XGBoost 库提供了一种高效的梯度提升实现,可以配置为训练随机森林集成模型。
随机森林算法比梯度提升更简单。XGBoost 库允许以一种重用和利用库中为训练随机森林模型而实现的计算效率的方式来训练模型。
在本教程中,您将了解如何使用 XGBoost 库开发随机森林集成模型。
完成本教程后,您将了解:
- XGBoost 提供了一种高效的梯度提升实现,可以配置为训练随机森林集成模型。
- 如何使用 XGBoost API 为分类和回归训练和评估随机森林集成模型。
- 如何调整 XGBoost 随机森林集成模型的超参数。
开始您的项目,阅读我的新书《Python 集成学习算法》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。

如何使用 XGBoost 开发随机森林集成
照片作者:Jan Mosimann,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- XGBoost 随机森林
- XGBoost 随机森林 API
- XGBoost 随机森林分类
- XGBoost 随机森林回归
- XGBoost 随机森林超参数
XGBoost 随机森林
XGBoost 是一个开源库,它提供了梯度提升集成算法的高效实现,简称为 Extreme Gradient Boosting 或 XGBoost。
因此,XGBoost 指的是项目、库和算法本身。
梯度提升是分类和回归预测建模项目的首选算法,因为它通常能获得最佳性能。梯度提升的问题在于训练模型通常非常慢,而且对于大型数据集来说这个问题会更加严重。
XGBoost 通过引入多种技术来解决梯度提升的速度问题,这些技术可以极大地加速模型的训练,并且通常能获得更好的模型整体性能。
您可以在本教程中了解更多关于 XGBoost 的信息
除了支持梯度提升,核心 XGBoost 算法还可以配置为支持其他类型的树集成算法,例如随机森林。
随机森林是决策树算法的集成。
每棵决策树都拟合在训练数据集的自助采样上。这是训练数据集的一个样本,其中一个给定的样本(行)可能被选择多次,称为有放回抽样。
重要的是,在树的每个分裂点会考虑输入变量(列)的随机子集。这确保了添加到集成中的每棵树都具有技能,但又以随机的方式不同。在每个分裂点考虑的特征数量通常是一个小子集。例如,在分类问题上,一个常见的启发式方法是选择等于总特征数平方根的特征数量,例如,如果数据集有 20 个输入变量,则选择 4 个。
您可以在本教程中了解更多关于随机森林集成算法的信息
使用 XGBoost 库训练随机森林集成的最大优势是速度。与原生 scikit-learn 实现等其他实现相比,它预计会快得多。
既然我们知道 XGBoost 支持随机森林集成,那么让我们来看看具体的 API。
想开始学习集成学习吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
XGBoost 随机森林 API
第一步是安装 XGBoost 库。
我建议使用 pip 包管理器,从命令行使用以下命令
|
1 |
sudo pip install xgboost |
安装完成后,我们可以在 Python 脚本中加载库并打印版本号,以确认它已正确安装。
|
1 2 3 4 |
# 检查 xgboost 版本 import xgboost # 显示版本 print(xgboost.__version__) |
运行脚本将加载 XGBoost 库并打印库版本号。
您的版本号应与此相同或更高。
|
1 |
1.0.2 |
XGBoost 库提供了两个包装类,允许将库提供的随机森林实现与 scikit-learn 机器学习库一起使用。
它们分别是用于分类和回归的 XGBRFClassifier 和 XGBRFRegressor 类。
|
1 2 3 |
... # 定义模型 model = XGBRFClassifier() |
集成中使用的树的数量可以通过“n_estimators”参数设置,通常会增加此值,直到模型性能不再有进一步的提升。通常使用数百或数千棵树。
|
1 2 3 |
... # 定义模型 model = XGBRFClassifier(n_estimators=100) |
XGBoost 不支持为每棵决策树抽取自助采样。这是该库的一个限制。
相反,可以通过“subsample”参数指定训练数据集的子样本(不放回抽样),其值为 0.0 到 1.0(训练数据集中的行数的 100%)之间的百分比。建议使用 0.8 或 0.9 的值,以确保数据集足够大以训练有技能的模型,但又足够多样以引入一些集成多样性。
|
1 2 3 |
... # 定义模型 model = XGBRFClassifier(n_estimators=100, subsample=0.9) |
在训练模型时,每隔分裂点使用的特征数量可以通过“colsample_bynode”参数指定,该参数接受数据集列数的百分比,范围从 0.0 到 1.0(训练数据集中的输入行数的 100%)。
如果我们的训练数据集中有 20 个输入变量,并且分类问题的启发式方法是特征数量的平方根,那么这可以设置为 sqrt(20) / 20,即约 4 / 20 或 0.2。
|
1 2 3 |
... # 定义模型 model = XGBRFClassifier(n_estimators=100, subsample=0.9, colsample_bynode=0.2) |
您可以在此处了解有关如何为随机森林集成配置 XGBoost 库的更多信息
现在我们熟悉了如何使用 XGBoost API 定义随机森林集成模型,让我们看一些实际示例。
XGBoost 随机森林分类
在本节中,我们将研究为分类问题开发 XGBoost 随机森林集成模型。
首先,我们可以使用 make_classification() 函数 创建一个包含 1,000 个示例和 20 个输入特征的合成二元分类问题。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 测试分类数据集 from sklearn.datasets import make_classification # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
接下来,我们可以在此数据集上评估 XGBoost 随机森林算法。
我们将使用重复分层 K 折交叉验证来评估模型,进行三次重复和 10 折。我们将报告模型在所有重复和折叠上的准确率的平均值和标准差。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 评估 XGBoost 随机森林算法进行分类 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from xgboost import XGBRFClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 定义模型 model = XGBRFClassifier(n_estimators=100, subsample=0.9, colsample_bynode=0.2) # 定义模型评估程序 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集分数 n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 报告表现 print('Mean Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例报告了模型的平均准确度和标准差。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。可以尝试多次运行示例并比较平均结果。
在这种情况下,我们可以看到 XGBoost 随机森林集成模型取得了大约 89.1% 的分类准确率。
|
1 |
平均准确率:0.891 (0.036) |
我们还可以使用 XGBoost 随机森林模型作为最终模型,并进行分类预测。
首先,XGBoost 随机森林集成模型将在所有可用数据上进行拟合,然后可以调用 predict() 函数对新数据进行预测。
以下示例在我们的二元分类数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 使用 XGBoost 随机森林进行分类预测 from numpy import asarray from sklearn.datasets import make_classification from xgboost import XGBRFClassifier # 定义数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # 定义模型 model = XGBRFClassifier(n_estimators=100, subsample=0.9, colsample_bynode=0.2) # 在整个数据集上拟合模型 model.fit(X, y) # 定义一行数据 row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808] row = asarray([row]) # 进行预测 yhat = model.predict(row) # 总结预测 print('Predicted Class: %d' % yhat[0]) |
运行示例将 XGBoost 随机森林集成模型拟合到整个数据集上,然后用于对新数据行进行预测,就像在应用程序中使用模型一样。
|
1 |
预测类别:1 |
现在我们熟悉了如何将随机森林用于分类,让我们看看回归的 API。
XGBoost 随机森林回归
在本节中,我们将研究为回归问题开发 XGBoost 随机森林集成模型。
首先,我们可以使用 make_regression() 函数 创建一个包含 1,000 个示例和 20 个输入特征的合成回归问题。
完整的示例如下所示。
|
1 2 3 4 5 6 |
# 测试回归数据集 from sklearn.datasets import make_regression # 定义数据集 X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7) # 汇总数据集 print(X.shape, y.shape) |
运行示例会创建数据集并总结输入和输出组件的形状。
|
1 |
(1000, 20) (1000,) |
接下来,我们可以在此数据集上评估 XGBoost 随机森林集成模型。
与上一节一样,我们将使用重复 K 折交叉验证来评估模型,进行三次重复和 10 折。
我们将报告模型在所有重复和折叠上的平均绝对误差 (MAE)。scikit-learn 库将 MAE 设为负数,以便最大化而不是最小化。这意味着较大的负 MAE 更好,而完美模型的 MAE 为 0。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 评估 XGBoost 随机森林集成模型进行回归 from numpy import mean from numpy import std from sklearn.datasets import make_regression from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedKFold from xgboost import XGBRFRegressor # 定义数据集 X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7) # 定义模型 model = XGBRFRegressor(n_estimators=100, subsample=0.9, colsample_bynode=0.2) # 定义模型评估程序 cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型并收集分数 n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1) # 报告表现 print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores))) |
运行示例将报告模型平均绝对误差的平均值和标准差。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。可以尝试多次运行示例并比较平均结果。
在这种情况下,我们可以看到默认超参数的随机森林集成模型达到了大约 108 的 MAE。
|
1 |
MAE:-108.290 (5.647) |
我们还可以使用 XGBoost 随机森林集成模型作为最终模型,并进行回归预测。
首先,随机森林集成模型将在所有可用数据上进行拟合,然后可以调用 predict() 函数对新数据进行预测。
以下示例在我们的回归数据集上演示了这一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 使用梯度 XGBoost 随机森林进行回归预测 from numpy import asarray from sklearn.datasets import make_regression from xgboost import XGBRFRegressor # 定义数据集 X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7) # 定义模型 model = XGBRFRegressor(n_estimators=100, subsample=0.9, colsample_bynode=0.2) # 在整个数据集上拟合模型 model.fit(X, y) # 定义单行数据 row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792] row = asarray([row]) # 进行预测 yhat = model.predict(row) # 总结预测 print('Prediction: %d' % yhat[0]) |
运行示例将 XGBoost 随机森林集成模型拟合到整个数据集上,然后用于对新数据行进行预测,就像在应用程序中使用模型一样。
|
1 |
预测:17 |
现在我们熟悉了如何开发和评估 XGBoost 随机森林集成模型,让我们来看看如何配置模型。
XGBoost 随机森林超参数
在本节中,我们将仔细研究一些您应该考虑为随机森林集成模型调整的超参数,以及它们对模型性能的影响。
探索树的数量
树的数量是为 XGBoost 随机森林配置的另一个关键超参数。
通常,树的数量会增加,直到模型性能趋于稳定。直觉可能认为更多的树会导致过拟合,但事实并非如此。考虑到学习算法的随机性,装袋和随机森林算法似乎在一定程度上能抵抗对训练数据集的过拟合。
树的数量可以通过“n_estimators”参数设置,默认为 100。
下面的示例探讨了树的数量对性能的影响,取值范围在 10 到 1,000 之间。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# 探索 XGBoost 随机森林树的数量对性能的影响 from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from xgboost import XGBRFClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() # 定义要考虑的树的数量 n_trees = [10, 50, 100, 500, 1000, 5000] for v in n_trees: models[str(v)] = XGBRFClassifier(n_estimators=v, subsample=0.9, colsample_bynode=0.2) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): # 定义模型评估程序 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): # 评估模型并收集结果 scores = evaluate_model(model, X, y) # 存储结果 results.append(scores) names.append(name) # 总结性能 print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告了每个配置的树数量的平均准确率。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。可以尝试多次运行示例并比较平均结果。
在这种情况下,我们可以看到性能在约 500 棵树后开始上升并保持平稳。平均准确率分数在 500、1,000 和 5,000 棵树之间波动,这可能是统计噪声。
|
1 2 3 4 5 6 |
>10 0.868 (0.030) >50 0.887 (0.034) >100 0.891 (0.036) >500 0.893 (0.033) >1000 0.895 (0.035) >5000 0.894 (0.036) |
为每个配置的树数量创建了准确率分数的箱线图。
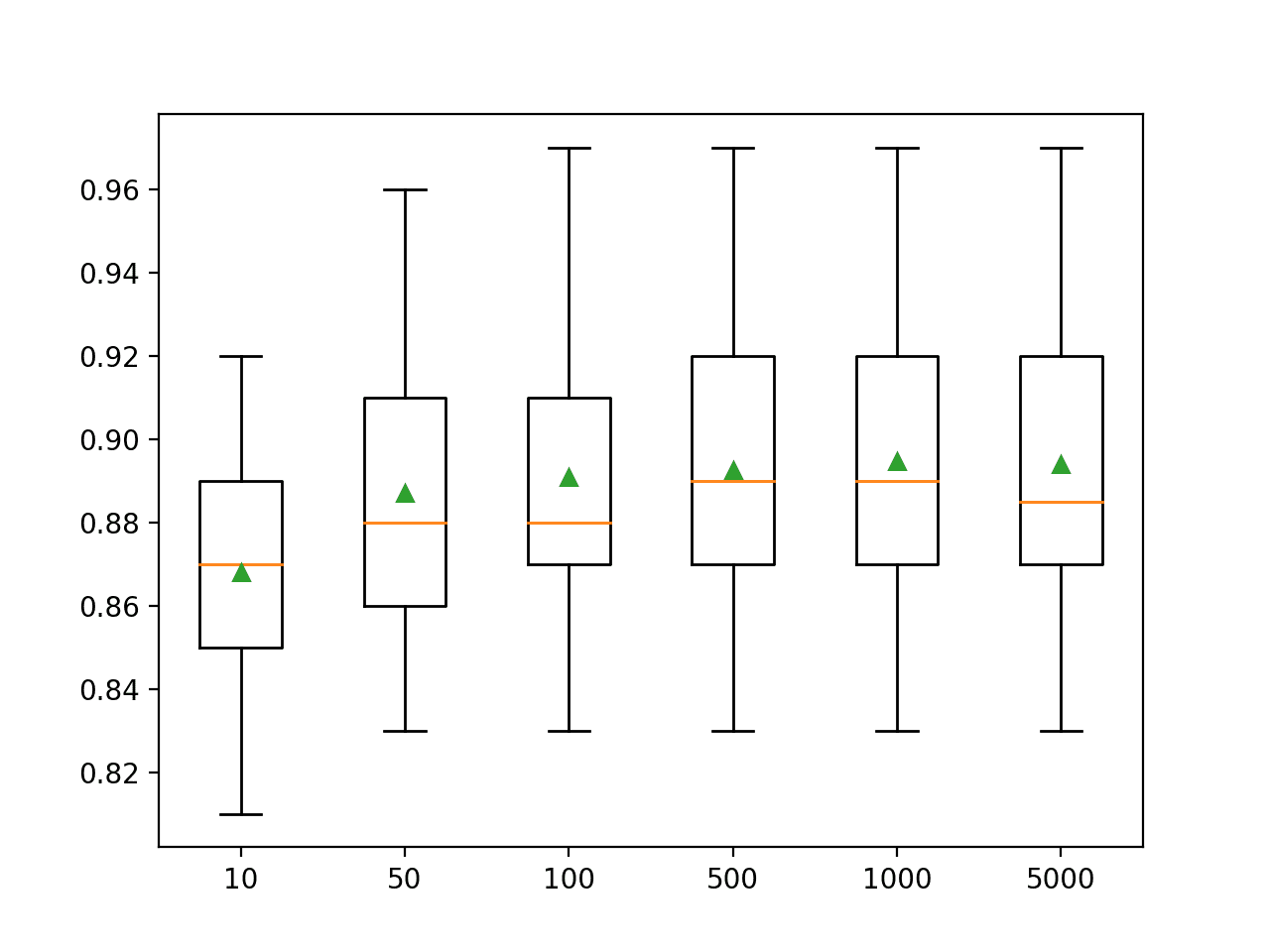
XGBoost 随机森林集成大小与分类准确率的箱线图
探索特征数量
对于每个分裂点随机采样的特征数量可能是配置随机森林最重要的特征。
它通过“colsample_bynode”参数设置,该参数接受从 0 到 1 的输入特征数量的百分比。
下面的示例探讨了在每个分裂点随机选择的特征数量对模型准确率的影响。我们将尝试从 0.0 到 1.0 的值,增量为 0.1,尽管我们预计低于 0.2 或 0.3 的值将产生良好或最佳性能,因为这相当于输入特征数量的平方根,这是一个常见的启发式方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
# 探索 XGBoost 随机森林特征数量对性能的影响 from numpy import mean from numpy import std from numpy import arange from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from xgboost import XGBRFClassifier from matplotlib import pyplot # 获取数据集 定义 获取_数据集(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) 返回 X, y # 获取要评估的模型列表 定义 获取_模型(): models = dict() for v in arange(0.1, 1.1, 0.1): key = '%.1f' % v models[key] = XGBRFClassifier(n_estimators=100, subsample=0.9, colsample_bynode=v) 返回 模型 # 使用交叉验证评估给定模型 def evaluate_model(model, X, y): # 定义模型评估程序 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) 返回 分数 # 定义数据集 X, y = get_dataset() # 获取要评估的模型 模型 = 获取_模型() # 评估模型并存储结果 results, names = list(), list() for name, model in models.items(): # 评估模型并收集结果 scores = evaluate_model(model, X, y) # 存储结果 results.append(scores) names.append(name) # 总结性能 print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # 绘制模型性能以供比较 pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
运行示例首先报告了每个特征集数量的平均准确率。
注意:鉴于算法或评估程序的随机性,或者数值精度的差异,您的结果可能有所不同。可以尝试多次运行示例并比较平均结果。
在这种情况下,我们可以看到随着集成成员使用更多的输入特征,平均模型性能呈下降趋势。
结果表明,在这种情况下,推荐值 0.2 将是一个不错的选择。
|
1 2 3 4 5 6 7 8 9 10 |
>0.1 0.889 (0.032) >0.2 0.891 (0.036) >0.3 0.887 (0.032) >0.4 0.886 (0.030) >0.5 0.878 (0.033) >0.6 0.874 (0.031) >0.7 0.869 (0.027) >0.8 0.867 (0.027) >0.9 0.856 (0.023) >1.0 0.846 (0.027) |
为每个特征集数量的准确率分数分布创建了箱线图。
我们可以看到,随着决策树考虑的特征数量的增加,性能呈下降趋势。
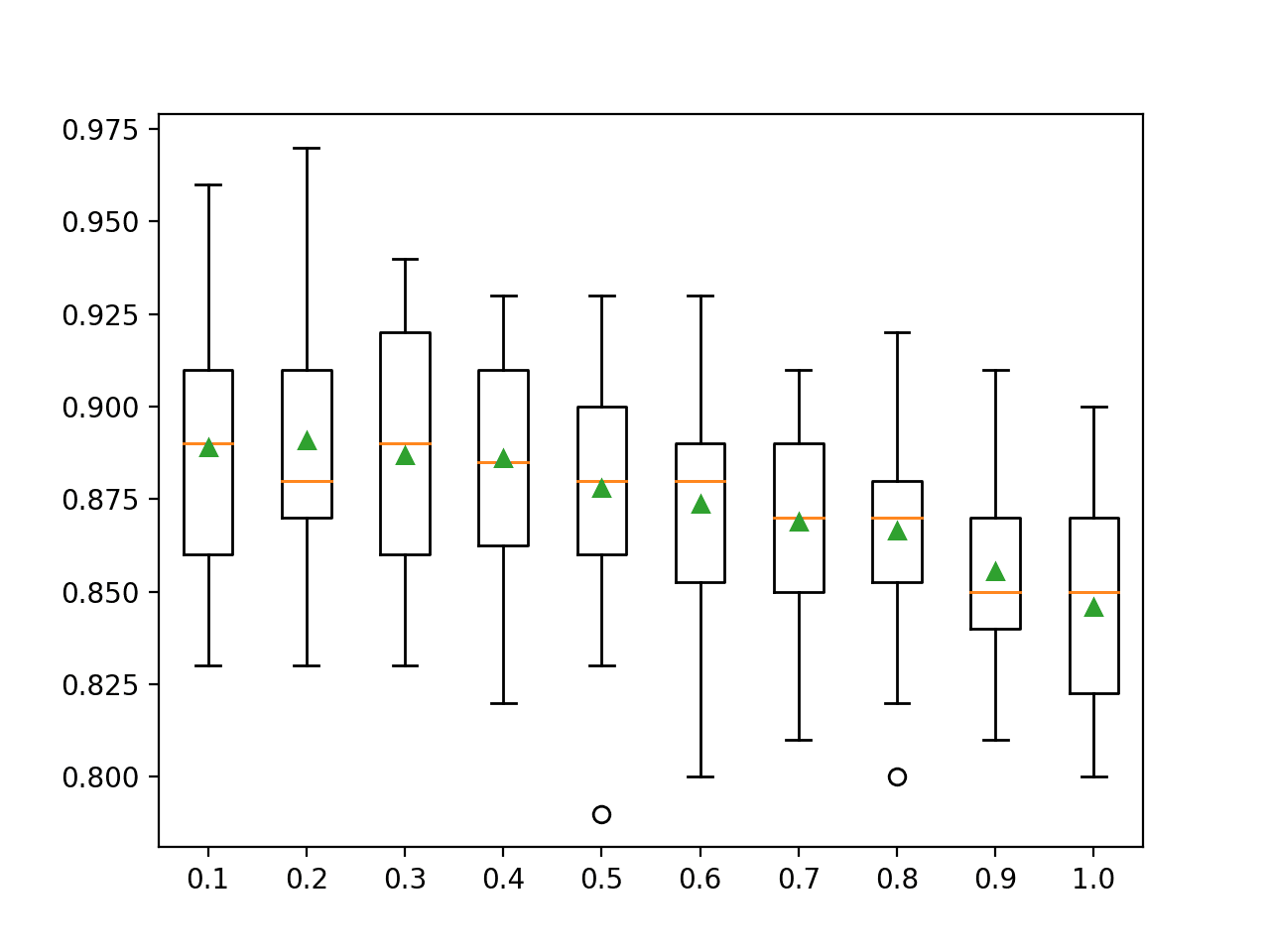
XGBoost 随机森林特征集大小与分类准确率的箱线图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
- 应用机器学习 XGBoost 简明介绍
- 如何在 Python 中开发随机森林集成模型
- 使用 Scikit-Learn、XGBoost、LightGBM 和 CatBoost 进行梯度提升
- 如何在 Python 中使用 scikit-learn 开发您的第一个 XGBoost 模型
API
总结
在本教程中,您了解了如何使用 XGBoost 库开发随机森林集成模型。
具体来说,你学到了:
- XGBoost 提供了一种高效的梯度提升实现,可以配置为训练随机森林集成模型。
- 如何使用 XGBoost API 为分类和回归训练和评估随机森林集成模型。
- 如何调整 XGBoost 随机森林集成模型的超参数。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
掌握现代集成学习!

在几分钟内改进您的预测
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 实现集成学习算法
它提供**自学教程**,并附有关于以下内容的**完整工作代码**:
堆叠、投票、提升、装袋、混合、超级学习器等等……


")



嗨,Jason,
好文!
我唯一的观察
使用时间序列交叉验证,我发现我的数据集的最佳超参数是 n_estimators=2 和 max_depth=24。这与默认参数非常不同,所以我感到很惊讶。
此致!
这确实令人惊讶!
尊敬的Jason博士,
当我运行“XGBoost 随机森林分类”标题下的代码时,在尝试拟合模型时会收到以下错误
程序产生此“错误”消息
注释:’
* 代码是直接复制您在 Spyder IDE 中输入的代码。
* 包版本
总而言之,我复制了相同的代码来做一个预测,但在拟合模型 fit.model(X,y) 时遇到了这个错误。
为什么?
谢谢你,
悉尼的Anthony
注意事项
* 我将相同的代码复制到了我的 Spyder IDE 中。
这看起来像是一个警告而不是错误,我猜你可以忽略它。
尊敬的Jason博士,
当我复制相同的代码并尝试执行 model.fit(X,y) 时,我得到的错误是
谢谢你,
悉尼的Anthony
尊敬的Jason博士,
这是在不移动水平滚动条的情况下出现的错误
[16:58:45] 警告:C:/Users/Administrator/workspace/xgboost-win64_release_1.3.0/src/learner.cc:1061: XGBoost 1.3.0 起,目标 'binary:logistic' 的默认评估指标已从 'error' 更改为 'logloss'。如果您想恢复旧行为,请明确设置 eval_metric。
谢谢你
悉尼的Anthony
尊敬的Jason博士,
谢谢你的回复。
我无法根据警告中的建议“关闭”警告消息。
这是使用 XGBoost 的随机森林分类器的代码片段。
这是输出
两点
(1) 要消除警告消息,请在实例化随机森林分类器时将两个参数设置为“use_label_encoder=False,eval_metric=’logloss’”
(2) 在进行预测时,将列表转换为数组。否则计算机将产生错误消息
为了纠正这个问题,将列表转换为数组
结论
要预测输出,拟合 XGBoost 使用的值的输入需要将列表“row”转换为数组。
谢谢你,
悉尼的Anthony
也许是库版本的问题或故障?
也许你可以在 stackoverflow 或 xgboost 的 github issues tab 上搜索/发帖?
尊敬的Jason博士,
只需要做两件事:
(1) 在模型实例化时,为了停止警告,添加两个参数
use_label_encoder=False,和 metric = ‘logloss’
model = XGBRFClassifier(n_estimators=100, subsample=0.9, colsample_bynode=0.28,use_label_encoder=False,eval_metric=’logloss’)
(2) 用于预测 yhat 的输入数据 ‘row’ 必须是数组,而不是列表。
row = [[-8.52381793,5.24451077,-12.14967704,-2.92949242,0.99314133,0.67326595,-0.38657932,1.27955683,-0.60712621,3.20807316,0.60504151,-1.38706415,8.92444588,-7.43027595,-2.33653219,1.10358169,0.21547782,1.05057966,0.6975331,0.26076035]]
# 将列表 row 转换为数组
from numpy import asarray
row = asarray(row)
print(“predict – watch the output”)
yhat = model.predict(row)
谢谢你,
悉尼的Anthony
干得不错。
对于 XGBRF,我仍然有些疑问。XGBRF 使用随机森林作为框架,并以 XGBoost 算法作为基础学习器来构建模型。可以这样理解吗?
不完全是。“xgboost”模型可以配置为“做”随机森林。
你好 Jason,
感谢这篇优秀的教程。
- 您知道 XGBoost 中的随机森林是否比 ExtraTrees(https://scikit-learn.cn/stable/modules/generated/sklearn.ensemble.ExtraTreesClassifier.html)在计算时间上更快吗?
- 是否可以从这个组合实现中提取/导出规则(就像分别使用 XGBoost 和随机森林一样)?
感谢您的回复!
/Angelos
不确定,我猜是。
抱歉,我不知道如何从树的集成中提取规则。
再次问好,
感谢您之前的回复。两个后续问题
- 您认为使用贝叶斯优化(BO)来搜索您在此处提出的方法中的超参数是否有意义?
- 如果我单独使用 BO 来调整 XGBoost 算法,相同的参数是否也适用于 XGBoost 的随机森林,或者这需要一个完全不同的超参数优化过程?
/Angelos
当然,试试看。
最好直接在数据上调整模型,而不是使用代理。
嗨,在使用 sklearn RandomForestClassifier 和 XGBoost XGBRFClassifier 时是否可能获得不同的分数?还是我做错了什么?
是的,请看这个
https://machinelearning.org.cn/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
嗨 Jason,你能用 KFold 交叉验证而不是 train test 来计算 Precision 和 Recall 值吗?
这应该很简单。只需计算 K 折中每个折的精确率和召回率,然后取平均值。取决于您使用的库,K 折交叉验证函数可能已经自动为您完成了平均。
嗨,Jason,
有没有办法提取测试数据的每一行的单独树预测?这对于分析预测分布而不是仅仅依赖点估计会很有用。
嗨 Thomas……这是一个很棒的问题!以下讨论可能对您感兴趣
https://stackoverflow.com/questions/20615750/how-do-i-output-the-regression-prediction-from-each-tree-in-a-random-forest-in-p