您可能观测值的频率不正确。
也许它们太精细或不够精细。Python 中的 Pandas 库提供了改变时间序列数据频率的能力。
在本教程中,您将了解如何使用 Python 中的 Pandas 来提高和降低时间序列数据的采样频率。
完成本教程后,您将了解:
- 关于时间序列重采样、两种重采样类型以及您需要使用它们的两大原因。
- 如何使用 Pandas 将时间序列数据重采样到更高的频率并对新观测值进行插值。
- 如何使用 Pandas 将时间序列数据降采样到更低的频率并汇总更高频率的观测值。
启动您的项目,阅读我的新书《Python 时间序列预测》,其中包含分步教程以及所有示例的Python 源代码文件。
让我们开始吧。
- 更新于 2016 年 12 月:修复了上采样和下采样定义的错误。
- 2019 年 4 月更新:更新了数据集链接。

如何使用 Python 重采样和插值时间序列数据
照片来自 sung ming whang,部分权利保留。
重采样
重采样涉及更改时间序列观测值的频率。
有两种重采样:
- 上采样:提高样本的频率,例如从分钟到秒。
- 下采样:降低样本的频率,例如从天到月。
在这两种情况下,都必须生成数据。
在进行上采样时,需要注意如何使用插值来计算精细级别的数据。在进行下采样时,需要注意选择用于计算新汇总值的汇总统计量。
您可能对重采样时间序列数据感兴趣的原因可能有两个:
- 问题框架:如果您的数据不可用,而您希望以特定的频率进行预测,则可能需要重采样。
- 特征工程:重采样还可以为监督学习模型提供额外的结构或洞察力。
这两种情况之间存在很多重叠。
例如,您可能拥有每日数据并希望预测每月问题。您可以直接使用每日数据,也可以将其降采样为每月数据并开发模型。
特征工程的视角可能在开发模型时利用来自两个时间尺度的观测值和汇总值。
让我们通过查看真实数据集和一些示例来具体化重采样。
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
洗发水销售数据集
此数据集描述了三年期间每月洗发水销售数量。
单位是销售计数,共有 36 个观测值。原始数据集归功于 Makridakis、Wheelwright 和 Hyndman (1998)。
以下是数据的前 5 行样本,包括标题行。
|
1 2 3 4 5 6 |
"Month","Sales" "1-01",266.0 "1-02",145.9 "1-03",183.1 "1-04",119.3 "1-05",180.3 |
以下是整个数据集的图。
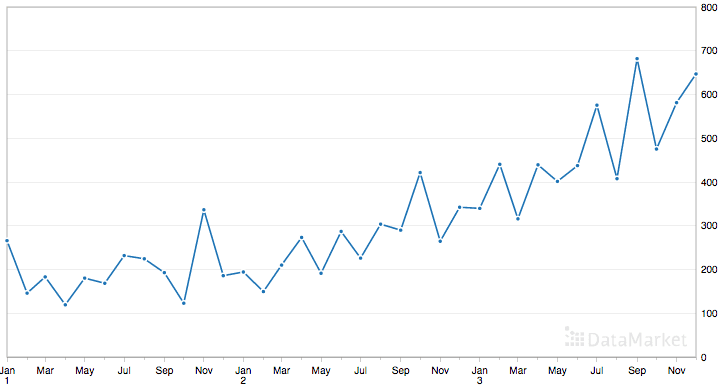
洗发水销售数据集
该数据集显示出递增的趋势,可能还有一些季节性成分。
加载洗发水销售数据集
下载数据集并将其放在当前工作目录中,文件名为“shampoo-sales.csv”。
数据集中时间戳没有绝对年份,但有月份。我们可以编写一个自定义日期解析函数来加载此数据集,并选择一个任意年份,例如 1900 年,作为年份基线。
以下是使用来自read_csv()的自定义日期解析函数加载洗发水销售数据集的代码片段。
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import read_csv from pandas import datetime from matplotlib import pyplot def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) print(series.head()) series.plot() pyplot.show() |
运行此示例会加载数据集并打印前 5 行。这显示了从 1900 年开始的日期处理的正确性。
|
1 2 3 4 5 6 7 |
月份 1901-01-01 266.0 1901-02-01 145.9 1901-03-01 183.1 1901-04-01 119.3 1901-05-01 180.3 Name: Sales of shampoo over a three year period, dtype: float64 |
我们还得到了数据集的图表,显示了销售额从一个月到另一个月的增长趋势。
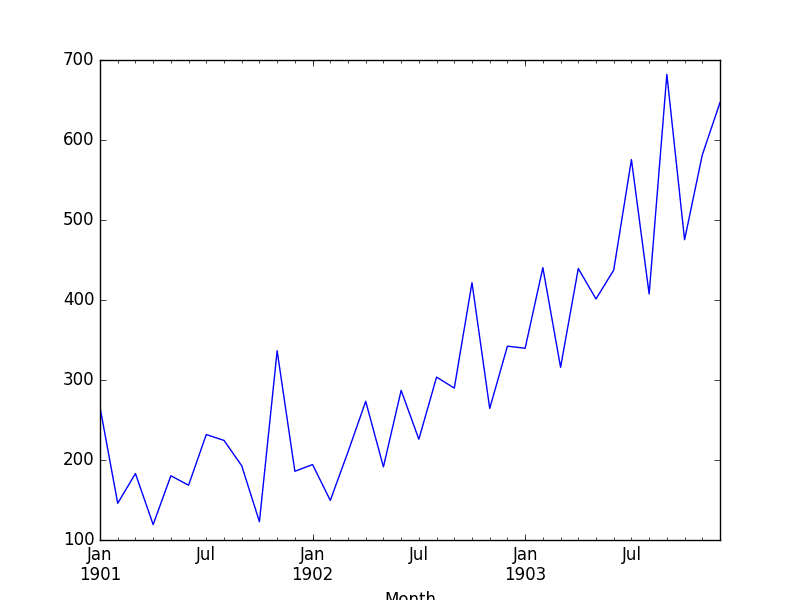
洗发水销售数据集图
上采样洗发水销售
洗发水销售中的观测值为月度。
假设我们想要每日销售信息。我们将不得不将频率从月度上采样到每日,并使用插值方案来填充新的每日频率。
Pandas 库在Series和DataFrame对象上提供了名为resample()的函数。这可用于在下采样时对记录进行分组,并在上采样时为新观测值留出空间。
我们可以通过调用重采样并指定首选的日历日频率或“D”来使用此函数将我们的月度数据集转换为每日数据集。
Pandas 很智能,您可以轻松地将频率指定为“1D”甚至特定于域的内容,例如“5D”。有关您可以使用的别名列表,请参阅本教程结尾的“进一步阅读”部分。
|
1 2 3 4 5 6 7 8 9 |
from pandas import read_csv from pandas import datetime def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) upsampled = series.resample('D') print(upsampled.head(32)) |
运行此示例会打印上采样数据集的前 32 行,显示一月份的每一天和二月份的第一天。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
月份 1901-01-01 266.0 1901-01-02 NaN 1901-01-03 NaN 1901-01-04 NaN 1901-01-05 NaN 1901-01-06 NaN 1901-01-07 NaN 1901-01-08 NaN 1901-01-09 NaN 1901-01-10 NaN 1901-01-11 NaN 1901-01-12 NaN 1901-01-13 NaN 1901-01-14 NaN 1901-01-15 NaN 1901-01-16 NaN 1901-01-17 NaN 1901-01-18 NaN 1901-01-19 NaN 1901-01-20 NaN 1901-01-21 NaN 1901-01-22 NaN 1901-01-23 NaN 1901-01-24 NaN 1901-01-25 NaN 1901-01-26 NaN 1901-01-27 NaN 1901-01-28 NaN 1901-01-29 NaN 1901-01-30 NaN 1901-01-31 NaN 1901-02-01 145.9 |
我们可以看到resample()函数已经创建了行,并在新值中填充了 NaN 值。我们可以看到一月和二月第一天仍然是我们原始数据中的销售量。
接下来,我们可以插值这些新频率下的缺失值。
Pandas 的Series对象提供了interpolate()函数来插值缺失值,并且有一系列简单的和更复杂的插值函数可供选择。您可能拥有领域知识来帮助选择如何插值数值。
一个好的起点是使用线性插值。这会在可用数据(在本例中为每月的第一天)之间绘制一条直线,并根据该直线填充所选频率的值。
|
1 2 3 4 5 6 7 8 9 10 |
from pandas import read_csv from pandas import datetime def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) upsampled = series.resample('D') interpolated = upsampled.interpolate(method='linear') print(interpolated.head(32)) |
运行此示例,我们可以看到插值后的值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
月份 1901-01-01 266.000000 1901-01-02 262.125806 1901-01-03 258.251613 1901-01-04 254.377419 1901-01-05 250.503226 1901-01-06 246.629032 1901-01-07 242.754839 1901-01-08 238.880645 1901-01-09 235.006452 1901-01-10 231.132258 1901-01-11 227.258065 1901-01-12 223.383871 1901-01-13 219.509677 1901-01-14 215.635484 1901-01-15 211.761290 1901-01-16 207.887097 1901-01-17 204.012903 1901-01-18 200.138710 1901-01-19 196.264516 1901-01-20 192.390323 1901-01-21 188.516129 1901-01-22 184.641935 1901-01-23 180.767742 1901-01-24 176.893548 1901-01-25 173.019355 1901-01-26 169.145161 1901-01-27 165.270968 1901-01-28 161.396774 1901-01-29 157.522581 1901-01-30 153.648387 1901-01-31 149.774194 1901-02-01 145.900000 |
从折线图来看,我们看不到绘制折线图时与绘制原始数据有任何区别,因为图表已经插值了点之间的值。
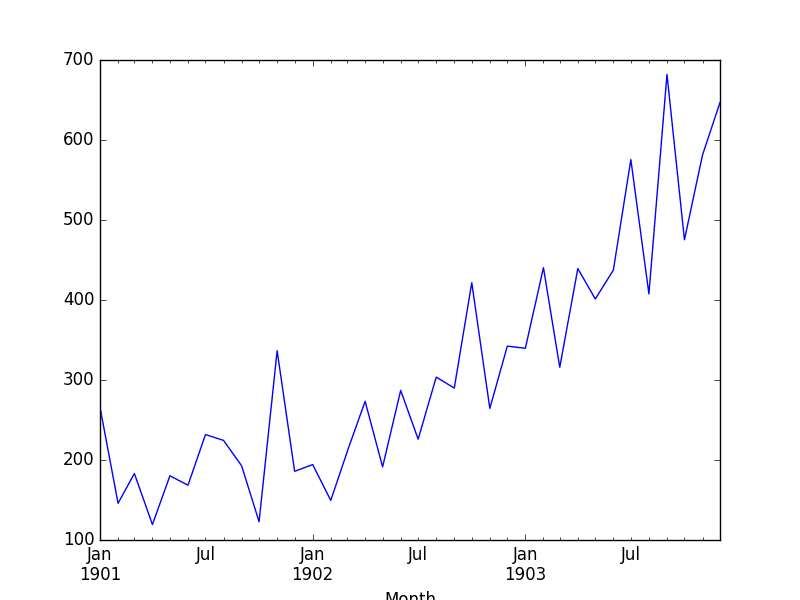
洗发水销售线性插值
另一种常见的插值方法是使用多项式或样条来连接数值。
这会创建更多曲线,并且在许多数据集上看起来更自然。使用样条插值需要指定阶数(多项式的项数);在这种情况下,2 阶就足够了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pandas import read_csv from pandas import datetime from matplotlib import pyplot def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) upsampled = series.resample('D') interpolated = upsampled.interpolate(method='spline', order=2) print(interpolated.head(32)) interpolated.plot() pyplot.show() |
运行示例,我们首先可以查看原始插值值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
月份 1901-01-01 266.000000 1901-01-02 258.630160 1901-01-03 251.560886 1901-01-04 244.720748 1901-01-05 238.109746 1901-01-06 231.727880 1901-01-07 225.575149 1901-01-08 219.651553 1901-01-09 213.957094 1901-01-10 208.491770 1901-01-11 203.255582 1901-01-12 198.248529 1901-01-13 193.470612 1901-01-14 188.921831 1901-01-15 184.602185 1901-01-16 180.511676 1901-01-17 176.650301 1901-01-18 173.018063 1901-01-19 169.614960 1901-01-20 166.440993 1901-01-21 163.496161 1901-01-22 160.780465 1901-01-23 158.293905 1901-01-24 156.036481 1901-01-25 154.008192 1901-01-26 152.209039 1901-01-27 150.639021 1901-01-28 149.298139 1901-01-29 148.186393 1901-01-30 147.303783 1901-01-31 146.650308 1901-02-01 145.900000 |
回顾折线图,我们可以看到插值后的值更加自然的曲线。
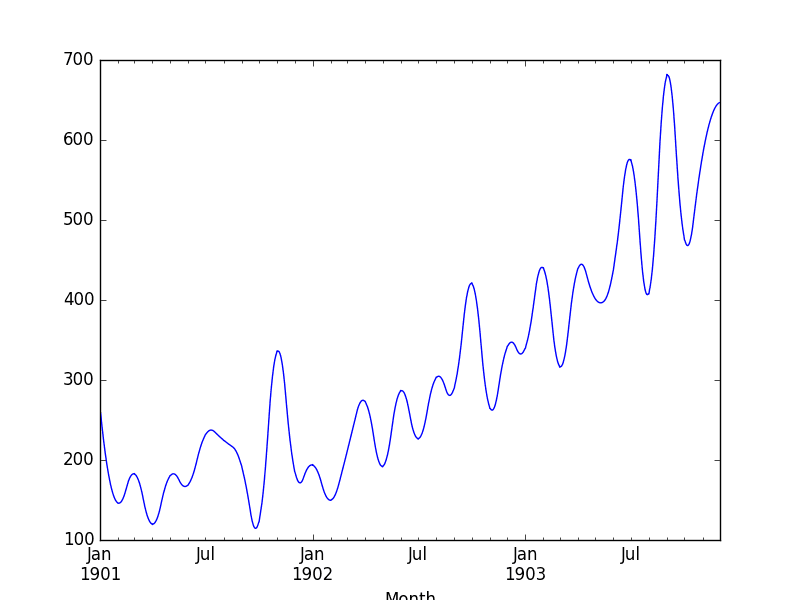
洗发水销售样条插值
总的来说,当您有缺失的观测值时,插值是一个有用的工具。
接下来,我们将考虑反方向重采样,降低观测值的频率。
下采样洗发水销售
销售数据是月度的,但也许我们更希望数据是季度的。
一年可以分为 4 个业务季度,每个季度 3 个月。
Pandas 中的resample()函数不是在现有观测值之间创建新行,而是按新频率对所有观测值进行分组。
我们可以使用“3M”这样的别名来创建 3 个月的组,但这可能会遇到问题,如果我们的观测值不是从一月、四月、七月或十月开始的。Pandas 有一个名为“Q”的季度感知别名,我们可以为此目的使用。
我们现在必须决定如何从每 3 条记录的组中创建新的季度值。一个好的起点是计算该季度的平均月度销售额。为此,我们可以使用mean()函数。
将所有内容放在一起,我们得到以下代码示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pandas import read_csv from pandas import datetime from matplotlib import pyplot def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) resample = series.resample('Q') quarterly_mean_sales = resample.mean() print(quarterly_mean_sales.head()) quarterly_mean_sales.plot() pyplot.show() |
运行示例会打印季度数据的前 5 行。
|
1 2 3 4 5 6 7 |
月份 1901-03-31 198.333333 1901-06-30 156.033333 1901-09-30 216.366667 1901-12-31 215.100000 1902-03-31 184.633333 Freq: Q-DEC, Name: Sales, dtype: float64 |
我们还绘制了季度数据,显示了原始观测值 3 年的 Q1-Q4。
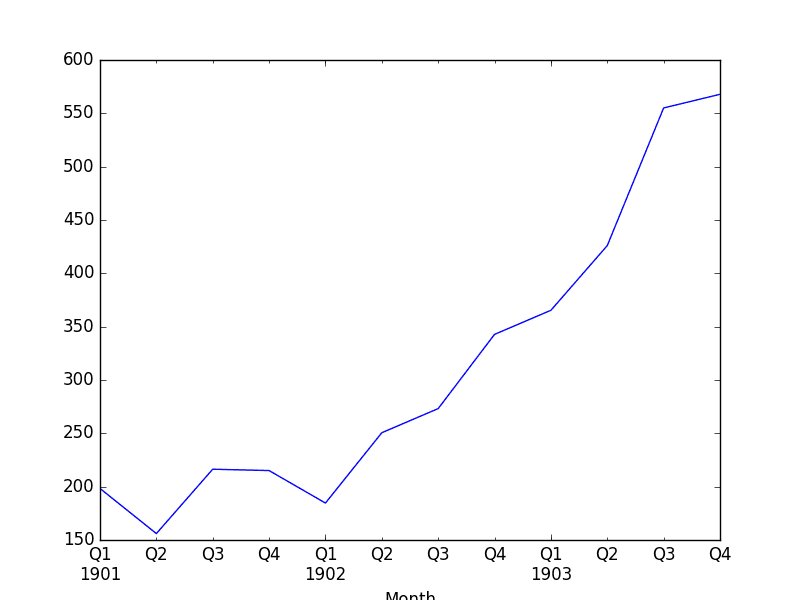
洗发水销售下采样季度
也许我们想做得更进一步,将月度数据变成年度数据,也许之后再用它来建模第二年。
我们可以使用“A”作为年末频率的别名来下采样数据,并在此次使用 sum 来计算每年的总销售额。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pandas import read_csv from pandas import datetime from matplotlib import pyplot def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) resample = series.resample('A') quarterly_mean_sales = resample.sum() print(quarterly_mean_sales.head()) quarterly_mean_sales.plot() pyplot.show() |
运行示例显示了 3 年观测值的 3 条记录。
我们还得到了一个图表,正确地将年份显示在 x 轴上,并将每年的总销售额显示在 y 轴上。
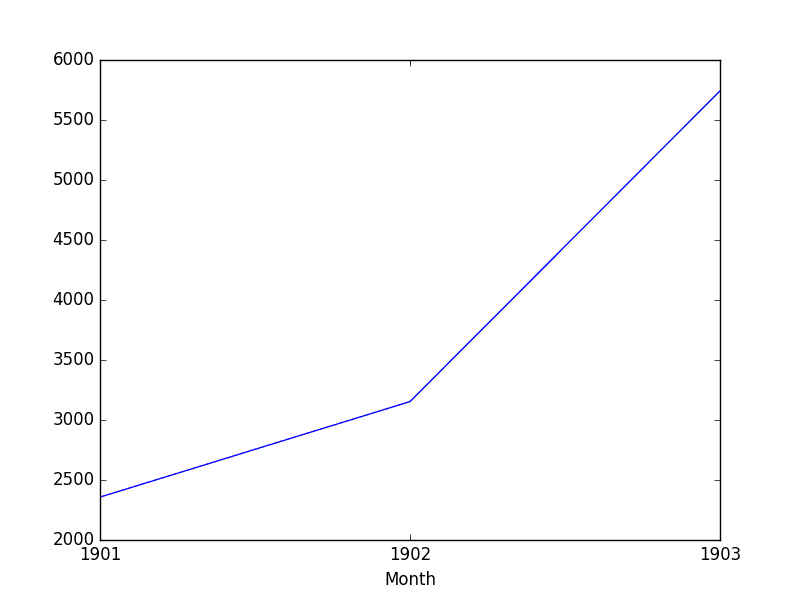
洗发水销售下采样年度总和
进一步阅读
本节提供了本教程中使用的 Pandas 函数的链接和进一步阅读材料。
- pandas.Series.resample API 文档,了解更多关于如何配置 resample() 函数的信息。
- Pandas 时间序列重采样示例,了解更多通用代码示例。
- Pandas 重采样时使用的偏移量别名,了解所有用于更改数据粒度的内置方法。
- pandas.Series.interpolate API 文档,了解更多关于如何配置 interpolate() 函数的信息。
总结
在本教程中,您学习了如何使用 Python 中的 Pandas 对时间序列数据进行重采样。
具体来说,你学到了:
- 关于时间序列重采样以及下采样和上采样观测频率之间的区别和原因。
- 如何使用 Pandas 对时间序列数据进行上采样以及如何使用不同的插值方案。
- 如何使用 Pandas 对时间序列数据进行下采样以及如何汇总分组数据。
您对重采样或插值时间序列数据或本教程有任何疑问吗?
请在评论中提出您的问题,我将尽力回答。
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






我感觉你把上采样和下采样弄反了。
https://en.wikipedia.org/wiki/Upsampling
https://en.wikipedia.org/wiki/Decimation_(signal_processing)
谢谢 Alex,已修复。
你好,
在上采样部分,你为什么写
upsampled = series.resample(‘D’).mean()
(顺便说一句,我认为应该是 _upsampled_,而不是 upsampled)。我不明白为什么在插入 NaN 时需要使用 mean。只写 series.resample(‘D’) 难道不够吗?
嗨 David,
你说得对,我已修正示例。
你好,
我认为需要添加“asfreq()”,即
upsampled = series.resample(‘D’).asfreq()
因为在新版本的 pandas 中,resample 只是一个分组操作,然后您需要聚合函数。
你好 Jason,
你没有!
Jason,我有一个希望快速得到答案的问题,这个问题是由于您上面给出的插值示例引起的。
我被分配了一项月度预测分析。我原始数据是每日的。如果我将其聚合到月级别,则只能得到 24 个可用观测值,因此许多模型可能会因此遇到困难。我觉得我应该能更多地利用我更丰富、更日常的数据集来解决我的问题。
我听说过(但记不清是哪里,也不知道是不是我凭空想象的!)一种解决方法是通过创建“虚假的”月度数据,例如从 12 月 26 日滚动到 1 月 26 日。所以对于 12 月,我将有 31 个“虚假的月份”,每个月从 12 月的每一天开始,并在 1 月的相应日期结束。这对于在短期时间序列中人为增加训练模型样本量是否是一种有效的方法?我立即意识到自相关是一个巨大的问题,但值得探索,还是我只是做梦?
对于处理短期时间序列,还有其他解决方法吗?
谢谢!
你好 Carmen,
也许 24 个观测值提供了足够的信息来进行准确的预测。
我建议您开发和评估一套不同的模型,并专注于产生有效结果的表示。
您的虚假月份想法只有在能够向学习算法暴露比其他方法/表示更多的信息时才有意义。
我很想听听您在预测问题上的进展。
我有一个时间序列数据,我正在使用重采样技术将我的数据从 15 分钟降采样到 1 小时。数据量很大(一年每 15 分钟一个值),所以我的原始 CSV 文件中有超过 30,000 行。
我正在使用
df[‘dt’] = pd.to_datetime(df[‘Date’] + ‘ ‘ + df[‘Time’])
df = df.set_index(‘dt’).resample(‘1H’)[‘KWH’].first().reset_index()
但在重采样后,只有第一天和最后一天的值是正确的,中间的所有值都被填充为 NAN。你能帮我指出我可能做错了什么吗?
重采样后,您需要对缺失数据进行插值。
这是重采样之前我的数据样子
24 01/01/16 06:00:04 4749.28 15.1 23.5 369.6 2016-01-01 06:00:04
25 01/01/16 06:15:04 4749.28 14.7 23.5 369.6 2016-01-01 06:15:04
26 01/01/16 06:30:04 4749.28 14.9 23.5 369.6 2016-01-01 06:30:04
27 01/01/16 06:45:04 4749.47 14.9 23.5 373.1 2016-01-01 06:45:04
28 01/01/16 07:00:04 4749.47 15.1 23.5 373.1 2016-01-01 07:00:04
29 01/01/16 07:15:04 4749.47 15.2 23.5 373.1 2016-01-01 07:15:04
... ... ... ... ... ... ...
2946 31/01/16 16:30:04 4927.18 15.5 24.4 373.1 2016-01-31 16:30:04
2947 31/01/16 16:45:04 4927.24 15.0 24.4 377.6 2016-01-31 16:45:04
2948 31/01/16 17:00:04 4927.30 15.2 24.4 370.5 2016-01-31 17:00:04
这是重采样之后的样子
df[‘dt’] = pd.to_datetime(df[‘Date’] + ‘ ‘ + df[‘Time’])
df = df.set_index(‘dt’).resample(‘1H’)[‘KWH’,’OCT’,’RAT’,’CO2′].first().reset_index()
17 2016-01-01 17:00:00 4751.62 15.0 23.8 370.9
18 2016-01-01 18:00:00 4751.82 15.1 23.6 369.2
19 2016-01-01 19:00:00 4752.01 15.3 23.6 375.4
20 2016-01-01 20:00:00 4752.21 14.8 23.6 370.1
21 2016-01-01 21:00:00 4752.61 15.0 23.8 369.2
22 2016-01-01 22:00:00 4752.80 15.2 23.7 369.6
23 2016-01-01 23:00:00 4753.00 15.7 23.5 372.3
24 2016-01-02 00:00:00 NaN NaN NaN NaN
25 2016-01-02 01:00:00 NaN NaN NaN NaN
26 2016-01-02 02:00:00 NaN NaN NaN NaN
27 2016-01-02 03:00:00 NaN NaN NaN NaN
28 2016-01-02 04:00:00 NaN NaN NaN NaN
29 2016-01-02 05:00:00 NaN NaN NaN NaN
... ... ... ... ...
8034 2016-11-30 22:00:00 NaN NaN NaN NaN
8035 2016-11-30 23:00:00 NaN NaN NaN NaN
8036 2016-11-30 23:00:00 NaN NaN NaN NaN
8037 2016-11-30 23:00:00 NaN NaN NaN NaN
8038 2016-11-30 23:00:00 NaN NaN NaN NaN
8039 2016-11-30 23:00:00 NaN NaN NaN NaN
8040 2016-12-01 00:00:00 4811.96 14.8 24.8 364.3
8041 2016-12-01 01:00:00 4812.19 15.1 24.8 376.7
8042 2016-12-01 02:00:00 4812.42 15.1 24.7 373.1
8043 2016-12-01 03:00:00 4812.66 15.2 24.7 372.7
8044 2016-12-01 04:00:00 4812.89 14.9 24.7 370.9
你真的认为将一月份每月 266 瓶洗发水的销量,重采样到每日间隔,然后说一月一日你卖了 266 瓶,一月二日卖了 262.125806 瓶是合理的吗?
不,这只是如何使用 API 的示例。
领域/领域专家可以指出合适的重采样和插值方案。
在将月度销售重采样到每日间隔时,而不是进行插值,是否有函数可以填充每日的平均月度销售额?这对于代表聚合值的非常有用的数据,其中数据集的总和应保持不变,而不管频率如何……例如,如果我需要上采样降雨量数据,那么总降雨量必须保持不变。是否有内置函数可以做到这一点?
当然,您可以做到。您必须编写一些代码。
我们刚让一名实习生用降雨量数据做了这个。这并不难!谢谢 Jason 的有用指南,这正是我一直在寻找的!
很高兴听到这个消息!
嗨,Jason,
关于如何做到这一点,有什么建议吗?我基本上有每月的总和和每日平均值,需要插值每日值,以便始终遵守月度总和。我没有遇到简单的重采样和插值问题,但一直在努力处理月度总和。
您能做的最好的就是(值/月天数),除非您能获得原始数据。
感谢您的建议。如果我将平均值放在月中并进行插值,它会接近但不会等于平均值 * 月天数。我希望避免“阶梯式”图表,并为每个月计算每日的增量增加/减少。我可以手动制作一个 Excel 模型示例,但还缺乏能力来实现。
月# #天 累积天数 平均速率 月累积 速率/日增长
1 31 31 60 1860 3.75
2 28 59 125 3500 0.603448276
3 31 90 100 3100 -2.071659483
4 30 120 60 1800 -0.575813404
5 31 151 50 1550 -0.103169103
月 日 累积天数 日速率 月累积检查
0 0 0 0 0
1 1 1 3.75 3.75
1 2 2 7.5 11.25
1 3 3 11.25 22.5
1 4 4 15 37.5
1 5 5 18.75 56.25
1 6 6 22.5 78.75
1 7 7 26.25 105
1 8 8 30 135
1 9 9 33.75 168.75
1 10 10 37.5 206.25
1 11 11 41.25 247.5
1 12 12 45 292.5
1 13 13 48.75 341.25
1 14 14 52.5 393.75
1 15 15 56.25 450
1 16 16 60 510
1 17 17 63.75 573.75
1 18 18 67.5 641.25
1 19 19 71.25 712.5
1 20 20 75 787.5
1 21 21 78.75 866.25
1 22 22 82.5 948.75
1 23 23 86.25 1035
1 24 24 90 1125
1 25 25 93.75 1218.75
1 26 26 97.5 1316.25
1 27 27 101.25 1417.5
1 28 28 105 1522.5
1 29 29 108.75 1631.25
1 30 30 112.5 1743.75
1 31 31 116.25 1860
2 1 32 116.8534483 116.8534483
2 2 33 117.4568966 234.3103448
2 3 34 118.0603448 352.3706897
2 4 35 118.6637931 471.0344828
2 5 36 119.2672414 590.3017241
2 6 37 119.8706897 710.1724138
2 7 38 120.4741379 830.6465517
2 8 39 121.0775862 951.7241379
2 9 40 121.6810345 1073.405172
2 10 41 122.2844828 1195.689655
2 11 42 122.887931 1318.577586
2 12 43 123.4913793 1442.068966
2 13 44 124.0948276 1566.163793
2 14 45 124.6982759 1690.862069
2 15 46 125.3017241 1816.163793
2 16 47 125.9051724 1942.068966
2 17 48 126.5086207 2068.577586
2 18 49 127.112069 2195.689655
2 19 50 127.7155172 2323.405172
2 20 51 128.3189655 2451.724138
2 21 52 128.9224138 2580.646552
2 22 53 129.5258621 2710.172414
2 23 54 130.1293103 2840.301724
2 24 55 130.7327586 2971.034483
2 25 56 131.3362069 3102.37069
2 26 57 131.9396552 3234.310345
2 27 58 132.5431034 3366.853448
2 28 59 133.1465517 3500
3 1 60 131.0748922 131.0748922
3 2 61 129.0032328 260.078125
3 3 62 126.9315733 387.0096983
3 4 63 124.8599138 511.8696121
…
干得好!
你好 Jason,
感谢您的精彩帖子。在我的时间序列数据中,我有两个特征列,即纬度和经度,索引是日期时间。
由于这些 GPS 坐标的捕获间隔不频繁,我想将我的数据重采样到固定的时间间隔,例如,每 5 秒一个 GPS 坐标。
有什么方法可以做到吗?
听起来您可以使用线性插值来处理时间,并使用类似线性的方法来处理空间坐标。
“类似线性的用于空间坐标”,线性什么?
线性意味着直线/平面或输入的总和或加权输入(例如线性组合)。
你好 Jason,
我有一个关于将数据从每日降采样到每周或每月数据的问题,
如果我的数据是多元时间序列,例如它包含分类变量和数值变量,我该如何自动对每个列进行降采样,有没有简单的方法可以做到?
提前感谢
您可能需要逐一处理每一列。
嗨,Jason,
我们能否使用(如果可以,如何使用)重采样来平衡数据中 2 个不相等的类别?例如,在预测股票价格方向时,多数类别将是“1”(价格上涨),少数类别将是“-1”(价格下跌)。问题是分类器可以预测大多数或所有标签为“1”,仍然具有高准确性,从而显示出对多数类别的偏见。
有什么方法可以解决这个问题吗?
是的,这篇帖子建议了一些平衡类别的算法
https://machinelearning.org.cn/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
我没有关于序列分类类别平衡的材料。
您能告诉我如何下采样我的标签数据吗?标签列只有 0 和 1,总共有 20 万行。我需要将此列下采样到 20 Hz,即 50 毫秒。
你好,我正在使用下面的代码,这是否正确?我的数据是存储在单行中的信号
from scipy import signal
resample_signal=scipy.signal.resample(x,256)
plt.plot(resample_signal)
我不知道。如果图表看起来不错,那么就是。
谢谢!这确实很有帮助,但我的问题有点不同。我的数据是以随机时间间隔记录的,我需要将值插值到 5 分钟的时间步长,如下所示
输入
——-
2018-01-01 00:04 | 10.00
2018-01-01 00:09 | 12.00
2018-01-01 00:12 | 10.00
2018-01-01 00:14 | 15.00
2018-01-01 00:18 | 20.00
所需输出
————————
2018-01-01 00:00 | 08.40
2018-01-01 00:05 | 10.40
2018-01-01 00:10 | 11.90
2018-01-01 00:15 | 16.10
2018-01-01 00:20 | 21.50
希望够清楚!
非常感谢您的帮助!
您可能需要查阅 resample/interpolate API 的相关文档,以便为此特定情况定制工具。
嗨!我正在尝试比较两年 CPI 的百分比。在这种特定情况下,我的数据有以下列:
‘Date’(一年中的每周一个日期,持续三年)
‘CPI’
以及其他与此无关的列。
问题是我必须将每个 CPI 除以其前一年同周的值。例如,如果我有 2010 年第 5 周的 CPI,我必须将其除以 2009 年第 5 周的 CPI。
我已经设法获取了每个观测值的周数和年份,但我无法弄清楚如何获取所需的值,因为它们都来自同一个数据框。任何帮助都将不胜感激。
抱歉,我对您的数据集并不十分熟悉。我不知道该如何确切地帮助您。
非常抱歉。我以为我附上了一部分。这是数据头(不确定这是否能满足“熟悉”的要求,但希望它能澄清)。
日期 CPI
05-02-2010 211.0963582
12-02-2010 211.2421698
19-02-2010 211.2891429
26-02-2010 211.3196429
05-03-2010 211.3501429
12-03-2010 211.3806429
19-03-2010 211.215635
26-03-2010 211.0180424
02-04-2010 210.8204499
09-04-2010 210.6228574
16-04-2010 210.4887
23-04-2010 210.4391228
30-04-2010 210.3895456
你好 Jason,
感谢您提供的有益指南。我目前正在尝试从每周回报中插值每日股票回报。我知道我必须保持总累积回报不变,但我仍然对程序感到困惑。您能否给我一些关于如何编写我的函数的提示?
谢谢
你具体遇到了什么问题?示例有帮助吗?
我可以用LSTM解决这个问题吗?怎么做?
LSTM可以进行插值。您可以将模型训练为生成器,并根据先前的输入序列使用它来生成下一个点。
嗨,
在重新采样时如何处理分类变量?
好问题,向前持久化。
先生,我一直在关注您的帖子。它们非常信息丰富。我非常感谢您的努力。
我现在正在处理一个包含6个月每日燃油销售数据(2018年2月至2018年7月)的数据集。在该数据集中,缺少5月份整整一个月的记录。我想预测8月份的每日燃油销售量。我不知道如何处理缺失的1个月的数据。我应该只分析2月、3月、4月的数据,还是需要插值5月份的数据?
如果您能对此问题提出任何建议,我将不胜感激。
提前感谢您,先生!!
也许可以尝试使用一两个月前的数据进行建模?
也许可以尝试进行插补?
也许可以尝试处理缺失数据的方法,例如LSTM中的掩码?
嗨,Jason,
非常感谢您的帖子!非常有帮助。
我有一个问题——我试图按周对员工离职人数进行重采样。我已经使用mean()来聚合每周的样本。我不确定在这种情况下平均值是如何计算的,为什么它会给出负值。任何帮助都将非常感激。
重采样前的数据:(索引=date_series)
date_series company year first_day_of_week date_of_attendance attrition_count week
1/1/2018 2018 0 1
1/2/2018 AAA 2018 12/31/2017 1/2/2018 2 1
1/3/2018 AAA 2018 12/31/2017 1/3/2018 0 1
1/4/2018 AAA 2018 12/31/2017 1/4/2018 0 1
1/5/2018 AAA 2018 12/31/2017 1/5/2018 1 1
1/6/2018 AAA 2018 12/31/2017 1/6/2018 1 1
1/7/2018 AAA 2018 1/7/2018 1/7/2018 0 1
用于重采样的代码
# 重采样为每周频率
df_week = df_test.resample(‘W’).mean()
重采样后的数据
week year attrition_count
1 2018 -0.554218343
这很奇怪,也许在计算平均值之前检查一下数据分组,看看具体是什么在起作用?
感谢这篇文章。
“假设我们想要每日销售信息。”这表明Python神奇地添加了不存在的信息。这有点误导。如果你没有每日数据,你就没有它。它必须被插值。
谢谢。
嗨,Jason,
感谢您的有益文章!
我正在尝试重新采样数据(pandas.DataFrame),但遇到了问题。
我有一些时间序列数据(存储在数据框中),并尝试使用pandas resample()对其进行降采样,但插值显然不起作用。
原始数据是浮点类型的时间序列(60秒的数据,间隔为0.0009秒),但是为了指定pandas resample()的“rule”,我将其转换为日期时间类型的时间序列。
(pd.to_datetime(df,unit = ‘s’,origin = pd.Timestamp(datetime.datetime.now())))
然后我尝试对时间序列数据进行降采样
(df = df.resample(‘ms’)。interpolate())
然而,似乎原始数据丢失了太多信息。
我认为图表的形状不会有太大变化,因为采样频率仅从1111.11 Hz变为1000 Hz。
(实际上丢失了很多信息。)
您是否知道此问题的原因或解决方案?
我认为在将浮点类型的时间序列转换为日期时间类型时会发生舍入,这可能会影响结果。
(警告:对于浮点参数,可能会发生精度舍入。为避免意外行为,请使用固定宽度的精确类型。
https://pandas.ac.cn/pandas-docs/stable/reference/api/pandas.to_datetime.html)
例如,第二行的正确输入时间应该是2019-02-02 12:00:25.0009,而不是2019-02-02 12:00:25.000900030
我认为第二行的正确输出值(2019-02-02 12:00:25.001)应该约为-0.0045(=-0.005460 +(-0.003701)/2)或接近-0.005,因为输出时间2019-02-02 12:00:25.001介于2019-02-02 12:00:25.000900030和2019-02-02 12:00:25.001800060之间。
输入
0 2019-02-02 12:00:25.000000000 – 0.007239
1 2019-02-02 12:00:25.000900030 – 0.005460
2 2019-02-02 12:00:25.001800060 – 0.003701
3 2019-02-02 12:00:25.002700090 – 0.001966
4 2019-02-02 12:00:25.003599882 – 0.000256
5 2019-02-02 12: 00: 25.004499912 0.001427
6 2019-02-02 12: 00: 25.005399942 0.003081
7 2019-02-02 12: 00: 25.006299973 0.004704
8 2019-02-02 12: 00: 25.007200003 0.006295
9 2019-02-02 12: 00: 25.008100033 0.007850
10 2019-02-02 12: 00: 25.009000063 0.009369
11 2019-02-02 12: 00: 25.009900093 0.010851
12 2019-02-02 12: 00: 25.010799885 0.012293
13 2019-02-02 12: 00: 25.011699915 0.013695
14 2019-02-02 12: 00: 25.012599945 0.015055
15 2019-02-02 12: 00: 25.013499975 0.016372
16 2019-02-02 12: 00: 25.014400005 0.017645
17 2019-02-02 12: 00: 25.015300035 0.018874
18 2019-02-02 12: 00: 25.016200066 0.020057
19 2019-02-02 12: 00: 25.017100096 0.021193
20 2019-02-02 12: 00: 25.017999887 0.022283
21 2019-02-02 12: 00: 25.018899918 0.023326
22 2019-02-02 12: 00: 25.019799948 0.024322
23 2019-02-02 12: 00: 25.020699978 0.025270
24 2019-02-02 12: 00: 25.021600008 0.026170
25 2019-02-02 12: 00: 25.022500038 0.027023
26 2019-02-02 12: 00: 25.023400068 0.027828
27 2019-02-02 12: 00: 25.024300098 0.028587
28 2019-02-02 12: 00: 25.025199890 0.029299
29 2019-02-02 12: 00: 25.026099920 0.029964
… … …
输出
2019-02-02 12:00:25.000 – 0.007239
2019-02-02 12:00:25.001 – 0.007142
2019-02-02 12:00:25.002 – 0.007046
2019-02-02 12:00:25.003 – 0.006950
2019-02-02 12:00:25.004 – 0.006853
2019-02-02 12:00:25.005 – 0.006757
2019-02-02 12:00:25.006 – 0.006661
2019-02-02 12:00:25.007 – 0.006564
2019-02-02 12:00:25.008 – 0.006468
2019-02-02 12:00:25.009 – 0.006372
2019-02-02 12:00:25.010 – 0.006276
2019-02-02 12:00:25.011 – 0.006179
2019-02-02 12:00:25.012 – 0.006083
2019-02-02 12:00:25.013 – 0.005987
2019-02-02 12:00:25.014 – 0.005890
2019-02-02 12:00:25.015 – 0.005794
2019-02-02 12:00:25.016 – 0.005698
2019-02-02 12:00:25.017 – 0.005601
2019-02-02 12:00:25.018 – 0.005505
2019-02-02 12:00:25.019 – 0.005409
2019-02-02 12:00:25.020 – 0.005312
2019-02-02 12:00:25.021 – 0.005216
2019-02-02 12:00:25.022 – 0.005120
2019-02-02 12:00:25.023 – 0.005023
2019-02-02 12:00:25.024 – 0.004927
2019-02-02 12:00:25.025 – 0.004831
2019-02-02 12:00:25.026 – 0.004735
2019-02-02 12:00:25.027 – 0.004638
2019-02-02 12:00:25.028 – 0.004542
2019-02-02 12:00:25.029 – 0.004446
…… ……
如果您能对此问题提出任何建议,我将不胜感激。
提前表示感谢!!
减少样本数量时会丢失信息。
也许尝试在执行降采样时使用不同的数学函数?
Jason,
感谢您的回复。
我也认为重采样数据时肯定会丢失信息。然而,在这种情况下,图表轮廓明显改变是一个问题。
如果以1111.11 Hz的采样频率获取1分钟的数据,获得的点数将超过60,000个。
即使以1000 Hz进行降采样,丢失的数据量最多约为6000个点。
然而,在绘制重采样数据时,图表的包络会发生明显变化,就好像以10 Hz进行降采样一样。
正如我在之前发送的数据片段中所见,插值显然效果不佳,我不知道原因,我感到很苦恼。
您知道是什么原因导致此问题以及如何解决吗?
致以最诚挚的问候。
在不参与您的项目的情况下,我无法知道。
我建议设计实验来帮助区分问题的原因,例如,查看实际数据值以及不同频率重采样数据的结果。也许大量的微小值的简单平均会导致这种效果?
也许可以质疑对于您正在解决的问题,大的变化是否重要?
您能否帮助我了解可用的插值方法?例如,销售数据不是到那天的总销售额,而是特定时间段内的销售额。例如,我有一周的销售额,数据是3年的。所以,如果我想将其重采样为每日频率,然后进行插值,我希望将一周的销售额分配到这一周的每一天。
我希望我能传达我的问题,其中线性插值不是我正在寻找的方法,因为数据不是到目前为止的总销售额,而是每周的销售额。
是的,您可以对序列进行每日重采样。每日值将不准确,它们将是每周值的平均值除以7之类的。
嗨,Jason,
您能否告知我们您对以下问题的评论?
如何处理多元时间序列中高度相关的特征?
谢谢
也许可以对具有相关序列的模型和不具有相关序列的模型进行建模,然后进行比较?
谢谢
很高兴它有帮助。
嗨,Jason,
我有一个非常大的数据集(> 2 GB),其中时间戳是其中一列,看起来像这样。
2248444710306450
2248444710454040
2248444710596550
2248444710738800
2248444710880930
2248444711024970
2248444711166630
2248444711309100
2248444711459830
2248444711602180
2248444711743050
2248444712478090
2248444712521820
2248444712561980
2248444712600190
2248444712674360
2248444712712680
2248444712749870
2248444712788060
2248444712825010
2248444712863270
2248444712900350
2248444712938420
2248444713544750
2248444713586800
2248444713628480
我需要将其转换为日期时间并进行降采样,以便每毫秒有一个观测值,现在它是纳秒。
使用pd.to_datetime进行转换时,出现了pandas._libs.tslib.OutOfBoundsDatetime:无法将单位为‘ms’的输入转换为日期时间。
我能否直接从时间戳进行降采样?非常感谢您的帮助,因为我需要在成功绘制和分析数据后绘制和构建模型。
我有一些想法:
也许可以尝试逐步加载数据?
也许可以尝试使用一小部分样本?
也许可以尝试在拥有大量RAM的AWS EC2上运行代码?
我这里有更多建议
https://machinelearning.org.cn/faq/single-faq/how-to-i-work-with-a-very-large-dataset
如何插值季节性周期时间序列中的缺失值?
scipy或pandas是否有此功能?我可以取先前季节性时间步长的平均值,如果可以的话,它如何自动检测其先前季节性时间步长的平均值?
嗯,你可以用多项式对季节性进行建模,减去它,分别重采样每个部分,然后加回。
先生,
我不知道我哪里做错了,但我无法复制这个教程。我加载数据就遇到了很多麻烦,并且我得到的第一个图与您的图完全不同!我无法继续进行到“upsampled = series.resample(‘D’)”部分。
听到这个我很遗憾,你具体遇到了什么问题?
您的日期时间代码有错误,已在下方修复
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x)
返回 datetime.strptime(x, ‘%Y-%m-%d’)
series = read_csv(‘s.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
print(series.head())
series.plot()
pyplot.show()
您可能下载了不同版本的数据集?
我在这里有一个它的副本
https://raw.githubusercontent.com/jbrownlee/Datasets/master/shampoo.csv
你一直是我的救星,Jason。你真的在帮助我在我的第一个全功能ML项目中生存下来。我感激不尽!!
谢谢,我很高兴得知这些教程很有帮助!
嗨 Jason,
当数据先增加然后减少然后再次增加时,可以使用哪种类型的插值?
因为当我使用样条插值时,它忽略了我减少的值,只是使我的数据随时间呈递增趋势。
也许可以用多项式拟合序列,并将其用作一种持久性模型。
非常感谢您的回复。您能给我推荐一个有用的链接吗?
是的,我相信这里有一个例子
https://machinelearning.org.cn/time-series-seasonality-with-python/
你好,
非常感谢您提供这篇详细的文章。我对回报的向上采样有一个疑问——当我们把每周频率转换为每日频率时,逻辑是如何确定的?例如,如果我的每周回报是7%,当我对它进行插值时,它应该转化为每日回报1%。将其扩展到您上面关于洗发水销售的例子,每月的洗发水销售量在200左右。当通过插值将其转换为每日频率时,每日销售量也约为200!这似乎不直观,我期望每日销售额在66(200/30)左右。我是否遗漏了什么?
提前感谢!
Shrija
我相信它使用简单的持久性。
对于更现实的转换,我相信需要自定义函数/代码。
谢谢!
不客气。
你好Jason,关于重采样和插值的精彩教程,这是我找到的最好的,谢谢。
我有一个问题:我运行了“Upsample Shampoo Sales”代码,完全按照您写的来,但在运行代码 upsampled = series.resample(‘D’) 后,我遇到了以下 AttributeError:‘DatetimeIndexResampler’ 对象没有属性 ‘head’。
你知道为什么会这样吗?
此外,我还有从2008年到2018年的年度数据,我想将其向上采样为月度数据,然后进行插值。您能否帮我创建一个使用datetime.strptime的定义函数?我是Python新手。非常感谢您:)
听到这个我很遗憾。也许这会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
抱歉,我没有能力为您编写自定义代码。
series.index = series[:, 0]
upsampled = series.resample(‘D’)
非常感谢您提供如此好的解释,但无法下载csv文件,如果可能请附上。
直接链接就在帖子中。
https://raw.githubusercontent.com/jbrownlee/Datasets/master/shampoo.csv
亲爱的 Jason,
感谢您的帖子。有一个问题,如果您有两个连续的行,每小时只有一个值
时间 值
0:45 100
1:15 150
您想获得1:00的值,即125,您能用这个解决方案做到吗?
谢谢
这称为线性插值。
您可以使用库(例如上面)或手动执行此操作。
https://en.wikipedia.org/wiki/Linear_interpolation
博士您好,我有一个疑问,
我有一个时间序列,我的数据具有不同的时间间隔(记录之间的差异是二十分钟,有时是三十分钟,依此类推)。
我使用了resample使其具有相同的时间间隔。然后我使用了前向传播来处理缺失值。
我有两个案例研究。我用这项技术和不用这项技术测试了模型的准确性。在第一种情况下,准确性有所提高,但在第二种情况下,准确性有所下降。
重采样导致准确性下降(与其他模型相比)可能是什么原因?可能是因为重采样创建了更多数据,模型在泛化方面遇到了更多困难?
提前感谢,并为一些英语误导表示歉意,因为英语不是我的母语。
您是指误差,而不是准确性,对吗?准确性对于回归是无效的。
如果您以较低的时间分辨率进行建模,问题几乎总会更简单,误差也会更低。
非常感谢您的回复!
也许我理解错了,但我将重采样用于打算与LSTM模型一起使用的数据。
所以我先运行了模型,然后又在重采样之后运行了模型。
然而,模型在重采样后的准确性更差。我使用了重采样作为预处理方法。我以为通过重采样,因为我的时间序列有不同的时间间隔,重采样方法可以帮助提高相对于基准模型的准确性。
例如,不重采样的准确性是88%,重采样后是63%。我的疑问是因为重采样的一个缺点可能是重采样创建了更多数据,导致模型在泛化方面遇到更多困难?
抱歉打扰您,再次感谢您的回复!
您是指误差,而不是准确性,对吗?准确性对于回归是无效的。
https://machinelearning.org.cn/faq/single-faq/how-do-i-calculate-accuracy-for-regression
您可能需要调整您的模型以适应数据。
https://machinelearning.org.cn/start-here/#better
能否将频率降采样到所需频率(例如50Hz),同时保持信号形状及其细节不变?如何做到?
这取决于您的数据,但可以尝试通过指定首选采样频率然后绘制结果。
我的数据集采样频率是200Hz。
-如何将频率降采样到50Hz?
我应该使用哪行代码?
也许可以先从“下采样洗发水销量”部分中的示例开始,然后根据您的需要进行调整。
user_id x y z
datetime
2018-12-16 09:13:04.335000+00:00 38.0 0.498 9.002 -5.038
2018-12-16 09:13:06.535000+00:00 38.0 0.344 9.385 -0.418
2018-12-16 09:13:06.605000+00:00 38.0 0.344 9.385 -0.418
2018-12-16 09:13:06.735000+00:00 38.0 -0.459 9.194 -0.828
2018-12-16 09:13:06.740000+00:00 38.0 -0.459 9.194 -0.828
2018-12-16 09:13:06.935000+00:00 38.0 -0.268 8.810 -0.690
2018-12-18 01:16:34.045000+00:00 38.0 1.417 3.639 9.133
2018-12-18 01:16:34.250000+00:00 38.0 1.570 3.371 9.116
2018-12-18 01:16:34.260000+00:00 38.0 1.570 3.371 9.116
2018-12-18 01:16:34.445000+00:00 38.0 1.570 4.405 9.008
2018-12-18 01:16:34.650000+00:00 38.0 -0.459 4.405 9.018
2018-12-18 01:16:34.655000+00:00 38.0 -0.459 4.405 9.018
2018-12-18 01:16:34.845000+00:00 38.0 -0.612 4.941 8.777
2018-12-18 01:16:35.045000+00:00 38.0 -0.612 4.750 8.582
2018-12-18 01:16:35.050000+00:00 38.0 -0.612 4.750 8.582
2018-12-18 01:16:35.245000+00:00 38.0 -0.344 4.788 8.567
这是我的数据集的简短版本。
我有两天的记录。我想做的是对数据进行重采样,以获得我拥有数据的秒数中每秒20个值。我不想重采样不存在于数据中的秒数。
如果我使用
df.set_index(‘datetime’).resample(‘5ms’).mean() ;
它会对整个数据集进行重采样。
我如何仅针对数据集中给定的时间戳进行重采样?
抱歉,我不太明白您的意思。您在重采样时是什么意思“仅针对数据集中给定的时间戳”?
运行上面未重采样的示例时,我收到了以下错误消息。
C:/Users/shr015/gbr_ts_anomoly/data/real/test.py:2: FutureWarning: pandas.datetime 类已弃用,将在 pandas 的未来版本中删除。请从 datetime 模块导入。
from pandas import datetime
回溯(最近一次调用)
File “C:\Program Files\JetBrains\PyCharm Community Edition 2020.2.2\plugins\python-ce\helpers\pydev\pydevd.py”, line 1448, in _exec
pydev_imports.execfile(file, globals, locals) # 执行脚本
File “C:\Program Files\JetBrains\PyCharm Community Edition 2020.2.2\plugins\python-ce\helpers\pydev\_pydev_imps\_pydev_execfile.py”, line 18, in execfile
exec(compile(contents+”\n”, file, ‘exec’), glob, loc)
File “C:/Users/shr015/gbr_ts_anomoly/data/real/test.py”, line 11, in
print(upsampled.head(32))
File “C:\Users\shr015\.conda\envs\deeplearning\lib\site-packages\pandas\core\resample.py”, line 115, in __getattr__
return object.__getattribute__(self, attr)
AttributeError: ‘DatetimeIndexResampler’ object has no attribute ‘head’
听到这个消息很遗憾,也许这些提示会有帮助
https://machinelearning.org.cn/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
嗨,Jason,
我有一个每小时的时间序列数据,我想将其重采样到每小时,以便我能够获得每天的观察值(因为有些天我只有2或3个观察值)。但是,我没有得到 NaN,而是得到了零。我还有一个大约3个月的间隙。当我进行插值时,这个间隙没有被填补。您有什么建议吗?
谢谢!
也许可以先从教程中的一个工作示例开始,然后根据您的需要进行调整?
嗨,Jason,
非常感谢您的教程,它极大地帮助我理解了深度学习的概念和工作流程。
我目前正在研究一个经济预测模型,但我在不同指标的采样率方面遇到了一个问题。例如,“利率”每天采样一次,“通货膨胀率”每月采样一次,而一些数据集每年采样一次,导致在以每日采样率将这些特征组合在一起时出现大量 NaN 值。
我想知道是否有解决办法?我在网上和书籍中都找不到答案。大多数在线教程处理的 NaN 值与整个数据集相比很少,而在我的数据集中,“通货膨胀”列在以每日速率上采样时会有 90% 的 NaN。
非常感谢。
您可以比较模型在具有标准化频率的数据上的性能,以及在具有不同频率的数据上拟合的模型,看看它是否能产生很大的差异。
嗨,Jason,
我的记录遵循 EEG 数据格式,采样率为 256Hz,但我需要将数据下采样到 120Hz。我看到索引显示为 0,1…,255,0,1,2,..255.0
我使用了 df = df.sample(frac = 120),它显示了与原始数据相似的模式。这种下采样方式是否可以?或者我应该采用其他技术来获得更好的下采样方法?
谢谢
如果您提到的模式是较低的频率,下采样仍然会保留它。这并不令人意外!您为什么要下采样它,为什么您不想在下采样后看到该模式?回答这些问题可能有助于您找到“更好的方法”。或者,根据您的目标,下采样可能根本不是预处理数据的最佳方法。
谢谢您的回复。我实际上收集了其他传感器的数据,其采样率为 120。所以我需要下采样 EEG 数据。我使用了 df = df.sample(frac = 120) 来下采样 EEG 数据,而模式与原始数据相似。我不知道其他方法可以做到。如果您知道,请告诉我。
为什么您会期望下采样后数据模式不相似?
我没有期望任何东西。我只是想知道是否有其他方法可以做到。
如果您知道您在寻找什么,您可以使用不同的预处理方法。对我来说,一件微不足道的事情可能是进行傅里叶变换,并将数据表示为频域而不是时域,以防您知道您在寻找频率方面的东西。这只是一个例子。
你好,
我有两个数据集,我想用它们来构建一个线性回归预测模型,但我有一个关于使用重采样方法将数据从每日频率降低到每月频率的问题,以便将其与月度失业率进行比较。月度失业率是我要预测的响应变量。这是构建预测线性回归模型的正确方法吗?
是的。通常在这种情况下,进行重采样是因为您希望对数据频率进行对齐。例如,您的一些自变量只有月度数据,因此将所有数据对齐到月度是有意义的。
非常感谢您的回复!
您好!将数据重采样到恒定频率(例如每秒 100 个样本)的最佳方法是什么?我的数据是不规则的。在 Matlab 中,我使用了“resample(signal, timestamps,100,’spline’)”,使用样条插值将不规则数据转换为恒定的每秒 100 个样本。在 Python 中,最佳等效方法是什么?
谢谢!
如果您使用 pandas,也有一个 resample 函数:https://pandas.ac.cn/docs/reference/api/pandas.DataFrame.resample.html
你好。
我有一个关于下采样的问题,就像上采样一样,我们看到原始时间戳对应的值没有改变,而是插入了“nan”,之后可以根据需要进行插值。但在下采样中,原始值会随着时间戳的下采样而改变。例如,一个包含每分钟瞬时电压的数据集,我们希望将数据集重采样为每小时数据,下采样后时间戳是正确的,但相应的瞬时电压不再是相同的,而是更改为平均值或其他函数。
如何恢复瞬时量的原始值?因为这些值对于进一步建模非常重要。
你好 aman…以下资源应该能提供更多清晰的信息
https://towardsdatascience.com/5-techniques-to-work-with-imbalanced-data-in-machine-learning-80836d45d30c
感谢您的快速回复。
嗨 James,
我有一个关于插值效率或速度的问题,以防上采样或聚合方法以防下采样。
有没有办法可以并行计算或加速这个过程,因为我有一个大型数据集,分布在多个 parquet 文件中。每个文件中的每个样本都有自己的插值率。
我的做法是循环遍历文件,然后根据与该样本关联的速率进行上采样或下采样,这花费了大量时间。
为了详细说明,我需要对超过 300,000 个样本进行上采样 –> 有没有办法加速这个过程??
提前感谢
嗨 James,
我有一个关于回归和预测分析中最小观测值数量的问题。
我的数据集由年度数据组成(范围从 2010 年到 2022 年,所以有 10 个观测值)。
那么,将原始数据集从年度数据上采样到月度数据是否合理?这样做有什么缺点吗?
谢谢!
您好 Kuro…如果可能的话,将您的系列数据点尽可能多地汇总到数据集中将是有益的。
这些数据来自一家公司的财务报告,直到 2010 年才发布。我认为收集其季度报告是我所能做的极限。我还能在这个阶段进行回归吗?
感谢您的快速回复!
您好……这非常有帮助。谢谢。
如果数据是每个日期的二维数组(例如 4x10:4 行 10 列)怎么办?如何将其读入数据框?以下是否可行?插值会以二维方式进行吗?
2023-06-01: (4,10) 数组
2023-06-02: (4,10) 数组
2023-06-03: (4,10) 数组
您好 Sam…… 不客气!以下内容可能对您有帮助
https://machinelearning.org.cn/understanding-the-design-of-a-convolutional-neural-network/
https://towardsdatascience.com/a-simple-2d-cnn-for-mnist-digit-recognition-a998dbc1e79a
我有一个月度游客数据集(访问山站的游客人数),我想将其上采样到每周。您能建议哪种技术效果最好吗?
您好 Ayush……以下资源可能对您有所帮助。
https://machinelearning.org.cn/implement-resampling-methods-scratch-python/