数值输入变量可能具有高度偏斜或非标准分布。
这可能是由数据中的异常值、多峰分布、高度指数分布等引起的。
许多机器学习算法在数值输入变量,甚至是回归情况下的输出变量具有标准概率分布(如高斯(正态)分布或均匀分布)时,更倾向于使用或表现更好。
分位数变换提供了一种自动转换数值输入变量以获得不同数据分布的方法,而后者又可用于作为预测模型的输入。
在本教程中,您将了解如何使用分位数变换来改变数值变量的分布,以提高机器学习的性能。
完成本教程后,您将了解:
- 许多机器学习算法在变量具有高斯或标准概率分布时表现更好。
- 分位数变换是一种将数值输入或输出变量转换为高斯或均匀概率分布的技术。
- 如何使用 QuantileTransformer 更改数值变量的概率分布,以提高预测模型的性能。
开始您的项目,阅读我的新书 数据准备机器学习,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何在机器学习中使用分位数变换
照片由 Bernard Spragg. NZ 提供,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- 更改数据分布
- 分位数变换
- 声纳数据集
- 正态分位数变换
- 均匀分位数变换
更改数据分布
许多机器学习算法在变量分布为高斯分布时表现更好。
回想一下,每个变量的观测值都可以被认为是来自一个概率分布。高斯分布是一种常见的分布,具有熟悉的钟形。它如此普遍,以至于经常被称为“正态”分布。
有关高斯概率分布的更多信息,请参阅教程
有些算法,如 线性回归 和 逻辑回归,明确假设实值变量具有高斯分布。其他非线性算法可能没有此假设,但当变量具有高斯分布时通常表现更好。
这适用于分类和回归任务中的实值输入变量,以及回归任务中的实值目标变量。
一些输入变量可能具有高度偏斜的分布,例如指数分布,其中最常见的观测值聚集在一起。一些输入变量可能存在导致分布高度分散的异常值。
这些顾虑以及其他顾虑,如非标准分布和多模态分布,可能会使数据集难以用各种机器学习模型进行建模。
因此,通常希望将每个输入变量转换为具有标准概率分布,例如高斯(正态)分布或均匀分布。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
分位数变换
分位数变换会将变量的概率分布映射到另一个概率分布。
回想一下,分位数函数,也称为百分点函数(PPF),是累积概率分布(CDF)的倒数。CDF 是一个返回给定值或以下值的概率的函数。PPF 是此函数的倒数,并返回给定概率或以下的值。
分位数函数可以对观测值进行排序或平滑化它们之间的关系,并可以映射到其他分布,例如均匀分布或正态分布。
该变换可以应用于训练数据集中的每个数值输入变量,然后将其作为输入提供给机器学习模型来学习预测建模任务。
此分位数变换在 scikit-learn Python 机器学习库中通过 QuantileTransformer 类 提供。
该类有一个“output_distribution”参数,可以设置为“uniform”或“normal”,默认为“uniform”。
它还提供了一个“n_quantiles”参数,该参数决定了数据集中观测值的映射或排序分辨率。此值必须小于数据集中观测值的数量,默认为 1,000。
我们可以通过一个小的实际示例来演示 QuantileTransformer。我们可以生成一个 随机高斯数 的样本,并通过计算指数来施加分布的偏斜。然后,可以使用 QuantileTransformer 将数据集转换为另一种分布,在这种情况下是回到高斯分布。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 分位数变换的演示 from numpy import exp from numpy.random import randn from sklearn.preprocessing import QuantileTransformer from matplotlib import pyplot # 生成高斯数据样本 data = randn(1000) # 给数据分布增加偏斜 data = exp(data) # 原始数据的直方图(带有偏斜) pyplot.hist(data, bins=25) pyplot.show() # 将数据重塑为行和列 data = data.reshape((len(data),1)) # 分位数变换原始数据 quantile = QuantileTransformer(output_distribution='normal') data_trans = quantile.fit_transform(data) # 变换后数据的直方图 pyplot.hist(data_trans, bins=25) pyplot.show() |
运行示例首先创建一个 1,000 个随机高斯值的样本,并向数据集中添加偏斜。
从偏斜的数据集创建直方图,清晰地显示了分布被推到了最左侧。
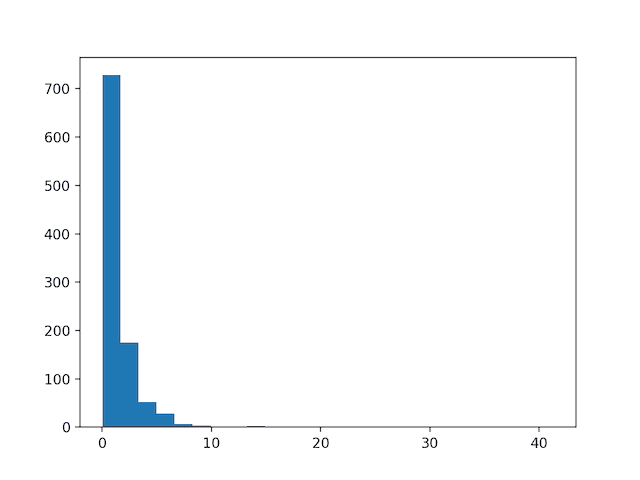
偏斜高斯分布的直方图
然后使用 QuantileTransformer 将数据分布映射为高斯分布并标准化结果,将值居中于均值 0 和标准差 1.0。
创建转换后数据的直方图,显示了高斯形状的数据分布。

分位数变换后偏斜高斯数据的直方图
在接下来的部分中,我们将更详细地研究如何在实际数据集上使用分位数变换。
接下来,我们介绍数据集。
声纳数据集
声纳数据集是用于二元分类的标准机器学习数据集。
它涉及 60 个实值输入和一个二类目标变量。数据集中有 208 个示例,并且类别相当平衡。
基线分类算法使用重复分层 10 折交叉验证可获得约 53.4% 的分类准确率。使用重复分层 10 折交叉验证,最佳性能约为 88%。
该数据集描述了岩石或模拟水雷的声纳回波。
您可以从这里了解更多关于数据集的信息
无需下载数据集;我们将从我们的示例中自动下载它。
首先,让我们加载并总结数据集。完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 加载并总结声纳数据集 from pandas import read_csv from pandas.plotting import scatter_matrix from matplotlib import pyplot # 加载数据集 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv" dataset = read_csv(url, header=None) # 总结数据集的形状 print(dataset.shape) # 总结每个变量 print(dataset.describe()) # 变量的直方图 dataset.hist() pyplot.show() |
运行示例首先总结加载数据集的形状。
这证实了 60 个输入变量、一个输出变量和 208 行数据。
提供了输入变量的统计摘要,显示值是数值,大约在 0 到 1 之间。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
(208, 61) 0 1 2 ... 57 58 59 count 208.000000 208.000000 208.000000 ... 208.000000 208.000000 208.000000 mean 0.029164 0.038437 0.043832 ... 0.007949 0.007941 0.006507 std 0.022991 0.032960 0.038428 ... 0.006470 0.006181 0.005031 min 0.001500 0.000600 0.001500 ... 0.000300 0.000100 0.000600 25% 0.013350 0.016450 0.018950 ... 0.003600 0.003675 0.003100 50% 0.022800 0.030800 0.034300 ... 0.005800 0.006400 0.005300 75% 0.035550 0.047950 0.057950 ... 0.010350 0.010325 0.008525 max 0.137100 0.233900 0.305900 ... 0.044000 0.036400 0.043900 [8 rows x 60 columns] |
最后,为每个输入变量创建直方图。
如果我们忽略图表的杂乱,只关注直方图本身,我们可以看到许多变量具有偏斜分布。
该数据集是使用分位数变换使变量更接近高斯分布的良好候选。
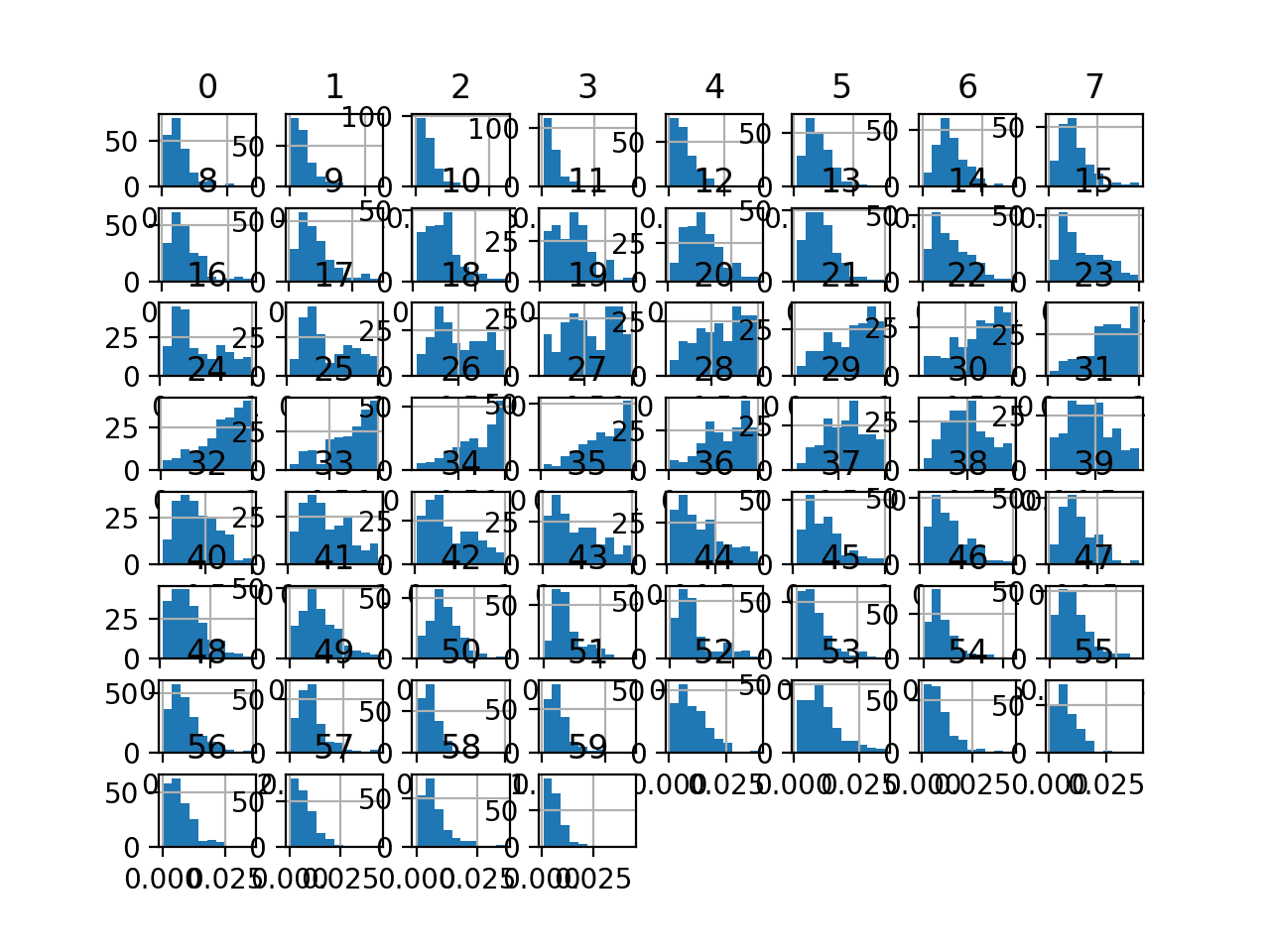
声纳二元分类数据集输入变量的直方图图
接下来,让我们在原始数据集上拟合和评估一个机器学习模型。
我们将使用具有默认超参数的 k-近邻算法,并使用 重复分层 k-折交叉验证对其进行评估。完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 在原始声纳数据集上评估 knn from numpy import mean from numpy import std from pandas import read_csv from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.neighbors import KNeighborsClassifier from sklearn.preprocessing import LabelEncoder from matplotlib import pyplot # 加载数据集 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv" dataset = read_csv(url, header=None) data = dataset.values # 分割为输入和输出列 X, y = data[:, :-1], data[:, -1] # 确保输入是浮点数,输出是整数标签 X = X.astype('float32') y = LabelEncoder().fit_transform(y.astype('str')) # 定义和配置模型 model = KNeighborsClassifier() # 评估模型 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') # 报告模型性能 print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例评估 KNN 模型在原始声纳数据集上的性能。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
我们可以看到,该模型实现了大约 79.7% 的平均分类准确率,这表明它具有技能(优于 53.4%),并且接近良好性能(88%)。
|
1 |
准确率:0.797 (0.073) |
接下来,让我们探讨对数据集进行正态分位数变换。
正态分位数变换
通常希望将输入变量转换为正态概率分布,以提高建模性能。
我们可以使用 QuantileTransformer 类应用分位数变换,并将“output_distribution”参数设置为“normal”。我们还必须将“n_quantiles”参数设置为小于训练数据集观测值数量的值,在本例中为 100。
定义后,我们可以调用 fit_transform() 函数并将其传递给我们的数据集,以创建我们数据集的量化转换版本。
|
1 2 3 4 |
... # 对数据集执行正态分位数变换 trans = QuantileTransformer(n_quantiles=100, output_distribution='normal') data = trans.fit_transform(data) |
让我们在声纳数据集上尝试一下。
下面列出了对声纳数据集进行正态分位数变换并绘制结果直方图的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 可视化声纳数据集的正态分位数变换 from pandas import read_csv from pandas import DataFrame from pandas.plotting import scatter_matrix from sklearn.preprocessing import QuantileTransformer from matplotlib import pyplot # 加载数据集 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv" dataset = read_csv(url, header=None) # 仅检索数字输入值 data = dataset.values[:, :-1] # 对数据集执行正态分位数变换 trans = QuantileTransformer(n_quantiles=100, output_distribution='normal') data = trans.fit_transform(data) # 将数组转换回数据框 dataset = DataFrame(data) # 变量的直方图 dataset.hist() pyplot.show() |
运行该示例会转换数据集并绘制每个输入变量的直方图。
与原始数据相比,我们可以看到每个变量的直方图形状看起来非常像高斯分布。
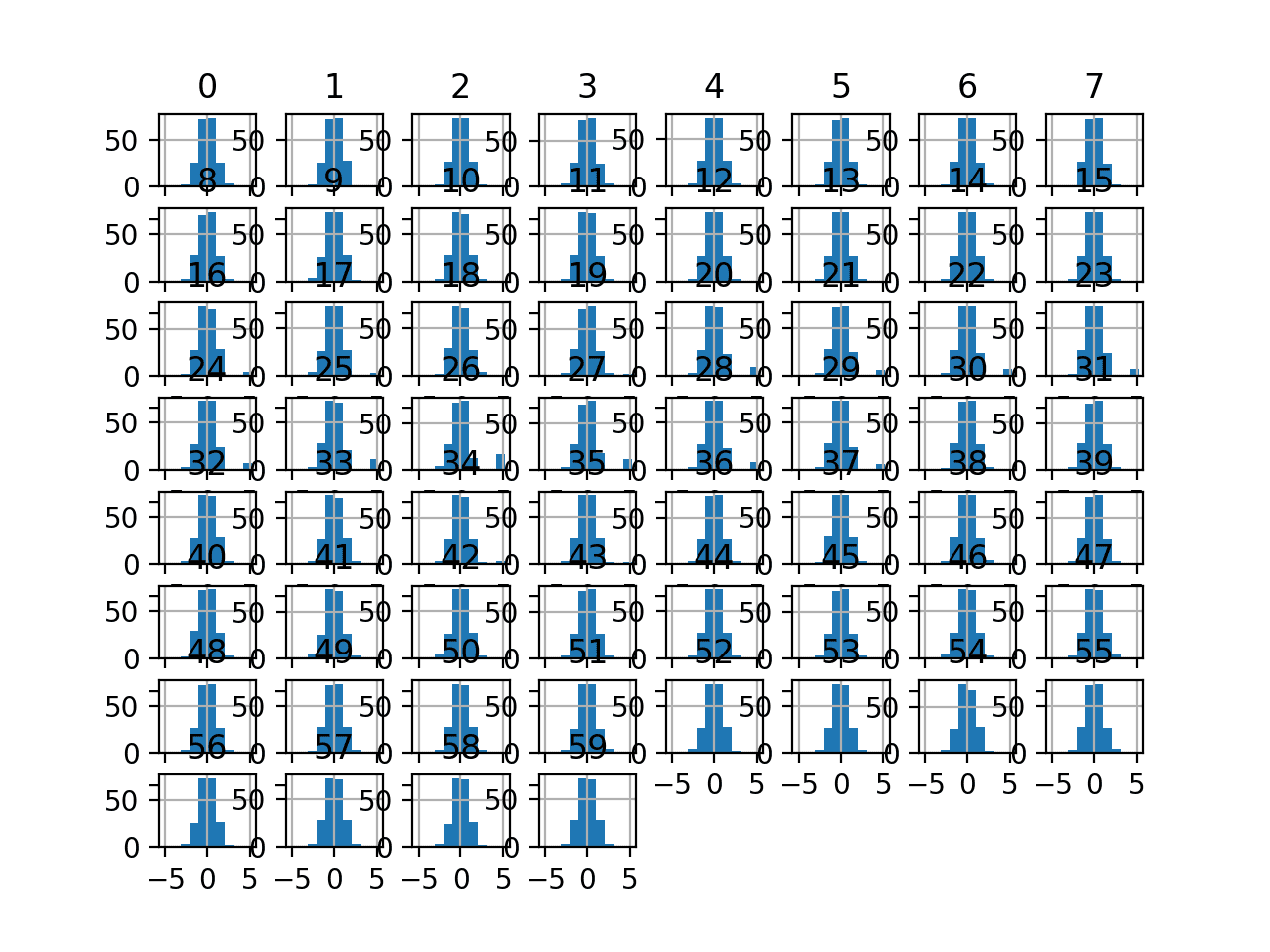
声纳数据集的正态分位数变换输入变量的直方图
接下来,让我们评估与上一节相同的 KNN 模型,但这次是在数据集的正态分位数变换上。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 在具有正态分位数变换的声纳数据集上评估 knn from numpy import mean from numpy import std from pandas import read_csv from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.neighbors import KNeighborsClassifier from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import QuantileTransformer from sklearn.pipeline import Pipeline from matplotlib import pyplot # 加载数据集 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv" dataset = read_csv(url, header=None) data = dataset.values # 分割为输入和输出列 X, y = data[:, :-1], data[:, -1] # 确保输入是浮点数,输出是整数标签 X = X.astype('float32') y = LabelEncoder().fit_transform(y.astype('str')) # 定义管道 trans = QuantileTransformer(n_quantiles=100, output_distribution='normal') model = KNeighborsClassifier() pipeline = Pipeline(steps=[('t', trans), ('m', model)]) # 评估管道 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) n_scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') # 报告管道性能 print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
运行示例,我们可以看到正态分位数变换将性能从没有变换的 79.7% 准确率提升到变换后的约 81.7%。
|
1 |
准确率:0.817 (0.087) |
接下来,让我们更详细地研究均匀分位数变换。
均匀分位数变换
有时将高度指数分布或多模态分布转换为均匀分布是有益的。
这对于具有大且稀疏值范围的数据特别有用,例如异常值常见而非罕见。
我们可以通过定义 QuantileTransformer 类并将其“output_distribution”参数设置为“uniform”(默认值)来应用变换。
|
1 2 3 4 |
... # 对数据集执行均匀分位数变换 trans = QuantileTransformer(n_quantiles=100, output_distribution='uniform') data = trans.fit_transform(data) |
下面的示例应用了均匀分位数变换,并为每个转换后的变量创建了直方图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 可视化声纳数据集的均匀分位数变换 from pandas import read_csv from pandas import DataFrame from pandas.plotting import scatter_matrix from sklearn.preprocessing import QuantileTransformer from matplotlib import pyplot # 加载数据集 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv" dataset = read_csv(url, header=None) # 仅检索数字输入值 data = dataset.values[:, :-1] # 对数据集执行均匀分位数变换 trans = QuantileTransformer(n_quantiles=100, output_distribution='uniform') data = trans.fit_transform(data) # 将数组转换回数据框 dataset = DataFrame(data) # 变量的直方图 dataset.hist() pyplot.show() |
运行该示例会转换数据集并绘制每个输入变量的直方图。
与原始数据相比,我们可以看到每个变量的直方图形状看起来非常均匀。

声纳数据集均匀分位数变换输入变量的直方图
接下来,让我们评估与上一节相同的 KNN 模型,但这次是在原始数据集的均匀分位数变换上。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 在具有均匀分位数变换的声纳数据集上评估 knn from numpy import mean from numpy import std from pandas import read_csv from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.neighbors import KNeighborsClassifier from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import QuantileTransformer from sklearn.pipeline import Pipeline from matplotlib import pyplot # 加载数据集 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv" dataset = read_csv(url, header=None) data = dataset.values # 分割为输入和输出列 X, y = data[:, :-1], data[:, -1] # 确保输入是浮点数,输出是整数标签 X = X.astype('float32') y = LabelEncoder().fit_transform(y.astype('str')) # 定义管道 trans = QuantileTransformer(n_quantiles=100, output_distribution='uniform') model = KNeighborsClassifier() pipeline = Pipeline(steps=[('t', trans), ('m', model)]) # 评估管道 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) n_scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') # 报告管道性能 print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
运行示例,我们可以看到均匀变换将性能从没有变换的 79.7% 准确率提升到变换后的约 84.5%,优于达到 81.7% 分数的正态变换。
|
1 |
准确率:0.845 (0.074) |
我们将分位数数量选择为任意值,在本例中为 100。
可以调整此超参数,以探索变换分辨率对模型结果技能的影响。
下面的示例执行此实验,并绘制了从 1 到 99 的不同“n_quantiles”值的平均准确率图。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
# 探索分位数数量对分类准确率的影响 from numpy import mean from numpy import std from pandas import read_csv from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.neighbors import KNeighborsClassifier from sklearn.preprocessing import QuantileTransformer from sklearn.preprocessing import LabelEncoder from sklearn.pipeline import Pipeline from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): # 加载数据集 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv" dataset = read_csv(url, header=None) data = dataset.values # 分离输入和输出列 X, y = data[:, :-1], data[:, -1] # 确保输入为浮点数,输出为整数标签 X = X.astype('float32') y = LabelEncoder().fit_transform(y.astype('str')) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() for i in range(1,100): # 定义管道 trans = QuantileTransformer(n_quantiles=i, output_distribution='uniform') model = KNeighborsClassifier() models[str(i)] = Pipeline(steps=[('t', trans), ('m', model)]) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise') 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results = list() for name, model in models.items(): scores = evaluate_model(model, X, y) results.append(mean(scores)) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.plot(results) pyplot.show() |
运行示例报告了“n_quantiles”参数每个值的平均分类准确率。
注意:由于算法或评估程序的随机性,或者数值精度的差异,您的结果可能会有所不同。考虑运行几次示例并比较平均结果。
我们可以看到,令人惊讶的是,较小的值带来了更高的准确率,例如 4 的准确率约为 85.4%。
|
1 2 3 4 5 6 7 8 9 10 11 |
>1 0.466 (0.016) >2 0.813 (0.085) >3 0.840 (0.080) >4 0.854 (0.075) >5 0.848 (0.072) >6 0.851 (0.071) >7 0.845 (0.071) >8 0.848 (0.066) >9 0.848 (0.071) >10 0.843 (0.074) ... |
创建折线图,显示变换中使用的分位数数量与结果模型的分类准确率。
我们可以看到 10 以下的值有一个提升,之后性能下降并趋于平缓。
结果强调,探索不同的分布和分位数数量以获得更好的性能是有益的。
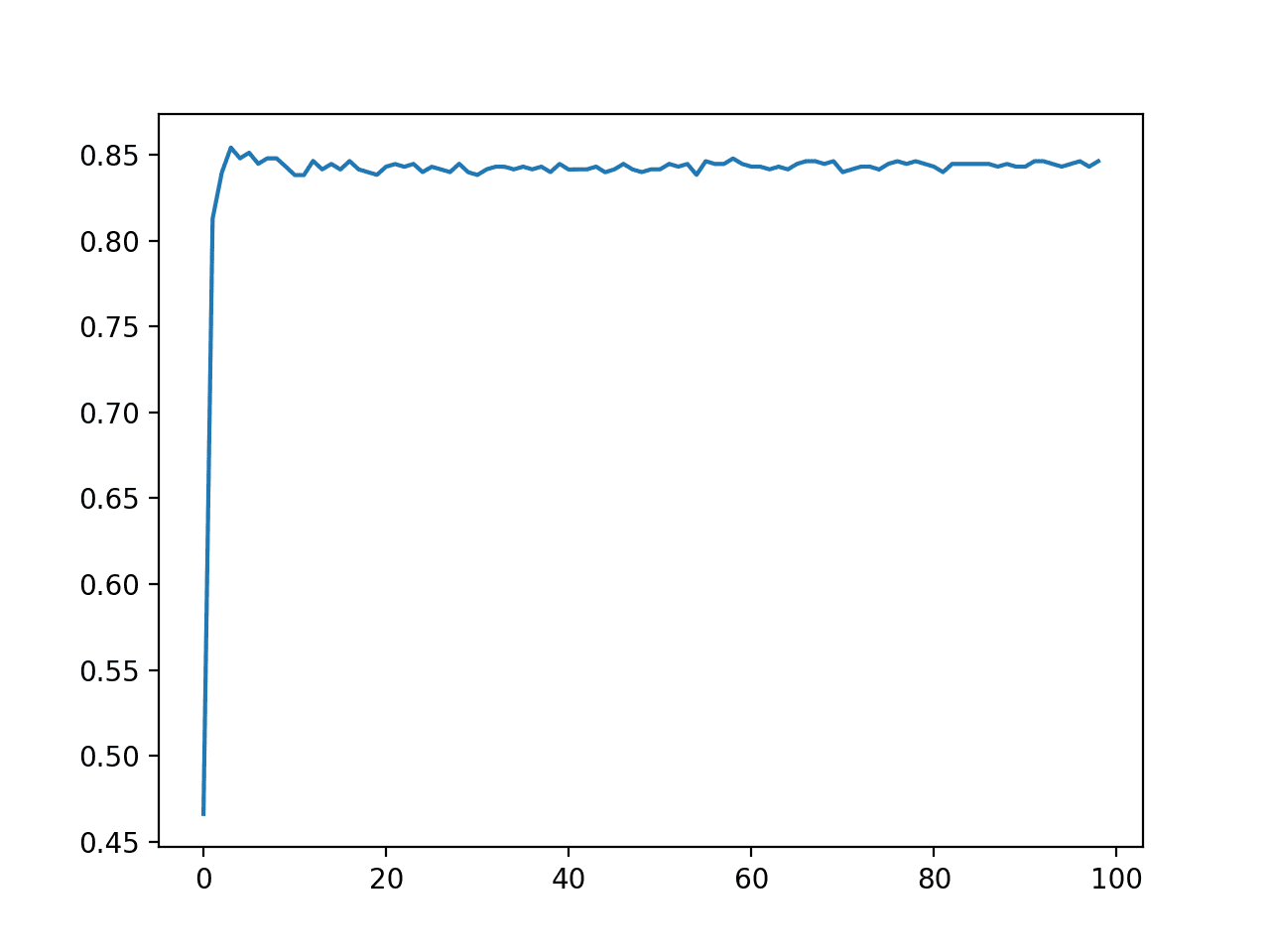
声纳数据集上 KNN 分类准确率与分位数数量的折线图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
数据集 (Dataset)
API
文章
总结
在本教程中,您了解了如何使用分位数变换来改变数值变量的分布,以提高机器学习的性能。
具体来说,你学到了:
- 许多机器学习算法在变量具有高斯或标准概率分布时表现更好。
- 分位数变换是一种将数值输入或输出变量转换为高斯或均匀概率分布的技术。
- 如何使用 QuantileTransformer 更改数值变量的概率分布,以提高预测模型的性能。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







决策树/梯度提升树在数值变量具有高斯或标准概率分布时是否更倾向于使用或表现更好?
不行。
决策树/提升树在数值变量具有高斯或标准概率分布时表现最差吗?
你好,Paul……以下资源可能会有所帮助。
https://towardsdatascience.com/decision-trees-d07e0f420175
你好,Jason,这是一篇很棒的教程。谢谢。
我的问题是,高标准差值意味着高准确率还是低准确率?
其次,你有没有关于如何编写可重用管道类的教程?
这意味着模型性能的估计方差更大。
你第二个问题是什么意思?
你好 Jason,教程很棒!非常感谢。也许值得指出问题描述中的一个小笔误。你写的是“该数据集描述了岩石或模拟地雷的雷达回波。”但应该是“该数据集描述了岩石或模拟地雷的声纳回波。”
不客气!
谢谢!
非常有用的,非常感谢。我注意到这里有“该类有一个 `output_distribution` 参数,可以设置为 ‘uniform’ 或 ‘random’,默认为 ‘uniform’。”,而不是‘random’,应该是‘normal’。如果我错了,请纠正我。
不客气!
谢谢,已修复!
晚上好,我是俄罗斯的一名学生,我现在正在准备一份关于“使用股票市场数据调整的机器学习”主题的研究报告。我需要你的帮助。
我对股票市场不太了解,抱歉。
https://machinelearning.org.cn/faq/single-faq/can-you-help-me-with-machine-learning-for-finance-or-the-stock-market
嗨,Jason,
感谢分享!🙂
我正在处理一个不平衡分类问题,一些列具有右偏分布(它们与金钱有关,所以大多数都接近于零)。
如果我使用对数变换或 QuantileTransformer 转换这些列,准确率会变差。
即使我移除异常值(98%/99% 分位数)来去除最高值,准确率也变差了。
顺便说一下,我使用的是带有 `class_weight="balanced"` 的逻辑回归。
为什么会这样?
我本以为准确率会提高。
谢谢
回答“为什么”这类问题很难,甚至不可能。这就是我们进行实验的原因。
我唯一的问题是,如果你在用高斯变换进行转换后执行了一个简单的回归——假设协变量呈正态分布——那么你如何解释结果?
你具体指的是什么?也许你可以详细说明一下问题?
当然——假设我的协变量非常右偏(约98%的协变量落在一个分位数内)。如果我使用分位数变换,并以更接近高斯分布的输出分布进行转换,然后使用相似的广义线性模型进行回归,我将如何解释系数、标准误和 p 值?
肯定,这与原来的解释不同吧?我之所以这样问,是因为我读了这篇论文:http://people.stat.sfu.ca/~lockhart/Research/Papers/ChenLockhartStephens.pdf
好问题,我没有直接的答案。
你好 Jason,感谢你所有的帖子,它们真的让我对这个领域产生了兴趣。
我有一个问题,这种转换在时间序列预测中有用吗?更具体地说,用于拟合 SARIMA 等模型?
不客气。
这可能对时间序列有帮助。也许可以尝试一下,并将结果与原始数据和其他变换(如幂变换)进行比较。
你好 Jason,
在为“神经网络”准备数据时,是否有方法可以确定何时进行转换以及何时不进行?例如上面提到的示例。通过 QuantileTransform 从泊松分布转换为高斯分布。
如果我说偏斜分布是导致我们在训练过程中出现的损失图中的锯齿状图形的原因之一,因为许多观测值移到了决策边界附近?这就是我们进行转换的原因吗?
谢谢,
经验告诉我,我们无法准确预测什么会起作用。
当它们为您的模型和数据集带来更好的性能时,就使用它们。
例如,尝试一下看看。
你好 Jason!!你能看出分位数变换(`output_distribution="nomal"`)和 StandardScaler 之间有什么区别吗?
谢谢!
原因不同,效果相似。
你好 Jason。一如既往的好教程。
我的问题是关于回归问题。假设你的目标(因变量)的经验分布既不是均匀的也不是高斯的。将自变量进行分位数缩放,使其输出分布与目标分布匹配,这是否是一个好选择?
你还会简单地用正态分布或均匀分布缩放自变量,而不缩放目标变量吗?
也许可以尝试一下,并与其他数据准备方法进行比较。
嗨,Jason,
非常感谢这篇文章。我有一个评论,可能会帮助到别人,还有一个问题。
– 评论:我使用分位数变换(QuantileTransformer)处理了一个具有不连续值索引的数据框,当使用转换后的数据框进行训练时,我收到一个错误:“输入包含 NaN、无穷大或对于 `dtype('float64')` 过大的值”。即使没有 NaN、正无穷大或负无穷大的值。有人通过在变换之前重置索引来解决问题,这对我来说也有效。
– 问题:我看到 sklearn 中有两个分位数变换(1)`sklearn.preprocessing.QuantileTransformer` 和(2)`sklearn.preprocessing.quantile_transform`。它说它们都是等效函数,并且在估计器 API 上有所不同。让我印象深刻的是,在第二个中有一个数据泄露风险的警告,并且说“一个常见的错误是在将数据拆分为训练集和测试集之前将其应用于整个数据。”你知道为什么这是一个错误吗?
谢谢
bryson_je
最终规则是,在您真正使用测试集之前,整个管道都应该对测试集进行未见过(unseen)的处理。因此,测试集不应该在预处理阶段暴露。您可以使用训练数据来拟合您的预处理器,并将其用于测试集。但您不应该用训练数据和测试数据一起拟合,因为如果我正在读取处理后的训练数据,我可能会以某种方式猜测出测试数据是什么样子的。
谢谢 Adrian。
bryson_je