长短期记忆网络(LSTMs)是一种强大的循环神经网络,能够学习长序列观测值。
LSTMs 的一个优势是它们可能在时间序列预测中表现出色,尽管这种方法在这些用途中以难以配置和使用而闻名。
LSTMs 的一个关键特性是它们保持内部状态,这有助于预测。这就提出了一个问题:在进行预测之前,如何最好地初始化已训练的 LSTM 模型的状态。
在本教程中,你将学习如何设计、执行和解释一个实验的结果,以探讨从训练数据集初始化已训练的 LSTM 状态,还是不使用先前的状态更好。
完成本教程后,您将了解:
- 关于如何最好地初始化用于预测的已训练 LSTM 状态的未决问题。
- 如何开发一个鲁棒的测试框架,用于评估单变量时间序列预测问题上的 LSTM 模型。
- 如何确定在你的时间序列预测问题上,在预测之前初始化 LSTM 状态是否是一个好主意。
通过我的新书《深度学习时间序列预测》启动你的项目,包括分步教程和所有示例的Python 源代码文件。
让我们开始吧。
- 2019 年 4 月更新:更新了数据集链接。

如何在 Python 中为时间序列预测的 LSTM 设置状态
图片来源:Tony Hisgett,保留部分权利。
教程概述
本教程分为 5 个部分,它们是:
- 初始化 LSTM 状态
- 洗发水销售数据集
- LSTM 模型和测试框架
- 代码列表
- 实验结果
环境
本教程假定您已安装 Python SciPy 环境。您可以使用 Python 2 或 3。
你必须安装 Keras(2.0 或更高版本),并使用 TensorFlow 或 Theano 后端。
本教程还假设您已安装 scikit-learn、Pandas、NumPy 和 Matplotlib。
如果您需要帮助设置 Python 环境,请参阅此帖子
初始化 LSTM 状态
在 Keras 中使用无状态 LSTM 时,你可以精确控制何时清除模型的内部状态。
这可以通过使用 model.reset_states() 函数实现。
在训练有状态 LSTM 时,在训练 epoch 之间清除模型状态很重要。这样,在 epoch 训练期间建立的状态与 epoch 中的观测序列是一致的。
鉴于我们有这种精细的控制,就存在一个问题,即在进行预测之前是否以及如何初始化 LSTM 的状态。
选项有:
- 在预测前重置状态。
- 在预测前使用训练数据集初始化状态。
我们假定使用训练数据初始化模型状态会更好,但这需要通过实验证实。
此外,可能有多种方法来初始化此状态;例如:
- 完成一个训练周期,包括权重更新。例如,在最后一个训练周期结束时不要重置。
- 完成训练数据的预测。
通常认为这两种方法大致等效。后一种预测训练数据集的方法更受青睐,因为它不需要修改网络权重,并且对于保存到文件的不可变网络来说,可以是一个可重复的过程。
在本教程中,我们将探讨以下两者之间的区别:
- 使用没有状态的已训练 LSTM 预测测试数据集(例如,重置后)。
- 在预测训练数据集之后,使用具有状态的已训练 LSTM 预测测试数据集。
接下来,让我们看看将在此实验中使用的标准时间序列数据集。
洗发水销售数据集
此数据集描述了 3 年期间洗发水月销量。
单位是销售计数,共有 36 个观测值。原始数据集归功于 Makridakis、Wheelwright 和 Hyndman (1998)。
以下示例加载并创建加载数据集的图表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 加载并绘制数据集 from pandas import read_csv from pandas import datetime from matplotlib import pyplot # 加载数据集 def parser(x): return datetime.strptime('190'+x, '%Y-%m') series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # 总结前几行 print(series.head()) # 线图 series.plot() pyplot.show() |
运行该示例将数据集作为 Pandas Series 加载并打印前 5 行。
|
1 2 3 4 5 6 7 |
月份 1901-01-01 266.0 1901-02-01 145.9 1901-03-01 183.1 1901-04-01 119.3 1901-05-01 180.3 名称:销售额,数据类型:float64 |
然后创建该系列的线图,显示出明显的上升趋势。
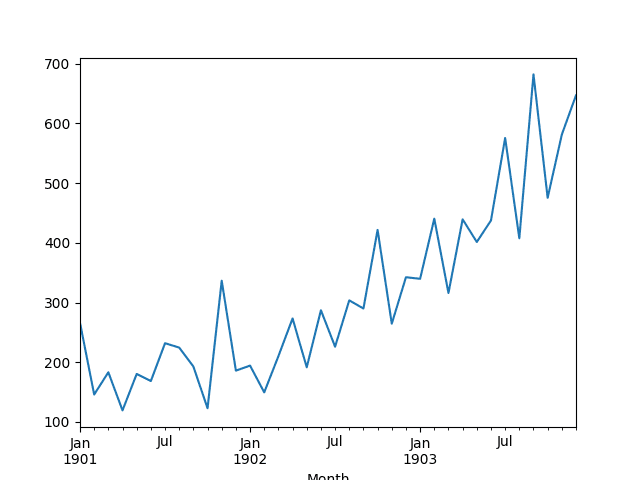
洗发水销售数据集的折线图
接下来,我们将看看实验中使用的LSTM配置和测试框架。
时间序列深度学习需要帮助吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
LSTM 模型和测试框架
数据分割
我们将把洗发水销售数据集分为两部分:训练集和测试集。
前两年的数据将用于训练数据集,剩下的一年数据将用于测试集。
模型将使用训练数据集进行开发,并对测试数据集进行预测。
模型评估
将使用滚动预测方案,也称为向前验证模型。
测试数据集的每个时间步都将逐一进行。模型将用于对该时间步进行预测,然后将从测试集中获取实际期望值,并将其提供给模型用于下一个时间步的预测。
这模拟了现实世界场景,其中每个月都会有新的洗发水销售观察值,并用于预测下个月。
这将通过训练和测试数据集的结构来模拟。我们将以一次性方法完成所有预测。
测试数据集上的所有预测都将被收集,并计算一个误差分数以总结模型的技能。将使用均方根误差(RMSE),因为它会惩罚大错误,并得到一个与预测数据单位相同的分数,即每月洗发水销售额。
数据准备
在我们使用 LSTM 模型拟合数据集之前,我们必须转换数据。
在拟合模型和进行预测之前,对数据集执行以下三种数据转换。
- 转换时间序列数据使其平稳。具体来说,使用 lag=1 差分以消除数据中的递增趋势。
- 将时间序列转换为监督学习问题。具体来说,将数据组织成输入和输出模式,其中前一个时间步的观测值用作输入,以预测当前时间步的观测值。
- 转换观测值以具有特定比例。具体来说,将数据重新缩放到-1到1之间的值,以满足LSTM模型的默认双曲正切激活函数。
LSTM 模型
将使用一个熟练但未调整的 LSTM 模型配置。
这意味着模型将适应数据并能够进行有意义的预测,但它不会是数据集的最佳模型。
网络拓扑由 1 个输入,一个具有 4 个单元的隐藏层,以及一个具有 1 个输出值的输出层组成。
模型将以 4 的批次大小训练 3,000 个 epoch。数据准备后,训练数据集将减少到 20 个观测值。这是为了使批次大小能够均匀地划分训练数据集和测试数据集(这是必需的)。
实验运行
每个场景将运行 30 次。
这意味着每个场景将创建和评估 30 个模型。每次运行的 RMSE 将被收集,从而提供一个结果群体,可以使用均值和标准差等描述性统计数据进行总结。
这是必需的,因为像 LSTM 这样的神经网络受到其初始条件(例如其初始随机权重)的影响。
每个场景的平均结果将使我们能够解释每个场景的平均行为以及它们之间的比较。
让我们深入了解结果。
代码列表
关键的模块化行为被分离成函数,以提高可读性和可测试性,以防你希望重用此实验设置。
场景的具体细节在 experiment() 函数中描述。
完整的代码列表如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 |
from pandas import DataFrame from pandas import Series 从 pandas 导入 concat from pandas import read_csv from pandas import datetime from sklearn.metrics import mean_squared_error 从 sklearn.预处理 导入 MinMaxScaler from keras.models import Sequential from keras.layers import Dense 从 keras.layers 导入 LSTM from math import sqrt import matplotlib # 能够在服务器上保存图像 matplotlib.use('Agg') from matplotlib import pyplot import numpy # 用于加载数据集的日期时间解析函数 def parser(x): return datetime.strptime('190'+x, '%Y-%m') # 将序列构造成监督学习问题 def timeseries_to_supervised(data, lag=1): df = DataFrame(data) columns = [df.shift(i) for i in range(1, lag+1)] columns.append(df) df = concat(columns, axis=1) df = df.drop(0) return df # 创建差分序列 def difference(dataset, interval=1): diff = list() for i in range(interval, len(dataset)): value = dataset[i] - dataset[i -interval] diff.append(value) return Series(diff) # 反转差分值 def inverse_difference(history, yhat, interval=1): return yhat + history[-interval] # 将训练和测试数据缩放到 [-1, 1] def scale(train, test): # 拟合缩放器 scaler = MinMaxScaler(feature_range=(-1, 1)) scaler = scaler.fit(train) # 转换训练集 train = train.reshape(train.shape[0], train.shape[1]) train_scaled = scaler.transform(train) # 转换测试集 test = test.reshape(test.shape[0], test.shape[1]) test_scaled = scaler.transform(test) return scaler, train_scaled, test_scaled # 预测值的逆缩放 def invert_scale(scaler, X, yhat): new_row = [x for x in X] + [yhat] array = numpy.array(new_row) array = array.reshape(1, len(array)) inverted = scaler.inverse_transform(array) return inverted[0, -1] # 训练一个 LSTM 网络 def fit_lstm(train, batch_size, nb_epoch, neurons): X, y = train[:, 0:-1], train[:, -1] X = X.reshape(X.shape[0], 1, X.shape[1]) model = Sequential() model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') for i in range(nb_epoch): model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False) model.reset_states() return model # 进行一步预测 def forecast_lstm(model, batch_size, X): X = X.reshape(1, 1, len(X)) yhat = model.predict(X, batch_size=batch_size) return yhat[0,0] # 运行重复实验 def experiment(repeats, series, seed): # 将数据转换为平稳 raw_values = series.values diff_values = difference(raw_values, 1) # 将数据转换为监督学习 supervised = timeseries_to_supervised(diff_values, 1) supervised_values = supervised.values # 将数据分割成训练集和测试集 train, test = supervised_values[0:-12], supervised_values[-12:] # 转换数据尺度 scaler, train_scaled, test_scaled = scale(train, test) # 运行实验 error_scores = list() for r in range(repeats): # 拟合模型 batch_size = 4 train_trimmed = train_scaled[2:, :] lstm_model = fit_lstm(train_trimmed, batch_size, 3000, 4) # 预测整个训练数据集以建立预测状态 if seed: train_reshaped = train_trimmed[:, 0].reshape(len(train_trimmed), 1, 1) lstm_model.predict(train_reshaped, batch_size=batch_size) # 预测测试数据集 test_reshaped = test_scaled[:,0:-1] test_reshaped = test_reshaped.reshape(len(test_reshaped), 1, 1) output = lstm_model.predict(test_reshaped, batch_size=batch_size) predictions = list() for i in range(len(output)): yhat = output[i,0] X = test_scaled[i, 0:-1] # 反转缩放 yhat = invert_scale(scaler, X, yhat) # 反转差分 yhat = inverse_difference(raw_values, yhat, len(test_scaled)+1-i) # 存储预测 predictions.append(yhat) # 报告性能 rmse = sqrt(mean_squared_error(raw_values[-12:], predictions)) print('%d) Test RMSE: %.3f' % (r+1, rmse)) error_scores.append(rmse) return error_scores # 加载数据集 series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser) # experiment repeats = 30 results = DataFrame() # 有状态初始化 with_seed = experiment(repeats, series, True) results['with-seed'] = with_seed # 无状态初始化 without_seed = experiment(repeats, series, False) results['without-seed'] = without_seed # 总结结果 print(results.describe()) # save boxplot results.boxplot() pyplot.savefig('boxplot.png') |
实验结果
运行实验需要一些时间或 CPU/GPU 硬件。
每次运行的 RMSE 都将打印出来,以显示进度。
运行结束时,会计算并打印每个场景的汇总统计数据,包括平均值和标准差。
注意:鉴于算法或评估过程的随机性,或者数值精度的差异,您的结果可能有所不同。请考虑多次运行该示例并比较平均结果。
完整输出如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
1) 测试 RMSE: 86.566 2) 测试 RMSE: 300.874 3) 测试 RMSE: 169.237 4) 测试 RMSE: 167.939 5) 测试 RMSE: 135.416 6) 测试 RMSE: 291.746 7) 测试 RMSE: 220.729 8) 测试 RMSE: 222.815 9) 测试 RMSE: 236.043 10) 测试 RMSE: 134.183 11) 测试 RMSE: 145.320 12) 测试 RMSE: 142.771 13) 测试 RMSE: 239.289 14) 测试 RMSE: 218.629 15) 测试 RMSE: 208.855 16) 测试 RMSE: 187.421 17) 测试 RMSE: 141.151 18) 测试 RMSE: 174.379 19) 测试 RMSE: 241.310 20) 测试 RMSE: 226.963 21) 测试 RMSE: 126.777 22) 测试 RMSE: 197.340 23) 测试 RMSE: 149.662 24) 测试 RMSE: 235.681 25) 测试 RMSE: 200.320 26) 测试 RMSE: 92.396 27) 测试 RMSE: 169.573 28) 测试 RMSE: 219.894 29) 测试 RMSE: 168.048 30) 测试 RMSE: 141.638 1) 测试 RMSE: 85.470 2) 测试 RMSE: 151.935 3) 测试 RMSE: 102.314 4) 测试 RMSE: 215.588 5) 测试 RMSE: 172.948 6) 测试 RMSE: 114.746 7) 测试 RMSE: 205.958 8) 测试 RMSE: 89.335 9) 测试 RMSE: 183.635 10) 测试 RMSE: 173.400 11) 测试 RMSE: 116.645 12) 测试 RMSE: 133.473 13) 测试 RMSE: 155.044 14) 测试 RMSE: 153.582 15) 测试 RMSE: 146.693 16) 测试 RMSE: 95.455 17) 测试 RMSE: 104.970 18) 测试 RMSE: 127.700 19) 测试 RMSE: 189.728 20) 测试 RMSE: 127.756 21) 测试 RMSE: 102.795 22) 测试 RMSE: 189.742 23) 测试 RMSE: 144.621 24) 测试 RMSE: 132.053 25) 测试 RMSE: 238.034 26) 测试 RMSE: 139.800 27) 测试 RMSE: 202.881 28) 测试 RMSE: 172.278 29) 测试 RMSE: 125.565 30) 测试 RMSE: 103.868 带种子 不带种子 计数 30.000000 30.000000 均值 186.432143 146.600505 标准差 52.559598 40.554595 最小值 86.565993 85.469737 25% 143.408162 115.221000 50% 180.899814 142.210265 75% 222.293194 173.287017 最大值 300.873841 238.034137 |
还创建并保存了一个箱线图到文件,如下所示。
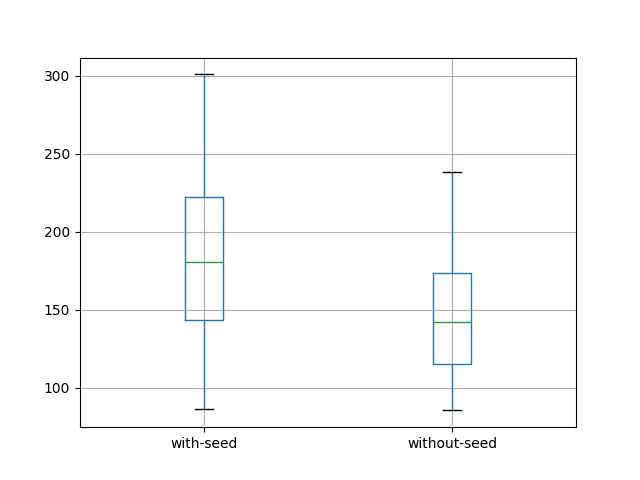
带有和不带状态种子的LSTM箱线图
结果令人惊讶。
它们表明,在预测测试数据集之前不给LSTM的状态设置种子,可以获得更好的结果。
这可以从平均误差较低的146.600505(每月洗发水销量)与186.432143(设置种子)进行比较中看出。在分布的箱线图中更为清晰。
也许所选的模型配置导致模型过小,以至于它不依赖于序列和内部状态来受益于预测前的种子设置。也许需要更大的实验。
扩展
这些令人惊讶的结果为进一步的实验打开了大门。
- 评估在最后一个训练时期结束后是否清除状态的影响。
- 评估一次性预测训练集和测试集与一次预测一个时间步长的影响。
- 评估在每个时期结束时是否重置LSTM状态的影响。
您是否尝试了其中一个扩展?在下面的评论中分享您的发现。
总结
在本教程中,您学习了如何通过实验确定在单变量时间序列预测问题上为LSTM模型状态设置种子的最佳方法。
具体来说,你学到了:
- 关于在预测之前为LSTM状态设置种子的问题以及解决这些问题的方法。
- 如何开发一个强大的测试工具来评估时间序列预测的LSTM模型。
- 如何确定在预测之前是否使用训练数据为LSTM模型状态设置种子。
您是否运行了实验或修改版本的实验?
在评论中分享您的结果;我很乐意看到它们。
您对这篇文章有任何疑问吗?
请在下面的评论中提出您的问题,我将尽力回答。
立即开发时间序列深度学习模型!

在几分钟内开发您自己的预测模型
...只需几行python代码
在我的新电子书中探索如何实现
用于时间序列预测的深度学习
它提供关于以下主题的自学教程:
CNN、LSTM、多元预测、多步预测等等...
最终将深度学习应用于您的时间序列预测项目
跳过学术理论。只看结果。






好文章!!想知道这是否会扩展到多变量情况?
非常感谢,
祝好,
安德鲁
谢谢Andrew,是的,我很快就会发布关于多变量情况的文章。
谢谢 Jason。
收到以下错误
ValueError: 在有状态网络中,您只能传入样本数量可以被批大小整除的输入。找到:19个样本
只将模型拟合循环中的时期(epochs)更改为nb_epoch=1,否则会收到
TypeError: 收到未知关键字参数:{'epochs': 1}
有什么建议吗?
谢谢
看起来您需要将Keras更新到2.0或更高版本。
这是一篇神奇的文章。从中受益匪浅。
我是深度学习和Keras的新手,也遇到了同样的问题。我注意到变量“train_scaled”的长度是21,
train_trimmed = train_scaled[2:, :]
作者将train_trimmed的起始索引设为2,所以我尝试将其改为
train_trimmed = train_scaled[1:, :]
也许这样可行。
感谢您的文章。但我不知道shampoo-sales.csv在哪里。
Leslie,你可以从这里下载它
https://datamarket.com/data/set/22r0/sales-of-shampoo-over-a-three-year-period
安装了最新的theano和tensorflow版本,收到了以下错误。有什么想法吗?谢谢。
回溯(最近一次调用)
文件“C:/Users/Myamoto/PycharmProjects/01.04.17_SentdexTensorflowWHD/errorfindentensorundkeras.py”,第143行,位于
with_seed = experiment(repeats, series, True)
文件“C:/Users/Myamoto/PycharmProjects/01.04.17_SentdexTensorflowWHD/errorfindentensorundkeras.py”,第111行,位于experiment
lstm_model = fit_lstm(train_trimmed, batch_size, 3000, 4)
文件“C:/Users/Myamoto/PycharmProjects/01.04.17_SentdexTensorflowWHD/errorfindentensorundkeras.py”,第81行,位于fit_lstm
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
文件“C:\Users\Myamoto\Anaconda3\lib\site-packages\keras\models.py”,第853行,位于fit
initial_epoch=initial_epoch)
文件“C:\Users\Myamoto\Anaconda3\lib\site-packages\keras\engine\training.py”,第1406行,位于fit
batch_size=batch_size)
文件“C:\Users\Myamoto\Anaconda3\lib\site-packages\keras\engine\training.py”,第1318行,位于_standardize_user_data
str(x[0].shape[0]) + ‘ samples’)
ValueError: 在有状态网络中,您只能传入样本数量可以被批大小整除的输入。找到:19个样本
是的,您需要以不同的方式分割数据或更改批处理大小。
谢谢Jason的这个教程。
上面的代码显示,“不带种子”是我的原始数据也要遵循的方法。
我还能够用单个超参数(如批处理大小、神经元、周期等)从更大的批处理环境中向模型提供数据。
现在是我个人永无止境的障碍。
如果我将重复次数减少到一次,然后说……
# 将数据分为训练集和测试集
而不是
train, test = supervised_values[0:-12], supervised_values[-12:]
train, test = supervised_values[0:-1], supervised_values[-1:]
……我可以通过拟合模型获得我自己的原始数据中包含的最后一个数据值的“实时预测”。
但我需要对未知数据进行一步提前预测。
我能够用其他一些模型做到这一点,但从未成功使用LSTM模型。
您将如何补充此代码以对未知数据进行一步提前预测?
不要使用此设置进行预测。此设置用于评估模型技能。
在所有数据上拟合模型,然后调用 model.predict(x),其中 x 是进行样本外预测所需的输入。
有没有关于如何完成LSTM模型,包括一步提前预测的例子?
实际上,我以为我可以单独使用fit_lstm和forecast_lstm函数。为什么不能这样做?
我有
unseenPredict = forecast_lstm(classRefSample.lstm_model, classRefSample.batch_size, X)
同时将训练好的模型和实验参数存储在外部类对象中。
我的问题是X的结构。
即如何单独使用 test_reshaped、test_scaled、invert_scale 和 inverse_difference,以及测试分区部分中只有一个数据行的最后已知观测值。
有没有关于如何单独使用这些方法的指南?
我们如何将test_reshaped转换回其原始值?
你好,
您只有一个时间序列。批次大小大于1有什么意义?
如果您只有一个样本且批次大小大于1,那么它没有效果。批次大小将为1(据我所知)。
感谢这篇有用的文章,
是否可以使用fit()(在训练集上,不重置状态)而不是使用predict()来为网络设置种子?
是的。试试看它是否会产生差异。
当将LSTM参数设置为有状态时,预测单变量时间序列时批处理大小是否需要为1
批次大小不一定非得是1。
为什么增加数据分割百分比会给我带来糟糕的结果。
结果应该会改善吗?
也许模型用于训练的数据更少,或者误差估计现在更准确了?
我真的很喜欢您出色的文章!我找到了我几乎需要的一切。非常感谢!
我想使用LSTM解决序列数据预测问题(多步预测/序列到序列?)。
这是一个非常简单的案例,只有一个样本。历史数据有1-30个按序列排列的观测值(每个步骤一个观测值)。
在第10步索引处,有10个按序列排列的观测值,预测第30步索引处的值。
在第11步,有11个按序列排列的观测值(一个新的观测值),预测第30步处的值……
这是seq2seq问题还是多步预测?
正如您所提到的,我们应该在进行预测之前调整LSTM或种子状态以找到一个好的LSTM模型。我购买了电子书“使用Python的长短期记忆网络”和“深度学习时间序列预测”。但我没有找到包含调整LSTM模型、预测前设置种子状态和当新观测值可用时更新模型(所有这些过程都为了进行相对准确的预测)的多步预测/seq2seq的完整代码。
我想知道您是否在某个地方(博客或电子书)有这样的例子,但我没有找到……
非常感谢!
谢谢。
这将作为第一步提供帮助
https://machinelearning.org.cn/faq/single-faq/how-do-you-use-lstms-for-multi-step-time-series-forecasting
那么也许可以遵循这个过程
https://machinelearning.org.cn/start-here/#deep_learning_time_series