循环神经网络 (RNN) 是一种神经网络,其中前一时间步的输出被作为当前时间步的输入。
这会创建一个带有循环的网络图或电路图,这使得理解信息如何在网络中流动变得困难。
在本文中,您将了解展开或解开循环神经网络的概念。
阅读本文后,你将了解:
- 具有循环连接的标准循环神经网络概念。
- 当网络为每个输入时间步复制时,前向传播展开的概念。
- 反向传播展开的概念,用于在训练期间更新网络权重。
开始您的项目,阅读我的新书《Python 语言长短期记忆网络》,其中包含分步教程和所有示例的Python 源代码文件。
让我们开始吧。
展开循环神经网络
循环神经网络是一种神经网络,其中前一时间步的输出被作为当前时间步的输入。
我们可以用一张图片来展示这一点。
下面我们可以看到,网络同时接收来自前一时间步的网络输出作为输入,并使用前一时间步的内部状态作为当前时间步的起点。
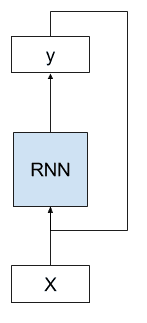
带循环的 RNN 示例
RNN 适合在多个时间步上进行拟合和预测。我们可以通过沿着输入序列展开或解开 RNN 图来简化模型。
可视化 RNN 的一种有用方法是考虑通过沿输入序列“展开”网络而形成的更新图。
— 监督序列标记与循环神经网络, 2008。
展开前向传播
考虑我们有多个时间步的输入 (X(t), X(t+1), …)、多个时间步的内部状态 (u(t), u(t+1), …) 和多个时间步的输出 (y(t), y(t+1), …) 的情况。
我们可以将上述网络图展开成一个没有循环的图。
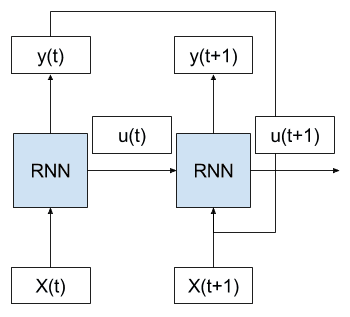
前向传播展开 RNN 的示例
我们可以看到循环被消除了,并且前一时间步的输出 (y(t)) 和内部状态 (u(t)) 被作为输入传递给网络,以处理下一个时间步。
这种概念的关键在于,网络(RNN)在展开的时间步之间不发生变化。具体来说,每个时间步使用相同的权重,只有输出和内部状态有所不同。
这样一来,就好像整个网络(拓扑结构和权重)都为输入序列中的每个时间步进行了复制。
此外,网络的每个副本都可以被视为相同的前馈神经网络的附加层。
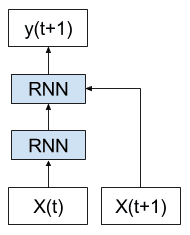
展开 RNN 的示例,其中网络的每个副本都是一层
一旦 RNN 在时间上展开,就可以将其视为非常深的前馈网络,其中所有层共享相同的权重。
— 深度学习,Nature, 2015
这是一个有用的概念工具和可视化,有助于理解在前向传播过程中网络中发生的情况。这是否也可能是深度学习库实现网络的方式,不一定。
展开反向传播
网络展开的思想在循环神经网络的反向传播实现方式中起着更大的作用。
正如 [时间反向传播] 的标准做法一样,网络会随时间展开,因此到达层的连接被视为来自前一个时间步。
— 双向 LSTM 和其他神经网络架构的逐帧语音识别, 2005
重要的是,给定时间步的误差反向传播取决于网络在前一个时间步的激活。
通过这种方式,反向传播需要展开网络的概念。
误差会传播回序列的第一个输入时间步,以便计算误差梯度并更新网络权重。
与标准反向传播一样,[时间反向传播] 由链式法则的重复应用组成。微妙之处在于,对于循环神经网络,损失函数不仅通过其对输出层的影响,还通过其对下一个时间步隐藏层的影响来依赖于隐藏层的激活。
— 监督序列标记与循环神经网络, 2008
展开循环网络图还会带来其他问题。每个时间步都需要一个新网络的副本,这又会占用内存,特别是对于拥有数千或数百万个权重的较大网络。随着时间步的数量攀升至数百,训练大型循环网络所需的内存可能会迅速膨胀。
… 需要根据输入序列的长度展开 RNN。通过将 RNN 展开 N 次,神经元在网络内的所有激活都会被复制 N 次,这会消耗大量内存,尤其是在序列非常长的情况下。这会阻碍在线学习或适配的小尺寸实现。此外,这种“完全展开”使得在共享内存模型(如图形处理单元 (GPU))上与多个序列进行并行训练效率低下。
— 使用连接主义时间分类的循环神经网络在线序列训练, 2015
进一步阅读
如果您想深入了解此主题,本节提供了更多资源。
论文
- 使用连接主义时间分类的循环神经网络在线序列训练, 2015
- 双向 LSTM 和其他神经网络架构的逐帧语音识别, 2005
- 监督序列标记与循环神经网络, 2008
- 深度学习,Nature, 2015
文章
- 时间反向传播简明介绍
- 理解 LSTM 网络。, 2015
- RNN 的滚动与展开, 2016
- 展开 RNN, 2017
总结
在本教程中,您了解了展开循环神经网络的可视化和概念工具。
具体来说,你学到了:
- 具有循环连接的标准循环神经网络概念。
- 当网络为每个输入时间步复制时,前向传播展开的概念。
- 反向传播展开的概念,用于在训练期间更新网络权重。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发用于序列预测的 LSTM!

在几分钟内开发您自己的 LSTM 模型。
...只需几行python代码
在我的新电子书中探索如何实现
使用 Python 构建长短期记忆网络
它提供关于以下主题的自学教程:
CNN LSTM、编码器-解码器 LSTM、生成模型、数据准备、进行预测等等...
最终将 LSTM 循环神经网络引入。
您的序列预测项目。
跳过学术理论。只看结果。






每个时间步都需要一个新网络的副本,这又会占用内存,特别是对于拥有数千或数百万个权重的较大网络。
我以为 RNN 的不同时间步共享相同的权重,那么为什么展开会增加权重数量并消耗更多内存?
此外,为什么展开会使 GPU 上的并行训练效率低下?据我所知,RNN 的一种优化方法是将其展开并为所有输入执行一个大型 gemm 来提高 gemm 的效率。
这篇文章对我非常有帮助。谢谢。
多亏了它,我可以很好地开始学习 RNN。
谢谢。
我对神经网络既着迷于解决实际问题,也着迷于通过类比大脑的工作方式来寻求理解,很难相信生物神经网络会爆炸式地消耗“内存”。虽然生物神经网络必然是循环的,但一定存在压缩,正如研究表明访问内存会改变内存那样。
我很想了解更多。我还需要声明,我在认知领域是个新手,所以如果我的批评看起来很明显,希望可以被原谅。
人工神经网络并不是要模拟大脑,它们是我们发现对建模预测问题有用的数学技巧。
你好,你用什么工具画这些图?
谷歌的绘图文档工具那个东西。
Jason 你好;帖子非常有帮助。在展开具有多个循环层的网络时,是否将每个循环实例展开为一个单独的子图?请参考 https://imgur.com/a/aFhCl 获取视觉辅助。
算了,我想我明白了 :D。
每个,每个层都会被单独展开,至少按照我临时想到的方法是这样。
当您说“所有层共享相同的权重”时,您指的是哪些层?我猜是连接输入到 RNN 层以及 RNN 层到输出层的权重。
另外,您能否提供 RNN 内部状态的可视化?
展开的 RNN 中的层。
感谢您的建议。
另外,当您说“前一时间步的输出 (y(t)) 和内部状态 (u(t)) 被作为输入传递给网络,以处理下一个时间步”时。我不确定我们是否将前一时间步的“内部状态”作为当前时间步内部状态的输入。我认为我们是“作用于”前一时间步的内部状态。请告诉我我的理解是否正确。
内部状态就像一个局部变量,被单元在时间步之间使用。
嗨
我有一个关于 RNN 中反向传播的问题。在应用链式法则从输出到权重矩阵和偏置时,是否有任何中间步骤计算相对于特征向量 X 的偏导数?我无法想象会这样,因为我们无法修改/调整特征向量,因为它“只读”。
我问的原因是我在以下文章的结尾看到了这个
https://eli.thegreenplace.net/2018/backpropagation-through-a-fully-connected-layer/
标题为“附加说明 – 相对于 x 的梯度”的段落。
您能对此有所阐述吗?
谢谢!
也许联系文章的作者问问他们是什么意思?
谢谢您的回答。
独立于这篇博文,我能否直接问您,据您所知,是否可以计算相对于输入特征向量的偏导数?如果可以,是在哪种神经网络中,或者是否有论文链接或您关于此的博文等?
抱歉,我暂时不知道。
嗨
供大家参考,关于我们为什么会计算相对于特征向量 X 的导数。
在 RNN 中,当我们使用链式法则计算 DL/DW(相对于权重矩阵的梯度)时,我们在反向传播时确实需要计算相对于 X 的梯度。
有关此的更多详细信息,请参阅同一作者关于 RNN 的后续博文。
https://eli.thegreenplace.net/2018/understanding-how-to-implement-a-character-based-rnn-language-model/
当我们应用链式法则计算 Dy[t]/dw 时
Dy[t]/dw = Dy[t]/dh[t] * dh[t]/dw
通过这种乘法,我们需要 Dy[t]/dh[t],这正是相对于输入向量(此处称为 h,RNN 的状态向量而不是 X)的导数计算。
感谢分享。
在反向传播时部分展开 RNN 是什么意思?
它是否字面意思是只展开一部分步骤?
我们这样做的原因是因为,正如其中一个引用提到的,展开整个 RNN 可能计算成本很高?
它在内存中被展开。
我们这样做是为了在计算速度和内存使用之间进行权衡。同时也是作为一种概念模型,用于理解训练期间 RNN 中发生的情况。
关于 RNN 的不错的机器学习技术……像您之前分享 Keras 神经网络一样,也分享一个简单的 RNN 模型。谢谢。
Keras 中最老的 RNN 实现称为 SimpleRNN,但人们通常更喜欢 LSTM 或 GRU。我们有一个 LSTM 的例子:https://machinelearning.org.cn/define-encoder-decoder-sequence-sequence-model-neural-machine-translation-keras/
我认为您的内容是互联网上文章中最好的。非常感谢!
Anurag,很高兴收到您的反馈!