在找到一个表现良好的机器学习模型并对其进行调优后,您必须最终确定您的模型,以便您可以在新数据上进行预测。
在本教程中,您将了解如何最终确定您的机器学习模型,将其保存到文件,并在以后加载它以在新数据上进行预测。
阅读本文后,您将了解
- 如何在Weka中训练最终版本的机器学习模型。
- 如何将最终确定的模型保存到文件。
- 如何稍后加载最终确定的模型并使用它来预测新数据。
通过我的新书《Weka机器学习精通》,开始您的项目,书中包含分步教程和所有示例的清晰屏幕截图。
让我们开始吧。

如何在 Weka 中保存你的机器学习模型并进行预测
照片由 Nick Kenrick 拍摄,保留部分权利。
教程概述
本教程分为 4 个部分
- 最终确定模型,您将了解如何训练模型的最终版本。
- 保存模型,您将了解如何将模型保存到文件。
- 加载模型,您将了解如何从文件加载模型。
- 进行预测,您将了解如何对新数据进行预测。
本教程提供了一个模板,您可以使用它来最终确定您在数据问题上的机器学习算法。
我们将使用 Pima 印第安人糖尿病发病数据集。每个实例代表一名患者的医疗详细信息,任务是预测患者在未来五年内是否会患上糖尿病。有 8 个数值输入变量,所有变量的尺度都不同。
最佳结果的准确率约为77%。
我们将在此数据集上最终确定一个逻辑回归模型,原因有两个:它是一个简单且易于理解的算法,并且它在该问题上表现非常好。
在Weka机器学习方面需要更多帮助吗?
参加我为期14天的免费电子邮件课程,逐步探索如何使用该平台。
点击注册,同时获得该课程的免费PDF电子书版本。
1. 最终确定机器学习模型
也许机器学习项目中被忽视最多的任务是如何最终确定模型。
一旦您付出了所有努力来准备数据、比较算法并对它们进行调优,您就需要创建最终模型,您打算使用它来做出新的预测。
最终确定模型涉及在您拥有的所有训练数据集上训练模型。
1. 打开Weka GUI Chooser。
2. 点击“Explorer”按钮打开Weka Explorer界面。
3. 从data/diabetes.arff文件加载 Pima 印第安人糖尿病发病数据集。
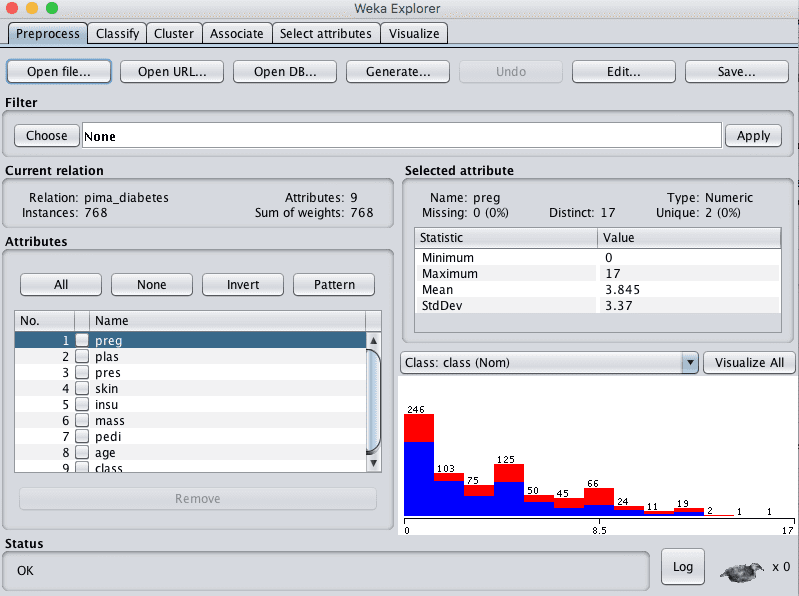
Weka加载 Pima 印第安人糖尿病发病数据集
4. 点击“Classify”选项卡以打开分类器。
5. 点击“Choose”按钮,然后在“functions”组下选择“Logistic”。
6. 在“Test options”下选择“Use training set”。
7. 点击“Start”按钮。
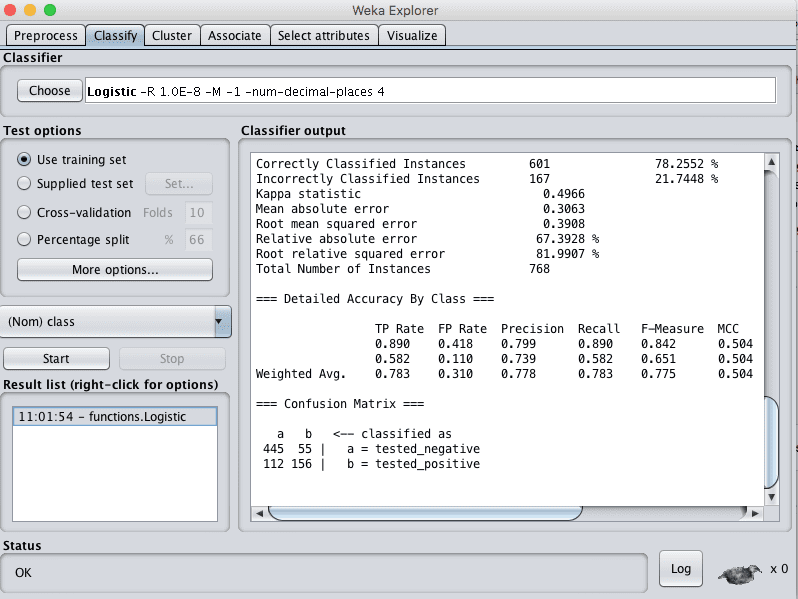
Weka训练逻辑回归模型
这将根据所有加载的数据集训练选定的逻辑回归算法。它还将根据所有数据集评估模型,但我们不关心此评估。
假定您已经通过交叉验证来估计模型在未见过数据上的性能,作为选择您要最终确定的算法的一部分。正是这个您之前准备的估计值,当您需要告知他人您的模型的技能时,您可以报告。
现在我们已经最终确定了模型,我们需要将其保存到文件。
2. 将最终确定的模型保存到文件
接上一个部分,我们需要将最终确定的模型保存到您磁盘上的文件中。
这样我们就可以在以后加载它,甚至在将来在不同的计算机上加载它并使用它来进行预测。将来我们不需要训练数据,只需要该模型的数据。
您可以轻松地在Weka Explorer界面中将训练好的模型保存到文件。
1. 在“Classify”选项卡的“Result list”中,右键单击您模型的相应结果项。
2. 从右键菜单中点击“Save model”。
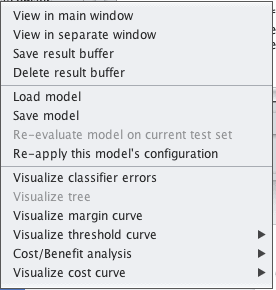
Weka将模型保存到文件
3. 选择一个位置并输入文件名,例如“logistic”,然后点击“Save”按钮。
您的模型现已保存到文件“logistic.model”。
它是一种二进制格式(非文本),Weka平台可以再次读取。因此,最好记下您用于创建模型文件的Weka版本,以防将来需要相同的Weka版本来加载模型并进行预测。通常,这不会有问题,但这是一个好的安全预防措施。
您现在可以关闭Weka Explorer。下一步是了解如何加载已保存的模型。
3. 加载最终确定的模型
您可以从文件加载已保存的Weka模型。
Weka Explorer界面使这变得容易。
1. 打开 Weka GUI Chooser。
2. 点击“Explorer”按钮打开Weka Explorer界面。
3. 加载任何旧数据集,这无关紧要。我们不会使用它,我们只需要加载一个数据集来访问“Classify”选项卡。如果您不确定,请再次加载data/diabetes.arff文件。
4. 点击“Classify”选项卡以打开分类器。
5. 右键单击“Result list”并点击“Load model”,选择在上一个部分保存的模型“logistic.model”。
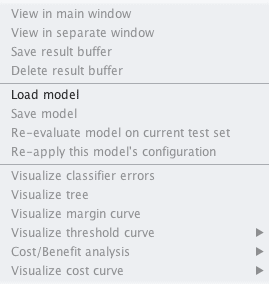
Weka从文件加载模型
模型现在将加载到Explorer中。
我们现在可以使用加载的模型来预测新数据。
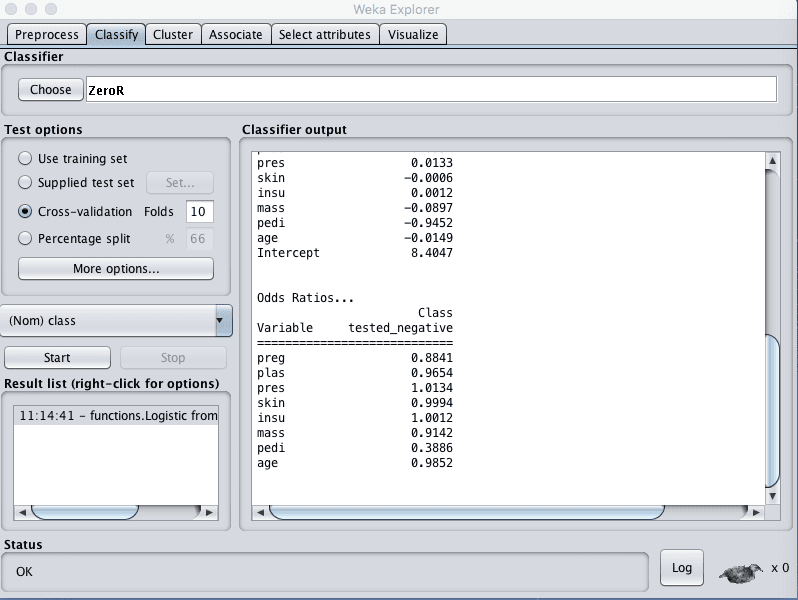
Weka已从文件加载模型,可供使用
4. 对新数据进行预测
现在我们可以对新数据进行预测。
首先,让我们创建一些模拟的新数据。复制文件“data/diabetes.arff”并将其另存为“data/diabetes-new-data.arff”。
在文本编辑器中打开文件。
在第 95 行找到文件中实际数据的开头,其中有 @data。
我们只需要保留 5 条记录。向下移动 5 行,然后删除文件中所有剩余的行。
我们想要预测的类值(输出变量)在每行的末尾。删除每个输出变量,并用问号(?)替换它们。
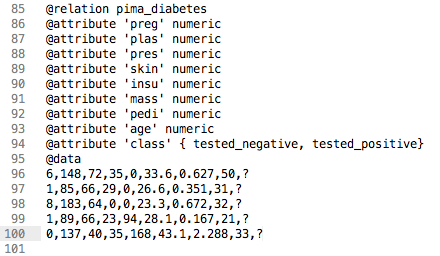
Weka用于新数据预测的数据集
现在我们有了“未见过”的数据,其输出未知,我们希望对其进行预测。
继续教程的前一部分,我们已经加载了模型。
1. 在“Classify”选项卡中,在“Test options”窗格中选择“Supplied test set”选项。
Weka选择要进行新预测的新数据集
2. 点击“Set”按钮,在选项窗口中点击“Open file”按钮,然后选择我们刚刚创建的名为“diabetes-new-data.arff”的模拟新数据集。点击窗口中的“Close”。
3. 点击“More options…”按钮以调出评估分类器的选项。
4. 取消选中我们不感兴趣的信息,特别是:
- “Output model”
- “Output per-class stats”
- “Output confusion matrix”
- “Store predictions for visualization”
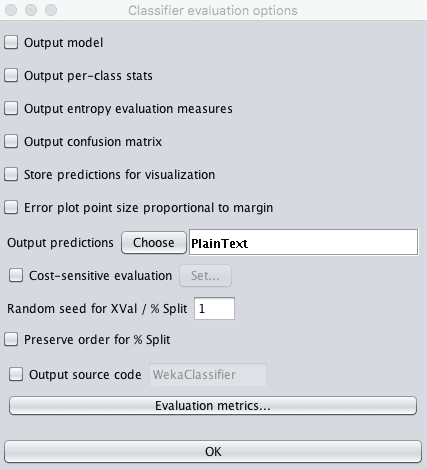
Weka用于预测的自定义测试选项
5. 对于“Output predictions”选项,点击“Choose”按钮并选择“PlainText”。
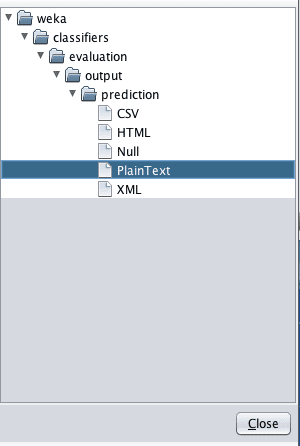
Weka以纯文本格式输出预测
6. 点击“OK”按钮确认分类器评估选项。
7. 右键单击“Results list”窗格中加载的模型对应的列表项。
8. 选择“Re-evaluate model on current test set”。
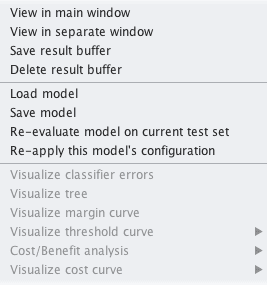
Weka在测试数据上重新评估加载的模型并进行预测
然后,每个测试实例的预测将列在“Classifier Output”窗格中。特别是结果的中间列,预测如“tested_positive”和“tested_negative”。
您可以为预测选择其他输出格式,例如 CSV,然后您可以稍后将其加载到 Excel 等电子表格中。例如,下面是相同预测的 CSV 格式示例。
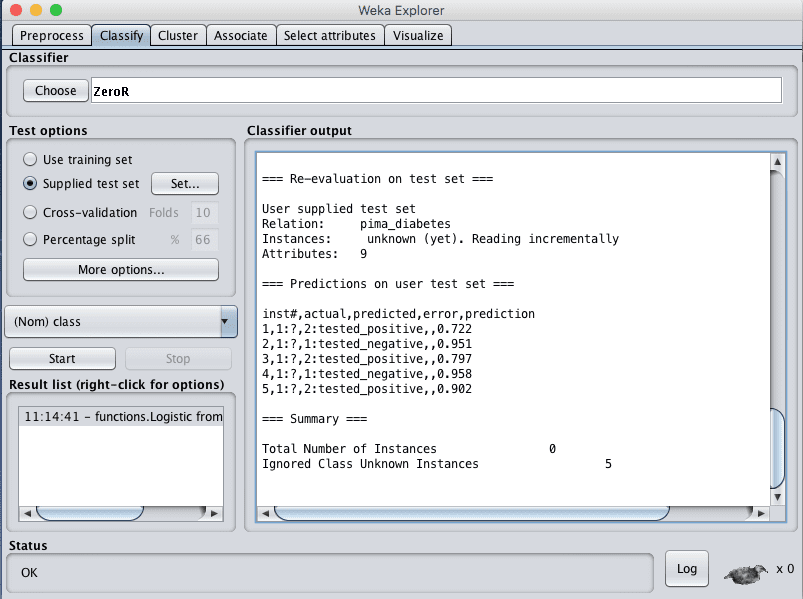
Weka已加载模型对新数据进行的预测
更多信息
Weka Wiki 包含有关保存和加载模型以及进行预测的更多信息,您可能会发现这些信息很有用。
总结
在本教程中,您了解了如何最终确定模型以及如何对新的未见过的数据进行预测。您可以看到如何使用此过程来为您自己预测新数据。
具体来说,你学到了:
- 如何训练机器学习模型的最终实例。
- 如何将最终确定的模型保存到文件以备将来使用。
- 如何从文件加载模型并使用它来预测新数据。
您对如何在 Weka 中最终确定模型或对此帖子有任何疑问吗?请在下方的评论区提问,我会尽力回答。
探索无需代码的机器学习!

在几分钟内开发您自己的模型
...只需几次点击
在我的新电子书中探索如何实现
使用 Weka 精通机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、构建模型、调优等等...
最终将机器学习应用到你自己的项目中
跳过学术理论。只看结果。






嗨
我可以打开保存的模型吗?
我想将保存的模型用作 Web 服务,但不是使用 weka 进行预测。
有办法吗?
谢谢
Kanan,我还没有自己做过。
您也许可以使用 PMML 格式
http://wiki.pentaho.com/display/DATAMINING/PMML+Support+in+Weka
不幸的是,链接显示“Weka 尚不支持导出 PMML 模型”。
谢谢……
如何在 Weka 中预测连续输出?当我尝试在测试集上运行模型时,出现“评估分类器时出错:类索引为负(未设置)!”错误,其中包含因变量。
很好的问题。
使用回归算法来预测连续值。
这是一个入门教程
https://machinelearning.org.cn/use-regression-machine-learning-algorithms-weka/
M5P 是否无法进行分类和连续变量的回归预测?我认为回归树可以做到这一点?
非常感谢您的这个教程。它非常直接。真的很喜欢。谢谢。
Kayode,很高兴听到您这么说。
非常感谢您的教程。它对我很有用。谢谢。
Ametun,很高兴听到您这么说。
嘿,非常感谢您的帮助!
给那些在做您描述的相同事情时遇到问题(使用 .csv 输入文件)的人一个附注:上面的描述对于 .arff 文件来说是完美的,但在我的例子中(使用 .csv),它只对前 112 行进行了预测,然后就停止了,原因不明。转换输入(训练和测试数据)解决了这个问题。
我期待您的更多教程🙂
感谢您的提示,Diane。
你好,
感谢您的辛勤工作。请您协助我,我正在处理犯罪问题,并且是 weka 的新手。我已使用 weka 将我的数据集分成 CSV 格式的测试和训练数据集。但当我放入分类器(如 Bayes、KNN)并加载测试数据集时,系统会抱怨。
请帮帮我
具体是什么错误?Weka 抱怨什么?
你好,
训练数据集和测试数据集的格式应该相同吗?如果是,为什么我的 weka 会抱怨测试数据集不兼容?另外,我们是不是将测试数据转换回纯文本?
是的,训练集和测试集必须是相同的格式,并且列数相同。
您可能不知道预测结果,在这种情况下,您可以使用“?”值。
谢谢。我非常感谢您的努力,您的教学非常出色。
谢谢!
感谢教程。我有一个问题,为什么实例数量未知?以及如何评估预测的准确性?我的意思是,我需要看到正确分类的实例数量等等…
本教程是关于在新数据上进行预测的。
如果您有已知预期结果的数据,您可以通过在 Weka 中将其选为外部测试数据集来对其进行预测。
你好,
我需要在单独的流派(博客数据)上训练模型,并在另一个流派(酒店评论)上进行测试。我通过 1. 应用 StringToWordVector 过滤器(更改过滤器的某些设置)2. 属性选择 3. 应用分类 Logistic 并选择“use training set”选项 4. 保存模型 来训练了一个模型。现在我对测试文件感到困惑,我是否需要对测试文件应用所有这些步骤直到第 3 步?这样做我的训练和测试文件属性不同但格式相同。
我的训练文件属性和测试文件属性是否必须完全相同(一模一样)?如果正确,我能否从训练文件中复制属性(从顶部到 @data)并粘贴到我的测试文件中,这样正确吗?
如果训练和测试文件的属性可以不同,那么就会出现错误“用于训练模型的数据和测试集不兼容。您是否要自动将分类器包装在“InputMappedClassifier”中,这是什么意思?如果选择“是”,它会做什么。
抱歉先生,我有很多问题。我探索了很多但仍然很困惑。这将是一个巨大的帮助。
谢谢你
你好,
我在 Weka 中构建了一个逻辑回归模型,并希望能够识别每个特定数据点的预测值。我目前拥有的输出不允许我将预测与单个实例匹配。
谢谢,
Mike
你好 Mike,
预测的顺序应该与用于进行预测的输入文件中的数据顺序匹配。
很棒的文章!非常简单直接!
谢谢 Bellz。
嗨 Jason
文章写得很好。我按照您建议的步骤进行,并且我正在应用随机森林分类器。我的训练集和测试集具有相同的属性。然而,在为未知数据进行预测阶段,它忽略了所有实例。下面是我在分类器输出中看到的消息:
=== 总结 ===
总实例数 0
忽略未知类别实例 72
=== 混淆矩阵 ===
a b <– 分类为
0 0 | a = 好
0 0 | b = 坏
您能建议一下我哪里做错了什么吗?
也许测试集数据已损坏或未正确加载?
Kanika Sood……你能帮我吗……我遇到了同样的错误??
我得到了我之前问题的答案。我现在的问题是:随机森林、BayesNet 总是只预测一个类别的所有实例。
也许您需要重新构思问题或收集更多数据。
如果您有所有类别的实例,您可能需要收集其他类别的示例。
这个过程将帮助您解决问题。
https://machinelearning.org.cn/start-here/#process
优雅、简单、练习。
谢谢,很高兴能帮到您 Billy!
抱歉,如果有人已经问过这个问题,但我在这里找不到。
当我使用我的模型来预测新数据时,输出文件只显示了 101 个项目/实例。请问如何让模型预测所有记录(约 5000 条记录)?
没有限制,将所有输入传递给 model.predict(X) 以获得预测。
Jason,感谢您的帖子!有没有办法获得前 3 个预测?
您具体指的是“前 3 个预测”是什么意思?
首先,感谢您让我发现了 Weka。我是众多人群中的一员,在看了教程、混淆矩阵后,我曾说过“太棒了!接下来做什么?”🙂
我刚上完 Udemy 上一个关于数据科学和 Python 的很长的课程… 我是否可以大胆地认为 Weka 可以替代 Python?(至少对于简单的任务?)
对于许多初学者在小型一次性项目上工作,它可以而且应该。
从 Weka 入门
https://machinelearning.org.cn/start-here/#weka
谢谢你!!
这个博客很有帮助,你能建议我如何使用 Python 在模型之上创建一个 UI 应用程序,让用户可以手动输入数据并给出正面或负面的结果吗?
抱歉,我不知道 Python 中的 UI 应用程序。也许是 Web 界面?
谢谢 Jason,这非常有帮助。您知道是否有办法保存特定的多层感知器配置吗?我正在运行感知器分类器并在 GUI 中将 GUI 设置为 true 以便进行调整,但我无论如何也想不出如何保存调整后的配置以便重复使用。我到处都找过了。
拟合模型后,您可以保存它。
运行模型时,Explorer 窗口应在顶部为您提供重新创建模型配置所需的命令行参数。
嗯,这正确地保存了像 Num Epochs、Learning Rate 等常规参数,但它没有保存特定的感知器 GUI 调整——例如,我通过感知器 GUI 手动连接和断开某些节点。
我错过了什么步骤,还是有什么我应该做的独特的事情可以允许它保存 GUI 中所做的更改?
谢谢!
感谢教程。我刚接触 Weka 和机器学习。教程很有帮助。只想知道如何判断特定实例的预测值?预测是按顺序进行的吗?
=== 用户测试集上的预测 ===
inst# 实际 预测 错误 预测
1 1:? 2:tested_positive 0.722
2 1:? 1:tested_negative 0.951
3 1:? 2:tested_positive 0.797
4 1:? 1:tested_negative 0.958
5 1:? 2:tested_positive 0.902
另外,2:tested_positive中的2是什么意思?
好问题。是的,预测的顺序将与输入文件中的观测顺序相匹配。
预测可能是一个类别编号(1或2),以及问题中关联的标签(positive或negative)。
谢谢你
不客气。
你好。
我在Linux操作系统中运行了weka,并得到了混淆矩阵输出。现在我想将这些值
用在图表中,我该如何访问这些值?我应该使用什么代码?
抱歉,我不明白,你具体指的是什么?
你好Jason。感谢你的精彩教程。使用WEKA进行预测就是这样吗?我的意思是,
a) 选择合适的模型(即分类器)
b) 在提供的测试集上运行它
c) 保存模型
d) 在WEKA Explorer中加载数据集,以便能够访问Classifier选项卡
e) 加载模型
f) 打开新文件,最后
g) 在新文件上重新评估模型以进行预测。
是的!它非常适合初学者。
你可以深入研究各个方面,我建议使用Experiment来系统地进行探索。
如何计算每个预测变量的优势比、95%置信区间和P值?
当我安装新包时,会显示一个错误消息。如何解决这个问题?
你好 Jason,
如何使用R程序进行预测并生成实际值?
请看这篇文章
https://machinelearning.org.cn/finalize-machine-learning-models-in-r/
你好 Jason,
假设我正在进一步调整和测试算法,并且我有独立的测试集和训练集,它们包含不同的实例分布,以便我可以选择模仿现实世界的分布,或者保持50/50的比例,看看哪种选择能使测试集(具有现实世界般的分布)具有更高的准确性。自然,我不想保存很多模型。我能否在不保存的情况下重新评估,在完成了训练集的交叉验证后就跳到第四步?
找到一个好的配置后,丢弃所有CV模型并训练一个最终模型。
请参阅关于此主题的帖子
https://machinelearning.org.cn/train-final-machine-learning-model/
非常感谢布朗利博士的精彩教程。它们在我的学校毕业项目上帮助了我很多。
我想在工作中执行这种预测建模技术,但我们处理的数据集非常大(数百万个元组),所以我的问题是——Weka能够处理非常大的数据集吗?
Weka似乎是一个非常简单且用户友好的工具。
我建议抽取数据样本进行建模,样本大小要足够小,以便在Weka中能放入内存。
如何将weka结果转移到安卓手机上?
我不知道,抱歉。
你好 jason,
我是 Lina,我阅读了上面所有的教程步骤……但仍然很困惑,如果我们使用全新的数据作为测试集,它能正常运行吗?例如,上面的示例显示你使用了5个相同的数据来预测类别……
抱歉,我不明白。也许你可以重述一下你的问题或提供更多背景信息?
你好,
我如何创建一个包含PMML模型实现的网站,并使其可供公众使用?
例如,用户输入10个参数,并通过PMML接收计算结果?
抱歉,我没有从模型创建网站的示例。
你好Jason,非常感谢你在这项工作中付出的努力。请问,WEKA中是否有部署Ripple Down Rule (RIDOR) Learner的选项?如果可能,我该如何操作?
Ben,可能吧,但我不太清楚,很抱歉。
你好!非常感谢你的教程。
我想知道为什么它不将结果保存在文件中?我是否必须将输出复制粘贴到csv文件中?
是的。您需要手动保存。Weka最初是为探索模型而设计的,而不是为使用模型。
你好。感谢你的教程。
我的问题是
是否可以对从模型加载的数据执行交叉验证或拆分百分比?
或者,如果我想执行这两个操作中的任何一个,是否必须加载相应的训练数据集并为它们构建一个新模型?
你具体指的是什么?
CV和拆分是使用训练数据来评估模型的方法。它怎么会“来自模型”呢?
感谢您的回答。
我有以下情况
我使用数据集“training.arff”和分类器(例如RandomForest)来生成模型“model1.model”;然后我将其保存。
如果我想用它来评估测试集,我加载“model1.model”并使用“reevaluate model on current test set”选项。到目前为止一切正常。
但是,如果我想验证我的模型,我发现没有直接的方法可以直接对来自model1.model的数据使用CV或拆分。我必须重新加载“training.arff”,使用CV,并看到它说“building model for training data”,这意味着它正在生成另一个模型。
我想知道是否可以验证生成的模型。
再次感谢您的反馈
我建议在保存和进行预测之前验证模型。
嗨,我如何预测两个不同的数据集?
你具体指的是什么?
你好,感谢你的辛勤工作,它真的帮助了我很多。
这是我的问题
=== 用户测试集上的预测 ===
inst# 实际 预测 错误 预测
1 1:? 2:tested_positive 0.722
2 1:? 1:tested_negative 0.951
3 1:? 2:tested_positive 0.797
4 1:? 1:tested_negative 0.958
5 1:? 2:tested_positive 0.902
预测下方的数字是什么意思?
0.722、0.951、0.797
这是否意味着预测正确的概率?
是的,是该类预测的概率。
你好,感谢你的信息丰富的文章。
我有一个关于weka在交叉验证期间选择的测试数据实例索引的问题。如何获取正在测试的测试数据索引?
=======
我选择了
数据集:iris.arff
总实例数:150
分类器:J48
交叉验证:10折
我还将输出预测设置为“PlainText”。
=============
在输出窗口中,我可以看到如下内容:
inst# 实际 预测 错误 预测
1 3:Iris-virginica 3:Iris-virginica 0.976
2 3:Iris-virginica 3:Iris-virginica 0.976
3 3:Iris-virginica 3:Iris-virginica 0.976
4 3:Iris-virginica 3:Iris-virginica 0.976
5 3:Iris-virginica 3:Iris-virginica 0.976
6 1:Iris-setosa 1:Iris-setosa 1
7 1:Iris-setosa 1:Iris-setosa 1
....
…
…
总共10个测试数据集。(每个15个实例)。
======================
由于WEKA使用分层交叉验证,测试集中的实例是随机选择的。
那么,如何知道上面几行中显示预测评估的测试数据实例的索引?
即
inst# 实际 预测 错误 预测
1 3:Iris-virginica 3:Iris-virginica 0.976
这个结果是针对哪个实例(总共50个Iris-virginica)的?
===============
在主数据文件中,前几个实例是
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
所以主数据文件以Iris-setosa开头。
索引应该是文件中的行号。
你好,感谢你的精彩教程。
我使用的是csv而不是arff。
当我提供一个包含145个true和70个false实例(按此顺序)的测试集时,结果只显示145个实例。它不计算那70个实例的结果。
如果数据集是随机排序的,结果只显示具有相同true/false值的最前面几个实例。例如,如果前十个实例是false,第11个是true,那么结果(和混淆矩阵)只为前十个实例计算。
请帮忙。
也许数据没有正确加载?
我们如何获得原始形式的输出预测?
你具体指的是什么?
你好Jason。我在这里关注你的几个教程有一段时间了。很高兴看到你仍然回答问题。我的问题是关于测试集的。我在@data区域中将所有类的实例都设为“?”,就像示例中一样,但为什么我的模型分类结果是这样的?
“总实例数:0
忽略类未知实例:7401”
是我哪里做错了吗?另外,我使用的模型是用LibSVM创建的。
不,你可以忽略这个说明。我们正在强迫Weka做它不想做的事情——在Explorer中进行预测。
如果我有一个用J48和StringToWordVector构建的模型。
如何在Java中将数据输入分类器进行分类?
Classifier cls = (Classifier) weka.core.SerializationHelper.read(“c:\\identify.model”);
ArrayList classes = new ArrayList(3);
classes.add(“type1”);
classes.add(“type2”);
classes.add(“type3”);
//Class attribute
Attribute classAttribute = new Attribute(“class”, classes);
ArrayList attributes = new ArrayList(2);
Attribute text=new Attribute(“text”, true);
attributes.add(text);
attributes.add(classAttribute);
//Create the empty dataset “sample” with above attributes
Instances sample = new Instances(“sample”, attributes, 0);
//Make position the class attribute
sample.setClassIndex(classAttribute.index());
//Create empty instance with five attribute values
Instance inst = new DenseInstance(2);
//Set instance values
inst.setValue(text, “What is this are you kidding me 1 2 3 4”);
//Set instance’s dataset to be the dataset “race”
inst.setDataset(sample);
//Set class as missing so we can predict
inst.setClassValue(0); // When I set class as missing, the filter not working at all.
sample.add(inst);
System.out.println(sample.toString());
StringToWordVector filter = createFilter(sample);
sample=filter.useFilter(sample, filter);
System.out.println(sample);
抱歉,我没有Weka API的Java编程示例,无法给你建议。
我想在.arff文件中添加一列,但我不希望分类器使用它,但我希望它出现在预测输出中,它只是我需要在输出中拥有的每个实例的一个名称——在Explorer中我该如何处理?
非常感谢。
我不确定,抱歉。也许可以发布到weka用户组。
你好Jason!感谢你的有用教程!
我使用了MPRegressor并获得了以下模型
MPRegressor,值为0.01的岭值和2个隐藏单元(useCGD=true)
输出单元0的隐藏单元0权重:2.9058790401172043
隐藏单元0权重
-0.2878670472862872 A
0.4012790926803488 B
0.6114550533482614 C
0.09745324473246314 D
-0.26600053341756486 E
隐藏单元0的偏差:-0.1802615484156791
输出单元0的隐藏单元1权重:-0.239991138003868
隐藏单元1权重
-6.4472828043452175 A
-4.770061719076585 B
-4.318804805199649 C
-2.077452814137676 D
1.0959052105040001 E
隐藏单元1的偏差:0.21400772835364332
输出单元0的偏差:-1.2579970537867124
有没有办法在Excel中使用这个模型?
干得漂亮!
我不知道如何在Excel中使用Weka模型,抱歉。
老师您好!
您能否帮助我如何设置逻辑回归模型,使其预测值大于1或2?
=== 用户测试集上的预测 ===
inst# actual predicted error prediction predicted error prediction
1 1:? 4:BSBA 0.328 6:BEED 0.618
这可能吗?
通常,逻辑回归用于二元分类问题。
谢谢老师。那么您能告诉我应该使用什么函数来进行多次预测吗?
将不胜感激。
几乎任何其他分类算法都可以。
我训练了一个非常大的数据集,大小为1GB,但模型文件只有300KB。这正常吗?
模型的大小与模型的复杂度成正比,这可能与数据集中的示例数量无关。
我也遇到了这个问题。我创建了模型,但我的测试数据集包含一些额外的属性,weka使用了InputMappedClassifier,但它重新训练了模型而不是仅仅测试它。为什么会这样?
也许可以尝试单独准备新数据,使其结构与训练数据集相同,例如在Excel或文本编辑器中?
你好 Jason,
我真的需要你的帮助。
我按照教程步骤在weka上进行预测。但是,发生了一个错误
问题评估分类器:类索引未设置!
我该如何纠正这个错误?
我不确定,有一些想法
也许数据集没有正确加载?
也许类变量没有指定?
谢谢你。
我能够预测模型。
还有一个疑问。
我正在研究远程教育中的逃课预测。
一个使用RandomForest创建的模型,在训练过程中,获得了90.01%的准确率和0.906的F测量值。但是当我使用该模型进行预测时,它将所有实例都分类为逃课(YES)。用于测试模型的数据集与用于训练的数据集相似。我已经检查了数据库并重复了整个过程,但结果没有变化。你有什么想法可以解决它吗?
结果
=== 混淆矩阵 ===
a b <– 分类为
323 0 | a = SIM
109 0 | b = NAO
谢谢。
抱歉,我不明白。你具体遇到了什么问题?
数据集中行的顺序重要吗?我可以把所有类别为“A”的行放在前面,然后把所有类别为“B”的行放在后面吗?
对于 LSTM 和 SGD 来说,这很重要。这真的取决于具体情况。
通常,在拟合模型时,我们希望每个 epoch 都打乱行的顺序,以避免学习到任何顺序。
你好 Jason,
感谢分享这些知识。
我有一个问题,我是 WEKA 的初学者,我已经完成了上述步骤,我读到测试集应该与训练集具有相同数量的属性,但鉴于我正在处理推文,并且词向量会不同,这怎么可能?
非常感谢您的帮助。
您需要将文本编码为相同长度的向量,例如,具有相同大小词汇量的词袋模型。
WEKA 能否对给定数据集进行两次预测?
通常,机器学习系统只会根据实例的给定特征集在可用类别(分类)中进行一次预测,或预测一个单一的实数值(回归)。
WEKA 能否训练一个系统对给定样本进行两次预测?
虽然这个问题可以从多个角度来看。我想要使用此功能的一个特定用例是根据图像的特征集来预测 (x,y) 坐标。在这里,x 和 y 是要预测的两个变量。
Weka 工具是否具备执行此操作的能力?
我不认为 weka 支持多输出预测问题。
我想用 weka 预测心理健康。我理解了这些步骤,但不知道如何创建带有某些属性的文件。你能指导我一下吗?
也许这个框架会有帮助
https://machinelearning.org.cn/how-to-define-your-machine-learning-problem/
我可以在 r 中使用那个模型吗
太棒了!
你熟悉 Tensorflow 吗?我可以在 tensorflow 中训练和保存模型,然后在 weka 中进行预测吗?
据我所知,不支持。
嗨,杰森,
我能否在 r 中加载那个保存的模型?
谢谢你
是的,这里有一个例子
https://machinelearning.org.cn/finalize-machine-learning-models-in-r/
不,我问的是 weka 保存的模型。我能否在 java 中加载?
抱歉,我没有加载模型的 Java 示例。
抱歉 Jason,我本来想问能否在 r 中加载。
你也许可以,我不知道,抱歉。
好的,谢谢。
抱歉,在 r 中加载。
嗨,Jason,
我在我的自定义 C 代码中使用了 Weka 为多层感知器 (MLP) 显示的权重和阈值,以对相同的训练数据进行预测。
然而,Weka 的结果与我的 C 代码实现结果不匹配。
在我的 C 代码中,我使用了前馈模型 (MLP),其中权重和阈值是从 Weka 训练模型获得的。
每个节点的计算如下所示:
Sum_node = threshold;
for( i = 0 ; i < Num_Input ; i++)
Sum_node += Input[i] * Weight[i][j] ;
hidden_node = 1/(1 + exp(-Sum_node)) ;
您能否告诉我 Weka 是否有不同的方法来测试新数据?
它可能在实现上有所不同。
您可以检查源代码,它是开源的。
如何在 Python 中使用 Weka?
我看不出为什么不。
抱歉,我没有这方面的例子。
嗨,Jason,
您知道每个 weka 分类器所需的输入数据的最大量吗?
好问题,我在这里回答
https://machinelearning.org.cn/much-training-data-required-machine-learning/
首先,非常感谢您写了这篇非常有帮助的文章。您能否帮助我了解如何在 Eclipse IDE 中使用 weka.jar 库来完成同样的事情(用 Java)?
抱歉,我没有 Java 示例。
我的数据集是 .crv 格式,并已导入到 weka 中,格式为 .aarf。我知道这个数据集很好——它是我导师提供的。我写了一个很好的决策树。我想使用数据集中的三个属性来预测一个人是否患有膀胱感染,这取决于响应,即他们的体温是否超过 40 度,以及他们是否出现恶心和腰痛。使用 weka 产生这样的东西的第一步是什么?我应该加载数据并使用 UserClassifier 来制作一棵树吗?我想 weka 可以剔除那些体温高、有腰痛或恶心的患者,我不确定如何进行。
也许从这里开始
https://machinelearning.org.cn/start-here/#weka
非常感谢!!
我从您那里获得了非常有价值的知识,关于如何在 Weka 中保存机器学习模型并进行预测,如果可能的话,您可以告诉我如何使用此结果来预测我的整个数据集吗?
抱歉,我无法为您进行预测。
我可以使用 Explorer 中保存的模型在 Experimenter 中进行预测吗?
我想我不能,凭我的经验。
我几年前用过 WEKA,我很喜欢。很多年前,Weka 是 Python 和 R 之前的首选机器学习软件。
您能分享一下为什么 WEKA 今天不如 Python/R 流行吗?
我同意!
我不知道。也许是对 GUI 的偏见?或者对 Java 的偏见?
这太疯狂了,因为您可以在 Weka 中非常高效地工作,而无需编写任何代码。而且您能立即理解机器学习/模型构建/选择过程。
你好,
我需要在 Linux 系统上使用 weka 来计算混淆矩阵的未加权平均召回率,我能知道脚本吗?
抱歉,我没有 Weka 的脚本。我只展示如何使用 GUI 界面。
哦,好的,非常感谢!我必须处理输出预测,是否有任何教程解释输出预测?
上面的教程正是关于这个主题的。
嗨,Jason,
感谢这篇出色的文章。我想知道是否有可能在 Weka 平台之外实现训练好的模型。
例如,如果我在特定数据集上使用 J48,然后可以使用“可视化决策树”选项将规则用作 if 语句在另一个平台上处理不同的数据集。
我能否对其他算法(如 Random Forest、SVM 等)做类似的事情?
我想训练好的模型将是某些方程,其中系数由训练数据生成?感谢任何建议。
是的,也许可以通过 Java API?
嗨,Jason,
我有一个 csv 文件,其中包含推文的 32 个属性,每个属性都是该文件的一列。我有一个 Nomber_of_retwwet’s 属性作为推文转发数的预测。如何实现对推文转发数的良好保护响应?
抱歉,我不明白。
如果你问的是如何处理你的数据集,我推荐这个过程
https://machinelearning.org.cn/start-here/#process
你好,非常感谢您提供的宝贵评论和教程。
我想知道是否有办法构建不同的模型来测试它们在测试数据上的表现?(例如,使用 10 折交叉验证并重复 20 次,得到 200 个模型,然后在测试数据上测试 200 次)!
是的,您可以为此目的使用 Weka Experimenter。
也许可以从这个教程开始
https://machinelearning.org.cn/regression-machine-learning-tutorial-weka/
你好,我还有另一个问题。我有健康和患病人群的数据。但是数据包含每个受试者的重复扫描(这意味着,例如,前 4 条数据属于患者 1,另外 3 次扫描属于患者 2,依此类推)。为了进行 CV,一个受试者及其所有扫描应该在训练集还是测试集中。当我执行 10 折 CV 时,在 Weka 中是否可以这样做?
是的,听起来每个患者都应该在分割到 fold 或 train/test split 之前进行分组。
非常感谢您的回复。您能否告诉我如何在进行 k 折交叉验证之前对受试者进行分组?现在,我分配了一个包含健康和患病人群的列。但我认为我应该分配另一列来根据他们的重复扫描对所有人群进行分类。
您可能需要编写一些自定义代码来对受试者进行分组。
谢谢您的回答。
不客气。
使用 Weka,我训练了一个 MLP 模型。我想使用部分数据对其进行进一步训练(我认为这有点像“迁移学习”)。我希望 Experimenter 的 resume 参数可以帮助我做到这一点。您知道是否可行吗?
抱歉,我不确定 Weka 能否做到这一点。也许可以把您的问题发布到 weka 用户组?
非常感谢,非常有帮助。能否训练一个神经网络模型,然后在 Weka 中用决策树对训练好的模型进行分类?如果可能,我们该如何做?以及在这种情况下如何使用测试数据集?
是的。
抱歉,我没有示例。
感谢回复。如果您知道其他可以帮助我的来源,并愿意分享,我将非常高兴。
看这里
https://machinelearning.org.cn/help-with-weka/
非常感谢您的指导。
在使用这个时我遇到了一个问题,当我加载模型并用我创建的测试集重新评估时,结果都显示相同的分类,这可能是不对的。
您能否帮我找出可能出错的地方?
谢谢!!
不客气。
也许可以确认您正在进行预测的行都是不同的,并且您期望为每一行都得到不同的预测?
我做了,我甚至复制了原始数据集,并将目标类别留空。结果仍然一样。
但是,我确实使用了一个不同的数据集得到了 2 个不同的结果。但是在每个数据集中,它都保持相同的类别。
这意味着问题出在我的测试数据上吗?
这很奇怪。也许可以尝试在训练数据上进行预测,以确认模型是否正常工作?
今天我弄清楚了原因。我将我的数据集用作 .csv 文件。那两个不同的结果来自两个不同的模型。(我同时处理三个模型,所以是我的错)。
无论如何,通过将 csv 文件转换为 .arff 并将所有数据类型更改为标称型,问题已得到解决。
非常感谢您的时间!!
祝您有美好的一天!
很高兴听到您解决了问题!
请问您能告诉我如何从数据集中提取所有 TP 和 FP 值吗?我之前做过一次,但忘了。我急需帮助,并且想要一个 csv 文件。
TP 和 FP 是根据您的预测计算的。Weka 在 Explorer 中的分类数据集上为您的模型报告这些值。
嗨,Jason,
我想问一下,如果我们不将数据替换为“?”而是将其保留原样(考虑到我正在使用的数据集是具有相似属性的不同数据集),这会改变模型的运作方式吗?
我的意思是,“?”是为了让我们看到模型的表现如何。如果我们保留原始值,模型会有不同的表现吗?
谢谢!
有些模型会出错,它们期望输入是数字。
是的,填充缺失值会使模型表现不同,具体是更好还是更差,取决于填充的类型。
你好,
我正在为特定数据集进行预测,当我使用“Test option”中的百分比分割并尝试将预测结果保存为 csv 格式时,得到的结果只包含预测的测试数据集,而不包含(预测的)训练数据。我想知道是否可以使用“Percentage Split”同时获得训练和测试的预测结果。
感谢您的时间。
据我所知,至少通过界面是不行的。
嗨,Jason,
感谢您的回复。我将尝试通过命令行运行,看看是否能返回训练和测试结果。
另外,当使用 PCA 选择属性时,我的输出屏幕显示如下:
0.8051 1 -0.077ATS2p-0.077ATS3p-0.077ATS1p-0.077Sp-0.077ATS4p…
我的问题是,为什么我无法获得完整的属性,而是以“……”结尾?是否可以保留我的全部结果?如果可以,您能否帮助我?
先谢谢您了。
我怀疑是你的IDE或笔记本导致了这个问题,这也是我建议不使用它们的原因。
https://machinelearning.org.cn/faq/single-faq/why-dont-use-or-recommend-notebooks
你好 Jason,
感谢您的评论,我将尝试通过命令行运行。
不客气。
你好 Jason,
我有一个疑问。是否可以在WEKA分类器工具箱中同时保存多个模型?例如,在我的数据集中,我希望应用所有类型的算法,即基于函数、基于懒惰学习、基于元学习和基于树的算法。
总共有10-15种方法,用于相同的数据集和子集选择。现在,我是否有任何方法可以保存所有这些10-15个模型以供将来参考,或者WEKA一次只允许保存1个模型?
谢谢你
我推荐使用实验者界面。
https://machinelearning.org.cn/compare-performance-machine-learning-algorithms-weka/
Jason,我需要你帮忙。
我正在WEKA中训练模型,并从xampp的MySql数据库中导入数据。我正在xampp上做一个Web应用程序,其中数据将从Web应用程序收集,我的模型需要使用这些数据进行预测。我能将Web服务连接到WEKA吗?你有什么建议?我该如何进行实时预测并将其发送回我的Web应用程序?
抱歉,我不知道如何在Web服务中使用WEKA。
精彩的帖子,谢谢!
不客气。
每次我打开一个保存的模型时,它都不显示结果。请问到底是什么问题?
您有任何错误消息吗?如果您能更详细地描述您的情况,将更容易帮助您。
非常感谢您提供这个易于遵循的教程。它非常直接但很棒。它对我的数据集有效。再次感谢您。
Alka,不客气!
我的WEKA v3.9.6版本尝试失败了!
天哪,WEKA中的预测方法真是令人费解。感觉像作弊。我不确定我是否理解正确?如果我有200列,每列有相同深度的行——矩阵(除行和列名外,均为数值数据),并在其上训练了模型。现在,我想根据提供的模式预测新201列中的数据模式。如果我理解正确,我不能仅仅在同一行的深度处将201列添加到200列的末尾,因为您提到提供的数据集必须与训练模型的“形状”相同(基本上这意味着确切的列/行数)。因此,如果我想为整个新的201列进行预测,我必须将其“嵌入”到这个新的/旧的提供的数据集中。如果我删除整个200列,并用“?”替换其中的行,我就预测了已知数据。所以,我删除了数据集中的第一列,并将整个数据集向左移动,以获得所谓的“?”201列,我希望在新的/旧的提供的数据集中的200列中进行预测。虽然这有点效果,但我得到的是整个列深度的100%相同的错误数值。
autoWEKA分类器出了些问题。也不清楚如何完成训练模型。使用与创建模型相同的分类器,因为我可以在菜单中选择所有其他选项?提供的实践示例教程也没有具体说明这个问题!如果情况是这样,那么有无数个选项可供选择。我的GPU支持CUDA 2.1,足以使用GPU来加速事物(DataMiner和Quasar可以),但WEKA不支持,所以WEKA没有GPU加速,即使是Intel Core-5 3570K CPU,速度也非常慢。
第二次运行AutoWEKA后,经过24小时的运行,并没有成功。AutoWEKA在蓝色命名的文本菜单中生成了许多分类器模型。只有两个成功地将模型重新应用到测试数据集上(模型是在该数据集上生成的),其他所有都导致了各种错误。当使用相同的方法进行预测时,这两个模型都会在重新应用模型到“新”数据集(与第一次使用的数据集相同)时,将预测列填充为“?”而不是数字。
我计划在我的机械工程硕士论文中使用机器学习,专业领域是流体动力学和传热学。现在我必须重新考虑整个方法,完全忽略机器学习部分,或者从头开始。
就我的经验而言,软件只有在使用示例教程时才有效,其他一切都无效!导师应该开始发布“失败教程”,这样我们所有人都可以看到“不该做什么”以及“还有什么无效”,如果考虑到墨菲定律的话,这将是一种更好的方法(就此而言,我不确定我在这里做错了什么……?)。我在网上读到,ANN几乎可以学习任何东西,而且在这方面几乎没有限制(除了硬件)。
WEKA在纸面上(在网上宣传)是我方法的一个有希望的解决方案,但结果却完全失败。更不用说令人困惑的GUI了,对于2023年来说,它应该更直观——一个人必须看教程才能开始使用。没有直接的流程工作流程输入-训练-测试-验证-预测。在已知数据集中使用NN进行预测没有意义,你可以使用插值技术和其他经典统计工具来完成。NN只适用于各种科学领域中的模式识别和模式预测,用于查看模型是模式驱动的还是混乱的。我无法想象有人能成功使用这样的软件,除非你是这种软件的开发者——那样你就可以自己编写代码了。否则,绝大多数人可能会像我一样失败,而且很可能永远不知道自己在做什么。因此,我只是一个用户,我没有更多时间“浪费在失败上”。我只是遵循教程,并阅读了大量的技术论文(纸面上看起来非常不错),但实际上使用该软件非常痛苦,充满了曲折和怪癖,正如我发现的那样。
也许这篇帖子能帮助某人理清思路,避免在WEKA上失败,并尝试使用其他东西,或者完全避免机器学习的“头痛”,选择其他解决方案。难怪人们“跳下机器学习的火车”。我不是在批评NN的核心算法,而是批评所有与之相关的其他东西以及它们的实现方式,包括GUI和使用过程。直到有更用户友好的GUI和更直观的。
你好Ango…请澄清你的问题,以便我们更好地帮助你。
嘿,很棒的教程,我有几个问题。我在模型中进行了一些预测,注意到它最多只能处理100个实例,我想知道是否可以增加这个数字,因为我处理的数据有超过100个数据点。另外,如何将结果转换为CSV文件?
你好Sean…您可能会对以下教程感兴趣:
https://machinelearning.org.cn/applied-machine-learning-weka-mini-course/