
选择正确的特征工程策略:一种决策树方法。
作者 | Ideogram 提供图片
在机器学习模型开发中,特征工程起着至关重要的作用,因为现实世界的数据经常伴随着噪声、缺失值、偏斜分布,甚至格式不一致。因此,特征工程包含了一系列广泛的技术,用于在模型训练或分析之前,将原始特征转换为更好、更一致的形式。
为了帮助您识别适用于您数据集特征的正确特征工程方法,本文提供了一个基于决策树的指南,根据数据的细微差别和类型,引导您找到最合适的策略。
选择正确特征工程策略的决策树指南
此决策树旨在作为核心视觉辅助工具,帮助您在构建机器学习模型或进行其他高级数据分析任务之前,选择要应用于您数据集的特征工程策略。
为什么是“策略”(复数)?您的数据集通常可能包含多个特征,其中许多可能需要应用各自的特征工程策略。我们是否仍然需要应用多个策略(再次是复数)而不是一个策略来处理特定属性?嗯,有时是这样。
例如,如果一个数值属性是偏斜的,并且也被用于基于距离的模型,您可能希望将属性值标准化为 z-scores(参见上图),并将其与另一个数值属性一起用于应用乘法交互,从而生成一个新颖、信息更丰富的特征。更不用说,您可能还希望添加一个额外属性来“标记”包含异常值的实例,如后文所述。
让我们深入探讨并揭示树中提到的部分技术和数据特性,以便您更好地理解何时以及为何使用它们。
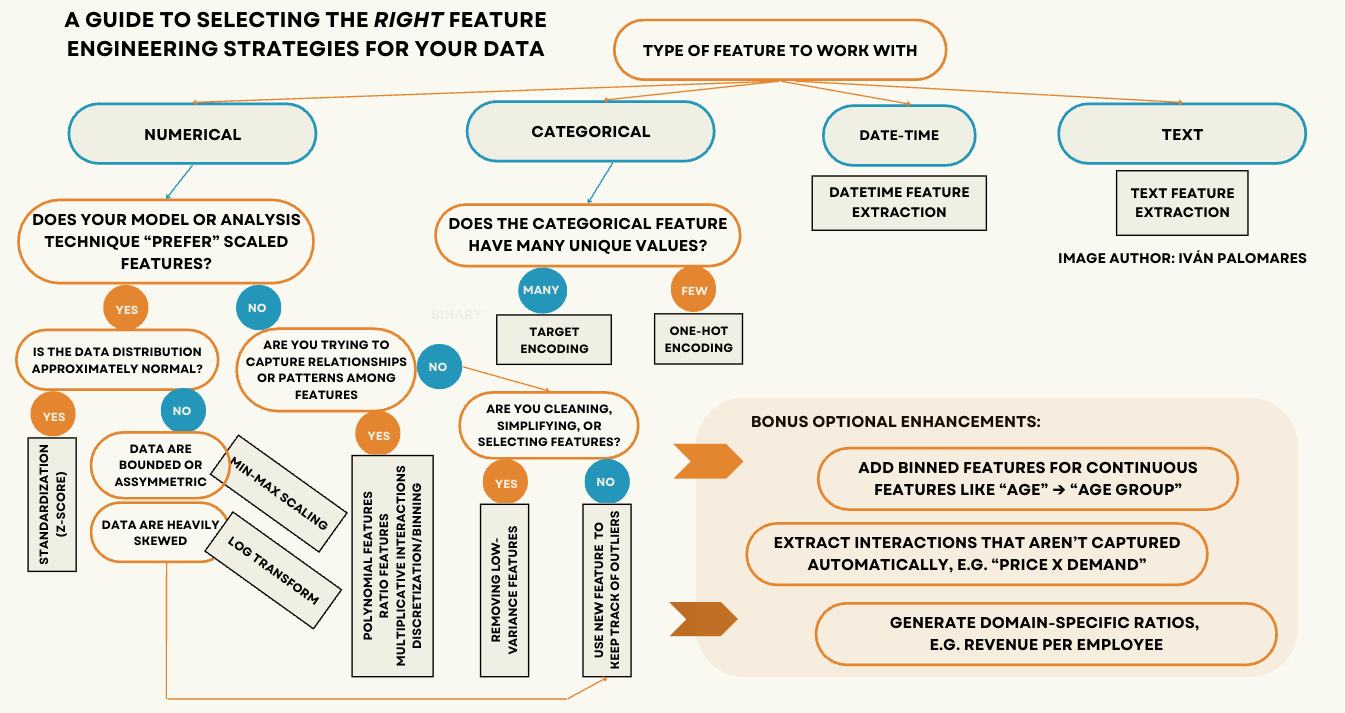
选择正确的特征工程技术(点击放大)
作者提供图片
数值特征
首先,许多机器学习算法要求数值数据进行适当的缩放,因为特征范围的差异会负面影响模型性能。例如,在具有距离度量或梯度下降优化的模型中,具有大范围的特征(如房价)可能会主导其他特征。值得庆幸的是,像scikit-learn这样的流行 Python 库提供了无缝处理这些过程的实现。
常见的特征缩放类型包括标准化(z-scores),当数据近似正态分布且不存在极端异常值时很有用。同时,最小-最大缩放(将特征中的值归一化到单位区间 [0, 1])适用于保留相对关系和原始值分布很关键的情况。最后,如果您的特征分布严重偏斜,对数(log)变换有助于“压缩”过大的值,并使分布更接近正态。
特征工程最常见的目标之一是捕获两个或多个现有特征之间的关系或模式,创建反映这些交互的新特征。多项式特征提取、计算比率、应用乘法交互或离散化高粒度的连续特征等方法,可以通过使这些潜在关系更明确来提高模型性能。这些技术可以帮助非交互感知模型(如线性回归)捕捉非线性,同时保持良好的模型可解释性。
除了已讨论的策略外,我们还可能希望通过删除方差非常小的特征来简化我们的特征集:这些特征通常为模型执行推断提供很少或没有有用的信息。此外,虽然异常值有时可能提供信息,但创建新的布尔特征来跟踪它们可能会很有用,从而使您的模型或分析能够区分典型和非典型观测值。
非数值特征:分类、日期时间文本
那么非数值特征呢?虽然绝大多数机器学习算法和模型都设计为主要处理数值信息,但也有方法可以编码其他类型的数据,通常以这些模型可以解析的数值格式。
分类特征通常有少量可能的取值(类别)。例如,一种纺织品可能只有四种可选颜色之一。在这些情况下,独热编码(创建多个二元列——每个类别一列)是最常见的方法。相反,对于具有许多可能取值的分类属性(例如,一个人属于某个国家的州或省),目标编码是一种更有效的策略。这包括将每个类别替换为该类别目标变量的平均值,使模型能够保留有用信息而不增加特征空间。此策略应谨慎使用,以避免潜在的数据泄露。
日期时间特征提取是获取结构化变量(如一天中的小时、月份中的日期,或日期是否落在工作日、周末或假期)的常见任务。这些特征可以揭示时间序列数据中的现象,如季节性、趋势或与预测分析和建模相关的行为模式。
文本特征提取对于处理非结构化文本的机器学习模型很有用。这通常通过将文本转换为数值表示来完成,包括词频、词频-逆文档频率 (TF-IDF) 或词嵌入,使模型能够有效地理解和利用文本数据。
总结
本文提供了一个面向决策树的指南,用于选择正确的功能工程技术和策略,以应用于各种数据集和功能,然后进行进一步的分析过程和机器学习建模。特征工程通常是将原始数据转化为有价值的输入的关键,以便模型能够充分利用它们并发挥最佳作用。






暂无评论。