数据可视化提供了对数据集中变量的分布和关系的洞察。
这种洞察有助于在建模之前选择要应用的数据准备技术以及可能最适合数据的算法类型。
Seaborn 是一个用于 Python 的数据可视化库,它构建在流行的 Matplotlib 数据可视化库之上,尽管它提供了简单的界面和更美观的绘图。
在本教程中,您将了解 Seaborn 数据可视化在机器学习中的入门。
完成本教程后,您将了解:
- 如何使用条形图、直方图和箱形图总结变量的分布。
- 如何使用折线图和散点图总结关系。
- 如何在同一张图中比较不同类别值下变量的分布和关系。
启动您的项目,阅读我的新书 《Python 机器学习精通》,其中包含分步教程以及所有示例的Python 源代码文件。
让我们开始吧。

如何使用 Seaborn 数据可视化进行机器学习
照片作者:Martin Pettitt,部分权利保留。
教程概述
本教程分为六个部分;它们是:
- Seaborn 数据可视化库
- 折线图
- 条形图
- 直方图
- 箱线图
- 散点图
Seaborn 数据可视化库
Python 中主要的绘图库称为 Matplotlib。
Seaborn 是一个绘图库,它提供了更简单的界面、用于机器学习的绘图的合理默认值,最重要的是,它的绘图比 Matplotlib 中的绘图更具美感。
Seaborn 要求先安装 Matplotlib。
您可以使用 pip 直接安装 Matplotlib,如下所示:
|
1 |
sudo pip install matplotlib |
安装完成后,您可以通过打印版本号来确认该库可以加载和使用,如下所示:
|
1 2 3 |
# matplotlib import matplotlib print('matplotlib: %s' % matplotlib.__version__) |
运行示例将打印 Matplotlib 库的当前版本。
|
1 |
matplotlib: 3.1.2 |
接下来,也可以使用 pip 安装 Seaborn 库:
|
1 |
sudo pip install seaborn |
安装完成后,我们也可以通过打印版本号来确认该库可以加载和使用,如下所示:
|
1 2 3 |
# seaborn import seaborn print('seaborn: %s' % seaborn.__version__) |
运行示例将打印 Seaborn 库的当前版本。
|
1 |
seaborn: 0.10.0 |
要创建 Seaborn 图,您必须导入 Seaborn 库并调用函数来创建图。
重要的是,Seaborn 绘图函数期望数据以 Pandas DataFrame 的形式提供。这意味着,如果您从 CSV 文件加载数据,则必须使用 Pandas 函数,如 read_csv() 将数据加载为 DataFrame。然后,在绘图时,可以通过 DataFrame 名称或列索引来指定列。
要显示图,可以调用 Matplotlib 库的 show() 函数。
|
1 2 3 |
... # 显示图 pyplot.show() |
或者,也可以将图保存到文件,例如 PNG 格式的图像文件。可以使用 Matplotlib 的 savefig() 函数来保存图像。
|
1 2 3 |
... # 保存图 pyplot.savefig('my_image.png') |
现在我们已经安装了 Seaborn,让我们看看在处理机器学习数据时可能需要的一些常用图。
折线图
折线图通常用于呈现定期收集的观测值。
X 轴表示固定间隔,例如时间。Y 轴显示观测值,按 X 轴排序并用线连接。
可以通过调用 lineplot() 函数并传入固定间隔的 X 轴数据和观测值的 Y 轴数据来在 Seaborn 中创建折线图。
我们可以使用 月度汽车销量的时间序列数据集来演示折线图。
该数据集包含两列:“Month”(月份)和“Sales”(销量)。月份将用作 X 轴,销量将绘制在 Y 轴上。
|
1 2 3 |
... # 创建折线图 lineplot(x='Month', y='Sales', data=dataset) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 时间序列数据集的折线图 from pandas import read_csv from seaborn import lineplot from matplotlib import pyplot # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv' dataset = read_csv(url, header=0) # 创建折线图 lineplot(x='Month', y='Sales', data=dataset) # 显示图 pyplot.show() |
运行示例将首先加载时间序列数据集并创建数据的折线图,清晰地显示了销量数据的趋势和季节性。
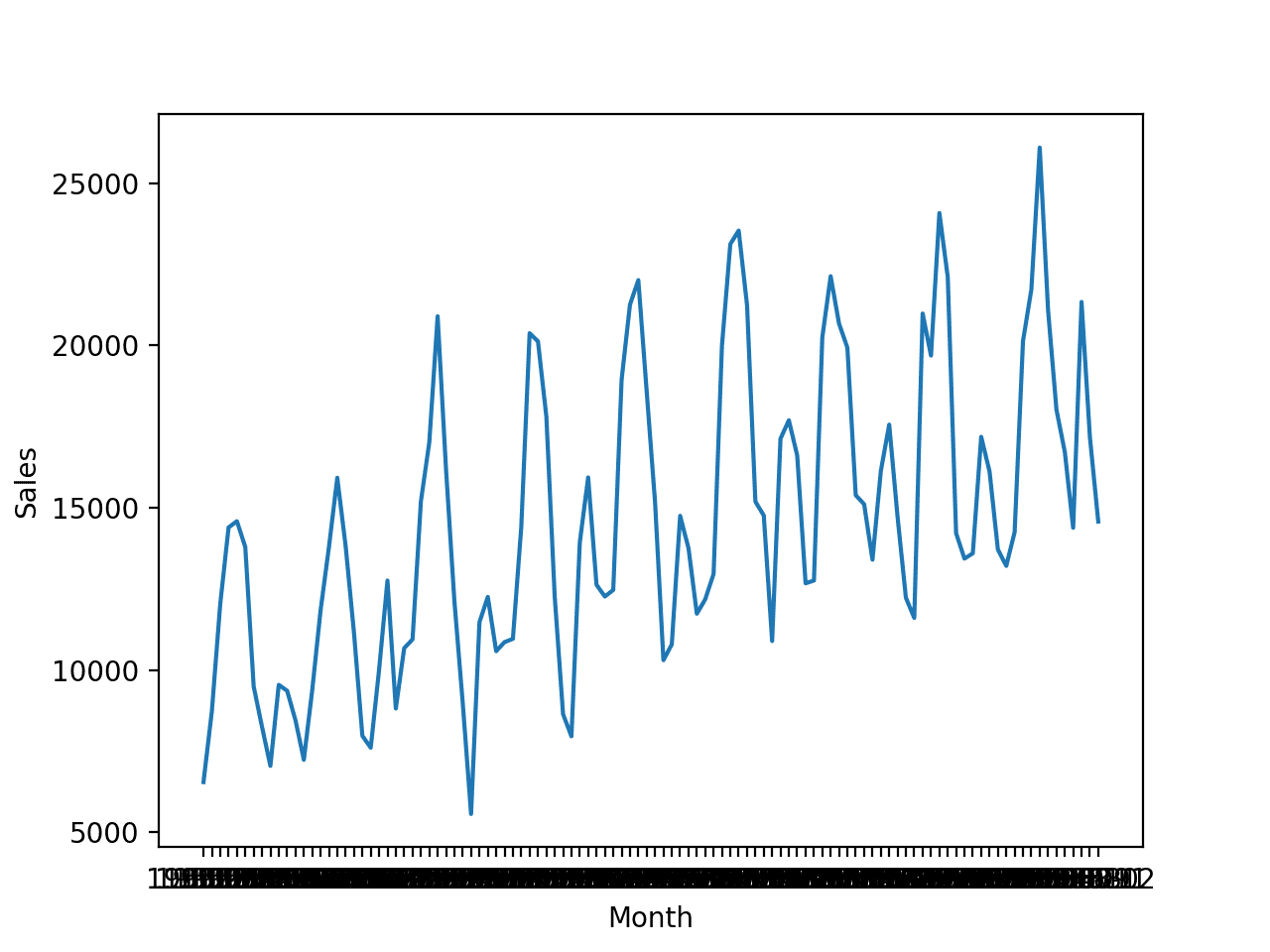
时间序列数据集的折线图
有关 Seaborn 折线图的更多精彩示例,请参阅:可视化统计关系。
条形图
条形图通常用于呈现多个类别的相对数量。
X 轴表示等间距的类别。Y 轴表示每个类别的数量,并绘制为从基线到 Y 轴相应水平的条形。
可以通过调用 countplot() 函数并传入数据来在 Seaborn 中创建条形图。
我们将演示使用 乳腺癌分类数据集中的一个变量创建条形图,该数据集由分类输入变量组成。
我们将只绘制一个变量,在本例中是第一个变量,即年龄段。
|
1 2 3 |
... # 创建折线图 countplot(x=0, data=dataset) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 分类变量的条形图 from pandas import read_csv from seaborn import countplot from matplotlib import pyplot # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv' dataset = read_csv(url, header=None) # 创建条形图 countplot(x=0, data=dataset) # 显示图 pyplot.show() |
运行示例将首先加载乳腺癌数据集并创建数据的条形图,显示每个年龄组以及属于每个组的个体(样本)数量。
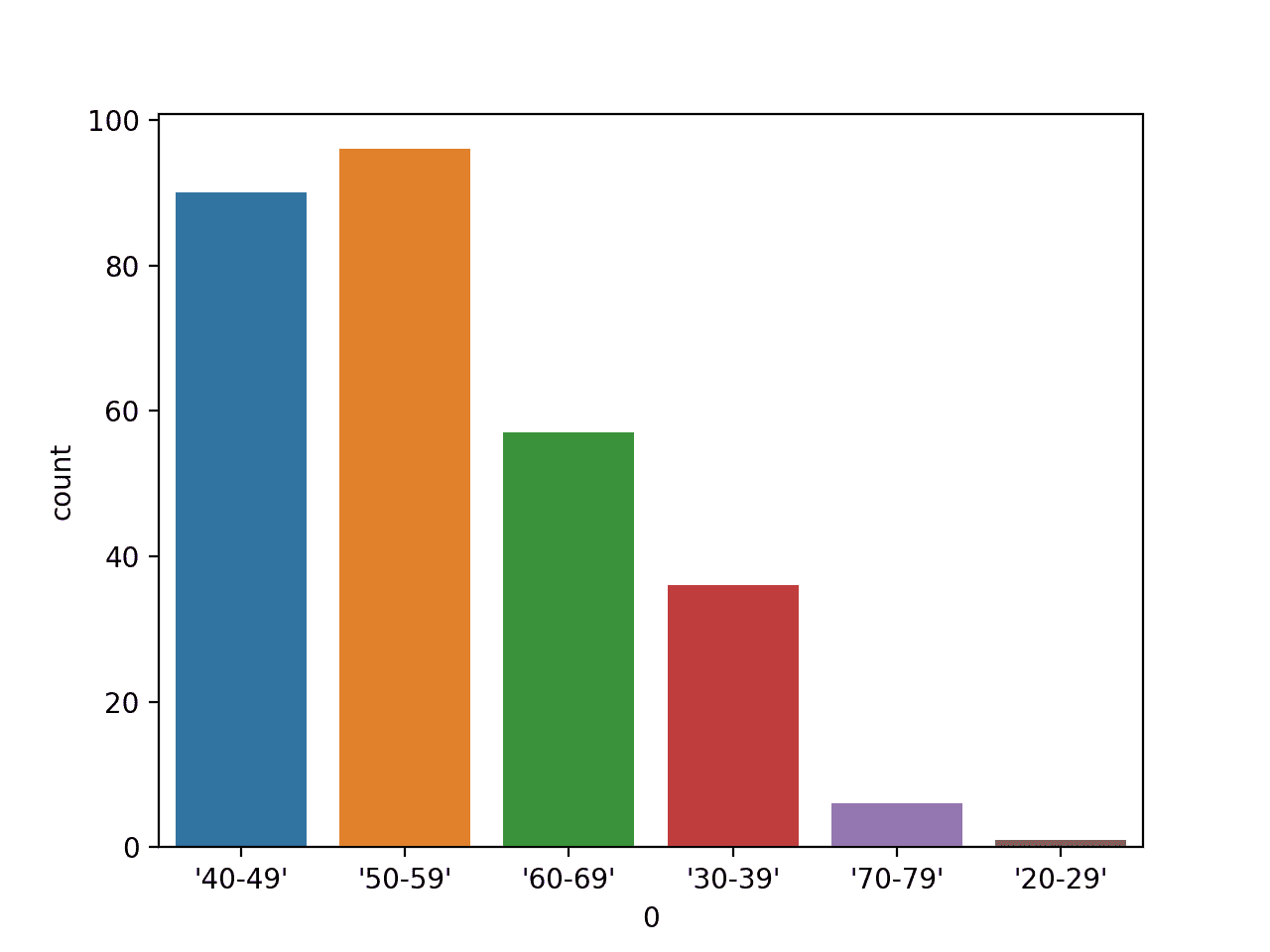
年龄段分类变量的条形图
我们也可能希望绘制每个类别的计数,例如第一个变量,相对于类别标签。
这可以通过使用 countplot() 函数并通过“hue”参数指定类别变量(列索引 9)来实现,如下所示:
|
1 2 3 |
... # 创建条形图 countplot(x=0, hue=9, data=dataset) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 分类变量相对于类别变量的条形图 from pandas import read_csv from seaborn import countplot from matplotlib import pyplot # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv' dataset = read_csv(url, header=None) # 创建条形图 countplot(x=0, hue=9, data=dataset) # 显示图 pyplot.show() |
运行示例将首先加载乳腺癌数据集并创建数据的条形图,显示每个年龄组以及属于每个组的个体(样本)数量,并按数据集的两个类别标签进行区分。
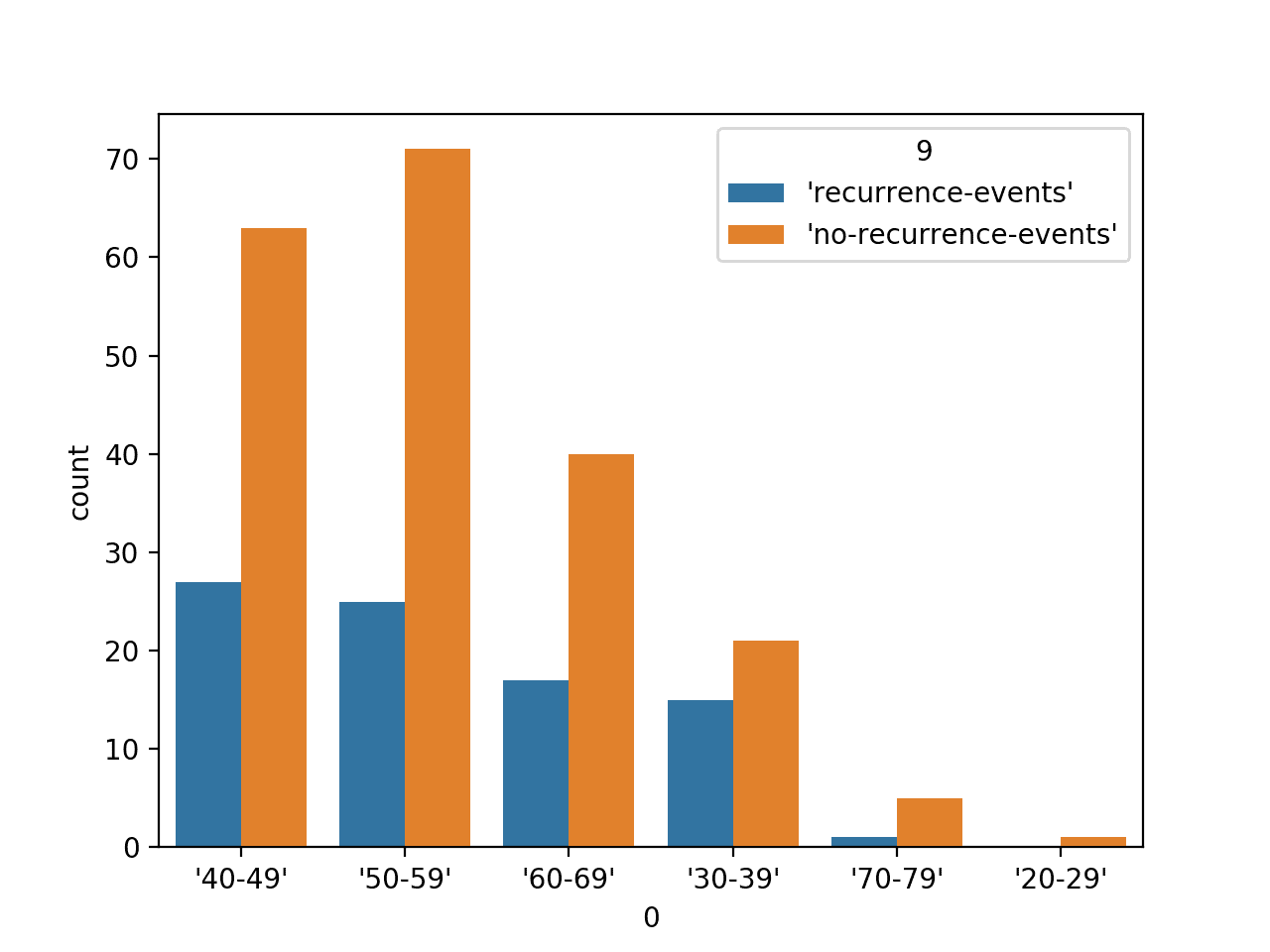
按类别标签划分的年龄段分类变量的条形图
有关 Seaborn 条形图的更多精彩示例,请参阅:绘制分类数据。
直方图
直方图通常用于总结数值数据样本的分布。
X 轴表示离散的 bin 或间隔。例如,值介于 1 和 10 之间的观测值可能被分成五个 bin,值 [1,2] 将分配到第一个 bin,[3,4] 将分配到第二个 bin,依此类推。
Y 轴表示属于每个 bin 的数据集中观测值的频率或计数。
本质上,数据样本被转换为条形图,其中 X 轴上的每个类别代表观测值间隔。
可以通过调用 distplot() 函数并传入变量来在 Seaborn 中创建直方图。
我们将使用 糖尿病分类数据集中的一个数值变量来演示箱形图。我们将只绘制一个变量,在本例中是第一个变量,即患者怀孕的次数。
|
1 2 3 |
... # 创建直方图 distplot(dataset[[0]]) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 数值变量的直方图 from pandas import read_csv from seaborn import distplot from matplotlib import pyplot # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataset = read_csv(url, header=None) # 创建直方图 distplot(dataset[[0]]) # 显示图 pyplot.show() |
运行示例将首先加载糖尿病数据集并创建变量的直方图,显示值的分布,并在零处有一个硬截断。
该图同时显示了直方图(bin 的计数)以及概率密度函数的平滑估计。
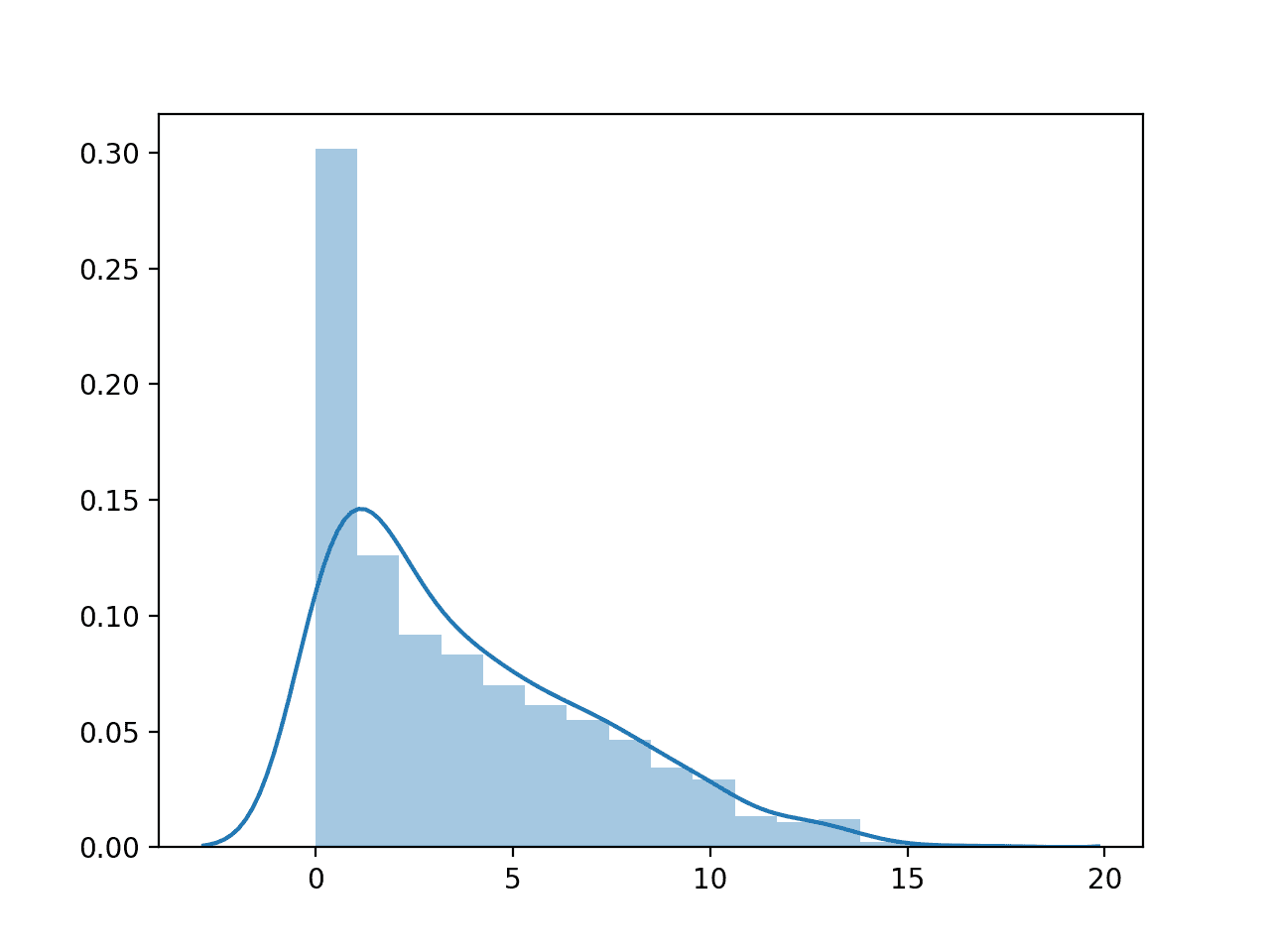
怀孕次数数值变量的直方图
有关 Seaborn 直方图的更多精彩示例,请参阅:可视化数据集的分布。
箱线图
箱形图,或简称 boxplot,通常用于总结数据样本的分布。
X 轴用于表示数据样本,如果需要,可以在 X 轴上并排绘制多个箱形图。
Y 轴表示观测值。绘制一个箱子来总结数据集的中间 50%,从第 25 个百分位数开始,到第 75 个百分位数结束。这称为 四分位距,或 IQR。中位数,或第 50 个百分位数,用一条线表示。
绘制称为须线的线,从箱子的两端延伸,计算为 (1.5 * IQR),以显示分布中合理值的预期范围。须线之外的观测值可能是异常值,并用小圆圈绘制。
可以通过调用 boxplot() 函数并传入数据来在 Seaborn 中创建箱形图。
我们将使用 糖尿病分类数据集中的一个数值变量来演示箱形图。我们将只绘制一个变量,在本例中是第一个变量,即患者怀孕的次数。
|
1 2 3 |
... # 创建箱形图 boxplot(x=0, data=dataset) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 数值变量的箱形图 from pandas import read_csv from seaborn import boxplot from matplotlib import pyplot # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataset = read_csv(url, header=None) # 创建箱形图 boxplot(x=0, data=dataset) # 显示图 pyplot.show() |
运行示例将首先加载糖尿病数据集并创建第一个输入变量的箱形图,显示患者怀孕次数的分布。
我们可以看到中位数略高于 2.5 次,有些异常值高达 15 次(哇!)。
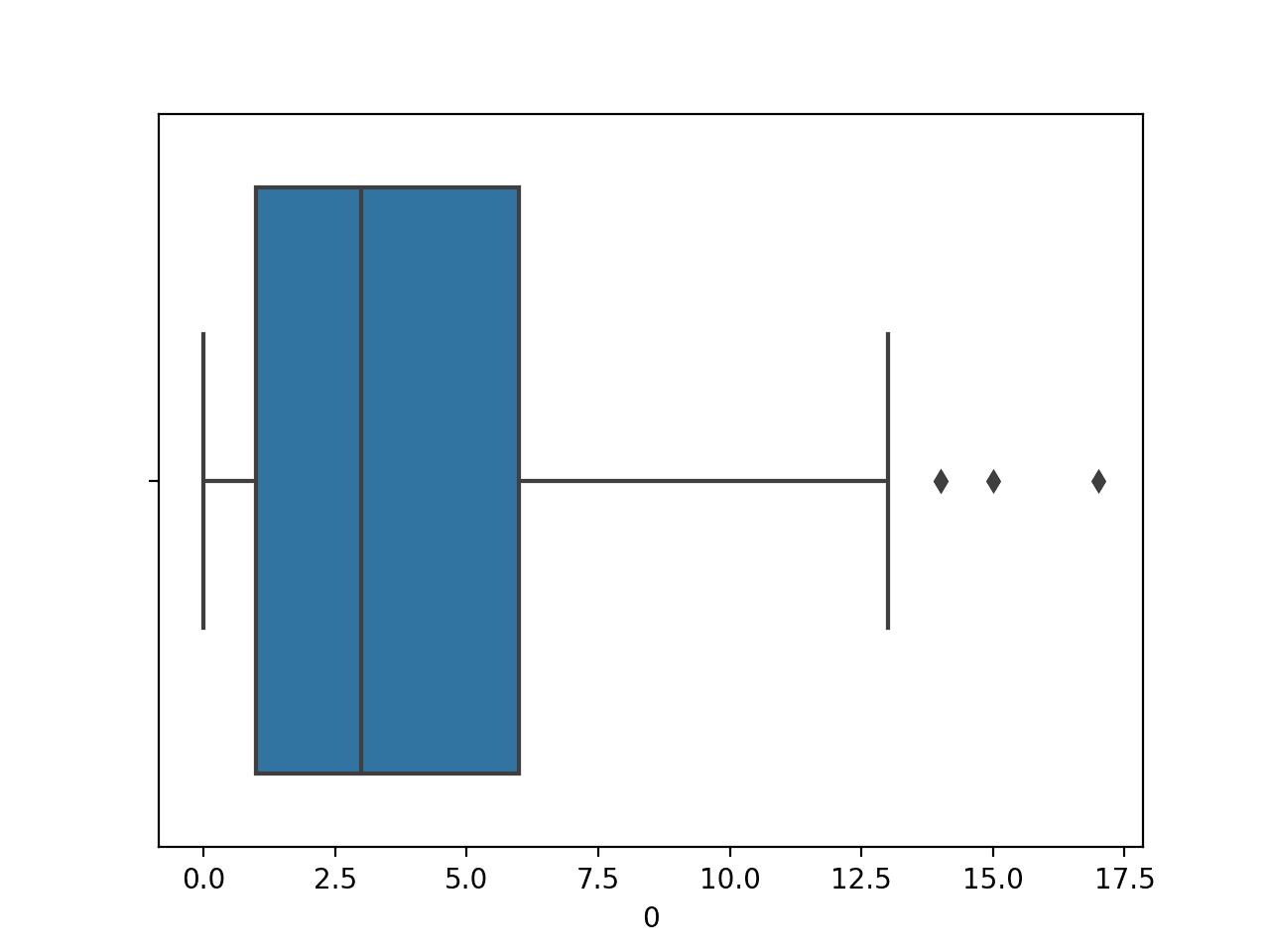
怀孕次数数值变量的箱形图
我们也可能希望绘制数值变量在每个类别值下的分布,例如第一个变量,相对于类别标签。
这可以通过调用 boxplot() 函数并将类别变量作为 X 轴,将数值变量作为 Y 轴来实现。
|
1 2 3 |
... # 创建箱形图 boxplot(x=8, y=0, data=dataset) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 数值变量与类别标签的箱形图 from pandas import read_csv from seaborn import boxplot from matplotlib import pyplot # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataset = read_csv(url, header=None) # 创建箱形图 boxplot(x=8, y=0, data=dataset) # 显示图 pyplot.show() |
运行示例将首先加载糖尿病数据集并创建数据的箱形图,显示怀孕次数作为数值变量在两个类别标签下的分布。
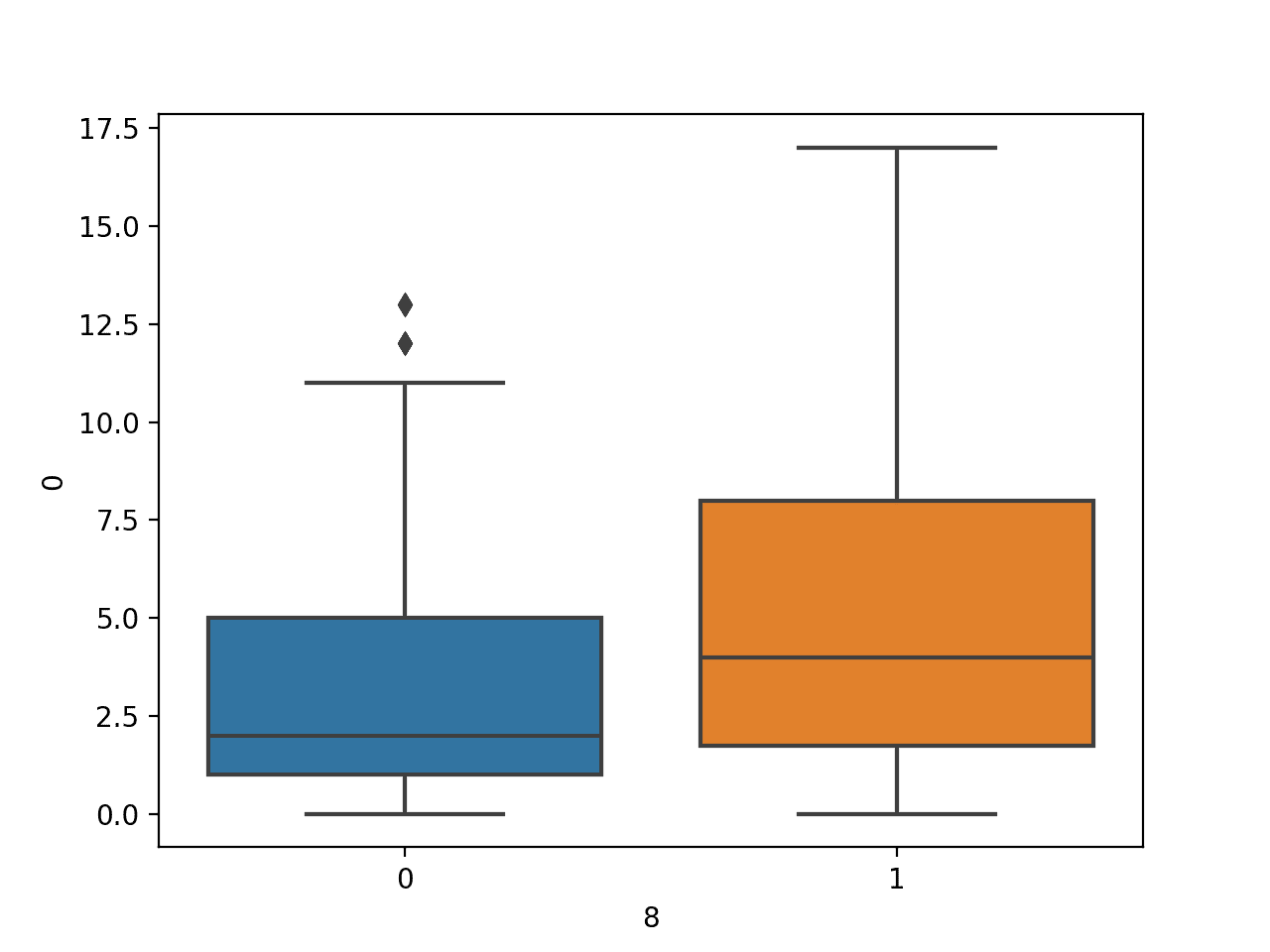
按类别标签划分的怀孕次数数值变量的箱形图
散点图
散点图,或 scatterplot,通常用于总结两个配对数据样本之间的关系。
配对数据样本意味着对某个观测值记录了两个度量,例如一个人的体重和身高。
X 轴表示第一个样本的观测值,Y 轴表示第二个样本的观测值。图上的每个点代表一个单独的观测值。
可以通过调用 scatterplot() 函数并传入两个数值变量来在 Seaborn 中创建散点图。
我们将使用 糖尿病分类数据集中的两个数值变量来演示散点图。我们将绘制第一个变量与第二个变量的关系,在本例中,第一个变量是患者怀孕的次数,第二个变量是口服葡萄糖耐量试验两小时后的血浆葡萄糖浓度(变量的更多详细信息在此)。
|
1 2 3 |
... # 创建散点图 scatterplot(x=0, y=1, data=dataset) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 两个数值变量的散点图 from pandas import read_csv from seaborn import scatterplot from matplotlib import pyplot # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataset = read_csv(url, header=None) # 创建散点图 scatterplot(x=0, y=1, data=dataset) # 显示图 pyplot.show() |
运行示例将首先加载糖尿病数据集并创建前两个输入变量的散点图。
我们可以看到两个变量之间存在某种程度的均匀关系。
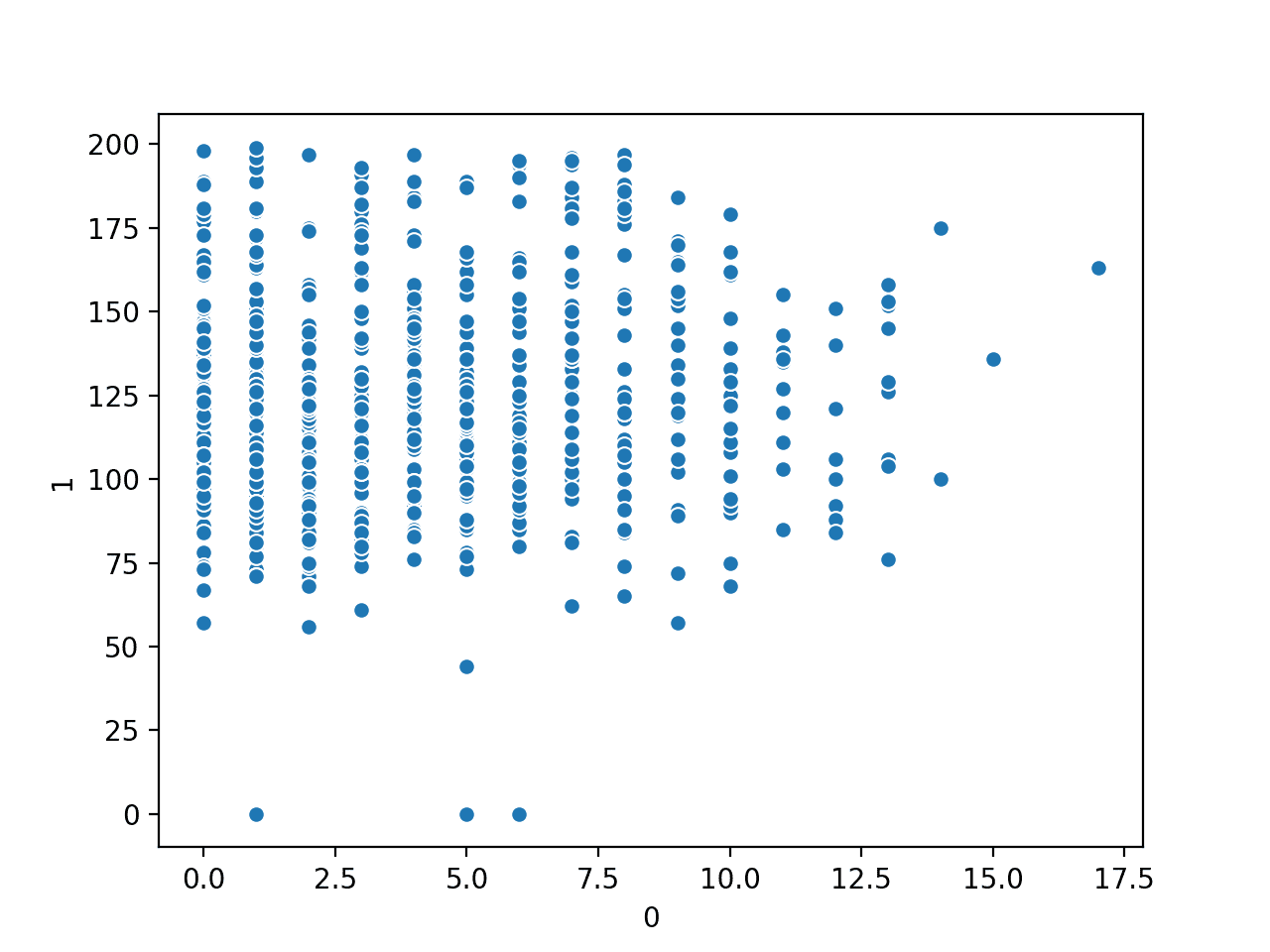
怀孕次数与血浆葡萄糖浓度数值变量的散点图
我们也可能希望绘制数值变量对与类别标签的关系。
这可以通过使用 scatterplot() 函数并通过“hue”参数指定类别变量(列索引 8)来实现,如下所示:
|
1 2 3 |
... # 创建散点图 scatterplot(x=0, y=1, hue=8, data=dataset) |
将这些结合起来,完整的示例列在下面。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 两个数值变量与类别标签的散点图 from pandas import read_csv from seaborn import scatterplot from matplotlib import pyplot # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataset = read_csv(url, header=None) # 创建散点图 scatterplot(x=0, y=1, hue=8, data=dataset) # 显示图 pyplot.show() |
运行示例将首先加载糖尿病数据集并创建前两个变量与类别标签的散点图。
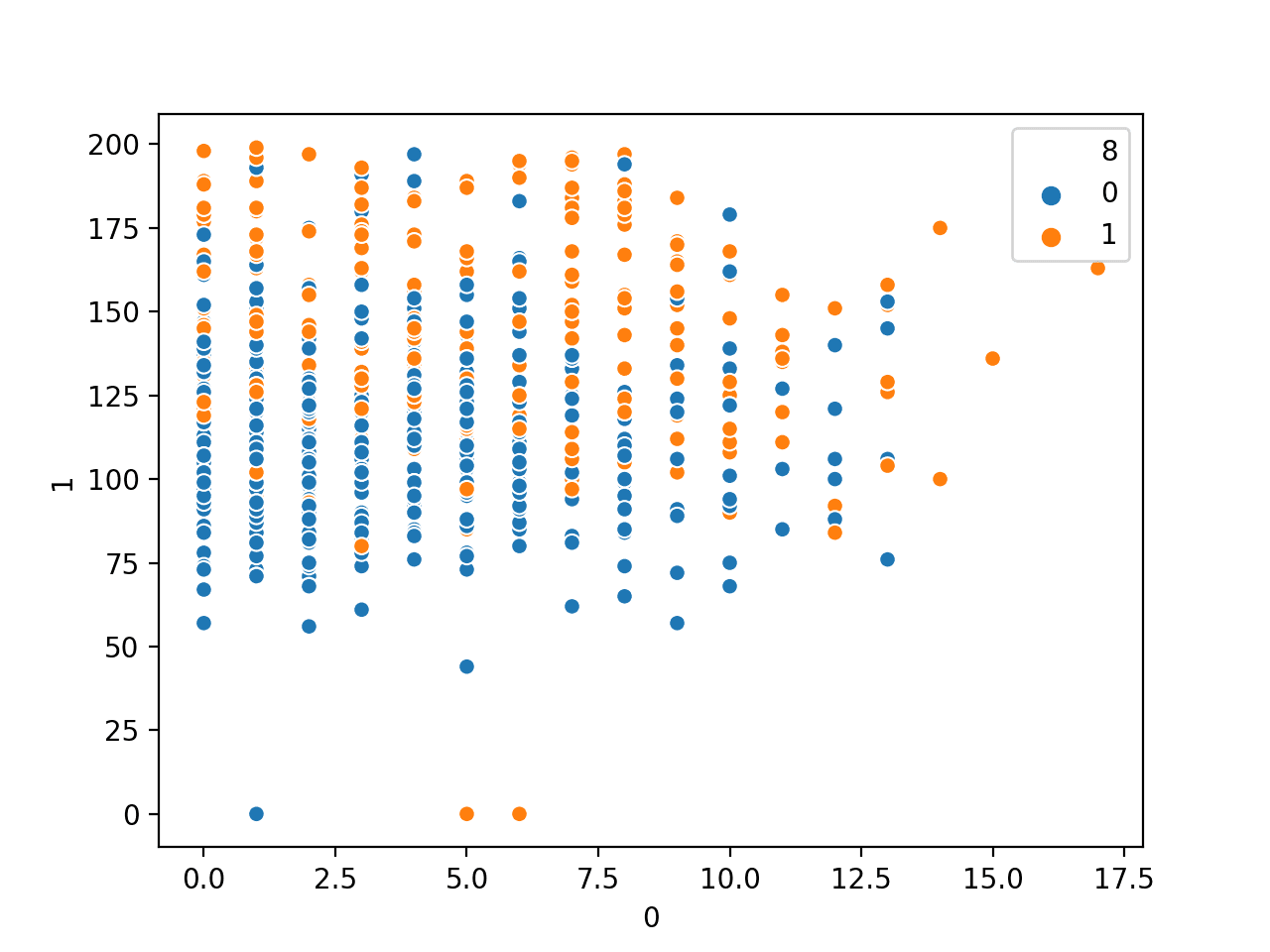
按类别标签划分的怀孕次数与血浆葡萄糖浓度数值变量的散点图
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
API
总结
在本教程中,您了解了 Seaborn 数据可视化在机器学习中的入门。
具体来说,你学到了:
- 如何使用条形图、直方图和箱形图总结变量的分布。
- 如何使用折线图和散点图总结关系。
- 如何在同一张图中比较不同类别值下变量的分布和关系。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
发现 Python 中的快速机器学习!

在几分钟内开发您自己的模型
...只需几行 scikit-learn 代码
在我的新电子书中学习如何操作
精通 Python 机器学习
涵盖自学教程和端到端项目,例如
加载数据、可视化、建模、调优等等...
最终将机器学习带入
您自己的项目
跳过学术理论。只看结果。

")




关于机器学习中数据可视化的宝贵信息和代码。
谢谢!
嗨,Jason,
首先,这条评论与这封信无关。我非常喜欢您的文章,并且几乎完成了其中三篇。我目前正在阅读和学习《Python 深度学习自然语言处理》。我喜欢您的解释,也喜欢您的算法总是能正常工作。我去年获得了分析学理学硕士学位,而您的文章是我顺利完成学位的原因。毕业后,我继续阅读您的文章以保持敏锐。谢谢。
我是一名数学博士、分析学理学硕士教授,在美国佐治亚州亚特兰大的克拉克亚特兰大大学任教。我做了多年的数学教授。然而,如果没有您的书籍,我将无法完成我的分析学理学硕士学位。这引出了我的观点。我的系主任要求我今年秋季教授线性代数。我喜欢线性代数,但距离上次教授这门课程已经过去很多年了。我建议我教授机器学习线性代数;我的系主任对此很感兴趣。因此,我将使用您的书《机器学习基础线性代数…》来首次教授我们 15 到 20 名数学专业的学生。当然,我需要补充变换和对角化等概念,但课程应该会顺利进行。(是的,我也有 Jim Hefferon 的教科书。)
我的问题是:通过我们的书店订购您的书籍的最佳方式是什么?我们的学生有相当于书籍代金券的东西,所以,如果可以通过我们的书店订购您的书籍,我们的学生将能更方便地获得它们。期待您的答复。
Charles Pierre
谢谢!祝贺您获得学位!
Charles,这是一个很好的问题。我经常向班级里的所有学生提供折扣码,或者由大学购买多用户许可并与学生共享书籍。我一直这样做。
联系我,告诉我您偏好的方式,我们可以进行设置。
https://machinelearning.org.cn/contact/
尊敬的Jason博士,
感谢您关于 seaborn 的教程,这是几周前承诺的。
两点
(1) 我想报告一个错误,在我绘制 X[0] 与 X[1] 相对于类别标签 y 的散点图时。
无论我是在 DOS 控制台还是 IDE IDLE 中运行示例,我都得到了以下错误:
版本
(2) 由于 seaborn 与 pyplot 一起使用,您可以添加例如 xlabel、ylabel 和 title。
总结
(1) 绘制按类别标签划分的散点图似乎存在问题。
(2) 由于 seaborn 与 pyplot 一起使用,我们可以使用 pyplot 添加标签。
谢谢你,
悉尼的Anthony
您是说教程中的按类别标签的散点图示例对您不起作用吗?
您是否使用了教程中的相同数据集?
尊敬的Jason博士,
为了回答“我是否……使用了教程中的相同数据集?”这个问题
是的。
代码存储方式
* 前往此页面上的练习。
* 在代码行上方,您的代码示例有一个可以复制文本的工具。
* 有一个提示按下ctrl+C进行复制。
* 按下ctrl+C
* 在文本编辑器Notepad++(不是MS Notepad)中,按下ctrl+V
* 保存为 test.py
在DOS命令行中运行 test.py
结果:上面粘贴的文本出现了那些错误。
回忆以下内容
再次强调,在尝试显示图形时会产生错误。
再次强调,此页面上的其他练习没有出现任何错误。
也许是seaborn的bug?可能需要只使用matplotlib。
谢谢你
悉尼的Anthony
抱歉,我无法解释您看到的故障。
我可以确认您的库版本看起来是正确的。
也许seaborn在Windows上需要额外的配置——我没有Windows机器。
尊敬的Jason博士,
感谢您的回复。
虽然seaborn的scatterplot实现不起作用并不是一个“天塌下来的”结果,但我仍然“用老办法”实现了相同的效果。
结论:“老派”绘图通过多几行代码实现了与“有bug”的seaborn相同的结果。
谢谢你,
悉尼的Anthony
漂亮的解决方法!
尊敬的Jason博士,
从上面的回复中回忆一下产生的错误
我一直在重新尝试seaborn,另一个解决方法是,不是使用scatterplot,而是使用pointplot并设置join=False
我尝试了不同的数据集,结果参差不齐,大多数情况下是错误。
搜索后,据报道,seaborn的scatterplot在matplotlib 3.3.1版本存在bug,参考 https://github.com/mwaskom/seaborn/issues/2194
截至2020年8月21日,seaborn的scatterplot与matplotlib一起工作时存在bug。
谢谢你,
悉尼的Anthony
感谢分享。
尊敬的Jason博士,
为了补充本教程中显示 Pima Indians Diabetes 数据的方法,这里有一个我想分享的“pima-indians-diabetes.csv”数据的成对散点图示例。
以上是 Pima Indians Diabetes 数据按糖尿病状态分类的所有数值数据的成对组合。
我们只显示特征之间的所有成对关系,X,不重复——也就是说,如果我们配对 a 和 b,我们就不配对 b 和 a。
此外,我们不在对角线上显示任何内容,例如kde。
谢谢你,
悉尼的Anthony
尊敬的Jason博士,
忘记提了
抱歉,
悉尼的Anthony
干得不错。
尊敬的Jason博士,
还有一个名为 plotly 的开源图形包,https://plotly.com/python/is-plotly-free/,它具有 MIT 许可证。
它需要安装包
这是 Pima Indians Diabetes 的一个低角且无对角线的散点图。
当调用 fig.show() 时,图形将在默认的互联网浏览器窗口中显示,该窗口的 IP 地址为 127.0.0.1。
您将以与 seaborn 和 matplotlib 的 scatter matrix 相同的方式看到一个 scatter matrix。
这是一个没有对角线(如 kde)的 scatter matrix,只有下半部分。
谢谢你,
悉尼的Anthony
感谢分享。
机器学习是否需要学习 Matplotlib 和 Seaborn?我看了 Google 的机器学习速成课程,他们没有涉及 Matplotlib 和 Seaborn。
https://developers.google.com/machine-learning/crash-course/prereqs-and-prework
它对于查看您的数据非常有帮助。