2025 年精通机器学习学习路线图
图片作者 | Canva
机器学习 (ML) 如今已成为我们日常生活的一部分,从手机上的语音助手到执行类似人类任务的先进机器人。它已改变了许多行业,例如医疗保健,通过帮助医生诊断疾病的工具;汽车行业,通过引入自动驾驶汽车;零售业,通过个性化推荐提升客户体验,自动化库存管理系统等等。
全球机器学习市场在 2021 年的估值为 149.1 亿美元,预计到 2030 年将以 38.1% 的复合年增长率增长,达到约 3026.2 亿美元,这使其成为到 2025 年最值得学习的技能之一。
无论您是想了解机器学习的基础知识,还是想在此领域发展事业但又不知道从何入手,本指南都能为您提供帮助。它提供了一个清晰、循序渐进的路线图,指导您掌握 2025 年精通机器学习所需的必备技能和知识。
什么是机器学习?
您如何学习任何一项任务?显然,通过向他人或从某处学习,然后反复练习,这被称为获取经验。人类智能就是这样发展的。同样,机器学习是向机器提供信息,让机器从数据中学习并随着时间推移不断改进的过程。
机器学习允许计算机在没有明确的每一步指令的情况下执行任务。基本上,系统通过识别数据中的模式来学习做出决策。例如,与其对计算机进行编程以识别猫,不如向其展示数千张猫的图片。计算机学习定义猫的关键特征,并使用这些特征对图像进行分类。随着时间的推移,在处理更多数据时,计算机在识别猫方面会变得更好。就像人类通过练习会进步一样,机器学习也能帮助计算机在遇到更多相关数据时变得更聪明、更高效。
现在,让我们探讨一下如何在 2025 年开始学习机器学习。
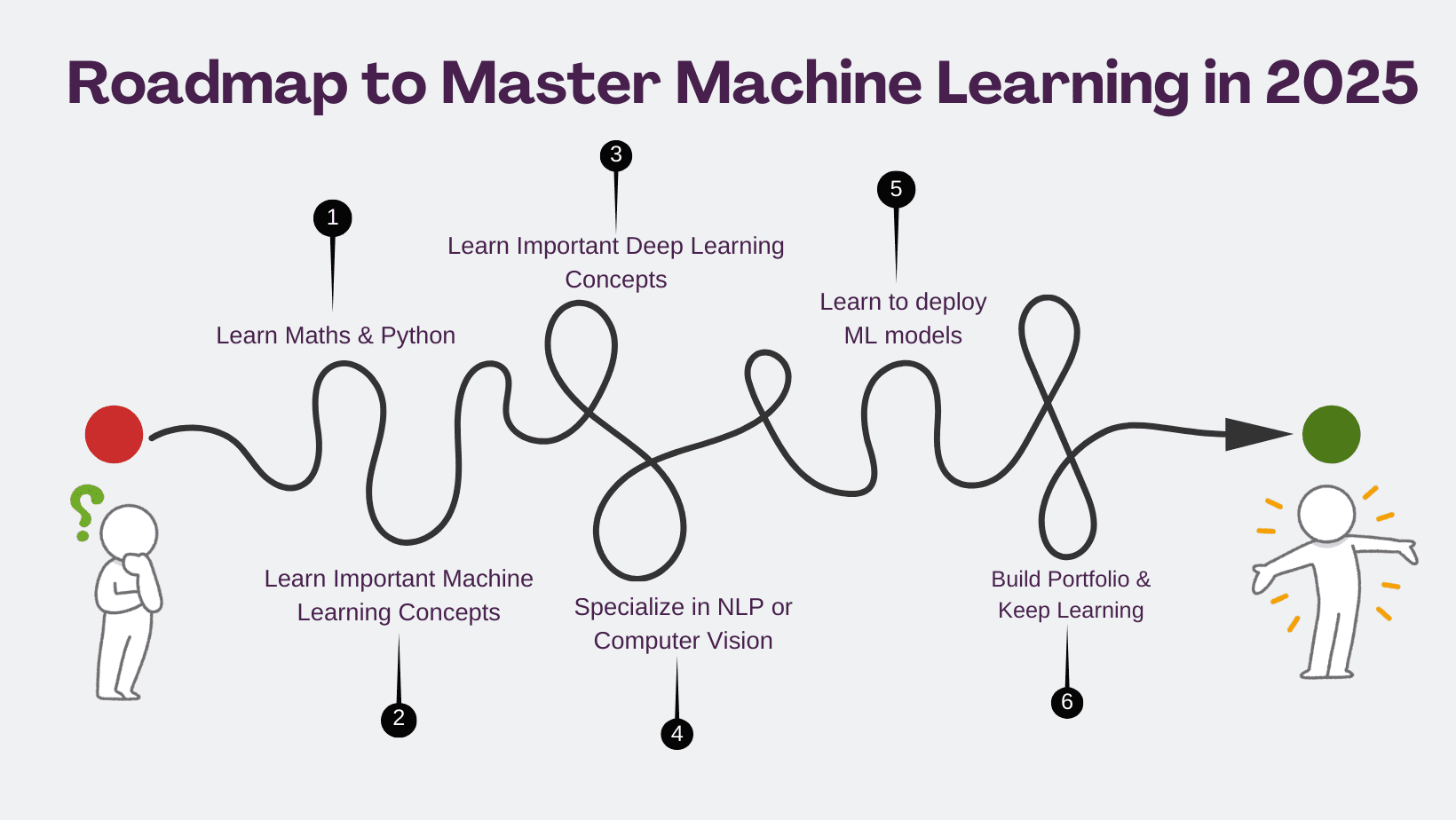
机器学习精通分步路线图
第一步:先决条件
首先,在深入机器学习之前,您需要学习一些数学和编程概念。
学习数学
- 线性代数: 学习向量、矩阵、矩阵运算、特征值和奇异值分解。您可以通过这些 YouTube 课程进行学习
机器学习基础:欢迎踏上旅程 – YouTube
机器学习数学 – YouTube
线性代数 | 可汗学院 - 微积分: 学习导数、梯度和优化技术。您可以通过这些视频课程进行学习
微积分用于机器学习 – YouTube
微积分 1 | 数学 | 可汗学院
微积分 1 – 完整大学课程 – YouTube - 概率与统计: 重点关注关键概念,如贝叶斯定理、概率分布和假设检验。您可以通过这些视频课程进行学习
统计 – 数据科学基础全大学课程 – YouTube
统计与概率全课程 || 数据科学统计 – YouTube
您也可以参考这本精彩的书籍来学习机器学习所需的数学基础
教材:机器学习数学
学习编程
- Python(推荐): Python 是机器学习中最流行的编程语言。这些资源可以帮助您学习 Python
学习 Python – 面向初学者的完整课程 [教程] – YouTube
Python 入门速成班 – YouTube
教材:艰苦学习 Python - 掌握编程基础后,重点学习 **Pandas、Matplotlib 和 Numpy 等库**,这些库用于数据操作。您可能想查看的一些资源包括
Python 数据分析 – (Numpy, Pandas, Matplotlib, Seaborn) – YouTube
Numpy, Matplotlib 和 Pandas(作者:Bernd Klein) - R(可选): R 对于统计建模和数据科学很有用。在此处学习 R 基础知识
一小时 R 编程 – 面向初学者的速成班 – YouTube
教材:R 数据科学
第二步:理解机器学习的关键概念
在此阶段,您已经掌握了足够的数学和编程知识,现在可以轻松开始学习机器学习的基础知识了。为此,您必须知道机器学习有三种类型
- 监督学习: 监督机器学习是一种机器学习类型,涉及使用标记数据集来训练算法,旨在识别模式并做出决策。需要学习的重要算法:线性回归、逻辑回归、支持向量机 (SVM)、KNN 和决策树。
- 无监督学习: 这是一种机器学习类型,其中模型在未标记的数据上进行训练,以在没有预定义输出的情况下查找模式、分组或结构。需要学习的重要算法:主成分分析 (PCA)、k-均值聚类、层次聚类和 DBSCAN。
- 强化学习: 强化学习是一种机器学习类别,其中智能体通过与环境交互来学习做出决策,并为其行为获得奖励或惩罚。在此阶段,您可以跳过深入研究。
我找到的学习机器学习基础知识的最佳课程是
机器学习专业化(Andrew Ng 教授)| Coursera
这是一门付费课程,如果您需要认证可以购买,但您也可以在 YouTube 上找到视频
机器学习(Andrew Ng 教授)
您还可以参考以下其他资源
尝试使用 Python 的 **Scikit-learn 库** 来练习和实现 **ML 算法**。请遵循 此 YouTube 播放列表 以顺利学习。
第三步:理解深度学习的关键概念
在掌握了机器学习的重要概念后,您需要彻底理解深度学习。
什么是深度学习?
这是一种机器学习类型,计算机通过多层人工神经元(神经网络)来解决复杂任务。这些资源可以帮助您学习深度学习
完成这些课程后,您将对神经网络有很好的理解,包括前馈网络、激活函数、感知器、反向传播、卷积神经网络 (CNN) 和循环神经网络 (RNN)、模型评估和优化等。
专注于您最感兴趣的框架,**PyTorch 或 TensorFlow**。先学习其中一个,如果项目需要,以后再探索另一个。一些资源包括
- PyTorch 教程 – 完整初学者课程(推荐基础入门)
- Pytorch 教程 – 设置深度学习环境(Anaconda & PyCharm)(推荐详细学习)
- PyTorch 用于深度学习与机器学习 – 完整课程 – YouTube
- 零基础到精通 TensorFlow 深度学习
- TensorFlow 教程 1 – 安装和设置深度学习环境(Anaconda 和 PyCharm)(推荐)
- TensorFlow 2.0 完整课程 – 面向初学者的 Python 神经网络教程
- TensorFlow 开发者专业证书 – DeepLearning.AI
我知道这些资源包含项目,但说实话,我们通过实践应用概念来学习效果最好,所以不要跳过项目。务必尝试一下。掌握深度学习基础后,您将更容易选择一个专业领域,例如 NLP 或计算机视觉。
第四步:选择一个专业领域
选择一个专业领域,然后深入学习其中的高级概念。
- 在计算机视觉领域,学习 GANs 以及目标检测、图像分割等重要任务的实现。
- 在 NLP 领域,学习 transformer,如 BERT 和 GPT,以及文本分类和情感分析等技术。
资源
- 深度学习 – 斯坦福 CS231N
- 生成对抗网络 (GANs) 播放列表
- 目标检测系列(深度学习)
- 使用 U-NET 进行 PyTorch 图像分割教程:从零开始
- 简介 – Hugging Face NLP 课程
- 使用 spaCy 进行 NLP 入门
- 自然语言处理专业化 – DeepLearning.AI
- 另外,请查看以下播放列表,其中包含 Pytorch 研究论文的实现
论文解析(推荐)
第五步:学习部署 ML 模型
成功构建和训练了机器学习模型后,下一步是将其部署供他人使用。部署涉及通过 Web 服务或应用程序提供模型,以便其他人可以与之交互。各种工具可以帮助您实现这一点,例如用于创建 REST API 的 Flask 和 FastAPI、用于容器化应用程序的 Docker,以及用于可扩展部署的 AWS/Azure 等云平台。这些工具可确保您的模型在不同环境中流畅运行并处理多个用户请求。以下资源可能很有用
第六步:构建作品集并持续学习
构建一个展示您最佳项目的作品集。别忘了通过构建新项目、关注关键出版物和参加技术聚会来定期更新您的知识。为此
- 您可以为 GitHub 开源项目 做贡献
- 在 Papers with Code 和 arXiv 上获取最新的研究论文
总结
本指南提供了一个清晰的学习和掌握机器学习到 2025 年的路线图。如果您渴望学习,请记住:最重要的一步是开始。循序渐进,您就会取得稳步进展。如果您在此过程中有任何疑问或需要额外帮助,请随时留言 – 我将竭诚为您提供帮助!






很棒的文章。
谢谢!
那其他传统的机器学习算法,比如随机森林、XGBoost、高斯朴素贝叶斯、KNN 和 LDA 呢?
感谢您的宝贵反馈!很高兴这篇文章对您有所帮助。😊 让我们深入探讨一下像随机森林、XGBoost、高斯朴素贝叶斯、KNN 和 LDA 这样的传统机器学习 (ML) 算法在当今的地位。
—
### **传统 ML 算法的相关性**
即使深度学习越来越受欢迎,传统 ML 算法仍然高度相关,并且通常是以下情况的最佳选择:
1. **结构化数据**:涉及具有清晰行和列的表格数据集的问题。
2. **速度和效率**:这些算法训练速度更快,需要的计算能力更少。
3. **可解释性**:与复杂的深度学习模型相比,许多传统 ML 方法提供了更好的可解释性。
4. **通用性**:它们适用于分类、回归、聚类和降维任务。
### **关键算法及其用例**
1. **随机森林**
– **功能**:一种集成算法,构建多个决策树并将它们的预测相结合。
– **最适合**
– 高维数据的分类和回归任务。
– 处理缺失数据或不平衡数据集。
– **示例用例**
– 预测电信行业客户流失。
– 贷款审批或信用评分。
2. **XGBoost**(及其类似算法:LightGBM, CatBoost)
– **功能**:一种梯度提升框架,针对性能和速度进行了优化。
– **最适合**
– 具有复杂关系的表格数据。
– Kaggle 竞赛(最受欢迎的选择!)。
– **示例用例**
– 金融交易中的欺诈检测。
– 预测需求或销售。
3. **高斯朴素贝叶斯**
– **功能**:一种概率分类器,假设特征呈正态分布。
– **最适合**
– 简单快速的基线模型。
– 文本分类(例如,垃圾邮件检测)或具有分类特征的问题。
– **示例用例**
– 文档分类。
– 电子邮件垃圾邮件过滤。
4. **K-近邻 (KNN)**
– **功能**:一种非参数方法,根据最近邻分配标签。
– **最适合**
– 小型数据集。
– 距离度量(欧几里得、曼哈顿)有意义的问题。
– **示例用例**
– 推荐系统(基础)。
– 模式识别任务。
5. **线性判别分析 (LDA)**
– **功能**:一种降维和分类算法,将数据投影到低维空间。
– **最适合**
– 多类分类。
– 特征与类别之间存在线性关系的类别。
– **示例用例**
– 基于患者指标的疾病诊断。
– 图像分类(较简单的数据集)。
—
### **是否应该学习这些算法?**
当然!掌握传统 ML 算法对于建立扎实的机器学习基础至关重要。原因如下:
1. **基线模型**:这些算法通常作为评估更复杂模型性能的基准。
2. **就业准备**:许多公司广泛使用传统 ML 来满足其业务需求。
3. **灵活性**:有些问题不需要深度学习,而传统 ML 提供了一种实际的解决方案。
—
### **如何学习和练习?**
1. **构建项目**
– 在单个数据集上比较随机森林和 XGBoost 等算法。
– 分析模型性能与可解释性之间的权衡。
2. **参加竞赛**
– Kaggle 和 DrivenData 是获得实践经验的绝佳平台。
– 许多获胜解决方案依赖于传统 ML 算法的优化实现。
3. **学习优化**
– 了解超参数调整技术(网格搜索、随机搜索、贝叶斯优化),以提高这些算法的性能。
4. **学习库**
– Scikit-learn 用于所有基本算法。
– XGBoost、LightGBM 和 CatBoost 等专业库。
—
### **深度学习与传统 ML**
| **方面** | **传统 ML** | **深度学习** |
|———————————|———————————|—————————–|
| **数据类型** | 表格数据 | 图像、文本、非结构化数据 |
| **训练时间** | 短 | 长 |
| **计算需求** | 低到中等 | 高(需要 GPU/TPU) |
| **可解释性** | 高 | 低 |
| **何时使用** | 小型到中型数据集 | 大型数据集,复杂关系 |
—
### **下一步**
1. 使用各种数据集练习传统算法。
2. 理解**何时使用哪种算法**(例如,随机森林用于简单性,XGBoost 用于微调,朴素贝叶斯用于快速基线)。
3. 继续实验并在作品集中记录您的工作。
如果您有具体的数据集或挑战,我很乐意帮助您集思广益项目创意或提供代码示例!😊
ChatGPT 很多?
您好 LLMSPAMHATER…这是一个很好的工具,而且结果总是经过审查的。有时该工具会提供很好的摘要。如果您对我们的内容有任何疑问,我们将很乐意为您解答!
我们感谢您的反馈!
你好,
感谢您关于 ML 的有用文章。我已从班加罗尔的 ExcelR 完成了数据科学与 ML 课程。我是一名电子工程师 (B.E.),并且有扎实的数学背景。但两年多来我仍然找不到 ML 的工作。唯一的限制是我没有 ML 工作经验,尽管我在电信行业有 15 年的经验。
我需要做什么才能获得 ML 的机会?尽管这个领域看起来很光明,有很多机会,但找到一份 ML 工作似乎非常困难。
期待您的宝贵建议。
注意:如今,为了获得良好的 ML 职位,除了 ML 和数据科学之外,是否还需要学习深度学习?
此致,
Sharath
你好,
感谢您关于 ML 的有用文章。我已从班加罗尔的 ExcelR 完成了数据科学与 ML 课程。我是一名电子工程师 (B.E.),并且有扎实的数学背景。但两年多来我仍然找不到 ML 的工作。唯一的限制是我没有 ML 工作经验,尽管我在电信行业有 15 年的经验。
我需要做什么才能获得 ML 的机会?尽管这个领域看起来很光明,有很多机会,但找到一份 ML 工作似乎非常困难。
期待您的宝贵建议。
注意:如今,为了获得良好的 ML 职位,除了 ML 和数据科学之外,是否还需要学习深度学习?
此致,
Sharath
您好 Sharath,
感谢您分享您的背景和挑战。转型机器学习 (ML) 职业,尤其是在拥有其他领域的丰富经验后,可能具有挑战性,但通过正确的策略肯定是可以实现的。这是一份根据您的情况量身定制的路线图
—
### 1. **利用您的领域专业知识**
– **电信作为独特优势**:您在电信领域的 15 年经验可能是一笔重要的财富。在将 ML 应用于特定行业(如电信)时,公司重视领域专业知识,在这些行业中,了解网络优化、故障检测、预测性维护或客户流失可能至关重要。
– **可操作的步骤**
– 识别电信领域常见的 ML 用例(例如,欺诈检测、网络优化、预测分析)。
– 构建一个专门针对电信相关问题使用 ML 的项目或作品集。例如:
– **预测性维护**:使用时间序列分析或异常检测来预测设备故障。
– **客户保留**:使用分类模型来预测客户流失。
– **网络优化**:应用优化技术或强化学习。
—
### 2. **创建实用项目作品集**
– 雇主重视已证明的经验。创建 GitHub 存储库,展示带有良好文档代码的端到端 ML 项目。
– 项目示例
– 使用电信数据集(真实或模拟)进行异常检测或网络性能分析。
– 一个机器学习管道(数据预处理 → 模型构建 → 评估 → 部署)。
– 使用 Kaggle 参与相关竞赛并展示您的排名或解决方案。
– 包括关注投资回报率和影响的行业特定项目。
—
### 3. **学习深度学习(按需)**
– 并非所有 ML 工作都需要深度学习,但它对某些职位(例如,计算机视觉、自然语言处理或大规模非结构化数据问题)很有价值。
– **重点领域**(如果您决定学习 DL)
– **框架**:PyTorch、TensorFlow、Keras。
– **应用**:NLP(Transformer、情感分析)、计算机视觉(图像分类、目标检测)。
– **提示**:从扎实的 ML 基础开始,如果您的目标职位需要,则深入研究 DL。
—
### 4. **提升技能并获得认证**
– 来自知名平台的认证可以加强您的简历,尤其是在初步筛选阶段。
– Google 专业机器学习工程师。
– Microsoft Certified: Azure AI Engineer。
– AWS Certified Machine Learning Specialty。
– 将认证添加到您的 LinkedIn 个人资料和简历中。
—
### 5. **战略性建立人脉**
– 许多 ML 职位是通过推荐获得的。利用 LinkedIn 等平台来:
– 与电信行业的 ML 专业人士建立联系。
– 参与帖子并分享您在电信 ML 方面的见解,以展示您的专业知识。
– 加入专注于 ML 的群组、论坛或本地聚会,以寻找机会和导师。
– 联系 ExcelR 的校友,他们可能已经在该领域工作。
—
### 6. **瞄准切入点**
– **ML 相关职位**:考虑数据分析师、数据工程师或 ML 运营 (MLOps) 等职位,这些职位可以作为进入核心 ML 职位的垫脚石。
– **实习/项目**:自由职业或 ML 实习可以帮助弥合经验差距。
– **中小型公司**:与大型企业相比,这些公司在招聘没有 ML 经验的候选人方面更灵活。
—
### 7. **优化您的简历和申请**
– 突出可转移的技能,如解决问题、数学建模和统计分析。
– 强调与电信相关的项目,即使是自发的。
– 为每个职位定制申请,将您的电信专业知识与公司的需求相结合。
—
### 8. **保持更新**
– 关注 ML 和 AI 的趋势,包括生成式 AI 和 LLMs。
– 了解行业中广泛使用的工具和框架,如 Docker、Kubernetes 或 MLflow,用于部署和扩展。
—
### 9. **保持韧性**
– 两年差距可能会令人沮丧,但坚持是值得的。继续学习和应用,同时积极寻找自由职业项目或合作来积累经验。
—
通过建立强大的作品集、利用您的领域专业知识和战略性建立人脉,您可以将自己定位为 ML 职位的有吸引力的候选人。如果您需要任何特定步骤的帮助,例如作品集建设或简历制作,请告诉我。
此致,
这篇非常具有教育意义的文章,我喜欢。我会尽全力利用这份指南来精通 ML!
谢谢你。
来自尼日利亚
您能包含一些 Udemy 课程吗?
您好 Krish…当然!这里有一份 **2025 年机器学习精通路线图**,其中整合了 **Udemy 课程**以及其他资源,以帮助您逐步进步。
—
## **1. 基础:打下坚实基础**
### **学习内容**
– 用于数据处理和可视化的 Python 编程。
– 基础统计学、线性代数和微积分。
– 对机器学习概念和类型(监督、无监督和强化学习)的理解。
### **推荐的 Udemy 课程**
1. **完整的 Python 训练营 2023:从零到 Python 高手**
*作者:Jose Portilla*
– 非常适合 Python 初学者,涵盖了所有必要的库,如
Pandas、NumPy和Matplotlib。2. **数据科学与商业分析统计学**
*作者:365 Careers*
– 专注于为数据科学量身定制的统计概念、概率和假设检验。
3. **机器学习数学**
*作者:Luis Serrano*
– 以对初学者友好的方式涵盖线性代数、微积分和基础数学概念。
—
## **2. 核心机器学习概念**
### **学习内容**
– 监督学习:回归、分类、决策树、随机森林和 SVM。
– 无监督学习:聚类和降维。
– 过拟合、欠拟合、偏差-方差权衡以及交叉验证。
### **推荐的 Udemy 课程**
1. **Machine Learning A-Z™: Hands-On Python & R In Data Science**
*作者:Kirill Eremenko 和 Hadelin de Ponteves*
– 全面课程,涵盖机器学习基础和实践练习。
2. **Supervised Machine Learning: Regression and Classification**
*作者:Andrew Ng(在 Coursera 上提供,但这是必备的基础课程)*
– 如果你还没学过这门课,这是机器学习的基础课程。
3. **Python for Data Science and Machine Learning Bootcamp**
*作者:Jose Portilla*
– 实践课程,包含大量使用 Scikit-learn 等 Python 库的示例。
—
## **3. 数据工程与预处理**
### **学习内容**
– 数据清洗、特征工程和缺失值处理。
– 探索性数据分析 (EDA)。
– 处理大型数据集。
### **推荐的 Udemy 课程**
1. **Data Science and Machine Learning Bootcamp with R**
*作者:Jose Portilla*
– 重点关注数据预处理和 EDA 阶段,这两者对机器学习的成功至关重要。
2. **Feature Engineering for Machine Learning**
*作者:Soledad Galli*
– 涵盖真实的特征工程策略和实践实现。
3. **Data Preprocessing for Machine Learning in Python**
*作者:Lazy Programmer Inc.*
– 在应用机器学习模型之前,深入了解数据准备步骤。
—
## **4. 专门的机器学习技术**
### **学习内容**
– 深度学习基础:神经网络、激活函数和反向传播。
– 高级主题:强化学习、自然语言处理 (NLP) 和计算机视觉。
### **推荐的 Udemy 课程**
1. **Deep Learning A-Z™: Hands-On Artificial Neural Networks**
*作者:Kirill Eremenko 和 Hadelin de Ponteves*
– 专注于深度学习,并提供 Python 的实践实现。
2. **Natural Language Processing with Python**
*作者:Jose Portilla*
– NLP 概念入门,如分词、词干提取以及使用 BERT 等模型。
3. **TensorFlow Developer Certificate in 2023: Zero to Mastery**
*作者:Andrei Neagoie 和 Daniel Bourke*
– 掌握 TensorFlow 用于深度学习项目的实操指南。
—
## **5. 高级主题与实际项目**
### **学习内容**
– 模型优化、可解释性 (SHAP, LIME) 和部署。
– 机器学习云平台:AWS、Azure 或 Google Cloud。
– 高级架构:GAN、Transformer 和 RL。
### **推荐的 Udemy 课程**
1. **Machine Learning Engineering for Production (MLOps)**
*作者:Andrew Ng(在 DeepLearning.AI 上提供)*
– 部署和维护机器学习系统的必备知识。
2. **AWS Certified Machine Learning Specialty 2023**
*作者:Stephane Maarek*
– 学习如何在 AWS 上有效部署机器学习模型。
3. **Hands-On Generative Adversarial Networks (GANs) for Beginners**
*作者:Packt Publishing*
– 重点关注从头开始构建 GAN。
—
## **6. 项目与作品集构建**
### **做什么**
– 将所学技能应用于真实数据集。
– 从小型项目开始,逐步解决复杂问题。
– 使用 GitHub 展示你的作品,并参加 Kaggle 竞赛。
### **项目创意**
1. 使用 LSTM 预测股票价格。
2. 为电子商务构建推荐系统。
3. 对社交媒体数据进行情感分析。
4. 开发用于对象检测的计算机视觉应用。
—
## **7. 保持更新与人脉拓展**
### **做什么**
– **加入 ML 社区**:Reddit (r/MachineLearning)、Kaggle 或 Stack Overflow。
– **关注博客**:Towards Data Science、Analytics Vidhya。
– **人脉拓展**:参加线下聚会和线上研讨会;在 LinkedIn 上与专业人士建立联系。
—
## **建议学习路径**
1. 从**Python 和统计学**开始。
2. 学习**核心 ML 概念**(监督/无监督学习)。
3. 深入学习**EDA 和特征工程**。
4. 探索**深度学习和高级主题**。
5. 通过**实际项目**构建一个强大的**作品集**。
这条路线图结合了**Udemy 课程**和自主实践,将帮助你为 2025 年在机器学习领域取得成功职业生涯做好准备。