数字时代开启了一个数据驱动决策至关重要的时代,房地产就是一个典型的例子。像艾姆斯房产这样的综合数据集为数据爱好者提供了宝库。通过对这些数据集的细致探索和分析,人们可以发现模式,获得洞察力,并做出明智的决策。
从这篇博文开始,您将踏上一段引人入胜的旅程,深入探索艾姆斯房产错综复杂的各个方面,主要关注数据科学技术。
让我们开始吧。

揭示不可见:在艾姆斯住房数据中可视化缺失值
图片来源:Joakim Honkasalo。保留部分权利。
概述
这篇博文分为三部分;它们是:
- 艾姆斯房产数据集
- 加载并评估数据集
- 发现并可视化缺失值
艾姆斯房产数据集
每个数据集都有一个故事要讲,了解其背景可以提供宝贵的上下文。虽然艾姆斯住房数据集在学术界广为人知,但我们今天分析的数据集,Ames.csv,是艾姆斯房产详情的更全面的集合。
迪安·德科克博士(Dr. Dean De Cock)是一位敬业的学者,他认识到房地产领域需要一个新的、可靠的数据集。他精心编译了艾姆斯住房数据集,此后它成为了初级数据科学家和研究人员的基石。该数据集以其全面的细节而闻名,捕捉了房地产的诸多方面。它已成为众多预测建模练习的基础,并为探索性数据分析提供了丰富的环境。
艾姆斯住房数据集被设想为旧波士顿住房数据集的现代替代品。它涵盖了2006年至2010年爱荷华州艾姆斯的住宅销售情况,提供了各种变量,为高级回归技术奠定了基础。
这个时间段在美国历史上尤为重要。2007-2008年之前,房价急剧膨胀,投机狂潮和次级抵押贷款助长了这一趋势。这最终导致了2007年末房地产泡沫的毁灭性破裂,这一事件在《大空头》等叙事中被生动地捕捉。这次崩溃的后果波及全国,导致了大衰退。房价暴跌,止赎案件飙升,许多美国人发现他们的抵押贷款已经资不抵债。艾姆斯数据集让我们得以一窥这个动荡时期,记录了全国经济动荡中的房地产销售情况。
通过我的书《数据科学初学者指南》启动您的项目。它提供了带有工作代码的自学教程。
加载并评估数据集
对于那些涉足数据科学领域的人来说,拥有正确的工具至关重要。如果您需要一些帮助来设置Python环境,这篇综合指南是一个极好的资源。
数据集维度:在深入进行复杂的分析之前,熟悉数据集的基本结构和数据类型至关重要。此步骤为后续探索提供了路线图,并确保您根据数据性质调整分析。环境就绪后,让我们加载并评估数据集在行(代表单个属性)和列(代表这些属性的特征)方面的范围。
|
1 2 3 4 5 6 7 8 9 |
# 加载Ames数据集 import pandas as pd Ames = pd.read_csv('Ames.csv') # 数据集形状 print(Ames.shape) rows, columns = Ames.shape print(f"数据集包含 {rows} 个房产,由 {columns} 个属性描述。") |
|
1 2 |
(2579, 85) 该数据集包含 2579 个房产,由 85 个属性描述。 |
数据类型:识别每个属性的数据类型有助于确定我们的分析方法。数值属性可以使用均值或中位数等度量进行汇总,而众数(最频繁的值)则适用于分类属性。
|
1 2 3 4 5 6 7 |
# 确定每个特征的数据类型 data_types = Ames.dtypes # 按数据类型统计总数 type_counts = data_types.value_counts() print(type_counts) |
|
1 2 3 4 |
对象 44 int64 27 float64 14 dtype: int64 |
数据字典:数据字典通常随附于综合数据集,是一种方便的资源。它提供每个特征的详细描述,指明其含义、可能的值,有时甚至包括其收集逻辑。对于像艾姆斯房产这样包含广泛特征的数据集,数据字典可以成为清晰的灯塔。通过参考所附的数据字典,分析师、数据科学家乃至领域专家可以对每个特征的细微差别有更深入的了解。无论是解读不熟悉特征的含义,还是辨别特定值的意义,数据字典都可作为全面的指南。它弥合了原始数据与可操作洞察之间的鸿沟,确保分析和决策都是基于充分信息的。
|
1 2 3 4 5 |
# 确定每个特征的数据类型 data_types = Ames.dtypes # 查看数据集中的一些数据类型(前5个和后5个特征) print(data_types) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
PID int64 GrLivArea int64 SalePrice int64 MSSubClass int64 MSZoning 对象 ... SaleCondition 对象 GeoRefNo float64 Prop_Addr 对象 Latitude float64 Longitude float64 长度: 85, dtype: 对象 |
地面居住面积和销售价格是数值(int64)数据类型,而销售条件(对象,在本例中为字符串类型)是分类数据类型。
发现并可视化缺失值
真实世界的数据集很少能完美整理,常常给分析师带来缺失值的挑战。这些数据空白可能由于数据收集错误、系统限制或信息缺失等各种原因而产生。处理缺失值不仅仅是技术上的必要,更是显著影响后续分析完整性和可靠性的关键一步。
理解缺失值的模式对于知情数据分析至关重要。这种洞察力指导着合适的插补方法的选择,这些方法根据现有信息填充缺失数据,从而影响结果的准确性和可解释性。此外,评估缺失值模式为特征选择决策提供了依据;具有大量缺失数据的特征可能会被排除,以提高模型性能并专注于更可靠的信息。本质上,掌握缺失值的模式确保了数据分析的健壮性和可信度,指导插补策略并优化特征纳入以获得更准确的洞察力。
NaN 还是 None?:在 pandas 中,isnull() 函数用于检测 DataFrame 或 Series 中的缺失值。具体来说,它识别以下类型的缺失数据:
np.nan(非数字),通常用于表示缺失的数值数据None,这是 Python 内置的对象,表示值的缺失或空值
nan 和 NaN 都是指 NumPy 的 np.nan 的不同方式,isnull() 将它们识别为缺失值。下面是一个快速示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 导入 NumPy import numpy as np # 创建一个包含各种缺失值类型的数据框 df = pd.DataFrame({ 'A': [1, 2, np.nan, 4, 5], 'B': ['a', 'b', None, 'd', 'e'], 'C': [np.nan, np.nan, np.nan, np.nan, np.nan], 'D': [1, 2, 3, 4, 5] }) # 使用 isnull() 识别缺失值 missing_data = df.isnull().sum() print(df) print() print(missing_data) |
|
1 2 3 4 5 6 |
A B C D 0 1.0 a NaN 1 1 2.0 b NaN 2 2 NaN None NaN 3 3 4.0 d NaN 4 4 5.0 e NaN 5 |
|
1 2 3 4 5 |
A 1 B 1 C 5 D 0 dtype: int64 |
可视化缺失值:当需要可视化缺失数据时,DataFrames、missingno、matplotlib 和 seaborn 等工具非常有用。通过根据缺失值百分比对特征进行排序并将其放入 DataFrame 中,您可以轻松地对受缺失数据影响最大的特征进行排名。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 计算每列缺失值的百分比 missing_data = Ames.isnull().sum() missing_percentage = (missing_data / len(Ames)) * 100 # 将计数和百分比组合成一个 DataFrame,以便更好地可视化 missing_info = pd.DataFrame({'缺失值': missing_data, '百分比': missing_percentage}) # 按缺失值百分比降序排列 DataFrame missing_info = missing_info.sort_values(by='百分比', ascending=False) # 显示具有缺失值的列 print(missing_info[missing_info['缺失值'] > 0]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
缺失值 百分比 PoolQC 2570 99.651028 MiscFeature 2482 96.238852 Alley 2411 93.485847 Fence 2054 79.643273 FireplaceQu 1241 48.119426 LotFrontage 462 17.913920 GarageCond 129 5.001939 GarageQual 129 5.001939 GarageFinish 129 5.001939 GarageYrBlt 129 5.001939 GarageType 127 4.924389 Longitude 97 3.761148 Latitude 97 3.761148 BsmtExposure 71 2.753005 BsmtFinType2 70 2.714230 BsmtFinType1 69 2.675456 BsmtQual 69 2.675456 BsmtCond 69 2.675456 GeoRefNo 20 0.775494 Prop_Addr 20 0.775494 MasVnrArea 14 0.542846 MasVnrType 14 0.542846 BsmtFullBath 2 0.077549 BsmtHalfBath 2 0.077549 GarageArea 1 0.038775 BsmtFinSF1 1 0.038775 Electrical 1 0.038775 TotalBsmtSF 1 0.038775 BsmtUnfSF 1 0.038775 BsmtFinSF2 1 0.038775 GarageCars 1 0.038775 |
missingno 包可以快速、图形化地表示缺失数据。可视化中的白线或空白表示缺失值。但是,它最多只能容纳 50 个带标签的变量。超过此范围,标签开始重叠或变得不可读,默认情况下,大型显示器会省略它们。
|
1 2 3 4 |
import missingno as msno import matplotlib.pyplot as plt msno.matrix(Ames, sparkline=False, fontsize=20) plt.show() |

使用 missingno.matrix() 可视化缺失值。
在使用 msno.bar() 可视化并提取缺失值最多的前 15 个特征后,可以按列清晰地进行图示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 计算每列缺失值的百分比 missing_data = Ames.isnull().sum() missing_percentage = (missing_data / len(Ames)) * 100 # 将计数和百分比组合成一个 DataFrame,以便更好地可视化 missing_info = pd.DataFrame({'缺失值': missing_data, '百分比': missing_percentage}) # 按缺失值百分比对 DataFrame 列进行排序 sorted_df = Ames[missing_info.sort_values(by='百分比', ascending=False).index] # 选择缺失值最多的前 15 列 top_15_missing = sorted_df.iloc[:, :15] # 使用 missingno 进行可视化 msno.bar(top_15_missing) plt.show() |
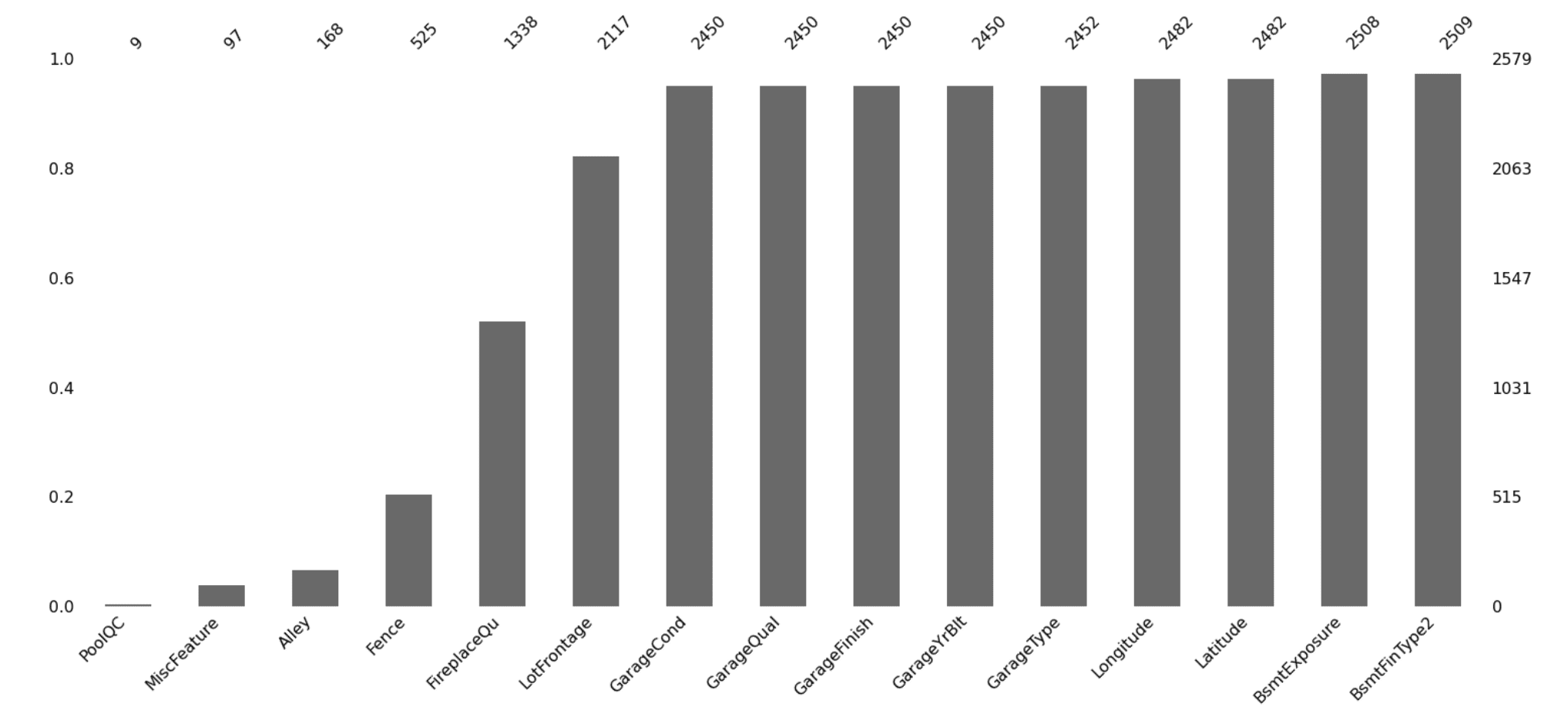
使用 missingno.bar() 可视化具有缺失值的特征。
上图显示,游泳池质量、杂项特征和房产小巷通道类型是缺失值数量最多的三个特征。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import seaborn as sns import matplotlib.pyplot as plt # 筛选并仅显示缺失值最多的前 15 列 top_15_missing_info = missing_info.nlargest(15, '百分比') # 使用 seaborn 创建水平条形图 plt.figure(figsize=(12, 8)) sns.barplot(x='百分比', y=top_15_missing_info.index, data=top_15_missing_info, orient='h') plt.title('缺失百分比前 15 的特征', fontsize=20) plt.xlabel('缺失值百分比', fontsize=16) plt.ylabel('特征', fontsize=16) plt.yticks(fontsize=11) plt.show() |
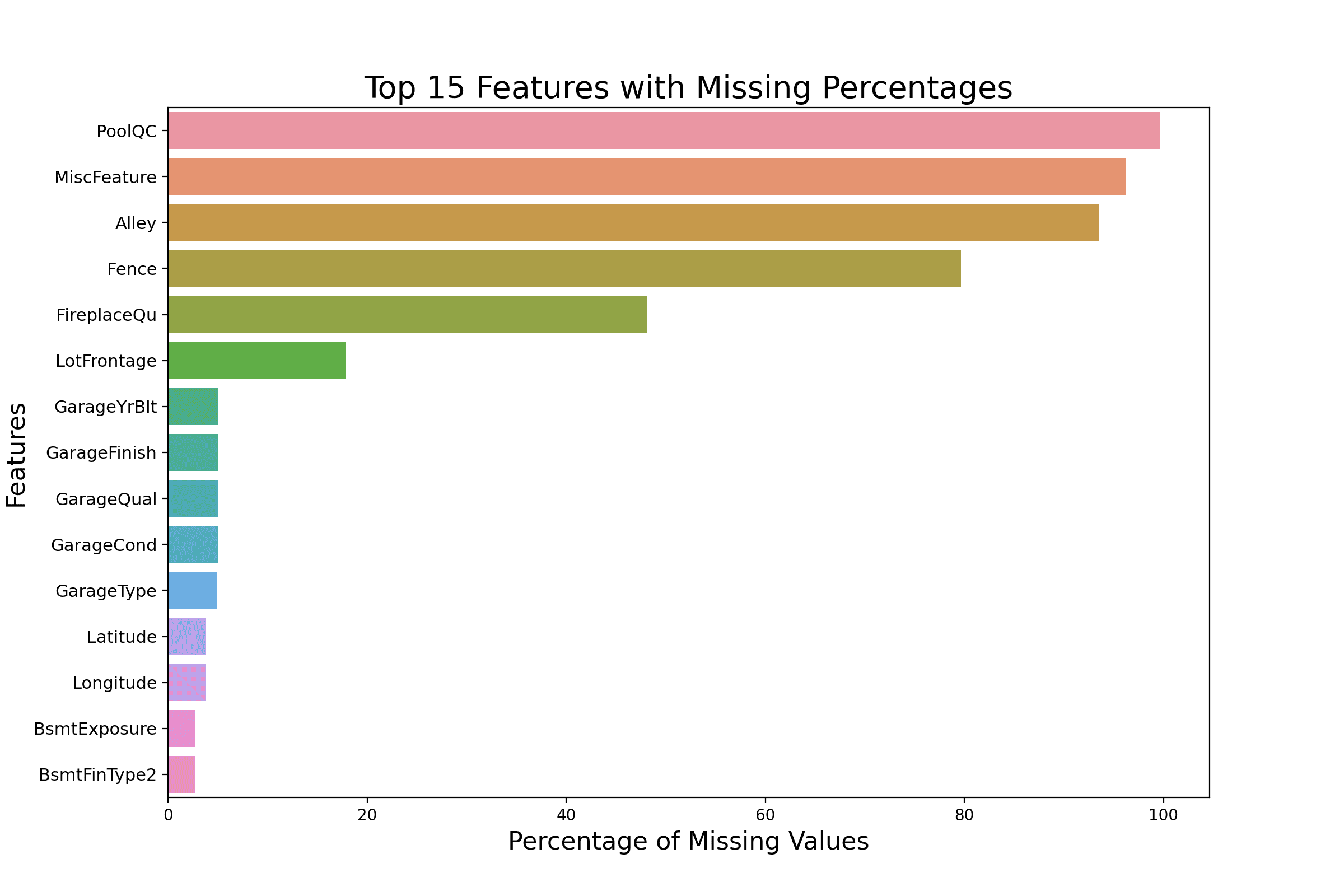
使用 seaborn 水平条形图可视化缺失数据。
使用 seaborn 的水平条形图可以将缺失值最高的特征以垂直格式列出,从而增加可读性和美观性。
处理缺失值不仅仅是一项技术要求;它是影响机器学习模型质量的重要一步。理解和可视化这些缺失值是这一复杂过程的第一步。
想开始学习数据科学新手指南吗?
立即参加我的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
教程
论文
资源
总结
在本教程中,您开始探索艾姆斯房产数据集,这是一个为数据科学应用量身定制的综合住房数据集合。
具体来说,您学习了:
- 关于艾姆斯数据集的背景,包括其背后的先驱者和学术重要性。
- 如何提取数据集维度、数据类型和缺失值。
- 如何使用
missingno、Matplotlib 和 Seaborn 等包快速可视化您的缺失数据。
您有任何问题吗?请在下面的评论中提出您的问题,我将尽力回答。







这是一个非常好的揭示缺失值可视化的方法。虽然我确实使用 missingno 来运行缺失值的可视化,但我以前从未使用 seaborn 进行绘图。我一定要试试!非常感谢!
不客气,Abdulsalam!
非常感谢 Vinod 的这篇文章。我很高兴能运行它并看到缺失值的重要性。我现在将继续学习您关于艾姆斯住房的下一个链接。
不客气!很高兴听到您觉得这篇文章有帮助。