随机森林是一种流行且有效的集成机器学习算法。
它广泛用于结构化(表格)数据集的分类和回归预测建模问题,例如电子表格或数据库表中的数据。
随机森林也可用于时间序列预测,尽管它要求时间序列数据集首先转换为监督学习问题。它还需要使用一种称为“滚动预测验证”的特殊技术来评估模型,因为使用 k 折交叉验证评估模型会导致乐观偏颇的结果。
在本教程中,您将学习如何开发用于时间序列预测的随机森林模型。
完成本教程后,您将了解:
- 随机森林是决策树算法的集成,可用于分类和回归预测建模。
- 时间序列数据集可以通过滑动窗口表示转换为监督学习。
- 如何使用随机森林回归模型进行时间序列预测的拟合、评估和预测。
让我们开始吧。

用于时间序列预测的随机森林
照片由 IvyMike 拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 随机森林集成
- 时间序列数据准备
- 用于时间序列的随机森林
随机森林集成
随机森林是决策树算法的集成。
它是决策树的引导聚合(bagging)的扩展,可用于分类和回归问题。
在 bagging 中,生成多个决策树,其中每个树都是从训练数据集的不同引导样本创建的。 引导样本是训练数据集的一个样本,其中一个示例可能在样本中出现多次。这被称为“有放回抽样”。
Bagging 是一种有效的集成算法,因为每个决策树都在略有不同的训练数据集上拟合,因此性能也略有不同。与正常的决策树模型(例如分类和回归树 (CART))不同,集成中使用的树未经剪枝,使它们对训练数据集略有过拟合。这是可取的,因为它有助于使每棵树更不同,并且预测或预测误差的相关性更小。
来自树的预测在所有决策树上进行平均,从而产生比模型中任何单个树更好的性能。
回归问题的预测是集成中所有树的预测的平均值。分类问题的预测是集成中所有树的类别标签的多数投票。
- 回归:预测是决策树的平均预测。
- 分类:预测是决策树预测的多数投票类别标签。
随机森林涉及从训练数据集的引导样本中构建大量决策树,就像 bagging 一样。
与 bagging 不同,随机森林在树的构建过程中,在每个分裂点还涉及选择输入特征(列或变量)的子集。通常,构建决策树涉及评估数据中每个输入变量的值以选择一个分裂点。通过将每个分裂点可能考虑的特征减少到随机子集,它迫使集成中的每个决策树更加不同。
其结果是,集成中每棵树所做的预测以及预测误差更加不同或相关性更小。当这些相关性较小的树的预测进行平均以进行预测时,它通常会比 bagging 决策树产生更好的性能。
有关随机森林算法的更多信息,请参阅教程
时间序列数据准备
时间序列数据可以被表述为监督学习。
给定一个时间序列数据集的数字序列,我们可以重新构造数据,使其看起来像一个监督学习问题。我们可以通过使用先前的时间步作为输入变量,并将下一个时间步作为输出变量来实现这一点。
让我们用一个例子来具体说明这一点。假设我们有一个时间序列如下:
|
1 2 3 4 5 6 |
时间,测量值 1, 100 2, 110 3, 108 4, 115 5, 120 |
我们可以通过使用前一时间步的值来预测下一时间步的值,将此时间序列数据集重构为监督学习问题。
以这种方式重新组织时间序列数据集,数据将如下所示
|
1 2 3 4 5 6 7 |
X, y ?, 100 100, 110 110, 108 108, 115 115, 120 120, ? |
请注意,时间列被删除,并且某些数据行无法用于训练模型,例如第一行和最后一行。
这种表示被称为滑动窗口,因为输入和预期输出的窗口随时间向前移动以创建用于监督学习模型的新“样本”。
有关准备时间序列预测数据的滑动窗口方法的更多信息,请参阅教程
我们可以使用 Pandas 中的 shift() 函数,根据所需的输入和输出序列长度自动创建时间序列问题的新框架。
这将是一个有用的工具,因为它将允许我们使用机器学习算法探索时间序列问题的不同框架,以查看哪个可能产生性能更好的模型。
下面的函数将把一个带有多列或单列的 NumPy 数组时间序列作为时间序列,并将其转换为具有指定数量输入和输出的监督学习问题。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 将时间序列数据集转换为监督学习数据集 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols = list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # 预测序列 (t, t+1, ... t+n) for i in range(0,n_out): cols.append(df.shift(-i)) # 将它们组合在一起 agg = concat(cols, axis=1) # 删除包含 NaN 值的行 if dropnan: agg.dropna(inplace=True) return agg.values |
我们可以使用此函数来为随机森林准备时间序列数据集。
有关此函数逐步开发的更多信息,请参阅教程
一旦数据集准备好,我们必须小心如何使用它来拟合和评估模型。
例如,在未来的数据上拟合模型并让它预测过去是无效的。模型必须在过去的数据上训练并预测未来。
这意味着不能使用在评估过程中随机化数据集的方法,例如k 折交叉验证。相反,我们必须使用一种称为“滚动预测验证”的技术。
在滚动预测验证中,数据集首先通过选择一个截止点来分割成训练集和测试集,例如,除了最后 12 个月的所有数据都用于训练,最后 12 个月用于测试。
如果我们对进行一步预测(例如一个月)感兴趣,那么我们可以通过在训练数据集上训练模型并预测测试数据集中的第一步来评估模型。然后我们可以将测试集中的真实观测值添加到训练数据集,重新拟合模型,然后让模型预测测试数据集中的第二步。
对整个测试数据集重复此过程将为整个测试数据集提供一步预测,可以从中计算误差度量以评估模型的技能。
有关滚动预测验证的更多信息,请参阅教程
下面的函数执行滚动预测验证。
它将时间序列数据集的整个监督学习版本以及用作测试集的行数作为参数。
然后,它逐步遍历测试集,调用 `random_forest_forecast()` 函数进行一步预测。计算误差度量并返回详细信息以供分析。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 将测试行拆分为输入和输出列 testX, testy = test[i, :-1], test[i, -1] # 在历史数据上拟合模型并进行预测 yhat = random_forest_forecast(history, testX) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 总结进度 print('>expected=%.1f, predicted=%.1f' % (testy, yhat)) # 估计预测误差 error = mean_absolute_error(test[:, -1], predictions) return error, test[:, 1], predictions |
调用 `train_test_split()` 函数将数据集分割成训练集和测试集。
我们可以在下面定义这个函数。
|
1 2 3 |
# 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test, :], data[-n_test:, :] |
我们可以使用 RandomForestRegressor 类进行一步预测。
下面的 `random_forest_forecast()` 函数实现了这一点,它将训练数据集和测试输入行作为输入,拟合模型并进行一步预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 拟合随机森林模型并进行一步预测 def random_forest_forecast(train, testX): # 将列表转换为数组 train = asarray(train) # 分割成输入和输出列 trainX, trainy = train[:, :-1], train[:, -1] # 拟合模型 model = RandomForestRegressor(n_estimators=1000) model.fit(trainX, trainy) # 进行一步预测 yhat = model.predict([testX]) return yhat[0] |
现在我们知道如何准备时间序列数据以进行预测并评估随机森林模型,接下来我们可以看看如何在真实数据集上使用随机森林。
用于时间序列的随机森林
在本节中,我们将探讨如何使用随机森林回归器进行时间序列预测。
我们将使用一个标准的单变量时间序列数据集,目的是使用模型进行一步预测。
您可以使用本节中的代码作为您自己项目的起点,并轻松将其用于多变量输入、多变量预测和多步预测。
我们将使用每日女性出生数据集,即三年内的每月出生人数。
您可以从这里下载数据集,并将其放置在当前工作目录中,文件名为“daily-total-female-births.csv”。
数据集的前几行如下所示
|
1 2 3 4 5 6 7 |
"日期","出生人数" "1959-01-01",35 "1959-01-02",32 "1959-01-03",30 "1959-01-04",31 "1959-01-05",44 ... |
首先,让我们加载并绘制数据集。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 |
# 加载并绘制时间序列数据集 from pandas import read_csv from matplotlib import pyplot # 加载数据集 series = read_csv('daily-total-female-births.csv', header=0, index_col=0) values = series.values # 绘制数据集 pyplot.plot(values) pyplot.show() |
运行示例会创建数据集的折线图。
我们可以看到没有明显的趋势或季节性。
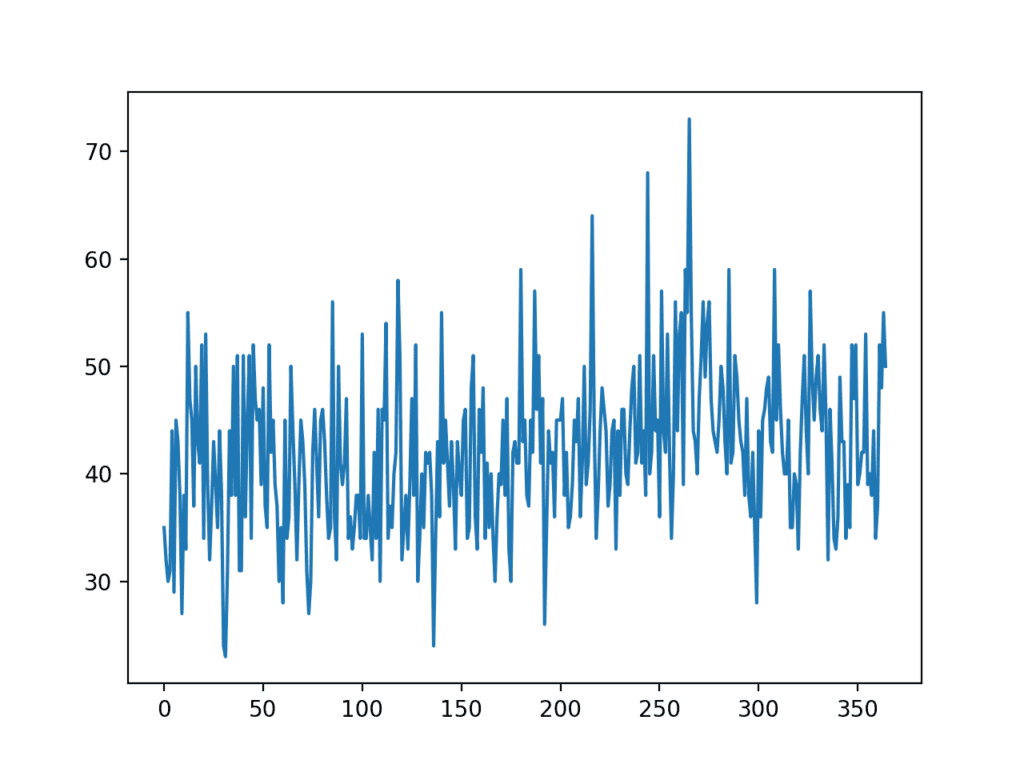
每月出生时间序列数据集的折线图
在预测最后 12 个月时,持久性模型可以实现大约 6.7 次出生的平均绝对误差 (MAE)。这提供了一个基准性能,高于该性能的模型可以被认为是熟练的。
接下来,我们可以评估随机森林模型在数据集上对过去 12 个月数据进行一步预测时的表现。
我们将仅使用前六个时间步作为模型输入和默认模型超参数,除了我们将使用 1000 棵树的集成(以避免欠学习)。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
# 使用随机森林预测每月出生人数 from numpy import asarray from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat from sklearn.metrics import mean_absolute_error from sklearn.ensemble import RandomForestRegressor from matplotlib import pyplot # 将时间序列数据集转换为监督学习数据集 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols = list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # 预测序列 (t, t+1, ... t+n) for i in range(0,n_out): cols.append(df.shift(-i)) # 将它们组合在一起 agg = concat(cols, axis=1) # 删除包含 NaN 值的行 if dropnan: agg.dropna(inplace=True) return agg.values # 将单变量数据集拆分为训练/测试集 def train_test_split(data, n_test): return data[:-n_test, :], data[-n_test:, :] # 拟合随机森林模型并进行一步预测 def random_forest_forecast(train, testX): # 将列表转换为数组 train = asarray(train) # 分割成输入和输出列 trainX, trainy = train[:, :-1], train[:, -1] # 拟合模型 model = RandomForestRegressor(n_estimators=1000) model.fit(trainX, trainy) # 进行一步预测 yhat = model.predict([testX]) return yhat[0] # 单变量数据的滚动预测验证 def walk_forward_validation(data, n_test): predictions = list() # 拆分数据集 train, test = train_test_split(data, n_test) # 用训练数据集初始化历史数据 history = [x for x in train] # 遍历测试集中的每个时间步 for i in range(len(test)): # 将测试行拆分为输入和输出列 testX, testy = test[i, :-1], test[i, -1] # 在历史数据上拟合模型并进行预测 yhat = random_forest_forecast(history, testX) # 将预测结果存储在预测列表中 predictions.append(yhat) # 将实际观测值添加到历史数据中以进行下一次循环 history.append(test[i]) # 总结进度 print('>expected=%.1f, predicted=%.1f' % (testy, yhat)) # 估计预测误差 error = mean_absolute_error(test[:, -1], predictions) return error, test[:, -1], predictions # 加载数据集 series = read_csv('daily-total-female-births.csv', header=0, index_col=0) values = series.values # 将时间序列数据转换为监督学习 data = series_to_supervised(values, n_in=6) # 评估 mae, y, yhat = walk_forward_validation(data, 12) print('MAE: %.3f' % mae) # 绘制预期值与预测值 pyplot.plot(y, label='Expected') pyplot.plot(yhat, label='Predicted') pyplot.legend() pyplot.show() |
运行示例会报告测试集中每个步骤的预期值和预测值,然后报告所有预测值的 MAE。
注意:考虑到算法或评估过程的随机性,或者数值精度差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
我们可以看到该模型的性能优于持久性模型,MAE 约为 5.9 次出生,而持久性模型为 6.7 次出生。
你能做得更好吗?
您可以测试不同的随机森林超参数和输入时间步数,看看是否可以获得更好的性能。在下面的评论中分享您的结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
>预期值=42.0,预测值=45.0 >预期值=53.0,预测值=43.7 >预期值=39.0,预测值=41.4 >预期值=40.0,预测值=38.1 >预期值=38.0,预测值=42.6 >预期值=44.0,预测值=48.7 >预期值=34.0,预测值=42.7 >预期值=37.0,预测值=37.0 >预期值=52.0,预测值=38.4 >预期值=48.0,预测值=41.4 >预期值=55.0,预测值=43.7 >预期值=50.0,预测值=45.3 MAE:5.905 |
创建了一个折线图,比较了数据集中最后 12 个月的预期值系列和预测值系列。
这提供了模型在测试集上表现如何的几何解释。
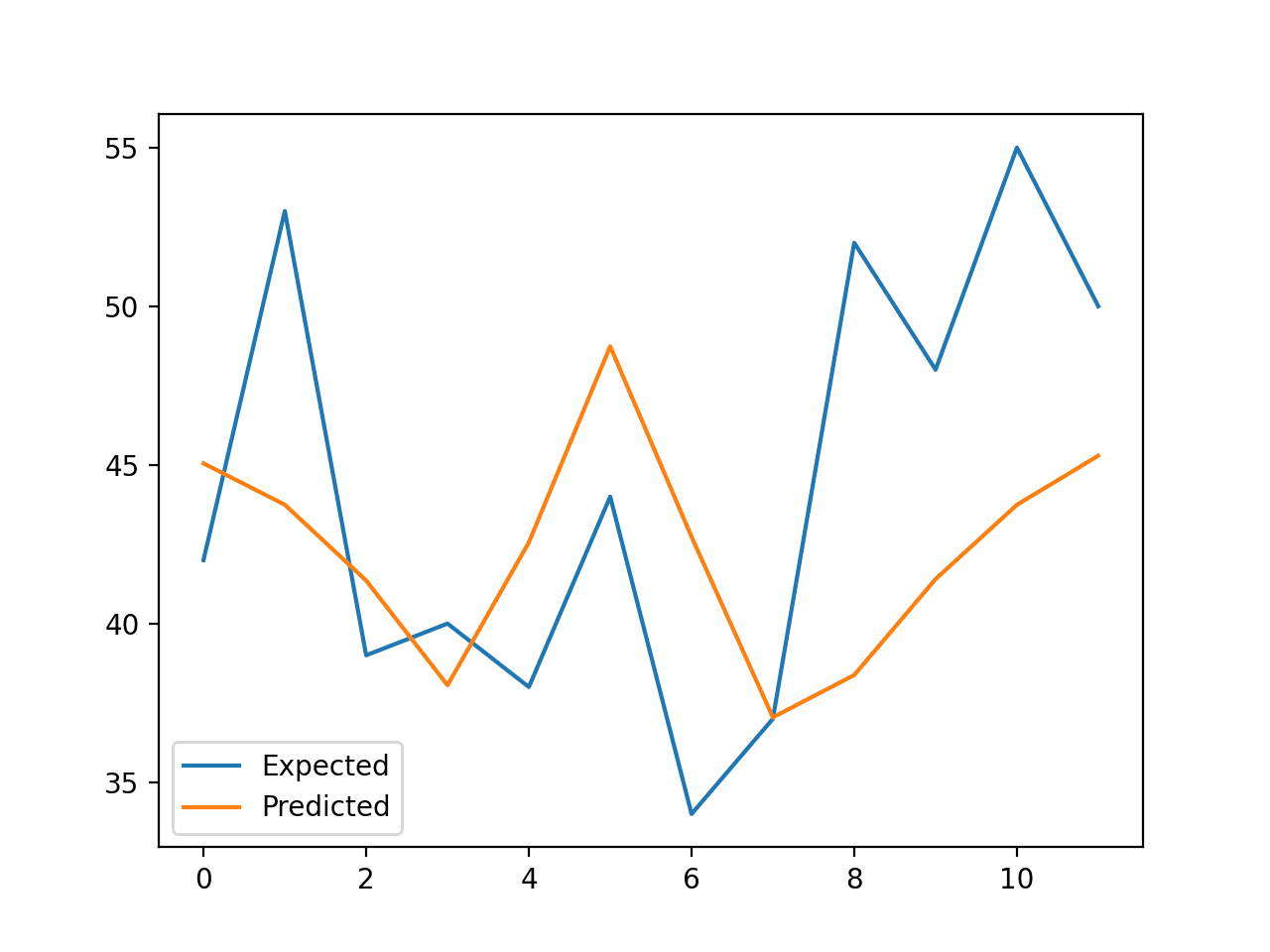
使用随机森林预测的出生人数与预期人数的折线图
一旦选择了最终的随机森林模型配置,就可以最终确定模型并用于对新数据进行预测。
这被称为样本外预测,例如预测超出训练数据集。这与模型评估期间进行预测相同,因为我们总是希望使用我们期望模型用于对新数据进行预测的相同过程来评估模型。
下面的示例演示了在所有可用数据上拟合最终随机森林模型并对数据集末尾之外进行一步预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# 最终确定模型并使用随机森林预测每月出生人数 from numpy import asarray from pandas import read_csv from pandas import DataFrame 从 pandas 导入 concat from sklearn.ensemble import RandomForestRegressor # 将时间序列数据集转换为监督学习数据集 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols = list() # 输入序列 (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # 预测序列 (t, t+1, ... t+n) for i in range(0,n_out): cols.append(df.shift(-i)) # 将它们组合在一起 agg = concat(cols, axis=1) # 删除包含 NaN 值的行 if dropnan: agg.dropna(inplace=True) return agg.values # 加载数据集 series = read_csv('daily-total-female-births.csv', header=0, index_col=0) values = series.values # 将时间序列数据转换为监督学习 train = series_to_supervised(values, n_in=6) # 分割成输入和输出列 trainX, trainy = train[:, :-1], train[:, -1] # 拟合模型 model = RandomForestRegressor(n_estimators=1000) model.fit(trainX, trainy) # 构建新预测的输入 row = values[-6:].flatten() # 进行一步预测 yhat = model.predict(asarray([row])) print('Input: %s, Predicted: %.3f' % (row, yhat[0])) |
运行示例会在所有可用数据上拟合一个随机森林模型。
使用已知数据的最后六个月准备新输入行,并预测数据集末尾之外的下个月。
|
1 |
输入:[34 37 52 48 55 50],预测:43.053 |
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
API
总结
在本教程中,您了解了如何开发用于时间序列预测的随机森林模型。
具体来说,你学到了:
- 随机森林是决策树算法的集成,可用于分类和回归预测建模。
- 时间序列数据集可以通过滑动窗口表示转换为监督学习。
- 如何使用随机森林回归模型进行时间序列预测的拟合、评估和预测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。


")



一如既往地非常有帮助!感谢分享。
谢谢!
太棒了,谢谢
谢谢!
内容丰富、文章精彩,用简单易懂的语言解释了复杂的概念。感谢您分享这些有价值的知识。
不客气。
太棒了,谢谢
谢谢。
感谢你的笔记本。我们如何进行多变量输入(而不是只用滞后)并进行 4-5 步提前预测呢?
我相信随机森林可以直接支持多个输出。
例如,准备您的数据并拟合您的模型。
你好 Jason……
非常感谢这篇文章。我发现您的大部分文章都非常有用和信息丰富。
需要您的建议——我有一系列产品,包含 3 年的历史数据以及其他预测变量。是否有直接的方法可以一次性训练所有产品,并生成长达 18 个月的多步预测。
谢谢。
我建议您测试一套不同的方法,以发现哪种方法最适合您的数据集。
嗨,Fawad
您找到解决办法了吗——我们如何进行多变量输入(而不是仅滞后)并进行 4-5 步的提前预测。另外我有很多产品。如何为随机森林构建这种输入?
相同的函数可用于准备多变量数据,相同的模型可用于建模。
嗨 Jason
我一直在尝试运行该程序,但我收到这些错误
第 56 行,在 walk_forward_validation 中
testX, testy = test[i, :-1], test[i, -1]
IndexError:轴 1 的索引 -1 超出范围,大小为 0
很抱歉听到这个消息,这可能会有所帮助。
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
太棒了,非常感谢。即使经过粗略的法语翻译,它也易于理解、具有教育意义且可用 🙂
谢谢!
有没有更简单的函数来定义滚动训练?
我还没找到。大多数库都搞砸了。
嘿,我不明白 testX 怎么像一行数据,而 testy 只有一个值。你们是怎么拟合这两个东西的?我的意思是,通常你会拟合两个值相同的数据集。我不明白 testX 怎么会是 [x, x2, x3, x4, x5, x6],而 testy 是 [y],然后你们拟合它们?我的意思是,对于每个 x,你们应该拟合一个 y,不是吗?希望您能解释一下。
谢谢你。
好问题,我建议从这里开始
https://machinelearning.org.cn/time-series-forecasting-supervised-learning/
如何使用随机森林进行多步预测?
谢谢。
我想那应该只是 model.predict(testX) 而不是 model.predict[testX]),对吧,这样它就可以预测 testX 的所有值而不是逐个预测?
随机森林直接支持多输出回归,只需准备好数据,模型就会学习它。
Jason,我可以用什么来对时间序列数据进行随机抽样。哪种方法,哪种算法?我手头有时间序列数据,但样本非常不规则。谢谢你的回答和这个博客
抱歉,我不太明白,也许这会有所帮助
https://machinelearning.org.cn/faq/single-faq/how-do-i-handle-discontiguous-time-series-data
谢谢,我正在分析。实际上,我的意思是,在时间序列数据中,有些观测值是趋势性的、季节性的或随机样本,而我有一个随机的。我该如何解决这个问题,还有其他想法吗?
如果它真的是随机的(例如随机游走),那么持久性模型可能是您能使用的最好模型。
哦,天哪,太感谢了。所以,您是说,如果我的数据真的是随机样本,——我可以通过您的博客检查这个随机游走测试——我就不能使用任何模型,比如 AR、ARIMA、随机森林、LSTM、XGBoost、CNN 等。可能所有这些都不会有用,对吗?
是的,我尝试了上面提到的许多算法,但它们都没有很好地工作。
不客气。
没错。如果数据是随机的,就无法预测。你所能做的最好就是使用一个持久性模型(最坏的情况)。
非常感谢,我非常感激
不客气。
嗨,Jason,
感谢您发表的这篇有意义的文章。
我正在从事一个项目,试图预测我的国家未来几个月的 Covid-19 传播情况。
您认为这种方法适用于 Covid-19 病例等时间序列数据吗?
谢谢,
Agron。
这是我在这里回答的一个常见问题
https://machinelearning.org.cn/faq/single-faq/how-can-i-use-machine-learning-to-model-covid-19-data
Jason 再次你好,
说实话,你提出的帖子并没有多大帮助。
你有什么关于 Covid-19 病毒传播预测的更具体建议吗?
任何帮助都将不胜感激。
提前感谢,
Agron。
抱歉,我没有关于这个具体主题的教程。
嗨,Jason!
我正在做关于预测时间序列观测值的本科论文。在我的论文中,我涵盖了 ARIMA、随机森林、支持向量回归器和 LSTM 模型,以评估预测能力。
我使用了一个包含 RSSI 和 LQI 值(IEEE 802.15.4 网络中链路质量的度量)的数据集,我的结果显示 RF、SVR 和 LSTM 的 MAPE > 20%,而在使用滚动预测验证的 ARIMA 中,我得到 <10%。
然而,我在哥伦比亚的 COVID-19 活跃病例中测试了这些相同的模型,没有对时间序列进行任何更改。SVR、RF 和 LSTM 的结果保持不变。我不知道为什么会发生这种情况。如果您能帮助我,我将不胜感激。
抱歉,我没听懂你的问题,你能不能重新表述一下?
嗨,Jason,
非常感谢您的精彩解释。您能解释一下如何在这里对随机森林模型进行网格搜索吗?
这里的例子会帮助你入门
https://machinelearning.org.cn/random-forest-ensemble-in-python/
嗨,杰森,这个效果真是太棒了。我正在用这个相同的样板代码来预测水位。它有多个变量,如温度、降雨量、水文学、水量,以及目标变量地下水位深度。总之,模型在训练集和测试集上工作得很好,但是当我尝试在整个数据集上拟合模型时,我收到了一个关于维度错误的提示
ValueError: 模型特征数必须与输入匹配。模型 n_features 为 62,输入 n_features 为 53
总共有 9 个特征,最后一个是目标,“深度”。
我没有做任何修改,使用了你用于在整个数据集上训练模型以获得预测的精确代码。这段特定的代码不能用于多个变量吗?
谢谢!
您可能需要调整代码以处理多个输入变量——特别是数据的准备工作。
我相信这会有帮助
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
我用这种方法设置了我的多变量数据,但我仍然遇到同样的问题。输入模型的特征数量是 79,但是它试图用于基于模型的最终预测的数量只有 60。问题出在这一行
row = values[-6:].flatten()
yhat = model.predict(asarray([row]))
训练数据是所有列,每个特征的 t 和 t-1,但根据您的代码,最终预测应该只从原始数据集馈送数据维度,而不带滞后列。我希望您能在这个特定文章中使用多变量数据集提供一个示例,就像您在所有其他时间序列文章中那样
我会在将来尝试提供一个额外的示例。
你最终找到解决这个问题的办法了吗?
嗨,Jason!首先,非常感谢您分享您的知识,您有没有使用递归策略进行多步预测的例子?例如,如果我想预测 12 个周期而不是一个呢?
嗯,抱歉我不记得了。也许有。我建议搜索博客(页面顶部的搜索框)。
你好,文章写得很好。
如何预测不在测试数据集中的下一个值?例如,预测未来 5 天
调用:model.predict()
嗨,Jason,
感谢这篇内容丰富的文章!
我有一个简单的问题,但在网上找不到明确的答案。如何使用滞后变量预测下个月(样本外)?例如,今天我需要预测下个月。由于我没有下个月的可用数据,如何解决这个问题?
不客气!
您必须根据您在预测时预期可用的数据来定义模型和准备数据。
如果某些数据在预测时不可用,则在定义模型和准备数据时不要将其用作输入。
例如,如果您想预测下个月,但您只有两个月前的数据,那么请定义您的数据和模型,始终根据两个月前的数据进行预测。
嘿,谢谢你的教程。由于我们需要保持数据顺序以进行未来预测,那么假设通过滑动窗口生成子集时,仅仅在该滑动窗口子集内发生“bagging”(有放回抽样)以及像标准 RF 那样随机选择特征子集是否正确?我想我有点困惑,因为数据顺序需要保持,但是又需要 RF 的“bagging”和随机选择列,这两者是如何结合在一起的呢?
只要模型未在测试集中的数据上进行训练,我们就没问题。模型本身不知道未来/过去。数据准备必须正确处理这个问题。
你好 Jason,很棒的帖子!
在这种情况下,使用 RF 和 ARIMA 预测时间序列有什么区别?
一个是决策树的集成,一个是线性模型。
嗨,Jason,
好文章。当我复制你的代码时,我得到了一个错误。请告诉我如何修复它。
代码 –
# 拟合模型
model = RandomForestRegressor(n_estimators=1000)
model.fit(trainX, trainY)
# 构建新预测的输入
row = values[-6:].flatten()
# 进行一步预测
yhat = model.predict(asarray([row]))
print(‘Input: %s, Predicted: %.3f’ % (row, yhat[0]))
错误 –
此 RandomForestRegressor 实例尚未拟合。在使用此估计器之前,请使用适当的参数调用“fit”。
或许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨 Jason
是否可以参考一个多变量时间序列的例子?
感谢您的关注。
抱歉,我想我没有随机森林用于多变量时间序列的示例。
嗨 Jason
我想请问,为了使随机森林模型适用于多并行输入和多步输出类型的多变量时间序列预测,我需要做些什么?
感谢您的关注。
从适当的数据集框架开始,然后您应该能够直接使用该模型。
也许可以尝试一下,学习如何根据您的数据集调整代码。
嗨 Jason
我想知道,当您提到从适当的数据集框架开始时,如果我想将随机森林模型用于多并行输入和多步输出类型的多变量时间序列预测;那么适当的数据集框架会是什么样子?
也就是说,在这种情况下,数据应该是什么样的结构才能使用随机森林?例如,将其保留为 CNN 1D 的情况,类型为:X =(#样本,#输入,#特征);y =(#样本,#输出,#特征)?或者以什么方式?
感谢您的关注。
适当的框架将只包含在预测时可用的一些数据子集,例如滞后观测值的一个子集。
这可以帮助您准备数据
https://machinelearning.org.cn/convert-time-series-supervised-learning-problem-python/
1D CNN 的结构与 LSTM 的结构相同
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-samples-timesteps-and-features-for-lstm-input
嗨,Jason,
你的博客很有帮助。我是机器学习新手,需要知道从何开始。如果你能告诉我如何从头开始浏览你的博客,我将不胜感激。
谢谢!
从这里开始
https://machinelearning.org.cn/start-here/
嗨,Jason,
感谢您精彩的博客。它确实有助于理解概念。
我读过一些文章提到 RF 模型不擅长捕捉趋势,这似乎是正确的。
有没有什么建议来解决这个问题?我们是否不需要像机器学习中通常那样对时间序列数据进行任何预处理?
不客气。
试试看吧。
是的,您可以对数据进行差分以使其在建模之前保持平稳
https://machinelearning.org.cn/machine-learning-data-transforms-for-time-series-forecasting/
嗨 Jason
我想知道,随机森林模型通常不能用于预测未来多于一步,这是正确的吗?或者,是否有可能将它们调整为多并行输入和多步输出模型?
感谢您的关注。
试试看。是的,你可以根据你的喜好调整上面的例子!
好的,谢谢,我会尝试的。
感谢布朗利博士的课程。我只想指出,在你对 walk_forward_regression 的第一个定义中,返回语法有拼写错误。
它应该是 return error, test[:, 1-], predictions 而不是 return error, test[:, 1], predictions。尽管完整代码中的函数是正确的。
谢谢。
你好,有没有办法让 RandomForestRegressor 优化 MASE?我查了源码,但只有 MSE 和 MAE 可用。
也许你用自定义代码覆盖了类/API?
嗨,Jason,
我真的认为我们会非常感谢一个多元时间序列的随机森林示例,即使它是一个非常简单的示例,因为你知道,关于多元时间序列的信息非常少。而且,例如,我已经完全整理了数据,但使用这个模型进行多元时间序列并不那么直观,而且模型执行仍然失败。
请,如果你能给一个这样的例子,那将会有很大的帮助。
谢谢您的关注,我正在等待您的答复。
感谢您的建议。
很棒的教程。当我尝试所有代码时,为什么会收到此错误?
ValueError: 无法将字符串转换为浮点数:“1959-01-01”
提前感谢。
这些提示可能会有所帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
你能告诉我你是如何解决这个问题的吗?
嗨,Mojtaba……我不太明白你的问题。请重新措辞,以便我能更好地帮助你。
抱歉,我的错。CSV 的导入配置错误,抱歉!🙂
没问题!
你好 Jason,
一如既往地感谢这篇精彩的文章。
你提到使用步进验证是必须的,但我不太明白为什么。
我理解在步进验证中,模型首先使用训练数据进行训练。然后,我们在测试数据集的第一步上评估模型,然后将其添加到训练数据中,模型在新训练数据上重新训练,依此类推。
但为什么它对时间序列数据集特别有用呢?
你在另一篇文章中(为了方便起见,下面附上链接)提到,使用正常的训练-测试拆分或 k 交叉验证“会导致乐观偏颇的结果”,原因是“它们假设观测之间没有关系,每个观测都是独立的。”
但是当我们转换数据并包含先前时间步的值时,我们不是保留了这一点吗?
例如,如果我们的特征值是 [t-2, t-1],而标签是 [t] 的值。
所以在这种情况下,以前的观测值用于估计我们感兴趣的值。因此我假设观测之间的关系得以保留。这正确吗?或者我遗漏了什么?
文章:https://machinelearning.org.cn/backtest-machine-learning-models-time-series-forecasting/
必须确保我们不训练未来数据或评估过去数据,例如,对序列数据提供公平的模型性能估计。
我明白了。
但是,即使我们将数据转换为正常的监督学习问题后,序列仍然重要吗?
即使序列很重要,我们是否可以使用简单的非随机测试分割?(例如,在前三年训练,在第四年测试)
是的。
是的,这正是步进验证的作用。
你好。我想问一下,walk_forward_validation 中的 n_test = 12 是预测最后 12 天的出生人数,对吗?
mae, y, yhat = walk_forward_validation(data, 12)
持久性模型预测最后 12 个月的 mae 值是 6.7 次出生,这个值是根据预测最后 12 天与模型的 mae 值 5.9 次出生进行比较计算出来的吗?
是的。
嗨,Jason,
非常感谢这篇好文章!!
在使用不同的数据时,我遇到了这个错误
TypeError: float() 参数必须是字符串或数字,而不是 'Timestamp'
我该怎么办?
谢谢!
看起来你正试图将日期/时间作为数据输入到你的模型中。你不能这样做。
嗨,Jason,
使用随机树进行预测时,您是否总是得到一个已输入到训练集中的预测,或者您可能会收到一个以前从未见过的预测?
谢谢,
Bob
我想这取决于模型和数据集。这可能并不重要。
嗨,Jason,
非常喜欢使用这些资源,它们帮助我深入研究机器学习,并为我的第一个数据科学职位进行了一些很好的研究。我有一个关于数据泄露的问题。我理解步进验证通过不训练未来数据来避免目标泄露,但是你建议在上述代码的哪里实现数据缩放,以避免对整个数据集进行归一化/标准化?
我阅读了你关于数据泄露的精彩文章,并理解了如何将这个过程融入 K 折交叉验证。只是在如何将其应用于你的自定义步进方法上有些困难。
谢谢!
谢谢!
在训练数据上拟合缩放器对象,并将其应用于训练和测试数据。如果/当您重新拟合模型对象时,您可以重新拟合缩放器对象。
感谢您的回复。
我一直在尝试实现它,但在修改你的随机森林模型代码时有点打转。最初,我以为我可以在 WF 验证中的 train_test_split 函数之后立即将缩放器拟合到训练数据上,并在循环之前将其应用于训练/测试数据集。
然后我意识到模型在添加新观察值到历史记录后会重新拟合,对吗?那么缩放器是否需要在每次迭代中,在这个之后,在 for 循环内重新拟合并应用于测试数据集?或者只对训练数据拟合一次然后对测试数据应用一次就可以了?
谢谢你。
您可能需要为您的案例开发一个新的例子。
嗨,Jason,
我对时间序列的随机森林超参数有两个担忧。
1.)如果你想增加 n_estimators 超参数中的决策树数量,如果你从 100 开始,从 1000 开始,那么这个值应该按什么比例增加?是从 100 到 100,从 1000 到 1000,还是如何?
2.)如果你有一个回归,并且你想调整每个分裂点要考虑的随机特征的数量,使其保持 total_input_features / 3,那么 max_features 超参数是否必须调整?如果是这种情况,要以这种方式调整它,应该如何配置?
感谢您的关注。
(1) 这里没有规则,但你需要证明你为什么这样做。最好的答案是你的实验证明的那个。
(2) 是的。
但是如果我希望超参数 max_features = total_input_features / 3,我应该如何配置它呢?是像“auto”、“sqrt”、“log2”这样吗?
你说的是设置模型的参数吗?我建议先保留默认值,然后尝试一下。
是的,我说的正是配置模型的参数,如果我希望 max_features = total_input_features / 3,我应该如何配置它?
感谢您的关注。
你可以这样设置:`sklearn.ensemble.RandomForestRegressor(max_features=0.33)` 或者 `sklearn.ensemble.RandomForestRegressor(max_features=int(total_input_features/3.0))`
哦,好的,我会这样做的,但是正如你所说,我首先会尝试默认值。
感谢你的帮助,Adrian,它对我总是很有用。
嗨,Jason,
又有一个问题,在实际工作中,使用随机森林对多元多并行时间序列进行多步回归时,有没有什么情况是我应该或方便对数据进行某种转换的?
感谢您的关注。
随机森林(即决策树)通常不需要缩放。但如果你正在考虑特征提取(例如 PCA),那可能就是你需要做的转换。然而,这取决于问题。例如,它通常对宏观经济回归很有用。
好的,谢谢你的回答。
嗨,Jason,首先感谢你的博客,我非常喜欢它,而且解释得非常清楚。
我正在尝试将其用于一个使用 3 个不同标签的多元时间序列数据集。然而,对于每个主题,标签会在某个时候从 1 更改为 3 或从 1 更改为 2。我正在尝试找出哪些特征导致了我的数据集中标签的这种变化。机器学习领域是否实现了类似的功能?
此外,这段代码使用 n_test 值来确定测试数据,并且它总是取数据集的最后 n_test 个值。有没有办法改变这一点,而是使用介于两者之间(当标签发生变化时)作为测试?这有意义吗?
标签取决于一些随机因素。这是你使用的标签编码器的性质。如果你不喜欢它,你最好手动操作:创建一个带有标签映射的 python 字典,然后在使用机器学习模型之前用它替换一列。
嗨 Jason 和 Adrian,
我很好奇是否可以计算滞后变量的聚合统计量?目前我的数据维度相当高,我想通过引入滞后来限制我引入的新特征的数量。我也尝试预测啮齿动物的行为,我觉得这需要我有一个相当大的窗口(即 2 秒),而我的数据由 200 毫秒的时间步长组成。我的想法是,与其为该窗口内的每个时间步引入特征,不如我可以采取一些聚合统计量,例如标准差或均值。这在机器学习领域常见吗?你认为我采用这种方法会丢失多少信息?
非常感谢您的帮助!
我不太明白你所说的滞后变量的聚合统计量是什么意思。但在某些模型中,添加新的派生特征以帮助预测是有意义的。例如,除了时间序列本身,将时间序列的移动平均值一起添加使其成为多维是一种常见的技巧,可以帮助提高准确性。
你好,时间序列预测中树如何分裂节点?我们有一个特征需要处理和预测,此外还有日期特征。
我认为这个例子中没有考虑日期。
谢谢你。我很好奇,在大多数非时间序列类型的分类或回归问题中,您都希望打乱数据。然而,我在这里搜索了一下,没有看到任何关于打乱数据的内容。我的想法是,您永远不应该打乱时间序列数据,但我没有找到任何关于为什么应该或不应该打乱时间序列数据的原因。只是好奇您的想法?
嗨,Anthony……你不应该打乱时间序列数据,因为深度学习模型正在学习数据中固有的相关性并提取基于数据顺序的特征。这就是为什么你不应该随机分割数据。
抱歉,我之前的帖子应该澄清一下,即使您使用“series_to_supervised”函数准备了数据,它会创建一系列过去的 数据和未来一步的数据。在这个步骤之后,在将其分割成训练数据和测试数据之前,有没有任何充分的理由打乱数据?
嗨,Anthony……你不应该打乱时间序列数据。
嗨 Jason 和 Adrian
感谢这篇精彩的帖子。你们有没有关于多元分析的类似帖子或研究,其中包括几个因素?
非常感谢您的回复!
此致!
嗨 Jing……您可能会对以下内容感兴趣
https://machinelearning.org.cn/how-to-develop-machine-learning-models-for-multivariate-multi-step-air-pollution-time-series-forecasting/
你好 Jason,
很高兴与您分享,我能够在我的数据上运行代码。
但我发现我的 MAE 始终在 41 左右。我已将 n_estimators 从 1000 更改为 5000。但 MAE 仍保持在 41 左右,没有变化。我现在应该进行哪些更改?
我如何实现带有自定义步长或步进的 def series to supervised,我希望在滑动窗口中移动多于一步。
谢谢
嗨 Farjam……请参阅之前关于设置所需值的回复。
你好,Jason
你能帮我一下,我如何自定义步长,我的意思是,在 def series_to_supervised 中,如何让步长大于一步?
嗨 Farjam……以下代码定义设置为步长为 1,但是您可以通过将“n_in”和“n_out”更改为对您的目标有意义的其他值,将其更改为您需要的任何步长。
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True)
嗨,Jason,
首先,感谢您的出色工作和教训。
我有一个问题:如果我们最终需要多个样本外值,该怎么办。
我的意思是,如果我们要从我们的实际历史数据最后一个样本开始预测未来许多天、周、年等,该怎么办?
我们应该将我们的第一个样本外预测纳入其中,然后从头开始重新整个过程,还是有更好的方法!
示例:假设我们有一个正在进行的体育赛季。想象一下,我们有该赛季 50 轮中的 11 轮结果,我们想预测剩下的直到赛季结束。
嗨 Enzo……我建议首先确保为给定任务选择了最合适的方法
https://machinelearning.org.cn/findings-comparing-classical-and-machine-learning-methods-for-time-series-forecasting/
*[...]数据的最后一个样本
**[...]整个过程[...]或者有更好的方法?
****[...]“任何体育赛季”[...]其余直到结束
嗨,Enzo……请澄清你的问题,以便我们更好地帮助你。
嗨,Jason!
感谢又一堂精彩的课!
我有一个疑问
我如何调整上述代码以进行多步预测?
在步进验证的情况下,如何调整随机森林的超参数?我们可以使用网格搜索来优化超参数,一旦获得最佳参数,我们再次使用步进验证吗?
嗨 Yogesh……以下资源可能对您有用
https://towardsdatascience.com/hyperparameter-tuning-the-random-forest-in-python-using-scikit-learn-28d2aa77dd74
您好 James 和 Jason,
我是你们博客的忠实粉丝,它们最近非常有用。
我有一个与 Yogesh 类似的问题。我阅读了您上面提供的资源,并且我对如何使用更传统的独立和因变量,甚至使用 sklearn 的 TimeSeriesSplit 来创建各种训练和验证集来运行网格搜索/管道有了一般的理解。我想在 RFR 上调整我的超参数,该 RFR 在步进验证方面表现良好。是否可以将步进验证整合到我的网格搜索中以调整模型?
谢谢。非常感谢任何帮助。
嗨 kmack……感谢您的反馈和支持!您可能会对以下资源感兴趣
https://machinelearning.org.cn/how-to-grid-search-deep-learning-models-for-time-series-forecasting/
https://stats.stackexchange.com/questions/440280/choosing-model-from-walk-forward-cv-for-time-series
嗨 Jason,我发现你的帖子和解释非常有帮助!
但是由于我是 Python 编码和机器学习的新手,你会如何编写代码来进行多步预测,比如在数据集结束后的 30 步?你会更改代码中的哪些部分?
非常感谢您的回复!
嗨 Bim……您可能需要研究 LSTM 以达到此目的
https://machinelearning.org.cn/use-timesteps-lstm-networks-time-series-forecasting/
嗨 Jason,我发现你的帖子非常有帮助!
使用随机森林或分位数回归随机森林来预测波动性是否正确?
嗨 Mona……您可能会对以下资源感兴趣
https://www.tandfonline.com/doi/full/10.1080/1331677X.2022.2089192
你好 Jason,
感谢你们所有的辛勤工作。请问您能评论一下以下内容吗?我注意到在您的时间序列 RF 示例中,random_forest_forecast 方法在每次预测请求(步骤)时被调用一次。但是,它在进行预测之前也会重新构建随机森林模型本身。随着预测窗口循环变长,模型构建越来越多地基于它已经预测过的数据。为什么有必要不断重建 RF 模型?
嗨 Jeff……模型正在用新数据更新。所以这实际上只是对同一个模型的更新。
你好,James,
我们如何添加一个外生变量?
例如,我们有一个包含 Demand 和 IsWeekend 变量的数据框。我们使用 series_to_supervised 函数和 10 个滞后,我们将得到一个包含 Demand、IsWeekend 和 t-n 变量(从 t-1 到 t-10)的数据框。我们是否以相同的方式应用 walkfoward 函数?如果不是,有没有这方面的示例或参考?
提前感谢
嗨 dvd……以下资源可能对您有用
https://timeseriesreasoning.com/contents/exogenous-and-endogenous-variables/
https://repositorio-aberto.up.pt/bitstream/10216/141197/2/433647.pdf
一个疑问
单考虑您的代码
trainX, trainy = train[:, :-1], train[:, -1]
这在我看来不太对,因为 trainy 包含在 trainX 中
如果 y = f(X),那么 y 不应该包含在 trainX 集中吗??
尽管如此,我仍然得到了一个非常好的预测误差。
感谢您的反馈!训练、测试分割的最佳实践可以在这里找到
https://machinelearning.org.cn/training-validation-test-split-and-cross-validation-done-right/
你好,根据这个官方链接,使用 scikit-learn 的随机森林无法进行增量学习
https://scikit-learn.cn/0.15/modules/scaling_strategies.html#incremental-learning
所以如果您理解正确的话,您每次都在重新构建森林,所以这不是步进的真实应用,还是我弄错了?
def random_forest_forecast(train, testX)
# 将列表转换为数组
train = asarray(train)
# 分割成输入和输出列
trainX, trainy = train[:, :-1], train[:, -1]
# 拟合模型
model = RandomForestRegressor(n_estimators=1000)
model.fit(trainX, trainy)
# 进行一步预测
yhat = model.predict([testX])
return yhat[0]
# 单变量数据的滚动预测验证
def walk_forward_validation(data, n_test)
predictions = list()
# 分割数据集
train, test = train_test_split(data, n_test)
# 使用训练数据集初始化历史数据
history = [x for x in train]
# 遍历测试集中的每个时间步
for i in range(len(test))
# 将测试行拆分为输入和输出列
testX, testy = test[i, :-1], test[i, -1]
# 在历史数据上拟合模型并进行预测
yhat = random_forest_forecast(history, testX)
# 将预测结果存储到预测列表中
predictions.append(yhat)
# 将实际观测值添加到历史数据中以供下一次循环使用
history.append(test[i])
# 总结进展
print('&#gt;预期=%.1f,预测=%.1f' % (testy, yhat))
# 估计预测误差
error = mean_absolute_error(test[:, -1], predictions)
return error, test[:, -1], predictions
嗨 Yassine……您执行过您的模型吗?如果没有,请执行并告诉我们您的发现。这将更好地帮助我们指导您下一步。
你好,谢谢你花时间,但是你没有回答我的问题,这是一个简单的问题,也许我应该重新表述一下,在你上面这份我相信是你的代码中,你每次用测试集扩展数据时,都会用新模型覆盖旧模型,这并不是步进的真正应用,我的证据是来自官方 sklearn 网站的这个链接,它讨论了增量学习,而随机森林不是其中之一。
嗨 Yassine……请按照您从 sklearn 文档中理解的建议进行操作。然后告诉我们您的发现。
嗨,现在我明白了你的代码展示了步进的原理,而不是如何实际实现它,部分困惑来自于我不知道 sklearn 中的随机森林不能增量训练,我以为你正在使用步进技术来增量训练模型。
嗨,Jason,
您的博客信息量很大。我有几个疑问。
根据 Goehry, 2020 的研究,对于相关数据随机森林的理论,使用块自举法代替用于独立同分布数据的标准自举法。在 R 或 Python 中实现用于时间序列数据的 randomForest 时,使用的是哪种自举法?
另一个问题是,’rangerts’ 包与 ‘randomForests’ 包相比如何?
先谢谢您了。
嗨 GT……在 R 或 Python 中实现时间序列数据的随机森林时,通常使用一种称为“时间序列交叉验证”的方法,而不是传统的自举方法。时间序列交叉验证通过按顺序将数据分成训练集和测试集来考虑数据中的时间依赖性,确保模型在未见过的未来数据上进行评估。
在 R 中,您可以使用 `caret` 包和 `timeslice` 方法进行时间序列交叉验证。此方法将数据分成多个连续的训练/测试集。
对于 Python,`scikit-learn` 等库通过 `TimeSeriesSplit` 类提供时间序列交叉验证功能。
关于您的第二个问题,`randomForest` 包和 `ranger` 包(不是 `rangerts`)都是 R 中随机森林的流行实现。以下是比较
1. **randomForest 包:**
– `randomForest` 包由 Leo Breiman 和 Adele Cutler 开发,是 R 中最早、使用最广泛的随机森林实现之一。
– 它提供了一个简单的界面来构建随机森林模型,并包含用于调整参数(例如树的数量和每次分裂时考虑的特征数量)的选项。
2. **ranger 包:**
– `ranger` 包是 R 中随机森林的一个较新的实现。
– 它旨在比 `randomForest` 包更快、更节省内存,尤其适用于大型数据集。
– `ranger` 还包括其他功能,例如变量重要性度量和处理具有超过 53 个级别的分类变量的能力。
总的来说,这两个包都有效地用于在 R 中构建随机森林模型,但您可能更喜欢 `ranger`,因为它具有改进的性能和附加功能,尤其是在处理大型数据集时。然而,两者的选择最终取决于您的具体要求和偏好。
非常感谢您的详细回复。不胜感激。