LeNet、AlexNet、VGG、Inception 和 ResNet 卷积神经网络创新简介。
尽管简单,但在给定的计算机视觉问题中,排列这些层的方法几乎是无限的。
幸运的是,有配置这些层的常见模式和架构创新,您可以使用它们来开发非常深的卷积神经网络。研究这些为最先进的图像分类任务开发的架构设计决策,可以为在设计您自己的深度卷积神经网络模型时如何使用这些设计提供理论依据和直觉。
在本教程中,您将发现卷积神经网络在挑战性图像分类问题中的关键架构里程碑。
完成本教程后,您将了解:
- 在实现卷积神经网络时,如何对滤波器数量和滤波器尺寸进行模式化。
- 如何以统一的模式排列卷积层和池化层以开发性能良好的模型。
- 如何使用 Inception 模块和残差模块来开发更深层次的卷积网络。
通过我的新书《深度学习计算机视觉》**开启您的项目**,其中包括分步教程和所有示例的 Python 源代码文件。
让我们开始吧。
- 2019年4月更新:纠正了 LeNet 滤波器尺寸的描述(感谢 Huang)。
教程概述
本教程分为六个部分;它们是:
- CNN 架构设计
- LeNet-5
- AlexNet
- VGG
- Inception 和 GoogLeNet
- 残差网络或 ResNet
CNN 架构设计
卷积神经网络的元素,例如卷积层和池化层,相对容易理解。
在实践中使用卷积神经网络的挑战在于如何设计模型架构,以最好地利用这些简单的元素。
学习如何设计有效的卷积神经网络架构的一种有用方法是研究成功的应用。由于 2012 年至 2016 年期间,ImageNet 大规模视觉识别挑战 (ILSVRC) 对 CNN 进行了深入研究和应用,因此这样做特别简单。这项挑战导致了非常困难的计算机视觉任务领域最先进技术的快速发展,以及卷积神经网络模型架构的一般创新。
我们将从 LeNet-5 开始,它通常被描述为 ILSVRC 之前 CNN 的第一个成功且重要的应用,然后我们将研究为 ILSVRC 开发的四种不同的卷积神经网络获胜架构创新,即 AlexNet、VGG、Inception 和 ResNet。
通过从高层次理解这些里程碑模型及其架构或架构创新,您将对这些架构元素在现代计算机视觉 CNN 应用中的使用产生更深的理解,并能够识别和选择可能对您自己的模型设计有用的架构元素。
想通过深度学习实现计算机视觉成果吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
LeNet-5
也许卷积神经网络的第一个广为人知且成功的应用是 LeNet-5,由 Yann LeCun 等人在其 1998 年的论文《基于梯度的学习应用于文档识别》(获取 PDF)中描述。
该系统是为手写字符识别问题开发的,并在 MNIST 标准数据集上进行了演示,实现了大约 99.2% 的分类准确率(或 0.8% 的错误率)。该网络随后被描述为更广泛系统(称为图转换网络)的核心技术。
这是一篇很长的论文,也许最值得关注的部分是第二节 B,它描述了 LeNet-5 架构。在该节中,论文将该网络描述为具有七层,输入灰度图像的形状为 32×32,这是 MNIST 数据集中的图像大小。
该模型提出了一种卷积层后接平均池化层(称为下采样层)的模式。这种模式重复了两到三次,然后输出特征图被展平并馈送到多个全连接层进行解释和最终预测。论文中提供了网络架构的图片,并在下面复制。
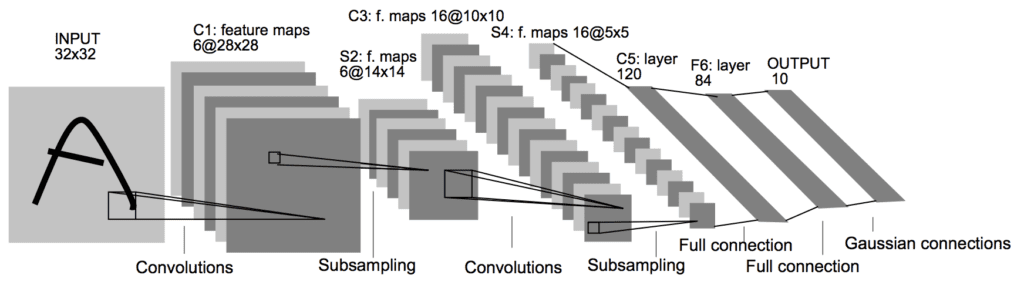
用于手写字符识别的 LeNet-5 卷积神经网络架构(取自 1998 年的论文)。
卷积层和池化层块的组合和重复模式在今天(二十多年后)仍然是设计和使用卷积神经网络的常见模式。
有趣的是,该架构使用少量滤波器作为第一个隐藏层,具体来说是六个滤波器,每个滤波器大小为 5×5 像素。在池化(称为子采样层)之后,另一个卷积层有更多滤波器,同样尺寸较小,但比之前的卷积层小,具体来说是 16 个滤波器,大小为 5×5 像素,再次后面跟着池化。在这两个卷积和池化层块的重复中,趋势是滤波器数量的增加。
与现代应用相比,滤波器数量也很少,但随着网络深度的增加而增加滤波器数量的趋势在现代技术使用中仍然是一个常见模式。
特征图的展平以及全连接层对提取特征的解释和分类在今天仍然是一种常见的模式。在现代术语中,架构的最后一部分通常被称为分类器,而模型中较早的卷积层和池化层则被称为特征提取器。
我们可以将与现代模型相关的架构关键方面总结如下:
- 固定大小的输入图像。
- 将卷积层和池化层分组为块。
- 架构中卷积-池化块的重复。
- 随着网络深度的增加,滤波器数量增加。
- 架构中独立的特征提取和分类器部分。
AlexNet
或许可以归因于重新激发对神经网络的兴趣并开启深度学习在许多计算机视觉应用中主导地位的工作是 Alex Krizhevsky 等人于 2012 年发表的论文,题为《使用深度卷积神经网络进行 ImageNet 分类》。
该论文描述了一个后来被称为“AlexNet”的模型,旨在解决ImageNet 大规模视觉识别挑战赛或ILSVRC-2010竞赛,该竞赛的目标是将物体照片分类到 1000 个不同类别中的一个。
ILSVRC 是一项从 2011 年到 2016 年举行的竞赛,旨在刺激计算机视觉领域的创新。在 AlexNet 开发之前,这项任务被认为非常困难,远远超出当时现代计算机视觉方法的能力。AlexNet 成功地展示了卷积神经网络模型在该领域的能力,并点燃了一团火,导致了更多的改进和创新,其中许多在随后的几年中都在相同的 ILSVRC 任务上得到了展示。更广泛地说,该论文表明,有可能为具有挑战性的问题开发深度且有效的端到端模型,而无需使用当时流行的无监督预训练技术。
AlexNet 设计中的重要因素是一套当时新颖或成功但尚未广泛采用的方法。现在,它们已成为使用 CNN 进行图像分类时的必备要素。
AlexNet 在每个卷积层之后使用修正线性激活函数(ReLU)作为非线性函数,而不是当时常用的 S 形函数,如 Logistic 或 Tanh。此外,输出层使用了 Softmax 激活函数,这现在已成为神经网络多类别分类的必备。
LeNet-5 中使用的平均池化被替换为最大池化方法,尽管在这种情况下,重叠池化被发现优于当前常用的非重叠池化(例如,池化操作的步长与池化操作的大小相同,例如 2 乘 2 像素)。为了解决过拟合问题,在模型分类器部分的全连接层之间使用了新提出的Dropout 方法,以提高泛化误差。
AlexNet 的架构很深,并扩展了 LeNet-5 中建立的一些模式。下图中取自论文,总结了模型架构,在这种情况下,为了在当时的 GPU 硬件上进行训练,将其分为两个管道。
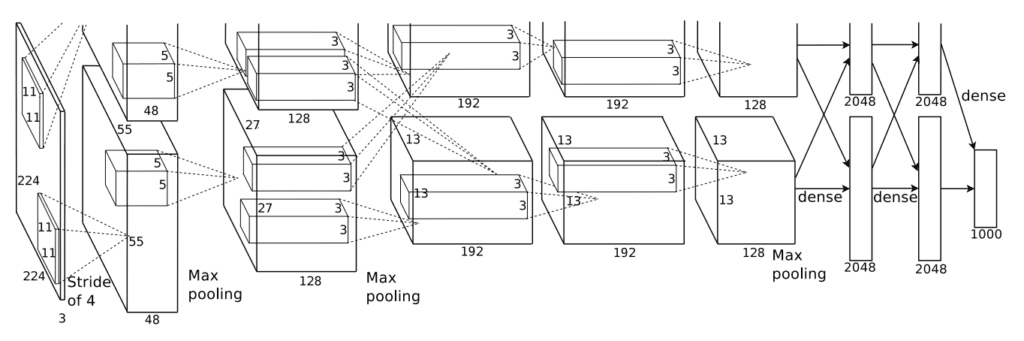
用于对象照片分类的 AlexNet 卷积神经网络架构(取自 2012 年论文)。
该模型在模型的特征提取部分有五个卷积层,在模型的分类器部分有三个全连接层。
输入图像固定为 224×224 尺寸,带有三个颜色通道。在每个卷积层中使用的滤波器数量方面,LeNet 中看到的随着深度增加滤波器数量的模式基本得到了遵循,在这种情况下,尺寸分别为:96、256、384、384 和 256。同样,随着深度增加滤波器(核)尺寸减小的模式也被使用,从较小的 11×11 开始,减小到 5×5,然后在更深层减小到 3×3。使用 5×5 和 3×3 等小滤波器现在已成为常态。
在模型特征检测部分的开始和结束处都使用了卷积层后接池化层的模式。有趣的是,使用了卷积层后立即接第二个卷积层的模式。这种模式也已成为现代标准。
该模型通过数据增强进行训练,人工增加了训练数据集的大小,使模型有更多机会学习不同方向的相同特征。
我们可以将与现代模型相关的架构关键方面总结如下:
- 在卷积层之后使用 ReLU 激活函数,输出层使用 Softmax。
- 使用最大池化而不是平均池化。
- 在全连接层之间使用 Dropout 正则化。
- 卷积层直接连接到另一个卷积层的模式。
- 使用数据增强。
VGG
AlexNet 之后,用于计算机视觉任务的深度卷积神经网络的开发似乎有点像一门“黑魔法”。
Karen Simonyan 和 Andrew Zisserman 于 2014 年发表的题为《用于大规模图像识别的非常深的卷积网络》的论文是一项重要的工作,它旨在标准化深度卷积网络的架构设计,并在此过程中开发出更深、性能更好的模型。
他们的架构通常被称为 VGG,以他们的实验室(牛津大学的视觉几何组)命名。他们的模型是在相同的 ILSVRC 竞赛(在这种情况下是 ILSVRC-2014 版的挑战)中开发和演示的。
第一个重要的差异是使用大量小滤波器,这已成为事实标准。具体来说,滤波器尺寸为 3×3 和 1×1,步长为 1,这与 LeNet-5 中的大尺寸滤波器以及 AlexNet 中较小但仍然相对较大的滤波器和 4 的大步长不同。
最大池化层在大多数(但不是所有)卷积层之后使用,借鉴了 AlexNet 的例子,但所有池化都使用 2×2 的尺寸和相同的步长进行,这也已成为事实标准。具体来说,VGG 网络使用了两个、三个甚至四个卷积层堆叠在一起的示例,然后才使用最大池化层。其原理是,具有较小滤波器的堆叠卷积层近似于具有较大尺寸滤波器(例如,三个堆叠的 3×3 滤波器卷积层近似于一个 7×7 滤波器卷积层)的单个卷积层的效果。
另一个重要的区别是使用了非常大量的滤波器。滤波器的数量随着模型深度的增加而增加,尽管开始时数量相对较大,为 64,并在模型特征提取部分的末尾增加到 128、256 和 512 个滤波器。
开发和评估了该架构的多个变体,尽管最常用的是其性能和深度所决定的两个变体。它们以层数命名:VGG-16 和 VGG-19,分别表示 16 层和 19 个学习层。
下面是论文中的表格;请注意右侧两列,它们表示 VGG-16 和 VGG-19 架构版本中使用的配置(滤波器数量)。
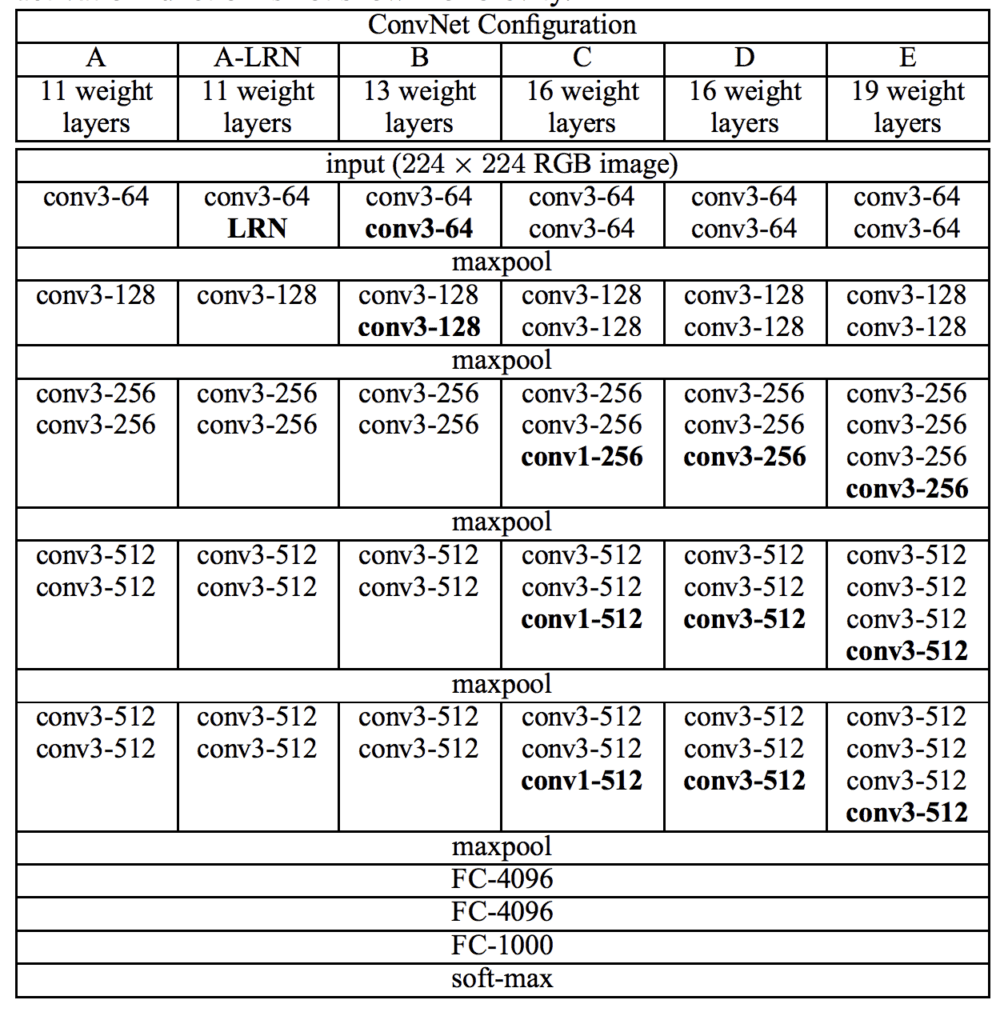
用于目标照片分类的 VGG 卷积神经网络架构(摘自 2014 年论文)。
VGG 模型中的设计决策已成为一般情况下简单直接使用卷积神经网络的起点。
最后,VGG 工作是首批在宽松许可下发布有价值模型权重的工作之一,这引领了深度学习计算机视觉研究人员之间的一种趋势。反过来,这导致了预训练模型(如 VGG)在迁移学习中作为新计算机视觉任务起点的广泛使用。
我们可以将与现代模型相关的架构关键方面总结如下:
- 使用非常小的卷积滤波器,例如 3×3 和 1×1,步长为 1。
- 使用最大池化,尺寸为 2×2,步长与维度相同。
- 在池化层之前堆叠卷积层以定义块的重要性。
- 卷积-池化块模式的显著重复。
- 开发了非常深(16 层和 19 层)的模型。
Inception 和 GoogLeNet
Christian Szegedy 等人在其 2015 年论文《更深层的卷积网络》中提出了卷积层使用的重要创新。
在论文中,作者提出了一种被称为 Inception(或 Inception v1,以区别于扩展版本)的架构,以及一个名为 GoogLeNet 的特定模型,该模型在 2014 年 ILSVRC 挑战赛中取得了优异成绩。
Inception 模型的核心创新被称为 Inception 模块。这是一个由并行卷积层组成的块,具有不同大小的滤波器(例如 1×1、3×3、5×5)和一个 3×3 最大池化层,然后将它们的输出连接起来。下面是摘自论文的 Inception 模块示例。
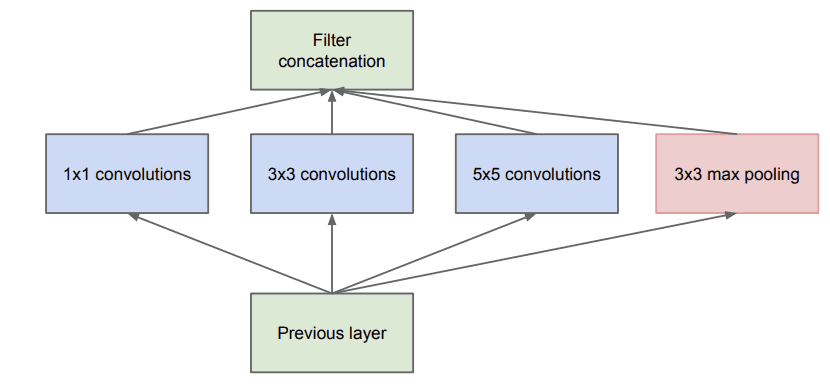
朴素 Inception 模块示例(摘自 2015 年论文)。
Inception 模型的一个朴素实现存在一个问题,即滤波器(深度或通道)的数量开始迅速增加,尤其是在堆叠 Inception 模块时。
对大量滤波器执行较大滤波器尺寸(例如 3 和 5)的卷积运算可能计算成本很高。为了解决这个问题,使用 1×1 卷积层来减少 Inception 模型中的滤波器数量。具体来说,是在 3×3 和 5×5 卷积层之前以及池化层之后。下面摘自论文的图片显示了 Inception 模块的这一改变。
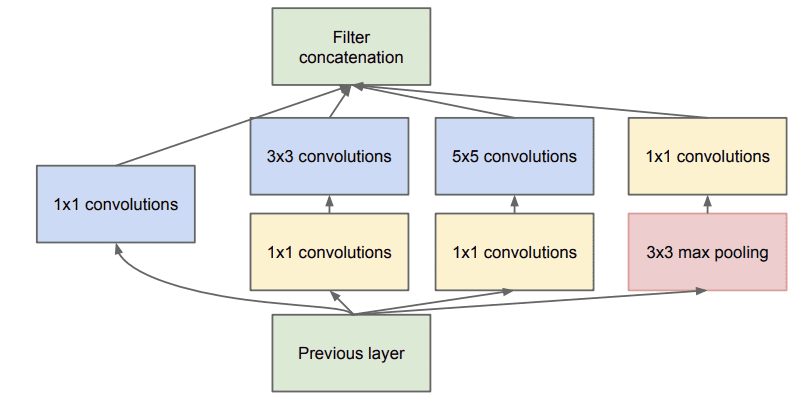
使用降维的 Inception 模块示例(摘自 2015 年论文)。
Inception 模型中第二个重要的设计决策是在模型的不同点连接输出。这是通过从主网络创建小的分支输出网络来实现的,这些网络经过训练以进行预测。目的是在深度模型的不同点提供来自分类任务的额外误差信号,以解决梯度消失问题。这些小型输出网络在训练后被移除。
下面显示了 GoogLeNet 模型的架构旋转版本(从左到右表示输入到输出),取自论文,使用了从左侧输入到右侧输出分类的 Inception 模块,以及仅在训练期间使用的两个额外的输出网络。
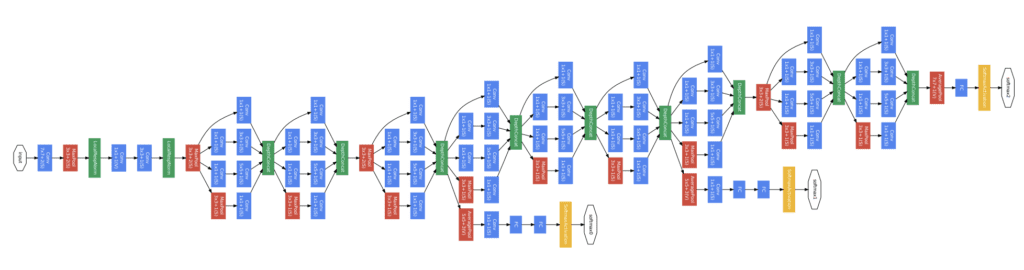
用于对象照片分类的 GoogLeNet 模型训练期间使用的架构(摘自 2015 年论文)。
有趣的是,在模型的特征提取部分,在分类器部分之前,使用了重叠的最大池化和大的平均池化操作。
我们可以将与现代模型相关的架构关键方面总结如下:
- Inception 模块的开发和重复使用。
- 大量使用 1×1 卷积来减少通道数量。
- 在网络中的多个点使用错误反馈。
- 开发了非常深(22 层)的模型。
- 使用全局平均池化作为模型的输出。
残差网络或 ResNet
我们将回顾的卷积神经网络的最后一个重要创新是由 Kaiming He 等人在其 2016 年论文《深度残差学习用于图像识别》中提出的。
在论文中,作者提出了一种非常深的模型,称为残差网络,或简称 ResNet,其一个示例在 2015 年 ILSVRC 挑战赛中取得了成功。
他们的模型拥有令人印象深刻的 152 层。模型设计的关键是残差块的概念,它利用了快捷连接。这些只是网络架构中的连接,其中输入保持不变(未加权)并传递到更深的层,例如跳过下一层。
残差块是两个卷积层和 ReLU 激活的模式,其中块的输出与块的输入(即快捷连接)相结合。如果块的输入形状与块的输出形状不同,则通过 1×1 卷积使用投影版本的输入,这被称为 1×1 卷积。这些被称为投影快捷连接,与无权重或恒等快捷连接相比。
作者从他们所谓的普通网络开始,这是一个受 VGG 启发的深度卷积神经网络,具有小滤波器(3×3),分组卷积层之间没有池化,并在模型特征检测部分末尾(在带有 softmax 激活函数的全连接输出层之前)进行平均池化。
通过添加快捷连接来定义残差块,普通网络被修改为残差网络。通常,快捷连接的输入形状与残差块的输出大小相同。
下图摘自论文,从左到右比较了 VGG 模型、普通卷积模型以及带有残差模块的普通卷积模型(称为残差网络)的架构。
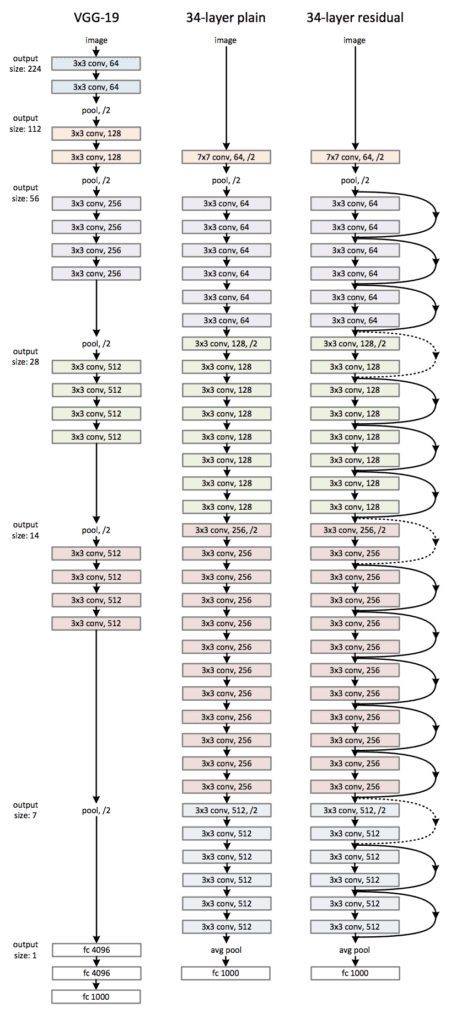
用于对象照片分类的残差网络架构(摘自 2016 年论文)。
我们可以将与现代模型相关的架构关键方面总结如下:
- 使用快捷连接。
- 残差块的开发和重复。
- 开发了非常深(152 层)的模型。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 基于梯度的学习应用于文档识别,(PDF) 1998。
- 使用深度卷积神经网络进行 ImageNet 分类, 2012.
- 用于大规模图像识别的超深度卷积网络, 2014.
- 使用卷积网络更深入, 2015.
- 用于图像识别的深度残差学习, 2016
API
文章
总结
在本教程中,您了解了卷积神经网络在挑战性图像分类中使用的关键架构里程碑。
具体来说,你学到了:
- 在实现卷积神经网络时,如何对滤波器数量和滤波器尺寸进行模式化。
- 如何以统一的模式排列卷积层和池化层以开发性能良好的模型。
- 如何使用 Inception 模块和残差模块来开发更深层次的卷积网络。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于视觉的深度学习模型!

在几分钟内开发您自己的视觉模型
...只需几行python代码
在我的新电子书中探索如何实现
用于计算机视觉的深度学习
它提供关于以下主题的自学教程:
分类、物体检测(YOLO和R-CNN)、人脸识别(VGGFace和FaceNet)、数据准备等等……
最终将深度学习引入您的视觉项目
跳过学术理论。只看结果。
")





先生,您能告诉我如何使用 CNN 和 RNN 对语音进行分类吗?
抱歉,我没有语音识别的示例,希望将来能涵盖它。
关于 AlexNet 的一个重要点是白皮书中的“小错误”,这可能会导致混淆、沮丧、失眠……:)
应用步幅后的输出体积必须是整数,而不是分数。
输出体积的公式:((W-K+2P) / S)+ 1
这里,我们有输入数据(W)=224×224,核尺寸(K)=11×11,步长(S)=4,填充(P)=0。
((224 − 11 + 2*0 ) / 4) +1 = 54.25 -> 小数值
但是,如果我们的输入图像是 227×227,我们得到 ((227 − 11 + 2*0 ) / 4 ) + 1 = 55 -> 整数值
教训:在深入研究之前,务必检查参数 😉
此致,
感谢分享。
这就是为什么 VGG 使用 224×224 吗?因为他们没有检查……哈哈。我一直想知道为什么 AlexNet 是 227,而 VGG 是 224。
我怀疑。
很棒的帖子。它清晰简洁。我真的很喜欢每个网络末尾的总结。这加强了学习。我仍然有很多东西没有完全理解。例如,我一直无法理解三个 3×3 如何等同于一个 7×7,或者两个 3×3 如何等同于一个 5×5。我尝试搜索一些视觉帮助,但没有找到足够清晰的。此外,我不理解 resnet 短连接的意义。我想那是另一个帖子的话题。感谢您运用您的知识,并将其简化,以帮助那些可能没有数学或该领域学术背景的人。继续努力!
谢谢!
是的,这周结束时我将发布一篇关于如何编写每个代码的帖子,这可能会有所帮助——例如,您可以试玩它们并查看输入/输出形状。
期待那个!我非常喜欢这篇带总结的历史回顾,因为我是机器学习和 CNN 的新手。不过,1×1 卷积层是我还不完全理解的地方。如果能有一个关于它如何减少滤波器数量的例子,我将不胜感激。
谢谢,我希望能尽快发布一篇专门讨论这个话题的帖子。
Le-Net 的滤波器尺寸是 5×5(C1 和 C3)。图中显示的是特征图尺寸。所以说滤波器非常大是错误的。AlexNet 才有大滤波器,特别是在第一层(11×11)。
谢谢,我会调查并修正描述。
堆叠卷积层是什么意思,以及如何编写这些堆叠层的代码?
堆叠层意味着一层叠在另一层之上。
我在这里展示了如何实现它们
https://machinelearning.org.cn/how-to-implement-major-architecture-innovations-for-convolutional-neural-networks/
如果是在 Andrew Ng 深度学习专业课程中的 CNN 课程之后阅读此帖子,会更容易理解。
谢谢。
你好,Jason。
“ReLU 非线性函数应用于每个卷积层和全连接层的输出。”
您需要这方面的帮助吗?
嗨,Jason,
我有一个问题;有时,非常深的卷积神经网络可能无法从数据中学习。出现这个问题的主要原因是什么?
谢谢。
可能是学习算法的配置问题。例如学习率、优化器等。
此外,也可能是网络架构和传输函数的选择问题。
好文章!
继续努力。
谢谢!