函数优化需要选择一种算法来有效地采样搜索空间并找到一个好的或最佳解决方案。
有许多算法可供选择,但重要的是要为问题建立一个基线,了解哪种类型的解决方案是可行或可能的。这可以通过使用朴素优化算法来实现,例如随机搜索或网格搜索。
朴素优化算法获得的结果在计算上是高效的,并且为更复杂的优化算法提供了比较点。有时,朴素算法被发现能够达到最佳性能,特别是在那些嘈杂或不平滑的问题上,以及那些领域专业知识通常会影响优化算法选择的问题上。
在本教程中,您将了解函数优化的朴素算法。
完成本教程后,您将了解:
- 朴素算法在函数优化项目中的作用。
- 如何生成和评估用于函数优化的随机搜索。
- 如何生成和评估用于函数优化的网格搜索。
使用我的新书《机器学习优化》启动您的项目,包括分步教程和所有示例的Python源代码文件。
让我们开始吧。
用于函数优化的随机搜索和网格搜索
图片由Kosala Bandara拍摄,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 朴素函数优化算法
- 函数优化的随机搜索
- 函数优化的网格搜索
朴素函数优化算法
有许多不同的算法可用于优化,但您如何知道获得的结果是否良好?
解决此问题的一种方法是使用朴素优化算法建立性能基线。
朴素优化算法是一种对要优化的目标函数不作任何假设的算法。
它可以非常轻松地应用,并且算法获得的最佳结果可以用作参考点,以比较更复杂的算法。如果更复杂的算法平均无法获得比朴素算法更好的结果,那么它对您的问题就没有技能,应该放弃。
有两种朴素算法可用于函数优化;它们是
- 随机搜索
- 网格搜索
这些算法被称为“搜索”算法,因为从根本上讲,优化可以被框定为搜索问题。例如,找到使目标函数输出最小化或最大化的输入。
还有一种算法叫做“穷举搜索”,它枚举所有可能的输入。这在实践中很少使用,因为枚举所有可能的输入是不可行的,例如,需要太多的运行时间。
然而,如果您发现自己正在处理一个优化问题,其中所有输入都可以在合理的时间内枚举和评估,那么这应该是您应该使用的默认策略。
让我们依次仔细看看每一个。
想要开始学习优化算法吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
函数优化的随机搜索
随机搜索也被称为随机优化或随机采样。
随机搜索涉及生成和评估目标函数的随机输入。它之所以有效,是因为它不对目标函数的结构做任何假设。这对于那些存在大量领域专业知识可能影响或偏离优化策略的问题是有益的,可以发现非直观的解决方案。
... 随机抽样,它只是使用伪随机数生成器在设计空间中抽取 m 个随机样本。为了生成一个随机样本 x,我们可以独立地从一个分布中抽取每个变量。
——第236页,《优化算法》,2019年。
随机搜索也可能是解决高度复杂问题的最佳策略,这些问题在搜索空间中存在嘈杂或不平滑(不连续)的区域,这可能会导致依赖可靠梯度的算法失效。
我们可以使用伪随机数生成器从域中生成随机样本。每个变量都需要明确定义的边界或范围,可以从该范围中均匀地随机抽取一个值,然后进行评估。
生成随机样本在计算上微不足道,并且不会占用太多内存,因此,生成大量输入样本然后对其进行评估可能是高效的。每个样本都是独立的,因此如果需要加速过程,可以并行评估样本。
以下示例给出了一个简单的一维最小化目标函数的示例,并生成然后评估100个输入值的随机样本。然后报告性能最佳的输入。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 函数优化随机搜索示例 from numpy.random import rand # 目标函数 def objective(x): return x**2.0 # 定义输入范围 r_min, r_max = -5.0, 5.0 # 从域中生成随机样本 sample = r_min + rand(100) * (r_max - r_min) # 评估样本 sample_eval = objective(sample) # 找到最佳解决方案 best_ix = 0 for i in range(len(sample)): if sample_eval[i] < sample_eval[best_ix]: best_ix = i # 总结最佳解决方案 print('Best: f(%.5f) = %.5f' % (sample[best_ix], sample_eval[best_ix])) |
运行示例会生成一个随机的输入值样本,然后对它们进行评估。接着会识别并报告表现最好的点。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
在这种情况下,我们可以看到结果非常接近最优输入0.0。
|
1 |
最佳:f(-0.01762) = 0.00031 |
我们可以更新示例以绘制目标函数并显示样本和最佳结果。完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# 带图表的函数优化随机搜索示例 from numpy import arange from numpy.random import rand from matplotlib import pyplot # 目标函数 def objective(x): return x**2.0 # 定义输入范围 r_min, r_max = -5.0, 5.0 # 从域中生成随机样本 sample = r_min + rand(100) * (r_max - r_min) # 评估样本 sample_eval = objective(sample) # 找到最佳解决方案 best_ix = 0 for i in range(len(sample)): if sample_eval[i] < sample_eval[best_ix]: best_ix = i # 总结最佳解决方案 print('Best: f(%.5f) = %.5f' % (sample[best_ix], sample_eval[best_ix])) # 以 0.1 为增量均匀采样输入范围 inputs = arange(r_min, r_max, 0.1) # 计算目标值 results = objective(inputs) # 创建输入与结果的线图 pyplot.plot(inputs, results) # 绘制样本 pyplot.scatter(sample, sample_eval) # 在最佳输入处绘制一条垂直线 pyplot.axvline(x=sample[best_ix], ls='--', color='red') # 显示绘图 pyplot.show() |
再次运行示例会生成随机样本并报告最佳结果。
|
1 |
最佳:f(0.01934) = 0.00037 |
然后创建一条线图,显示目标函数的形状、随机样本以及样本中找到的最佳结果的红线。
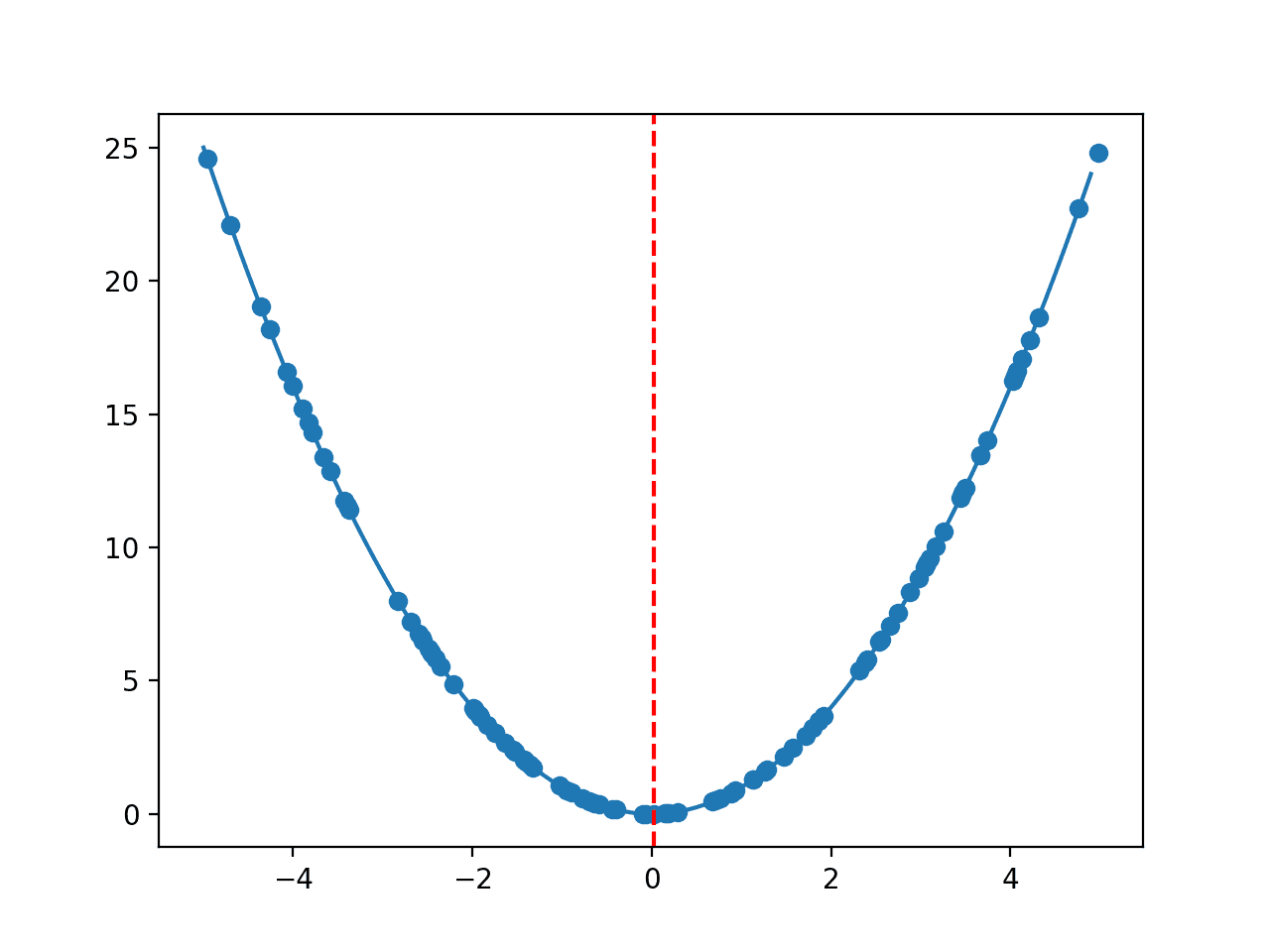
一维目标函数与随机样本的线图
函数优化的网格搜索
网格搜索也称为网格采样或全因子采样。
网格搜索涉及为目标函数生成统一的网格输入。在一维中,这将是沿线均匀分布的输入。在二维中,这将是表面上均匀分布点的格点,以此类推,适用于更高维度。
全因子抽样计划在搜索空间上放置一个均匀间隔点的网格。这种方法易于实现,不依赖于随机性,并且覆盖了空间,但它使用了大量的点。
——第235页,《优化算法》,2019年。
与随机搜索一样,网格搜索在那些通常使用领域专业知识来影响特定优化算法选择的问题上特别有效。网格可以帮助快速识别搜索空间中可能需要更多关注的区域。
样本网格通常是均匀的,尽管不一定如此。例如,可以使用对数10刻度进行均匀间隔,从而允许跨数量级进行采样。
缺点是网格的粗糙度可能会跳过搜索空间中存在良好解决方案的整个区域,随着问题输入数量(搜索空间维度)的增加,这个问题会变得更糟。
可以通过选择点的均匀间隔,然后依次枚举每个变量并按选择的间隔递增每个变量来生成样本网格。
下面的例子给出了一个简单的二维最小化目标函数的例子,并生成并评估了输入变量间距为0.1的网格样本。然后报告性能最好的输入。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 函数优化网格搜索示例 from numpy import arange from numpy.random import rand # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 定义输入范围 r_min, r_max = -5.0, 5.0 # 从域中生成网格样本 sample = list() step = 0.1 for x in arange(r_min, r_max+step, step): for y in arange(r_min, r_max+step, step): sample.append([x,y]) # 评估样本 sample_eval = [objective(x,y) for x,y in sample] # 找到最佳解决方案 best_ix = 0 for i in range(len(sample)): if sample_eval[i] < sample_eval[best_ix]: best_ix = i # 总结最佳解决方案 print('Best: f(%.5f,%.5f) = %.5f' % (sample[best_ix][0], sample[best_ix][1], sample_eval[best_ix])) |
运行该示例会生成输入值的网格,然后对其进行评估。接着会识别并报告表现最好的点。
注意:由于算法或评估过程的随机性,或者数值精度的差异,您的结果可能会有所不同。请考虑运行几次示例并比较平均结果。
在这种情况下,我们可以看到结果精确地找到了最优解。
|
1 |
最佳:f(-0.00000,-0.00000) = 0.00000 |
我们可以更新示例以绘制目标函数并显示样本和最佳结果。完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# 函数优化网格搜索示例,带绘图 from numpy import arange from numpy import meshgrid from numpy.random import rand from matplotlib import pyplot # 目标函数 def objective(x, y): return x**2.0 + y**2.0 # 定义输入范围 r_min, r_max = -5.0, 5.0 # 从域中生成网格样本 sample = list() step = 0.5 for x in arange(r_min, r_max+step, step): for y in arange(r_min, r_max+step, step): sample.append([x,y]) # 评估样本 sample_eval = [objective(x,y) for x,y in sample] # 找到最佳解决方案 best_ix = 0 for i in range(len(sample)): if sample_eval[i] < sample_eval[best_ix]: best_ix = i # 总结最佳解决方案 print('Best: f(%.5f,%.5f) = %.5f' % (sample[best_ix][0], sample[best_ix][1], sample_eval[best_ix])) # 以 0.1 为增量均匀采样输入范围 xaxis = arange(r_min, r_max, 0.1) yaxis = arange(r_min, r_max, 0.1) # 从坐标轴创建网格 x, y = meshgrid(xaxis, yaxis) # 计算目标值 results = objective(x, y) # 创建填充等高线图 pyplot.contourf(x, y, results, levels=50, cmap='jet') # 将样本绘制为黑色圆圈 pyplot.plot([x for x,_ in sample], [y for _,y in sample], '.', color='black') # 将最佳结果绘制为白色星号 pyplot.plot(sample[best_ix][0], sample[best_ix][1], '*', color='white') # 显示绘图 pyplot.show() |
再次运行示例会生成网格样本并报告最佳结果。
|
1 |
最佳:f(0.00000,0.00000) = 0.00000 |
然后创建等高线图,显示目标函数的形状,黑色圆点表示网格样本,白色星号表示样本中找到的最佳结果。
请注意,域边缘的一些黑点似乎偏离了绘图;这只是我们选择绘制点的方式(例如,未居中于样本)造成的假象。
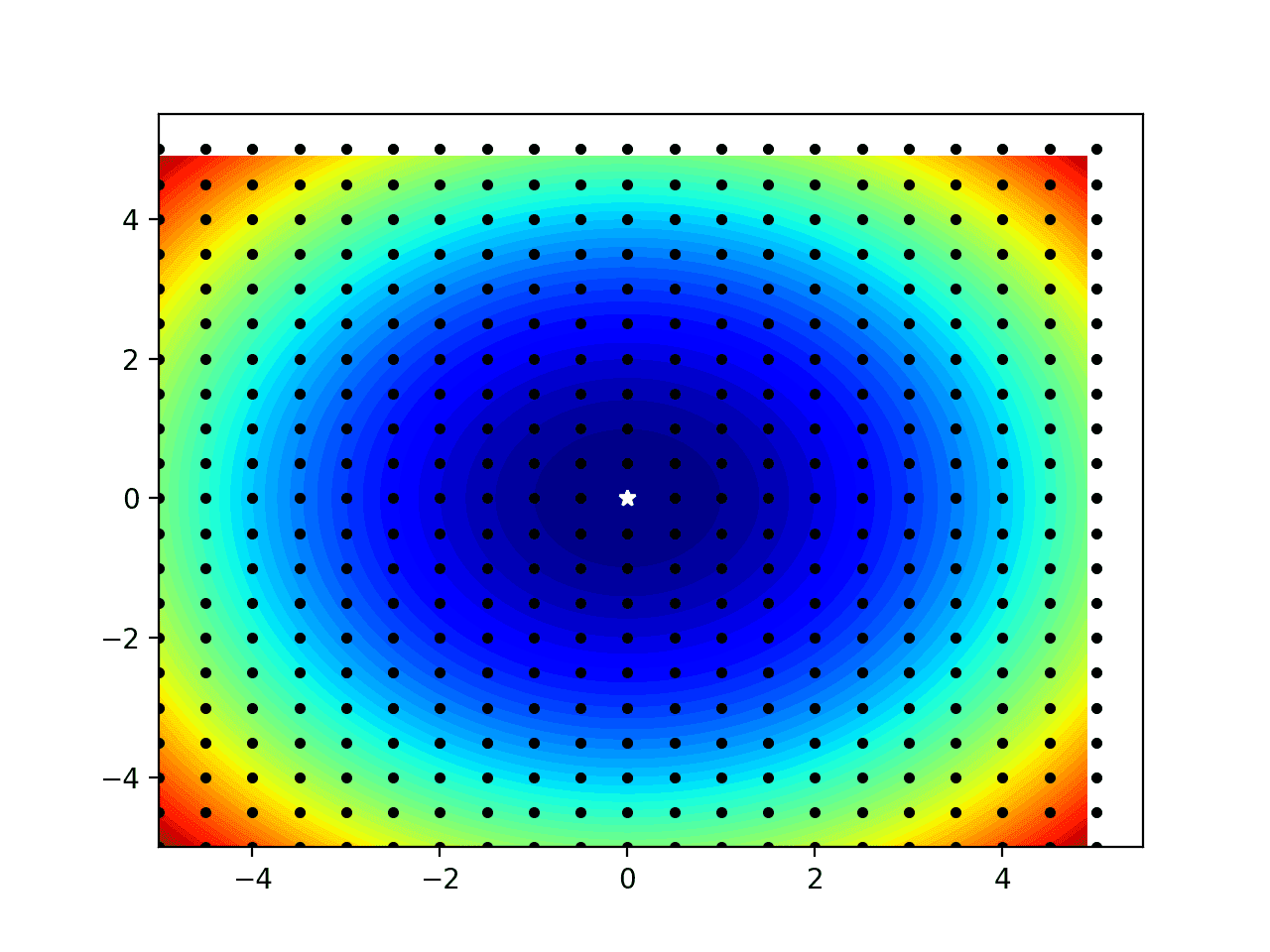
一维目标函数与网格样本的等高线图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- 优化算法, 2019.
文章
总结
在本教程中,您了解了函数优化的朴素算法。
具体来说,你学到了:
- 朴素算法在函数优化项目中的作用。
- 如何生成和评估用于函数优化的随机搜索。
- 如何生成和评估用于函数优化的网格搜索。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







你好,请问能否提供一些使用PSO算法进行数据分析和优化的示例?感谢您的合作。
感谢您的建议,或许以后会考虑。
谢谢你的代码!你有没有关于如何编写自适应随机搜索的Python脚本的例子?
你好,Honor...当然!自适应随机搜索(ARS)是一种优化算法,用于寻找函数的最小值(或最大值)。它涉及随机采样解决方案空间,并根据每次迭代的结果逐步调整搜索。
这是一个实现自适应随机搜索以最小化给定目标函数的简单 Python 脚本
### Python 自适应随机搜索脚本
pythonimport numpy as np
import matplotlib.pyplot as plt
# 目标函数(最小化)
def objective_function(x)
return x[0]**2 + x[1]**2 # 简单的二次函数
# 自适应随机搜索(ARS)算法
def adaptive_random_search(objective, bounds, n_iter, step_size, adaptive_rate, initial_solution=None)
# 随机初始化解决方案
if initial_solution is None
solution = np.random.uniform(bounds[:, 0], bounds[:, 1], size=bounds.shape[0])
else
solution = initial_solution
solution_eval = objective(solution)
best_solution, best_eval = solution, solution_eval
scores = []
for iteration in range(n_iter)
# 生成一个随机解决方案
candidate = solution + np.random.randn(bounds.shape[0]) * step_size
candidate_eval = objective(candidate)
# 如果候选解决方案更好,则采纳它if candidate_eval < best_eval: best_solution, best_eval = candidate, candidate_eval step_size *= adaptive_rate # 减小步长以微调 else: step_size /= adaptive_rate # 增大步长以探索更多 scores.append(best_eval) print(f"Iteration {iteration+1}, Best Solution: {best_solution}, Best Eval: {best_eval:.4f}, Step Size: {step_size:.4f}") return best_solution, best_eval, scores # 示例用法 if __name__ == '__main__': # 定义搜索的边界(针对每个维度) bounds = np.array([[-5.0, 5.0], [-5.0, 5.0]]) # 2D空间 # 定义参数 n_iter = 100 step_size = 0.5 adaptive_rate = 0.9 # 调整步长 # 运行ARS best_solution, best_eval, scores = adaptive_random_search(objective_function, bounds, n_iter, step_size, adaptive_rate) # 绘制随时间变化的性能 plt.plot(scores, label='Best Evaluation') plt.xlabel('迭代') plt.ylabel('目标函数值') plt.title('自适应随机搜索性能') plt.legend() plt.show() print(f"最佳解决方案: {best_solution}, 最佳目标: {best_eval:.4f}")
### 关键组件解释
1. **目标函数**:您希望最小化或最大化的函数。在此情况下,它是一个简单的二次函数 \( f(x) = x_0^2 + x_1^2 \)。您可以将其替换为您正在优化的任何函数。
2. **边界**:定义每个变量的限制(例如,在二维搜索空间中,两个变量都为 \([-5, 5]\))。
3. **步长**:决定算法在每次迭代中“跳跃”的距离。它在搜索过程中动态调整。
4. **自适应率**:步长根据算法是否找到改进的解决方案而调整的因子。
5. **随机候选生成**:通过向当前解决方案添加按步长缩放的随机高斯噪声来生成新的候选解决方案。
### 算法步骤
1. 从边界内的随机解开始。
2. 通过向当前解添加随机高斯噪声来生成随机候选解。
3. 如果新的候选解改进了目标函数,则采纳它并减小步长以专注于更精细的局部搜索。
4. 如果候选解没有改进,则增加步长以探索更多的搜索空间。
5. 重复直到达到最大迭代次数。
### 自适应机制
自适应随机搜索的关键思想是根据候选方案是否改进了当前方案来调整步长。这使得算法能够更有效地收敛到局部最小值。
您可以修改此代码,方法是
- 将
objective_function替换为您想要优化的函数。- 根据您问题的需求调整边界和步长。
如果您需要进一步的说明或代码特定部分的帮助,请告诉我!
我尝试复制了代码,它的输出结果打印得很漂亮。但是图表没有显示任何绘图(带标签的空图)。我该如何修改绘图范围来显示输出?
import numpy as np
import matplotlib.pyplot as plt
import time
start_time = time.time()
#目标函数(最小化)
def objective_function(x)
return x[0]**2 + x[1]**2
#自适应随机搜索
def adaptive_random_search(objective, bounds, n_iter, step_size, adaptive_rate, initial_solution=None)
#随机初始化解决方案
if initial_solution is None
solution = np.random.uniform(bounds[:,0], bounds[:,1], size=bounds.shape[0])
else
solution = initial_solution
solution_eval = objective(solution)
best_solution, best_eval = solution, solution_eval
scores = []
for iteration in range(n_iter)
#生成一个随机解决方案
candidate = solution + np.random.randn(bounds.shape[0]) * step_size
candidate_eval = objective(candidate)
#如果候选解决方案更好,则采纳它
if candidate_eval < best_eval
best_solution, best_eval = candidate, candidate_eval
step_size *= adaptive_rate
#减小步长以微调
else
step_size /= adaptive_rate #增大步长以探索更多
scores.append(best_eval)
print(f"迭代 {iteration+1}, 最佳解决方案: {best_solution}, 最佳评估: {best_eval:.4f}, 步长: {step_size:.4f}")
return best_solution, best_eval, scores
#示例用法
if __name__=='__main__'
#定义搜索的边界(针对每个维度)
bounds = np.array([[-5.0, 5.0],[-5.0,5.0]]) #2D空间
#定义参数
n_iter = 1000
step_size = 0.5
adaptive_rate = 0.9 #调整步长
#运行ARS
best_solution, best_eval, scores = adaptive_random_search(objective_function, bounds, n_iter, step_size, adaptive_rate)
execution_time = time.time() – start_time
print("执行时间(秒): " + str(execution_time))
#绘制随时间变化的性能
plt.plot(scores, label='最佳评估')
plt.xlabel('迭代')
plt.ylabel('目标函数值')
plt.title('自适应随机搜索性能')
plt.legend()
plt.show()
print(f"最佳解决方案:{best_solution}, 最佳目标: {best_eval:.4f}")