运行 Python 脚本是开发过程中重要的一步,因为这样才能知道你的代码是否如你所愿地运行。此外,我们通常需要将信息传递给 Python 脚本才能使其正常工作。
在本教程中,您将了解运行和传递信息给 Python 脚本的各种方法。
完成本教程后,您将了解:
- 如何使用命令行界面、Jupyter Notebook 或集成开发环境 (IDE) 运行 Python 脚本
- 如何通过硬编码 Jupyter Notebook 中的输入变量,或通过交互式使用 sys.argv 命令,或通过交互式使用 input() 函数将信息传递给 Python 脚本。
使用我的新书《Python for Machine Learning》快速启动您的项目,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
运行并向Python脚本传递信息
照片由 Andrea Leopardi 拍摄,保留部分权利。
教程概述
本教程分为两部分;它们是
- 运行 Python 脚本
- 使用命令行界面
- 使用 Jupyter Notebook
- 使用集成开发环境 (IDE)
- Python 输入
运行 Python 脚本
使用命令行界面
命令行界面广泛用于运行 Python 代码。
让我们通过首先打开命令提示符或终端窗口(取决于您正在使用的操作系统)来测试一些命令。
在命令行界面中键入 python 命令将启动 Python 交互式会话。您将看到一条消息,通知您正在使用的 Python 版本。
|
1 2 3 |
Python 3.7.4 (default, Aug 13 2019, 15:17:50) [Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin 输入“help”、“copyright”、“credits”或“license”以获取更多信息。 |
在交互式会话期间,您在命令行界面中输入的任何语句都将立即执行。例如,输入 2 + 3 将返回 5
|
1 |
2 + 3 |
|
1 |
5 |
以这种方式使用交互式会话有其优点,因为您可以轻松快速地测试 Python 代码行。但是,如果您更感兴趣于编写较长的程序,例如开发机器学习算法,那么它并不是理想的选择。一旦交互式会话终止,代码也会消失。
另一种选择是运行 Python 脚本。让我们先从一个简单的例子开始。
在文本编辑器(如 Notepad++、Visual Studio Code 或 Sublime Text)中,键入语句 print("Hello World!") 并将文件保存为 *test_script.py* 或您选择的任何其他名称,只要包含 *.py* 扩展名即可。
现在,回到您的命令行界面,键入 python 命令,后跟您的脚本文件名。在执行此操作之前,您可能需要更改路径以指向包含脚本文件的目录。运行脚本文件后应产生以下输出:
|
1 |
python test_script.py |
|
1 |
Hello World! |
现在,让我们编写一个脚本文件,该文件加载一个预训练的 Keras 模型,并为这张狗的图片输出预测。通常,我们还需要以命令行 *参数* 的形式将信息传递给 Python 脚本。为此,我们将使用 sys.argv 命令将图像路径和要返回的前 N 个预测数量传递给脚本。我们可以有任意数量的输入参数,具体取决于代码的需求,在这种情况下,我们将继续从参数列表中读取输入。
我们将要运行的脚本文件包含以下代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import sys import numpy as np from tensorflow.keras.applications import vgg16 from tensorflow.keras.applications.vgg16 import preprocess_input, decode_predictions from tensorflow.keras.preprocessing import image # 加载在 ImageNet 数据集上预训练的 VGG16 模型 vgg16_model = vgg16.VGG16(weights='imagenet') # 读取调用脚本时传递给解释器的命令行参数 image_path = sys.argv[1] top_guesses = sys.argv[2] # 加载图像,根据模型目标尺寸进行调整 img_resized = image.load_img(image_path, target_size=(224, 224)) # 将图像转换为数组 img = image.img_to_array(img_resized) # 添加一个维度 img = np.expand_dims(img, axis=0) # 缩放像素强度值 img = preprocess_input(img) # 为测试图像生成预测 pred_vgg = vgg16_model.predict(img) # 解码并打印前 3 个预测 print('Prediction:', decode_predictions(pred_vgg, top=int(top_guesses))) |
在上面的代码中,我们使用 `sys.argv[1]` 和 `sys.argv[2]` 读取了前两个命令行参数。我们可以通过使用 `python` 命令,后跟脚本文件名,然后传递图像路径(在图像保存到磁盘后)和我们希望预测的前 N 个预测数量作为参数来运行脚本。
|
1 |
python pretrained_model.py dog.jpg 3 |
这里,*pretrained_model.py* 是脚本文件名,*dog.jpg* 图片已保存到与 Python 脚本相同的目录中。
生成的三个最高预测如下:
|
1 |
Prediction: [[('n02088364', 'beagle', 0.6751468), ('n02089867', 'Walker_hound', 0.1394801), ('n02089973', 'English_foxhound', 0.057901423)]] |
但是命令行中还可以有更多选项。例如,以下命令将以“优化”模式运行脚本,在这种模式下,调试变量 `__debug__` 被设置为 `False`,并且会跳过 `assert` 语句。
|
1 |
python -O test_script.py |
以下是使用 Python 模块(如调试器)启动脚本:
|
1 |
python -m pdb test_script.py |
我们将在另一篇文章中讨论调试器和性能分析器的使用。
使用 Jupyter Notebook
从命令行界面运行 Python 脚本是一个简单直接的选项,前提是您的代码主要生成字符串输出。
但是,当我们处理图像时,通常也希望生成视觉输出。我们可能需要检查输入图像在被馈送到神经网络之前应用的任何预处理的正确性,或者可视化神经网络产生的输出。Jupyter Notebook 提供了一个交互式计算环境,可以帮助我们实现这一点。
通过 Jupyter Notebook 界面运行 Python 脚本的一种方法是将代码添加到 Notebook 的“单元格”中。但这表示您的代码会保留在 Jupyter Notebook 中,无法在其他地方访问,例如像上面那样使用命令行。另一种方法是使用 `%` 前缀的 `run` magic 命令。尝试在 Jupyter Notebook 的单元格中键入以下代码:
|
1 |
%run pretrained_model.py dog.jpg 3 |
在这里,我们再次将 Python 脚本文件名指定为 *pretrained_model.py*,后跟图像路径和最高预测数量作为输入参数。您将看到最高的三项预测会显示在产生此结果的单元格下方。
现在,假设我们想显示输入图像,以检查它是否已根据模型的目标尺寸正确加载。为此,我们将稍微修改代码,如下所示,并将其保存到一个新的 Python 脚本 *pretrained_model_image.py* 中:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import sys import numpy as np import matplotlib.pyplot as plt from tensorflow.keras.applications import vgg16 from tensorflow.keras.applications.vgg16 import preprocess_input, decode_predictions from tensorflow.keras.preprocessing import image # 加载在 ImageNet 数据集上预训练的 VGG16 模型 vgg16_model = vgg16.VGG16(weights='imagenet') # 读取调用脚本时传递给解释器的参数 image_path = sys.argv[1] top_guesses = sys.argv[2] # 加载图像,根据模型目标尺寸进行调整 img_resized = image.load_img(image_path, target_size=(224, 224)) # 将图像转换为数组 img = image.img_to_array(img_resized) # 显示图像以检查是否已正确调整大小 plt.imshow(img.astype(np.uint8)) # 添加一个维度 img = np.expand_dims(img, axis=0) # 缩放像素强度值 img = preprocess_input(img) # 为测试图像生成预测 pred_vgg = vgg16_model.predict(img) # 解码并打印前 3 个预测 print('Prediction:', decode_predictions(pred_vgg, top=int(top_guesses))) |
通过 Jupyter Notebook 界面运行新保存的 Python 脚本现在将显示调整大小后的 $224 \times 224$ 像素图像,并打印前三个预测。
|
1 |
%run pretrained_model_image.py dog.jpg 3 |
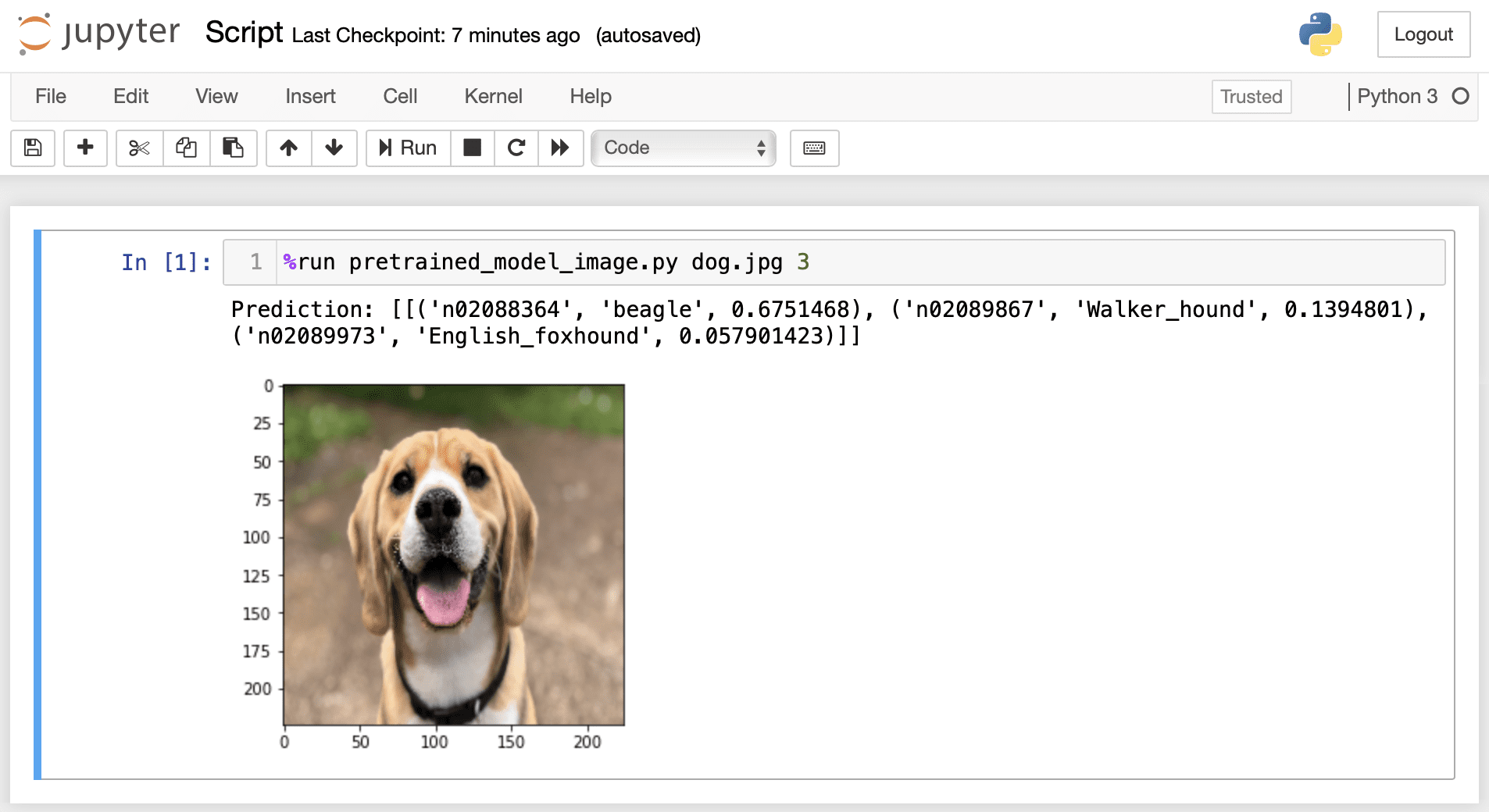
在 Jupyter Notebook 中运行 Python 脚本
或者,我们可以将代码精简为以下内容(并将其保存到另一个 Python 脚本 *pretrained_model_inputs.py*):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# 加载在 ImageNet 数据集上预训练的 VGG16 模型 vgg16_model = vgg16.VGG16(weights='imagenet') # 加载图像,根据模型目标尺寸进行调整 img_resized = image.load_img(image_path, target_size=(224, 224)) # 将图像转换为数组 img = image.img_to_array(img_resized) # 显示图像以检查是否已正确调整大小 plt.imshow(img.astype(np.uint8)) # 添加一个维度 img = np.expand_dims(img, axis=0) # 缩放像素强度值 img = preprocess_input(img) # 为测试图像生成预测 pred_vgg = vgg16_model.predict(img) # 解码并打印前 3 个预测 print('Prediction:', decode_predictions(pred_vgg, top=top_guesses)) |
并在 Jupyter Notebook 自身的某个单元格中定义输入变量。以这种方式运行 Python 脚本需要我们也在 `%run` magic 命令后使用 `-i` 选项:
|
1 |
%run -i pretrained_model_inputs.py |
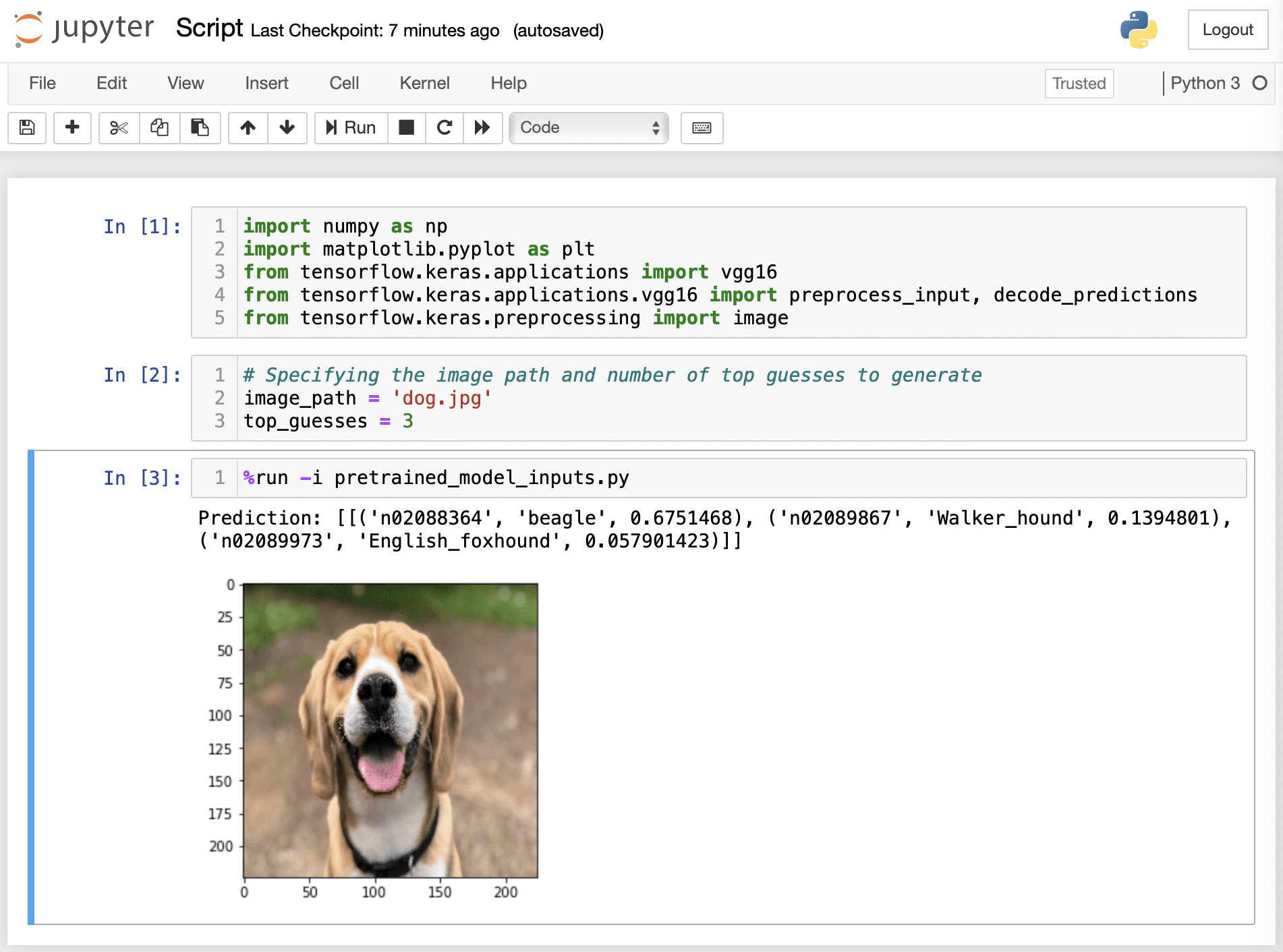
在 Jupyter Notebook 中运行 Python 脚本
这样做的优点是可以更轻松地访问可以在 Jupyter Notebook 中交互式定义的 Python 脚本中的变量。
随着您的代码不断增长,结合使用文本编辑器和 Jupyter Notebook 可以提供一种便捷的方式:文本编辑器可用于创建 Python 脚本,这些脚本存储可重用的代码,而 Jupyter Notebook 则提供了一个交互式计算环境,便于进行数据探索。
想开始学习机器学习 Python 吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
使用集成开发环境 (IDE)
另一种选择是从 IDE 运行 Python 脚本。这需要先创建一个项目,然后将带有 *.py* 扩展名的 Python 脚本添加到项目中。
如果我们选择 PyCharm 或 Visual Studio Code 作为 IDE,就需要创建一个新项目,然后选择我们要使用的 Python 解释器版本。将 Python 脚本添加到新创建的项目后,就可以运行它来生成输出。下图是我们在 macOS 上运行 Visual Studio Code 的屏幕截图。根据 IDE 的不同,应该有一个选项可以选择是否使用调试器运行代码。
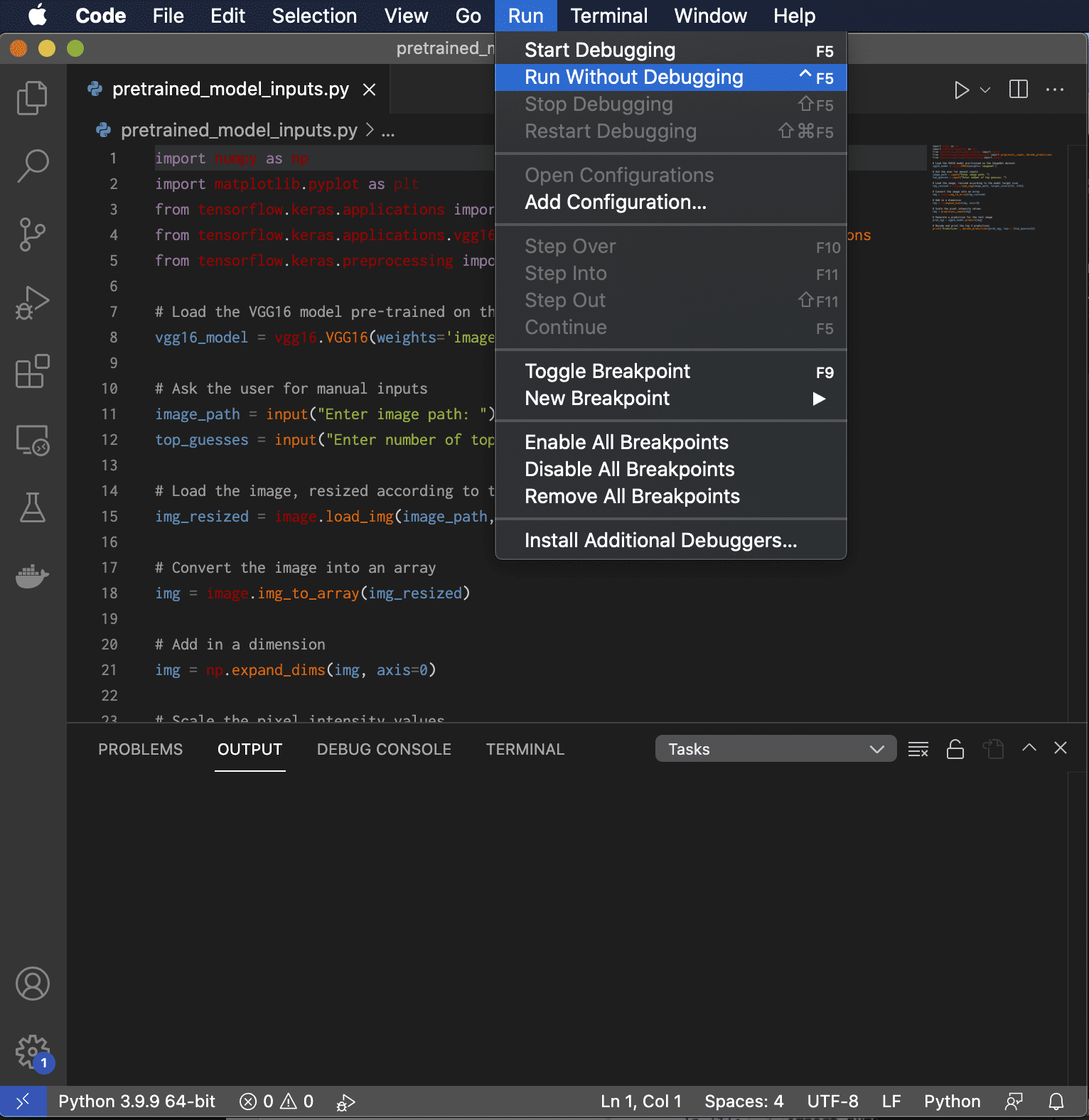
Python 输入
到目前为止,我们已经考虑了使用 `sys.argv` 命令或在运行脚本之前在 Jupyter Notebook 中硬编码输入变量来将信息传递给 Python 脚本的选项。
另一种选择是通过 `input()` 函数从用户那里获取输入。
考虑以下代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import numpy as np import matplotlib.pyplot as plt from tensorflow.keras.applications import vgg16 from tensorflow.keras.applications.vgg16 import preprocess_input, decode_predictions from tensorflow.keras.preprocessing import image # 加载在 ImageNet 数据集上预训练的 VGG16 模型 vgg16_model = vgg16.VGG16(weights='imagenet') # 要求用户手动输入 image_path = input("Enter image path: ") top_guesses = input("Enter number of top guesses: ") # 加载图像,根据模型目标尺寸进行调整 img_resized = image.load_img(image_path, target_size=(224, 224)) # 将图像转换为数组 img = image.img_to_array(img_resized) # 添加一个维度 img = np.expand_dims(img, axis=0) # 缩放像素强度值 img = preprocess_input(img) # 为测试图像生成预测 pred_vgg = vgg16_model.predict(img) # 解码并打印前 3 个预测 print('Prediction:', decode_predictions(pred_vgg, top=int(top_guesses))) |
在这里,系统会提示用户手动输入图像路径(图像已保存到包含 Python 脚本的同一目录中,因此仅指定图像名称即可)以及要生成的最高预测数量。两个输入值都是字符串类型;但是,在稍后使用最高预测数量时,会将其转换为整数。
无论是在命令行界面、Jupyter Notebook 还是 Python IDE 中运行此代码,它都会提示用户输入所需信息,然后生成用户请求的预测数量。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
书籍
- Python 基础知识, 2018.
- Python 机器学习蓝图, 2019.
总结
在本教程中,您了解了运行和传递信息给 Python 脚本的各种方法。
具体来说,你学到了:
- 如何使用命令行界面、Jupyter Notebook 或集成开发环境 (IDE) 运行 Python 脚本
- 如何通过 `sys.argv` 命令,或通过在 Jupyter Notebook 中硬编码输入变量,或通过交互式使用 `input()` 函数将信息传递给 Python 脚本。
你有什么问题吗?
在下面的评论中提出您的问题,我将尽力回答。
掌握机器学习 Python!

更自信地用 Python 编写代码
...从学习实用的 Python 技巧开始
在我的新电子书中探索如何实现
用于机器学习的 Python
它提供自学教程和数百个可运行的代码,为您提供包括以下技能:
调试、性能分析、鸭子类型、装饰器、部署等等...





 in Keras")
感谢本教程。它为我提供了一种理解如何为模型提供输入的方法。对那些通过示例学习的人来说很有帮助。
感谢您的反馈,Paul!祝您一切顺利!