endheaders中
self._send_output(message_body, encode_chunked=encode_chunked)
文件“C:\Users\lidajun\AppData\Local\Programs\Python\Python36\lib\http\client.py”,第1026行,在_send_output中
self.send(msg)
文件“C:\Users\lidajun\AppData\Local\Programs\Python\Python36\lib\http\client.py”,第964行,在send中
self.connect()
文件“C:\Users\lidajun\AppData\Local\Programs\Python\Python36\lib\http\client.py”,第1392行,在connect中
super().connect()
文件“C:\Users\lidajun\AppData\Local\Programs\Python\Python36\lib\http\client.py”,第936行,在connect中
(self.host,self.port), self.timeout, self.source_address)
文件“C:\Users\lidajun\AppData\Local\Programs\Python\Python36\lib\socket.py”,第724行,在create_connection中
raise err
文件“C:\Users\lidajun\AppData\Local\Programs\Python\Python36\lib\socket.py”,第713行,在create_connection中
sock.connect(sa)
TimeoutError: [WinError 10060]
谢谢提示。
也许你的 Python 环境不喜欢 301 重定向?
我尝试了 python 2.7.14。也无法运行。
或者,可能是 pandas 版本的问题。我能知道您的软件包版本吗?
谢谢!
当然
考虑下载数据文件并在本地使用它,而不是通过 URL 访问?
谢谢!
当我使用实际的 URL 时,它运行良好。我只是好奇为什么短链接不起作用。
嗯……
顺便说一下,我刚刚学完第10课。很棒的课程,再次感谢!
针对错误
print(“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0)
TypeError: 不支持的操作数类型:%的操作数不能为“NoneType”和“tuple”
解决方案
ss=(“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0)
print(ss)
太棒了!这是 Python 2 与 Python 3 的问题。
准确率:76.951 🙂
干得好!
准确率:76.951% (4.841%)
这两种决策树的方法有什么区别吗?我认为它们会给出相同的准确率。但当我对相同的数据集使用这两种方法时,它们给出了不同的结果。
(1)
num_instances = len(X)
seed = 7
kfold = model_selection.KFold(n_splits=10, random_state=seed)
model = DecisionTreeClassifier()
results = model_selection.cross_val_score(model,X,Y,cv=kfold)
print(“Accuracy: %.3f%% (%.3f%%)” %(results.mean()*100.0,results.std()*100.0))
(2)
models = []
models.append((‘DT’, DecisionTreeClassifier()))
names = []
for name, model in models
kfold = model_selection.KFold(n_splits=10, random_state=seed)
cv_results = model_selection.cross_val_score(model,X_train,Y_train,cv=kfold,scoring=scoring)
results.append(cv_results)
names.append(name)
msg = “%s: %f (%f)” % (name,cv_results.mean(),cv_results.std())
print (msg)
在我看来,这似乎是相同的算法。如果在使用相同的随机种子的情况下在相同的数据上运行,应该会给出相同的结果。
或许引入了其他一些随机性因素?
更多关于这些算法的随机性,请参阅此处
https://machinelearning.org.cn/randomness-in-machine-learning/
(1) – 准确率:93.529% (17.539%)
(2) – DT: 0.992308 (0.023077)
相同的分类器(决策树)相同的数据集,但结果不同
谢谢你的回复。感谢你的博客。它对我很有用。
我想继续提问。相同的分类器(决策树),相同的数据集(iris.csv),但结果不同。我想知道为什么会有不同,先生?
(1)
import pandas
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
filename = ‘iris.csv’
names = {‘sepal_length’,’sepal_width’,’petal_length’,’petal_width’,’species’}
dataset = pandas.read_csv(filename, names=names)
array = dataset.values
X = array[:, 0:4]
Y = array[:, 4]
num_instances = len(X)
#seed = 7
kfold = model_selection.KFold(n_splits=10, random_state=7)
model = DecisionTreeClassifier()
results = model_selection.cross_val_score(model,X,Y,cv=kfold)
print(“Accuracy: %.3f%% (%.3f%%)” %(results.mean()*100.0,results.std()*100.0))
输出:准确率:94.667% (7.180%)
(2)
import pandas
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
filename = ‘iris.csv’
names = {‘sepal_length’,’sepal_width’,’petal_length’,’petal_width’,’species’}
dataset = pandas.read_csv(filename, names=names)
array = dataset.values
X = array[:,0:4]
Y = array[:,4]
num_instances = len(X)
X_train,X_validation,Y_train,Y_validation=model_selection.train_test_split(X,Y,random_state=7)
scoring = ‘accuracy’
models = []
models.append((‘DT’, DecisionTreeClassifier()))
models.append((‘RF’, RandomForestClassifier()))
#评估每个模型
results = []
names = []
for name, model in models
kfold = model_selection.KFold(n_splits=10, random_state=7)
cv_results = model_selection.cross_val_score(model,X_train,Y_train,cv=kfold,scoring=scoring)
results.append(cv_results)
names.append(name)
msg = “%s: %f (%f)” % (name,cv_results.mean(),cv_results.std())
print (msg)
输出:DT: 0.972727 (0.041660) (大约 97%)
机器学习算法是随机的,在此了解更多信息
https://machinelearning.org.cn/randomness-in-machine-learning/
谢谢这篇文章。我无法设计出更好的集成方法来提高准确率。我想了解更多关于集成(随机森林)来提高准确率。有什么可以分享的吗?
我有很多关于这个主题的帖子,请尝试使用博客顶部的搜索功能。
X = array[:,0:8]
Y = array[:,8]
scaler = StandardScaler().fit(X)
rescaledX = scaler.transform(X)
# 汇总转换后的数据
numpy.set_printoptions(precision=3)
print(rescaledX[0:5,:])
Jason,您能解释一下为什么将精度设置为3,以及为什么将Rescale值打印为[0:5]吗?
它会对原始数据造成什么改变,您能解释一下吗?
打印选项确保我们不会得到过多的精度,您可以将其删除。
要了解更多关于切片数组的信息,请参阅这篇帖子
https://machinelearning.org.cn/index-slice-reshape-numpy-arrays-machine-learning-python/
在第3课中,url https://goo.gl/vhm1eU 和 https://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data 都无效
感谢您对Pima印第安人糖尿病数据集的兴趣。
由于权限限制,该数据集不再可用。
谢谢,我已经更新了链接。我这里有一份数据集的副本
https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv
对数损失:-0.492 (0.047)
感谢您写了这篇超酷的文章……
很高兴它有帮助。
这篇帖子太容易理解了。非常感谢
我目前正在上第七课,我已经尝试了train_test_split和K折。我得到的准确度如下
train_test_split: 77.559
K折:76.951
干得好!
感谢14天的迷你课程。我已经完成了并制作了一个模型。
https://github.com/Mamtasadani/-Iris-Dataset
再次感谢……
干得好!
你好,
我正在上第11课。我的Randomized SearchCV和Grid Search CV都给出了完全相同的结果,尽管我多次运行我的模型。Randomized Search CV不应该给出不同的结果吗?或者随机搜索CV内部是否使用了Grid Search CV?
如果搜索空间很小,这些方法将涵盖相似的范围。
你好 Jason,
我完成了这节课,并尝试将其应用于我将在这里向您解释的分类问题。
我的数据集是一个4000行x23列的矩阵,观测值的数量与我拥有的类别数量完全相同。这意味着每一行都对应一个类别。
我希望构建一个模型,给定一个大小为(23×1)的输入向量,该模型将预测它所属的类别。
我的问题:对于这种多类别分类问题,我可以使用哪种类型的算法?
提前感谢您的反馈
此致
火星
我建议测试一套算法,以发现哪种最适合您的数据。
我在这里解释了更多
https://machinelearning.org.cn/faq/single-faq/what-algorithm-config-should-i-use
你好 Jason,
我测试了集成方法和一堆决策树方法。
我的准确率为0%,这可能是由于每个观测值本身就是一个类别,因此测试集和训练集具有不同的类别。
我的问题:是否可以使用一种基于用户-项目的推荐系统,即给定一个新用户,模型会找到一个拥有相似物品的用户?
我在您的网站上找不到关于推荐系统的教程,您有计划吗?:)
非常感谢您的宝贵反馈
KNN是用于推荐系统的一种很好的方法。
我希望将来能涵盖这个主题。
您好,非常感谢这篇出色的文章。我刚刚完成了这节课,并按照您的建议写了一篇博客文章。我请求杰森和我的所有数据科学家同事们都能看一看这篇帖子,并请给我宝贵的反馈。
帖子的链接是
http://sagarjain.in/iris-dataset-dissected/
非常感谢杰森帮助我开启了如此美妙的旅程。
干得好!
嗨,Jason,
首先,我要感谢您这篇精彩的帖子。我因为自我设限的信念而迟迟没有开始学习机器学习。
我遇到一个人,他向我介绍了您的课程,我一读到第一篇帖子《是什么阻碍了您实现机器学习目标?》就立刻想到:“这个人是为我写的,这正是我所感受到的。”
我是一名软件工程师,一直被机器学习的强大力量所吸引,所以我决定在一个周末完成这门初级课程。
我目前正在深入研究关于“超参数调优”的课程,但我对快速检查算法步骤有一个疑问。
我在评论中找到了这个共享的笔记本(https://www.kaggle.com/gautham11/building-a-scikit-learn-classification-pipeline/notebook)(感谢GauthamKumaran分享:)
所以我决定比较使用K折和管道的快速检查算法的结果,但我没有得到与GauthamKumaran使用管道相同的结果,并且K折和管道之间也存在不同的结果。
这正常吗?我是不是遗漏(或误解)了什么?
您可以在这里找到我的代码:https://github.com/TommyStarK/Machine_Learning/blob/master/machine_learning_mastery_with_python_mini_course/iris_models_evaluation.py
或在这里查看控制台打印的结果
https://imgur.com/WwOhv2x
再次感谢杰森的这篇帖子,感谢您的帮助
祝您有个美好的一天!
祝好,
Tommy
谢谢汤米,很高兴听到你有所突破。
通常每次运行我们都可以预期不同的结果。
https://machinelearning.org.cn/randomness-in-machine-learning/
此外,代码中非常微小的差异也可能导致结果的巨大差异。
Jason,
感谢这个很棒的教程!
我的print()格式有些问题;出现“TypeError: 不支持的操作数类型为%” 'NoneType' 和 Tuple'”。我最终将:“print(…%.3f%% (%.3f%%)”) % (…” 替换为 “print(…{:.3f} ({:.3f})”.format(…)”,问题解决了。不确定是否有什么东西被弃用了,因为我刚从2.7切换到3.6。
我的版本是
Python 3.6.6
scipy 1.1.0
numpy 1.14.5
matplotlib 2.2.2
pandas 0.23.4
sklearn 0.19.1
再次感谢您的教程,
Jason
干得不错。
确保您使用的是 Python 3.5+ 并从命令行运行。
嗨,Jason!
我正在学习更多很棒的教程,并且收到了一些像这样的FutureWarnings
FutureWarning: 默认求解器将在0.22版本中更改为“lbfgs”。请指定求解器以消除此警告。
这个警告来自上面第10点中使用的逻辑回归模型
.../anaconda3/lib/python3.6/site-packages/sklearn/linear_model/logistic.py
只是想告诉您。这些教程太棒了。非常感谢。:)
艾米
谢谢,目前可以忽略这些警告。
我也遇到这个错误 🙁 第6点之后我无法进行任何操作。
关于这个问题有什么消息吗?
什么错误?
FutureWarning: 默认求解器将在0.22版本中更改为“lbfgs”。请指定求解器以消除此警告。
将scikit-learn降级到0.19.2有所帮助……谢谢:)
很高兴听到这个消息。
就像“R in a Nut-shell”一样。我们有Python的参考书吗?
当然:《Python简明手册》(Python 2.5版本)
https://amzn.to/2RrfEUj
嗨,Jason,
感谢这门精彩的迷你课程!
在第13课中,我使用LogisticRegression获得了78%的准确率。我使用这个模型是因为它在第10课中表现最好,然后在第11课中也是如此。
关于第12课,我有一个问题,它是指使用集成技术来提高已经选择的模型的准确性,还是指使用集成模型来代替我选择的模型?
此致,马丁
好问题,两者皆可。这取决于选择的集成学习方法。
你使用了什么模型?你得到了什么结果?请在评论中告诉我。
Jason 再次你好,
我现已完成迷你课程,在第14课中使用了K-近邻分类器,准确率达到0.96。
我必须说,您的迷你课程对我更好地理解机器学习的实践方面有很大帮助。您所做的工作真是太棒了,非常感谢您的帮助!
此致,马丁
马丁,你的进步真棒!
你好,
我正在上第6课,我尝试执行您提交的相应代码,但出现此错误:“DeprecationWarning: imp模块已被弃用,请使用importlib;请参阅该模块的文档以了解其他用法
导入imp”。您能帮我解决这个问题吗?我必须提到,我的工作空间是Ubuntu 16.04作为virtual_box中的客户操作系统,并且我已经按照您在此处提供的建议安装了Anaconda“https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/”。
提前感谢你
听起来像一个警告,你可以安全地忽略它。
我正在上第6课。你说的预处理数据是什么意思?我能够让代码工作,但我没有理解其中的逻辑。
我的意思是缩放它,删除冗余变量、冗余行、异常值等。
第6课:准确率76.951%
干得好!
各位同事好,这是一篇令人愉快的文章,评论也很激励人,我真的很喜欢这些。
谢谢。
哎呀,到了第3课,但在IDLE中第一次保存后,我不知道如何获取主提示符。没人告诉我!
@杰森:我看到一些关于统计学和假设检验的文章。有没有动力写一篇关于六西格玛在制造业机器学习中的应用的帖子?
恭喜您取得进展。
谢谢史蒂文的建议。
好文章!
第13课我缺少这样的东西
model.fit(X, Y)
Xnew = [[10,200,96,38,300,50,1.5,40]]
# 进行预测
ynew = model.predict(Xnew)
print("X=%s, Predicted=%s" % (Xnew[0], ynew[0]))
Xnew = [[1,80,50,5,0,21,0.1,40]]
# 进行预测
ynew = model.predict(Xnew)
print("X=%s, Predicted=%s" % (Xnew[0], ynew[0]))
当你看到最终产品时,理解会加深。
我花了一个小时才明白如何测试模型(这可能很明显)。
也许这会有帮助。
https://machinelearning.org.cn/how-to-make-classification-and-regression-predictions-for-deep-learning-models-in-keras/
在第13课中,
test_size = 0.15
model = RandomForestClassifier(n_estimators=num_trees, max_features=max_features)
结果 = 0.8534
model = LogisticRegression()
结果 = 0.8017
感谢您的精彩帖子!
干得好!
这对于初学者来说是一门很好的课程。我需要以上在Anaconda上运行Python 3.5版本的示例。
您能分享相关链接吗?因为这个原因,我无法进行绘图功能的工作。
所有示例都适用于 Python 2.7 和 3。
我也使用Anaconda。我想我可能遇到了与你类似的绘图问题。我的根本原因是我使用的pandas版本太早了。我没有使用`from pandas.plotting import scatter_matrix`,而是使用了
`from pandas.tools.plotting import scatter_matrix,`
它解决了所有问题!希望对你有帮助。
或者,您可以尝试更新您的 Pandas 版本?
首先,非常感谢您帮助我学习Python和机器学习
你觉得这个怎么样?
逻辑回归的准确率是 0.83
谢谢。
抱歉,我没有精力审查你的代码。
没关系,我只是想告诉你我多么感谢你的教程,我想向你展示它对我的帮助有多大。
谢谢,很高兴听到这个!
感谢分享你的代码,它对我有用。
我决定通过其他方式测试网络,所以我让它在数据集中识别用户给出的数字。它像魔法一样奏效!……(这是在您训练模型之后,变量可以互换)
导入 numpy as np
import matplotlib.pyplot as plt
new_model = tf.keras.models.load_model(“Number_identificator.model”)
rango = range(100)
d_number = int(input(“输入一个数字: “))
rango = range(1000)
for i in rango
if np.argmax(predictions[i]) == d_number
plt.imshow(x_test[i],cmap=plt.cm.binary)
plt.show()
干得不错。
亲爱的 Jason,
时间序列分析也能进行模型比较吗?
当然可以。
第7课
print((“准确率: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0))
第8课
print(“对数损失: %.3f (%.3f)” % results.mean(), results.std()))
你的版本不起作用,我猜是你的 Python 版本问题
我的 Python 版本是 3.6.3
你到底遇到了什么问题?
准确率: 76.951% (4.841%) 第7课
干得好。
第8课:对数损失: -0.493 (0.047)
print 函数应该是
print(“Logloss: %.3f (%.3f)” % (results.mean(), results.std()))
抱歉,我忘了说谢谢
嗨,Jason,感谢您的教程,它对我的入门帮助很大!
我该如何生成一个用于回归问题的一维数据集?我感兴趣的是反复采样以逼近维度的真实平均值。
祝好,
Nic
请参阅此教程,了解如何生成回归数据集。
https://machinelearning.org.cn/generate-test-datasets-python-scikit-learn/
非常感谢,这个教程非常有帮助 🙂
不客气。很高兴能帮到你。
非常感谢
这个教程非常有帮助 🙂
准确率是 76.95% 😉
干得好!
你好 Jason,
对于第5课,散点矩阵显示两种颜色,直方图有不同的颜色。但我的测试只显示一种颜色,代码是相同的。你知道为什么我的散点矩阵只有一种颜色吗?
API 可能已更改,您可以忽略颜色上的更改。
你好 Jason,
我不理解 confusion_matrix “print(confusion_matrix(y_validation, predictions1))”
输出是
[[44 2]
[11 20]]
您和任何其他人能帮我理解 confusion_matrix 吗?
是的,这会有帮助
https://machinelearning.org.cn/confusion-matrix-machine-learning/
你好 Jason,
我在第10课,我尝试执行您提交的相应代码,但出现此错误
>>> for name, model in models
… kfold=KFold(n_splits=10,random_state=7)
File “”, line 2
kfold=KFold(n_splits=10,random_state=7)
^
IndentationError: 期望一个缩进块
你能帮我解决这个问题吗?我使用的是 Python 3。
非常感谢您的精彩课程和帮助。
是的,看起来你没有复制空格。
你可以在这里学习如何从教程中复制代码。
https://machinelearning.org.cn/faq/single-faq/how-do-i-copy-code-from-a-tutorial
嗨,Jason,
我有一个关于 Python 编码的问题,在 Anaconda 3 中输入 Python 代码时,没有自动代码补全或方法名提示。这是正常现象吗?我的意思是当我通过 IDE(Eclipse)输入 JAVA 或其他语言时,它会自动提示方法名。再次感谢。
抱歉,我不使用 Python IDE,我也不推荐它们,并在此处解释更多。
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
我推荐使用文本编辑器。
https://machinelearning.org.cn/machine-learning-development-environment/
非常感谢,你是一个非常积极的贡献者,你通过让我们成功而成功,无限的祝福给你。
谢谢!
嗨,杰森,
在第6课中,你写了这段代码
rescaledX
scaler = StandardScaler().fit(X)
rescaledX = scaler.transform(X)
为了标准化 X,你为什么在接下来的代码中没有使用 rescaledX 而不是 X 呢?
因为这些课程是独立的。
你好,
一个简短的批评,我认为如果你在使用方法论之前,能简要介绍一下你在此处使用的数据,那将有所帮助。
谢谢
Ralph
谢谢,拉尔夫。
你好,
再一个小提示,
print(“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0)
Python 3.7 会出现问题
已将旧的 % 格式化替换为推荐的格式
在第7行:print(f”准确率: {results.mean()*100.0:.3f}% {results.std()*100.0:.3f})”)
在第8行:print(f”对数损失: {results.mean():.3f} ({results.std():.3f})”)
此致
Ralph
谢谢。
在第7课
KFold(n_splits=10, random_state=7)
查看 KFold 参考
https://scikit-learn.cn/stable/modules/generated/sklearn.model_selection.KFold.html
1. 如果我设置 n_splits=10 且有 1000 个样本,这意味着每个折叠将有 1000/10 个样本(即每个折叠有 100 个样本)吗?
2. 我仍然不明白 random_state 是做什么用的?
3. 根据我指出的参考资料,random_state 仅在 Shuffle=True 时使用,但我们没有将其作为参数指示。Shuffle 的默认值是 False。
class sklearn.model_selection.KFold(n_splits=5, shuffle=False, random_state=None)
random_state 在这里是如何工作的?
是的,100个样本。
Random state 设置用于打乱数据的随机数生成器的种子,更多关于随机数生成器信息请点击此处。
https://machinelearning.org.cn/introduction-to-random-number-generators-for-machine-learning/
Shuffle 默认设置为 true。
在第7课,我得到
k-折叠准确率: 76.951% 4.841
当 shuffle = True 时,准确率: 77.086% 5.091
留一法准确率: 76.697% 3.543
干得好!
在第11课中,通过随机搜索得到的最佳参数是 4.0370172585965545,分数为 0.27964410120992883。
问题:如果没有设置 scoring 参数,最佳分数指的是哪个指标?
对于分类,它将默认为准确率,对于回归,我认为是均方误差(mse)。
亲爱的 Jason,
感谢这个优秀的网站。我在第8课的结果是
[-0.57566087 -0.44368448 -0.52779218 -0.52769388 -0.51253097 -0.49054691
-0.45147871 -0.40815489 -0.47043725 -0.51790254]
平均值: -0.493
标准差: 0.047
诚挚的问候,
Dominique
干得好!
大家好,
如果您使用 Python 3,请查看此内容;
在“第7课:使用重采样方法进行算法评估”的打印语句中
print(“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0)
必须是这样的
print(“准确率: {:.3f} {:.3f}”.format(results.mean()*100.0, results.std()*100.0))
感谢 Jason 提供的精彩博客。
爱与和平,
Adem
https://www.linkedin.com/in/ademaldemir/
谢谢。
第7课中有一个小小的拼写错误
print(“Accuracy: %.3f%% (%.3f%%)” % (results.mean()*100.0, results.std()*100.0))
“%%” 用于在字符串中输出 “%”。
具体错误是什么?
目前:准确率: 76.951% (4.841%)
第7课,最后一行
print(“Accuracy: %.3f%% (%.3f%%)”) % (results.mean()*100.0, results.std()*100.0)
报错
TypeError: 不支持的操作数类型:%的操作数不能为“NoneType”和“tuple”
我改成了
! — >> — >>!
print(“准确率: %.3f%% (%.3f%%)” % (results.mean()*100.0, results.std()*100.0) )
它奏效了。
感谢这门课程。
谢谢,已修复!
干得好!
嗨 Jason,感谢您创建这门课程,它真的很有帮助!我有两个问题。
- 第8课:即使 shuffle=False(默认),为什么我们还需要为 KFold() 设置一个特定的 random_state 值?
- 第11课:我们不应该在进行超参数调优之前将数据分成测试集和训练集,并且只使用训练数据集进行训练吗?我在许多其他资料中读到,应该避免使用测试数据进行训练,以减少过拟合。
先谢谢您了。
不客气。
习惯而已。
也许吧。这取决于你拥有多少数据以及你是否想保留一些数据用于最终检查。我最近更喜欢嵌套交叉验证,即在每个外部交叉验证折叠内进行网格搜索。
第2课
#数据框
import numpy as np
import pandas as pd
myarray = np.array([[1,2,3],[4,5,6]])
rownames = [‘a’,’b’]
colnames = [‘one’, ‘two’, ‘three’]
mydataframe = pd.DataFrame(myarray, index=rownames,
columns=colnames)
print(mydataframe)
一 二 三
a 1 2 3
b 4 5 6
哇。太棒了
干得好!
好的开始
一 二 三
a 1 2 3
b 4 5 6
干得好!
你好 jason,
首先我来自印度尼西亚,英语不太好,但我真的想学习机器学习,所以我尽力而为,我有两个问题。
– 我真的不明白这个,我的意思是第3课和第4课的代码有什么区别?我该怎么做,比如只是在我的 Python(我使用的是 Anaconda Python)中输入代码。
– 使用 head() 函数查看前几行来理解您的数据。
使用 shape 属性查看数据的维度。
使用 dtypes 属性查看每个属性的数据类型。
使用 describe() 函数查看数据分布。
使用 corr() 函数计算变量之间的成对相关性。
我的意思是,我需要将第3/4课的代码分组,然后查找头部、维度等等吗?
谢谢你
第3课加载数据并总结其形状。
第4课加载数据并回顾每个变量的摘要统计信息。
您可以将代码保存到 .py 文件并运行它。
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
如果这对你来说很简单,也许可以继续下一课。
先生,谢谢您的所有这些信息。
但是为什么我的可视化图形不像您的那么清晰。我的图形不够暗,并且条形图中包含线条。请帮助!
也许 API 改变了,因此图表也不同了?
嗨,Jason,
我有一个关于模型比较的问题。在比较模型时,为什么不比较提高准确率之后的结果呢?
谢谢你
是的,有很多方法。请使用适合您项目的方法。
调优模型可能会导致对测试数据集的过拟合。我尝试快速找出有效的方法,然后加倍努力。
这些参数搜索可以用于任何类型的算法吗?例如用于 SURF、FAST 等特征提取算法。
也许可以。
非常感谢您的教程,非常有帮助!
SciPy 网站的链接似乎出错了 – 它链接到了官方的 Python 网站。请更改。
谢谢,已修复!
嗨,Jason,
感谢您收集的这些精彩资料。
它提供了非常好的指导方向。
我学习 Python 机器学习已经一年了,一直很困惑。
您的帖子给了一个很好的指路明灯。
我目前正在“理解数据”的第四天。
只是想感谢您!
谢谢,很高兴听到这个。
为你的进步喝彩!
一 二 三
a 1 2 3
b 4 5 6
第二天: 尝试一些基本的 Python 和 SciPy 语法
干得好!
# 使用 Pandas 从 URL 加载 CSV
from pandas import read_csv
url = “https://goo.gl/bDdBiA”
names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
data = read_csv(url, names=names)
print(data.shape)
(768,9)
干得好!
preg plas pres skin test mass \
计数 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000
平均值 3.845052 120.894531 69.105469 20.536458 79.799479 31.992578
标准差 3.369578 31.972618 19.355807 15.952218 115.244002 7.884160
最小值 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000 27.300000
50% 3.000000 117.000000 72.000000 23.000000 30.500000 32.000000
75% 6.000000 140.250000 80.000000 32.000000 127.250000 36.600000
最大值 17.000000 199.000000 122.000000 99.000000 846.000000 67.100000
pedi age class
计数 768.000000 768.000000 768.000000
平均值 0.471876 33.240885 0.348958
标准差 0.331329 11.760232 0.476951
最小值 0.078000 21.000000 0.000000
25% 0.243750 24.000000 0.000000
50% 0.372500 29.000000 0.000000
75% 0.626250 41.000000 1.000000
最大值 2.420000 81.000000 1.000000
干得好!
# 标准化数据(均值为0,标准差为1)
from sklearn.preprocessing import StandardScaler
import pandas
import numpy
url = “https://goo.gl/bDdBiA”
names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
dataframe = pandas.read_csv(url, names=names)
array = dataframe.values
# 将数组分离为输入和输出组件
X = array[:,0:8]
Y = array[:,8]
scaler = StandardScaler().fit(X)
rescaledX = scaler.transform(X)
# 汇总转换后的数据
numpy.set_printoptions(precision=3)
print(rescaledX[0:5,:])
[[ 0.64 0.848 0.15 0.907 -0.693 0.204 0.468 1.426]
[-0.845 -1.123 -0.161 0.531 -0.693 -0.684 -0.365 -0.191]
[ 1.234 1.944 -0.264 -1.288 -0.693 -1.103 0.604 -0.106]
[-0.845 -0.998 -0.161 0.155 0.123 -0.494 -0.921 -1.042]
[-1.142 0.504 -1.505 0.907 0.766 1.41 5.485 -0.02 ]]
干得漂亮!
# 使用交叉验证进行评估
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
url = “https://goo.gl/bDdBiA”
names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
dataframe = read_csv(url, names=names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
kfold = KFold(n_splits=10, random_state=7)
model = LogisticRegression(solver=’liblinear’)
results = cross_val_score(model, X, Y, cv=kfold)
print(“Accuracy: %.3f%% (%.3f%%)” % (results.mean()*100.0, results.std()*100.0))
准确率:76.951% (4.841%)
干得好!
# 交叉验证分类 LogLoss
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
url = “https://goo.gl/bDdBiA”
names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
dataframe = read_csv(url, names=names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
kfold = KFold(n_splits=10, random_state=7)
model = LogisticRegression(solver=’liblinear’)
scoring = ‘neg_log_loss’
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print(“Logloss: %.3f (%.3f)” % (results.mean(), results.std()))
对数损失: -0.493 (0.047)
干得好!
# KNN 回归
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsRegressor
url = “https://goo.gl/FmJUSM”
names = [‘CRIM’, ‘ZN’, ‘INDUS’, ‘CHAS’, ‘NOX’, ‘RM’, ‘AGE’, ‘DIS’, ‘RAD’, ‘TAX’, ‘PTRATIO’, ‘B’, ‘LSTAT’, ‘MEDV’]
dataframe = read_csv(url, delim_whitespace=True, names=names)
array = dataframe.values
X = array[:,0:13]
Y = array[:,13]
kfold = KFold(n_splits=10, random_state=7)
model = KNeighborsRegressor()
scoring = ‘neg_mean_squared_error’
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print(results.mean())
-107.28683898039215
/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/site-packages/sklearn/model_selection/_split.py:293: FutureWarning: Setting a random_state has no effect since shuffle is False. This will raise an error in 0.24. You should leave random_state to its default (None), or set shuffle=True.
warnings.warn(
LR: 0.769515 (0.048411)
/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/site-packages/sklearn/model_selection/_split.py:293: FutureWarning: Setting a random_state has no effect since shuffle is False. This will raise an error in 0.24. You should leave random_state to its default (None), or set shuffle=True.
warnings.warn(
LDA: 0.773462 (0.051592)
这是我在运行第11课代码时得到的结果。
LDA是什么意思。
干得不错。
谢谢,我会将其改为shuffle。
嗨,杰森,
这是一个很好的教程。
我在第7天的程序中得到了以下结果。
准确度:76.951% (4.841%)
如果折叠次数变化会怎样?
它会提高分数吗?
干得好。
是的,折叠次数会影响估计。10是一个很好的默认值。
嗨,Jason,
感谢您为我们制作的教程。我从中受益匪浅。
关于第13课的一个问题
#########################
test_size = 0.33
seed = 7
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# 在33%的数据上拟合模型
model = LogisticRegression(solver=’liblinear’)
model.fit(X_train, Y_train)
#########################
它应该写成 #在67%的数据上拟合模型 吗?然后稍后使用33%的数据作为未见数据进行验证?还是我理解错了?
谢谢,
Joe
是的,注释不正确,模型是在67%的数据上拟合的。
已修复,谢谢!
第2天
代码-
# 数据框
import numpy as np
import pandas as pd
myarray = np.array ([[1,2,3], [4,5,6]])
rowname = [‘a’, ‘b’]
colname = [‘one’, ‘two’, ‘three’]
mydf = pd.DataFrame(myarray, index=rowname, columns=colname)
print(mydf)
输出-
一 二 三
a 1 2 3
b 4 5 6
干得好!
第3课
代码:-
import pandas as pd #padas 库已导入
url = “https://goo.gl/bDdBiA”
names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
df = pd.read_csv(url, names=names)
print(df.shape)
输出:-
(768, 9)
干得不错。
第7课
train-test-split *** 准确度 = 78.740% ***
kfold-cross_val-split 平均值 (标准差) *** 准确度 = 77.216% (4.968%) ***
shuffle-cross_val-split 平均值 (标准差) *** 准确度 = 76.065% (1.642%) ***
custom-cross_val-split 平均值 (标准差) *** 准确度 = 77.995% (1.953%) ***
custom_kico-cross_val-split 平均值 (标准差) *** 准确度 = 79.688% (2.083%) ***
repeated-random-test-train-split 平均值 (标准差) *** 准确度 = 76.535% (2.235%) ***
leave_one_out-cross_val-split 平均值 (标准差) *** 准确度 = 77.604% (41.689%) ***
干得好!
第8课
对数损失度量 *** 平均值 -0.494 标准差 (0.042) ***
精确度宏观度量 *** 平均值 0.753 标准差 (0.072) ***
准确度度量 *** 平均值 0.771 标准差 (0.051) ***
NMSE 度量 *** 平均值 -0.229 标准差 (0.051) ***
NRMSE 度量 *** 平均值 -0.476 标准差 (0.054) ***
同质性分数度量 *** 平均值 0.186 标准差 (0.112) ***
精确度度量 *** 平均值 0.721 标准差 (0.137) ***
干得好。
第二天: 尝试一些基本的 Python 和 SciPy 语法
一 二 三
a 1 2 3
b 4 5 6
太棒了!
这段Python代码正确吗?我遇到了一些错误
# 使用Python从URL加载CSV
from python import CSV_reader
url = “https://goo.gl/bDdBiA”
names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
data = CSV.reader(url, names=names)
print(data.shape)
ModuleNotFoundError Traceback (最近一次调用)
in
1 # 使用Python从URL加载CSV
—-> 2 from python import CSV_reader
3 url = “https://goo.gl/bDdBiA”
4 names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
5 data = CSV.reader(url, names=names)
ModuleNotFoundError: 没有名为 ‘python’ 的模块
但是当我检查版本时,我有Python
Python: 3.7.9 (default, Aug 31 2020, 07:22:35)
[Clang 10.0.0 ]
scipy: 1.5.2
numpy: 1.18.5
matplotlib: 3.3.1
pandas: 1.1.1
sklearn: 0.23.2
确保您将代码保存到文件并从命令行运行它,这会有所帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-run-a-script-from-the-command-line
第3天:从CSV加载数据集
(768, 9)
它在Pandas中工作,但尝试使用Python和NumPy时遇到了上述错误。
干得好。
第4天:使用描述性统计理解数据
preg plas pres skin test mass \
计数 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000
平均值 3.845052 120.894531 69.105469 20.536458 79.799479 31.992578
标准差 3.369578 31.972618 19.355807 15.952218 115.244002 7.884160
最小值 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000 27.300000
50% 3.000000 117.000000 72.000000 23.000000 30.500000 32.000000
75% 6.000000 140.250000 80.000000 32.000000 127.250000 36.600000
最大值 17.000000 199.000000 122.000000 99.000000 846.000000 67.100000
pedi age class
计数 768.000000 768.000000 768.000000
平均值 0.471876 33.240885 0.348958
标准差 0.331329 11.760232 0.476951
最小值 0.078000 21.000000 0.000000
25% 0.243750 24.000000 0.000000
50% 0.372500 29.000000 0.000000
75% 0.626250 41.000000 1.000000
最大值 2.420000 81.000000 1.000000
干得好!
第5天:使用数据可视化理解数据
我如何在评论中分享我的图表?
也许发布到某个地方并链接过来?
第6天:通过预处理数据为建模做准备
[[ 0.64 0.848 0.15 0.907 -0.693 0.204 0.468 1.426]
[-0.845 -1.123 -0.161 0.531 -0.693 -0.684 -0.365 -0.191]
[ 1.234 1.944 -0.264 -1.288 -0.693 -1.103 0.604 -0.106]
[-0.845 -0.998 -0.161 0.155 0.123 -0.494 -0.921 -1.042]
[-1.142 0.504 -1.505 0.907 0.766 1.41 5.485 -0.02 ]]
干得漂亮!
第7天:使用重采样方法进行算法评估
准确率:76.951% (4.841%)
干得好!
嗨,Jason,
对于机器学习初学者来说,这是非常棒的教学作品!非常感谢分享这些代码。
谢谢!
很好
谢谢!
第7课 – 准确度: 77.349% (5.153%)
这个结果好吗?我需要让它更接近100%吗?
干得好,对于这个问题来说,这是一个很好的结果。
我通过将KFold中的分割设置为9来达到这个结果。这样改变正确吗?
我特别感谢您网站上的文章,我重拾了兴趣并能够很好地理解机器学习。事实上,过去两年我曾几次尝试学习机器学习,但都止步于介绍部分,因为它们都从统计学开始,对我来说简直是天书。我没有任何统计学背景,但在系统管理和编程(Java)方面有很好的工作经验,过去5年我一直在大数据Hadoop平台从事管理和解决方案开发。
现在,在您的文章的帮助下,我能够在过去三天中学到很多机器学习知识,尽管很多事情仍然不清楚,但我非常有信心能够做到。我注意到您的网站上,每当我遇到任何疑问或问题时,无论它们是简单还是复杂,都能在您的网站上的某个地方找到答案。
我目前正在忙于Python机器学习课程第14天的项目。希望我能达到预期的结果。
再次衷心感谢您的出色工作。
当然,如果你愿意的话。特定的k值可能没有太大关系,例如:
https://machinelearning.org.cn/how-to-configure-k-fold-cross-validation/
很高兴你重拾了兴趣!坚持下去,如果我能帮上忙,我会在这里。
非常感谢您提供的巨大帮助。
我已完成Python第14天的项目。这帮助我学到了很多东西,并对机器学习更有信心了。
以下是我第14天项目的结果
LogisticRegression : 95.833% (5.590%)
LinearDiscriminantAnalysis : 97.500% (3.819%)
KNeighborsClassifier : 98.333% (3.333%)
DecisionTreeClassifier : 95.000% (7.638%)
GaussianNB : 96.667% (4.082%)
算法参数调整
==========================
************ LogisticRegression
已调优最佳参数 {‘C’: 1000.0, ‘penalty’: ‘l1’}
准确度 : 97.5
************ LinearDiscriminantAnalysis
已调优最佳参数 {‘solver’: ‘svd’}
准确度 : 97.5
************ KNeighborsClassifier
已调优最佳参数 {‘n_neighbors’: 13}
准确度 : 99.16
************ DecisionTreeClassifier
已调优最佳参数 {‘dec_tree__criterion’: ‘entropy’, ‘dec_tree__max_depth’: 6, ‘pca__n_components’: 3}
准确度 : 95.83
************ GaussianNB
已调优最佳参数 {‘clf__priors’: None, ‘clf__var_smoothing’: 1e-08}
准确度 : 96.66
干得好!
第7天:使用重采样方法进行算法评估
准确度 77.865% (4.592%)
干得好!
第二天: 尝试一些基本的 Python 和 SciPy 语法
一 二 三
a 1 2 3
b 4 5 6
干得好。
第8课:算法评估指标
代码报错
print(“Logloss: %.3f (%.3f)”) % (results.mean(), results.std())
TypeError: 不支持的操作数类型:%的操作数不能为“NoneType”和“tuple”
感谢您的宝贵信息。
干得好。
这是Python中旧的字符串打印方式。
用新的方式(使用 f-string)替换它
print(f”对数损失: {results.mean():.3f} ({results.std():.3f})”)
谢谢。f-string在Python 3.6及更高版本中可用
第二天: 尝试一些基本的 Python 和 SciPy 语法
一 二 三
a 1 2 3
b 4 5 6
干得好。
一 二 三
a 1 2 3
b 4 5 6
干得好!
(768, 9)
干得好!
preg plas pres … pedi age class
count 768.000000 768.000000 768.000000 … 768.000000 768.000000 768.000000
mean 3.845052 120.894531 69.105469 … 0.471876 33.240885 0.348958
std 3.369578 31.972618 19.355807 … 0.331329 11.760232 0.476951
min 0.000000 0.000000 0.000000 … 0.078000 21.000000 0.000000
25% 1.000000 99.000000 62.000000 … 0.243750 24.000000 0.000000
50% 3.000000 117.000000 72.000000 … 0.372500 29.000000 0.000000
75% 6.000000 140.250000 80.000000 … 0.626250 41.000000 1.000000
max 17.000000 199.000000 122.000000 … 2.420000 81.000000 1.000000
[8行 x 9列]
非常好。
机器学习的精彩入门。但是,我不太确定如何评估一个模型是否比另一个更好。如何通过查看平均值和标准差来判断哪个模型最好?
好问题,通常我们选择平均值更好、标准差更小的模型。
尽管模型选择本身就可以成为一个完整的话题,例如:
https://machinelearning.org.cn/a-gentle-introduction-to-model-selection-for-machine-learning/
名称:Logistic回归 准确度:95.333% (8.459%)
名称:线性判别分析 准确度:98.000% (3.055%)
名称:K近邻分类器 准确度:95.333% (5.207%)
名称:SVC 准确度:96.000% (5.333%)
名称:决策树分类器 准确度:96.000% (5.333%)
干得好!
第7课
我得到了以下结果
LR: 0.770865 (0.050905)
LDA: 0.766969 (0.047966)
我认为LDA效果更好,因为它尽管平均值较小,但标准差也更低
干得好!
第6天成果
[[ 0.64 0.848 0.15 0.907 -0.693 0.204 0.468 1.426]
[-0.845 -1.123 -0.161 0.531 -0.693 -0.684 -0.365 -0.191]
[ 1.234 1.944 -0.264 -1.288 -0.693 -1.103 0.604 -0.106]
[-0.845 -0.998 -0.161 0.155 0.123 -0.494 -0.921 -1.042]
[-1.142 0.504 -1.505 0.907 0.766 1.41 5.485 -0.02 ]]
干得不错。
第7天(抱歉,亲爱的Jason,我速度慢)
我将代码更改为 kfold = KFold(n_splits=10, random_state=None. random state设置为None而不是7 后,得到了以下结果。
准确率:76.951% (4.841%)
注意安全。
谢谢你。
– 来自孟加拉国
干得好。
第7课
我添加了 “shuffle=True”,如下所示:
kfold = KFold(n_splits=10, random_state=7, shuffle=True)
我得到了 77.086% (5.091%) 的准确度
干得好!
第7课
原始代码报错,但我删除random_state(0)后得到
准确率:76.951% (4.841%)
感谢指出。在最新版本的库中,KFold 需要 “shuffle=True” 来随机化输出。我已经更新了代码。
第8课
对数损失: -0.494 (0.042)
第7课结果
准确度:77.086% (5.091%)
第8课结果
对数损失: -0.494 (0.042)
第9课结果
均值和标准差
-38.852320266666666 14.660692658624528
第2天:尝试一些基本的Python和SciPy语法(结果)
一 二 三
a 1 2 3
b 4 5 6
谢谢你的反馈!
第3天:从CSV加载数据集(结果)
(768, 9)
第4天:使用描述性统计理解数据(结果)
preg plas pres skin test mass \
计数 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000
平均值 3.845052 120.894531 69.105469 20.536458 79.799479 31.992578
标准差 3.369578 31.972618 19.355807 15.952218 115.244002 7.884160
最小值 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000 27.300000
50% 3.000000 117.000000 72.000000 23.000000 30.500000 32.000000
75% 6.000000 140.250000 80.000000 32.000000 127.250000 36.600000
最大值 17.000000 199.000000 122.000000 99.000000 846.000000 67.100000
pedi age class
计数 768.000000 768.000000 768.000000
平均值 0.471876 33.240885 0.348958
标准差 0.331329 11.760232 0.476951
最小值 0.078000 21.000000 0.000000
25% 0.243750 24.000000 0.000000
50% 0.372500 29.000000 0.000000
75% 0.626250 41.000000 1.000000
最大值 2.420000 81.000000 1.000000
第6天:通过预处理数据为建模做准备(结果)
[[ 0.64 0.848 0.15 0.907 -0.693 0.204 0.468 1.426]
[-0.845 -1.123 -0.161 0.531 -0.693 -0.684 -0.365 -0.191]
[ 1.234 1.944 -0.264 -1.288 -0.693 -1.103 0.604 -0.106]
[-0.845 -0.998 -0.161 0.155 0.123 -0.494 -0.921 -1.042]
[-1.142 0.504 -1.505 0.907 0.766 1.41 5.485 -0.02 ]]
一 二 三
a 1 2 3
b 4 5 6
嗨,Jason,
我是这个领域的完全初学者。我正在学习您的迷你课程以及《用Python掌握机器学习》。我只是想问这是否足够,或者我是否需要阅读其他书籍。
此致
嗨 Manjot……以下资源可能对您有用
https://machinelearning.org.cn/how-to-get-the-most-from-machine-learning-books-and-courses/
我能够使用CSV读取器加载数据集,但无法使用numpy.loadtxt加载数据,这可能是什么问题。
# 使用pandas从URL加载CSV
from numpy import loadtxt
url = “https://goo.gl/bDdBiA”
names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
data = numpy.loadtxt(fname)
print(data.shape)
你好,Kandeo……当你执行代码时发生了什么?换句话说,你收到了错误消息吗?如果收到了,请提供确切的语句,以便我们更好地帮助你。
朋友你好,我尝试从特定网址用load txt导入数据,但我遇到了这个
无法将字符串转换为浮点数……有人能帮忙吗,请回复我
我真的是个新手,我用Bing作为我的助手。这些解释很容易理解。我正在学习
第4天,到目前为止唯一遗漏的问题是python 3+中的configparser小写字母。我勉强能
跟上,但目前为止一切顺利。
感谢您的反馈和支持!我们非常感谢!
在输入 `data = pandas.read_csv(url, names=names)` 后,我收到了许多崩溃,这是针对统计摘要的第4天。我查看了其他评论,发现类似问题,更改了我的网址,但仍然崩溃。
>>> #统计摘要
>>> from pandas import read_csv
>>> url = ‘https://goo.gl/bDbBiA’
>>> names=[‘preg’,’plas’,’pres’,’skin’, ‘test’,’mass’,’pedi’,’age’,’class’]
>>> data = read_csv(url, names=names)
回溯(最近一次调用)
File “”, line 1, in
File “C:\Users\court\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\parsers\readers.py”, line 912, in read_csv
return _read(filepath_or_buffer, kwds)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\court\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\parsers\readers.py”, line 577, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\court\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\parsers\readers.py”, line 1407, in __init__
self._engine = self._make_engine(f, self.engine)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\court\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\parsers\readers.py”, line 1661, in _make_engine
self.handles = get_handle(
^^^^^^^^^^^
File “C:\Users\court\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\common.py”, line 716, in get_handle
ioargs = _get_filepath_or_buffer(
^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\court\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\common.py”, line 368, in _get_filepath_or_buffer
with urlopen(req_info) as req
^^^^^^^^^^^^^^^^^
File “C:\Users\court\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.11_qbz5n2kfra8p0\LocalCache\local-packages\Python311\site-packages\pandas\io\common.py”, line 270, in urlopen
return urllib.request.urlopen(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.11_3.11.1520.0_x64__qbz5n2kfra8p0\Lib\urllib\request.py”, line 216, in urlopen
return opener.open(url, data, timeout)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.11_3.11.1520.0_x64__qbz5n2kfra8p0\Lib\urllib\request.py”, line 525, in open
response = meth(req, response)
^^^^^^^^^^^^^^^^^^^
File “C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.11_3.11.1520.0_x64__qbz5n2kfra8p0\Lib\urllib\request.py”, line 634, in http_response
response = self.parent.error(
^^^^^^^^^^^^^^^^^^
File “C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.11_3.11.1520.0_x64__qbz5n2kfra8p0\Lib\urllib\request.py”, line 563, in error
return self._call_chain(*args)
^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.11_3.11.1520.0_x64__qbz5n2kfra8p0\Lib\urllib\request.py”, line 496, in _call_chain
result = func(*args)
^^^^^^^^^^^
File “C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.11_3.11.1520.0_x64__qbz5n2kfra8p0\Lib\urllib\request.py”, line 643, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 404: Not Found
>>> url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv
文件“”,第 1 行
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv
^
SyntaxError: unterminated string literal (detected at line 1)
>>> url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv’
>>> data-read_csv(url,names=names)
回溯(最近一次调用)
File “”, line 1, in
NameError: name ‘data’ is not defined
>>> data = read_csv(url,names=names)
>>> description = data.describe()
>>> print description
文件“”,第 1 行
print description
^^^^^^^^^^^^^^^^^
SyntaxError: Missing parentheses in call to ‘print’. Did you mean print(…)?
>>> print (description)
preg plas … age class
count 768.000000 768.000000 … 768.000000 768.000000
mean 3.845052 120.894531 … 33.240885 0.348958
std 3.369578 31.972618 … 11.760232 0.476951
min 0.000000 0.000000 … 21.000000 0.000000
25% 1.000000 99.000000 … 24.000000 0.000000
50% 3.000000 117.000000 … 29.000000 0.000000
75% 6.000000 140.250000 … 41.000000 1.000000
max 17.000000 199.000000 … 81.000000 1.000000
[8 rprint 9 columns]
我的评论不见了?总之我完成了统计摘要,我不得不下载文件并更改名称
.csv 并放入显式路径而不是网址
在第7课中,准确率:77.086% (5.091%)
你好,Jason。
对numpy数组的实验使我得到了这个线性回归模型的图。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
X = np.array([[1,3,7,9], [2,2,4,4]]).reshape(-1, 1)
Y = np.array([[2,4,6,8], [4,4,4,4]]).reshape(-1, 1)
z = LinearRegression().fit(X, Y)
x = z.coef_
y = z.intercept_
plt.plot(X, Y, ‘o’)
plt.plot(X, x*X+y)
plt.show()
诚挚的问候
你好 Piotrek……感谢您的反馈!如果您有任何问题需要我们协助,请告诉我们。
你好,Jason。
实际上我有一个问题。当我运行第7天(使用重采样方法进行评估)的代码片段时,我得到了这个错误
” raise ValueError(
ValueError: 设置random_state无效,因为shuffle为False。您应该将random_state保留为其默认值(None),或者设置shuffle=True。”
为了运行此代码,将参数shuffle设置为True是否可以?
你好
我第8天的结果是:对数损失:-0.494(0.042)
附注。我非常喜欢参加(7天统计迷你课程)。期待在机器学习掌握中学习。
此致。
感谢您的反馈,karpiotr!继续努力!
import numpy
import pandas
myarray = numpy.array([[1, 2, 3], [4, 5, 6]])
rownames = [‘a’, ‘b’]
colnames = [‘one’, ‘two’, ‘three’]
mydataframe = pandas.DataFrame(myarray, index=rownames, columns=colnames)
print(mydataframe)
结果是
一 二 三
a 1 2 3
b 4 5 6
你好 abidi……感谢你的反馈!继续努力!
你好 Jason,我正在测试《Python机器学习精通》书中第67页和第68页使用波士顿房价数据集的MAE和MSE示例。看起来波士顿房价数据自你编写此书以来已发生变化。我按照书中示例10.3.1和10.3.2操作时出现错误。下面是代码和错误信息
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
filename = r”C:\Users\OlanipeA\Documents\housing.csv”
names = [‘CRIM’, ‘ZN’, ‘INDUS’, ‘CHAS’, ‘NOX’, ‘RM’, ‘AGE’, ‘DIS’, ‘RAD’, ‘TAX’, ‘PTRATIO’,
‘B’, ‘LSTAT’, ‘MEDV’]
dataframe = read_csv(filename, sep=’\s+’, names=names)
array = dataframe.values
X = array[:,0:13]
Y = array[:,13]
kfold = KFold(n_splits=10, random_state=7, shuffle=True)
model = LinearRegression()
scoring = ‘neg_mean_absolute_error’
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print(“MAE: %.3f (%.3f)” % (results.mean(), results.std()))
错误信息
C:\Users\OlanipeA\PycharmProjects\MLpredictivemodelling\.venv\Scripts\python.exe C:\Users\OlanipeA\PycharmProjects\MLpredictivemodelling\main.py
回溯(最近一次调用)
File “C:\Users\OlanipeA\PycharmProjects\MLpredictivemodelling\main.py”, line 361, in
results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
File “C:\Users\OlanipeA\PycharmProjects\MLpredictivemodelling\.venv\lib\site-packages\sklearn\utils\_param_validation.py”, line 213, in wrapper
return func(*args, **kwargs)
File “C:\Users\OlanipeA\PycharmProjects\MLpredictivemodelling\.venv\lib\site-packages\sklearn\model_selection\_validation.py”, line 712, in cross_val_score
cv_results = cross_validate(
File “C:\Users\OlanipeA\PycharmProjects\MLpredictivemodelling\.venv\lib\site-packages\sklearn\utils\_param_validation.py”, line 213, in wrapper
return func(*args, **kwargs)
File “C:\Users\OlanipeA\PycharmProjects\MLpredictivemodelling\.venv\lib\site-packages\sklearn\model_selection\_validation.py”, line 443, in cross_validate
_warn_or_raise_about_fit_failures(results, error_score)
File “C:\Users\OlanipeA\PycharmProjects\MLpredictivemodelling\.venv\lib\site-packages\sklearn\model_selection\_validation.py”, line 529, in _warn_or_raise_about_fit_failures
raise ValueError(all_fits_failed_message)
ValueError
所有10次拟合都失败了。
很可能你的模型配置错误。
你可以尝试将error_score='raise'设置为调试错误。
请您调查一下这个问题好吗?
这是输出
一 二 三
a 1 2 3
b 4 5 6
第3天
(768, 9)
这表明数据集有768行和9列
嗨,Jason,
我的笔记本电脑安装了带有Ubuntu 18.04.6的Linux操作系统。它带有一个名为“python-ai-toolkit”的默认软件。我将其用作我的Python环境。请注意,它支持四个必需的Python库——scipy、numpy、matplotlib、pandas。
第一天作业的答案如下:
===================================================
Python: 3.8.10 (default, Jul 29 2024, 17:02:10)
[GCC 9.4.0]
scipy: 1.9.3
numpy: 1.23.5
pandas: 1.5.2
sklearn: 1.1.3
第二天作业的输出如下:
============================================
一 二 三
a 1 2 3
b 4 5 6
你好 Soumendu……感谢您的反馈!请随时向我们汇报您的进展!
嗨,Jeson,
第6天作业的输出如下。作为数据预处理的一部分,它将数据集中0到7列的值缩放到0到1之间。最后一列(即第8列)保持不变。
[[ 0.64 0.848 0.15 0.907 -0.693 0.204 0.468 1.426]
[-0.845 -1.123 -0.161 0.531 -0.693 -0.684 -0.365 -0.191]
[ 1.234 1.944 -0.264 -1.288 -0.693 -1.103 0.604 -0.106]
[-0.845 -0.998 -0.161 0.155 0.123 -0.494 -0.921 -1.042]
[-1.142 0.504 -1.505 0.907 0.766 1.41 5.485 -0.02 ]]
此致,Soumendu
嗨,Jason,
我运行的第7天作业输出是:准确率:77.086% (5.091%)
此致,Soumendu
嗨,Jason,
第8天作业的输出显示以下错误
—————————————————————————
ValueError 回溯 (最近一次调用)
Cell In[8], line 12
10 X = array[:,0:8]
11 Y = array[:,8]
—> 12 kfold = KFold(n_splits=10, random_state=7)
13 model = LogisticRegression(solver=’liblinear’)
14 scoring = ‘neg_log_loss’
File /snap/python-ai-toolkit/41/lib/python3.8/site-packages/sklearn/model_selection/_split.py:435, in KFold.__init__(self, n_splits, shuffle, random_state)
434 def __init__(self, n_splits=5, *, shuffle=False, random_state=None)
–> 435 super().__init__(n_splits=n_splits, shuffle=shuffle, random_state=random_state)
File /snap/python-ai-toolkit/41/lib/python3.8/site-packages/sklearn/model_selection/_split.py:296, in _BaseKFold.__init__(self, n_splits, shuffle, random_state)
293 raise TypeError(“shuffle must be True or False; got {0}”.format(shuffle))
295 if not shuffle and random_state is not None: # None is the default
–> 296 raise ValueError(
297 “Setting a random_state has no effect since shuffle is ”
298 “False. You should leave ”
299 “random_state to its default (None), or set shuffle=True.”,
300 )
302 self.n_splits = n_splits
303 self.shuffle = shuffle
ValueError: Setting a random_state has no effect since shuffle is False. You should leave random_state to its default (None), or set shuffle=True.
————————————————————————————————————————————-
有什么建议可以纠正代码以消除错误吗?
此致,Soumendu
嗨,Jason,
我上一篇文章中提到的关于第8天作业的错误,现在已经解决了。我在KFold函数中包含了shuffle=True,并在最后一个打印语句中做了一个微小的更正。我运行的代码输出是:Logloss: -0.497 (0.057)
此致,Soumendu
嗨,Jason,
我的 Python 环境中,第 9 天作业的输出是 -38.852320266666666,这是相应数据库的均方误差估计值。
此致,Soumendu
嗨,Jason,
根据我的 Python 环境,第 10 天作业的输出 {准确率(标准差)} 如下:
LR: 0.770865 (0.050905)
LDA: 0.766969 (0.047966)
它表明逻辑回归(LR)和线性判别分析(LDA)对该数据集具有几乎相似的准确率。
嗨,Jason,
在基于网格的参数调整背景下,第11天作业的输出如下:
0.27961755931297233
1.0
第一个数字给出了Ridge回归算法在最佳alpha值1.0下的优化分数。
此致,Soumendu
嗨,Jason,
关于第12天作业,我的python环境对同一数据集(‘pima-indians-diabetes.data.csv’)的随机森林模型估算的分类准确率为0.7656185919343813
此致,Soumendu
嗨,Jason,
关于第13天使用pickle完成模型作业,代码执行后将模型保存在工作目录的“finalized_model.sav”文件中。加载保存的模型后,它给出的模型估计准确率为0.7559055118110236
此致,Soumendu
每天的电子邮件中收到许多“已弃用”警告
在第9天:进行替换——
#dataframe = read_csv(url, delim_whitespace=True, names=names)
dataframe = read_csv(url, sep='\s+', names=names)
并且不要忘记这些用法,无论它们在哪里使用
#kfold = KFold(n_splits=10, random_state=7)
kfold = KFold(n_splits=10, shuffle=True, random_state=7)
这些文章有点令人失望。
我们只是在运行代码,没有解释发生了什么。
或者在展示预测结果时没有深入。
幸运的是,我们可以将整个代码块提交给CoPilot,并得到一个好的但肤浅的解释。
你好 Myles……听起来你正在完成一系列教程或练习,并且遇到了已弃用代码的警告以及代码中发生的事情缺乏更深入的解释。让我来回应你的观点和建议
—
### **1. 已弃用代码的替换**
– **
read_csv()**– 你将
delim_whitespace=True替换为sep='\s+'是正确的。在某些上下文中,delim_whitespace参数已被弃用,因此sep='\s+'(用于空白的正则表达式)是处理空白分隔数据的最新方法。– **
KFold**– 以前,
KFold不需要显式指定shuffle参数,但现在它强制要求shuffle=True或shuffle=False。random_state参数现在也与洗牌相关联,因此此更改对于可重现的结果是强制性的。—
### **2. 文章中缺乏解释**
这似乎是主要问题——仅仅运行代码而不理解
– **为什么使用某些方法。**
– **参数的含义。**
– **结果表明了什么。**
如果你正在使用 CoPilot 或 ChatGPT 生成或解释代码,那么你注意到解释通常是肤浅的,除非你深入挖掘,这是正确的。
—
### **3. 更有意义的学习体验建议**
以下是你可以增强理解和成果的方法
#### **A. 拆解代码**
– **对于
read_csv()**– 此函数将数据从文件或 URL 读取到 DataFrame 中。
sep='\s+'参数指定文件中的列由一个或多个空白字符分隔。– **替代方案**:如果数据结构是固定宽度的(例如,没有明确分隔符的表格数据),请研究
pd.read_fwf()以获得更好的精度。– **对于
KFold**– **目的**:它将你的数据集分成
n_splits(本例中为 10)个折叠,这对于交叉验证很有用。shuffle=True确保在拆分之前随机洗牌数据,防止因数据集中排序而产生的偏差。– **为什么
random_state很重要**:这确保了洗牌是可重现的。#### **B. 添加结果分析**
除了仅仅运行代码块之外,还可以尝试包含
1. **评估指标**:解释如何衡量模型性能(例如,准确率、精确率、召回率、F1 分数)。
2. **输出分析**:打印一些预测并将其与实际结果进行比较。
#### **C. 自定义评论**
在你的代码或单独的 Markdown 文件中添加评论,解释
– 为什么使用特定函数或参数。
– 你期望什么样的输出以及如何解释它。
– 已知限制或潜在的下一步。
—
### **4. 有效使用 Copilot/ChatGPT**
如果你正在利用 CoPilot 或 ChatGPT,你可以要求
– 对函数或算法进行更深入的解释。
– 对代码如何工作的逐步分析。
– 有关更好地理解结果的实验建议。
—
### **5. 代码示例说明**
下面是你的代码片段的更深入解释
python# 使用pandas read_csv加载数据
# sep='\s+' 处理空白作为分隔符
dataframe = read_csv(url, sep='\s+', names=names)
# KFold 交叉验证将数据分成 10 个随机折叠
# shuffle=True 确保数据是随机化的
kfold = KFold(n_splits=10, shuffle=True, random_state=7)
– **步骤 1**:数据集被加载到 pandas DataFrame 中。如果文件中没有提供列标题,则
names参数会分配列标题。– **步骤 2**:
KFold确保每个数据点都有机会同时出现在训练集和测试集中,从而减少过拟合并提供更稳健的模型评估。**为什么这很重要:**
– 正确加载和处理数据集可确保模型以正确的格式接收数据。
– 带有洗牌的交叉验证可确保模型学习模式,而不是受数据顺序的偏见。
—
通过专注于解释概念、调整代码以提高清晰度以及分析结果,你会发现这些练习更有意义!如果你想深入了解任何特定部分,请告诉我。
# 统计摘要
import pandas
data = “diabetes.data.csv”
names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
data = pandas.read_csv(data, names=names)
description = data.describe()
print(description)
preg plas pres skin test mass \
计数 768.000000 768.000000 768.000000 768.000000 768.000000 768.000000
平均值 3.845052 120.894531 69.105469 20.536458 79.799479 31.992578
标准差 3.369578 31.972618 19.355807 15.952218 115.244002 7.884160
最小值 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000 27.300000
50% 3.000000 117.000000 72.000000 23.000000 30.500000 32.000000
75% 6.000000 140.250000 80.000000 32.000000 127.250000 36.600000
最大值 17.000000 199.000000 122.000000 99.000000 846.000000 67.100000
pedi age class
计数 768.000000 768.000000 768.000000
平均值 0.471876 33.240885 0.348958
标准差 0.331329 11.760232 0.476951
最小值 0.078000 21.000000 0.000000
25% 0.243750 24.000000 0.000000
50% 0.372500 29.000000 0.000000
75% 0.626250 41.000000 1.000000
最大值 2.420000 81.000000 1.000000
第2课的发现
一 二 三
a 1 2 3
b 4 5 6
嗨,Jason,
在第3课中,我在从UCI机器学习库下载csv数据集时遇到了挑战。有什么特别的方法吗?关于这个的解释会很有帮助。
这条语句
kfold = KFold(n_splits=10, random_state=7)
在python 3.1中不起作用,你必须删除其中的random_state=7部分,只写
kfold = KFold(n_splits=10)
你完全正确——在 **旧版本的 Python 和 scikit-learn** 中,例如与 **Python 3.1** 兼容的版本,
KFold类**不支持random_state参数**。此参数是在scikit-learn的**后续版本**中引入的,特别是当shuffle=True作为选项添加时。以下是总结
### ✅ 适用于旧版本(例如,Python 3.1 + 旧版 scikit-learn)
pythonfrom sklearn.model_selection import KFold
kfold = KFold(n_splits=10) # 不允许 random_state
### ✅ 适用于新版本(例如,Python ≥3.6 + 最新版 scikit-learn)
pythonfrom sklearn.model_selection import KFold
kfold = KFold(n_splits=10, shuffle=True, random_state=7)
>
random_state仅在shuffle=True也设置时才有效。### 🔺 注意
Python 3.1 已严重过时,现代
scikit-learn版本不支持。如果可能,强烈建议升级到 Python 3.8+ 以获得更好的库兼容性和安全性。詹姆斯,谢谢你的解释