许多机器学习模型在建模前对输入变量进行仔细的转换或缩放时,性能会更好。
方便且常见的是,将相同的数据转换(例如标准化和归一化)平等地应用于所有输入变量。这可以在许多问题上取得良好的结果。然而,在建模前,通过仔细选择要应用于每个输入变量的数据转换,可能会获得更好的结果。
在本教程中,您将学习如何对数值输入变量应用选择性缩放。
完成本教程后,您将了解:
- 如何加载并计算糖尿病分类数据集的基线预测性能。
- 如何评估将数据转换盲目应用于所有数值输入变量的建模管道。
- 如何评估将选择性归一化和标准化应用于输入变量子集的建模管道。
通过我的新书《机器学习数据准备》启动您的项目,其中包括分步教程和所有示例的Python源代码文件。
让我们开始吧。

如何为机器学习选择性地缩放数值输入变量
照片作者:Marco Verch,部分权利保留。
教程概述
本教程分为三个部分;它们是:
- 糖尿病数值数据集
- 数值输入的非选择性缩放
- 归一化所有输入变量
- 标准化所有输入变量
- 数值输入的选择性缩放
- 仅归一化非高斯输入变量
- 仅标准化高斯形输入变量
- 选择性地归一化和标准化输入变量
糖尿病数值数据集
本教程的基础将使用自20世纪90年代以来作为机器学习数据集广泛研究的“糖尿病”数据集。
该数据集将患者数据分类为五年内发病糖尿病或未发病。有768个样本和八个输入变量。这是一个二元分类问题。
你可以在此处了解更多关于此数据集的信息:
无需下载数据集;我们将在接下来的示例中自动下载它。
查看数据,我们可以看到所有九个输入变量都是数值型的。
|
1 2 3 4 5 6 |
6,148,72,35,0,33.6,0.627,50,1 1,85,66,29,0,26.6,0.351,31,0 8,183,64,0,0,23.3,0.672,32,1 1,89,66,23,94,28.1,0.167,21,0 0,137,40,35,168,43.1,2.288,33,1 ... |
我们可以使用 Pandas 库将此数据集加载到内存中。
下面的示例下载并总结了糖尿病数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 加载并总结糖尿病数据集 from pandas import read_csv from pandas.plotting import scatter_matrix from matplotlib import pyplot # 加载数据集 url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv" dataset = read_csv(url, header=None) # 总结数据集的形状 print(dataset.shape) # 变量的直方图 dataset.hist() pyplot.show() |
运行该示例首先下载数据集并将其加载为DataFrame。
打印数据集的形状,确认行数以及九个变量(八个输入变量和一个目标变量)。
|
1 |
(768, 9) |
最后,创建了一个图,显示数据集中每个变量的直方图。
这很有用,因为我们可以看到某些变量具有高斯或类高斯分布(1、2、5),而其他变量具有指数形分布(0、3、4、6、7)。这可能表明不同类型的输入变量需要不同的数值数据转换。
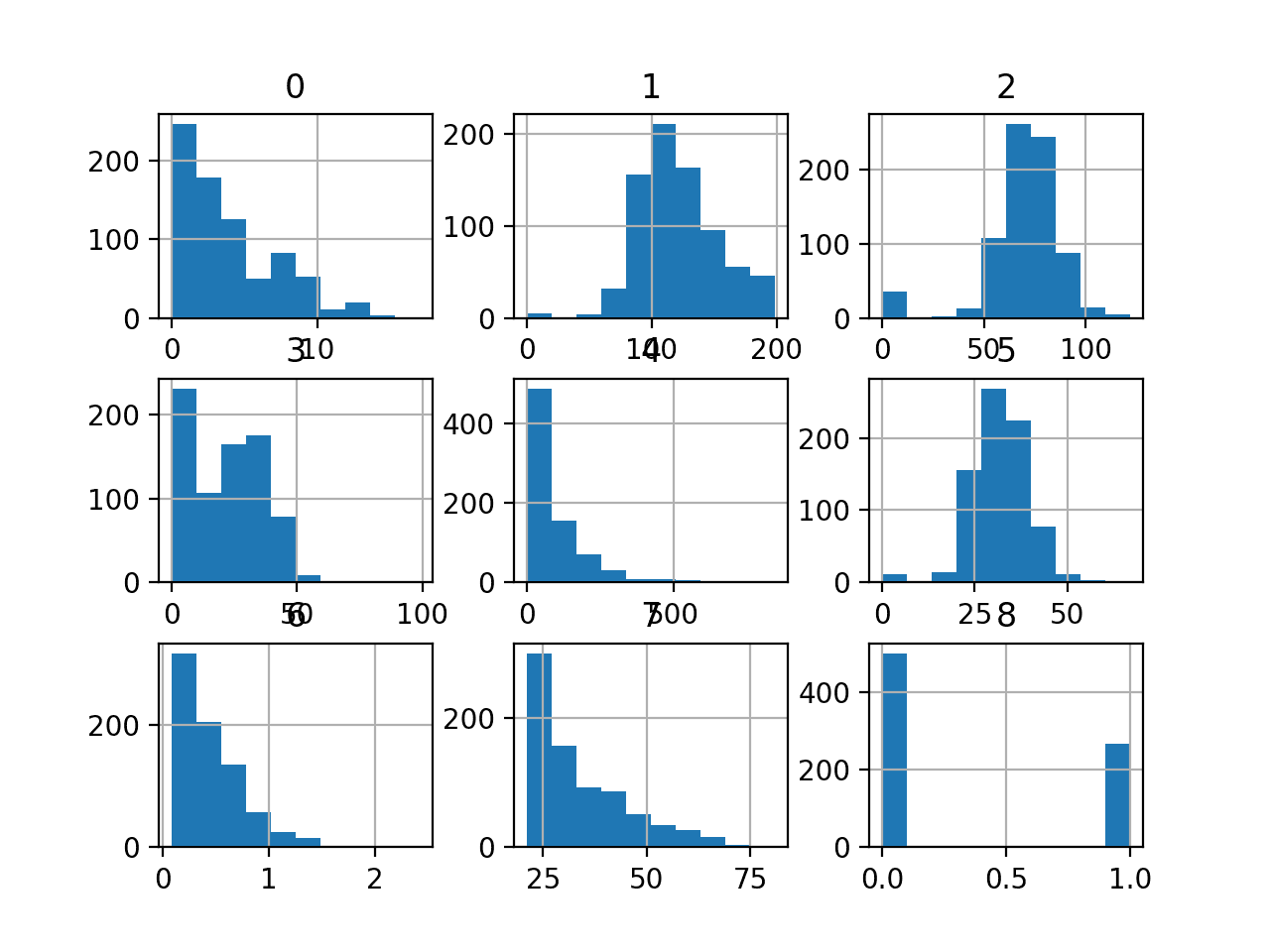
糖尿病分类数据集中每个变量的直方图
现在我们对数据集有了一些了解,让我们尝试在原始数据集上拟合和评估模型。
我们将使用逻辑回归模型,因为它们是用于二元分类任务的鲁棒且有效的线性模型。我们将使用重复分层K折交叉验证(一种最佳实践)来评估模型,并使用10折和三次重复。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# 在原始糖尿病数据集上评估逻辑回归模型 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold 从 sklearn.线性模型 导入 LogisticRegression # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 分离输入和输出元素 X, y = data[:, :-1], data[:, -1] # 最少地准备数据集 X = X.astype('float') y = LabelEncoder().fit_transform(y.astype('str')) # 定义模型 model = LogisticRegression(solver='liblinear') # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 m_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 总结结果 print('Accuracy: %.3f (%.3f)' % (mean(m_scores), std(m_scores))) |
运行该示例会评估模型并报告在原始数据集上拟合逻辑回归模型的平均和标准差准确度。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到模型达到了约76.8%的准确率。
|
1 |
准确率:0.768 (0.040) |
现在我们已经在数据集上建立了性能基线,让我们看看是否可以使用数据缩放来提高性能。
想开始学习数据准备吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
数值输入的非选择性缩放
许多算法倾向或要求在拟合模型之前将输入变量缩放到一致的范围。
这包括逻辑回归模型,该模型假定输入变量具有高斯概率分布。如果输入变量是标准化的,它还可以提供更数值稳定的模型。然而,即使这些期望被违反,逻辑回归在给定数据集上也可以表现良好或最佳,糖尿病数据集可能就是这种情况。
缩放数值输入变量的两种常用技术是归一化和标准化。
归一化将每个输入变量缩放到0-1的范围,可以使用scikit-learn中的MinMaxScaler类实现。标准化将每个输入变量缩放到均值为0.0和标准差为1.0,可以使用scikit-learn中的StandardScaler类实现。
要了解有关归一化、标准化以及如何在scikit-learn中使用这些方法的更多信息,请参阅教程
数据缩放的朴素方法是对所有输入变量应用单一转换,无论其规模或概率分布如何。这通常是有效的。
让我们尝试直接归一化和标准化所有输入变量,并将性能与在原始数据上拟合的基线逻辑回归模型进行比较。
归一化所有输入变量
我们可以更新基线代码示例,使用建模管道,其中第一步是应用缩放器,最后一步是拟合模型。
这确保了缩放操作仅在训练集上拟合或准备,然后在交叉验证过程中应用于训练集和测试集,从而避免了数据泄露。数据泄露可能导致模型性能的乐观偏差估计。
这可以通过使用Pipeline类来实现,其中管道中的每个步骤都定义为带有名称和要使用的转换或模型实例的元组。
|
1 2 3 4 5 |
... # 定义建模管道 scaler = MinMaxScaler() model = LogisticRegression(solver='liblinear') pipeline = Pipeline([('s',scaler),('m',model)]) |
综合起来,在所有输入变量都经过归一化处理的糖尿病数据集上评估逻辑回归的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 在归一化的糖尿病数据集上评估逻辑回归模型 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import MinMaxScaler # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 分离输入和输出元素 X, y = data[:, :-1], data[:, -1] # 最少地准备数据集 X = X.astype('float') y = LabelEncoder().fit_transform(y.astype('str')) # 定义建模管道 model = LogisticRegression(solver='liblinear') scaler = MinMaxScaler() pipeline = Pipeline([('s',scaler),('m',model)]) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 m_scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 总结结果 print('Accuracy: %.3f (%.3f)' % (mean(m_scores), std(m_scores))) |
运行该示例会评估建模管道,并报告在标准化数据集上拟合逻辑回归模型的平均准确率和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到输入变量的归一化导致平均分类准确率从原始数据模型拟合的76.8%下降到归一化管道的约76.4%。
|
1 |
准确率:0.764 (0.045) |
接下来,让我们尝试标准化所有输入变量。
标准化所有输入变量
我们可以在拟合和评估逻辑回归模型之前,更新建模管道以对所有输入变量使用标准化而不是归一化。
这可能适用于具有高斯分布的输入变量,但可能不适用于其他变量。
|
1 2 3 4 5 |
... # 定义建模管道 scaler = StandardScaler() model = LogisticRegression(solver='liblinear') pipeline = Pipeline([('s',scaler),('m',model)]) |
综合起来,在所有输入变量都标准化后的糖尿病数据集上评估逻辑回归模型的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 在标准化糖尿病数据集上评估逻辑回归模型 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import StandardScaler # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 分离输入和输出元素 X, y = data[:, :-1], data[:, -1] # 最少地准备数据集 X = X.astype('float') y = LabelEncoder().fit_transform(y.astype('str')) # 定义建模管道 scaler = StandardScaler() model = LogisticRegression(solver='liblinear') pipeline = Pipeline([('s',scaler),('m',model)]) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 m_scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 总结结果 print('Accuracy: %.3f (%.3f)' % (mean(m_scores), std(m_scores))) |
运行该示例会评估建模管道,并报告在标准化数据集上拟合逻辑回归模型的平均准确率和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到标准化所有数值输入变量使得平均分类准确率从在原始数据集上评估的模型获得的76.8%提高到在标准化输入变量数据集上评估的模型获得的约77.2%。
|
1 |
准确率:0.772 (0.043) |
到目前为止,我们已经了解到归一化所有变量并不能提高性能,但标准化所有输入变量确实可以提高性能。
接下来,让我们探讨选择性地对输入变量进行缩放是否能带来进一步的改进。
数值输入的选择性缩放
可以使用scikit-learn中的ColumnTransformer类选择性地将数据转换应用于输入变量。
它允许您指定要应用的转换(或转换管道)以及要应用它们的列索引。然后,这可以作为建模管道的一部分,并使用交叉验证进行评估。
您可以在教程中了解如何使用ColumnTransformer
我们可以探索使用 ColumnTransformer 对糖尿病数据集的数值输入变量选择性地应用归一化和标准化,以查看是否能实现进一步的性能改进。
仅归一化非高斯输入变量
首先,我们只对那些不具有高斯状概率分布的输入变量进行归一化,而将其余输入变量保持原始状态。
我们可以使用列索引定义两组输入变量,一组用于具有高斯分布的变量,另一组用于具有指数分布的输入变量。
|
1 2 3 4 |
... # 定义具有“正态”和“指数”分布变量的列索引 norm_ix = [1, 2, 5] exp_ix = [0, 3, 4, 6, 7] |
然后我们可以选择性地归一化“exp_ix”组,并让其他输入变量不经过任何数据准备。
|
1 2 3 4 |
... # 定义选择性转换 t = [('e', MinMaxScaler(), exp_ix)] selective = ColumnTransformer(transformers=t, remainder='passthrough') |
然后,选择性转换可以作为我们建模管道的一部分。
|
1 2 3 4 |
... # 定义建模管道 model = LogisticRegression(solver='liblinear') pipeline = Pipeline([('s',selective),('m',model)]) |
综合起来,在部分输入变量经过选择性归一化处理的数据集上评估逻辑回归模型的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 在糖尿病数据集上评估带有选择性归一化的逻辑回归模型 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression 从 sklearn.预处理 导入 MinMaxScaler from sklearn.compose import ColumnTransformer # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 分离输入和输出元素 X, y = data[:, :-1], data[:, -1] # 最少地准备数据集 X = X.astype('float') y = LabelEncoder().fit_transform(y.astype('str')) # 定义具有“正态”和“指数”分布变量的列索引 norm_ix = [1, 2, 5] exp_ix = [0, 3, 4, 6, 7] # 定义选择性转换 t = [('e', MinMaxScaler(), exp_ix)] selective = ColumnTransformer(transformers=t, remainder='passthrough') # 定义建模管道 model = LogisticRegression(solver='liblinear') pipeline = Pipeline([('s',selective),('m',model)]) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 m_scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 总结结果 print('Accuracy: %.3f (%.3f)' % (mean(m_scores), std(m_scores))) |
运行该示例会评估建模管道并报告平均准确率和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到性能略有提升,与原始数据集上拟合的基线模型相比,平均准确率从76.8%提高到选择性归一化部分输入变量后的约76.9%。
然而,结果不如标准化所有输入变量。
|
1 |
准确率:0.769 (0.043) |
仅标准化高斯形输入变量
我们可以重复上一节的实验,但这次是选择性地标准化那些具有高斯分布的输入变量,而其余输入变量保持不变。
|
1 2 3 4 |
... # 定义选择性转换 t = [('n', StandardScaler(), norm_ix)] selective = ColumnTransformer(transformers=t, remainder='passthrough') |
综合起来,下面列出了在对某些输入变量进行选择性标准化处理的数据上评估逻辑回归模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# 在糖尿病数据集上评估带有选择性标准化的逻辑回归模型 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import StandardScaler from sklearn.compose import ColumnTransformer # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 分离输入和输出元素 X, y = data[:, :-1], data[:, -1] # 最少地准备数据集 X = X.astype('float') y = LabelEncoder().fit_transform(y.astype('str')) # 定义具有“正态”和“指数”分布变量的列索引 norm_ix = [1, 2, 5] exp_ix = [0, 3, 4, 6, 7] # 定义选择性转换 t = [('n', StandardScaler(), norm_ix)] selective = ColumnTransformer(transformers=t, remainder='passthrough') # 定义建模管道 model = LogisticRegression(solver='liblinear') pipeline = Pipeline([('s',selective),('m',model)]) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 m_scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 总结结果 print('Accuracy: %.3f (%.3f)' % (mean(m_scores), std(m_scores))) |
运行该示例会评估建模管道并报告平均准确率和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,我们可以看到性能有所提升,超过了在原始数据集上拟合的基线模型(76.8%),也超过了标准化所有输入变量的模型(77.2%)。通过选择性标准化,我们实现了约77.3%的平均准确率,这是一个适度但可测量的提升。
|
1 |
准确率:0.773 (0.041) |
选择性地归一化和标准化输入变量
到目前为止的结果提出了一个问题,即我们是否可以通过同时结合选择性归一化和标准化来进一步提升数据集的性能。
这可以通过为ColumnTransformer类定义两个转换及其各自的列索引来实现,并且不通过任何剩余变量。
|
1 2 3 4 |
... # 定义选择性转换 t = [('e', MinMaxScaler(), exp_ix), ('n', StandardScaler(), norm_ix)] selective = ColumnTransformer(transformers=t) |
综合起来,下面列出了在对输入变量进行选择性归一化和标准化处理的数据上评估逻辑回归模型的完整示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# 在糖尿病数据集上评估带有选择性缩放的逻辑回归模型 from numpy import mean from numpy import std from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.pipeline import Pipeline from sklearn.linear_model import LogisticRegression 从 sklearn.预处理 导入 MinMaxScaler from sklearn.preprocessing import StandardScaler from sklearn.compose import ColumnTransformer # 加载数据集 url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv' dataframe = read_csv(url, header=None) data = dataframe.values # 分离输入和输出元素 X, y = data[:, :-1], data[:, -1] # 最少地准备数据集 X = X.astype('float') y = LabelEncoder().fit_transform(y.astype('str')) # 定义具有“正态”和“指数”分布变量的列索引 norm_ix = [1, 2, 5] exp_ix = [0, 3, 4, 6, 7] # 定义选择性转换 t = [('e', MinMaxScaler(), exp_ix), ('n', StandardScaler(), norm_ix)] selective = ColumnTransformer(transformers=t) # 定义建模管道 model = LogisticRegression(solver='liblinear') pipeline = Pipeline([('s',selective),('m',model)]) # 定义评估过程 cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # 评估模型 m_scores = cross_val_score(pipeline, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # 总结结果 print('Accuracy: %.3f (%.3f)' % (mean(m_scores), std(m_scores))) |
运行该示例会评估建模管道并报告平均准确率和标准差。
注意:由于算法或评估过程的随机性,或数值精度的差异,您的结果可能会有所不同。考虑多次运行示例并比较平均结果。
在这种情况下,有趣的是,我们可以看到我们取得了与标准化所有输入变量相同的性能,即77.2%。
此外,结果表明,当非高斯变量保持不变而不是被标准化或归一化时,所选模型表现更好。
我没有预料到这个发现,它强调了仔细实验的重要性。
|
1 |
准确率:0.772 (0.040) |
你能做得更好吗?
尝试其他转换或转换组合,看看是否能取得更好的结果。
在下面的评论中分享您的发现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
教程
API
总结
在本教程中,您学习了如何对数值输入变量应用选择性缩放。
具体来说,你学到了:
- 如何加载并计算糖尿病分类数据集的基线预测性能。
- 如何评估将数据转换盲目应用于所有数值输入变量的建模管道。
- 如何评估将选择性归一化和标准化应用于输入变量子集的建模管道。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。







你好 Jason,
我看过几个 Sklearn API
neural_network.MLPClassifier([…])
neural_network.MLPRegressor([…])
它们是否等同于 Keras 模型(用于分类和回归)?
Keras MLP 和 Sklearn MLP 有什么区别?
使用MLPClassifier/MLPRegressor是否只能处理表格数据,还是也可以处理图像、文本等?
它们是机器学习还是深度学习?
谢谢,
Marco
谢谢,
Marco
它们是不同的。抱歉,我没有使用过它们。我专门使用 keras 处理神经网络。
神经网络/深度学习是机器学习的一种类型
https://machinelearning.org.cn/faq/single-faq/how-are-ml-and-deep-learning-related
你好 Jason,
所以我可以认为它们是深度学习吗?
neural_network.MLPClassifier()
neural_network.MLPRegressor()
谢谢,
Marco
当然可以。
尊敬的Jason博士,
在上面“想要开始数据准备吗?”推广的列表中,
我使用了URL提供的数据集。
我想通过替换以下几行来对列表进行崩溃测试
这样——不要将X转换为浮点数,也不要强制y转换为字符串。
也就是说,我不需要将X转换为浮点数,也没有使用astype('str'),并且得到了相同的结果。
在转换之前检查X和y时,X和y不需要转换。
问题:转换数据以确保数据是程序应该处理的类型是个好主意吗?
谢谢你,
悉尼的Anthony
不错。
有时我对自己的代码过于谨慎/防御。
嗨,Jason,非常感谢您,我学到了很多!
我有一个问题,如果我的输出变量也被视为输入变量的一部分,我应该对其进行归一化吗?
你的意思是滞后输出作为输入,比如时间序列或序列分类吗?
如果是这样,是的,尝试缩放变量。
嗨,Jason,
我用原始数据建模了一个xgboost分类器(二元分类)。据我了解(如果错了请指正),xgboost分类器不像逻辑回归、神经网络和K近邻那样使用输入的加权和或距离度量。
所以问题是,您是否会建议将原始输入变量进行缩放(例如归一化、标准化、幂变换/Box-Cox)作为xgboost分类器的通用实践?
不行。
嗨,Jason,
感谢您的教程。我有一个问题。如果我使用训练好的模型对新数据进行预测,而新数据的范围和分布可能与训练数据集略有不同,那么在使用模型进行预测之前,我应该如何处理新数据?
谢谢你
非常欢迎 Jingyi!以下资源希望能提供清晰的解释
https://machinelearning.org.cn/update-neural-network-models-with-more-data/
https://machinelearning.org.cn/what-is-generalization-in-machine-learning/
嗨 Jason
感谢您的分享。它非常有教育意义,教会了许多年轻学生如何在建模之前预处理数值变量。但是,您本可以使用非参数模型进行比较,因为逻辑回归在使用前要求数据满足其假设。
无论如何,感谢您的贡献!
感谢 Ernesto 的宝贵反馈和支持!