半监督学习是一个具有挑战性的问题,它涉及在只有少量标记样本和大量未标记样本的数据集上训练分类器。
生成对抗网络(GAN)是一种通过图像判别器模型有效地利用大型未标记数据集来训练图像生成器模型的架构。在某些情况下,判别器模型可以用作开发分类器模型的起点。
半监督生成对抗网络(SGAN)模型是GAN架构的扩展,它涉及同时训练监督判别器、无监督判别器和生成器模型。其结果是,既能得到一个泛化能力强的监督分类模型,也能得到一个能生成该领域图像的合理示例的生成器模型。
在本教程中,您将学习如何从头开始开发一个半监督生成对抗网络。
完成本教程后,您将了解:
- 半监督GAN是GAN架构的扩展,用于在利用标记和未标记数据训练分类器模型。
- 在 Keras 中实现半监督 GAN 所使用的监督和无监督判别器模型,至少有三种方法。
- 如何从头开始在 MNIST 上训练半监督 GAN,并加载和使用训练好的分类器进行预测。
开始您的项目,阅读我的新书 《Python生成对抗网络》,其中包含分步教程以及所有示例的Python源代码文件。
让我们开始吧。

如何从头开始实现半监督生成对抗网络。
照片由 Carlos Johnson 拍摄,保留部分权利。
教程概述
本教程分为四个部分;它们是
- 什么是半监督 GAN?
- 如何实现半监督判别器模型
- 如何为 MNIST 开发半监督 GAN
- 如何加载和使用最终的 SGAN 分类器模型
什么是半监督 GAN?
半监督学习是指在需要预测模型但只有少量标记示例和大量未标记示例的问题。
最常见的例子是分类预测建模问题,其中可能有一个非常大的数据集,但只有一小部分具有目标标签。模型必须从少量标记示例中学习,并以某种方式利用更多的未标记示例数据集,以便泛化到将来对新示例进行分类。
半监督 GAN,有时简称为 SGAN,是生成对抗网络架构的扩展,用于解决半监督学习问题。
这项工作的主要目标之一是提高生成对抗网络在半监督学习中的有效性(通过在额外的未标记示例上学习来提高监督任务,在本例中为分类,的性能)。
——《改进GAN训练技术》,2016。
传统 GAN 中的判别器经过训练,用于预测给定图像是真实的(来自数据集)还是伪造的(生成的),从而使其能够从无标记图像中学习特征。然后,可以通过 迁移学习 将判别器用作开发同一数据集的分类器的起点,从而使监督预测任务受益于 GAN 的无监督训练。
在半监督 GAN 中,判别器模型被更新以预测 K+1 个类别,其中 K 是预测问题中的类别数,并为新的“伪造”类别添加额外的类别标签。它涉及同时直接训练判别器模型以进行无监督 GAN 任务和监督分类任务。
我们在一个包含 N 个类别输入的 数据集上训练一个生成模型 G 和一个判别器 D。在训练时,D 被设置为预测输入属于 N+1 个类别中的哪一个,其中添加了一个额外的类别以对应于 G 的输出。
—— 《使用生成对抗网络进行半监督学习》,2016。
因此,判别器以两种模式进行训练:监督模式和无监督模式。
- 无监督训练:在无监督模式下,判别器以与传统 GAN 相同的方式进行训练,以预测示例是真实的还是伪造的。
- 监督训练:在监督模式下,判别器被训练来预测真实示例的类别标签。
在无监督模式下进行训练允许模型从大型未标记数据集中学习有用的特征提取能力,而在监督模式下进行训练则允许模型利用提取的特征并应用类别标签。
结果是一个分类器模型,当在很少的标记示例(例如几十、几百或一千个)上进行训练时,可以在 MNIST 等标准问题上取得最先进的结果。此外,训练过程还可以产生更高质量的生成器模型输出图像。
例如,Augustus Odena 在其 2016 年题为“《使用生成对抗网络进行半监督学习》”的论文中展示了,在 MNIST 手写数字识别任务上,当使用 25、50、100 和 1000 个标记示例进行训练时,GAN 训练的分类器能够与独立的 CNN 模型媲美甚至表现更好。
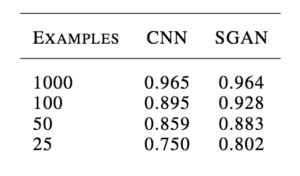
MNIST 上 CNN 和 SGAN 分类准确度比较结果表示例。
来源:使用生成对抗网络进行半监督学习
OpenAI 的 Tim Salimans 等人在其 2016 年题为“《改进 GAN 训练技术》”的论文中,使用半监督 GAN 在包括 MNIST 在内的多个图像分类任务上取得了当时的最佳结果。

MNIST 上其他 GAN 模型与 SGAN 分类准确度比较结果表示例。
来源:改进 GAN 训练技术
想从零开始开发GAN吗?
立即参加我为期7天的免费电子邮件速成课程(附示例代码)。
点击注册,同时获得该课程的免费PDF电子书版本。
如何实现半监督判别器模型
我们可以通过多种方式为半监督 GAN 实现判别器模型。
在本节中,我们将回顾三种候选方法。
传统判别器模型
考虑标准 GAN 模型的判别器模型。
它必须接受图像作为输入,并预测它是真实的还是伪造的。更具体地说,它预测输入图像为真实的概率。输出层使用 sigmoid 激活函数来预测 [0,1] 范围内的概率值,并且模型通常使用二元交叉熵损失函数进行优化。
例如,我们可以定义一个简单的判别器模型,它接受 28x28 像素的灰度图像作为输入,并预测图像为真实的概率。我们可以遵循最佳实践,使用具有 2x2 步长 和 Leaky ReLU 激活函数 的卷积层来对图像进行下采样。
下面的 `define_discriminator()` 函数实现了这一点,并定义了我们的标准判别器模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# 定义判别器模型的示例 from keras.models import Model from keras.layers import Input from keras.layers import Dense 从 keras.layers 导入 Conv2D from keras.layers import LeakyReLU 从 keras.layers 导入 Dropout from keras.layers import Flatten from keras.optimizers import Adam from keras.utils.vis_utils import plot_model # 定义独立的判别器模型 def define_discriminator(in_shape=(28,28,1)): # 图像输入 in_image = Input(shape=in_shape) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image) fe = LeakyReLU(alpha=0.2)(fe) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # 展平特征图 fe = Flatten()(fe) # dropout fe = Dropout(0.4)(fe) # output layer d_out_layer = Dense(1, activation='sigmoid')(fe) # define and compile discriminator model d_model = Model(in_image, d_out_layer) d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5)) return d_model # 创建模型 model = define_discriminator() # 绘制模型 plot_model(model, to_file='discriminator_plot.png', show_shapes=True, show_layer_names=True) |
运行该示例将创建判别器模型的图,清晰显示输入图像的 28x28x1 形状以及单个概率值的预测。
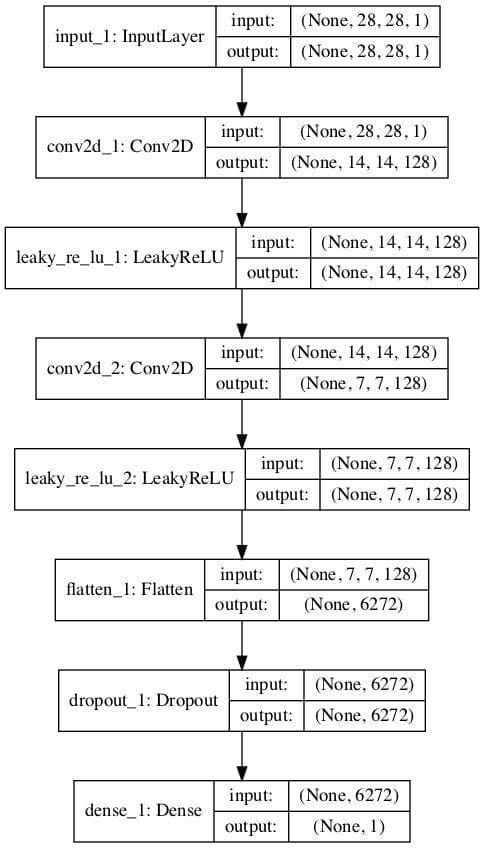
标准 GAN 判别器模型图
具有共享权重的独立判别器模型
从标准 GAN 判别器模型开始,我们可以更新它以创建两个共享特征提取权重的模型。
具体来说,我们可以定义一个预测图像是真实还是伪造的分类器模型,以及第二个预测给定模型的类别的分类器模型。
- 二元分类器模型。预测图像是真实的还是伪造的,输出层使用 sigmoid 激活函数,并使用 二元交叉熵损失函数 进行优化。
- 多类别分类器模型。预测图像的类别,输出层使用 softmax 激活函数,并使用 分类交叉熵损失函数 进行优化。
这两个模型具有不同的输出层,但共享所有特征提取层。这意味着对其中一个分类器模型的更新将影响两个模型。
下面的示例首先创建具有二元输出的传统判别器模型,然后重用特征提取层并创建一个新的多类别预测模型,在本例中为 10 个类别。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 定义半监督判别器模型的示例 from keras.models import Model from keras.layers import Input from keras.layers import Dense 从 keras.layers 导入 Conv2D from keras.layers import LeakyReLU 从 keras.layers 导入 Dropout from keras.layers import Flatten from keras.optimizers import Adam from keras.utils.vis_utils import plot_model # 定义独立的监督和无监督判别器模型 def define_discriminator(in_shape=(28,28,1), n_classes=10): # 图像输入 in_image = Input(shape=in_shape) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image) fe = LeakyReLU(alpha=0.2)(fe) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # 展平特征图 fe = Flatten()(fe) # dropout fe = Dropout(0.4)(fe) # 无监督输出 d_out_layer = Dense(1, activation='sigmoid')(fe) # 定义并编译无监督判别器模型 d_model = Model(in_image, d_out_layer) d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5)) # 监督输出 c_out_layer = Dense(n_classes, activation='softmax')(fe) # 定义并编译监督判别器模型 c_model = Model(in_image, c_out_layer) c_model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy']) return d_model, c_model # 创建模型 d_model, c_model = define_discriminator() # 绘制模型 plot_model(d_model, to_file='discriminator1_plot.png', show_shapes=True, show_layer_names=True) plot_model(c_model, to_file='discriminator2_plot.png', show_shapes=True, show_layer_names=True) |
运行该示例将创建并绘制两个模型。
第一个模型的图与之前相同。
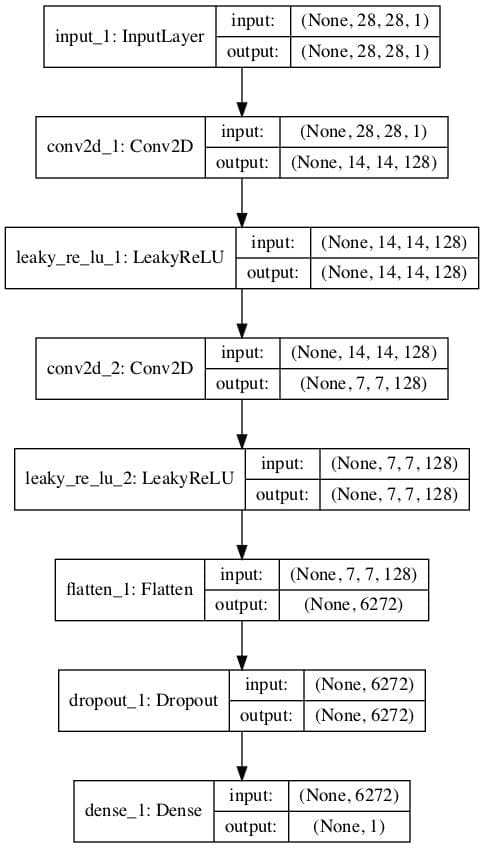
无监督二元分类 GAN 判别器模型图
第二个模型的图显示了相同的预期输入形状和相同的特征提取层,并带有一个新的 10 类分类输出层。
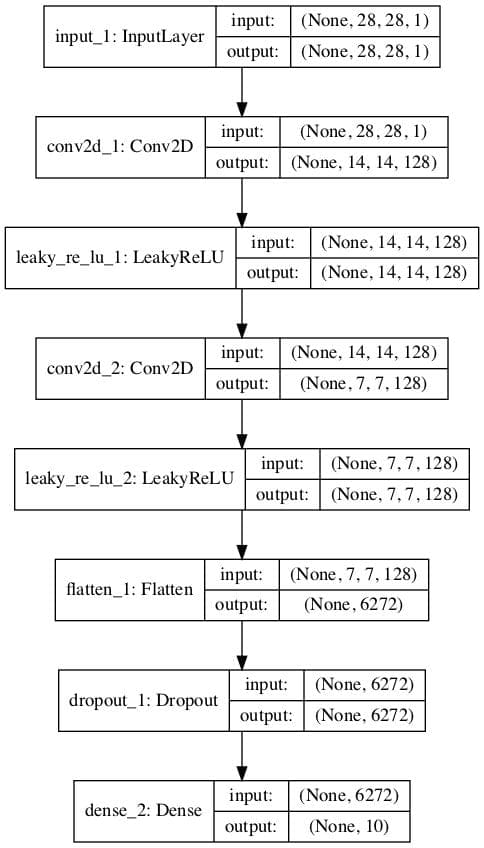
监督多类别分类 GAN 判别器模型图
具有共享权重的单个判别器模型
实现半监督判别器模型的另一种方法是拥有一个具有多个输出层的单一模型。
具体来说,这是一个具有一个输出层用于无监督任务,一个输出层用于监督任务的单一模型。
这类似于为监督和无监督任务拥有单独的模型,因为它们都共享相同的特征提取层,只是在这种情况下,每个输入图像总是具有两个输出预测,特别是实/伪预测和监督类别预测。
这种方法的一个问题是,当模型使用未标记和生成的图像进行更新时,没有监督类别标签。在这种情况下,这些图像的监督输出必须具有“未知”或“伪造”的输出标签。这意味着监督输出层需要一个额外的类别标签。
下面的示例实现了半监督 GAN 架构中判别器模型的多个输出的单一模型方法。
我们可以看到模型定义了两个输出层,监督任务的输出层定义为 n_classes + 1。在本例中为 11,为额外的“未知”类别标签留出了空间。
我们还可以看到模型被编译为两个损失函数,每个损失函数对应于模型的一个输出层。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# 定义半监督判别器模型的示例 from keras.models import Model from keras.layers import Input from keras.layers import Dense 从 keras.layers 导入 Conv2D from keras.layers import LeakyReLU 从 keras.layers 导入 Dropout from keras.layers import Flatten from keras.optimizers import Adam from keras.utils.vis_utils import plot_model # 定义独立的监督和无监督判别器模型 def define_discriminator(in_shape=(28,28,1), n_classes=10): # 图像输入 in_image = Input(shape=in_shape) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image) fe = LeakyReLU(alpha=0.2)(fe) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # 展平特征图 fe = Flatten()(fe) # dropout fe = Dropout(0.4)(fe) # 无监督输出 d_out_layer = Dense(1, activation='sigmoid')(fe) # 监督输出 c_out_layer = Dense(n_classes + 1, activation='softmax')(fe) # 定义并编译监督判别器模型 model = Model(in_image, [d_out_layer, c_out_layer]) model.compile(loss=['binary_crossentropy', 'sparse_categorical_crossentropy'], optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy']) return model # 创建模型 model = define_discriminator() # 绘制模型 plot_model(model, to_file='multioutput_discriminator_plot.png', show_shapes=True, show_layer_names=True) |
运行该示例将创建并绘制单一的多输出模型。
该图清晰地显示了共享层以及独立的无监督和监督输出层。
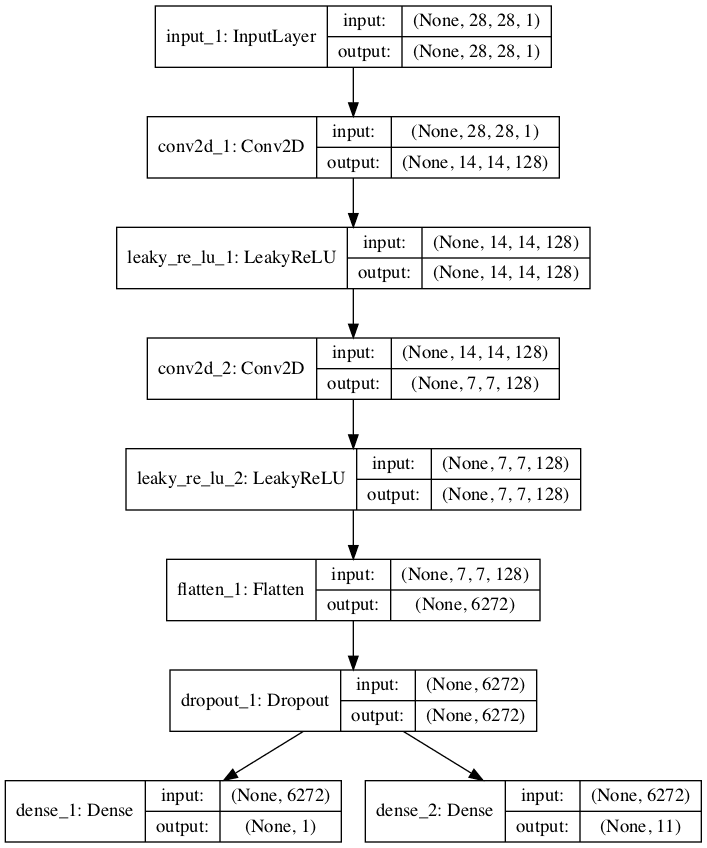
具有无监督和监督输出层的半监督 GAN 判别器模型图
堆叠的具有共享权重的判别器模型
最后一种方法与前两种方法非常相似,涉及创建独立的逻辑无监督和监督模型,但尝试将一个模型的输出层重用到另一个模型的输入。
该方法基于 OpenAI 的 Tim Salimans 等人在 2016 年发表的论文“《改进 GAN 训练技术》”中对半监督模型的定义。
在论文中,他们描述了一种高效的实现方式:首先创建具有 K 个输出类别和 softmax 激活函数的监督模型。然后定义无监督模型,该模型接受监督模型在 softmax 激活之前的输出,然后计算指数输出的归一化总和。
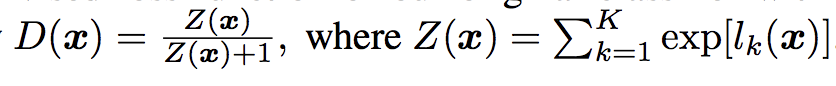
SGAN 中无监督判别器模型的输出函数示例。
来源:改进 GAN 训练技术
为了更清楚地说明这一点,我们可以用 NumPy 实现这个激活函数,并通过它运行一些示例激活来观察结果。
完整的示例如下所示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# 自定义激活函数的示例 import numpy as np # 自定义激活函数 def custom_activation(output): logexpsum = np.sum(np.exp(output)) result = logexpsum / (logexpsum + 1.0) return result # 全为 -10 output = np.asarray([-10.0, -10.0, -10.0]) print(custom_activation(output)) # 全为 -1 output = np.asarray([-1.0, -1.0, -1.0]) print(custom_activation(output)) # 全为0 output = np.asarray([0.0, 0.0, 0.0]) print(custom_activation(output)) # 全为 1 output = np.asarray([1.0, 1.0, 1.0]) print(custom_activation(output)) # 全为 10 output = np.asarray([10.0, 10.0, 10.0]) print(custom_activation(output)) |
请记住,无监督模型在 softmax 激活函数之前的输出将直接是节点的激活值。它们将是小的正值或负值,但未归一化,因为这将由 softmax 激活完成。
自定义激活函数将输出一个介于 0.0 和 1.0 之间的值。
对于小的或负的激活值,输出接近 0.0;对于大的或正的激活值,输出接近 1.0。当我们运行示例时,我们可以看到这一点。
|
1 2 3 4 5 |
0.00013618124143106674 0.5246331135813284 0.75 0.890768227426964 0.9999848669190928 |
这意味着模型被鼓励为真实示例输出一个强烈的类别预测,为伪造示例输出一个小的类别预测或低激活值。这是一个巧妙的技巧,允许在两个模型中重用监督模型相同的输出节点。
激活函数几乎可以直接通过 Keras 后端实现,并从 `Lambda` 层调用,例如,一个将自定义函数应用于该层输入的层。
完整的示例列在下面。首先,用 softmax 激活和分类交叉熵损失函数定义监督模型。无监督模型堆叠在监督模型输出层之上(在 softmax 激活之前),并且节点激活值通过 Lambda 层通过我们的自定义激活函数。
由于我们已经归一化了激活值,因此不需要 sigmoid 激活函数。与之前一样,无监督模型使用二元交叉熵损失进行拟合。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
# 定义半监督判别器模型的示例 from keras.models import Model from keras.layers import Input from keras.layers import Dense 从 keras.layers 导入 Conv2D from keras.layers import LeakyReLU 从 keras.layers 导入 Dropout from keras.layers import Flatten from keras.layers import Activation from keras.layers import Lambda from keras.optimizers import Adam from keras.utils.vis_utils import plot_model from keras import backend # 自定义激活函数 def custom_activation(output): logexpsum = backend.sum(backend.exp(output), axis=-1, keepdims=True) result = logexpsum / (logexpsum + 1.0) return result # 定义独立的监督和无监督判别器模型 def define_discriminator(in_shape=(28,28,1), n_classes=10): # 图像输入 in_image = Input(shape=in_shape) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image) fe = LeakyReLU(alpha=0.2)(fe) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # 展平特征图 fe = Flatten()(fe) # dropout fe = Dropout(0.4)(fe) # 输出层节点 fe = Dense(n_classes)(fe) # 监督输出 c_out_layer = Activation('softmax')(fe) # 定义并编译监督判别器模型 c_model = Model(in_image, c_out_layer) c_model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy']) # 无监督输出 d_out_layer = Lambda(custom_activation)(fe) # 定义并编译无监督判别器模型 d_model = Model(in_image, d_out_layer) d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5)) return d_model, c_model # 创建模型 d_model, c_model = define_discriminator() # 绘制模型 plot_model(d_model, to_file='stacked_discriminator1_plot.png', show_shapes=True, show_layer_names=True) plot_model(c_model, to_file='stacked_discriminator2_plot.png', show_shapes=True, show_layer_names=True) |
运行示例会创建并绘制两个模型,它们看起来与第一个示例中的两个模型非常相似。
无监督判别器模型的堆叠版本
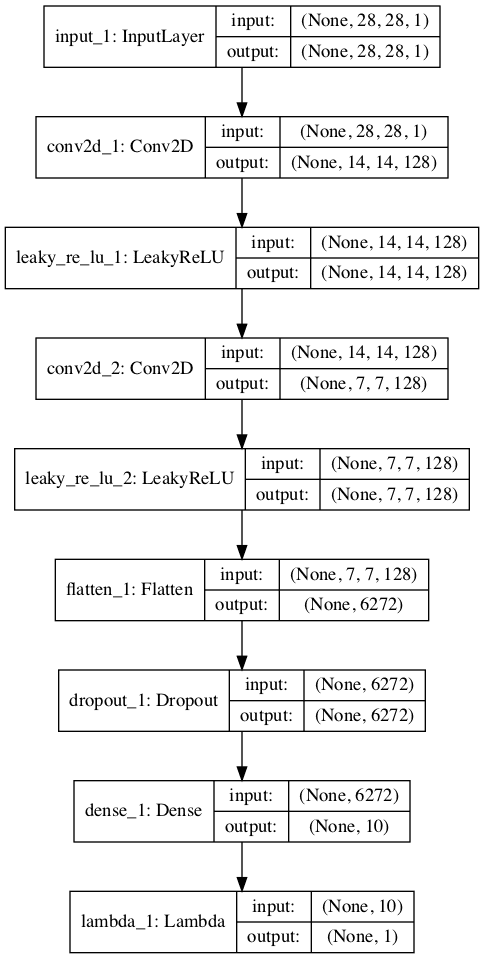
半监督GAN的无监督判别器模型堆叠版本的图
有监督判别器模型的堆叠版本
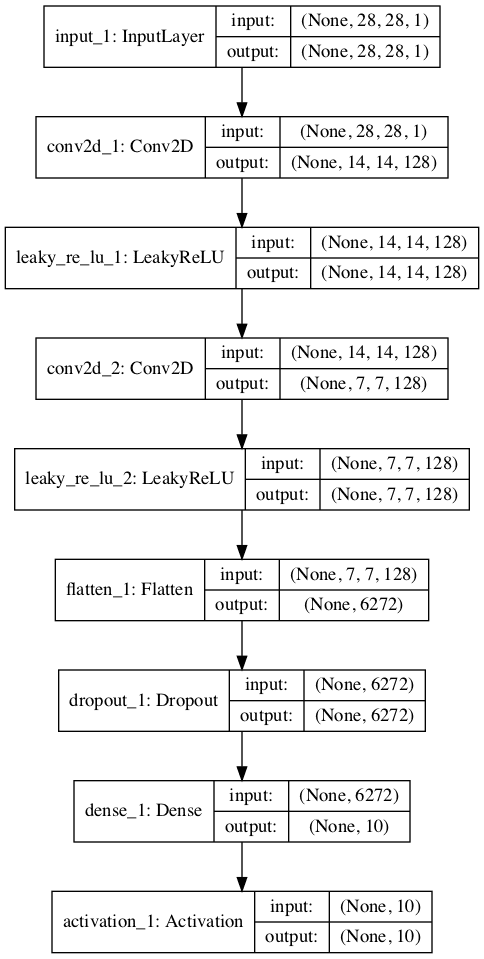
半监督GAN的监督判别器模型堆叠版本的图
现在我们已经了解了如何在半监督GAN中实现判别器模型,我们可以开发一个完整的图像生成和半监督分类的示例。
如何为 MNIST 开发半监督 GAN
在本节中,我们将为MNIST手写数字数据集开发一个半监督GAN模型。
该数据集有10个数字0-9的类别,因此分类器模型将有10个输出节点。模型将拟合包含60,000个样本的训练数据集。训练数据集中只有100张图像带有标签,每个类别10张。
我们将首先定义模型。
我们将使用堆叠判别器模型,完全按照上一节的定义。
接下来,我们可以定义生成器模型。在这种情况下,生成器模型将接收潜在空间中的一个点作为输入,并使用转置卷积层输出一个28x28的灰度图像。下面的define_generator()函数实现了这一点并返回定义的生成器模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 定义独立的生成器模型 def define_generator(latent_dim): # 图像生成器输入 in_lat = Input(shape=(latent_dim,)) # 7x7 图像的基础 n_nodes = 128 * 7 * 7 gen = Dense(n_nodes)(in_lat) gen = LeakyReLU(alpha=0.2)(gen) gen = Reshape((7, 7, 128))(gen) # 上采样到 14x14 gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen) gen = LeakyReLU(alpha=0.2)(gen) # 上采样到 28x28 gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen) gen = LeakyReLU(alpha=0.2)(gen) # 输出 out_layer = Conv2D(1, (7,7), activation='tanh', padding='same')(gen) # 定义模型 model = Model(in_lat, out_layer) return model |
生成器模型将通过无监督判别器模型进行拟合。
我们将使用复合模型架构,这在Keras实现中是训练生成器模型的常用方法。具体来说,使用了权重共享,其中生成器模型的输出直接传递给无监督判别器模型,并且判别器的权重被标记为不可训练。
下面的define_gan()函数实现了这一点,它接受已定义的生成器和判别器模型作为输入,并返回用于训练生成器模型权重的复合模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 定义组合的生成器和判别器模型,用于更新生成器 def define_gan(g_model, d_model): # 使判别器中的权重不可训练 d_model.trainable = False # 将生成器的图像输出作为判别器的输入 gan_output = d_model(g_model.output) # 将GAN模型定义为接收噪声并输出分类 model = Model(g_model.input, gan_output) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt) return model |
我们可以加载训练数据集并缩放像素到[-1, 1]的范围,以匹配生成器模型的输出值。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 加载图像 def load_real_samples(): # 加载数据集 (trainX, trainy), (_, _) = load_data() # 扩展到3D,例如添加通道 X = expand_dims(trainX, axis=-1) # 从整数转换为浮点数 X = X.astype('float32') # 从 [0,255] 缩放到 [-1,1] X = (X - 127.5) / 127.5 print(X.shape, trainy.shape) return [X, trainy] |
我们还可以定义一个函数来选择训练数据集的一个子集,其中保留标签并训练判别器的有监督版本。
下面的select_supervised_samples()函数实现了这一点,并仔细确保样本的选择是随机的并且类别是平衡的。标记样本的数量被参数化并设置为100,这意味着10个类别中的每个类别将有10个随机选择的样本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 选择数据集的有监督子集,确保类别平衡 def select_supervised_samples(dataset, n_samples=100, n_classes=10): X, y = dataset X_list, y_list = list(), list() n_per_class = int(n_samples / n_classes) for i in range(n_classes): # 获取该类的所有图像 X_with_class = X[y == i] # 选择随机实例 ix = randint(0, len(X_with_class), n_per_class) # 添加到列表 [X_list.append(X_with_class[j]) for j in ix] [y_list.append(i) for j in ix] return asarray(X_list), asarray(y_list) |
接下来,我们可以定义一个函数来检索真实训练样本的批次。
选择图像和标签的样本,并进行替换。当我们在训练模型时,可以稍后使用相同的函数从标记和未标记的数据集中检索样本。对于“未标记数据集”,我们将忽略标签。
|
1 2 3 4 5 6 7 8 9 10 11 |
# 选择真实样本 def generate_real_samples(dataset, n_samples): # 分割为图像和标签 images, labels = dataset # 选择随机实例 ix = randint(0, images.shape[0], n_samples) # 选择图像和标签 X, labels = images[ix], labels[ix] # 生成类别标签 y = ones((n_samples, 1)) return [X, labels], y |
接下来,我们可以定义用于通过生成器模型生成图像的函数。
首先,generate_latent_points()函数将创建一批随机点在潜在空间中,这些点可以用作生成图像的输入。generate_fake_samples()函数将调用此函数来生成一批图像,这些图像可以在训练期间馈送到无监督判别器模型或复合GAN模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 z_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 z_input = z_input.reshape(n_samples, latent_dim) return z_input # 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(generator, latent_dim, n_samples): # 在潜在空间中生成点 z_input = generate_latent_points(latent_dim, n_samples) # 预测输出 images = generator.predict(z_input) # 创建类别标签 y = zeros((n_samples, 1)) return images, y |
接下来,我们可以定义一个函数,在需要评估模型性能时调用。
此函数将使用生成器模型的当前状态生成并绘制100张图像。这张图像图可用于主观评估生成器模型的性能。
然后,在整个训练数据集上评估有监督的判别器模型,并报告分类准确率。最后,将生成器模型和有监督的判别器模型保存到文件,以备将来使用。
下面的summarize_performance()函数实现了这一点,并且可以定期调用,例如在每个训练周期结束时。可以在运行结束时回顾结果,以选择一个分类器模型,甚至生成器模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 生成样本并保存为图,并保存模型 def summarize_performance(step, g_model, c_model, latent_dim, dataset, n_samples=100): # 准备伪示例 X, _ = generate_fake_samples(g_model, latent_dim, n_samples) # 将范围从[-1,1]缩放到[0,1] X = (X + 1) / 2.0 # 绘制图像 for i in range(100): # 定义子图 pyplot.subplot(10, 10, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(X[i, :, :, 0], cmap='gray_r') # 保存图到文件 filename1 = 'generated_plot_%04d.png' % (step+1) pyplot.savefig(filename1) pyplot.close() # 评估分类器模型 X, y = dataset _, acc = c_model.evaluate(X, y, verbose=0) print('分类器准确率: %.3f%%' % (acc * 100)) # 保存生成器模型 filename2 = 'g_model_%04d.h5' % (step+1) g_model.save(filename2) # 保存分类器模型 filename3 = 'c_model_%04d.h5' % (step+1) c_model.save(filename3) print('>已保存: %s, %s, 和 %s' % (filename1, filename2, filename3)) |
接下来,我们可以定义一个函数来训练模型。定义的模型和加载的训练数据集作为参数提供,训练周期数和批次大小被参数化并具有默认值,在本例中为20个周期和100个批次大小。
选择的模型配置发现很快就过拟合了训练数据集,因此训练周期数相对较少。将周期数增加到100或更多可以生成质量高得多的图像,但分类器模型的质量会降低。平衡这两者可能是一个有趣的扩展。
首先,选择训练数据集的标记子集,并计算训练步数。
训练过程与训练标准GAN模型几乎相同,只是增加了使用标记示例更新有监督模型。
更新模型的单个周期包括首先使用标记示例更新有监督的判别器模型,然后使用未标记的真实和生成示例更新无监督的判别器模型。最后,通过复合模型更新生成器模型。
判别器模型的共享权重使用1.5批次的样本进行更新,而生成器模型的权重在每次迭代中都使用一个批次的样本进行更新。将此更改为使每个模型由相同数量更新,可能会改进模型训练过程。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 训练生成器和判别器 def train(g_model, d_model, c_model, gan_model, dataset, latent_dim, n_epochs=20, n_batch=100): # 选择有监督数据集 X_sup, y_sup = select_supervised_samples(dataset) print(X_sup.shape, y_sup.shape) # 计算每个训练 epoch 的批次数量 bat_per_epo = int(dataset[0].shape[0] / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 计算半批样本的大小 half_batch = int(n_batch / 2) print('n_epochs=%d, n_batch=%d, 1/2=%d, b/e=%d, steps=%d' % (n_epochs, n_batch, half_batch, bat_per_epo, n_steps)) # 手动枚举 epoch for i in range(n_steps): # 更新监督判别器(c) [Xsup_real, ysup_real], _ = generate_real_samples([X_sup, y_sup], half_batch) c_loss, c_acc = c_model.train_on_batch(Xsup_real, ysup_real) # 更新无监督判别器(d) [X_real, _], y_real = generate_real_samples(dataset, half_batch) d_loss1 = d_model.train_on_batch(X_real, y_real) X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) d_loss2 = d_model.train_on_batch(X_fake, y_fake) # 更新生成器(g) X_gan, y_gan = generate_latent_points(latent_dim, n_batch), ones((n_batch, 1)) g_loss = gan_model.train_on_batch(X_gan, y_gan) # 总结此批次的损失 print('>%d, c[%.3f,%.0f], d[%.3f,%.3f], g[%.3f]' % (i+1, c_loss, c_acc*100, d_loss1, d_loss2, g_loss)) # 每隔一段时间评估模型性能 if (i+1) % (bat_per_epo * 1) == 0: summarize_performance(i, g_model, c_model, latent_dim, dataset) |
最后,我们可以定义模型并调用函数来训练和保存模型。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 潜在空间的大小 latent_dim = 100 # 创建判别器模型 d_model, c_model = define_discriminator() # 创建生成器 g_model = define_generator(latent_dim) # 创建GAN gan_model = define_gan(g_model, d_model) # 加载图像数据 dataset = load_real_samples() # 训练模型 train(g_model, d_model, c_model, gan_model, dataset, latent_dim) |
将所有这些内容结合起来,在 MNIST 手写数字图像分类任务上训练半监督 GAN 的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 |
# MNIST 的半监督 GAN 示例 from numpy import expand_dims from numpy import zeros from numpy import ones from numpy import asarray from numpy.random import randn from numpy.random import randint from keras.datasets.mnist import load_data from keras.optimizers import Adam from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Reshape from keras.layers import Flatten 从 keras.layers 导入 Conv2D from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU 从 keras.layers 导入 Dropout from keras.layers import Lambda from keras.layers import Activation from matplotlib import pyplot from keras import backend # 自定义激活函数 def custom_activation(output): logexpsum = backend.sum(backend.exp(output), axis=-1, keepdims=True) result = logexpsum / (logexpsum + 1.0) return result # 定义独立的监督和无监督判别器模型 def define_discriminator(in_shape=(28,28,1), n_classes=10): # 图像输入 in_image = Input(shape=in_shape) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image) fe = LeakyReLU(alpha=0.2)(fe) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # 下采样 fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # 展平特征图 fe = Flatten()(fe) # dropout fe = Dropout(0.4)(fe) # 输出层节点 fe = Dense(n_classes)(fe) # 监督输出 c_out_layer = Activation('softmax')(fe) # 定义并编译监督判别器模型 c_model = Model(in_image, c_out_layer) c_model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy']) # 无监督输出 d_out_layer = Lambda(custom_activation)(fe) # 定义并编译无监督判别器模型 d_model = Model(in_image, d_out_layer) d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5)) return d_model, c_model # 定义独立的生成器模型 def define_generator(latent_dim): # 图像生成器输入 in_lat = Input(shape=(latent_dim,)) # 7x7 图像的基础 n_nodes = 128 * 7 * 7 gen = Dense(n_nodes)(in_lat) gen = LeakyReLU(alpha=0.2)(gen) gen = Reshape((7, 7, 128))(gen) # 上采样到 14x14 gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen) gen = LeakyReLU(alpha=0.2)(gen) # 上采样到 28x28 gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen) gen = LeakyReLU(alpha=0.2)(gen) # 输出 out_layer = Conv2D(1, (7,7), activation='tanh', padding='same')(gen) # 定义模型 model = Model(in_lat, out_layer) return model # 定义组合的生成器和判别器模型,用于更新生成器 def define_gan(g_model, d_model): # 使判别器中的权重不可训练 d_model.trainable = False # 将生成器的图像输出作为判别器的输入 gan_output = d_model(g_model.output) # 将GAN模型定义为接收噪声并输出分类 model = Model(g_model.input, gan_output) # 编译模型 opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt) return model # 加载图像 def load_real_samples(): # 加载数据集 (trainX, trainy), (_, _) = load_data() # 扩展到3D,例如添加通道 X = expand_dims(trainX, axis=-1) # 从整数转换为浮点数 X = X.astype('float32') # 从 [0,255] 缩放到 [-1,1] X = (X - 127.5) / 127.5 print(X.shape, trainy.shape) return [X, trainy] # 选择数据集的有监督子集,确保类别平衡 def select_supervised_samples(dataset, n_samples=100, n_classes=10): X, y = dataset X_list, y_list = list(), list() n_per_class = int(n_samples / n_classes) for i in range(n_classes): # 获取该类的所有图像 X_with_class = X[y == i] # 选择随机实例 ix = randint(0, len(X_with_class), n_per_class) # 添加到列表 [X_list.append(X_with_class[j]) for j in ix] [y_list.append(i) for j in ix] return asarray(X_list), asarray(y_list) # 选择真实样本 def generate_real_samples(dataset, n_samples): # 分割为图像和标签 images, labels = dataset # 选择随机实例 ix = randint(0, images.shape[0], n_samples) # 选择图像和标签 X, labels = images[ix], labels[ix] # 生成类别标签 y = ones((n_samples, 1)) return [X, labels], y # 在潜在空间中生成点作为生成器的输入 def generate_latent_points(latent_dim, n_samples): # 在潜在空间中生成点 z_input = randn(latent_dim * n_samples) # 重塑为网络的输入批次 z_input = z_input.reshape(n_samples, latent_dim) return z_input # 使用生成器生成 n 个假示例,并带有类别标签 def generate_fake_samples(generator, latent_dim, n_samples): # 在潜在空间中生成点 z_input = generate_latent_points(latent_dim, n_samples) # 预测输出 images = generator.predict(z_input) # 创建类别标签 y = zeros((n_samples, 1)) return images, y # 生成样本并保存为图,并保存模型 def summarize_performance(step, g_model, c_model, latent_dim, dataset, n_samples=100): # 准备伪示例 X, _ = generate_fake_samples(g_model, latent_dim, n_samples) # 将范围从[-1,1]缩放到[0,1] X = (X + 1) / 2.0 # 绘制图像 for i in range(100): # 定义子图 pyplot.subplot(10, 10, 1 + i) # 关闭轴线 pyplot.axis('off') # 绘制原始像素数据 pyplot.imshow(X[i, :, :, 0], cmap='gray_r') # 保存图到文件 filename1 = 'generated_plot_%04d.png' % (step+1) pyplot.savefig(filename1) pyplot.close() # 评估分类器模型 X, y = dataset _, acc = c_model.evaluate(X, y, verbose=0) print('分类器准确率: %.3f%%' % (acc * 100)) # 保存生成器模型 filename2 = 'g_model_%04d.h5' % (step+1) g_model.save(filename2) # 保存分类器模型 filename3 = 'c_model_%04d.h5' % (step+1) c_model.save(filename3) print('>已保存: %s, %s, 和 %s' % (filename1, filename2, filename3)) # 训练生成器和判别器 def train(g_model, d_model, c_model, gan_model, dataset, latent_dim, n_epochs=20, n_batch=100): # 选择有监督数据集 X_sup, y_sup = select_supervised_samples(dataset) print(X_sup.shape, y_sup.shape) # 计算每个训练 epoch 的批次数量 bat_per_epo = int(dataset[0].shape[0] / n_batch) # 计算训练迭代次数 n_steps = bat_per_epo * n_epochs # 计算半批样本的大小 half_batch = int(n_batch / 2) print('n_epochs=%d, n_batch=%d, 1/2=%d, b/e=%d, steps=%d' % (n_epochs, n_batch, half_batch, bat_per_epo, n_steps)) # 手动枚举 epoch for i in range(n_steps): # 更新监督判别器(c) [Xsup_real, ysup_real], _ = generate_real_samples([X_sup, y_sup], half_batch) c_loss, c_acc = c_model.train_on_batch(Xsup_real, ysup_real) # 更新无监督判别器(d) [X_real, _], y_real = generate_real_samples(dataset, half_batch) d_loss1 = d_model.train_on_batch(X_real, y_real) X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch) d_loss2 = d_model.train_on_batch(X_fake, y_fake) # 更新生成器(g) X_gan, y_gan = generate_latent_points(latent_dim, n_batch), ones((n_batch, 1)) g_loss = gan_model.train_on_batch(X_gan, y_gan) # 总结此批次的损失 print('>%d, c[%.3f,%.0f], d[%.3f,%.3f], g[%.3f]' % (i+1, c_loss, c_acc*100, d_loss1, d_loss2, g_loss)) # 每隔一段时间评估模型性能 if (i+1) % (bat_per_epo * 1) == 0: summarize_performance(i, g_model, c_model, latent_dim, dataset) # 潜在空间的大小 latent_dim = 100 # 创建判别器模型 d_model, c_model = define_discriminator() # 创建生成器 g_model = define_generator(latent_dim) # 创建GAN gan_model = define_gan(g_model, d_model) # 加载图像数据 dataset = load_real_samples() # 训练模型 train(g_model, d_model, c_model, gan_model, dataset, latent_dim) |
该示例可以在配备 CPU 或 GPU 硬件的工作站上运行,但建议使用 GPU 以获得更快的执行速度。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行该示例几次并比较平均结果。
在运行开始时,将总结训练数据集的大小,以及监督子集的大小,以确认我们的配置。
每个模型的性能在每次更新结束时都会进行总结,包括监督判别器模型(c)的损失和准确率,无监督判别器在真实和生成样本上的损失(d),以及通过复合模型更新的生成器模型的损失(g)。
监督模型的损失将收缩到一个接近零的小值,准确率将达到 100%,并在整个运行过程中保持不变。如果无监督判别器和生成器保持平衡,它们的损失应该在整个运行过程中保持在适中的值。
|
1 2 3 4 5 6 7 8 9 |
(60000, 28, 28, 1) (60000,) (100, 28, 28, 1) (100,) n_epochs=20, n_batch=100, 1/2=50, b/e=600, steps=12000 >1, c[2.305,6], d[0.096,2.399], g[0.095] >2, c[2.298,18], d[0.089,2.399], g[0.095] >3, c[2.308,10], d[0.084,2.401], g[0.095] >4, c[2.304,8], d[0.080,2.404], g[0.095] >5, c[2.254,18], d[0.077,2.407], g[0.095] ... |
监督分类模型在每个训练 epoch 结束时(在本例中是每 600 次训练更新后)在整个训练数据集上进行评估。此时,模型的性能得以总结,显示其能够快速获得良好的技能。
考虑到模型仅在每类 10 个标记示例上进行训练,这令人惊讶。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
分类器准确率:85.543% 分类器准确率:91.487% 分类器准确率:92.628% 分类器准确率:94.017% 分类器准确率:94.252% 分类器准确率:93.828% 分类器准确率:94.122% 分类器准确率:93.597% 分类器准确率:95.283% 分类器准确率:95.287% 分类器准确率:95.263% 分类器准确率:95.432% 分类器准确率:95.270% 分类器准确率:95.212% 分类器准确率:94.803% 分类器准确率:94.640% 分类器准确率:93.622% 分类器准确率:91.870% 分类器准确率:92.525% 分类器准确率:92.180% |
模型也会在每个训练 epoch 结束时保存,并且还会生成生成的图像的图。
与相对较少的训练 epoch 相比,生成的图像质量很好。
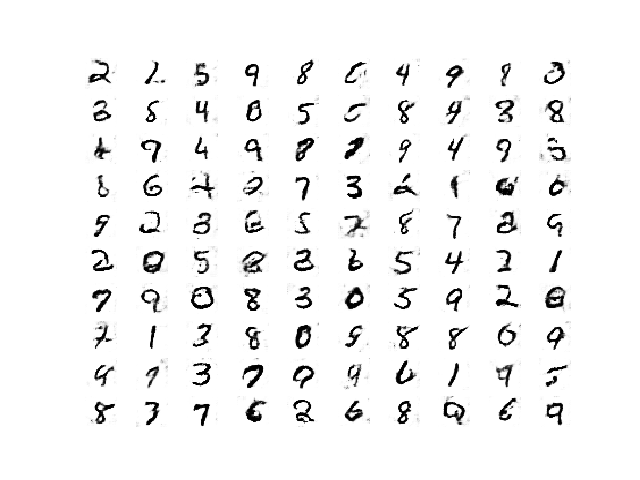
经过 8400 次更新后,半监督 GAN 生成的手写数字图。
如何加载和使用最终的 SGAN 分类器模型
现在我们已经训练了生成器和判别器模型,我们可以利用它们了。
在半监督 GAN 的情况下,我们对生成器模型的兴趣较小,而对监督模型的兴趣较大。
回顾特定运行的结果,我们可以选择一个已知在测试数据集上具有良好性能的特定保存模型。在本例中,是在 12 个训练 epoch 或 7,200 次更新后保存的模型,该模型在训练数据集上的分类准确率为 95.432%。
我们可以通过 Keras 的 load_model() 函数直接加载模型。
|
1 2 3 |
... # 加载模型 model = load_model('c_model_7200.h5') |
加载后,我们可以再次在整个训练数据集上评估它以确认发现,然后在其上评估保留的测试数据集。
请记住,特征提取层期望输入图像的像素值缩放到 [-1,1] 的范围,因此,在将任何图像提供给模型之前必须进行此操作。
加载已保存的半监督分类器模型并在完整的 MNIST 数据集上对其进行评估的完整示例如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 加载分类器模型并生成图像的示例 from numpy import expand_dims from keras.models import load_model from keras.datasets.mnist import load_data # 加载模型 model = load_model('c_model_7200.h5') # 加载数据集 (trainX, trainy), (testX, testy) = load_data() # 扩展到 3d,例如添加通道 trainX = expand_dims(trainX, axis=-1) testX = expand_dims(testX, axis=-1) # 从 ints 转换为 floats trainX = trainX.astype('float32') testX = testX.astype('float32') # 从 [0,255] 缩放到 [-1,1] trainX = (trainX - 127.5) / 127.5 testX = (testX - 127.5) / 127.5 # 评估模型 _, train_acc = model.evaluate(trainX, trainy, verbose=0) print('Train Accuracy: %.3f%%' % (train_acc * 100)) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Test Accuracy: %.3f%%' % (test_acc * 100)) |
运行该示例将加载模型并在 MNIST 数据集上对其进行评估。
注意:由于算法或评估程序的随机性,或数值精度的差异,您的结果可能会有所不同。请考虑运行该示例几次并比较平均结果。
我们可以看到,在本例中,模型在训练数据集上达到了预期的 95.432% 的性能,证实我们已加载了正确的模型。
我们还可以看到,在保留的测试数据集上的准确率同样良好,甚至略好,约为 95.920%。这表明学习到的分类器具有良好的泛化能力。
|
1 2 |
训练准确率:95.432% 测试准确率:95.920% |
我们已经成功演示了通过 GAN 架构拟合的半监督分类器模型的训练和评估。
扩展
本节列出了一些您可能希望探索的扩展本教程的想法。
- 独立分类器。在标记数据集上直接拟合一个独立的分类器模型,并将其性能与 SGAN 模型进行比较。
- 标记示例数量。重复使用更多或更少的标记示例的示例,并比较模型的性能。
- 模型调优。调整判别器和生成器模型的性能,以进一步提升监督模型的性能,使其更接近最先进的结果。
如果您探索了这些扩展中的任何一个,我很想知道。
请在下面的评论中发布您的发现。
进一步阅读
如果您想深入了解,本节提供了更多关于该主题的资源。
论文
- 半监督生成对抗网络学习, 2016.
- 训练 GAN 的改进技术, 2016.
- 基于分类生成对抗网络的无监督和半监督学习, 2015.
- 基于 GAN 的半监督学习:具有改进推理的流形不变性, 2017.
- 基于 GAN 的半监督学习:重新审视流形正则化, 2018.
API
- Keras数据集API。
- Keras 序列模型 API
- Keras卷积层API
- 我如何“冻结”Keras层?
- MatplotLib API
- NumPy 随机抽样 (numpy.random) API
- NumPy 数组操作例程
文章
- 基于 GAN 的半监督学习, 2018.
- 基于 GAN 的半监督学习, 2017.
项目
总结
在本教程中,您将学习如何从头开始开发一个半监督生成对抗网络。
具体来说,你学到了:
- 半监督GAN是GAN架构的扩展,用于在利用标记和未标记数据训练分类器模型。
- 在 Keras 中实现半监督 GAN 所使用的监督和无监督判别器模型,至少有三种方法。
- 如何从头开始在 MNIST 上训练半监督 GAN,并加载和使用训练好的分类器进行预测。
你有什么问题吗?
在下面的评论中提出你的问题,我会尽力回答。
立即开发生成对抗网络!

在几分钟内开发您的GAN模型
...只需几行python代码在我的新电子书中探索如何实现
使用 Python 构建生成对抗网络
它提供了关于以下内容的自学教程和端到端项目:
DCGAN、条件GAN、图像翻译、Pix2Pix、CycleGAN
以及更多...

 From Scratch with Keras")




SGAN 的概念解释得非常好。您能否在上述代码中加入特征匹配?
感谢您的建议。也许将来。
你好!我刚刚实现了一个可能的特征匹配版本。但我发现 FM 技巧根本没有帮助。有什么建议吗?我的代码在这里
https://github.com/King-Of-Knights/Keras-Semi-Supervised-Learning-GANs/blob/master/sslgan_feature_match.py
干得不错。
抱歉,我没有能力审查调试代码,因为我每天都会收到大量类似请求。
https://machinelearning.org.cn/faq/single-faq/can-you-read-review-or-debug-my-code
感谢 Jason 的精彩解释。我运行了代码,执行时间很长。
您认为,在这么长的执行时间内,SGAN 能否与 VAT 等其他类型的半监督学习竞争?
干得好!
这确实取决于问题的具体情况和模型。测试各种方法是个好主意。
太棒了 Jason!但是,如果我需要使用一个不在后端中的自定义函数,而不是自定义激活函数呢?例如,我生成了一个人脸图像作为输出,我想计算它的 FaceNet 嵌入,并在损失函数中惩罚生成和实际嵌入之间的差异。我认为我可以通过 tf.session.run 将其更改为数组,然后计算其 FaceNet 嵌入,但它抛出了一个错误,说我必须为占位符张量提供一个值。
非常酷的想法!
您可以使用自定义函数,但请记住您将使用张量而不是数组。因此,所有简单的操作都必须使用后端函数,这些函数将包装张量的 TF/Theano 函数。
可能需要一些实验。
你的意思是,我需要改变 Facenet 预测的所有代码吗?或者,如果我想使用 dlib 来提取每个张量的 68 个地标,我需要改变它们的代码。在他们的代码中,他们明确表示支持列表或数组作为输入。还有其他方法可以解决这个问题吗?
不,我的意思是,如果您使用自定义函数,您将处理张量而不是数组。
您使用什么版本的 Keras 和 TensorFlow?
Keras 2.3 和 TF2.0。
# 更新监督判别器(c)
[Xsup_real, ysup_real], _ = generate_real_samples([X_sup, y_sup], half_batch)
c_loss, c_acc = c_model.train_on_batch(Xsup_real, ysup_real)
如果我们想训练监督判别器,我们需要使用标记数据,对吗?我的意思是,我们应该使用
[Xsup_real, ysup_real], _ = select_supervised_samples(datasets)
而不是
[Xsup_real, ysup_real], _ = generate_real_samples([X_sup, y_sup], half_batch)
我很困惑,我错了还是没有?谢谢!
抱歉,是我的错,没关系!您的教程太棒了,真的帮了我很多!
不客气。
您能给我们提供一个关于 CatGAN 的教程吗?
感谢您的建议!
感谢您精彩的讲解!
我想用您的 SGAN 代码进行 2D 图像分割。
由于我刚接触深度学习,所以想问一些问题。
1. 将判别器当前的 1D 输出层修改为 2D 输出层是否适用于分割?
2. 如果您知道,能否告诉我一些用于 2D 图像的 Keras 分割代码的良好示例?
3. 如果您将代码修改为用于 2D 图像分割,您会怎么做?
再次感谢您,祝您有美好的一天!
抱歉,我不知道如何直接将此示例应用于分割。
感谢您提供的精彩文章!
我研究了您提到的两个扩展,并将 SGAN 的性能与独立分类器进行了比较。我每次都使用不同数量的标记数据来训练 SGAN 和独立分类器。
我还为独立分类器和 SGAN 添加了数据增强(主要是因为独立分类器在没有数据增强的情况下性能非常低)。
结果基本符合预期,但确实显示了 SGAN 在少量监督数据下的影响。
代码和结果(生成的图)可在我的 GitHub 存储库中找到 – https://github.com/zoharri/SGAN_vs_Classifier。
谢谢。
您做的扩展很棒!感谢分享。
你好 Json,感谢您的解释。
SGAN 中的判别器多分类器实例是独立训练的,并且不与生成器连接。您能否解释一下它与普通 CNN 分类器的区别?
判别器是一个简单的图像分类器。
感谢这篇很棒的文章!
我对于如何将输入馈送到具有多个输出的单个判别器模型感到困惑。假设我们有 X_train(标记)和 X_test(未标记)数据。X_test 的输出应该馈送到“d_output_layer”,X_train 的输出应该馈送到“c_output_layer”。那么,我们该如何处理?我的意思是,如何馈送数据并从所需层获取输出。
谢谢
抱歉,我不明白您遇到的问题。
哪种 Python、Keras 和 TensorFlow 版本适合运行上述代码?
我为 python 3.6 遇到了以下错误
ImportError: Could not find ‘msvcp140.dll’. TensorFlow requires that this DLL be installed in a directory that is named in your %PATH% environment variable. You may install this DLL by downloading Visual C++ 2015 Redistributable Update 3 from this URL: https://www.microsoft.com/en-us/download/details.aspx?id=53587
Keras 2.3 和 TensorFlow 2。
感谢您抽出宝贵时间为我解答疑问。
不客气。
嗨,Jason,
感谢您提供这个精彩的教程。
我尝试将其应用于我的用例,但生成器为所有类生成相同的图像。您知道这是为什么吗?
不客气。
也许可以尝试更改模型的配置以适应您的数据?
我确实尝试增加了每类的样本数量。还有其他可以改进这种情况的参数吗?
是的,请看这个
https://machinelearning.org.cn/how-to-code-generative-adversarial-network-hacks/
你好!感谢您的精彩解释!
我有一个关于共享权重的堆叠判别器的问题。如果监督和无监督判别器在激活层之前共享权重。那么,为什么 c_model 有 316,938 个权重,而 d_model 有 633,876 个权重?在我看来,c_model 和 d_model 都共享公共层,并应用不同的激活函数来创建不同的模型。那么它们的权重数量应该相同吗?
谢谢!
抱歉!我指的是 316,938 个参数和 633,876 个参数,而不是权重。
这也许有助于理解 GAN 训练
https://machinelearning.org.cn/how-to-code-the-generative-adversarial-network-training-algorithm-and-loss-functions/
你好,
这是一篇很棒的文章,我能够在我的应用程序中实现它。我不太清楚应该保存哪个模型来生成图像?您最后是如何生成图像的?我应该保存哪个模型来做同样的事情?通常,我们会保存生成器模型,但我在这里有点困惑。
谢谢 🙂
谢谢!
生成器模型用于生成图像。
是的,我们保存生成器模型。
您好,您的文章非常好,对我有帮助!
我有一个小问题,如果这个模型可以转换为传统的数据形式,也就是向量形式,该如何改变呢?
谢谢!
谢谢!
是的,但 GANs 是为了图像设计的,而不是表格数据。这是一个例子
https://machinelearning.org.cn/how-to-develop-a-generative-adversarial-network-for-a-1-dimensional-function-from-scratch-in-keras/
本教程中的分类器准确性是什么意思?是说分类器识别样本标签(例如0-9)的效率如何?还是分类器准确性表示分类器区分真实样本和生成(或假)样本的效率如何?此外,分类器准确性和训练准确性是一样的吗?
我们在这里训练一个生成器和一个分类模型。准确性是指分类模型。
也许重读一下“什么是半监督 GAN?”这一节。
如何获得生成器生成的图像的类别标签?
您可以使用分类模型对生成的图像进行分类。
谢谢,这句话对我来说是有用的:“c_out_layer = Activation(‘softmax’)(fe)”
太棒了!
如何选择 latent_dim?它属于数据集吗?
我正在尝试将此应用于另一个数据集,那么如何调整另一个数据集的 latent_dim 值?因为我使用了值=100,结果准确率很差,只有53%,是其他问题吗?
谢谢,
通常很小。模型对尺寸不太敏感,因为它们会施加自己的结构。
谢谢,我正在用我的数据尝试您的代码,我的图像尺寸是 256x256x3,而且准确率很低,所以我想知道问题是出在分类模型还是潜在维度上,因为我也显示了生成的图像,而且它们在多次迭代后质量非常差?
准确性是 GAN 的一个糟糕指标,直接查看生成的图像。
也许这里的一些建议会有帮助
https://machinelearning.org.cn/how-to-code-generative-adversarial-network-hacks/
您说训练超过 100 个 epoch 会提高图像生成但不会提高分类(在第 12 个 epoch 达到最高分类器准确率的例子中),现在您又说图像质量对准确性很重要?这里的诀窍是什么????? 您能否就准确性与图像生成提供更多见解?顺便说一句,这个页面上的所有作品都太棒了,您太棒了,谢谢,继续加油!
抱歉,我的评论是关于 GAN 的通用评论,例如在使用 GAN 进行图像生成时。
嗨
很棒的文章,我学到了很多。
有一件事对我来说不清楚。在训练生成器时,为什么您要生成标签为 1?
X_gan, y_gan = generate_latent_points(latent_dim, n_batch), ones((n_batch, 1))
好问题,请看这个
https://machinelearning.org.cn/how-to-code-the-generative-adversarial-network-training-algorithm-and-loss-functions/
嗨,Jason,
非常感谢您提供清晰有用的文章!
我遇到了一个奇怪的问题,当时我在 TensorFlow (2.3.0) 中改编了这个例子——模型在单个 epoch/600 步内就能训练到合理的准确率,但如果我保存然后重新加载它,准确率就会变成随机的 (~10%)。
您知道可能是什么问题吗?
…
# 训练模型
train(g_model, d_model, c_model, gan_model, dataset, latent_dim, n_epochs=1)
# 加载数据集
(trainX, trainy) = dataset
_, train_acc = c_model.evaluate(trainX, trainy, verbose=0)
print(‘Final Accuracy: %.3f%%’ % (train_acc * 100)) # 这个值 >80%
### 从文件中加载 c_model 并将其应用于相同数据
from tensorflow.keras.models import load_model
model = load_model(‘res/c_model_0600_sm’) #.h5
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
print(‘Final Accuracy: %.3f%%’ % (train_acc * 100)) # 这个值 <10%
也许可以尝试使用独立的 Keras 库并比较您系统上的结果?
嗨 Jason
非常感谢您对 ML 的热情和您的有用文章
我在 Google Colab 中遇到了同样的问题。您说的“使用独立的 Keras 库”是什么意思?
我认为即使导入 keras 库,colab 也会自动导入 tensorflow.keras,并且 tensorflow 的版本是 2.3.0。我做了一些搜索,但都不明白。您能帮帮我吗?
谢谢
我指的是使用 keras 而不是 tf.keras
https://machinelearning.org.cn/faq/single-faq/what-is-the-difference-between-keras-and-tf-keras
你好!
为什么我们将 d_model.trainable 设置为 False?我以为我们在训练 d_model,并在半监督 GAN 中禁用生成器。
提前感谢您!
好问题,您可以在这里了解更多关于我们在 Keras 中如何构建 GAN 模型进行训练。
https://machinelearning.org.cn/how-to-code-the-generative-adversarial-network-training-algorithm-and-loss-functions/
谢谢!
嗨,Jason,
感谢这次精彩的解释!
– 您能否介绍一下“使用 CNN 的自监督图像分类”的文章/资源?
考虑到我们的数据集没有任何标签(注释过的标签),并且我们想对图像进行分类。您会怎么解决?
感谢您的指导,
感谢您的建议。
您知道有什么资源可以参考吗?
谢谢
是的,这会有帮助
https://machinelearning.org.cn/faq/single-faq/where-can-i-get-a-research-paper-on-___
您好,您能提供一张像这张一样的架构图吗?-> https://media.arxiv-vanity.com/render-output/3592810/semi_gans.png
谢谢!
感谢您的建议。
您好,我觉得这个概念非常有趣。但是,我正在尝试运行代码以获得视觉体验,但似乎有一些错误消息。另外,我想了解一下 SGAN 是否适用于分类真实和虚假的指纹,因为我目前正在研究这个。谢谢。
谢谢。
为什么不直接使用多层感知机模型?为什么要使用 GAN?
嗨,Jason,
我实现了您的代码。但我不知道为什么当我加载模型并测试模型时,准确率是 9.99%。
也许仔细检查一下您是否复制了所有代码?
也许尝试重新拟合模型?
也许检查库版本号?
这是训练过程
>11988, c[0.001,100], d[0.742,0.858], g[1.056]
>11989, c[0.001,100], d[0.828,0.937], g[0.922]
>11990, c[0.001,100], d[0.970,0.843], g[0.903]
>11991, c[0.001,100], d[0.792,0.848], g[1.147]
>11992, c[0.001,100], d[0.944,0.992], g[1.223]
>11993, c[0.002,100], d[0.712,0.919], g[1.263]
>11994, c[0.002,100], d[0.667,0.846], g[1.177]
>11995, c[0.002,100], d[0.923,0.911], g[1.162]
>11996, c[0.001,100], d[0.916,0.775], g[1.115]
>11997, c[0.001,100], d[0.799,0.638], g[0.975]
>11998, c[0.002,100], d[0.837,0.939], g[0.914]
>11999, c[0.001,100], d[0.810,0.816], g[0.961]
>12000, c[0.001,100], d[0.676,0.928], g[1.012]
分类器准确率:92.422%
>已保存:generated_plot_12000.png, g_model_12000.h5, and c_model_12000.h5
但当我加载模型时,结果是这样的
警告:tensorflow:加载已保存优化器状态时出错。因此,您的模型将从一个新初始化的优化器开始。
训练准确率:9.690%
测试准确率:9.720%
先生,您好,
我想感谢您的回复,
我用 MNIST 数据集运行了您的代码,它逐行完全一致,并且训练时的准确率是正确的,具有高准确率,但在我加载模型并测试之后却有所不同。我不确定原因。当我尝试使用另一个数据集时,我也遇到了类似的错误。
这太奇怪了!我以前从未见过这种情况。
我想知道模型是否没有正确保存/加载,例如,也许在保存前后检查权重值。
您好,非常感谢您的评论。
我检查了 TensorFlow 和 Keras,现在结果没问题了。
再次非常感谢。
您好,当您设置 d_model.trainable = False 时,这是否不会阻止判别器学习?也许 train_on_batch 会覆盖这一点,但我正在使用 tf.gradienttape 尝试,并且除非我在训练过程中将 d_model.trainable 设置为 True,否则我无法更改模型的权重。
不行。
它只在复合模型中生效。您可以在 API 文档中了解有关层冻结的更多信息。
您仍然可以手动更改权重——“trainable”标志被 Keras API 在调用 fit() 等内部尊重。
你好,
通过将 d_model.trainable 设置为 False,这是否阻止了判别器和分类器学习?至少我尝试过使用 GradientTape。也许 train_on_batch 会覆盖它?是我理解错了什么吗?
不。它只在判别器作为复合模型的一部分时产生影响。
也许从这里开始
https://machinelearning.org.cn/how-to-develop-a-generative-adversarial-network-for-a-1-dimensional-function-from-scratch-in-keras/
如何加载自定义数据集?假设我以前在我的机器上有一个图像数据集。
也许这可以帮助您加载图像
https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/
我没明白潜空间到底是什么?
是的,我明白了。第一次接触确实有点让人头晕。
试试这个教程
https://machinelearning.org.cn/what-are-generative-adversarial-networks-gans/
您好,当我使用自定义激活时,我的判别器模型的损失没有改善。
还有,为什么我们需要在训练集而不是验证集上评估数据?
通常 GAN 不会收敛,所以损失不会改善。
https://machinelearning.org.cn/faq/single-faq/why-is-my-gan-not-converging
您好,我有一些问题。
1. 为什么我们需要在训练集上评估而不是验证集?
2. 我不知道为什么,但当我使用 custom_activation 时,监督判别器的损失没有改善。
谢谢
我建议在验证集上进行评估,我在这里是为了让示例更简单。
https://machinelearning.org.cn/faq/single-faq/why-do-you-use-the-test-dataset-as-the-validation-dataset
感谢您的回复,您是最棒的。
我还有另一个问题。您为什么要使用 Adam 并设置 lr = 0.0002 和 beta = 0.5?这会影响 GAN 和结果的质量吗?
不客气。
是的,我相信这种 Adam 配置通常是推荐的,并且对于 GAN 模型普遍有效。
当我使用自定义激活时,我的判别器对真实样本的损失总是太高(约 0.75~),准确率仅为 0.02。而我的判别器对假样本的损失较低(约 0.3~),准确率接近 0.98。这正常吗?
也许可以与您特定数据集上的其他模型、其他配置进行比较。
再次感谢,Jason!
一如既往,非常感谢您在这里分享这些信息。
我有一个疑问:是否可以将预训练模型(例如 VGG16)包含进生成器?这样可以帮助生成器利用预训练模型提取的特征来生成更好的图像。
感谢您的任何回复。
不客气。
您也许可以使用预训练模型,但我预计性能会更差。您可以尝试一下。
嗨,Brownlee先生,
非常感谢您提供这个资源。我想知道如何使用自定义数据集(96×96 图像,13 个类别)来运行这个示例。
我该如何更新 n_nodes = 128 * 7 * 7,以及 gen = Reshape((7, 7, 128))(gen),和 gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’)(gen)?
以及我该如何更改 in_shape=(28,28,1)?
我查阅了 https://machinelearning.org.cn/how-to-load-and-manipulate-images-for-deep-learning-in-python-with-pil-pillow/,但仍然有些卡住。关于这个示例,任何帮助都会很感激。
抱歉,我不确定在这种情况下该如何提供指导。您可能需要进行一些尝试和错误来调整模型以适应您的数据集。
自定义激活函数是否可以用于二分类问题,还是只能用于多类问题?
是的,您可以使用自定义激活函数。
当我绘制 discriminator.summary() 时,它显示我有不可训练的参数,这正常吗?
这看起来确实很奇怪。
您可以做一个测试吗?我在这里测试过,当调用 build_gan() 时就会发生这种情况。也许当 train_on_batch 时,模型即使 trainable=False 也会训练,但当我们使用 fit() 时就不行了。
你好,
我正在将 GAN 用于全监督问题。但是,我的指标非常差。您能检查一下我下面的训练循环——特别是 criterion 部分吗?
谢谢
在我看来似乎还可以。GAN可能需要很长时间才能训练好。
很棒的文章。
感谢您的反馈和赞美!
此致,
先生您好,我有一个非常基础的问题。我们如何计算神经网络的训练时间?
您好 Norman…您使用的是什么环境?在此讨论中可以找到使用 Jupyter Notebook 的示例
https://towardsdatascience.com/report-time-execution-prediction-with-keras-and-tensorflow-8c9d9a889237
我正在使用 TensorFlow 和 Google Colab。
感谢您的反馈 Norman!以下资源也可能让您对设置本地环境感兴趣。
https://machinelearning.org.cn/setup-python-environment-machine-learning-deep-learning-anaconda/
强烈建议您在能力范围内,在 Colab 中运行 Python 代码,并同时运行本地 Python 实例(如 Anaconda),以增加您对编程和调试的信心。
此致,
我的神经网络每个 epoch 需要 4 秒,每一步需要 2 毫秒。我的目标是计算神经网络的总训练时间。所以,我对此感到困惑。
您好,您能分享一下此代码的 PyTorch 实现吗?
您好 ZMB…以下内容可能对您有帮助
https://machinelearning.org.cn/pytorch-tutorial-develop-deep-learning-models/
你好,
在具有共享权重的独立判别器模型中,您是如何训练它的?
我的意思是,如果分类器模型没有额外的标签来预测类别是否为“未知”,您只能在有标签的图像上训练该模型,对吗?
那么您是先将所有图像(有标签和无标签的真实图像,以及生成的假图像)输入到第一个判别器,然后将少量有标签的图像输入到第二个判别器吗?
谢谢。
您好 Juan…以下内容可能有所帮助
https://machinelearning.org.cn/how-to-code-the-generative-adversarial-network-training-algorithm-and-loss-functions/
嗨
在您写“bat_per_epo = int(dataset[0].shape[0] / n_batch)”的 train 函数的行中,
难道不应该是
bat_per_epo = int(X_sup.shape[0] / n_batch)
?
因为 dataset[0] 包含整个 mnist x_train,而我们实际上只使用了其中的 100 张图片。
感谢您的反馈 Mahdi!
我们可以将代码用于另一个数据集(二分类)吗?如果可以,如何做?
我可以在多标签分类特征提取中使用 GAN 作为图像到 CSV 文件的判别器吗?
您好 Arega…以下讨论可能有助于阐明
https://www.quora.com/Can-Generative-Adversarial-networks-use-multi-class-labels
您好,当您说您训练了 20 个 epoch,n_batch=100 时
如果我想将其与基于 CNN 的分类器进行比较,我应该也运行它 20 个 epoch,还是其他数量?
您好 Ashay…您的理解是正确的!建议您按您所说的那样做。
谢谢,那么如果我的理解是正确的,即使步数约为 1000 步(batch_size=256),GAN 也只训练 20 个 epoch 吗?
在这里,其他未标记的样本被用于训练整个数据集,然后生成模型可以学习更好的特征,然后分类器判别器模型训练 20 个 epoch,但当正常判别器更新权重时,它也会获得权重更新。
您好 Ashay…您说得对!请与我们分享您的 GAN 模型表现如何!
谢谢,我注意到对于有 10 个类别的医学图像数据,当每类至少有 300 个以上样本时,基线 CNN 的表现接近 ssgan。直到 100 个样本时,仍然有超过 5% 的准确率差异。
就像 MNIST 一样,分类器模型是 7200c.h5,这是否意味着它比训练了 20 个 epoch 的传统 ML 分类器训练得更多?
只需相应地更改损失函数、n_classes 和样本即可,例如这里的 100 可能意味着每个 50。