在为建模选择和准备数据之前,您需要了解您拥有的东西。
如果您使用 Python 进行机器学习,Pandas 是一个可以帮助您更好地理解数据的库。
在这篇文章中,您将发现一些用于 Pandas 的快速肮脏的技巧,以提高您对数据结构、分布和关系的理解。
通过我的新书《Machine Learning Mastery With Python》开始您的项目,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2018年3月更新:添加了替代链接以下载数据集,因为原始链接似乎已被删除。
数据分析
数据分析就是关于提出和回答关于您数据的问题。
作为一名机器学习从业者,您可能对您正在工作的领域不太熟悉。最好有领域专家在场,但这并非总是可能的。
当您学习应用机器学习时,无论是使用标准机器学习数据集、咨询还是处理竞赛数据集,都会遇到这些问题。
您需要激发关于您数据的疑问,以便您可以进行追查。您需要更好地理解您拥有的数据。您可以通过总结和可视化数据来实现这一点。
Pandas
Pandas Python 库专为快速数据分析和操作而构建。它的简洁性令人惊叹,如果您在 R 等其他平台上处理过这项任务,它也会很熟悉。
Pandas 的优势似乎在于数据操作方面,但它提供了非常方便易用的数据分析工具,包装了 statsmodels 中的标准统计方法和 matplotlib 中的绘图方法。
糖尿病发病
我们需要一个小型数据集,您可以使用它来探索 Pandas 的各种数据分析技巧。
UIC 机器学习存储库提供了大量的标准机器学习数据集,供您学习和练习应用机器学习。我最喜欢的是 Pima Indians 糖尿病数据集。
该数据集描述了女性 Pima 印第安人根据其病历详细信息确定糖尿病是否发病。(更新:可在此处下载)。下载数据集并将其保存到当前工作目录中,文件名为 pima-indians-diabetes.data。
总结数据
我们将首先通过查看数据的结构来了解我们拥有的数据。
加载数据
首先将 CSV 数据从文件加载到内存中作为数据框。我们知道提供的数据名称,因此在从文件加载数据时将设置这些名称。
|
1 2 3 |
导入 pandas 为 pd names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = pd.read_csv('pima-indians-diabetes.data', names=names) |
了解更多关于 Pandas IO 函数和 read_csv 函数。
描述数据
现在我们可以查看数据的形状。
我们可以通过直接打印数据框来查看数据的前 60 行。
|
1 |
print(data) |
我们可以看到所有数据都是数字,并且最后列的 class 值是我们想要预测的因变量。
在数据转储的末尾,我们可以看到数据框本身的描述,共有 768 行和 9 列。所以现在我们对数据的形状有了一个概念。
接下来,我们可以通过查看摘要统计信息来了解每个属性的分布情况。
|
1 |
print(data.describe()) |
这将显示一个表格,其中包含我们数据框中 9 个属性的详细分布信息。具体来说:计数、均值、标准差、最小值、最大值以及 25%、50%(中位数)、75% 的百分位数。
我们可以查看这些统计数据并开始注意到有关我们问题的有趣事实。例如,平均妊娠次数为 3.8,最低年龄为 21,有些人身体质量指数为 0,这是不可能的,表明某些属性值应被标记为缺失。
了解更多关于 DataFrame 上的 describe 函数。
可视化数据
图形更能说明属性的分布和关系。
尽管如此,仔细查看统计数据仍然很重要。每次您以不同的方式审查数据时,您都会注意到不同的方面,并可能获得对问题的不同见解。
Pandas 使用 matplotlib 创建图形,并提供方便的函数来实现这一点。您可以 了解更多关于 Pandas 中的数据可视化。
特征分布
第一个也是最容易查看的属性是每个属性的分布。
我们可以开始查看每个属性的分布,通过查看箱形图和须须图。
|
1 2 |
import matplotlib.pyplot as plt data.boxplot() |
此代码片段更改了绘图样式(通过 matplotlib)为默认样式,该样式看起来更好。
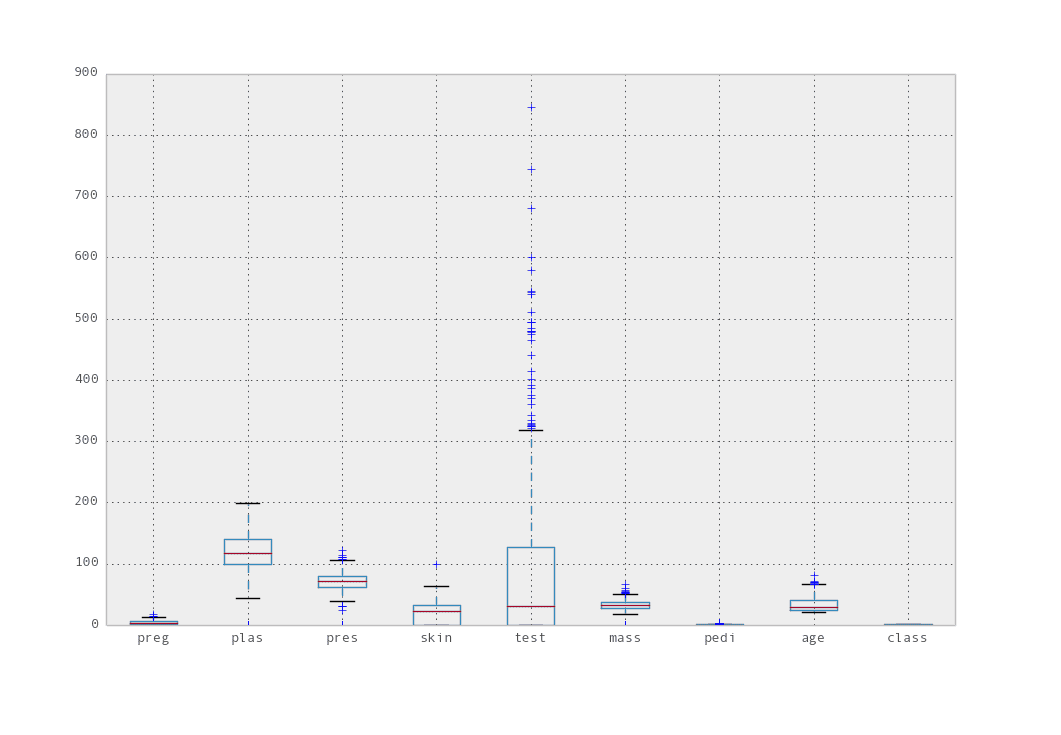
属性箱须图
我们可以看到 test 属性有很多异常值。我们还可以看到 plas 属性似乎具有相对均匀的正态分布。我们还可以通过将值离散化到存储桶中并查看每个存储桶中的频率作为直方图来查看每个属性的分布。
|
1 |
data.hist() |
这使您可以注意到属性分布的有趣特性,例如像 pres 和 skin 这样的属性的可能正态分布。
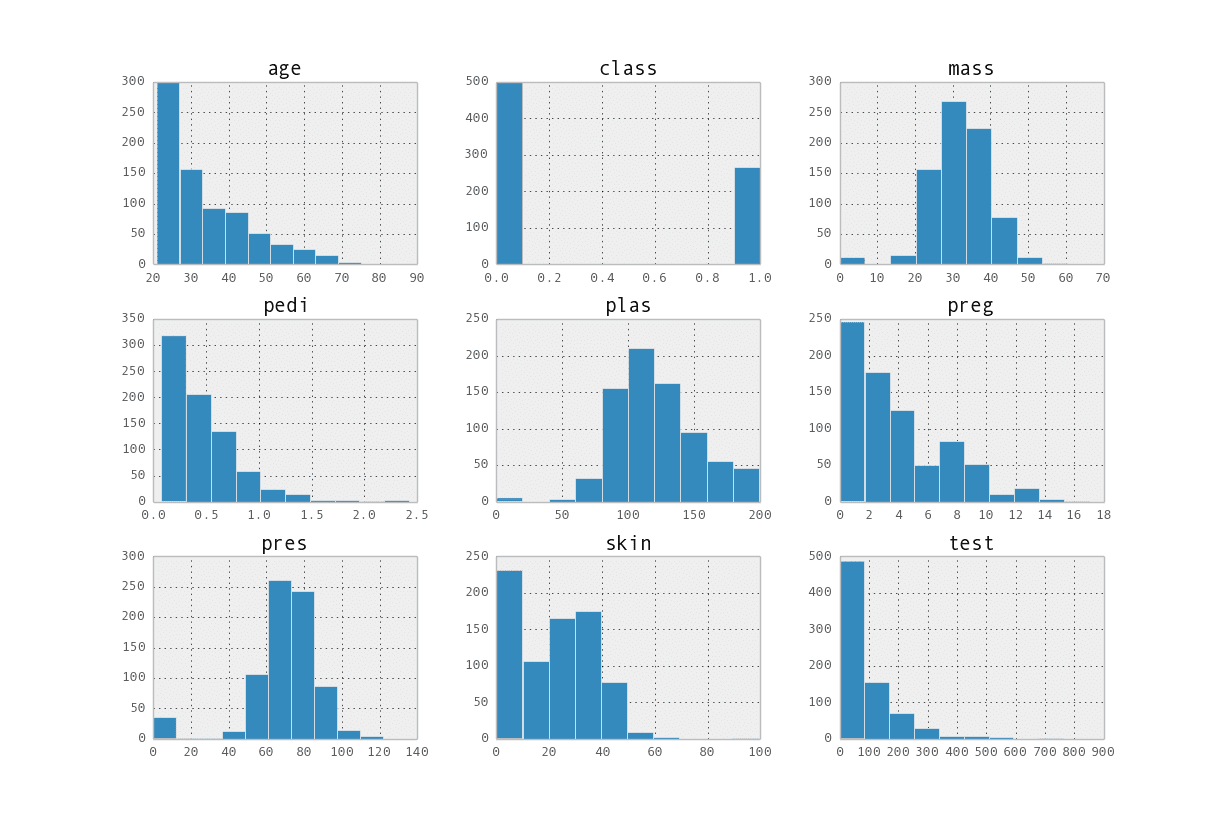
属性直方图矩阵
您可以了解更多关于 DataFrame 上的 boxplot 和 hist 函数。
特征-类别关系
下一个重要的关系是每个属性与类别属性的关系。
一种方法是可视化每个类别的实例的属性分布,并注意差异。您可以为每个属性生成一个直方图矩阵,并为每个类别值生成一个直方图矩阵,如下所示:
|
1 |
data.groupby('class').hist() |
数据按类别属性(两组)分组,然后为每个组中的属性创建直方图矩阵。结果是两个图像。
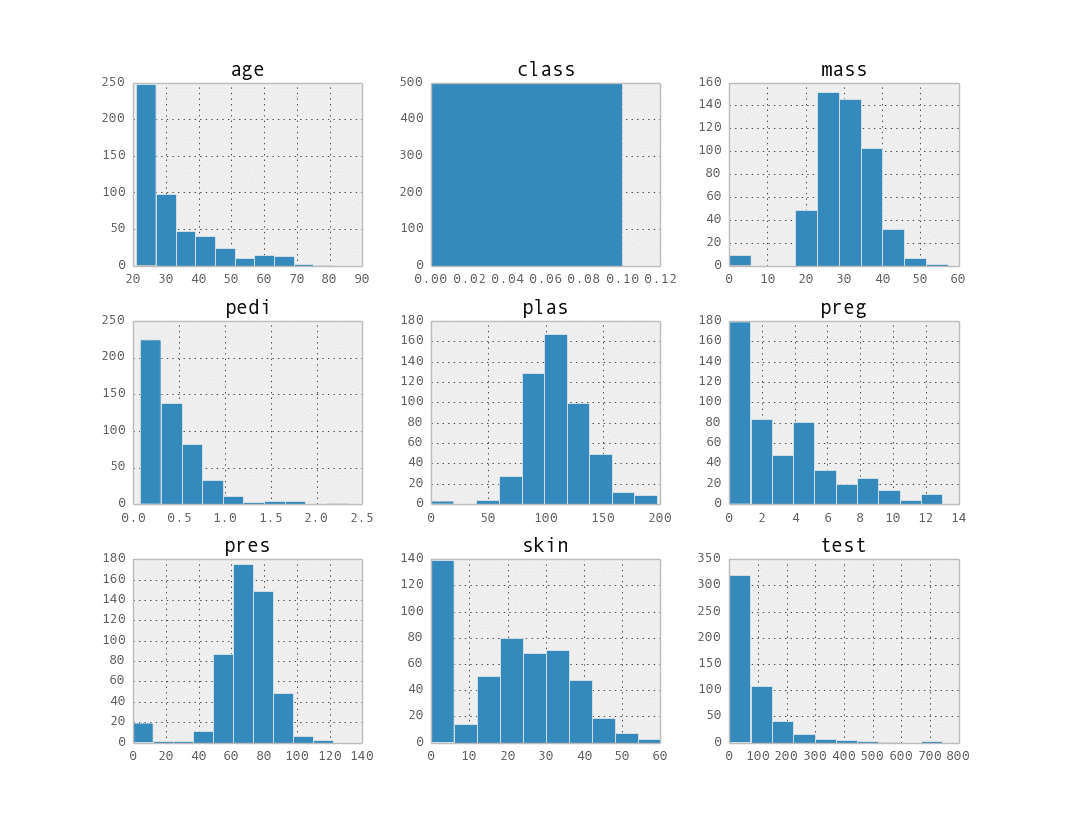
类别 0 的属性直方图矩阵
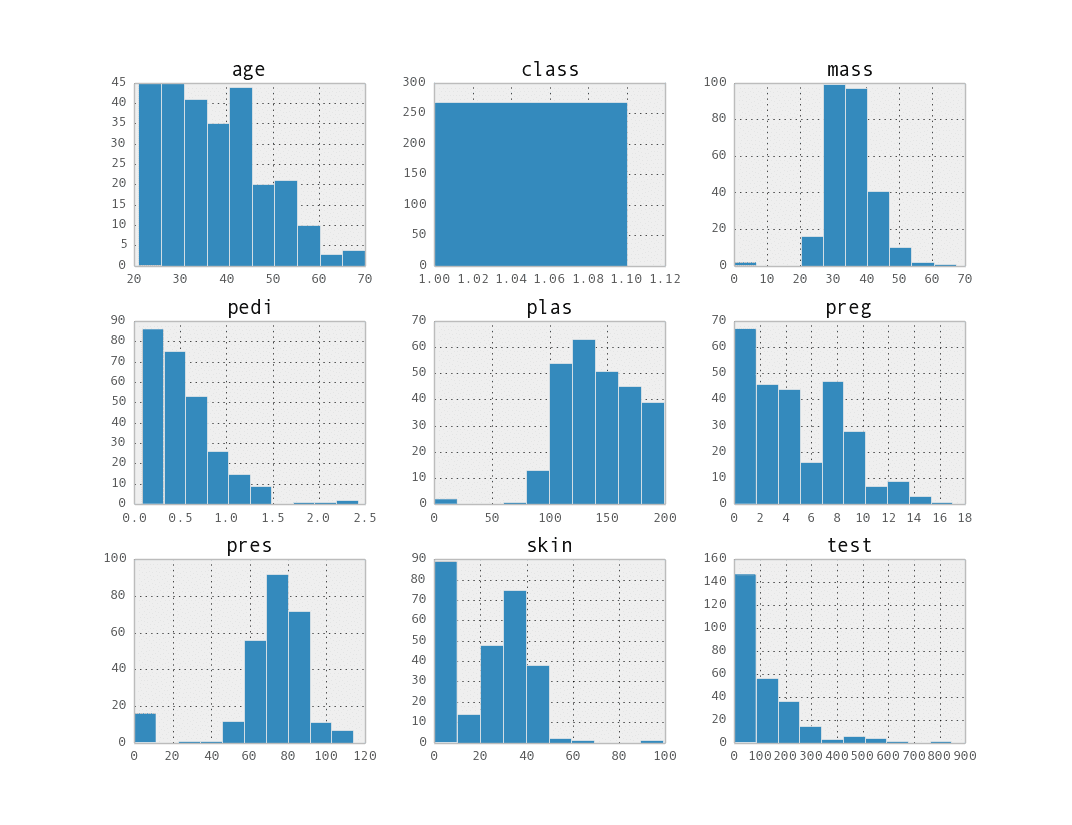
类别 1 的属性直方图矩阵
这有助于指出类别之间分布的差异,例如 plas 属性的差异。
您可以在同一图上更好地对比每个类别的属性值。
|
1 |
data.groupby('class').plas.hist(alpha=0.4) |
这按类别对数据进行分组,然后仅绘制 plas 的直方图,显示类别值 0 为红色,类别值 1 为蓝色。您可以看到相似形状的正态分布,但存在偏移。该属性很可能有助于区分类别。
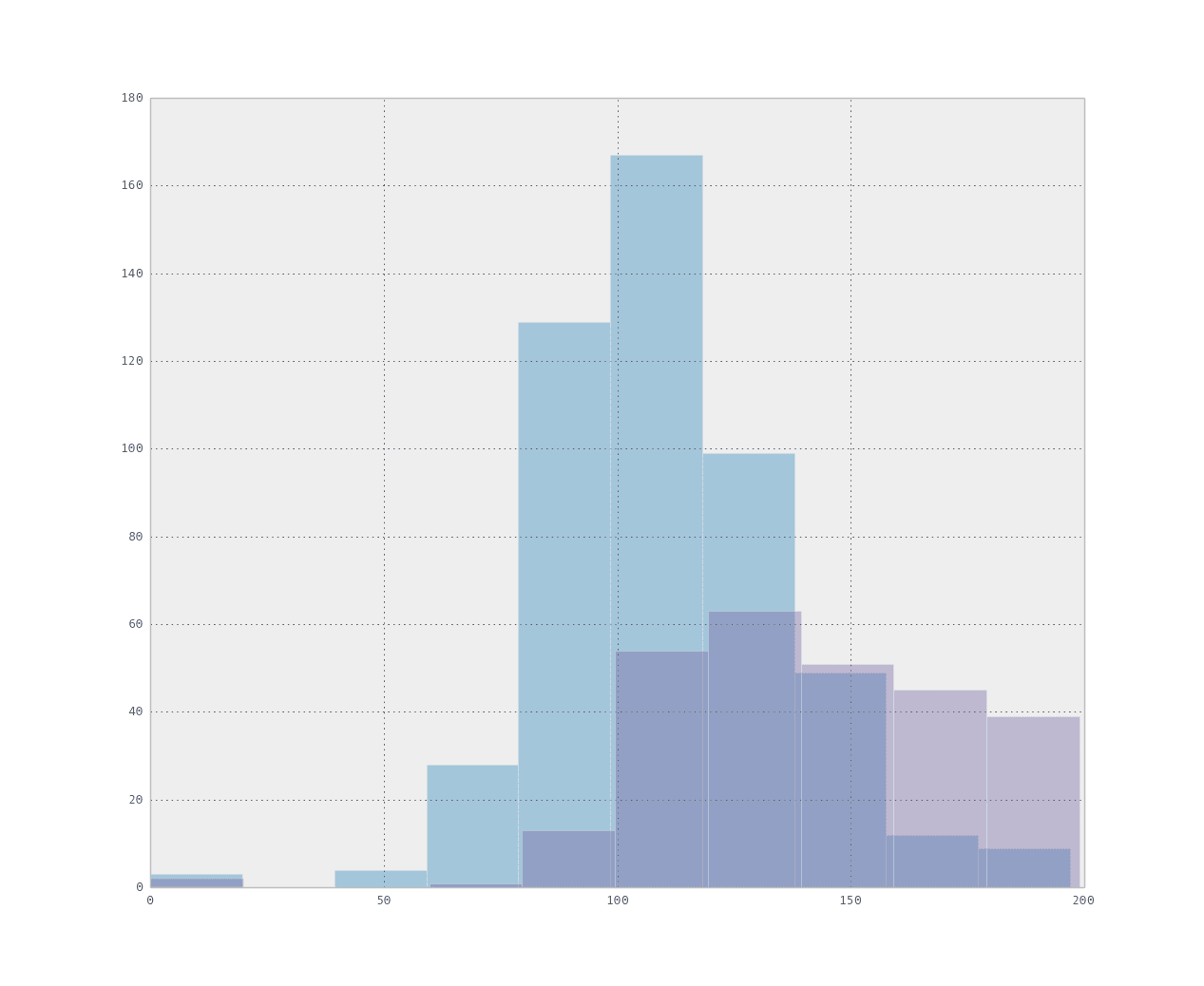
每个类别的重叠属性直方图
您可以阅读更多关于 DataFrame 上的 groupby 函数。
特征-特征关系
最后一个需要探索的重要关系是属性之间的关系。
我们可以通过查看每对属性交互的分布来回顾属性之间的关系。
|
1 2 |
from pandas.plotting import scatter_matrix scatter_matrix(data, alpha=0.2, figsize=(6, 6), diagonal='kde') |
这使用了一个内置函数来创建所有属性相对于所有属性的散点图矩阵。对角线(属性相对于自身绘制)显示属性的核密度估计。
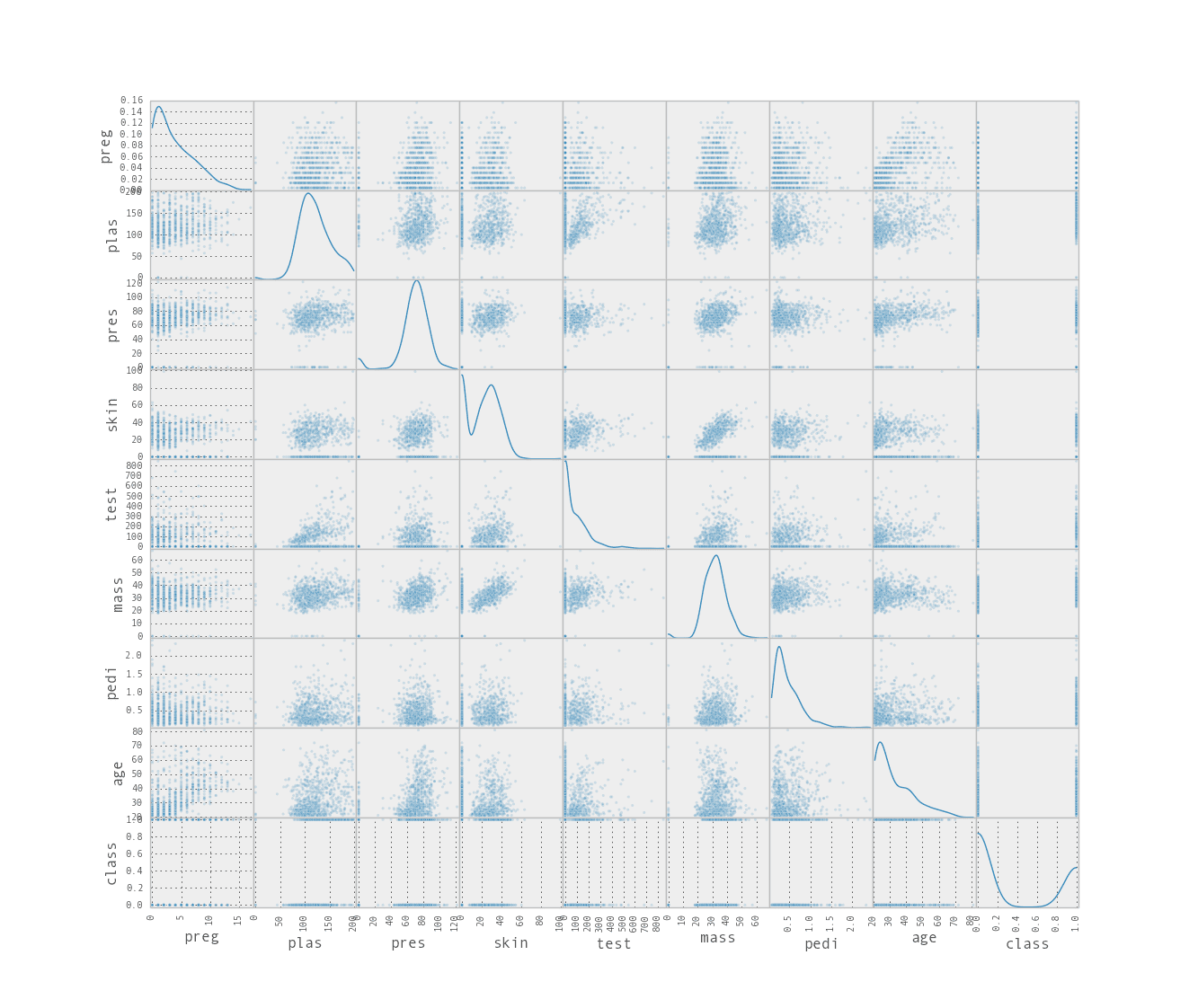
属性散点图矩阵
这是一个强大的图,从中可以获得很多关于数据的灵感。例如,我们可以看到 age 和 preg 之间可能存在相关性,skin 和 mass 之间也可能存在关系。
总结
我们在本文中涵盖了很多内容。
我们首先研究了用于加载 CSV 格式数据并使用摘要统计信息描述数据的快速肮脏的单行命令。
接下来,我们研究了各种不同的绘图方法来揭示有趣的数据结构。我们通过箱须图和直方图查看了数据分布,然后查看了属性与类别属性的分布,最后查看了属性在成对散点图中的关系。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。






这篇文章是一个很棒的工具,但我遇到了一个无法克服的错误。我正在运行以下脚本(在 python 2.7 中):
pima = pan.read_csv(PIMA_FILE, names = COLUMN_NAMES)
pan.options.display.mpl_style = ‘default’
pima.boxplot()
pima.hist()
pima.groupby(‘diabetic’).hist()
scatter_matrix(pima, alpha=0.2, figsize=(6, 6), diagonal=’kde’)
pima.groupby(‘diabetic’).glucose.hist(alpha=0.4)
前四个图出现了,但最后一个没有。只有当我注释掉前四个图时,最后一个图才会出现。
你好,
对我来说,即使是第一个图也没有显示。当我运行该命令时,我会收到此错误?
_IceTransSocketUNIXConnect: 无法连接到非本地主机 vl-sankumar-ice
_IceTransSocketUNIXConnect: 无法连接到非本地主机 vl-sankumar-ice
Qt: Session management error: 无法打开网络套接字
此致,
Santosh
我真的很喜欢这篇实践性很强的文章,谢谢!
谢谢 Andreas!
你好,这是一篇关于第一个探索性技术的好文章。
我有一些问题:
– 您是如何保存图形以获得如此好的布局的?您能否完成您的脚本并添加适当的行?
– 您知道如何为每个类别在对角线上具有 KDE 的散点图矩阵吗?
提前感谢
Jason。不错的帖子。
在我的 Ubuntu 中,窗口会显示,但 2 秒后就会关闭……。
救命。
你好,
写 plt.rcParams.get(‘axes.color_cycle’) 而不是 pd.options.display.mpl_style = ‘default’,对我来说就可以了。
Jason,
非常感谢这篇有帮助的文章,非常有价值。
我一直喜欢跟着算法。
不客气 Benson。
好文章。谢谢 Jason 的分享!
谢谢 Nitin。
嗨,Jason,
您好。您的文章真的很有帮助。
您能否提供一个例子,用于进行 scatter_matrix,但在对角线上叠加两个直方图?
谢谢,
Tal
好主意 Tal,也许将来可以。
你好,我有一些问题……
1. 我尝试 data.groupby(‘class’).plas.hist(alpha=0.4),但得到错误 “‘DataFrameGroupBy’ object has no attribute ‘plas'”。如何修复?
2. 如何更改 x 和 y 值的大小?
3. 如何在可视化数据时忽略异常值?
也许您加载的数据没有列名?
这里有关于缩放的示例。
https://machinelearning.org.cn/prepare-data-machine-learning-python-scikit-learn/
在可视化之前考虑删除异常值。
出色的文章,它确实帮助我学习了一些快速探索数据集的技巧。谢谢。
很高兴听到这个消息!
您能告诉我如何为这个添加图例,以显示哪个颜色显示哪个类别在右上角吗?
data.groupby(‘class’).plas.hist(alpha=0.4)
这被称为图例。
您可以在此处了解有关 matplotlib 库的更多信息:
https://matplotlib.net.cn/
您可以在此处了解有关 matplotlib 中图例的更多信息:
https://matplotlib.net.cn/users/legend_guide.html
这是一篇关于使用 pandas 进行数据分析的精彩文章。我学到了新技巧。我将这篇文章推荐给了我所有的朋友。非常感谢 Jason Brownlee。
谢谢,听到这个我很高兴。
哇,很棒的材料!我一定会将其加入书签!
谢谢。
与这项工作无关,但我是一名 ML 和 CNN 新手,并且想处理涉及时间序列滤波的信号处理……是否有任何地方可以给我一些指导?
我正在研究有关此主题的教程。希望很快能发布。
做得很好。
恭喜!
谢谢。
非常有帮助!谢谢。
谢谢,很高兴听到这个。
我使用了
> plt.style.use(‘ggplot’)
而不是
>pd.options.display.mpl_style = ‘default’
这修复了一些错误。
很棒的教程!
感谢分享。
很棒的文章,特别是当你是一个新手,不知道从哪里开始探索你的数据时。谢谢。
谢谢。很高兴有帮助。
你好,非常好的教程,但我遇到了这个错误
OptionError: ‘您只能设置现有选项的值’
我以为可能是因为我的数据,但当我复制你的例子和你的数据集时,我得到了同样的错误。您能对此说明一下吗?
谢谢,我已经更新了示例。
哇!我已经使用 pandas 进行机器学习一段时间了,但我从未想过它有内置的绘图功能,令人难以置信的信息。也许是我自己的无知,但非常感谢 Jason!一如既往的深刻见解。
谢谢,很高兴它有帮助!
Pandas 中的 Dataframes 还有 .corr() 函数,它可以计算相关矩阵,还有 .cov() 函数,它可以测量协方差矩阵!
好建议!