回归是指涉及预测数值的问题。
这与涉及预测类别的分类不同。与分类不同,您不能使用分类准确率来评估回归模型做出的预测。
相反,您必须使用专门为评估回归问题预测而设计的误差指标。
在本教程中,您将了解如何计算 **回归误差指标** 以用于预测建模项目。
完成本教程后,您将了解:
- 回归预测模型是涉及预测数值的问题。
- 回归指标涉及计算误差分数来总结模型的预测能力。
- 如何计算和报告均方误差、均方根误差和平均绝对误差。
让我们开始吧。

机器学习的回归指标
照片作者:Gael Varoquaux,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 回归预测模型
- 评估回归模型
- 回归指标
- 均方误差
- 均方根误差
- 平均绝对误差
回归预测模型
预测建模是开发一个使用历史数据进行新数据预测的模型的问题,而我们不知道答案。
预测建模可以描述为从输入变量(X)近似映射函数(f)到输出变量(y)的数学问题。这被称为函数逼近问题。
建模算法的任务是在时间和资源可用时找到最佳的映射函数。
有关应用机器学习中函数逼近的更多信息,请参阅文章
回归预测建模是从输入变量(X)到连续输出变量(y)的映射函数(f)的逼近任务。
回归与分类不同,后者涉及预测类别或类标签。
有关分类和回归之间差异的更多信息,请参阅教程
连续输出变量是实数值,例如整数或浮点数值。这些通常是数量,例如金额和大小。
例如,预测一所房屋的售价可能是一个特定的美元金额,可能在 100,000 美元到 200,000 美元之间。
- 回归问题需要预测一个数量。
- 回归可以具有实值或离散输入变量。
- 具有多个输入变量的问题通常称为多元回归问题。
- 按时间顺序排列输入变量的回归问题称为时间序列预测问题。
现在我们对回归预测建模有了了解,让我们看看如何评估回归模型。
评估回归模型
初学者在进行回归预测建模项目时常问一个问题是
如何为我的回归模型计算准确率?
准确率(例如分类准确率)是分类而不是回归的衡量标准。
我们 **不能** 为回归模型计算准确率.
回归模型的技能或性能必须报告为这些预测中的误差。
如果您仔细想想,这是有道理的。如果您正在预测一个数值,例如身高或美元金额,您不想知道模型是否完全预测了该值(这在实践中可能非常困难);相反,我们想知道预测值与预期值的接近程度。
误差恰恰解决了这个问题,并总结了预测值与预期值的平均接近程度。
有三种误差指标常用于评估和报告回归模型的性能;它们是
- 均方误差 (MSE)。
- 均方根误差 (RMSE)。
- 平均绝对误差 (MAE)
回归还有许多其他指标,尽管这些是最常用的。您可以在此处查看 scikit-learn Python 机器学习库支持的完整回归指标列表
在下一节中,我们逐一仔细了解它们。
回归指标
在本节中,我们将仔细研究流行的回归模型指标以及如何为您的预测建模项目计算它们。
均方误差
均方误差,简称 MSE,是回归问题的流行误差指标。
它也是使用回归问题的最小二乘框架拟合或优化的算法的重要损失函数。这里的“最小二乘”指的是最小化预测值与预期值之间的均方误差。
MSE 计算为数据集中预测值和预期目标值之间平方差的均值或平均值。
- MSE = 1 / N * sum for i to N (y_i – yhat_i)^2
其中 _y_i_ 是数据集中第 i 个预期值,_yhat_i_ 是第 i 个预测值。这两个值之间的差值被平方,这具有去除符号的效果,从而得到正误差值。
平方运算还会放大或夸大较大的误差。也就是说,预测值与预期值之间的差值越大,得到的平方正误差就越大。当 MSE 用作损失函数时,这会“惩罚”模型更大的误差。当用作指标时,它还会通过放大平均误差分数来“惩罚”模型。
我们可以创建一个图来感受预测误差的变化如何影响平方误差。
下面的示例提供了一个小型的人工数据集,其中所有预期值均为 1.0,预测值从完美 (1.0) 到错误 (0.0) 以 0.1 的增量变化。计算并绘制了每个预测值与预期值之间的平方误差,以显示平方误差的二次方增长。
|
1 2 3 |
... # 计算误差 err = expected[i] - predicted[i]**2 |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 均方误差增加示例 from matplotlib import pyplot from sklearn.metrics import mean_squared_error # 真实值 expected = [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0] # 预测值 predicted = [1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1, 0.0] # 计算误差 errors = list() for i in range(len(expected)): # 计算误差 err = (expected[i] - predicted[i])**2 # 存储误差 errors.append(err) # 报告误差 print('>%.1f, %.1f = %.3f' % (expected[i], predicted[i], err)) # 绘制误差 pyplot.plot(errors) pyplot.xticks(ticks=[i for i in range(len(errors))], labels=predicted) pyplot.xlabel('预测值') pyplot.ylabel('均方误差') pyplot.show() |
运行该示例首先报告每个情况的预期值、预测值和平方误差。
我们可以看到误差上升得很快,比线性(直线)快。
|
1 2 3 4 5 6 7 8 9 10 11 |
>1.0, 1.0 = 0.000 >1.0, 0.9 = 0.010 >1.0, 0.8 = 0.040 >1.0, 0.7 = 0.090 >1.0, 0.6 = 0.160 >1.0, 0.5 = 0.250 >1.0, 0.4 = 0.360 >1.0, 0.3 = 0.490 >1.0, 0.2 = 0.640 >1.0, 0.1 = 0.810 >1.0, 0.0 = 1.000 |
创建的折线图显示,随着预期值和预测值之间差异的增加,平方误差值呈曲线状或超线性增长。
该曲线不是我们可能想当然的直线,因为这是一种误差指标。
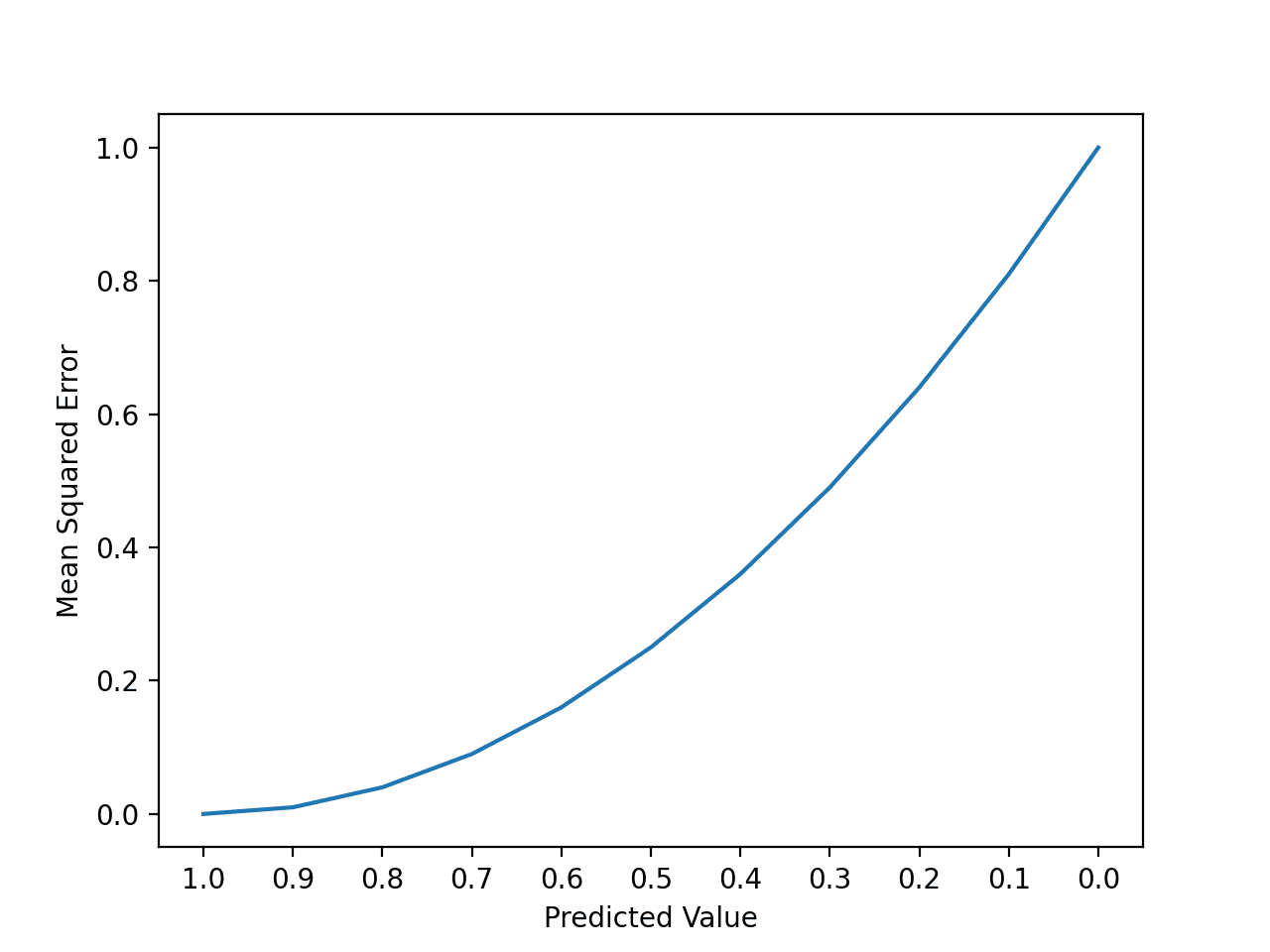
预测平方误差增加的折线图
将各个误差项进行平均,以便我们可以报告模型的性能,即模型在进行预测时通常会产生多少误差,而不是针对特定示例。
MSE 的单位是平方单位。
例如,如果您的目标值代表“美元”,那么 MSE 将是“平方美元”。这可能会让利益相关者感到困惑;因此,在报告结果时,通常使用均方根误差(在下一节讨论)。
您预期值和预测值之间的均方误差可以使用 scikit-learn 库中的 mean_squared_error() 函数 来计算。
该函数接受一系列一维数组或列表的预期值和预测值,并返回均方误差值。
|
1 2 3 |
... # 计算误差 errors = mean_squared_error(expected, predicted) |
下面的示例给出了一个计算一组人为设定的预期值和预测值之间均方误差的示例。
|
1 2 3 4 5 6 7 8 9 10 |
# 计算均方误差的示例 from sklearn.metrics import mean_squared_error # 真实值 expected = [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0] # 预测值 predicted = [1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1, 0.0] # 计算误差 errors = mean_squared_error(expected, predicted) # 报告误差 print(errors) |
运行该示例将计算并打印均方误差。
|
1 |
0.35000000000000003 |
完美的均方误差值为 0.0,这意味着所有预测都完全匹配预期值。
这几乎从未发生过,如果发生,则表明您的预测建模问题过于简单。
好的 MSE 是相对于您的特定数据集而言的。
最好首先使用朴素预测模型(例如,预测训练数据集中的目标值均值)来建立数据集的基线 MSE。达到比朴素模型 MSE 更好的 MSE 的模型具有技能。
均方根误差
均方根误差,简称 RMSE,是均方误差的扩展。
重要的是,计算了误差的平方根,这意味着 RMSE 的单位与正在预测的目标值的原始单位相同。
例如,如果您的目标变量的单位是“美元”,那么 RMSE 误差分数也将是“美元”单位,而不是像 MSE 那样的“平方美元”。
因此,通常使用 MSE 损失来训练回归预测模型,并使用 RMSE 来评估和报告其性能。
RMSE 的计算方法如下:
- RMSE = sqrt(1 / N * sum for i to N (y_i – yhat_i)^2)
其中 _y_i_ 是数据集中第 i 个预期值,_yhat_i_ 是第 i 个预测值,_sqrt()_ 是平方根函数。
我们可以将 RMSE 重写为 MSE:
- RMSE = sqrt(MSE)
请注意,RMSE 不能计算为均方误差值的平方根的平均值。这是初学者常犯的一个错误,也是 Jensen 不等式 的一个例子。
您可能还记得,平方根是平方运算的逆运算。MSE 使用平方运算来去除每个误差值的符号并惩罚较大的误差。平方根会逆转此运算,同时确保结果保持为正。
您预期值和预测值之间的均方根误差可以使用 scikit-learn 库中的 mean_squared_error() 函数 来计算。
默认情况下,该函数计算 MSE,但我们可以通过将“squared”参数设置为 _False_ 来配置它以计算 MSE 的平方根。
该函数接受一系列一维数组或列表的预期值和预测值,并返回均方误差值。
|
1 2 3 |
... # 计算误差 errors = mean_squared_error(expected, predicted, squared=False) |
下面的示例给出了一个计算一组人为设定的预期值和预测值之间均方根误差的示例。
|
1 2 3 4 5 6 7 8 9 10 |
# 计算均方根误差的示例 from sklearn.metrics import mean_squared_error # 真实值 expected = [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0] # 预测值 predicted = [1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1, 0.0] # 计算误差 errors = mean_squared_error(expected, predicted, squared=False) # 报告误差 print(errors) |
运行该示例将计算并打印均方根误差。
|
1 |
0.5916079783099616 |
完美的 RMSE 值为 0.0,这意味着所有预测都完全匹配预期值。
这几乎从未发生过,如果发生,则表明您的预测建模问题过于简单。
好的 RMSE 是相对于您的特定数据集而言的。
最好首先使用朴素预测模型(例如,预测训练数据集中的目标值均值)来建立数据集的基线 RMSE。达到比朴素模型 RMSE 更好的 RMSE 的模型具有技能。
平均绝对误差
平均绝对误差,简称 MAE,是一个流行的指标,因为与 RMSE 一样,误差分数的单位与正在预测的目标值的单位相匹配。
与 RMSE 不同,MAE 的变化是线性的,因此很直观。
也就是说,MSE 和 RMSE 比小误差更惩罚大误差,从而夸大或放大平均误差分数。这是由于误差值的平方。MAE 不会对不同类型的误差给予更多或更少的权重,而是随着误差的增加,分数线性增加。
顾名思义,MAE 分数是绝对误差值的平均值。绝对值或 _abs()_ 是一个使数字变为正数的数学函数。因此,预期值与预测值之间的差值可以是正数或负数,在计算 MAE 时会被强制为正数。
MAE 的计算方法如下:
- MAE = 1 / N * sum for i to N abs(y_i – yhat_i)
其中 _y_i_ 是数据集中第 i 个预期值,_yhat_i_ 是第 i 个预测值,_abs()_ 是绝对值函数。
我们可以创建一个图来感受预测误差的变化如何影响 MAE。
下面的示例提供了一个小型的人工数据集,其中所有预期值均为 1.0,预测值从完美 (1.0) 到错误 (0.0) 以 0.1 的增量变化。计算并绘制了每个预测值与预期值之间的绝对误差,以显示误差的线性增加。
|
1 2 3 |
... # 计算误差 err = abs((expected[i] - predicted[i])) |
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 预测平均绝对误差增加的图 from matplotlib import pyplot from sklearn.metrics import mean_squared_error # 真实值 expected = [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0] # 预测值 predicted = [1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1, 0.0] # 计算误差 errors = list() for i in range(len(expected)): # 计算误差 err = abs((expected[i] - predicted[i])) # 存储误差 errors.append(err) # 报告误差 print('>%.1f, %.1f = %.3f' % (expected[i], predicted[i], err)) # 绘制误差 pyplot.plot(errors) pyplot.xticks(ticks=[i for i in range(len(errors))], labels=predicted) pyplot.xlabel('预测值') pyplot.ylabel('平均绝对误差') pyplot.show() |
运行该示例首先报告每个情况的预期值、预测值和绝对误差。
我们可以看到误差呈线性增加,这是直观且易于理解的。
|
1 2 3 4 5 6 7 8 9 10 11 |
>1.0, 1.0 = 0.000 >1.0, 0.9 = 0.100 >1.0, 0.8 = 0.200 >1.0, 0.7 = 0.300 >1.0, 0.6 = 0.400 >1.0, 0.5 = 0.500 >1.0, 0.4 = 0.600 >1.0, 0.3 = 0.700 >1.0, 0.2 = 0.800 >1.0, 0.1 = 0.900 >1.0, 0.0 = 1.000 |
创建的折线图显示,随着预期值和预测值之间差异的增加,绝对误差值呈直线状或线性增加。
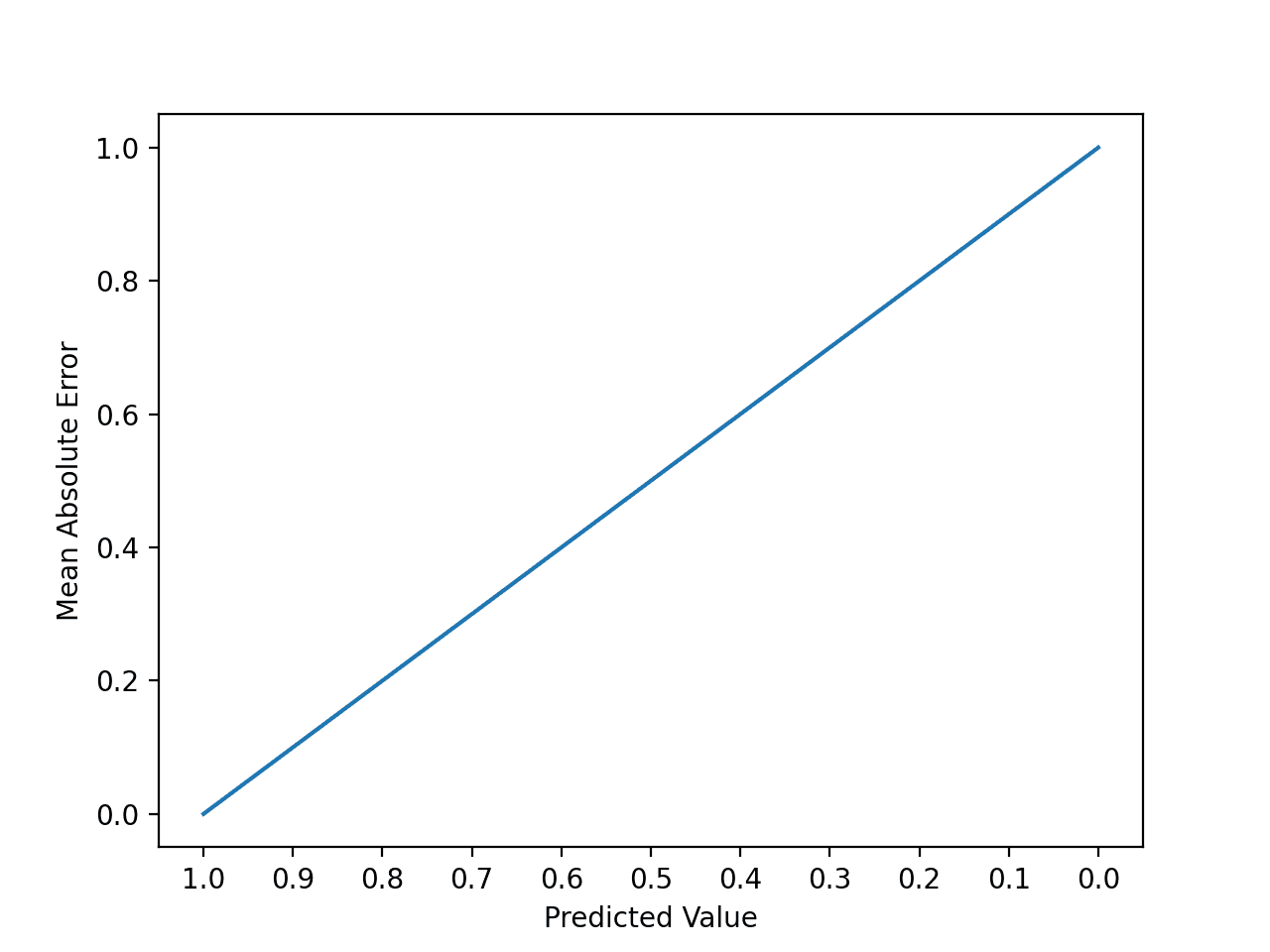
预测绝对误差增加的折线图
您预期值和预测值之间的平均绝对误差可以使用 scikit-learn 库中的 mean_absolute_error() 函数 来计算。
该函数接受一系列一维数组或列表的预期值和预测值,并返回平均绝对误差值。
|
1 2 3 |
... # 计算误差 errors = mean_absolute_error(expected, predicted) |
下面的示例给出了一个计算一组人为设定的预期值和预测值之间平均绝对误差的示例。
|
1 2 3 4 5 6 7 8 9 10 |
# 计算平均绝对误差的示例 from sklearn.metrics import mean_absolute_error # 真实值 expected = [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0] # 预测值 predicted = [1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1, 0.0] # 计算误差 errors = mean_absolute_error(expected, predicted) # 报告误差 print(errors) |
运行该示例将计算并打印平均绝对误差。
|
1 |
0.5 |
完美的平均绝对误差值为 0.0,这意味着所有预测都完全匹配预期值。
这几乎从未发生过,如果发生,则表明您的预测建模问题过于简单。
好的 MAE 是相对于您的特定数据集而言的。
最好首先使用朴素预测模型(例如,预测训练数据集中的目标值均值)来建立数据集的基线 MAE。达到比朴素模型 MAE 更好的 MAE 的模型具有技能。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
API
- Scikit-Learn API:回归指标.
- Scikit-Learn 用户指南第 3.3.4 节。回归指标.
- sklearn.metrics.mean_squared_error API.
- mean_absolute_error API.
文章
总结
在本教程中,您学习了如何计算回归预测项目的误差。
具体来说,你学到了:
- 回归预测模型是涉及预测数值的问题。
- 回归指标涉及计算误差分数来总结模型的预测能力。
- 如何计算和报告均方误差、均方根误差和平均绝对误差。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。






非常感谢您的精彩文章。您有计划解释其他回归指标,例如 r2_score、RMSLE、MAPE、Pearson 相关系数等吗?
是的,我希望将来能做到。
那太好了!😉
这很好,但直线误差在小于 1 的值时高于抛物线,我不知道这是否是错误,或者是我错过了什么?
抱歉,我没明白,您能详细说明一下吗?
大家在 MSE 上遗漏的一点是,它只在误差大于 1 时惩罚大误差。但在误差范围从 0 到 1(就像您的情况)时,取平方实际上是在折算误差,我们可以在您的图上清楚地看到这一点,其中直线实际上位于 MSE 曲线之上。
你说得对。但是,作为一种指标,这可能不是问题,因为接近 0 的值比接近 1 的值打折更多。
附注:您为什么不使用 mathjax?它是一个 JavaScript 库,可以让您很好地显示数学公式,这将大大提高可读性。
但是这篇文章本身已经很棒了!
是的,这是故意的,旨在使内容对开发人员更具吸引力。
关于 MSE 有趣的一点是,如果您有异常值,它通常会对误差和算法产生很大的影响(恕我直言)。
同意,对异常值预测中的误差惩罚更大。
嗨,Jason,
很棒的概述。我认为MAE部分开头的这句话有一个错别字:“与RMSE不同,RMSE的变化是线性的,因此是直观的。”是不是应该写成:“与RMSE不同,MAE的变化是线性的,因此是直观的。”?
谢谢,已修复!
你好。感谢这篇文章,它真的很有帮助!有一个问题
> 首先为数据集建立一个基准MAE是一个好主意,可以使用一个简单的预测模型,比如从训练数据集中预测目标值的平均值。一个MAE比简单模型的MAE更好的模型就具有技能。
如何制作一个简单的预测模型?通过制作一个平均目标值的列,然后在其上进行预测?我理解得对吗?
是的!
你可以预测训练集的平均值。
Jason,你能详细解释一下吗?我该如何制作一个简单的预测模型?我很尴尬地承认,我无法理解你说的“训练集的平均值”是什么意思。
另外,“测试套件”是什么意思?在你一个XGBoost回归的例子中提到
“使用包含三次重复的、经过分层的10折交叉验证的测试套件,简单模型可以达到约6.6的平均绝对误差(MAE)。表现最佳的模型在该测试套件上可以达到约1.9的MAE。这为该数据集的预期性能提供了界限。”
如何找到简单模型的数值和表现最佳的模型界限?提前非常感谢。
测试套件只是指你将应用于模型的测试集合。那些应该是具有足够变化的测试用例,可以给模型一个好的分数。在引用的句子中,它是通过分层交叉验证生成的。
谢谢Adrian的回复。我明白了你的意思。
我后来还找到了Jason在这里发布的文章,他解释了如何使用零规则算法进行简单基线预测
https://machinelearning.org.cn/implement-baseline-machine-learning-algorithms-scratch-python/
但我仍然不知道如何确定任何给定数据集上的预期性能的上限。提前感谢大家。
我知道你在这里没有讨论MAPE,但你提到了我们无法计算回归模型的准确性。你认为为了报告目的,将MAPE减去1以获得“准确性”有什么看法吗?
那将是反向MAPE(或类似的东西),而不是准确性。
你好Jason。
是否有可能为机器学习模型设定一个目标值?比如模型可以产生0.7的MAE,但我希望我的MAE是0.2,所以我希望模型一直循环直到达到所需的值。
这是可能的,还是仅仅接受模型在数据集上的表现?
对于给定的模型+数据集+测试套件,可能无法实现给定的指标得分。
你好Jason,我有点困惑。在回归预测建模部分,你提到“具有多个输入变量的问题通常称为*多元回归*问题。”
但是根据我在网上其他地方看到的,多元回归问题是指输出变量(即多个y变量)的问题。而多重回归问题是指输入变量(即多个x变量)的问题。
例如
https://www.quora.com/What-is-the-difference-between-a-multiple-linear-regression-and-a-multivariate-regression
也许这会有所帮助
https://machinelearning.org.cn/taxonomy-of-time-series-forecasting-problems/
归根结底,使用能帮助你理解问题的术语。
非常感谢您的精彩文章。
> 初学者在回归预测建模项目中的一个常见问题是
>
> 如何计算回归模型的准确性?
>
> 准确性(例如分类准确性)是分类的度量,而不是回归。
>
> 我们无法计算回归模型的准确性。
这正是我现在面临问题的答案。
许多人仍然相信深度学习,并想要准确性(尽管是回归问题)。
事实上,回归问题的指标,比如这里描述的那些,可能很难想象(对于那些避免学习数学的成年人来说)。
我想知道他们是更好地理解这里的解释,还是通过展示混淆矩阵,将其归为分类问题会更好。
很高兴听到这篇教程有帮助。
至少,我正在学习……………………
太棒了!
你好,我只是想知道你是否知道我可以在我的iPad上使用的任何软件,如果有的话。谢谢。
iPad 真的不是这些东西的好环境。如果你为它配一个蓝牙键盘,你大概可以用它作为一个浏览器,并在 Google Colab 上进行你的项目。
关于指标的文章写得很好,但我的小问题是,绝对误差的正确公式是什么,是实际值减去预测值,还是预测值减去实际值
不重要——因为你会取差值的绝对值。
嗨,Jason,
我有一个关于评估单步预测和多步预测的MSE的问题。
模型以两种不同的方式进行训练
1. 执行单步预测,使用60个时间步长的历史值。
2. 执行5步预测,使用60个时间步长的历史值。
我的问题是,多步预测是否会提高第一次预测的准确性?
例如,
我训练了单步预测并获得了0.045的MSE。
我还训练了5步预测,但我计算了单步预测的MSE,得到了0.0047的MSE。
我尝试比较两个模型的单步预测MSE。
我的假设是,如果我们用多步预测来训练模型,将会提高单步预测的准确性。但MSE并没有显示任何改进。
我能知道我的假设是否正确吗?与用单步预测训练的模型相比,用多步预测训练的模型会提高单步预测的准确性吗?
非常感谢
你的假设不一定总是正确的——这取决于具体的模型。考虑最简单的ARIMA模型,p=1,多步预测只是预测噪声。
感谢这篇精彩的文章。
是否有用于选择多个有效性指标中哪一个的指标?
我刚刚发现了以下关于分类问题的非常有用的文章。
https://machinelearning.org.cn/tour-of-evaluation-metrics-for-imbalanced-classification/
致以最诚挚的问候。
我正在尝试找到最优的输入参数,以便模拟模型能够准确地预测低值和高值,即预测值应接近1:1线(观测值 vs 预测值)。在这种情况下,最佳的误差度量是什么?
你好Urs……你可能会觉得以下内容有帮助
https://machinelearning.org.cn/optimization-for-machine-learning-crash-course/
你好,
这是一篇关于回归中指标的非常好的文章。谢谢你。
一个常见的问题,比如“对异常值鲁棒”是什么意思?你能解释一下这个术语吗?
你好Dafrin……这意味着模型的准确性不会受到少数数据点(这些数据点不在大多数数据范围内)的太大影响。更多信息可以在这里找到
https://machinelearning.org.cn/robust-regression-for-machine-learning-in-python/
你好Jason。非常好的文章!我想问一下。R方可以作为衡量回归模型性能的指标吗?我想听听你的意见!
Kostas,不客气!以下内容可能对您有益
https://www.statology.org/r-squared-in-python/
什么是R2?
它与文章中定义的三个误差度量不同吗?
1)MSE
2)RMSE
3)MAE
请详细说明。
你好Sandeep……以下资源可能会增加清晰度
https://statisticsbyjim.com/regression/interpret-r-squared-regression/
非常感谢您的教程,,,它非常有帮助...????