自回归积分移动平均模型,简称ARIMA,是一种用于时间序列分析和预测的流行线性模型。
statsmodels库提供了ARIMA在Python中的实现。ARIMA模型可以保存到文件中,以便以后在新数据上进行预测。statsmodels库的当前版本存在一个bug,阻止了已保存模型的加载。
在本教程中,您将了解如何诊断和解决此问题。
快速开始您的项目,阅读我的新书《Python时间序列预测》,其中包含分步教程和所有示例的Python源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。
- 2019年8月更新:更新了数据加载以使用新的API。
注意:本教程中讨论的bug似乎
已在statsmodels 0.12.1版本中修复。

如何在 Python 中保存 ARIMA 时间序列预测模型
照片由Les Chatfield拍摄,保留部分权利。
每日女性出生数据集
首先,让我们看一下可用于理解statsmodels ARIMA实现问题的标准时间序列数据集。
这个“每日女性出生”数据集描述了1959年加州每日新生女婴的数量。
单位是计数,共有 365 个观测值。数据集的来源归功于 Newton (1988)。
下载数据集并将其放在您当前的工作目录中,文件名为“_daily-total-female-births.csv_”。
下面的代码片段将加载并绘制数据集。
|
1 2 3 4 5 |
from pandas import read_csv from matplotlib import pyplot series = read_csv('daily-total-female-births.csv', header=0, index_col=0)) series.plot() pyplot.show() |
运行示例将数据集加载为Pandas Series,然后显示数据的折线图。
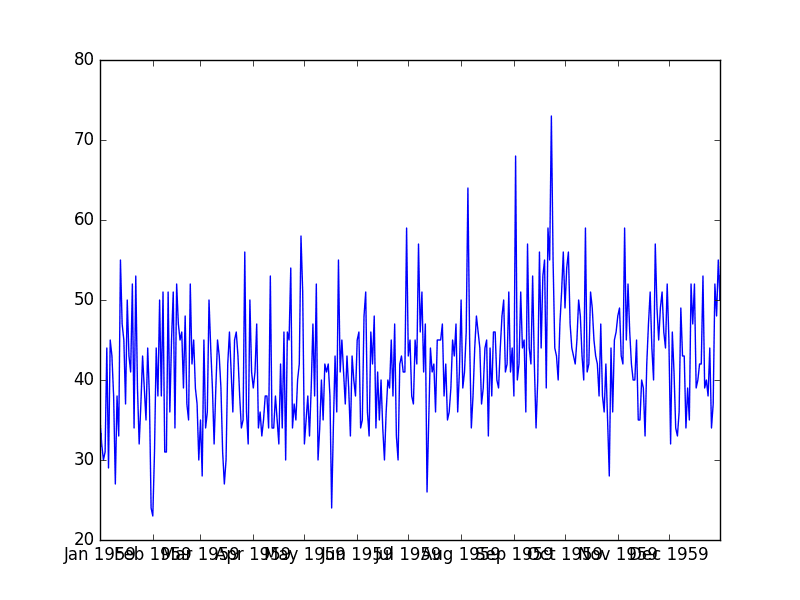
每日女性出生总数图
停止以**慢速**学习时间序列预测!
参加我的免费7天电子邮件课程,了解如何入门(附带示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
Python 环境
确认您使用的是最新版本的statsmodels库。
您可以通过运行下面的脚本来完成此操作
|
1 2 |
import statsmodels print('statsmodels: %s' % statsmodels.__version__) |
运行脚本应该会产生一个显示statsmodels 0.6或0.6.1的结果。
|
1 |
statsmodels: 0.6.1 |
您可以使用Python 2或3。
注意:本教程中讨论的bug似乎
已在statsmodels 0.12.1版本中修复。
ARIMA模型保存bug
我们可以轻松地在每日女性出生数据集上训练ARIMA模型。
下面的代码片段在数据集上训练了一个ARIMA(1,1,1)。
model.fit()函数返回一个ARIMAResults对象,我们可以在该对象上调用save()将模型保存到文件,然后调用load()在以后加载它。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from pandas import read_csv from statsmodels.tsa.arima_model import ARIMA from statsmodels.tsa.arima_model import ARIMAResults # 加载数据 series = read_csv('daily-total-female-births.csv', header=0, index_col=0)) # 准备数据 X = series.values X = X.astype('float32') # 拟合模型 model = ARIMA(X, order=(1,1,1)) model_fit = model.fit() # 保存模型 model_fit.save('model.pkl') # 加载模型 loaded = ARIMAResults.load('model.pkl') |
运行此示例将训练模型并将其保存到文件,没有问题。
当您尝试从文件加载模型时,将报告一个错误。
|
1 2 3 4 5 6 7 8 |
回溯(最近一次调用) File "...", line 16, in <module> loaded = ARIMAResults.load('model.pkl') File ".../site-packages/statsmodels/base/model.py", line 1529, in load return load_pickle(fname) File ".../site-packages/statsmodels/iolib/smpickle.py", line 41, in load_pickle return cPickle.load(fin) TypeError: __new__() takes at least 3 arguments (1 given) |
具体来说,请注意这一行
|
1 |
TypeError: __new__() takes at least 3 arguments (1 given) |
到目前为止一切顺利,那么我们如何解决呢?
ARIMA模型保存bug的解决方法
Zae Myung Kim于2016年9月发现了此bug并报告了此故障。
您可以在此处阅读所有相关信息
该bug的发生是因为statsmodels中尚未定义Python对象序列化库pickle所需的一个函数。
在保存ARIMA模型之前,必须在其模型中定义一个__getnewargs__函数,该函数定义了构建对象所需的参数。
我们可以解决这个问题。修复涉及两件事:
- 定义一个适合ARIMA对象的__getnewargs__函数的实现。
- 将新函数添加到ARIMA。
值得庆幸的是,Zae Myung Kim在他的bug报告中提供了一个函数示例,因此我们可以直接使用它。
|
1 2 |
def __getnewargs__(self): return ((self.endog),(self.k_lags, self.k_diff, self.k_ma)) |
Python允许我们猴子补丁(monkey patch)一个对象,即使是来自statsmodels这样的库的对象。
我们可以通过赋值来定义现有对象上的一个新函数。
我们可以像下面这样为ARIMA对象上的__getnewargs__函数做到这一点:
|
1 |
ARIMA.__getnewargs__ = __getnewargs__ |
下面列出了使用猴子补丁在Python中训练、保存和加载ARIMA模型的完整示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from pandas import read_csv from statsmodels.tsa.arima_model import ARIMA from statsmodels.tsa.arima_model import ARIMAResults # monkey patch around bug in ARIMA class def __getnewargs__(self): return ((self.endog),(self.k_lags, self.k_diff, self.k_ma)) ARIMA.__getnewargs__ = __getnewargs__ # 加载数据 series = read_csv('daily-total-female-births.csv', header=0, index_col=0)) # 准备数据 X = series.values X = X.astype('float32') # 拟合模型 model = ARIMA(X, order=(1,1,1)) model_fit = model.fit() # 保存模型 model_fit.save('model.pkl') # 加载模型 loaded = ARIMAResults.load('model.pkl') |
现在运行示例,模型将被成功加载,而不会出错。
总结
在本篇文章中,您了解了如何解决statsmodels ARIMA实现中导致ARIMA模型无法保存和加载到文件的问题。
您了解了如何编写猴子补丁来解决该bug,以及如何证明该bug确实已被修复。
您是否在您的项目中使用过此解决方法?
Let me know about it in the comments below.
想用Python开发时间序列预测吗?

几分钟内开发您自己的预测
...只需几行python代码在我的新电子书中探索如何实现
Python 时间序列预测入门
它涵盖了**自学教程**和**端到端项目**,主题包括:*数据加载、可视化、建模、算法调优*等等。
最终将时间序列预测带入
您自己的项目
跳过学术理论。只看结果。






Jason您好,感谢您的解决方法。
我正在使用statsmodels 0.8.0,并一直尝试使用pickle本身(即不使用内置方法)来保存拟合模型的字典。我仍然遇到您上面提到的关于ARIMA对象没有dates属性的错误。为什么它会试图查找一个`dates`属性呢?
您能想到一个针对这种情况的解决方法吗?
您试过这个解决方法吗?
布朗利博士,您好,
感谢您的分享。我尝试调整此解决方法,使其适用于季节性ARIMA建模,但我仍然遇到问题。我想将模型保存到pickle文件中,但我一直收到以下错误:“Type error: can’t pickle statsmodels.tsa.statespace._statespace.dStatespace objects”
您对此有什么想法吗?我正在使用以下代码。
mod = sm.tsa.statespace.SARIMAX(
timeseries,
order=(1, 0, 1),
seasonal_order=(0, 1, 1, 28),
enforce_stationarity=False,
enforce_invertibility=False
)
self.trained_model = mod.fit()
self.trained_model.save(‘call model.p’)
谢谢!
抱歉,我没试过。
也许可以联系发现此解决方法的开发者,他可能对SARIMAX有一些想法。
Veeral您好,
您是否找到了解决您问题的方法?我也遇到了SARIMA模型的相同问题。
大家好,
我也遇到了SARIMAX模型同样的问题;有人找到解决方案了吗?
嗨,Jason,
感谢这篇文章。
我正在使用ARIMA拟合值并将其保存为pickle文件。之后,pickle文件用于进行样本外预测。但是,在进行样本外预测时,我遇到了以下错误:Cannot cast ufunc subtract output from dtype(‘float64’) to dtype(‘int64’) with casting rule ‘same_kind’。您对此原因有任何想法吗?
抱歉,我没见过这个。
也许可以尝试发布到 stackoverflow?
Jason您好,感谢这篇精彩的文章!我按照这个方法保存了一个具有特定ARIMA阶数的pickle文件。模型已成功拟合并保存为pickle文件。但是,当我加载pickle文件以获取样本外预测时,任何步数的预测值都为null。您对此问题有什么想法吗?
基本上,在拟合模型后,model_fit.summary()会抛出错误。我知道这不是一个代码解决问题的平台,但我认为如果模型摘要在拟合模型后抛出错误,这是一个非常普遍的情况!
这很奇怪。也许注释掉那一行?
抱歉,我没见过这个问题。也许可以确保您使用的是最新版本的Statsmodels?
Jason,问题是,在读取pickle文件后,样本外预测会产生null值。我认为这可能是一个bug,我会尝试在Git上报告。谢谢。
这是一种形状。
我在博客中有一些示例,可以直接使用系数,而无需包装类。也许那将是一个好的解决方法?
你好,杰森,
感谢您的文章,我使用statsmodels 0.9.0,没有这种bug。
很高兴听到这个消息!
你好 Jason,
您了解Azure ML管道吗?那里有一个名为“create python model”的模块。但我不知道它如何工作以及如何传递参数。先谢谢了!
抱歉,我从未使用过MS平台。
您好,感谢您的精彩帖子。但我对如何使用加载的模型来预测特征感到困惑。例如,我在此提供代码(可能也取自您的某个教程,因为我正在通过您的资源学习所有这些东西)
Actual = [x for x in train_set]
Predictions = list()
#调用ARIMA模型来拟合和预测数据的函数
def StartARIMAForecasting(Actual, P, D, Q)
model = ARIMA(Actual, order=(P, D, Q))
model_fit = model.fit(disp=0)
prediction = model_fit.forecast()[0]
return prediction
for timepoint in range(len(test_set))
ActualValue = test_set[timepoint]
#预测值
Prediction = StartARIMAForecasting(Actual, 2,1,2)
print(‘Actual=%f, Predicted=%f’ % (ActualValue, Prediction))
#添加到列表中
Predictions.append(Prediction)
Actual.append(ActualValue)
现在,我可以在哪里写代码来保存模型,在保存和加载之后,正确的预测代码行是什么?我非常期待得到解决方案。🙂
注意:在我的数据集中,我使用了datetime作为索引。
好问题。
模型在拟合后保存。然后可以加载它来做出预测。
也许这会有帮助。
https://machinelearning.org.cn/make-sample-forecasts-arima-python/
谢谢。我马上试试。还有一个问题在我脑海中闪过。ARIMA是否可以用于多元和多步预测?到目前为止,我只找到了用于单变量时间序列的ARIMA。
是的,它被称为VAR或VARIMA,请参阅这篇文章。
https://machinelearning.org.cn/time-series-forecasting-methods-in-python-cheat-sheet/
嗨
对于我来说,如何使用加载的模型并不清楚。即使看了关于https://machinelearning.org.cn/make-sample-forecasts-arima-python/ 的其他帖子也不清楚。
您能举个例子吗?
当然,您具体遇到了什么问题?也许我可以提供一些建议。
您好,我一直在为我的时间序列预测部署尝试您的保存的LSTM模型代码很长时间了。现在我遇到了一个让我卡住一段时间的问题,您能分享一些技巧吗?
以下是我的代码
model.py
from pandas import read_csv
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.tsa.arima_model import ARIMAResults
import warnings
warnings.filterwarnings(“ignore”)
# monkey patch around bug in ARIMA class
def __getnewargs__(self)
return ((self.endog),(self.k_lags, self.k_diff, self.k_ma))
ARIMA.__getnewargs__ = __getnewargs__
# 加载数据
series = read_csv(‘Sales.csv’, header=0, index_col=0)
# 准备数据
X = series.values
X = X.astype(‘float32’)
# 拟合模型
model = ARIMA(X, order=(1,1,1))
model_fit = model.fit()
# 保存模型
model_fit.save(‘model.pkl’)
app.py
from flask import Flask, make_response, request, render_template
import io
from io import StringIO
import csv
import pandas as pd
import numpy as np
import pickle
import os
from keras.models import load_model
from statsmodels.tsa.arima_model import ARIMAResults
app = Flask(__name__)
def transform(text_file_contents)
return text_file_contents.replace(“=”, “,”)
@app.route(‘/’)
def form()
return “””
让我们尝试预测..
插入您的 CSV 文件,然后下载结果
预测
"""
@app.route(‘/transform’, methods=[“POST”])
def transform_view()
if request.method == ‘POST’
f = request.files[‘data_file’]
if not f
return “No file”
stream = io.StringIO(f.stream.read().decode(“UTF8”), newline=None)
csv_input = csv.reader(stream)
#print(“file contents: “, file_contents)
#print(type(file_contents))
print(csv_input)
for row in csv_input
print(row)
stream.seek(0)
result = transform(stream.read())
df = pd.read_csv(StringIO(result), usecols=[1])
# 从磁盘加载模型
model = ARIMAResults.load(‘model.pkl’)
dataset = df.values
dataset = dataset.astype(‘float32’)
dataset = np.reshape(dataset, (-1, 1))
df = model.predict(dataset)
response = make_response(df.to_csv())
response.headers[“Content-Disposition”] = “attachment; filename=result.csv”
return response
if __name__ == “__main__”
app.run(debug=True, port = 9000, host = “localhost”)
抱歉,我没有能力审查/调试您的代码,也许您可以总结一下您遇到的具体问题?
KeyError: ‘The
startargument could not be matched to a location related to the index of the data.’错误表明,您指定的任何数据范围,例如在predict函数中,范围的起始点的索引对于您的数据集无效。
也许您可以打印您的数据集长度和您尝试使用的起始索引,并直接进行比较。
遇到了错误。你能帮我解决吗。
—————————————————————————
ModuleNotFoundError Traceback (最近一次调用)
in
3 from pandas import read_csv
4 from pandas import DataFrame
—-> 5 from statsmodels.tsa.arima.model import ARIMA
6 from matplotlib import pyplot
7 # load dataset
ModuleNotFoundError: No module named ‘statsmodels.tsa.arima’
JG您好…以下帖子希望能帮助您解决问题。基本上您需要确保已安装statsmodels。
https://stackoverflow.com/questions/69047074/no-module-named-statsmodels-tsa-arima-in-colab-but-not-in-pycharm