在深入了解你正在处理的机器学习问题时,你需要亲密接触你的数据。
我个人有时觉得这一步很繁琐,只想赶快 定义我的测试环境,但我知道它总能发现一些值得测试的想法和假设。因此,我使用一个循序渐进的过程来捕获关于实际数据集的最小观察数,然后再进行应用机器学习的这一步。

快速粗略的数据分析
图片来源: timparkinson,部分权利保留
在本篇文章中,你将发现我快速简便的数据集分析流程,从中获得最小的观察结果(以及最少的理解)。
用我的新书 《Weka 机器学习精通》 启动你的项目,书中包含分步教程和所有示例的清晰截图。
数据分析
数据分析步骤的目的是通过更好地理解数据来提高对问题的理解。
这包括提供多种不同的方式来描述数据集,以抓住和测试可以在后续实验中进行测试的观察和假设。
我用于描述给定数据集的两种不同方法是:
- 汇总数据:描述数据和数据分布。
- 可视化数据:创建数据的各种图形摘要。
关键在于从不同角度或视图来查看数据集,以从中获得见解。
1. 汇总数据
汇总数据是描述数据实际结构。我通常使用许多自动化工具来描述属性分布等内容。我喜欢汇总数据的最小方面是结构和分布。
数据结构
汇总数据结构是描述属性的数量和数据类型。例如,通过此过程可以为数据准备步骤中的转换提供思路,将属性从一种类型转换为另一种类型(例如,实数到序数或序数到二元)。
此步骤的一些启发性问题包括:
- 有多少个属性和实例?
- 每个属性的数据类型是什么(例如,名义型、序数型、整数型、实数型等)?
数据分布
汇总每个属性的分布也可以为数据准备步骤中的可能数据转换提供思路,例如分箱、标准化和Z-score标准化的需要和效果。
我喜欢捕获每个实数值属性的分布摘要。这通常包括最小值、最大值、中位数、众数、均值、标准差和缺失值的数量。
此步骤的一些启发性问题包括:
- 为每个实数值属性创建五数摘要。
- 类别属性值的分布是什么?
了解类别属性的分布(或回归输出变量的均值)很有用,因为你可以用它来定义预测模型的最小准确率。
例如,如果一个二元分类问题(2个类别)的分布是 80% 苹果和 20% 香蕉,那么预测器可以预测每个测试实例为“苹果”,并确保达到 80% 的准确率。这是所有测试环境中的算法都必须超越的最差情况算法,用于评估算法。
此外,如果有时间或兴趣,我喜欢使用参数(皮尔逊)和非参数(斯皮尔曼)相关系数来生成成对属性相关性的摘要。这可以突出可能被移除的属性(它们之间高度相关)以及可能具有高度预测性的属性(与结果属性高度相关)。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
2. 可视化数据
可视化数据是创建汇总数据的图形,捕获它们并研究其中有趣的结构。
可创建的图表数量似乎无穷无尽(尤其是在 R 等软件中),因此我倾向于保持简单,专注于直方图和散点图。
属性直方图
我喜欢创建所有属性的直方图并标记类别值。我喜欢这样做是因为我在学习机器学习时大量使用 Weka,它能为您完成这个任务。尽管如此,在 R 等其他软件中也很容易做到。
图形化地呈现离散分布可以快速突出可能的分布族(如正态分布或指数分布)以及类别值如何映射到这些分布。
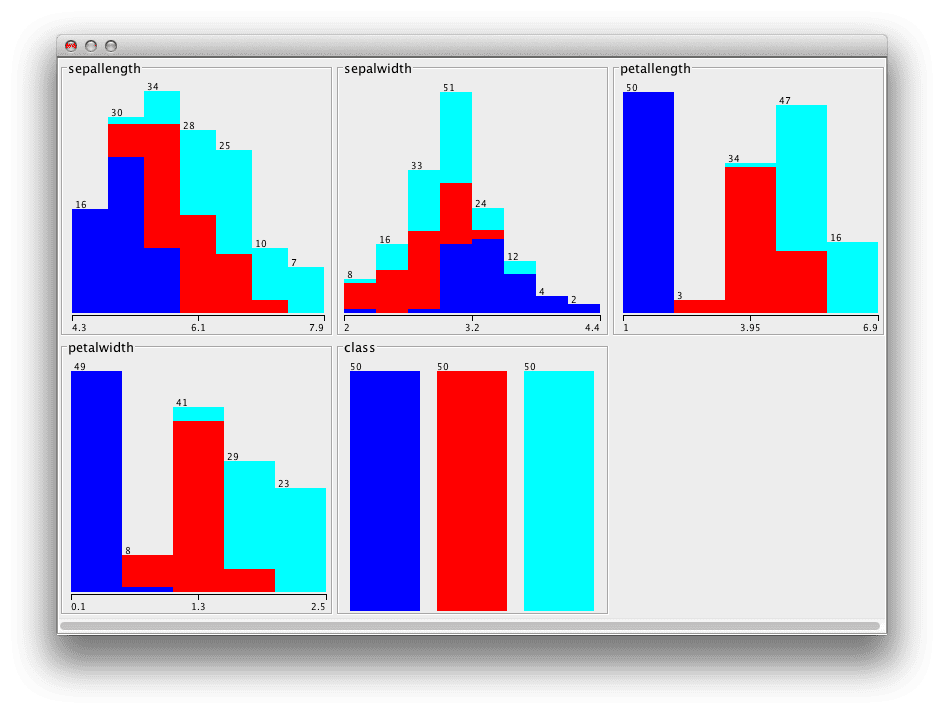
显示类别值的属性直方图
此步骤的一些启发性问题包括:
- 显示了哪些分布族(如果有)?
- 属性中是否存在明显映射到类别值的结构?
成对散点图
散点图将一个属性绘制在每个轴上。此外,可以通过散点图的颜色映射到类别值来添加第三个轴。可以为所有属性对创建成对散点图。
这些图形可以快速突出属性之间的二维结构(如相关性),以及属性到类别值的映射中跨属性的趋势。
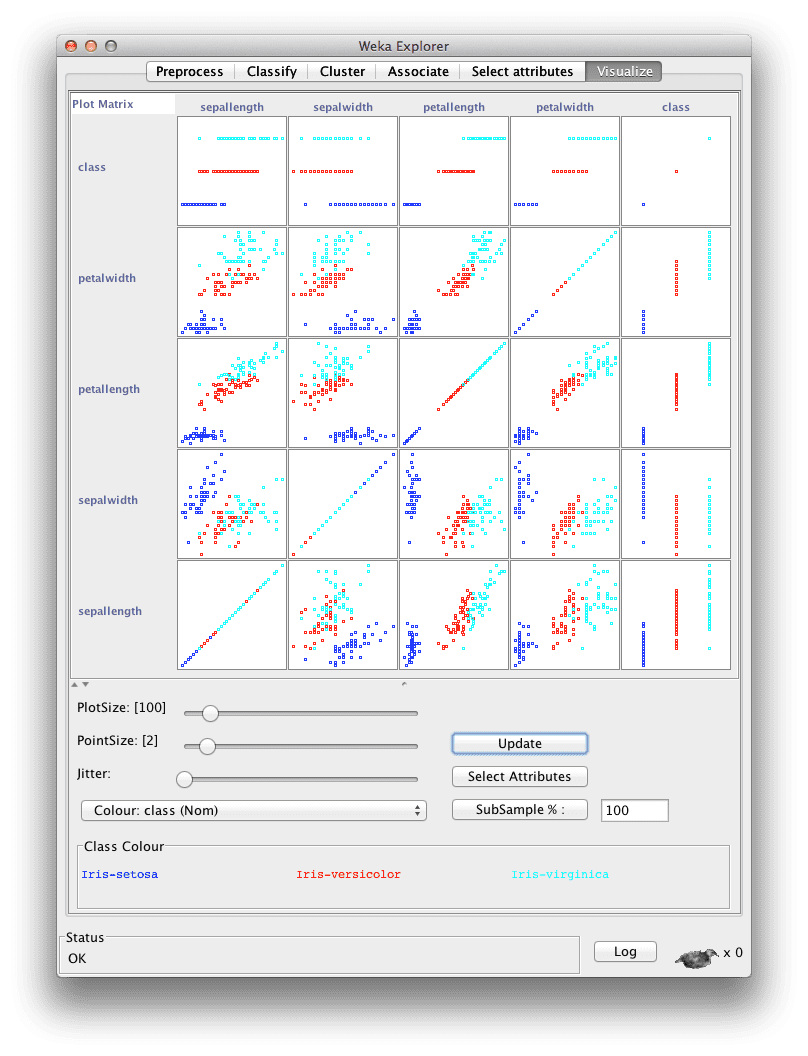
显示类别值的成对散点图
此步骤的一些启发性问题包括:
- 显示了哪些有趣的二维结构?
- 属性到类别值之间显示了哪些有趣的关联?
总结
在本篇文章中,你发现了一个数据分析流程,旨在创建数据的不同视图,以引发对数据的观察和假设。
使用的两种方法是:
- 汇总数据:描述数据和数据分布。
- 可视化数据:创建数据的各种图形摘要。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






谢谢分享
不客气!
非常有趣,感谢分享。
哇,我觉得这个话题太棒了。我认为我需要在数据可视化方面做很多工作,并更多地了解它。谢谢 Jason。
谢谢,非常好!
感谢分享。
我有一个问题:如果我的数据中包含大量缺失值,我是否需要在可视化数据并将其分割为训练集和测试集之前进行插补,然后再进行进一步的分析?
Yvette,这是一个很好的问题。
我建议在处理前后都进行可视化。使用处理前的数据来了解原始数据的外观。应用转换并插补缺失值/删除缺失值等,然后再次可视化,了解其效果。还要在处理前后计算统计数据(甚至按类别计算统计数据),以了解你如何改变了数据的分布。
希望这能有所帮助。
好文章,Jason。我认为了解数据是工作的 80%。很多时候我们急于进入模型选择和调优阶段,而没有真正花足够的时间与数据打交道。有时,在以特定方式转换数据后,简单的模型(如线性回归)就足够了,但相反,我们却花费数天时间去调整一个不必要的集成模型!这在 Kaggle 竞赛中非常普遍。
再次感谢这些信息!
我同意。对数据的深入理解和对问题的细致表述非常重要。
👋